Protección de bases de datos críticas frente a fallos y desastres mediante Autonomous Data Guard
La función Autonomous Data Guard permite mantener las bases de datos de producción críticas disponibles para las aplicaciones esenciales a pesar de los fallos, los desastres, los errores humanos o los daños en los datos. Este tipo de capacidad se suele denominar recuperación ante desastres.
En la base de datos de IA autónoma en una infraestructura de Exadata dedicada, puede configurar y gestionar Autonomous Data Guard en el nivel de la base de datos de contenedores autónoma.
Acerca de Autonomous Data Guard
Autonomous Data Guard crea y mantiene dos copias completamente independientes de su base del datos: una base principal a la que se conectan y utilizan sus aplicaciones, y una base en espera que es una copia sincronizada de la base. A continuación, en caso de que la base del datos principal deje de estar disponible por cualquier motivo, Autonomous Data Guard puede convertir la base del dato en espera en la base del dato principal y, como tal, empieza a prestar servicio a sus aplicaciones.
La base de datos principal y en espera a menudo se denominan bases de Datos peer entre sí. Puede tener hasta dos bases de datos en espera por base de datos de contenedores autónoma.
Nota: Las aplicaciones se deben configurar a fin de utilizar la continuidad de aplicación transparente (TAC) para obtener todas las ventajas que ofrecen las funciones de disponibilidad del base de Datos que ofrece Autonomous Data Guard.
En este diagrama se muestra cómo se mantiene sincronizada cada una de las bases de datos en espera con la principal.
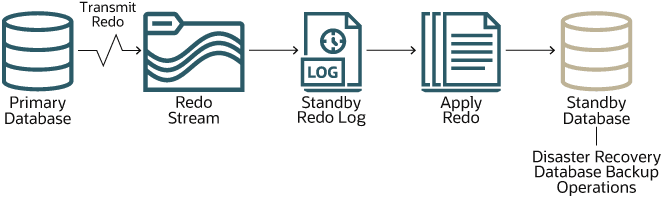
Descripción de la ilustración autonomous-data-guard.png
Los cambios realizados en la base de datos principal se registran en el redo log de la base de datos principal. Autonomous Data Guard transmite estos registros de redo como un flujo a través de la red al redo log de la base de datos en espera. A continuación, la base de datos en espera aplica estos registros a la base de datos en espera. De esta forma, la base de datos en espera se mantiene sincronizada con la base de datos principal.
La sincronización es casi instantánea, pero, como implica el proceso que se acaba de describir, hay dos operaciones que consumen tiempo: transportar los registros de redo a la base de datos en espera y aplicar los registros de redo a la base de datos en espera. La primera de estas se denomina demora de traslado, y la otra se denomina demora de aplicación. Puede ver los valores de demora actuales de una base de datos de IA autónoma desde la página Detalles de la base de datos en Autonomous Data Guard. Puede ver valores de demora actuales en todas las bases de datos autónomas de IA de una base de datos del contenedor en la página Detalles de las bases de datos del contenedor de forma similar.
Nota: Con varias bases de datos en espera, el transporte de redo en cascada no está soportado.
Configuración de Autonomous Data Guard
En Autonomous AI Database on Dedicated Exadata Infrastructure, puede configurar y gestionar Autonomous Data Guard a nivel de base de datos de contenedores autónoma (ACD). Puede activar Autonomous Data Guard para las ACD ya aprovisionadas y agregar hasta dos ACD en espera desde su página Detalles mediante la consola de Oracle Cloud Infrastructure. Consulte Activación de Autonomous Data Guard en una base de datos de contenedores autónoma y Adición de una segunda base de datos de contenedores autónoma en espera para obtener instrucciones.
-
Ahora puede crear y gestionar Autonomous Data Guard entre una base de datos autónoma en Oracle Cloud Infrastructure (OCI) y una base de datos autónoma en Amazon Web Services (AWS).
-
Puede agregar una ACD en espera de la región de AWS a la ACD ya aprovisionada en la región de OCI. También puede agregar una ACD en espera en la región de OCI a una ACD ya aprovisionada en la región de AWS.
