Nota:
- Este tutorial requiere acceso a Oracle Cloud. Para registrarse en una cuenta gratuita, consulte Introducción a Oracle Cloud Infrastructure Free Tier.
- Utiliza valores de ejemplo para las credenciales, el arrendamiento y los compartimentos de Oracle Cloud Infrastructure. Al finalizar el laboratorio, sustituya estos valores por otros específicos de su entorno en la nube.
Utilice OCI Data Flow con Apache Spark Streaming para procesar un tema de Kafka en una aplicación escalable y casi en tiempo real
Introducción
Oracle Cloud Infrastructure (OCI) Data Flow es un servicio gestionado para el proyecto de código abierto denominado Apache Spark. Básicamente, con Spark puede utilizarlo para operaciones masivas de procesamiento de archivos, transmisión y base de datos. Puede crear aplicaciones con un procesamiento escalable muy alto. Spark puede ampliar y utilizar máquinas agrupadas para paralizar trabajos con una configuración mínima.
Con Spark como servicio gestionado (Data Flow), puede agregar muchos servicios escalables para multiplicar la potencia del procesamiento en la nube. Data Flow tiene la capacidad de procesar Spark Streaming.
Las aplicaciones de transmisión requieren una ejecución continua durante un largo período de tiempo que, a menudo, se extiende más allá de las 24 horas y puede ser hasta semanas o incluso meses. En caso de fallos inesperados, las aplicaciones de transmisión deben reiniciarse desde el punto de fallo sin producir resultados de cálculo incorrectos. Data Flow se basa en puntos de control de flujo estructurado de Spark para registrar el desplazamiento procesado que se puede almacenar en el cubo de Object Storage.
Nota: Si necesita procesar datos como estrategia por lotes, puede leer este artículo: Procesar archivos grandes en Autonomous Database y Kafka con Oracle Cloud Infrastructure Data Flow

En este tutorial, puede ver las actividades más comunes utilizadas para procesar el flujo de volúmenes de datos, consultar la base de datos y fusionar o unir los datos para formar otra tabla en la memoria o enviar datos a cualquier destino casi en tiempo real. Puede escribir estos datos masivos en su base de datos y en una cola de Kafka con un rendimiento muy económico y muy eficaz.
Objetivos
- Descubra cómo se puede utilizar Data Flow para procesar una gran cantidad de datos en una aplicación escalable y casi en tiempo real.
Requisitos
-
Un inquilino operativo de Oracle Cloud: puede crear una cuenta gratuita de Oracle Cloud con $ 300.00 durante un mes para probar este tutorial. Consulte Creación de una cuenta gratuita de Oracle Cloud
-
CLI de OCI (interfaz de línea de comandos de Oracle Cloud) instalada en la máquina local: este es el enlace para instalar la CLI de OCI.
-
Una aplicación Apache Spark instalada en la máquina local. Consulte Desarrollo local de aplicaciones de Oracle Cloud Infrastructure Data Flow y despliegue en la nube para obtener información sobre cómo realizar el desarrollo local y en Data Flow.
Nota: Esta es la página oficial que se va a instalar: Apache Spark. Existen procedimientos alternativos para instalar Apache Spark para cada tipo de sistema operativo (Linux/Mac OS/Windows).
-
CLI de envío de Spark instalado. Este es el enlace para instalar Spark Submit CLI.
-
Maven instalado en la máquina local.
-
Conocimientos de los conceptos de OCI:
- Compartimentos
- Políticas de IAM
- arrendamiento
- OCID de los recursos
Tarea 1: Creación de la estructura de Object Storage
El almacenamiento de objetos se utilizará como repositorio de archivos por defecto. Puede utilizar otro tipo de repositorios de archivos, pero el almacenamiento de objetos es una forma sencilla y de bajo costo de manipular los archivos con rendimiento. En este tutorial, ambas aplicaciones cargarán un archivo CSV de gran tamaño del almacenamiento de objetos y mostrarán cómo Apache Spark es rápido e inteligente para procesar un gran volumen de datos.
-
Crear un compartimento: los compartimentos son importantes para organizar y aislar los recursos en la nube. Puede aislar sus recursos mediante políticas de IAM.
-
Puede utilizar este enlace para comprender y configurar las políticas de los compartimentos: Gestión de compartimentos
-
Cree un compartimento para alojar todos los recursos de las 2 aplicaciones de este tutorial. Cree un compartimento denominado analytics.
-
Vaya al menú principal de Oracle Cloud y busque: Identidad y seguridad, Compartimentos. En la sección Compartimentos, haga clic en Crear compartimento e introduzca el nombre.

