Note:
- Este tutorial requiere acceso a Oracle Cloud. Para registrarse en una cuenta gratuita, consulte Introducción a la cuenta gratuita de Oracle Cloud Infrastructure.
- Utiliza valores de ejemplo para credenciales, arrendamiento y compartimentos de Oracle Cloud Infrastructure. Al completar el laboratorio, sustituya estos valores por otros específicos de su entorno en la nube.
Ejecución del modelo LLM de Elyza en la instancia informática A10.2 de OCI con Oracle Resource Manager mediante el despliegue con un clic
Introducción
Oracle Cloud Infrastructure (OCI) Compute permite crear diferentes tipos de unidades para probar los modelos de unidad de procesamiento de gráficos (GPU) para inteligencia artificial (IA) desplegados localmente. En este tutorial, utilizaremos la unidad A10.2 con recursos de subred y VCN preexistentes que puede seleccionar de Oracle Resource Manager.
El código de Terraform también incluye la configuración de la instancia para ejecutar un modelo de lenguaje grande virtual (vLLM) Elyza local para tareas de procesamiento de lenguaje natural.
Objetivos
- Cree una unidad A10.2 en OCI Compute, descargue el modelo Elyza LLM y consulte el modelo vLLM local.
Requisitos
-
Asegúrese de tener una red virtual en la nube (VCN) de OCI y una subred en la que se desplegará la máquina virtual (VM).
-
Comprensión de los componentes de red y sus relaciones. Para obtener más información, consulte Visión general de Networking.
-
Descripción de las redes en la nube. Para obtener más información, consulte el siguiente vídeo: Video for Networking in the Cloud EP.01: Virtual Cloud Networks.
-
Requisitos:
- Tipo de instancia: unidad A10.2 con dos GPU Nvidia.
- Sistema operativo: Oracle Linux.
- Selección de imagen: el script de despliegue selecciona la última imagen de Oracle Linux con soporte de GPU.
- Etiquetas: agrega una etiqueta de formato libre GPU_TAG = "A10-2".
- Tamaño del volumen de inicio: 250GB.
- Inicialización: utiliza cloud-init para descargar y configurar los modelos de vLLM Elyza.
Tarea 1: Descarga del código de Terraform para el despliegue con un solo clic
Descargue el código de Terraform de ORM desde aquí: orm_stack_a10_2_gpu_elyza_models.zip para implantar modelos de Elyza vLLM localmente, lo que le permitirá seleccionar una VCN y una subred existentes para probar el despliegue local de modelos de Elyza vLLM en una unidad de instancia A10.2.
Una vez que haya descargado el código de Terraform de ORM de forma local, siga los pasos que se indican a continuación: Creación de una pila a partir de una carpeta para cargar la pila y ejecutar la aplicación del código de Terraform.
Nota: Asegúrese de haber creado una red virtual en la nube (VCN) de OCI y una subred en la que se desplegará la VM.
Tarea 2: Creación de una VCN en OCI (opcional si aún no se ha creado)
Para crear una VCN en Oracle Cloud Infrastructure, consulte: Vídeo para descubrir cómo crear una red virtual en la nube en OCI.
o bien,
Para crear una VCN, realice los siguientes pasos:
-
Conéctese a la consola de OCI, introduzca Nombre de inquilino en la nube, Nombre de usuario y Contraseña.
-
Haga clic en el menú de hamburguesa (≡) en la esquina superior izquierda.
-
Vaya a Red, Redes virtuales en la nube y seleccione el compartimento adecuado en la sección Ámbito de lista.
-
Seleccione VCN con conexión a Internet, y haga clic en Iniciar asistente de VCN.
-
En la página Crear una VCN con conexión a Internet, introduzca la siguiente información y haga clic en Siguiente.
- NOMBRE de VCN: introduzca
OCI_HOL_VCN. - COMPARTMENT: seleccione el compartimento adecuado.