Tenga en cuenta lo siguiente antes de configurar Autonomous Data Guard:
-
Las bases de datos de IA autónomas desplegadas en Exadata Cloud@Customer deben tener abierto el puerto 1522 para permitir el tráfico TCP entre la base de datos principal y la base de datos en espera en una configuración de Autonomous Data Guard.
-
Autonomous Data Guard no se puede activar en una base de datos autónoma con una ejecución de mantenimiento activa programada en los próximos tres días. Puede ejecutar primero el mantenimiento activo y, a continuación, activar Autonomous Data Guard o cambiar el programa de ejecución de mantenimiento para que no comience hasta que se agregue la segunda base de datos en espera.
-
La adición de una segunda base de datos en espera requiere un reinicio sucesivo automático para la primera base de datos en espera. La base de datos primaria no se ve afectada por este reinicio sucesivo.
Configurar Autonomous Data Guard con claves gestionadas por el cliente
En Autonomous AI Database on Dedicated Exadata Infrastructure, puede configurar y gestionar Autonomous Data Guard con claves gestionadas por el cliente a nivel de base de datos de contenedores autónoma (ACD). Puede activar Autonomous Data Guard para las ACD ya aprovisionadas y agregar hasta dos ACD en espera desde su página Detalles mediante la consola de Oracle Cloud Infrastructure. Consulte Activación de Autonomous Data Guard en una base de datos de contenedores autónoma y Adición de una segunda base de datos de contenedores autónoma en espera para obtener instrucciones.
Tenga en cuenta lo siguiente antes de configurar Autonomous Data Guard con claves gestionadas por el cliente:
-
Si utiliza Oracle Cloud Infrastructure Key Management System (OCI KMS) y desea activar Autonomous Data Guard entre regiones:
-
Primero debe replicar el almacén de OCI en la región en la que desea agregar la base de datos en espera. Consulte Replicación de almacenes y claves para obtener más información.
-
Solo puede tener las bases de datos primaria y en espera en un máximo de 2 regiones. Es decir, si desea agregar una segunda base de datos en espera y ya ha utilizado varias regiones para la primera base de datos en espera, la segunda base de datos en espera debe estar en la región primaria o en la primera región en espera.
Nota: Los almacenes virtuales creados antes de que se introdujera la función de replicación de almacén entre regiones no se pueden replicar entre regiones. Cree un nuevo almacén y nuevas claves si tiene un almacén que necesita replicar en otra región y la replicación no está soportada para ese almacén. Sin embargo, todos los almacenes privados admiten la replicación entre regiones. Consulte Replicación de almacén virtual entre regiones para obtener más información.
-
-
Si utiliza Oracle Key Vault (OKV) y desea activar Autonomous Data Guard entre regiones, asegúrese de que ha agregado direcciones IP de conexión para el cluster de OKV en el almacén de claves.
-
Si utiliza el sistema de gestión de claves de AWS (KMS de AWS) y desea activar Autonomous Data Guard entre regiones:
- Debe tener una clave de varias regiones de AWS registrada en la región principal. Puede seleccionar el tipo de clave de AWS como multirregión solo cuando la cree y no se podrá cambiar posteriormente.
- Debe definir las políticas necesarias en la región replicada, ya que las políticas no se replican automáticamente.
- La clave de varias regiones de AWS KMS se debe replicar de la región de origen a la región de destino desde la consola de AWS. Consulte Replicación de claves de AWS KMS en la consola de AWS para obtener más información.
- La clave de varias regiones de AWS KMS se debe replicar de la región principal a la región de destino desde la consola de OCI. Consulte Replicación de claves de AWS KMS en la consola de OCI para obtener más información.
Transiciones y operaciones de roles
Una vez creada una base de datos de contenedores autónoma (ACD), puede cambiar el rol de las base de datos peer mediante una operación del switchover o del failover. Si el failover automático está activado, Autonomous Data Guard realiza automáticamente una operación del failover cuando la base de datos principal deja de estar disponible, por cualquier motivo.
Un switchover es una reversión de rol entre la base datos principal y su base de datos en espera. Un switchover garantiza que no se produzcan pérdidas de datos. Durante una operación de switchover, la base de datos principal realiza la transición al rol en espera y la base de datos en espera realiza la transición al rol principal. Para realizar una operación de switchover, consulte Cambio de roles en una configuración de Autonomous Data Guard.