Nota: Debe otorgar acceso a un grupo de usuarios e incluir el usuario.
-
Haga clic en Crear compartimento para incluir el compartimento.
-
-
Cree su cubo en Object Storage: los cubos son contenedores lógicos para almacenar objetos, por lo que todos los archivos utilizados para esta demostración se almacenarán en este cubo.
-
Vaya al menú principal de Oracle Cloud y busque Almacenamiento y Cubos. En la sección Cubos, seleccione el compartimento (análisis), creado anteriormente.

-
Haga clic en Crear cubo. Cree 4 cubos: aplicaciones, datos, logs de flujo de datos, cartera

-
Introduzca la información de Nombre de cubo con estos 4 cubos y mantenga los demás parámetros con la selección por defecto.
-
Para cada cubo, haga clic en Crear. Puede ver los cubos creados.

-
Nota: Revise las políticas de IAM para el bloque. Debe configurar las políticas si desea utilizar estos cubos en sus aplicaciones de demostración. Puede revisar los conceptos y configurar aquí Visión general de Object Storage y Políticas de IAM.
Tarea 2: Creación de Autonomous Database
Oracle Cloud Autonomous Database es un servicio gestionado para Oracle Database. Para este tutorial, las aplicaciones se conectarán a la base de datos a través de una cartera por motivos de seguridad.
-
Instancie la instancia de Autonomous Database como se describe aquí: aprovisionamiento de Autonomous Database.
-
En el menú principal de Oracle Cloud, seleccione la opción Almacén de datos, seleccione Oracle Database y Autonomous Data Warehouse; seleccione su compartimento análisis y siga el tutorial para crear la instancia de base de datos.
-
Asigne a la instancia el nombre Logs procesados, seleccione logs como nombre de base de datos y no necesita cambiar ningún código en las aplicaciones.
-
Introduzca la contraseña de administrador y descargue el archivo zip de cartera.

-
Después de crear la base de datos, puede configurar la contraseña de usuario ADMIN y descargar el archivo zip de cartera.



-
Guarde el archivo zip de cartera (
Wallet_logs.zip) y anote la contraseña ADMIN, deberá configurar el código de aplicación. -
Vaya a Almacenamiento, Cubos. Cambie al compartimento analytics y verá el cubo Wallet. Haga clic en él.
-
Para cargar el archivo zip de cartera, haga clic en Cargar y adjunte el archivo Wallet_logs.zip.

Nota: Revise las políticas de IAM para acceder a Autonomous Database aquí: Política de IAM para Autonomous Database
Tarea 3: Carga de los archivos de muestra CSV
Para demostrar la potencia de Apache Spark, las aplicaciones leerán un archivo CSV con 1.000.000 líneas. Estos datos se insertarán en la base de datos de Autonomous Data Warehouse con una sola línea de comandos y se publicarán en un flujo de Kafka (Oracle Cloud Streaming). Todos estos recursos son ampliables y perfectos para un gran volumen de datos.
-
Descargue estos 2 enlaces y cárguelos en el cubo de datos:
-
Nota:
- organizations.csv solo tiene 100 líneas, solo para probar las aplicaciones en su máquina local.
- organizations1M.csv contiene 1 000 000 líneas y se utilizará para ejecutarse en la instancia de Data Flow.
-
En el menú principal de Oracle Cloud, vaya a Almacenamiento y Cubos. Haga clic en el cubo de datos y cargue los 2 archivos del paso anterior.


-
Cargar una tabla auxiliar en la base de datos de ADW
-
Descargue este archivo para cargarlo en la base de datos de ADW: GDP PER CAPTA COUNTRY.csv
-
En el menú principal de Oracle Cloud, seleccione Oracle Database y Autonomous Data Warehouse.
-
Haga clic en la instancia Logs procesados para ver los detalles.
-
Haga clic en Acciones de base de datos para ir a las utilidades de la base de datos.

-
Introduzca las credenciales para el usuario ADMIN.

-
Haga clic en la opción SQL para ir a Utilidades de consulta.

-
Haga clic en Carga de datos.

-
Borre el archivo GDP PER CAPTA COUNTRY.csv en el panel de la consola y continúe con la importación de los datos en una tabla.

