Acerca de los pipelines de datos en la base de datos de IA autónoma
Los pipelines de datos de Autonomous AI Database son pipelines de carga o pipelines de exportación.
Los pipelines de carga proporcionan una carga de datos incremental continua desde orígenes externos (a medida que los datos llegan al almacén de objetos, se cargan en una tabla de base de datos). Los pipelines de exportación proporcionan una exportación incremental continua de datos al almacén de objetos (a medida que aparecen nuevos datos en una tabla de base de datos, se exportan al almacén de objetos). Los pipelines utilizan el programador de base de datos para cargar o exportar continuamente datos incrementales.
Los pipelines de datos de Autonomous AI Database proporcionan lo siguiente:
-
Operaciones unificadas: los pipelines permiten cargar o exportar datos de forma rápida y sencilla y repetir estas operaciones a intervalos regulares para obtener nuevos datos. El paquete
DBMS_CLOUD_PIPELINEproporciona un juego unificado de procedimientos PL/SQL para la configuración del pipeline y para crear e iniciar un trabajo programado para las operaciones de carga o exportación. -
Procesamiento de datos programado: los pipelines supervisan su origen de datos y cargan o exportan periódicamente los datos a medida que llegan nuevos datos.
-
Alto rendimiento: los pipelines escalan las operaciones de transferencia de datos con los recursos disponibles en su base de datos de IA autónoma. Por defecto, los pipelines utilizan el paralelismo para todas las operaciones de carga o exportación, y se escalan según los recursos de CPU disponibles en su base de datos de IA autónoma o según un atributo de prioridad configurable.
-
Atomicidad y recuperación: los pipelines garantizan la atomicidad para que los archivos del almacén de objetos se carguen exactamente una vez para un pipeline de carga.
-
Supervisión y Solución de Problemas: los pipelines proporcionan tablas de estado y log detalladas que le permiten supervisar y depurar operaciones de pipeline.
-
Compatible con multinube: los pipelines en la base de datos de IA autónoma admiten un cambio sencillo entre proveedores de nube sin cambios en la aplicación. Los pipelines admiten todos los formatos URI de almacenamiento de credenciales y objetos que soporta Autonomous AI Database (Oracle Cloud Infrastructure Object Storage, Amazon S3, Azure Blob Storage o Azure Data Lake Storage, Google Cloud Storage y almacenes de objetos compatibles con Amazon S3).
Acerca del ciclo de vida del pipeline de datos en la base de datos de IA autónoma
El paquete DBMS_CLOUD_PIPELINE proporciona procedimientos para crear, configurar, probar e iniciar un pipeline. El ciclo de vida y los procedimientos del pipeline son los mismos para los pipelines de carga y exportación.
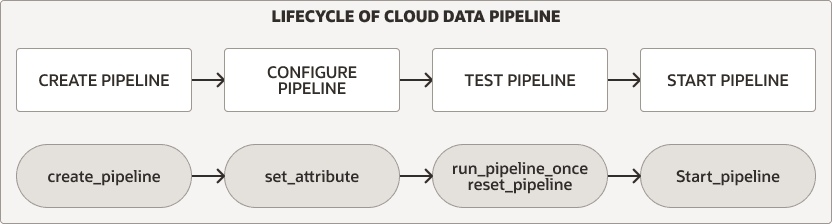
Descripción de la ilustración pipeline_lifecycle.png
Para cualquiera de los tipos de pipeline, realice los siguientes pasos para crear y utilizar un pipeline:
-
Cree y configure el pipeline. Consulte Creación y configuración de pipelines para obtener más información.
-
Pruebe un nuevo pipeline. Consulte Prueba de pipelines para obtener más información.
-
Iniciar un pipeline. Consulte Inicio de un pipeline para obtener más información.
Además, puede supervisar, parar o borrar pipelines:
-
Mientras se ejecuta un pipeline, ya sea durante la prueba o durante el uso regular después de iniciar el pipeline, puede supervisar el pipeline. Consulte Supervisión y solución de problemas de pipelines para obtener más información.
-
Puede parar un pipeline y, posteriormente, volver a iniciarlo o borrar un pipeline cuando haya terminado de utilizarlo. Consulte Parada de un pipeline y Borrado de un pipeline para obtener más información.
Acerca de los pipelines de carga en la base de datos de IA autónoma
Utilice un pipeline de carga para la carga incremental continua de datos desde archivos externos en el almacén de objetos hasta una tabla de base de datos. Un pipeline de carga identifica periódicamente nuevos archivos en el almacén de objetos y carga los nuevos datos en la tabla de la base de datos.
Un pipeline de carga funciona de la siguiente forma (algunas de estas funciones se pueden configurar mediante atributos de pipeline):
-
Los archivos del almacén de objetos se cargan en paralelo en una tabla de base de datos.
-
Un pipeline de carga utiliza el nombre del archivo del almacén de objetos para identificar y cargar archivos más recientes de forma única.
-
Una vez que se haya cargado un archivo en el almacén de objetos en la tabla de la base de datos, si el contenido del archivo cambia en el almacén de objetos, no se volverá a cargar.
-
Si se suprime el archivo del almacén de objetos, no afecta a los datos de la tabla de la base de datos.