Un failover se produce cuando la base del datos principal no está disponible. El failover genera una transición de la base de datos en espera al rol de principal. Si el failover automático no está activado, puede realizar un failover manual como se describe en Failover a la base de datos en espera en una configuración de Autonomous Data Guard.
La disponibilidad y el estado de la base de datos después de una operación de failover se caracterizan por dos objetivos de recuperación:
-
Objetivo de tiempo de recuperación (RTO). El objetivo de tiempo de recuperación (RTO) es la cantidad máxima de tiempo necesaria para que la base de datos esté disponible para las aplicaciones después de un failover y está relacionado en cierta medida con la demora de aplicación en el momento del fallo. Para Autonomous Data Guard, el RTO son los segundos hasta un máximo de dos minutos.
-
Objetivo de punto de recuperación (RPO). El RPO es la duración máxima de la posible pérdida de datos de la base de datos principal con fallos y está relacionado en cierta medida con la demora de transporte en el momento del fallo. Para Autonomous Data Guard, el RPO es de casi cero.
Después de una conmutación por error, la base de datos principal fallida pasa a ser una base de datos en espera desactivada y deja de estar disponible para cualquier conexión de base de datos. Puede volver a activarlo y convertirlo en una base de datos en espera en buen estado mediante una operación reinstate. Una vez que se ha vuelto a instanciar una base de datos principal con fallos como base de datos en espera, puede realizar un switchover para devolverla a su rol principal original. Para realizar una operación de nueva instanciación, consulte Nueva instanciación de la base de datos en espera desactivada en una configuración de Autonomous Data Guard.
Failover automático o failover de inicio rápido
Con la conmutación por error automática, cuando la base de datos de contenedores automática principal deja de estar disponibles debido a un fallo en la región, un fallo en un dominios de disponibilidad, un fallo en la Infraestructura de Exadata o el Cluster de VM deExadata autónomo (AVMC), o al fallo del propio ACD, se produce un conmutación por error automático a la base de datos de contenedores automática en espera. También se denomina failover de inicio rápido.
No puede activar el failover automático al configurar Autonomous Data Guard en una ACD. El failover automático solo se puede activar o desactivar al actualizar la configuración de Autonomous Data Guard desde la página Detalles de ACD.
Nota: El failover automático no se puede activar para las bases de datos de IA autónomas desplegadas en Exadata Cloud@Customer con configuración de Autonomous Data Guard entre regiones.
No puede agregar una segunda ACD en espera con failover automático activado para la primera ACD en espera. Por lo tanto, desactive el failover automático mediante Actualizar configuración de Autonomous Data Guard antes de crear la segunda base de datos de contenedor autónoma en espera y vuelva a activarla más tarde, si es necesario.
Los modos de protección de máximo rendimiento y máxima disponibilidad soportan el failover automático:
-
En el modo Máxima disponibilidad, el failover automático garantiza que no hay pérdida de datos.
-
En el modo Máximo rendimiento, el failover automático garantiza que la base del dato en espera no vaya más allá del valor especificado para Límite para demora de failover de inicio temprano. Por defecto, el Límite de demora de failover de inicio temprano está definido en 30 segundos y solo se aplica al modo Máximo de rendimiento. En este caso, el failover automático solo es posible cuando la demora de aplicación (pérdida de datos potencial) de la base de datos en espera no supera el límite de demora configurado. Puede modificar el límite de demora de failover de inicio rápido a cualquier valor entre 5 y 3600.
Consulte Actualización de la configuración de Autonomous Data Guard para obtener más información.