-
Puede ver la nueva tabla denominada GDPPERCAPTA importada correctamente.

Tarea 4: Creación de un almacén secreto para la contraseña ADW ADMIN
Por motivos de seguridad, la contraseña ADW ADMIN se guardará en un almacén. Oracle Cloud Vault puede alojar esta contraseña con seguridad y se puede acceder a ella en la aplicación con la autenticación de OCI.
-
Cree el secreto en un almacén como se describe en la siguiente documentación: Agregar la contraseña de administrador de la base de datos al almacén
-
Cree una variable denominada PASSWORD_SECRET_OCID en las aplicaciones e introduzca el OCID.



Nota: Revise la política de IAM para OCI Vault aquí: Política de IAM de OCI Vault.
Tarea 5: Creación de un flujo de Kafka (Oracle Cloud Streaming)
Oracle Cloud Streaming es un servicio de transmisión gestionada similar a Kafka. Puede desarrollar aplicaciones con las API de Kafka y los SDK comunes. En este tutorial, creará una instancia de Streaming y la configurará para que se ejecute en ambas aplicaciones con el fin de publicar y consumir un gran volumen de datos.
-
En el menú principal de Oracle Cloud, vaya a Análisis e IA, Flujos.
-
Cambie el compartimento a analytics. Se crearán todos los recursos de esta demostración en este compartimento. IAM es más seguro y fácil de controlar.
-
Haga clic en Crear flujo.

-
Introduzca el nombre como kafka_like (por ejemplo) y puede mantener todos los demás parámetros con los valores predeterminados.

-
Haga clic en Crear para inicializar la instancia.
-
Espere el estado Activo. Ahora puede utilizar la instancia.
Nota: En el proceso de creación de flujo, puede seleccionar la opción Crear automáticamente un pool de flujos por defecto para crear automáticamente el pool por defecto.
-
Haga clic en el enlace DefaultPool.

-
Visualice la configuración de la conexión.


-
Anote esta información, ya que la necesitará en el siguiente paso.
Nota: Revise las políticas de IAM para OCI Streaming aquí: Política de IAM para OCI Streaming.
Tarea 6: Generación de un TOKEN AUTH para acceder a Kafka
Puede acceder a OCI Streaming (API de Kafka) y a otros recursos en Oracle Cloud con un token de autenticación asociado a su usuario en OCI IAM. En la configuración de conexión de Kafka, las cadenas de conexión SASL tienen un parámetro denominado password y un valor AUTH_TOKEN, como se describe en la tarea anterior. Para permitir el acceso a OCI Streaming, debe ir a su usuario en la consola de OCI y crear un TOKEN AUTH.
-
En el menú principal de Oracle Cloud, vaya a Identidad y seguridad, Usuarios.
Nota: Recuerde que el usuario que necesita para crear AUTH TOKEN es el usuario configurado con la CLI de OCI y toda la configuración de Políticas de IAM para los recursos creados hasta ahora. Los recursos son:
- Oracle Cloud Autonomous Data Warehouse
- Flujo de Oracle Cloud
- Almacenamiento de objetos de Oracle
- Flujo de datos de Oracle
-
Haga clic en su nombre de usuario para ver los detalles.

-
Haga clic en la opción Tokens de autenticación en el lado izquierdo de la consola y haga clic en Generar token.
Nota: El token solo se generará en este paso y no estará visible una vez completado el paso. Por lo tanto, copie el valor y guárdelo. Si pierde el valor del token, debe volver a generar el token de autenticación.


Tarea 7: Configuración de la aplicación Demo
Este tutorial tiene una aplicación de demostración para la que configuraremos la información necesaria.
- DataflowSparkStreamDemo: esta aplicación se conectará al flujo de Kafka y consumirá todos los datos y se fusionará con una tabla de ADW denominada GDPPERCAPTA. Los datos del flujo se fusionarán con GDPPERCAPTA y se guardarán como un archivo CSV, pero se pueden exponer a otro tema de Kafka.
-
Descargue la aplicación mediante el siguiente enlace:
-
Busque los siguientes detalles en la consola de Oracle Cloud:
-
Espacio de nombres de arrendamiento