-
-
Si se encuentran fallos, un pipeline de carga vuelve a intentar la operación automáticamente. Los reintentos se intentan en cada ejecución posterior del trabajo programado del pipeline.
-
En los casos en que los datos de un archivo no cumplen con la tabla de base de datos, se marcan como
FAILEDy se pueden revisar para depurar y solucionar el problema.- Si algún archivo no se carga, el pipeline no se para y sigue cargando los demás archivos.
-
Los pipelines de carga admiten varios formatos de archivo de entrada, incluidos: JSON, CSV, XML, Avro, ORC y Parquet.
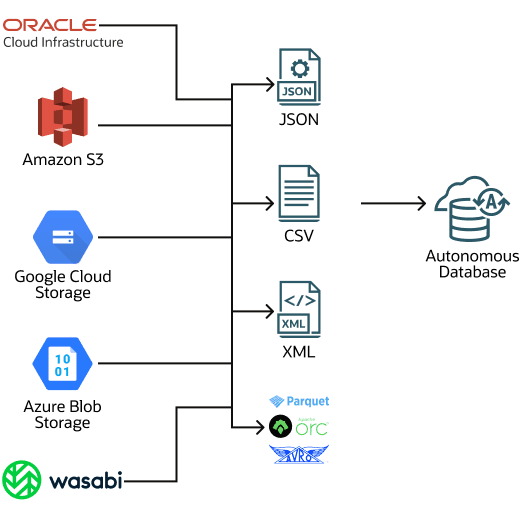
La migración desde bases de datos que no son de Oracle es un posible caso de uso para un pipeline de carga. Cuando necesite migrar los datos de una base de datos que no sea de Oracle a Oracle Autonomous AI Database, puede extraer los datos y cargarlos en Autonomous AI Database (el formato de Oracle Data Pump no se puede utilizar para migraciones desde bases de datos que no sean de Oracle). Al utilizar un formato de archivo genérico, como CSV, para exportar datos de una base de datos que no sea de Oracle, puede guardar los datos en archivos y cargarlos en el almacén de objetos. A continuación, cree un pipeline para cargar los datos en la base de datos de IA autónoma. El uso de un pipeline de carga para cargar un gran conjunto de archivos CSV proporciona importantes ventajas, como la tolerancia a fallos, y las operaciones de reanudación y reintento. Para una migración con un juego de datos de gran tamaño, puede crear varios pipelines, uno por tabla para los archivos de base de datos que no son de Oracle, a fin de cargar datos en Autonomous AI Database.
Acerca de los pipelines de exportación en la base de datos de IA autónoma
Utilice un pipeline de exportación para una exportación incremental continua de datos de la base de datos al almacén de objetos. Un pipeline de exportación identifica periódicamente los datos candidatos y carga los datos en el almacén de objetos.
Hay tres opciones de pipeline de exportación (las opciones de exportación se pueden configurar mediante atributos de pipeline):
-
Exporte los resultados incrementales de una consulta al almacén de objetos mediante una columna de fecha o registro de hora como clave para realizar un seguimiento de los datos más recientes.
-
Exporte los datos incrementales de una tabla al almacén de objetos mediante una columna de fecha o registro de hora como clave para realizar un seguimiento de los datos más recientes.
-
Exportar datos de una tabla al almacén de objetos mediante una consulta para seleccionar datos sin una referencia a una columna de fecha o registro de hora (de modo que el pipeline exporte todos los datos que seleccione la consulta para cada ejecución del programador).
Los pipelines de exportación tienen las siguientes funciones (algunas de estas se pueden configurar mediante atributos de pipeline):
-
Los resultados se exportan en paralelo al almacén de objetos.
-
En caso de fallo, un trabajo de pipeline posterior repite la operación de exportación.
-
Los pipelines de exportación admiten varios formatos de archivo de exportación, incluidos: CSV, JSON, Parquet o XML.
Acerca de los Pipelines Mantenidos de Oracle
La base de datos de IA autónoma proporciona pipelines incorporados para exportar logs al almacén de objetos. Estos pipelines están preconfigurados y los puede iniciar el usuario ADMIN.
Los pipelines mantenidos por Oracle son:
-
ORA$AUDIT_EXPORT: este pipeline exporta los logs de auditoría de la base de datos al almacén de objetos en formato JSON y se ejecuta cada 15 minutos después de iniciar el pipeline (según el valor de atributointerval). -
ORA$APEX_ACTIVITY_EXPORT: este pipeline exporta el log de actividad del espacio de trabajo de Oracle APEX al almacén de objetos en formato JSON. Este pipeline está preconfigurado con la consulta SQL para recuperar los registros de actividad de APEX y se ejecuta cada 15 minutos después de iniciar el pipeline (según el valor del atributointerval).
Los pipelines mantenidos de Oracle son propiedad del usuario ADMIN y el usuario ADMIN puede modificar los atributos de los pipelines mantenidos de Oracle.
Por defecto, los pipelines mantenidos de Oracle utilizan OCI$RESOURCE_PRINCIPAL como credential_name.
Consulte Uso de pipelines mantenidos de Oracle para obtener más información.