Además de los fallos de hardware, las interrupciones del dominio de disponibilidad y las interrupciones regionales, existen otras condiciones de estado de base de datos que pueden disparar un failover de inicio rápido, como se muestra a continuación:
| Estado de la base de datos | Descripción |
|---|---|
| Archivo de control corrupto | Se ha dañado el archivo de control de forma permanente debido a un fallo del disco. |
| Diccionario corrupto | Daños en el diccionario de una base de datos esencial. Actualmente, este estado solo se puede detectar cuando la base de datos está abierta. |
| Errores de escritura de archivo de datos | Se detectan errores de escritura en cualquier archivo de datos, incluidos los archivos temporales, los archivos de datos del sistema y los archivos de deshacer. |
Como resultado del failover automático, el rol de la base de datos principal con fallos pasa a ser Base de datos en espera desactivada y, después de un breve período, la base de datos en espera asume el rol de la base de datos principal. Una vez que ha finalizado el failover automático, aparece un mensaje en la página de detalles de la base de datos en espera desactivada que le indica que se ha producido un failover.
Después de que el servicio haya resuelto las incidencias anteriores de la base de datos de contenedores autónoma principal, puede realizar un switchover manual para devolver ambas bases de datos a sus roles iniciales. Después de aprovisionar la base de datos en espera, puede realizar varias tareas de gestión relacionadas con la base de datos en espera, como:
-
Realizar un switchover manual de una base de datos principal a una base de datos en espera.
-
Realizar un failover manual de una base de datos principal a una base de datos en espera.
-
Volver a instanciar una base de datos principal a un rol en espera después de un failover.
-
Terminar una base de datos en espera.
En una configuración de Autonomous Data Guard con varias bases de datos en espera y failover automático:
-
Los failovers manuales requieren que vuelva a instanciar manualmente la base de datos primaria original, que se convierte en la nueva base de datos en espera.
-
Cuando se produce un failover automático, la base de datos de IA autónoma en una infraestructura de Exadata dedicada intenta volver a instanciar la antigua base de datos principal como base de datos en espera. Sin embargo, si ese intento falla, se debe rehabilitar manualmente.
Base de Datos de Instantánea en Espera
Una base de datos de instantánea en espera es una base de datos en espera totalmente actualizable creada mediante la conversión de una base de datos de contenedores autónoma (ACD) en espera en una ACD de instantánea en espera. Consulte Conversión de la base de datos física en espera a la base de datos de instantánea en espera para obtener instrucciones paso a paso.
Una base de datos de instantánea en espera recibe y archiva, pero no aplica, los datos de redo de la base de datos primaria. Sin embargo, aumenta el objetivo de tiempo de recuperación (RTO) porque no se aplican cambios en tiempo real de la base de datos primaria.
La función de instantánea en espera soporta varios casos de uso, pero estos son los casos de uso principales:
-
Conecte las instancias de la aplicación primaria y en espera a las bases de datos primaria y en espera en modo de lectura-escritura para realizar las configuraciones iniciales.
-
Aplique primero un parche a la base de datos de instantánea en espera y pruebe con la instancia de la aplicación en espera para confirmar la estabilidad del parche. Para ello es necesario convertir primero la base de datos física en espera en una base de datos de instantánea en espera, para que el parche se pueda aplicar en la base de datos de instantánea en espera.
Nota: No puede convertir una base de datos de contenedores autónoma física en espera en una base de datos de instantánea en espera con failover automático activado.
Al realizar la conversión a una base de datos de instantánea en espera, puede activar nuevos servicios de base de datos que solo estén activos en modo de instantánea o utilizar el mismo juego de servicios utilizado con la base de datos primaria. Sin embargo, la activación de servicios de base de datos primaria en la base de datos de instantánea en espera puede provocar que las solicitudes de conexión de instantánea en espera se reenvíen a la base de datos primaria o viceversa si utiliza cadenas de conexión de base de datos incorrectas. Por lo tanto, debe tener cuidado de utilizar la cadena de conexión adecuada al conectarse a la base de datos primaria y de instantánea en espera.
Nota: Al crear nuevos servicios con base de datos de instantánea en espera, se actualizan las carteras de todas las bases de datos de IA autónomas de la base de datos de instantánea en espera ACD. Para acceder a la base de datos, vuelva a cargar las carteras desde bases de datos de IA autónomas en espera y utilice cadenas de conexión de instantánea en espera.
