Consultar datos externos con el catálogo de datos de AWS Glue
Autonomous AI Database es compatible con un sistema de sincronización con una instancia de Amazon AWS Glue Data Catalog.
Acerca de las consultas con el catálogo de datos de AWS Glue
Autonomous AI Database te permite sincronizar con los metadatos del catálogo de datos de pegamento de Amazon Web Service (AWS). Autonomous AI Database crea automáticamente una tabla externa de base de datos para cada tabla recogida por AWS Glue sobre los datos almacenados en el servicio de almacenamiento simple de Amazon (S3). Los usuarios pueden consultar los datos almacenados en S3 desde la base de datos de IA autónoma sin tener que derivar manualmente el esquema para los orígenes de datos externos y crear tablas externas.
Amazon AWS Glue Data Catalog es un servicio centralizado de gestión de metadatos que ayuda a los profesionales de datos a descubrir datos y admite la gobernanza de datos en la nube de AWS. Una instancia de base de datos de IA autónoma tiene la capacidad de sincronizar automáticamente los metadatos del catálogo de datos con AWS Glue Data Catalog, lo que permite a los usuarios de la base de datos utilizar inmediatamente la base de datos de IA autónoma para consultar los datos almacenados en la nube de AWS.
La sincronización con AWS Glue Data Catalog tiene las mismas propiedades que la sincronización con OCI Data Catalog. La sincronización es dinámica, lo que mantiene la base de datos actualizada con respecto a los cambios en los datos subyacentes, lo que reduce el costo de administración, ya que mantiene automáticamente cientos a miles de tablas.
Conceptos relacionados con las consultas con el catálogo de datos de AWS Glue
Es necesario comprender los siguientes conceptos para consultar con los catálogos de datos de Amazon Web Service (AWS) Glue.
Catálogo de datos de AWS Glue: Base de datos
Una base de datos de AWS Glue representa una recopilación de definiciones de tablas relacionales, organizadas en un grupo lógico. Cada instancia del catálogo de datos de AWS Glue gestiona varias bases de datos.
Catálogo de datos de AWS Glue: Tabla
Una tabla AWS Glue representa una tabla relacional sobre los datos almacenados en la nube de AWS. Una tabla de AWS Glue define el esquema de los datos subyacentes y consta de información de columna, información de partición, información de serialización, información de almacenamiento, estadísticas, metadatos definidos por el usuario y otros metadatos. Las tablas del catálogo de datos de AWS Glue se pueden crear manualmente o automáticamente mediante un rastreador de AWS Glue.
Catálogo de datos de pegamento: Crawler
Puede utilizar un rastreador para rellenar el catálogo de datos de AWS Glue con tablas. Este es el método principal utilizado por la mayoría de los usuarios de AWS Glue. Un rastreador puede explorar varios almacenes de datos en una sola ejecución. Al finalizar, Crawler crea o actualiza una o más tablas en su catálogo de datos. Los trabajos de extracción, transformación y carga (ETL) que defina en AWS Glue utilizan estas tablas de catálogo de datos como orígenes y destinos. El trabajo ETL lee y escribe en los almacenes de datos especificados en las tablas de catálogo de datos de origen y destino.
Las tablas de AWS Glue pueden ser creadas manualmente por el usuario o automáticamente utilizando un rastreador predefinido o personalizado. Los rastreadores se conectan a los almacenes de datos subyacentes (por ejemplo, Amazon S3), invocan clasificadores para derivar el esquema de los datos y crean tablas de AWS Glue para almacenar los metadatos inferidos. AWS Glue proporciona clasificadores para tipos de archivo comunes, como CSV, JSON, Parquet y AVRO.
Asignación entre la base de datos de IA autónoma y AWS Glue
Durante el proceso de sincronización, las tablas externas se crean en la base de datos de IA autónoma derivada de las bases de datos y tablas de AWS Glue Data Catalog en Amazon S3.
AWS Glue organiza los metadatos recopilados en bases de datos y tablas. Una base de datos de AWS Glue es una recopilación de definiciones de tablas relacionales. Tablas de AWS Glue que describen el esquema y las propiedades comunes de los archivos asociados a la tabla.
AWS Glue sigue el modelo relacional para representar atributos. Para asignar esquemas jerárquicos a esquemas relacionales, AWS Glue infiere el esquema de los datos semiestructurados y simplifica los datos a un esquema relacional mediante un proceso ETL.