-
secreto de contraseña
-
Configuración de conexión de flujo
-
Token de autenticación
-
-
Abra el archivo zip descargado (
Java-CSV-DB.zipyJavaConsumeKafka.zip). Vaya a la carpeta /src/main/java/example y busque el código Example.java.
Estas son las variables que se deben cambiar con los valores de recursos de su arrendamiento.
NOMBRE VARIABLE NOMBRE DE RECURSO TÍTULO DE INFORMACIÓN bootstrapServers Configuración de conexión de flujo Servidores de inicialización de datos streamPoolId Configuración de conexión de flujo Valor ocid1.streampool.oc1.iad..... en la cadena de conexión SASL kafkaUsername Configuración de conexión de flujo valor de nombre de usuario dentro de " " en cadena de conexión SASL kafkaPassword Token de autenticación El valor solo se muestra en el paso de creación OBJECT_STORAGE_NAMESPACE ESPACIO DE NOMBRES DE ARRENDAMIENTO ARRENDAMIENTO ESPACIO DE NOMBRES ESPACIO DE NOMBRES DE ARRENDAMIENTO ARRENDAMIENTO PASSWORD_SECRET_OCID PASSWORD_SECRET_OCID OCID
Nota: Todos los recursos creados para esta demostración se encuentran en la región US-ASHBURN-1. Proteja la región que desea que funcione. Si cambia la región, debe cambiar 2 puntos en 2 archivos de código:
Example.java: cambie la variable bootstrapServers, sustituyendo "us-ashburn-1" por la nueva región
OboTokenClientConfigurator.java: cambie la variable CANONICAL_REGION_NAME con la nueva región
Tarea 8: Descripción del código Java
Este tutorial se creó en Java y este código se puede transferir también a Python. Para demostrar la eficiencia y escalabilidad, la aplicación se desarrolló para mostrar algunas posibilidades en un caso de uso común de un proceso de integración. Por lo tanto, el código de la aplicación muestra los siguientes ejemplos:
- Conéctese al flujo de Kafka y lea los datos
- Procesar JOINS con una tabla ADW para crear información útil
- Generar un archivo CSV con cada información útil proveniente de Kafka
Esta demostración se puede ejecutar en la máquina local y desplegarse en la instancia de Data Flow para ejecutarla como un trabajo.
Nota: Para el trabajo Data Flow y su máquina local, utilice la configuración de la CLI de OCI para acceder a los recursos de OCI. En Data Flow, todo está preconfigurado, por lo que no es necesario cambiar los parámetros. En el lado de la máquina local, debe haber instalado la CLI de OCI y configurado el inquilino, el usuario y la clave privada para acceder a sus recursos de OCI.
Vamos a mostrar el código Example.java en las secciones:
-
Inicialización de Apache Spark: esta parte del código representa la inicialización de Spark. Muchos parámetros para realizar procesos de ejecución se configuran automáticamente, por lo que es muy fácil trabajar con el motor de Spark. La inicialización difiere si se ejecuta dentro del flujo de datos o en la máquina local. Si está en Data Flow, no necesita cargar el archivo zip de cartera de ADW, la tarea de carga, descompresión y lectura de los archivos de cartera es automática dentro del entorno de Data Flow, pero en la máquina local, se debe realizar con algunos comandos.

-
Lea el secreto de ADW Vault: esta parte del código accede al almacén para obtener el secreto de la instancia de Autonomous Data Warehouse.

-
Consultar una tabla de ADW: esta sección muestra cómo ejecutar una consulta en una tabla.

-
Operaciones de Kafka: esta es la preparación para conectarse a OCI Streaming mediante la API de Kafka.
Nota: Oracle Cloud Streaming es compatible con la mayoría de las API de Kafka.

Hay un proceso para analizar los datos de JSON procedentes del tema Kafka en un juego de datos con la estructura correcta (ID de organización, nombre, país).
-
Fusionar los datos de un juego de datos de Kafka y un juego de datos de Autonomous Data Warehouse: en esta sección se muestra cómo ejecutar una consulta con 2 juegos de datos.

-
Salida en un archivo CSV: aquí se muestra cómo los datos combinados generan la salida en un archivo CSV.

