Note:
- Este tutorial requiere acceso a Oracle Cloud. Para registrarse en una cuenta gratuita, consulte Introducción a la cuenta gratuita de Oracle Cloud Infrastructure.
- Utiliza valores de ejemplo para credenciales, arrendamiento y compartimentos de Oracle Cloud Infrastructure. Al finalizar el laboratorio, sustituya estos valores por otros específicos de su entorno en la nube.
Análisis de documentos PDF en lenguaje natural con OCI Generative AI
Introducción
Oracle Cloud Infrastructure Generative AI (OCI Generative AI) es una solución avanzada de inteligencia artificial generativa que permite a empresas y desarrolladores crear aplicaciones inteligentes utilizando modelos de lenguaje de vanguardia. Basada en potentes tecnologías como los grandes modelos de lenguaje (LLM), esta solución permite la automatización de tareas complejas, haciendo que los procesos sean más rápidos, eficientes y accesibles a través de interacciones de lenguaje natural.
Una de las aplicaciones más impactantes de OCI Generative AI es el análisis de documentos PDF. Las empresas a menudo se ocupan de grandes volúmenes de documentos, como contratos, informes financieros, manuales técnicos y documentos de investigación. La búsqueda manual de información en estos archivos puede llevar mucho tiempo y ser propensa a errores.
Con el uso de la inteligencia artificial generativa, es posible extraer información de forma instantánea y precisa, lo que permite a los usuarios consultar documentos complejos simplemente formulando preguntas en lenguaje natural. Esto significa que, en lugar de leer páginas completas para encontrar una cláusula específica en un contrato o un punto de datos relevante en un informe, los usuarios pueden simplemente preguntar al modelo, que devuelve rápidamente la respuesta basada en el contenido analizado.
Además de la recuperación de información, OCI Generative AI también se puede utilizar para resumir documentos largos, comparar contenido, clasificar información e incluso generar insights estratégicos. Estas capacidades hacen que la tecnología sea esencial para varios campos, como los legales, financieros, sanitarios e ingeniería, optimizando la toma de decisiones y aumentando la productividad.
Al integrar esta tecnología con herramientas como los servicios de Oracle AI, OCI Data Science y API para el procesamiento de documentos, las empresas pueden crear soluciones inteligentes que transformen completamente la forma en que interactúan con sus datos, lo que hace que la recuperación de información sea más rápida y efectiva.
Requisitos
- Instale Python
version 3.10o superior y la interfaz de línea de comandos de Oracle Cloud Infrastructure (CLI de OCI).
Tarea 1: Instalación de paquetes de Python
El código Python requiere determinadas bibliotecas para utilizar OCI Generative AI. Ejecute el siguiente comando para instalar los paquetes de Python necesarios.
pip install -r requirements.txt
Tarea 2: Descripción del código Python
Esta es una demostración de OCI Generative AI para consultar funcionalidades de Oracle SOA Suite y Oracle Integration. Ambas herramientas se utilizan actualmente para estrategias de integración híbrida, lo que significa que operan tanto en entornos locales como en la nube.
Dado que estas herramientas comparten funcionalidades y procesos, este código ayuda a comprender cómo implantar el mismo enfoque de integración en cada herramienta. Además, permite a los usuarios explorar características y diferencias comunes.
Descargue el código Python desde aquí:
Puede encontrar los documentos PDF aquí:
Cree una carpeta denominada Manuals y mueva estos PDF allí.
-
Importar Bibliotecas:
Importa las bibliotecas necesarias para procesar PDF, OCI Generative AI, vectorización de texto y almacenamiento en bases de datos vectoriales (Facebook AI Similarity Search (FAISS) y ChromaDB).
-
UnstructuredPDFLoaderse utiliza para extraer texto de los PDF. -
ChatOCIGenAIpermite el uso de modelos de IA generativa de OCI para responder preguntas. -
OCIGenAIEmbeddingscrea incrustaciones (representaciones vectoriales) de texto para la búsqueda semántica.
-
-
Cargar y procesar PDF:
Muestra los archivos PDF que se van a procesar.
-
UnstructuredPDFLoaderlee cada documento y lo divide en páginas para facilitar la indexación y la búsqueda. -
Las Id. de documento se almacenan para referencia futura.

-
-
Configure el modelo de IA generativa de OCI:
Configura el modelo
Llama-3.1-405balojado en OCI para generar respuestas basadas en los documentos cargados.Define parámetros como
temperature(control aleatorio),top_p(control de diversidad) ymax_tokens(límite de token).