Puede volver a convertir la ACD de instantánea en espera en una ACD física en espera desde Oracle Cloud Infrastructure (OCI) manualmente. Consulte Convert Snapshot Standby to Physical Standby para obtener instrucciones detalladas. Si una instantánea en espera no se convierte manualmente a una física en espera, se volverá a convertir automáticamente a una física en espera después de 7 días desde su creación. En cualquier caso, la conversión de la base de datos de instantánea en espera a una base de datos física en espera desechará todas las actualizaciones locales de las bases de datos de instantánea en espera y aplicará los datos de redo recibidos de las bases de datos primarias.
Cuando una ACD en espera está en el modo de instantánea en espera, no puede realizar las siguientes operaciones en la ACD principal:
-
Crear o terminar bases de datos de IA autónomas
-
Escala o reduce verticalmente las bases de datos de IA autónomas
-
Restauración de bases de datos de IA autónomas
Si la situación lo exige, puede realizar un conmutación por error manualmente en una instantánea en espera desde la base de datos principal. En ese caso, el failover convierte la base de datos de instantánea en espera en una base de datos física en espera desechando todas las actualizaciones locales realizadas en la base de datos de instantánea en espera y aplicando los datos de la base de datos primaria. Consulte Failover a la base de datos en espera en una configuración de Autonomous Data Guard para obtener instrucciones detalladas.
No se permite un switchover entre la base de datos primaria y su base de datos de instantánea en espera. Debe convertir manualmente la instantánea en espera en una física en espera antes de intentar realizar una operación de switchover.
Acceso a bases de datos en espera desde aplicaciones cliente
En una configuración de Autonomous Data Guard, las aplicaciones cliente normalmente se conectan a la base de datos principal y realizan operaciones en ella.
Conexión a la base de datos física en espera
además de esta conectividad normal, Autonomous Data Guard le ofrece la opción para conectar aplicaciones cliente que realizan operaciones de sólo lectura en la base datos en espera. Para aprovechar esta opción, las aplicaciones cliente se conectan a la base de datos mediante nombres de servicio de base de datos que incluyen "_RO" (para "solo lectura"), como se describe en Nombres de servicio de base de datos predefinidos para la base de datos de IA autónoma.
Conexión a la Base de Datos Instantánea en Espera
Autonomous Data Guard también permite conectar aplicaciones cliente que realizan operaciones de lectura y escritura a la base de datos de instantánea en espera. Estas operaciones son locales para la base de datos de instantánea en espera y no modifican su base de datos primaria. Para conectarse a una base de datos de instantánea en espera, las aplicaciones cliente pueden utilizar los nombres de servicio de base de datos que incluyen "_SS" (para "instantánea en espera"), como se describe en Nombres de servicio de base de datos predefinidos para bases de datos de IA autónomas.
Nota: Cuando la base de datos en espera está en modo de instantánea en espera, todos los servicios de base de datos que incluyen servicios "_RO" en su nombre están inactivos y no se pueden utilizar para conexiones.
Supervisión de tiempos de demora
Mientras se ejecutan las bases de dato que utilizan Autonomous Data Guard, puede supervisar la demora del transporte y aplicar los tiempos de demora desde la página Detalles de las bases de dato (o de las bases de dato de contenedores) seleccionando Grupos de Autonomous Data Guard. También puede utilizar la consola de OCI o las API de observación para supervisar la demora del transporte y configurar alarmas y notificaciones. Consulte Observabilidad de bases de datos con métricas de base de datos de IA autónoma para obtener más información.
Debe esperar que aparezcan fluctuaciones menores a lo largo del tiempo a medida que la carga de trabajo de la base de datos cambia y fluye. Sin embargo, si observa una tendencia ascendente continua en el tiempo de demora, puede realizar estas acciones para resolver la situación:
-
Tendencia ascendente en la demora de aplicación. Una tendencia ascendente continua en la demora de aplicación indica que la base de datos en espera no tiene capacidad suficiente para asumir los registros de redo procedentes de la base de datos principal. Para resolver esta situación, amplíe las OCPU de la base de datos, como se describe en Adición de recursos de almacenamiento o CPU a una base de datos de IA autónoma dedicada.