- Bloqueo de CIDR de VCN: introduzca
10.0.0.0/16. - BLOQUE de CIDR de la SUBRED PÚBLICA: introduzca
10.0.2.0/24. - BLOQUE DE CIDR DE SUBNET PRIVADA: introduzca
10.0.1.0/24. - Resolución de DNS: seleccione Usar nombres de host de DNS en esta VCN.
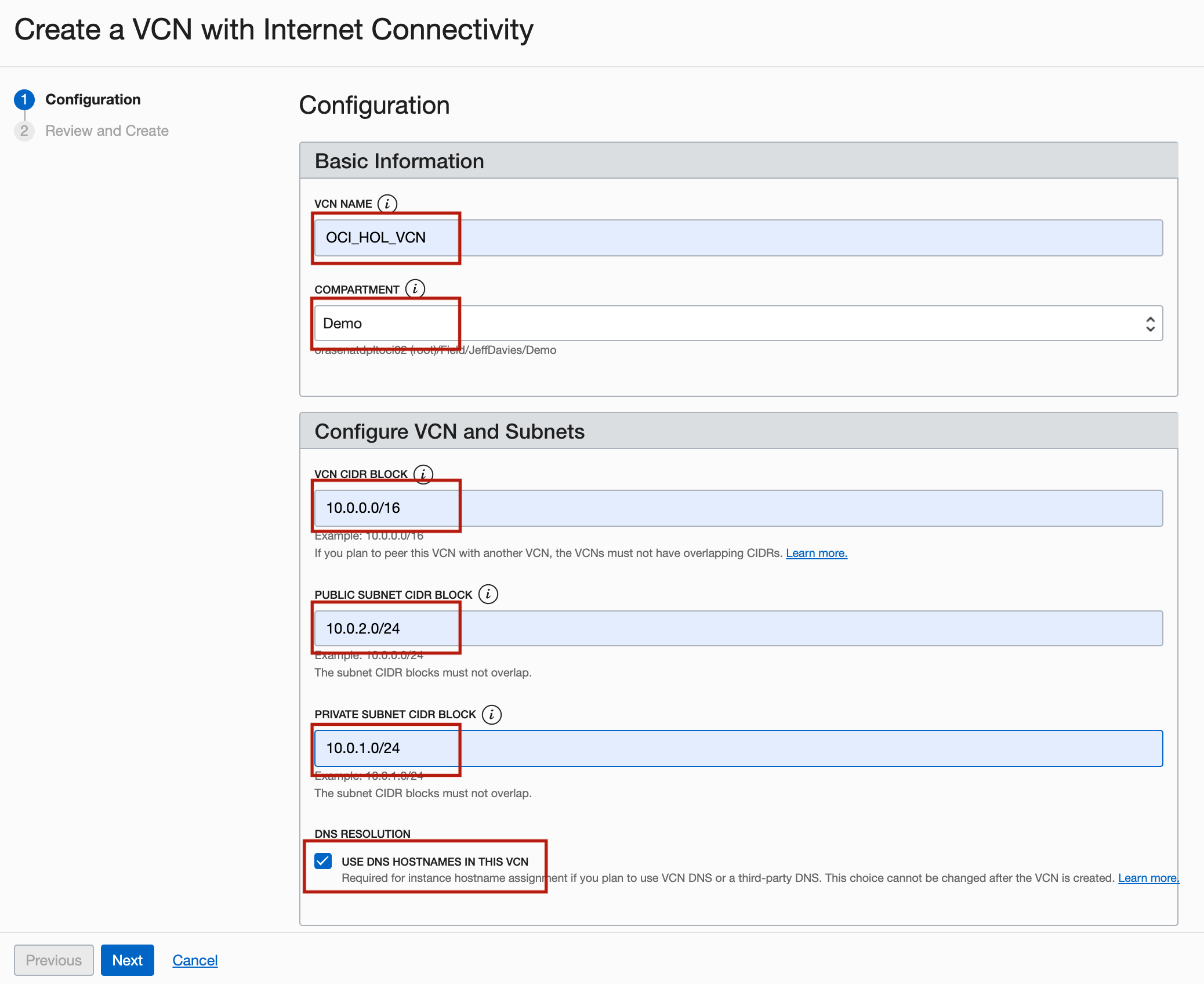
- NOMBRE de VCN: introduzca
-
En la página Revisar, revise su configuración y haga clic en Crear.
