Visión general de Speech
Puede utilizar el servicio Speech para convertir archivos multimedia en texto legible almacenado en formato JSON y SRT.
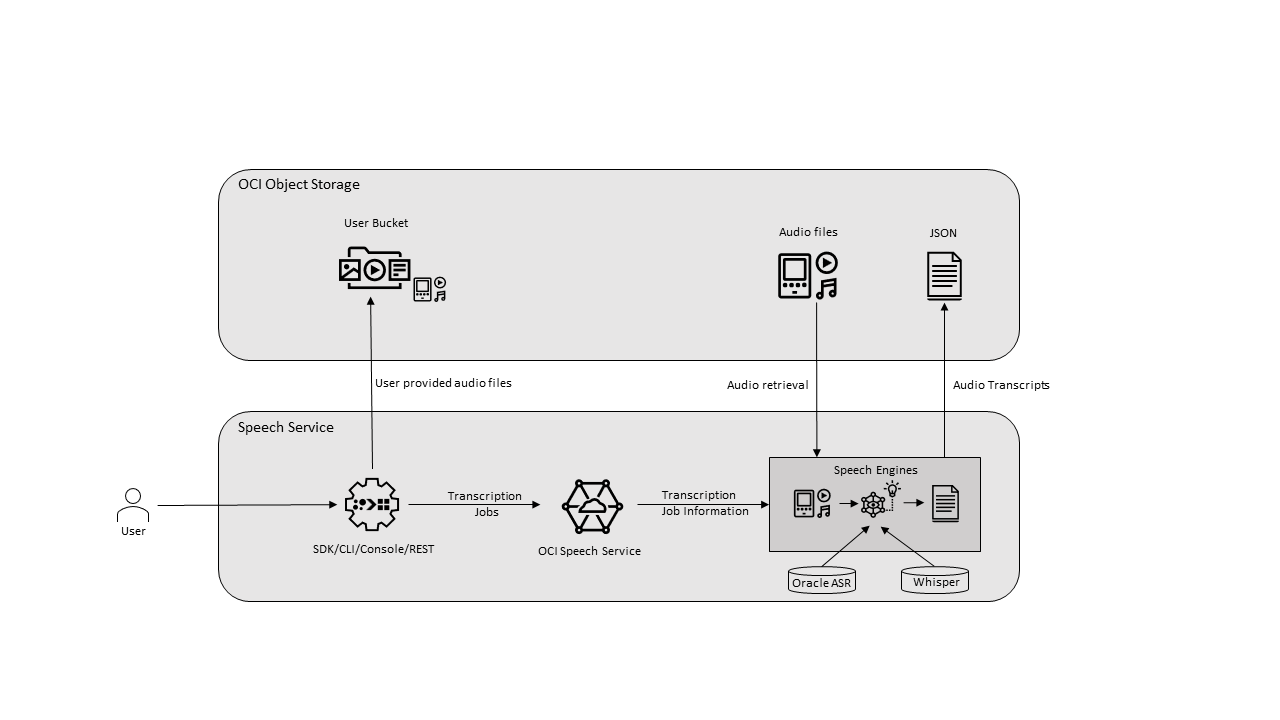
El habla aprovecha el poder del lenguaje hablado, lo que le permite convertir fácilmente los archivos multimedia que contienen el habla humana en transcripciones de texto altamente exactas. El servicio es una aplicación nativa de Oracle Cloud Infrastructure (OCI) a la que puede acceder mediante la consola, la API de REST, la CLI y el SDK. Además, puede utilizar el servicio Speech en una sesión de bloc de notas de Data Science.
El habla utiliza la tecnología de reconocimiento automático de voz (ASR) para proporcionar una transcripción gramaticalmente correcta. Speech maneja grabaciones de medios de baja fidelidad y transcribe grabaciones desafiantes como reuniones o llamadas a centros de llamadas. Con Speech, puede convertir los archivos almacenados en Object Storage o en un activo de datos en texto exacto, normalizado, con registro de hora y filtrado por palabras malsonantes. Esta funcionalidad solo está disponible con Speech. Por ejemplo, puede indexar la salida de voz (un archivo de texto) mediante Data Lake. Sin los servicios descendentes, esta capacidad no existe en Speech.
Los modelos Speech son robustos para entornos acústicos y canales de grabación que aseguran que se trata de un servicio de transcripción de buena calidad.