La siguiente tabla representa la asignación entre los conceptos de OCI Data Catalog y los conceptos de AWS Glue Data Catalog.
| Catálogo de datos de OCI | Catálogo de datos de AWS Glue | Oracle AI Database |
|---|---|---|
| Activo de datos | Base de datos | Esquema |
| Carpeta | (Cubo) | Esquema |
| Entidad lógica | Tabla | Tabla |
Flujo de trabajo de usuario para consultas con el catálogo de datos de AWS Glue
El flujo de trabajo de usuario básico para consultar datos de AWS S3 con AWS Glue Data Catalog implica conectarse a AWS Glue Data Catalog, sincronizar con Autonomous AI Database para crear automáticamente tablas externas y, a continuación, consultar los datos de S3.
El administrador de Database Data Catalog crea una conexión entre la instancia de Autonomous AI Database y una instancia de AWS Glue Data Catalog y, a continuación, configura y ejecuta una sincronización (sincronización) entre el catálogo de datos de AWS Glue y la base de datos de IA autónoma. Autonomous AI Database crea automáticamente una tabla externa para las tablas recogidas por AWS Glue sobre los datos almacenados en S3.
El administrador de consultas de Database Data Catalog o el administrador de bases de datos otorgan acceso de lectura a las tablas externas generadas para que los analistas de datos y otros usuarios de la base de datos puedan examinar y consultar la base de datos de IA autónoma sin tener que derivar manualmente el esquema para los orígenes de datos externos y crear tablas externas.
Usuarios
En la siguiente tabla se describen los diferentes tipos de usuarios que realizan las acciones de flujo de trabajo del usuario.
| Usuario | Descripción |
|---|---|
| Administrador de catálogo de datos de base de datos | Usuario de base de datos con rol DCAT_SYNC. |
| Administrador de consultas de Data Catalog de base de datos | Usuario de base de datos capaz de otorgar acceso en tablas externas creadas automáticamente a otros usuarios. |
| Analista de datos | Usuario de base de datos en base de datos de IA autónoma que consulta datos en AWS S3, ya sea consultando tablas externas creadas automáticamente o interactuando directamente con el catálogo de datos de AWS Glue. |
| Usuario de catálogo de datos de AWS Glue | Usuario de AWS con acceso a un catálogo de datos de AWS Glue. |
| Usuario de almacenamiento de objetos de AWS S3 | Usuario de AWS con acceso a los datos almacenados en AWS S3 |
Flujo de Trabajo de Usuario
La siguiente tabla describe cada acción incluida en el flujo de trabajo y el tipo de usuario que puede realizar la acción.
Nota
Nota: El paquete DBMS_DCAT está disponible para realizar las tareas necesarias para consultar el almacenamiento de objetos de AWS S3 mediante AWS Glue Data Catalog. Consulte Paquete DBMS_DCAT.
| Acción | Quién es el usuario | Descripción |
|---|---|---|
| Crear políticas | Administrador de catálogo de datos de base de datos | La credencial de usuario de la base de datos de IA autónoma debe tener los permisos adecuados para acceder al catálogo de datos de AWS Glue y para leer desde el almacenamiento de objetos S3. Más información: Credenciales necesarias y políticas de IAM. |
| Crear credenciales | Administrador de catálogo de datos de base de datos | Asegúrese de que las credenciales de la base de datos estén en su lugar para acceder al catálogo de datos de AWS Glue y consultar el almacenamiento de objetos de S3. El usuario llama a `DBMS_CLOUD.CREATE_CREDENTIAL` para crear credenciales de usuario. Nota: Solo se admiten las credenciales de Amazon Web Services (AWS). No se admiten las credenciales de AWS Amazon Resource Names (ARN). Más información: [Procedimiento BDMS_CLOUD CREATE_CREDENTIAL](dbms-cloud-subprograms.html#GUID-742FC365-AA09-48A8-922C-1987795CF36A) |