Nota: La versión LLaMA disponible puede cambiar con el tiempo. Compruebe la versión actual de su arrendamiento y actualice el código si es necesario.
-
Crear incrustaciones e indexación de vectores:
Utiliza el modelo de integración de Oracle para transformar el texto en vectores numéricos, lo que facilita las búsquedas semánticas en documentos.

-
FAISS almacena las incrustaciones de los documentos PDF para consultas rápidas.
-
retrieverpermite recuperar los extractos más relevantes en función de la similitud semántica de la consulta del usuario.

-
-
En la primera ejecución del procesamiento, los datos vectoriales se guardarán en una base de datos FAISS.

-
Defina la petición de datos:
Crea una petición de datos inteligente para el modelo generativo, guiándolo a considerar solo los documentos relevantes para cada consulta.
Esto mejora la precisión de las respuestas y evita la información innecesaria.

-
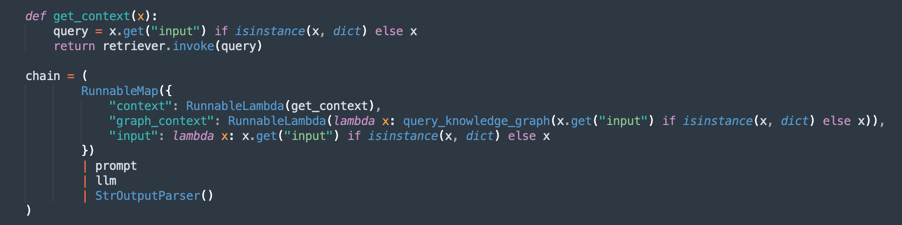
Creación de la cadena de proceso (RAG - Generación con recuperación aumentada):
Implementa un flujo de RAG, donde:
retrieverbusca los extractos de documentos más relevantes.promptorganiza la consulta para obtener un mejor contexto.llmgenera una respuesta basada en los documentos recuperados.StrOutputParserformatea la salida final.

-
Bucle de preguntas y respuestas:
Mantiene un bucle en el que los usuarios pueden hacer preguntas sobre los documentos cargados.
-
La IA responde utilizando la base de conocimientos extraída de los PDF.
-
Si introduce
quit, saldrá del programa.

-
Ahora, puede elegir 3 opciones para procesar los documentos. Puedes pensar:
- ¿Cuánta potencia tienes que procesar?
- ¿Cuántas veces tienes que procesar?
- ¿Cómo es la calidad de sus respuestas?
Por lo tanto, tiene las siguientes opciones:
Fixed Size Chunking: una alternativa más rápida para procesar los documentos. Puede ser suficiente para obtener lo que quieres.
Fragmentación semántica: este proceso será más lento que la fragmentación de tamaño fijo, pero proporcionará más fragmentación de calidad.
Fragmentación semántica con GraphRAG: entregará un método más preciso porque organizará los textos de fragmentación y los gráficos de conocimientos.
Fragmentación de tamaño fijo
Descargue el código desde aquí: oci_genai_llm_context_fast.py.
-
¿Qué es la fragmentación de tamaño fijo?
Fragmentación de tamaño fijo es una estrategia de división de texto simple y eficiente donde los documentos se dividen en fragmentos basados en límites de tamaño predefinidos, normalmente medidos en tokens, caracteres o líneas.
Este método no analiza el significado o la estructura del texto. Simplemente divide el contenido en intervalos fijos, independientemente de si el corte ocurre en medio de una oración, párrafo o idea.
-
Funcionamiento de la fragmentación de tamaño fijo:
-
Regla de ejemplo: divida el documento cada 1000 tokens (o cada 3000 caracteres).
-
Superposición opcional: para reducir el riesgo de dividir el context relevante, algunas implantaciones agregan una superposición entre fragmentos consecutivos (por ejemplo, superposición de 200 tokens) para garantizar que el context importante no se pierda en el límite.
-
-
Ventajas de la fragmentación de tamaño fijo:
-
Procesamiento rápido: no es necesario el análisis semántico, la inferencia de LLM ni la comprensión del contenido. Solo cuenta y corta.
-
Bajo consumo de recursos: uso mínimo de CPU/GPU y memoria, lo que lo hace escalable para juegos de datos de gran tamaño.
-
Fácil de implementar: funciona con secuencias de comandos simples o bibliotecas de procesamiento de texto estándar.