-
Tendencia ascendente en la demora de transporte. Una tendencia ascendente continua en la demora de transporte indica una incidencia de rendimiento de red. El personal de operaciones de Oracle Cloud supervisa de manera constante el rendimiento de la red, por lo que la situación debería resolverse sin que realice ninguna acción. Sin embargo, si lo desea, puede informar de la situación al personal de operaciones mediante la emisión de una solicitud de servicio, como se describe en Creación de una solicitud de servicio en My Oracle Support.
Opciones de configuración de Autonomous Data Guard
When you configure Autonomous Data Guard , you specify which Exadata Infrastructure and Autonomous Exadata VM Cluster resources you want the standby database created in, and you specify which data protection mode you want to use.
Tiene las siguientes opciones al especificar qué recursos del cluster de VM de Exadata autónomo y de infraestructura de Exadata se utilizarán para la base en espera:
-
En una región diferente de la infraestructura de Exadata y el clúster de VM de Exadata que se encuentra en la base datos principal:
Esta elección proporciona el nivel más alto de protección contra desastres, incluida una pérdida catastrófica de la conectividad de red externa o de la alimentación a toda una región.
Para aprovechar al máximo esta protección entre regiones, el nivel de aplicación también se debe configurar de modo que soporte la protección entre regiones. Por lo tanto, Oracle recomienda que elija esta opción si el nivel de aplicación ya está configurado de esta forma o si desea volver a configurarlo de modo que soporte la protección entre regiones.
Si decide ubicar la base datos en espera en una región diferente, Oracle recomienda utilizar el modo de protección Máximo rendimiento.
-
Dominio de disponibilidad (AD) diferente de la infraestructura de Exadata y del cluster de VM de Exadata que es el principal:
Esta elección proporciona un alto nivel de protección contra desastres, incluida una pérdida catastrófica de las conexiones de red externa o la alimentación a un dominio del área de disponibilidad dentro de una región.
Esta opción proporciona un buen equilibrio entre la protección de datos y la simplicidad de la configuración en el nivel de aplicación.
Si decide ubicar la base a datos en espera en un dominio que tenga disponibilidad diferente, Oracle recomienda utilizar el modo de protección Máxima disponibilidad.
-
En el mismo dominio de disponibilidad (AD) que la infraestructura Exadata y la cluster de VM Exadata autónomo de las bases de datos principales:
Esta opción proporciona un nivel mínimo de protección contra desastres y Oracle recomienda que no la seleccione.
Si la infraestructura de Exadata y los recursos del clúster de máquina virtual de Exadata autónomo de las bases de datos principales están en una región que solo tiene una región de disponibilidad, Oracle recomienda utilizar la opción de "en una región diferente".
Si decide ubicar la base de datos de reserva en el mismo dominio, Oracle recomienda utilizar el modo de protección Máxima disponibilidad.
-
En un arrendamiento diferente de la infraestructura de Exadata autónomo de las bases de datos principales:
SE APLICA A:
 Solo Oracle Public Cloud
Solo Oracle Public CloudEsta opción permite agregar una base de datos en espera en un arrendamiento diferente de la base de datos primaria, lo que permite el failover o switchover de la base de datos a esa base de datos en espera entre arrendamientos. También puede crear una instantánea en espera en el arrendamiento remoto. Tener una base de datos en espera entre arrendamientos puede ser útil con la migración de la base de datos entre arrendamientos.
Bases de datos en espera entre arrendamientos:
-
Se puede activar con el modelo de recursos informáticos de ECPU u OCPU. La base de datos en espera debe utilizar el mismo modelo informático que la base de datos primaria.
-
Admite failover automático. Sin embargo, no se puede activar el failover automático para las bases de datos de IA autónomas desplegadas en Exadata Cloud@Customer con configuración de Autonomous Data Guard entre regiones.
-
No se puede agregar mediante la Consola de Oracle Cloud Infrastructure. Solo puede agregar una base de datos en espera entre arrendamientos mediante la CLI o la API de REST. Una vez agregada la base de datos en espera, puede ver la base de datos en espera entre arrendamientos, realizar un failover o switchover a la base de datos en espera entre arrendamientos desde la consola de Oracle Cloud Infrastructure.
-
Acerca de los modos de protección
Autonomous Data Guard proporciona estos modos de protección de datos:
-
Máxima Disponibilidad. Este modo de protección proporciona el máximo nivel de protección de datos posible sin poner en riesgo la disponibilidad de la base de datos principal.