| Conectar | Administrador de catálogo de datos de base de datos | Establezca una conexión entre una instancia de base de datos de IA autónoma y una instancia de AWS Glue Data Catalog. La conexión utiliza los privilegios del usuario de AWS Glue Data Catalog. Se admiten conexiones desde una instancia de base de datos de IA autónoma a varias instancias de AWS Glue Data Catalog. Para iniciar una conexión entre una instancia de base de datos de IA autónoma y una instancia de AWS Glue Data Catalog, el usuario:
Una vez realizada la conexión, la base de datos de IA autónoma almacena los metadatos asociados, como el ID de catálogo, la región, el punto final y los objetos de credenciales de AWS Glue. Más información: Procedimiento SET_DATA_CATALOG_CONN, Procedimiento UNSET_DATA_CATALOG_CONN, Procedimiento SET_DATA_CATALOG_CREDENTIAL, Procedimiento SET_OBJECT_STORE_CREDENTIAL. |
| Sincronizar | Administrador de catálogo de datos de base de datos | El usuario puede iniciar manualmente una sincronización con los catálogos de datos de AWS Glue conectados mediante La sincronización realiza lo siguiente:
|
| Sincronización de supervisión | Administrador de catálogo de datos de base de datos | El usuario puede ver el estado de sincronización consultando la vista USER_LOAD_OPERATIONS. Una vez finalizado el proceso de sincronización, el usuario puede ver un log de los resultados de la sincronización, incluidos los detalles sobre las asignaciones a tablas externas.Más información: [Monitoring and Troubleshooting Loads](load-data-cloud-monitor.html#GUID-657A579F-CF44-458B-8C97-3E50D0C98006) |
| Otorgar Privilegios | Administrador de consultas de Database Data Catalog, administrador de base de datos | El administrador de consultas del catálogo de datos de la base de datos o el administrador de la base de datos deben otorgar privilegios de lectura en las tablas externas generadas a los usuarios del analista de datos. Esto permite a los analistas de datos consultar las tablas externas generadas. |
| Consulta | Analista de datos | Los analistas de datos pueden revisar los esquemas y las tablas sincronizados en los esquemas GLUE$* y consultar las tablas externas mediante cualquier herramienta o aplicación que soporte Oracle SQL. A los datos de S3 se accede mediante los privilegios del usuario de almacenamiento de objetos S3 de AWS. Más información: Ejemplo: consulta con el catálogo de datos AWS Glue |
| Terminar conexiones | Administrador de catálogo de datos de base de datos | Para eliminar una asociación de Data Catalog existente, el usuario llama al procedimiento Esta acción solo se realiza cuando ya no tiene previsto utilizar el catálogo de datos de AWS Glue conectado y las tablas externas que se derivan del catálogo. Esta acción suprime los metadatos de AWS Glue Data Catalog y borra las tablas externas sincronizadas de la instancia de la base de datos de IA autónoma. Más información: procedimiento UNSET_DATA_CATALOG_CONN |
Ejemplo: consulta con el catálogo de datos de AWS Glue
En este ejemplo, se le guía por el proceso de ejecutar consultas sobre conjuntos de datos almacenados en Amazon Simple Storage Service (Amazon S3) mediante un catálogo de datos de AWS Glue.
En este ejemplo, se inspeccionan los metadatos de un catálogo de datos de AWS Glue para ver qué objetos de Amazon S3 se han explorado y existen anteriormente en el catálogo de datos. A continuación, la base de datos de IA autónoma se asocia con AWS Glue Data Catalog y Amazon S3. El catálogo de datos se sincroniza con Autonomous AI Database para crear tablas externas a través de los juegos de datos almacenados en Amazon S3. Las tablas externas se utilizan para consultar los conjuntos de datos en Amazon S3.
-
Inspeccionar metadatos en el catálogo de datos de AWS Glue.
-
Inicie la consola AWS Glue.
-
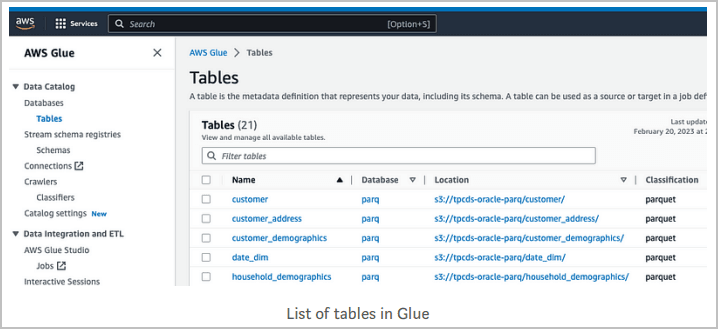
Navegue hasta el catálogo de datos, las bases de datos y las tablas para buscar objetos existentes.
En este ejemplo, existen algunos objetos en Amazon S3 para los que AWS Glue ha explorado y creado tablas anteriormente, como se muestra a continuación:
-
-
Asocie AWS Glue a la base de datos de IA autónoma.
-
Cree credenciales en la base de datos de IA autónoma.