-
-
Limitaciones de la fragmentación de tamaño fijo:
-
Conciencia semántica deficiente: los fragmentos pueden cortar oraciones, párrafos o secciones lógicas, lo que lleva a ideas incompletas o fragmentadas.
-
Precisión de recuperación reducida: en aplicaciones como la búsqueda semántica o la generación aumentada de recuperación (RAG), los límites de fragmentos deficientes pueden afectar a la relevancia y la calidad de las respuestas recuperadas.
-
-
Cuándo utilizar la fragmentación de tamaño fijo:
-
Cuando la velocidad de procesamiento y la escalabilidad son las principales prioridades.
-
Para pipelines de ingestión de documentos a gran escala en los que la precisión semántica no es crítica.
-
Como primer paso en los escenarios en los que posteriormente se realizará una acotación o un análisis semántico aguas abajo.
-
Este es un método muy simple para dividir el texto.

-
Este es el proceso principal de fragmentación fija.

Nota: Descargue este código para procesar la fragmentación fija más más rápida:
oci_genai_llm_context_fast.py -
Fragmentación semántica
Descargue el código desde aquí: oci_genai_llm_context.py.
-
¿Qué es la fragmentación semántica?
La fragmentación semántica es una técnica de preprocesamiento de texto en la que los documentos grandes (como PDF, presentaciones o artículos) se dividen en partes más pequeñas denominadas fragmentos, y cada fragmento representa un bloque de texto semánticamente coherente.
A diferencia de la fragmentación tradicional de tamaño fijo (por ejemplo, dividir cada 1000 tokens o cada X caracteres), la fragmentación semántica utiliza inteligencia artificial (normalmente grandes modelos de lenguaje - LLM) para detectar límites de contenido natural, respetando temas, secciones y context.
En lugar de cortar el texto arbitrariamente, Semantic Chunking trata de preservar el significado completo de cada sección, creando piezas independientes y conscientes del contexto.
-
¿Por qué la fragmentación semántica puede hacer que el procesamiento sea más lento?
Un proceso de fragmentación tradicional, basado en el tamaño fijo, es rápido. El sistema solo cuenta tokens o caracteres y los corta en consecuencia. Con la fragmentación semántica, se requieren varios pasos adicionales de análisis semántico:
- Lectura e interpretación del texto completo (o bloques grandes) antes de la división: el LLM debe comprender el contenido para identificar los mejores límites de fragmentos.
- Ejecución de peticiones de datos del LLM o modelos de clasificación de temas: el sistema suele consultar el LLM con preguntas como ¿Es este el final de una idea? o ¿Este párrafo inicia una nueva sección?.
- Mayor uso de memoria y CPU/GPU: dado que el modelo procesa bloques de texto más grandes antes de tomar decisiones de fragmentación, el consumo de recursos es significativamente mayor.
- Toma de decisiones secuencial e incremental: la fragmentación semántica suele funcionar en pasos (por ejemplo, analizando bloques de 10 000 tokens y, a continuación, refinando los límites de fragmentos dentro de ese bloque), lo que aumenta el tiempo total de procesamiento.
Nota:
- En función de la potencia de procesamiento del equipo, esperará mucho tiempo para finalizar la primera ejecución mediante Fragmentación semántica.
- Puede utilizar este algoritmo para producir fragmentación personalizada mediante OCI Generative AI.
-
Cómo funciona la fragmentación semántica:
-
smart_split_text(): separa el texto completo en pequeños fragmentos de 10 kb (puede configurar para adoptar otras estrategias). El mecanismo percibe el último párrafo. Si parte del párrafo está en la siguiente parte del texto, esta parte se ignorará en el procesamiento y se agregará al siguiente grupo de texto de procesamiento. -
semantic_chunk(): este método utilizará el mecanismo del LLM de OCI para separar los párrafos. Incluye la inteligencia para identificar los títulos, los componentes de una tabla, los párrafos para ejecutar un fragmento inteligente. La estrategia aquí es utilizar la técnica de fragmento semántico. Tomará más tiempo completar la misión si se compara con el procesamiento común. Por lo tanto, el primer procesamiento tardará mucho tiempo, pero el siguiente cargará todos los datos guardados previamente por FAISS. -
split_llm_output_into_chapters(): este método finalizará el fragmento, separando los capítulos.
Nota: Descargue este código para procesar la fragmentación semántica:
oci_genai_llm_context.py -
Fragmentación semántica con GraphRAG
Descargue el código desde aquí: oci_genai_llm_graphrag.py.