Compatibilidad con varios formatos de medios por idioma
Estos formatos de medios son compatibles con todos los idiomas admitidos en el servicio Speech:
AACAC3AMRAUFLACM4AMKVMP3MP4OGAOGGOPUSWAVWEBM
| Idioma | Código de Idioma | Ratio de muestra |
|---|---|---|
| Inglés-Estados Unidos | en-US |
>= 8 khz |
| Español-España | es-ES |
>= 8 khz |
| Portugués-Brasil | pt-BR |
>= 8 khz |
| Inglés de Gran Bretaña | en-GB |
>= 16 khz |
| Inglés - Australia | en-AU |
>= 16 khz |
| Inglés - India | en-IN |
>= 16 khz |
| Hindi-India | hi-IN |
>= 16 khz |
| Francés | fr-FR |
>= 16 khz |
| Alemán-Germany | de-DE |
>= 16 khz |
| Italiano-Italia | it-IT |
>= 16 khz |
Para unos mejores resultados:
- Utilice un formato sin pérdidas como FLAC o WAV con codificación PCM de 16 bits.
- Utilice una frecuencia de muestreo de 8.000 Hz para medios de baja fidelidad y de 16.000 a 48.000 Hz para medios de alta fidelidad.
Puede utilizar archivos de medios WAV de PCM de un solo canal de 16 bits con una frecuencia de muestreo de 8 kHz o 16 kHz. Recomendamos Audacity (GUI) o FFmpeg (línea de comandos) para la transcodificación de medios. Se admite una longitud máxima de archivo de medios de cuatro horas y hasta 2 GB.
El habla es susceptible a la calidad de los archivos multimedia de entrada. Los diferentes acentos, los ruidos de fondo, el cambio de un idioma a otro, el uso de idiomas de fusión o múltiples hablantes al mismo tiempo afectan la calidad de la transcripción.
El habla proporciona estas capacidades
-
Transcripciones precisas: produce archivos JSON y subtítulos (SRT) SubRip precisos y fáciles de usar escritos directamente en el cubo de Object Storage que elija. Puede aprovechar la transcripción e integrarla directamente con las aplicaciones, y utilizarla para subtítulos o búsqueda y análisis de contenido.
- Modelo de susurro: los datos multilingües se recopilan de la web y soportan la transcripción de voz a texto basada en archivos para más de 50 idiomas.
-
JSON con registro de hora: la transcripción proporciona un registro de hora para cada token (palabra). Puede utilizar el registro de hora para buscar y encontrar el texto que está buscando en el archivo multimedia y luego saltar rápidamente a esa ubicación.
-
Multilingüe: produce transcripciones precisas en inglés, inglés-Gran Bretaña, inglés-Australia, inglés-India, español, portugués, francés, italiano, alemán e hindi.
-
API asíncrona: API asíncronas directas con procesamiento por lotes de tareas de transcripción. Las API permiten cancelar trabajos que aún no se han procesado, lo que permite ahorrar tiempo y dinero.
-
Normalizaciones de texto: proporciona normalizaciones de texto para números, direcciones, monedas, etc. Con las normalizaciones de texto, obtienes una transcripción de mayor calidad de la inteligencia artificial que es más fácil de leer y comprender.
-
Filtrado de profesionalidad: permite eliminar, enmascarar o etiquetar palabras ofensivas de la transcripción.
-
Puntuación de confianza por palabra y transcripción: produce puntuaciones de confianza de palabras y transcripciones en el archivo JSON generado. Puede utilizar las puntuaciones de confianza para identificar rápidamente las palabras que requieren atención.
-
Títulos cerrados: proporciona un archivo SRT como formato de salida adicional. Use la SRT para agregar subtítulos cerrados a los archivos de video.
-
Puntuación: el texto largo requiere puntuación, por lo que Speech puntúa el contenido de la transcripción automáticamente.
-
Telephoney ready: los archivos pueden ser 8 kHz o 16 kHz y cada uno se detecta automáticamente para que se aplique el modelo correcto. Con esta capacidad, puede transcribir grabaciones telefónicas.
-
Diarización de altavoces: asocia texto de transcripción con altavoces específicos mediante escenarios de comprensión del lenguaje natural, como extraer una prescripción de audio médico identificando al proveedor de servicios en comparación con el paciente. La diarización de altavoces es una combinación de segmentación de altavoces y agrupación de altavoces. La segmentación del altavoz encuentra los puntos de cambio del altavoz en un flujo de audio. Los grupos de altavoces agrupan segmentos de voz en función de las características del altavoz.
Conceptos Clave
Estos son los conceptos clave del servicio Speech:
- Trabajos de transcripción
-
Un trabajo es una única solicitud asíncrona de la consola o la API de voz. Cada trabajo se identifica de forma única mediante un ID, que puede utilizar para recuperar el estado y los resultados del trabajo.
Un trabajo en un inquilino se procesa en un principio estricto de primera manera. Cada trabajo puede contener hasta 100 tareas. Si ejecuta un trabajo que supera el máximo de tareas, ese trabajo falla. Los trabajos se conservan durante 90 días.
- Transcribir en tiempo real
- Permite enviar un flujo de audio al servicio y recibir los resultados en texto (formato JSON y SRT) en tiempo real.
- tareas
-
Una tarea es el resultado de un único archivo procesado en un trabajo. Los trabajos pueden tener varias tareas en función de lo que esté almacenado en el cubo de Object Storage que especifique para un trabajo.