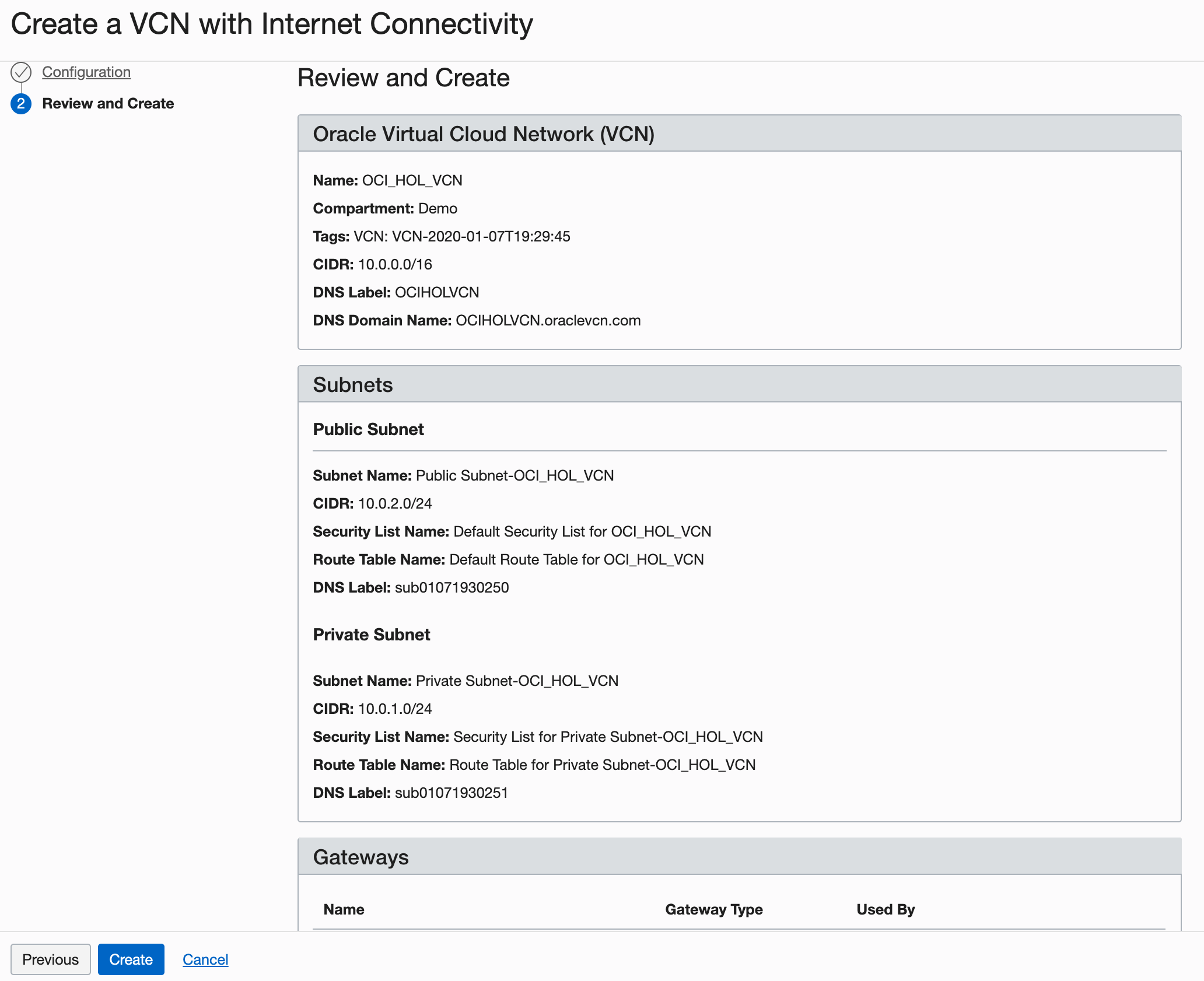
Descripción de la ilustración setupVCN4.png
Tardará un momento en crear la VCN y una pantalla de progreso le mantendrá informado sobre el flujo de trabajo.