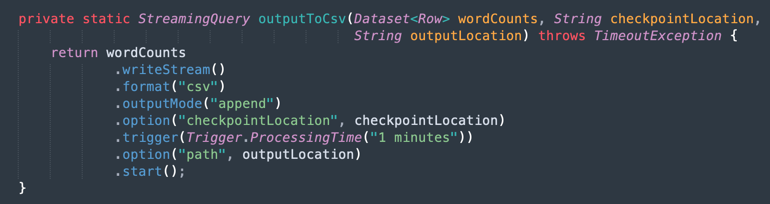
Tarea 9: Empaquetar la aplicación con Maven
Antes de ejecutar el trabajo en Spark, es necesario empaquetar la aplicación con Maven.
-
Vaya a la carpeta /DataflowSparkStreamDemo y ejecute este comando:
mvn package -
Puede ver Maven iniciando el empaquetado.

-
Si todo es correcto, puede ver el mensaje Correcto.

Tarea 10: Verificar la ejecución
-
Pruebe la aplicación en la máquina de Spark local ejecutando este comando:
spark-submit --class example.Example target/consumekafka-1.0-SNAPSHOT.jar -
Vaya a su instancia de Kafka de Oracle Cloud Streaming y haga clic en Producir mensaje de prueba para generar algunos datos para probar su aplicación en tiempo real.
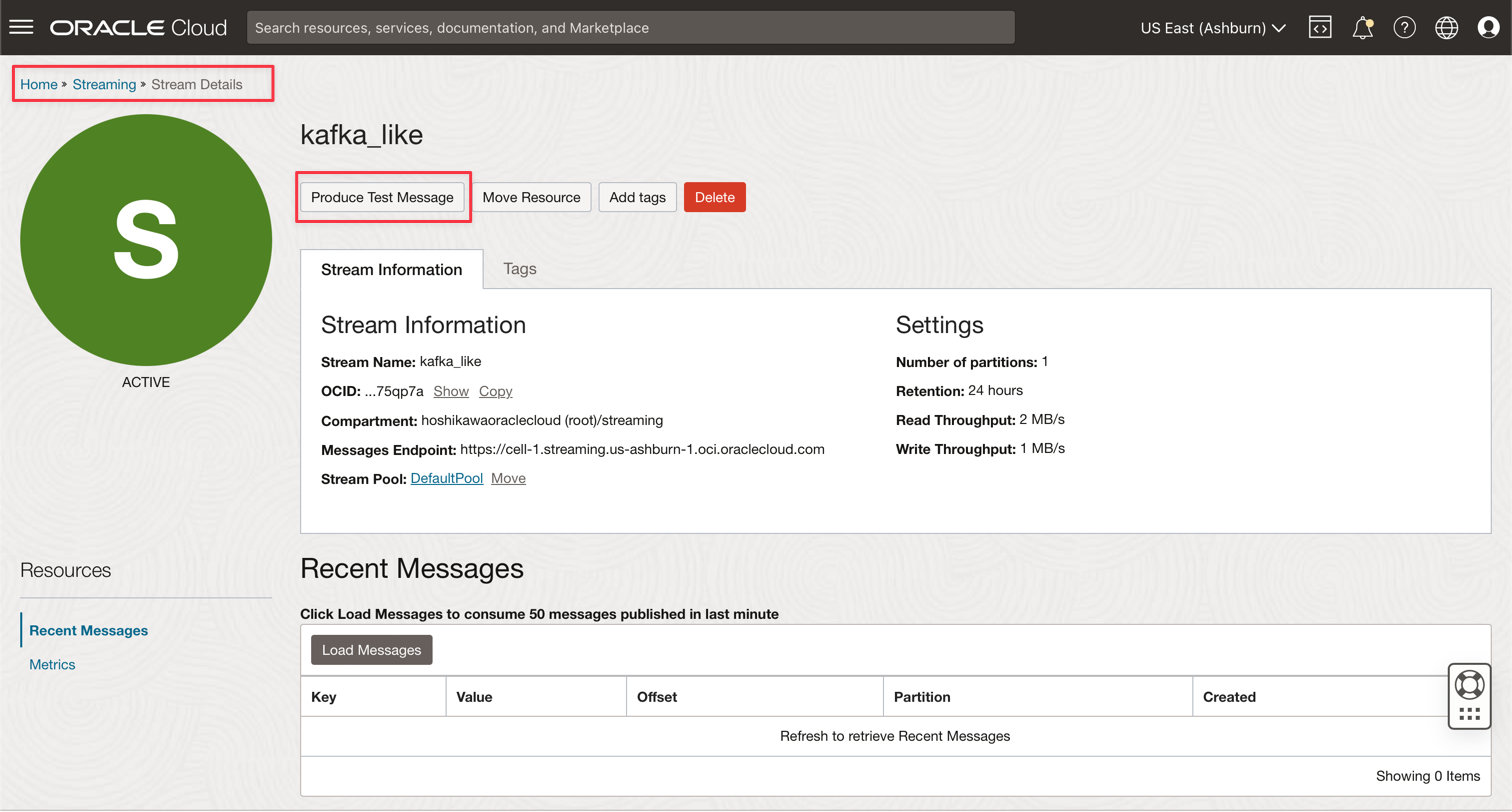
-
Puede incluir este mensaje JSON en el tema de Kafka.
{"Organization Id": "1235", "Name": "Teste", "Country": "Luxembourg"}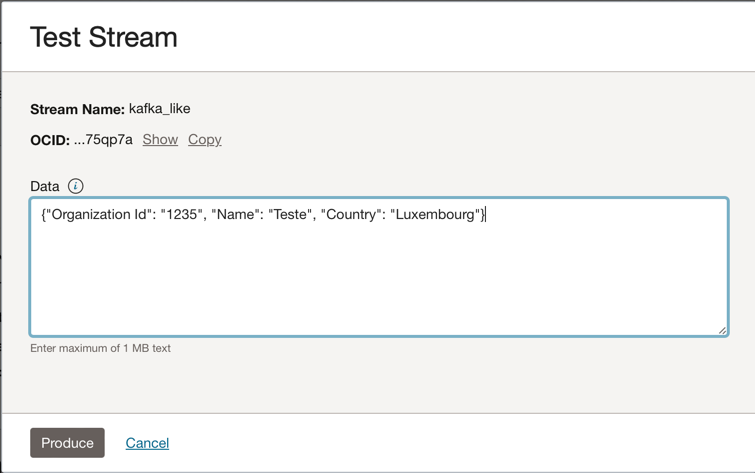
-
Cada vez que haga clic en Producir, enviará un mensaje a la aplicación. Puede ver el log de salida de la aplicación de forma similar a esta:
-
Estos son los datos leídos del tema de kafka.