La base de datos principal no confirmará las transacciones hasta que reciba la confirmación de que los datos se han recibido en la base de datos de espera (no se han escrito para el disco). Si la bases de datos principal no recibe esta confirmación a un plazo de 30 segundos, funcionará como si estuviera en modo de máximo rendimiento para mantener la disponibilidad de las bases de datos principales hasta que vuelva a recibir las confirmaciones en forma oportuna.
Este modo de protección garantiza que no se pierda ningún dato, excepto en el caso de determinados fallos dobles, como un fallo de una base de datos principal tras un fallo de la base de datos en espera.
-
Máximo Rendimiento. Este es el modo de protección por defecto. Proporciona el nivel de protección de datos más alto posible sin afectar al rendimiento de la base de datos principal.
La base de datos principal confirma las transacciones tan pronto como todos los datos de redo generados por esas transacciones se hayan escrito en su redo log en línea. También envía datos de redo a la base de datos en espera, pero esto se realiza de forma asíncrona con respecto a la confirmación de transacción, por lo que el rendimiento de la base de datos principal no se ve afectado por los retrasos en la escritura de datos de redo en la base de datos en espera.
Este modo de protección ofrece una protección de datos ligeramente inferior al modo de máxima disponibilidad y tiene un impacto mínimo en el rendimiento de la base de datos principal.
Puede cambiar el modo de protección en una configuración de Autonomous Data Guard desde la consola de Oracle Cloud Infrastructure (OCI). Consulte Actualización de la configuración de Autonomous Data Guard para obtener instrucciones paso a paso.
Para obtener más información sobre los modos de protección en Oracle Data Guard (que subyacen a la función Autonomous Data Guard), consulte la sección sobre los modos de protección de Oracle Data Guard en Oracle Data Guard Concepts and Administration.
Mejores prácticas al configurar Autonomous Data Guard
Si bien la base de datos de IA autónoma permite crear hasta dos bases de datos autónomas en espera con Autonomous Data Guard, puede elegir utilizar una o varias bases de datos autónomas en espera, según sus necesidades. Sin embargo, para utilizar la opción de recuperación ante desastres más resistente que ofrece una base de datos de IA autónoma, puede agregar una base de datos de contenedor autónoma en espera y una base de datos de contenedor autónoma en espera remota o entre regiones con máxima disponibilidad como modo de protección de datos.
Vamos a entender las ventajas de este diseño:
-
Local Standby (En espera local):
-
El failover automático a una base de datos en espera local en la misma región proporciona un aislamiento de fallos local significativo y simplicidad de failover de aplicaciones.
-
El valor de negocio de una base de datos en espera local se ve en una operación de failover sin pérdida de datos y en un tiempo de inactividad de la aplicación reducido a segundos.
-
Las aplicaciones realizan una operación de failover automática y transparente a la base de datos en espera local, manteniendo la misma latencia entre los servidores de aplicaciones y la base de datos. Esto es especialmente importante para OLTP y aplicaciones de paquetes porque una mayor latencia puede afectar significativamente al rendimiento y al tiempo de respuesta general de la aplicación.
-
-
En espera remota:
-
Si un desastre regional hace que los sistemas en espera principal y local no sean accesibles, la aplicación y la base de datos pueden realizar un failover a la base de datos en espera remota.
-
Aunque el tiempo de inactividad de la base de datos sigue siendo muy bajo cuando se produce un desastre regional, el tiempo de inactividad de la aplicación puede ser mayor debido a la orquestación adicional necesaria para las operaciones de failover de la base de datos, la aplicación y el DNS en la región secundaria.
-
-
Máxima Disponibilidad:
-
Si el failover automático o el failover de inicio rápido (FSFO) están activados, siempre que la ACD principal deje de estar disponible, Autonomous Data Guard realiza un failover a la base de datos en espera local sin pérdida de datos y sin cambios en la latencia de la base de datos en la aplicación.
-
Si se activa la conmutación por error automática o la conmutación por error de inicio rápido (FSFO), siempre que no se pueda acceder a toda la región principal, el sistema realiza una conmutación por error a la base de datos en espera remota con una posible pérdida de datos.