-
Una vez creada la VCN, haga clic en View Virtual Cloud Network (Ver red virtual en la nube).
En situaciones reales, creará varias redes virtuales en la nube en función de su necesidad de acceso (qué puertos abrir) y quién puede acceder a ellas.
Tarea 3: Consulte los detalles de configuración de cloud-init
El script cloud-init instala todas las dependencias necesarias, inicia Docker, descarga e inicia los modelos de vLLM Elyza. Puede encontrar el siguiente código en el archivo cloudinit.sh descargado en la tarea 1.
dnf install -y dnf-utils zip unzip
dnf config-manager --add-repo=https://download.docker.com/linux/centos/docker-ce.repo
dnf remove -y runc
dnf install -y docker-ce --nobest
systemctl enable docker.service
dnf install -y nvidia-container-toolkit
systemctl start docker.service
...
Cloud-init descargará todos los archivos necesarios para ejecutar el modelo Elyza y no necesita su token de API predefinido en Hugging Face. Se necesitará el token de API para iniciar el modelo de Elyza mediante Docker en la tarea 6.
Tarea 4: Supervisión del sistema
Realice un seguimiento de la finalización de cloud-init y el uso de recursos de GPU con los siguientes comandos (si es necesario).
-
Supervise la finalización de cloud-init:
tail -f /var/log/cloud-init-output.log. -
Supervise el uso de GPU:
nvidia-smi dmon -s mu -c 100 --id 0,1. -
Desplegar e interactuar con el modelo vLLM Elyza mediante Python: (cambie los parámetros solo si es necesario; el comando ya está incluido en el script
cloud-init):python -O -u -m vllm.entrypoints.api_server \ --host 0.0.0.0 \ --port 8000 \ --model /home/opc/models/${MODEL} \ --tokenizer hf-internal-testing/llama-tokenizer \ --enforce-eager \ --max-num-seqs 1 \ --tensor-parallel-size 2 \ >> /home/opc/${MODEL}.log 2>&1
Tarea 5: Prueba de la integración del modelo
Interactúe con el modelo de las siguientes formas mediante los comandos o los detalles de Jupyter Notebook.
-
Pruebe el modelo desde la interfaz de línea de comandos (CLI) una vez que cloud-init haya finalizado.
curl -X POST "http://0.0.0.0:8000/generate" \ -H "accept: application/json" \ -H "Content-Type: application/json" \ -d '{"prompt": "Write a humorous limerick about the wonders of GPU computing.", "max_tokens": 64, "temperature": 0.7, "top_p": 0.9}' -
Pruebe el modelo desde el bloc de notas de Jupyter (asegúrese de abrir el puerto
8888).import requests import json url = "http://0.0.0.0:8000/generate" headers = { "accept": "application/json", "Content-Type": "application/json", } data = { "prompt": "Write a short conclusion.", "max_tokens": 64, "temperature": 0.7, "top_p": 0.9 } response = requests.post(url, headers=headers, json=data) if response.status_code == 200: result = response.json() # Pretty print the response for better readability formatted_response = json.dumps(result, indent=4) print("Response:", formatted_response) else: print("Request failed with status code:", response.status_code) print("Response:", response.text) -
Integra Gradio con el chatbot para consultar el modelo.