- Modelos
-
Los modelos acústicos y de lenguaje preentrenados, incluidos los modelos Whisper, impulsan el proceso de transcripción del trabajo.
Autenticación y autorización
Cada servicio de OCI se integra con IAM con fines de autenticación y autorización para todas las interfaces (la consola, el SDK o la CLI y la API de REST).
Un administrador de la organización debe definir grupos, compartimentos y políticas que controlen qué usuarios pueden acceder a qué servicios, qué recursos y el tipo de acceso. Por ejemplo, las políticas controlan quién puede crear usuarios, crear y gestionar la red en la nube, iniciar instancias, crear cubos, descargar objetos, etc. Para obtener más información, consulte Introducción a las políticas.
- Para obtener más información sobre la escritura de políticas de voz, consulte Acerca de las políticas de voz.
- Para obtener detalles sobre la escritura de políticas de otros servicios, consulte Referencia de políticas.
Si es un usuario normal (no un administrador) que necesita utilizar los recursos de OCI que posee la compañía, póngase en contacto con el administrador para que configure su identificador de usuario en su lugar. El administrador puede confirmar qué compartimento o compartimentos debería utilizar.
Identificadores de recursos
El servicio Speech admite trabajos y tareas como recursos de OCI. La mayoría de los tipos de recursos tienen un identificador único asignado por Oracle denominado ID de Oracle Cloud (OCID). Para obtener información sobre el formato del OCID y otras formas de identificar los recursos, consulte Identificadores de recursos.
Regiones y dominios de disponibilidad
El habla está disponible en todas las regiones comerciales de OCI. Consulte About Regions and Availability Domains para obtener la lista de regiones disponibles para OCI, junto con las ubicaciones, los identificadores de región, las claves de región y los dominios de disponibilidad asociados.
El texto a voz solo está disponible en la región comercial Oeste de EE. UU. (Phoenix).
Maneras de acceder
Puede acceder a Speech mediante la consola (una interfaz basada en explorador), la interfaz de línea de comandos (CLI) o la API de REST. En esta guía se incluyen instrucciones para la consola, la CLI y la API.
Para acceder a la consola, debe utilizar un explorador soportado. Para ir a la página de conexión de la Consola, abra el menú de navegación situado en la parte superior de esta página y haga clic en Consola de Infrastructure. Se le solicitará que introduzca el inquilino en la nube, el nombre de usuario y la contraseña.
Para obtener una lista de los SDK disponibles, consulte Los SDK y la CLI. Para obtener información general sobre el uso de la API, consulte API de REST.
Límites de servicio
En cada región activada para su arrendamiento, se aplican estos límites:
Límites de archivo
-
El tamaño máximo de archivo es 2 GB.
-
La duración del archivo es de un máximo de 4 horas.
Límites de Trabajos
Conversión de texto en voz
El texto a voz admite un máximo de 10000 caracteres por solicitud.
Transcribir en tiempo real
La transcripción activa soporta un máximo de 10 sesiones simultáneas por arrendamiento. Se puede aumentar el límite abriendo una solicitud de servicio con los Servicios de Soporte Oracle. Para obtener más información, consulte Solicitud de aumento del límite de servicio.
Comparación de modelos Whisper y Oracle ASR
Compare el modelo Whisper y el modelo de Oracle ASR para crear trabajos de transcripción.
Además del modelo de voz nativo de Oracle ASR, Speech soporta el modelo Whisper de OpenAI. Whisper se entrena en un gran corpus de datos multilingües recopilados de la web, y admite la transcripción de voz a texto basada en archivos para más de 50 idiomas. Este modelo utiliza los mismos puntos finales de servicio e interfaces de API y SDK que el modelo de Oracle ASR para proporcionarle flexibilidad y compatibilidad. Además, el modelo Whisper utiliza la diarización para etiquetar los altavoces individuales en la grabación.
Utilice la siguiente comparación de los modelos Whisper y Oracle ASR para seleccionar el modelo correcto al crear un trabajo de transcripción.
| Función | Modelo de ASR de Oracle | Modelo de susurro en OCI Speech |
|---|---|---|
| Transcripciones en tiempo real | Soportado | Soportado |
| Tamaño de archivo grande | Hasta 2 GB | Hasta 2 GB |
| Registro de hora de nivel de palabra | Soportado | Soportado |
| Formato de Archivo | AAC, AC3, AMR, AU, FLAC, M4A, MKV, MP3, MP4, OGA, OGG, OPUS, WAV, WEBM | AAC, AC3, AMR, AU, FLAC, M4A, MKV, MP3, MP4, OGA, OGG, OPUS, WAV, WEBM |
| Soporte multilingüe | Inglés, español, francés, alemán, italiano, portugués e hindi | Igual que el modelo ASR de Oracle más otros 50 idiomas* |
| Diarización | Soportado | Soportado |