-
Estos son los datos fusionados de la tabla ADW.

-
Tarea 11: Creación y ejecución de un trabajo de flujo de datos
Ahora, con las dos aplicaciones que se ejecutan con éxito en su máquina de Spark local, puede desplegarlas en el flujo de datos de Oracle Cloud de su arrendamiento.
Nota: Consulte la documentación de Spark Streaming para configurar el acceso a recursos como Oracle Object Storage y Oracle Streaming (Kafka): Activar acceso a Data Flow
-
Cargue los paquetes en Object Storage.
- Antes de crear una aplicación de Data Flow, debe cargar la aplicación de artefacto Java (el archivo ***-SNAPSHOT.jar) en el cubo de Object Storage denominado apps.
-
Cree una aplicación de Data Flow.
-
Seleccione el menú principal de Oracle Cloud y vaya a Análisis e IA y Flujo de datos. Asegúrese de seleccionar el compartimento análisis antes de crear una aplicación de flujo de datos.
-
Haga clic en Crear aplicación.

-
Rellene los parámetros como este.

-
Haga clic en Crear.
-
Después de la creación, haga clic en el enlace Ampliar demostración para ver los detalles. Para ejecutar un trabajo, haga clic en Ejecutar.
Nota: Haga clic en Mostrar opciones avanzadas para activar la seguridad de OCI para el tipo de ejecución Flujo de Spark.

-
-
Active las siguientes opciones.

-
Haga clic en Ejecutar para ejecutar el trabajo.
-
Confirme los parámetros y vuelva a hacer clic en Ejecutar.

-
Es posible ver el estado del trabajo.

-
Espere hasta que el estado vaya a Correcto y podrá ver los resultados.

-
Enlaces relacionados
Agradecimientos
- Autor: Cristiano Hoshikawa (ingeniero de la solución Oracle LAD A-Team)
Más recursos de aprendizaje
Explore otros laboratorios en docs.oracle.com/learn o acceda a más contenido de aprendizaje gratuito en el canal YouTube de Oracle Learning. Además, visite education.oracle.com/learning-explorer para convertirse en un explorador de Oracle Learning.
Para obtener documentación sobre los productos, visite Oracle Help Center.
Use OCI Data Flow with Apache Spark Streaming to process a Kafka topic in a scalable and near real-time application
F79979-02
May 2023
Copyright © 2023, Oracle and/or its affiliates.