GraphRAG (Generación aumentada por recuperación aumentada por gráficos) es una arquitectura de IA avanzada que combina la recuperación tradicional basada en vectores con gráficos de conocimientos estructurados. En un pipeline RAG estándar, un modelo de lenguaje recupera fragmentos de documentos relevantes utilizando la similitud semántica de una base de datos vectorial (como FAISS). Sin embargo, la recuperación basada en vectores funciona de manera no estructurada, basándose únicamente en incrustaciones y métricas de distancia, que a veces pierden significados contextuales o relacionales más profundos.
GraphRAG mejora este proceso mediante la introducción de una capa de gráfico de conocimientos, donde las entidades, los conceptos, los componentes y sus relaciones se representan explícitamente como nodos y bordes. Este context basado en gráficos permite al modelo de lenguaje razonar sobre relaciones, jerarquías y dependencias que la similitud de vectores por sí sola no puede capturar.
-
¿Por qué combinar fragmentación semántica con GraphRAG?
La fragmentación semántica es el proceso de dividir inteligentemente documentos grandes en unidades significativas o "fragmentos", en función de la estructura del contenido, como capítulos, encabezados, secciones o divisiones lógicas. En lugar de romper documentos puramente por límites de caracteres o división ingenua de párrafos, la fragmentación semántica produce fragmentos de mayor calidad conscientes del context que se alinean mejor con la comprensión humana.
-
Fragmentación semántica con GraphRAG Ventajas:
-
Representación mejorada del conocimiento:
- Los fragmentos semánticos conservan los límites lógicos en el contenido.
- Los gráficos de conocimientos extraídos de estos fragmentos mantienen relaciones precisas entre entidades, sistemas, API, procesos o servicios.
-
Recuperación contextual multimodal (el modelo de idioma recupera ambos):
- context no estructurado de la base de datos vectorial (similitud semántica).
- context estructurado a partir del gráfico de conocimientos (triples entidad-relación).
- Este enfoque híbrido conduce a respuestas más completas y precisas.
-
Capacidades de razonamiento mejoradas:
- La recuperación basada en gráficos permite el razonamiento relacional.
- El LLM puede responder preguntas como:
- ¿De qué servicios depende la API de pedidos?
- ¿Qué componentes forman parte de SOA Suite?
- Estas consultas relacionales suelen ser imposibles con enfoques de solo incrustación.
-
Mayor explicabilidad y trazabilidad:
- Las relaciones de grafos son legibles por el usuario y transparentes.
- Los usuarios pueden inspeccionar cómo se derivan las respuestas de los conocimientos textuales y estructurales.
-
Alucinación reducida: el gráfico actúa como una restricción en el LLM, anclando respuestas a relaciones verificadas y conexiones de hechos extraídas de los documentos de origen.
-
Escalabilidad en dominios complejos:
- En los dominios técnicos (por ejemplo, API, microservicios, contratos legales, estándares de atención médica), las relaciones entre componentes son tan importantes como los propios componentes.
- GraphRAG combinado con escalas de fragmentación semántica de manera efectiva en estos contextos, preservando tanto la profundidad textual como la estructura relacional.
Nota:
- Descargue el código para procesar la fragmentación semántica con graphRAG desde aquí:
oci_genai_llm_graphrag.py. - Necesitará:
- Un docker instalado y activo para utilizar la base de datos del sistema operativo de gráficos de código abierto Neo4J para realizar la prueba.
- Instale la biblioteca Python neo4j.