import requests import gradio as gr import os # Function to interact with the model via API def interact_with_model(prompt): url = 'http://0.0.0.0:8000/generate' headers = { "accept": "application/json", "Content-Type": "application/json", } data = { "prompt": prompt, "max_tokens": 64, "temperature": 0.7, "top_p": 0.9 } response = requests.post(url, headers=headers, json=data) if response.status_code == 200: result = response.json() completion_text = result["text"][0].strip() # Extract the generated text return completion_text else: return {"error": f"Request failed with status code {response.status_code}"} # Retrieve the MODEL environment variable model_name = os.getenv("MODEL") # Example Gradio interface iface = gr.Interface( fn=interact_with_model, inputs=gr.Textbox(lines=2, placeholder="Write a prompt..."), outputs=gr.Textbox(type="text", placeholder="Response..."), title=f"{model_name} Interface", # Use model_name to dynamically set the title description=f"Interact with the {model_name} deployed locally via Gradio.", # Use model_name to dynamically set the description live=True ) # Launch the Gradio interface iface.launch(share=True)
Tarea 6: Despliegue del modelo con Docker (si es necesario)
También puede desplegar el modelo con Docker para entornos encapsulados:
-
Modelo de origen externo.
docker run --gpus all \ --env "HUGGING_FACE_HUB_TOKEN=$TOKEN_ACCESS" \ -p 8000:8000 \ --ipc=host \ --restart always \ vllm/vllm-openai:latest \ --tensor-parallel-size 2 \ --model elyza/$MODEL -
Modelo que se ejecuta con docker mediante los archivos locales ya descargados (se inicia más rápido).
docker run --gpus all \ -v /home/opc/models/$MODEL/:/mnt/model/ \ --env "HUGGING_FACE_HUB_TOKEN=$TOKEN_ACCESS" \ -p 8000:8000 \ --env "TRANSFORMERS_OFFLINE=1" \ --env "HF_DATASET_OFFLINE=1" \ --ipc=host vllm/vllm-openai:latest \ --model="/mnt/model/" \ --tensor-parallel-size 2
Puede consultar el modelo de las siguientes formas:
-
Consulte el modelo iniciado con Docker desde la CLI (se necesita más atención):
-
Modelo iniciado con Docker desde origen externo.
(elyza) [opc@a10-2-gpu ~]$ curl -X 'POST' 'http://0.0.0.0:8000/v1/chat/completions' \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -d '{ "model": "elyza/'${MODEL}'", "messages": [{"role": "user", "content": "Write a humorous limerick about the wonders of GPU computing."}], "max_tokens": 64, "temperature": 0.7, "top_p": 0.9 }' -
Modelo iniciado localmente con Docker.
curl -X 'POST' 'http://0.0.0.0:8000/v1/chat/completions' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{ "model": "/mnt/model/", "messages": [{"role": "user", "content": "Write a humorous limerick about the wonders of GPU computing."}], "max_tokens": 64, "temperature": 0.7, "top_p": 0.9 }'
-
-
Consulte el modelo iniciado con Docker desde un bloc de notas de Jupyter.
-
Modelo iniciado desde Docker Hub.
import requests import json import os url = "http://0.0.0.0:8000/v1/chat/completions" headers = { "accept": "application/json", "Content-Type": "application/json", } # Assuming `MODEL` is an environment variable set appropriately model = f"elyza/{os.getenv('MODEL')}" data = { "model": model, "messages": [{"role": "user", "content": "Write a humorous limerick about the wonders of GPU computing."}], "max_tokens": 64, "temperature": 0.7, "top_p": 0.9 } response = requests.post(url, headers=headers, json=data) if response.status_code == 200: result = response.json() # Extract the generated text from the response completion_text = result["choices"][0]["message"]["content"].strip() print("Generated Text:", completion_text) else: print("Request failed with status code:", response.status_code) print("Response:", response.text) -
El contenedor se ha iniciado localmente con Docker.
import requests import json import os url = "http://0.0.0.0:8000/v1/chat/completions" headers = { "accept": "application/json", "Content-Type": "application/json", } # Assuming `MODEL` is an environment variable set appropriately model = f"/mnt/model/" # Adjust this based on your specific model path or name data = { "model": model, "messages": [{"role": "user", "content": "Write a humorous limerick about the wonders of GPU computing."}], "max_tokens": 64, "temperature": 0.7, "top_p": 0.9 } response = requests.post(url, headers=headers, json=data) if response.status_code == 200: result = response.json() # Extract the generated text from the response completion_text = result["choices"][0]["message"]["content"].strip() print("Generated Text:", completion_text) else: print("Request failed with status code:", response.status_code) print("Response:", response.text)
-
-
Consulte el modelo iniciado con Docker mediante Gradio integrado con el bot conversacional.