-
Cómo afecta Autonomous Data Guard a las operaciones de gestión estándar
En algunos casos, las operaciones de gestión estándar que realice en las bases de datos de contenedores autónomas funcionan de manera diferente en las bases de datos de contenedores principal y en espera en una configuración de Autonomous Data Guard en comparación con las bases de datos de contenedores estándar. En la siguiente lista se describen estas diferencias.
-
Cambiar el programa de mantenimiento
La programación del mantenimiento de una base de datos de contenedores principal y su base de datos en espera están enlazadas: el mantenimiento en la base de datos en espera se realiza varios días antes que el mantenimiento en la base de datos principal. El valor por defecto es 7 días; puede elegir entre 1 y 7 días al crear la base de datos de contenedores principal, o posteriormente mediante la edición de los detalles de mantenimiento.
-
Cambiar el tipo de mantenimiento
El tipo de mantenimiento de una base de datos de contenedores principal y su base de datos en espera debe ser el mismo. Puede elegir el tipo de mantenimiento para la base de datos de contenedores principal y la base de datos en espera al crear la base de datos de contenedores principal o posteriormente, mediante la edición de los detalles de mantenimiento.
-
Desactivar copias de seguridad automáticas
No puede desactivar las copias de seguridad automáticas al aprovisionar una base de datos de contenedores autónoma (ACD) con Autonomous Data Guard.
-
Gestionar el mantenimiento programado
Puede gestionar el mantenimiento programado de una base de datos de contenedores principal y su base de datos en espera por separado. Sin embargo, debido a que el mantenimiento de las dos está enlazado, debe realizar el mantenimiento programado en la base de datos en espera antes que en la principal si decide cambiar la hora de mantenimiento programado.
-
Traslado a un compartimento diferente
Puede mover las bases de datos de contenedores principal y en espera a diferentes compartimentos por separado y de forma independiente, al igual que si fueran bases de datos de contenedores estándar. Sin embargo, como ocurre con las bases de datos de contenedores estándar, debe tener el máximo cuidado al mover una base de datos de contenedor para asegurarse de que esta sigue siendo accesible para los grupos adecuados de usuarios en la nube.
-
Reiniciar
Puede reiniciar las bases de datos de contenedores principal y en espera por separado y de forma independiente, al igual que si fueran bases de datos de contenedores estándar.
-
Rotación de la clave de cifrado
Puede rotar las claves de cifrado desde la base de datos de contenedor autónoma o la base de datos primaria.
-
Terminar
Puede terminar las bases de datos de contenedores principal y en espera por separado. Sin embargo, las consecuencias de terminar una base de datos de contenedores principal y terminar una base de datos de contenedores en espera son diferentes:
-
Al terminar una base de datos de contenedor principal se termina tanto la bases de datos de contenedores principal como la de espera. No puede terminar una base que contenga bases de datos de contenedores principales que contengan bases de datos de IA autónomas.
-
Al terminar una 1base de datos del contenedor en espera, se termina la base de datos del contenedor en espera y Se elimina de la configuración de Autonomous Data Guard. Si solo queda una base de datos primaria, se elimina la configuración de Autonomous Data Guard, lo que convierte la base de datos primaria en una base de datos de contenedores autónoma.
-
Guías paso a paso
Para obtener orientación paso a paso sobre la gestión de la configuración de Autonomous Data Guard en una base de datos de contenedores autónoma, consulte:
-
Activar Autonomous Data Guard en una base de Datos de contenedores autónoma
-
Visualización del estado de la configuración de una instancia de Autonomous Data Guard
-
Cambio de roles en una configuración de Autonomous Data Guard
-
Failover a la base de datos en espera en una configuración de Autonomous Data Guard
-
Conversión de la Base de Datos Física en Espera a la Base de Datos de Instantánea
-
Conversión de Instantáneas en Espera a Bases de Datos Físicas en Espera
-
Adición de una segunda base de datos de contenedores autónoma en espera
También puede utilizar la API para ver y gestionar una configuración de Autonomous Data Guard. Para obtener más información, consulte la sección sobre API para gestionar la configuración de Autonomous Data Guard.