Hay 2 métodos en este código:
-
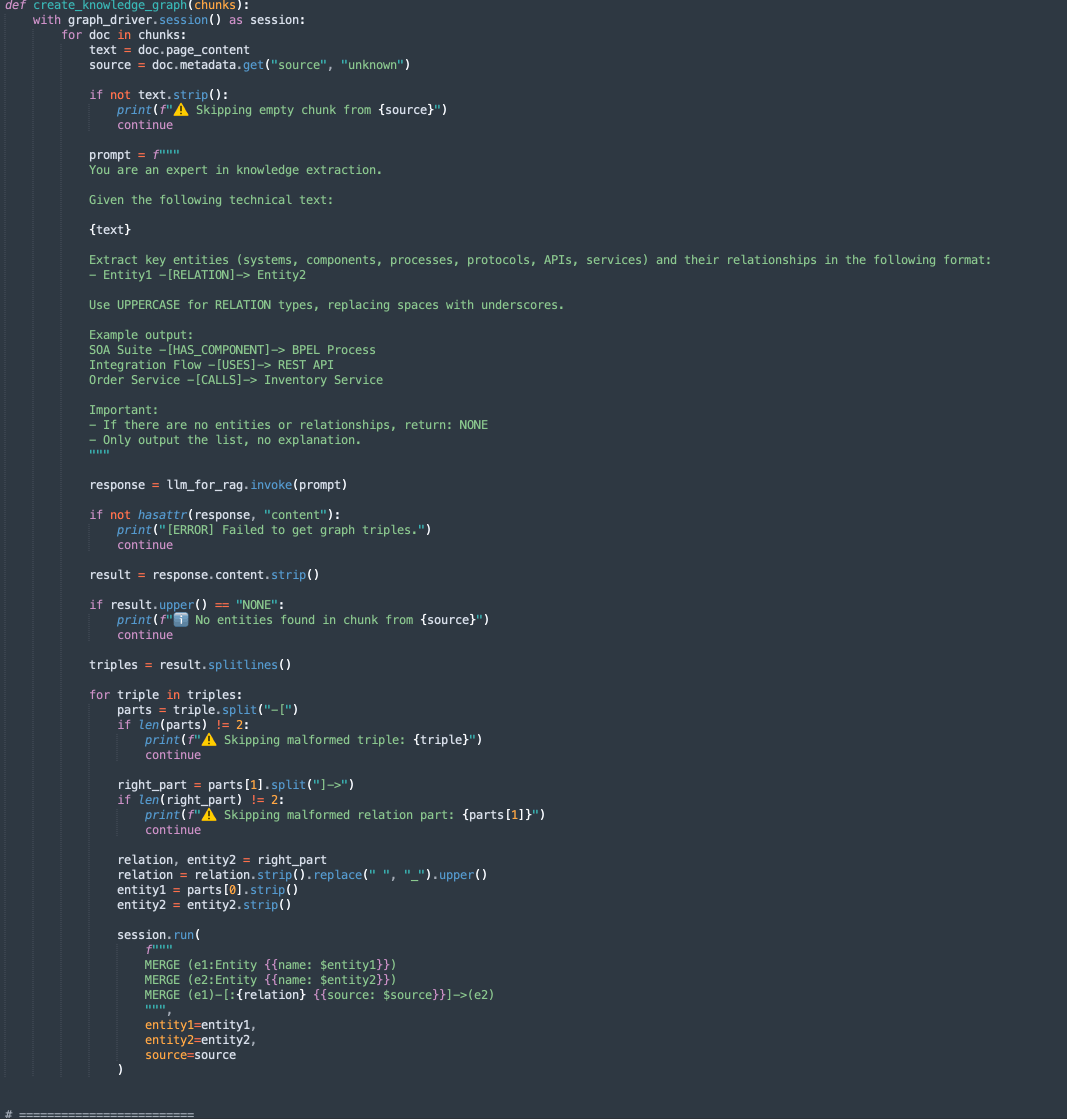
create_knowledge_graph:-
Este método extrae automáticamente entidades y relaciones de fragmentos de texto y las almacena en un gráfico de conocimientos Neo4j.
-
Para cada fragmento de documento, envía el contenido a un LLM (modelo de lenguaje grande) con una petición de datos que solicita la extracción de entidades (como sistemas, componentes, servicios, API) y sus relaciones.
-
Analiza cada línea, extrae Entity1, RELATION y Entity2.
-
Almacena esta información como nodos y bordes en la base de datos de gráficos Neo4j mediante consultas Cypher:
MERGE (e1:Entity {name: $entity1}) MERGE (e2:Entity {name: $entity2}) MERGE (e1)-[:RELATION {source: $source}]->(e2)
-
-
-
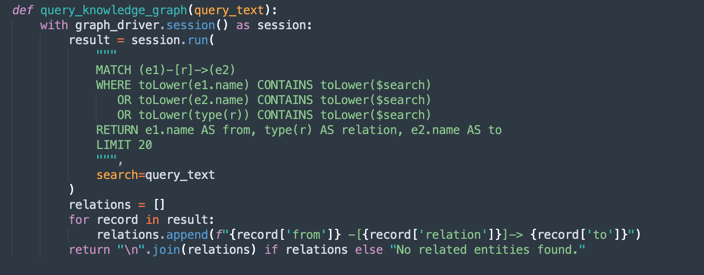
query_knowledge_graph:-
Este método consulta el gráfico de conocimientos Neo4j para recuperar relaciones relacionadas con una palabra clave o concepto específico.