-
Modelo iniciado con Docker desde origen externo.
import requests import gradio as gr import os # Function to interact with the model via API def interact_with_model(prompt): url = 'http://0.0.0.0:8000/v1/chat/completions' # Update the URL to match the correct endpoint headers = { "accept": "application/json", "Content-Type": "application/json", } # Assuming `MODEL` is an environment variable set appropriately model = f"elyza/{os.getenv('MODEL')}" data = { "model": model, "messages": [{"role": "user", "content": prompt}], # Use the user-provided prompt "max_tokens": 64, "temperature": 0.7, "top_p": 0.9 } response = requests.post(url, headers=headers, json=data) if response.status_code == 200: result = response.json() completion_text = result["choices"][0]["message"]["content"].strip() # Extract the generated text return completion_text else: return {"error": f"Request failed with status code {response.status_code}"} # Retrieve the MODEL environment variable model_name = os.getenv("MODEL") # Example Gradio interface iface = gr.Interface( fn=interact_with_model, inputs=gr.Textbox(lines=2, placeholder="Write a prompt..."), outputs=gr.Textbox(type="text", placeholder="Response..."), title=f"{model_name} Interface", # Use model_name to dynamically set the title description=f"Interact with the {model_name} model deployed locally via Gradio.", # Use model_name to dynamically set the description live=True ) # Launch the Gradio interface iface.launch(share=True) -
El contenedor se ha iniciado localmente con Docker mediante Gradio
import requests import gradio as gr import os # Function to interact with the model via API def interact_with_model(prompt): url = 'http://0.0.0.0:8000/v1/chat/completions' # Update the URL to match the correct endpoint headers = { "accept": "application/json", "Content-Type": "application/json", } # Assuming `MODEL` is an environment variable set appropriately model = "/mnt/model/" # Adjust this based on your specific model path or name data = { "model": model, "messages": [{"role": "user", "content": prompt}], "max_tokens": 64, "temperature": 0.7, "top_p": 0.9 } response = requests.post(url, headers=headers, json=data) if response.status_code == 200: result = response.json() completion_text = result["choices"][0]["message"]["content"].strip() return completion_text else: return {"error": f"Request failed with status code {response.status_code}"} # Example Gradio interface iface = gr.Interface( fn=interact_with_model, inputs=gr.Textbox(lines=2, placeholder="Write a humorous limerick about the wonders of GPU computing."), outputs=gr.Textbox(type="text", placeholder="Response..."), title="Model Interface", # Set your desired title here description="Interact with the model deployed locally via Gradio.", live=True ) # Launch the Gradio interface iface.launch(share=True)
Nota: Comandos de firewall para abrir el puerto
8888para el bloc de notas de Jupyter.sudo firewall-cmd --zone=public --permanent --add-port 8888/tcp sudo firewall-cmd --reload sudo firewall-cmd --list-all -
Agradecimientos
-
Autor: Bogdan Bazarca (ingeniero sénior en la nube)
-
Contribuyentes: equipo de Oracle NACI-AI-CN-DEV
Más recursos de aprendizaje
Explore otros laboratorios en docs.oracle.com/learn o acceda a más contenido de aprendizaje gratuito en el canal YouTube de Oracle Learning. Además, visite education.oracle.com/learning-explorer para convertirse en Oracle Learning Explorer.
Para obtener documentación sobre el producto, visite Oracle Help Center.
Run Elyza LLM Model on OCI Compute A10.2 Instance with Oracle Resource Manager using One Click Deployment
G11823-01
July 2024