La siguiente llamada al procedimiento incluye el ID de acceso y la clave secreta para proporcionar acceso a la base de datos de IA autónoma a los datos subyacentes en Amazon S3.
<pre class="copy"><code>exec dbms_cloud.create_credential('CRED_AWS','<access id>', '<access key>');</code></pre> -
Asocie las credenciales al catálogo de datos AWS Glue y al almacenamiento de objetos de Amazon S3.
Estas llamadas a procedimientos asocian el catálogo de datos y el almacenamiento de objetos, respectivamente, con las credenciales.
<pre class="copy"><code>exec dbms_dcat.set_data_catalog_credential('CRED_AWS'); exec dbms_dcat.set_object_store_credential('CRED_AWS');</code></pre> -
Configure una región de AWS en la que se ejecute Glue.
<pre class="copy"><code>exec dbms_dcat.set_data_catalog_conn(region => 'us-west-2', catalog_type=>'AWS_GLUE');</code></pre>
-
-
Sincronice los metadatos para crear tablas externas en la base de datos de IA autónoma derivada de las bases de datos y tablas AWS Glue.
-
Ahora que se ha realizado la asociación, utilice la vista
all_glue_databasespara buscar qué bases de datos se encuentran dentro de un catálogo de datos de AWS Glue.<pre class="copy"><code>select * from all_glue_databases order by name;</code></pre> -
Utilice la vista
all_glue_tablespara obtener una lista de tablas disponibles para la sincronización.<pre class="copy"><code>select * from all_glue_tables order by database_name, name;</code></pre>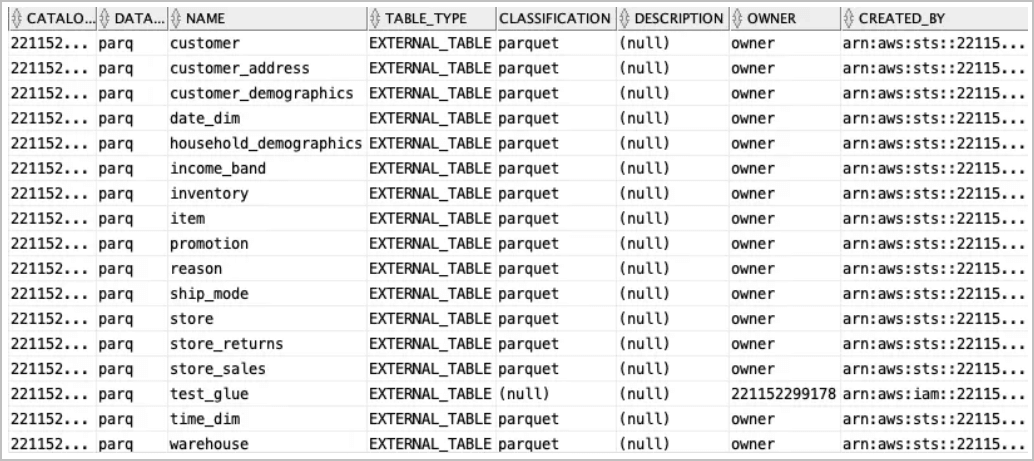
-
Sincronice la base de datos de IA autónoma con dos tablas,
storeyitem, que se encuentran en la base de datosparq.<pre class="copy"><code>begin dbms_dcat.run_sync( synced_objects => ' { "database_list": [ { "database": "parq", "table_list": ["store","item"] } ] }', error_semantics => 'STOP_ON_ERROR'); end; /</code></pre>
-
-
Inspeccione nuevos objetos en la base de datos de IA autónoma y ejecute una consulta sobre S3.
-
Utilice SQL Developer para ver los nuevos objetos creados por la operación de sincronización anterior.
El esquema
GLUE$PARQ_TPCDS_ORACLE_PARQse ha generado y nombrado automáticamente mediante la llamada al procedimientodbms_dcat.run_sync.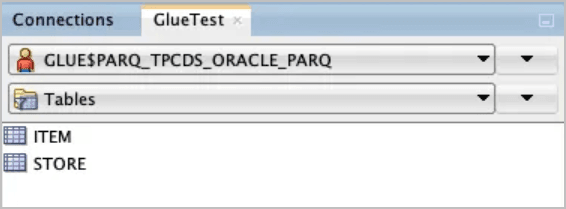
-
Ejecute una consulta SQL en los almacenes de juegos de datos de Amazon S3.
<pre class="copy"><code>SELECT * FROM glue$parq_tpcds_oracle_parq.store;</code></pre>
-