-
Ejecuta una consulta Cypher que busca:
Any relationship (e1)-[r]->(e2) Where e1.name, e2.name, or the relationship type contains the query_text (case-insensitive). -
Devuelve hasta 20 triples coincidentes formateados como:
Entity1 -[RELATION]-> Entity2
-
Nota:
Neo4j Uso:
Esta implantación utiliza Neo4j como base de datos de gráficos de conocimientos integrada para fines de demostración y creación de prototipos. Si bien Neo4j es una base de datos de gráficos potente y flexible adecuada para cargas de trabajo de desarrollo, prueba y pequeñas y medianas, puede que no cumpla los requisitos para cargas de trabajo empresariales, esenciales o de alta seguridad, especialmente en entornos que exigen alta disponibilidad, escalabilidad y conformidad de seguridad avanzada.
Para entornos de producción y escenarios empresariales, recomendamos aprovechar Oracle Database con capacidades de Gráfico, que ofrece:
Fiabilidad y seguridad empresariales.
Escalabilidad para cargas de trabajo esenciales.
Modelos de grafos nativos (Property Graph y RDF) integrados con datos relacionales.
Funciones avanzadas de análisis, seguridad, alta disponibilidad y recuperación ante desastres.
Integración completa de Oracle Cloud Infrastructure (OCI).
Al utilizar Oracle Database para cargas de trabajo de grafos, las organizaciones pueden unificar datos estructurados, semiestructurados y graficados en una única plataforma empresarial segura y ampliable.
Tarea 3: Ejecutar Consulta para Contenido de Oracle Integration y Oracle SOA Suite
Ejecute el siguiente comando.
FOR FIXED CHUNKING TECHNIQUE (MORE FASTER METHOD)
python oci_genai_llm_context_fast.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
FOR SEMANTIC CHUNKING TECHNIQUE
python oci_genai_llm_context.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
FOR SEMANTIC CHUNKING COMBINED WITH GRAPHRAG TECHNIQUE
python oci_genai_llm_graphrag.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
Nota: Los parámetros
--devicey--gpu_namese pueden utilizar para acelerar el procesamiento en Python, mediante GPU si la máquina tiene uno. Tenga en cuenta que este código también se puede utilizar con modelos locales.
El contexto proporcionado distingue a Oracle SOA Suite y Oracle Integration. Puede probar el código teniendo en cuenta estos puntos:
- La consulta solo se debe realizar para Oracle SOA Suite: por lo tanto, solo se deben tener en cuenta los documentos de Oracle SOA Suite.
- La consulta solo se debe realizar para Oracle Integration. Por lo tanto, solo se deben tener en cuenta los documentos de Oracle Integration.
- La consulta requiere una comparación entre Oracle SOA Suite y Oracle Integration: por lo tanto, se deben tener en cuenta todos los documentos.
Podemos definir el siguiente contexto, lo que ayuda en gran medida a interpretar los documentos correctamente.
En la siguiente imagen se muestra el ejemplo de comparación entre Oracle SOA Suite y Oracle Integration.

Pasos Siguientes
En este código se muestra una aplicación de OCI Generative AI para el análisis inteligente en PDF. Permite a los usuarios consultar de manera eficiente grandes volúmenes de documentos mediante búsquedas semánticas y un modelo de IA generativa para generar respuestas precisas en lenguaje natural.
Este enfoque se puede aplicar en varios campos, como el legal, el cumplimiento, el soporte técnico y la investigación académica, lo que hace que la recuperación de información sea mucho más rápida e inteligente.
Enlaces relacionados
-
Puente de la nube y la IA conversacional: LangChain y la plataforma OCI Data Science
-
Introducción a los agentes LangChain de Python personalizados e integrados
-
Oracle Database Insider: Graph RAG: lleva el poder de los gráficos a la IA generativa
Acuses de recibo
- Autor: Cristiano Hoshikawa (ingeniero de soluciones de Oracle LAD A-Team)
Más recursos de aprendizaje
Explore otros laboratorios en docs.oracle.com/learn o acceda a más contenido de aprendizaje gratuito en el canal YouTube de Oracle Learning. Además, visite education.oracle.com/learning-explorer para convertirse en un explorador de Oracle Learning.
Para obtener documentación sobre el producto, visite Oracle Help Center.
Analyze PDF Documents in Natural Language with OCI Generative AI
G29537-05
Copyright ©2025, Oracle and/or its affiliates.