Utilisation de JupyterHub dans le service de mégadonnées 3.0.26 ou version antérieure
Utilisez JupyterHub pour gérer les carnets ODH 1.x du service de mégadonnées 3.0.26 ou antérieurs pour des groupes d'utilisateurs.
Préalables
Avant d'accéder à JupyterHub à partir d'un navigateur, un administrateur doit :
- Rendre le noeud disponible aux connexions entrantes des utilisateurs. L'adresse IP privée du noeud doit être mappée à une adresse IP publique. La grappe peut également être configurée pour utiliser un hôte bastion ou Oracle FastConnect. Voir Connexion aux noeuds de grappe avec des adresses IP privées.
- Ouvrez le port
8000sur le noeud en configurant les règles de trafic entrant dans la liste de sécurité du réseau. Voir Définition des règles de sécurité.
JupyterHub Données d'identification par défaut
Les données d'identification de connexion de l'administrateur par défaut pour JupyterHub dans le service de mégadonnées 3.0.21 et les versions antérieures sont les suivantes :
- Nom d'utilisateur :
jupyterhub - Mot de passe : Mot de passe de l'administrateur Apache Ambari. Il s'agit du mot de passe d'administrateur de la grappe qui a été spécifié lors de la création de celle-ci.
- Nom de principal pour la grappe hautement disponible :
jupyterhub - Fichier keytab de la grappe hautement disponible :
/etc/security/keytabs/jupyterhub.keytab
Les données d'identification de connexion de l'administrateur par défaut pour JupyterHub dans le service de mégadonnées 3.0.22 à 3.0.26 sont les suivantes :
- Nom d'utilisateur :
jupyterhub - Mot de passe : Mot de passe de l'administrateur Apache Ambari. Il s'agit du mot de passe d'administrateur de la grappe qui a été spécifié lors de la création de celle-ci.
- Nom principal de la grappe hautement disponible :
jupyterhub/<FQDN-OF-UN1-Hostname> - Fichier keytab de la grappe hautement disponible :
/etc/security/keytabs/jupyterhub.keytabExemple :Principal name for HA cluster: jupyterhub/pkbdsv2un1.rgroverprdpub1.rgroverprd.oraclevcn.com Keytab for HA cluster: /etc/security/keytabs/jupyterhub.keytab
L'administrateur crée des utilisateurs supplémentaires et leurs données d'identification de connexion, et fournit les données d'identification de connexion à ces utilisateurs. Pour plus d'informations, voir Gérer les utilisateurs et les autorisations.
Sauf mention explicite d'un autre type d'administrateur, le terme administrator ou admin dans l'ensemble de cette section fait référence à l'administrateur de JupyterHub, jupyterhub.
Accès à JupyterHub
Vous pouvez également accéder au lien JupyterHub à partir de la page des détails de la grappe sous URL de la grappe.
Vous pouvez également créer un équilibreur de charge pour fournir un élément frontal sécurisé pour accéder aux services, notamment JupyterHub. Voir Connexion aux services d'une grappe à l'aide d'un équilibreur de charge.
Génération de carnets
Les préalables doivent être satisfaits pour l'utilisateur qui tente de générer des carnets.
- Accédez à JupyterHub.
- Connectez-vous avec les données d'identification de l'administrateur. L'autorisation ne fonctionne que si l'utilisateur est présent sur l'hôte Linux. JupyterHub recherche l'utilisateur sur l'hôte Linux lors de la tentative de génération du serveur de carnets.
- Vous êtes dirigé vers une page d'options de serveur où vous devez demander un ticket Kerberos. Ce ticket peut être demandé à l'aide du principal Kerberos et du fichier keytab, ou du mot de passe Kerberos. L'administrateur de la grappe peut fournir le principal Kerberos et le fichier keytab, ou le mot de passe Kerberos.
Le ticket Kerberos est nécessaire pour accéder aux répertoires HDFS et aux autres services de mégadonnées que vous voulez utiliser.
Les préalables doivent être satisfaits pour l'utilisateur qui tente de générer des carnets.
- Accédez à JupyterHub.
- Connectez-vous avec les données d'identification de l'administrateur. L'autorisation ne fonctionne que si l'utilisateur est présent sur l'hôte Linux. JupyterHub recherche l'utilisateur sur l'hôte Linux lors de la tentative de génération du serveur de carnets.
Gérer JupyterHub
Un utilisateur JupyterHub admin peut effectuer les tâches suivantes pour gérer les carnets dans JupyterHub sur les noeuds ODH 1.x du service de mégadonnées 3.0.26 ou antérieurs.
En tant qu'utilisateur admin, vous pouvez configurer JupyterHub.
Configurez JupyterHub au moyen du navigateur pour les grappes du service de mégadonnées 3.0.26 ou antérieures.
Arrêtez ou démarrez JupyterHub au moyen du navigateur pour les grappes du service de mégadonnées 3.0.26 ou antérieures.
En tant qu'utilisateur admin, vous pouvez arrêter ou désactiver l'application afin qu'elle ne consomme pas de ressources, telles que la mémoire. Le redémarrage peut également aider à rectifier des problèmes inattendus ou un comportement.
En tant qu'administrateur, vous pouvez limiter le nombre de serveurs de carnets actifs dans la grappe du service de mégadonnées.
Par défaut, les carnets sont stockés dans le répertoire HDFS d'une grappe.
Vous devez avoir accès au répertoire HDFS hdfs:///user/<username>/. Les carnets sont enregistrés dans hdfs:///user/<username>/notebooks/.
- Connectez-vous en tant qu'utilisateur
opcau noeud d'utilitaire où JupyterHub est installé (le deuxième noeud d'utilitaire d'une grappe hautement disponible, ou le premier et unique noeud d'une grappe qui n'est pas hautement disponible). - Utilisez
sudopour gérer les configurations JupyterHub stockées dans/opt/jupyterhub/jupyterhub_config.py.c.Spawner.args = ['--ServerApp.contents_manager_class="hdfscm.HDFSContentsManager"'] - Utilisez
sudopour redémarrer JupyterHub.sudo systemctl restart jupyterhub.service
En tant qu'utilisateur administrateur, vous pouvez stocker les carnets d'utilisateurs individuels dans le stockage d'objets au lieu de HDFS. Lorsque vous faites passer le gestionnaire de contenu de HDFS au stockage d'objets, les blocs-notes existants ne sont pas copiés vers le stockage d'objets. Les nouveaux carnets sont enregistrés dans le stockage d'objets.
- Connectez-vous en tant qu'utilisateur
opcau noeud d'utilitaire où JupyterHub est installé (le deuxième noeud d'utilitaire d'une grappe hautement disponible, ou le premier et unique noeud d'une grappe qui n'est pas hautement disponible). - Utilisez
sudopour gérer les configurations JupyterHub stockées dans/opt/jupyterhub/jupyterhub_config.py. Voir Générer la clé d'accès et la clé secrète pour savoir comment générer les clés requises.c.Spawner.args = ['--ServerApp.contents_manager_class="s3contents.S3ContentsManager"', '--S3ContentsManager.bucket="<bucket-name>"', '--S3ContentsManager.access_key_id="<accesskey>"', '--S3ContentsManager.secret_access_key="<secret-key>"', '--S3ContentsManager.endpoint_url="https://<object-storage-endpoint>"', '--S3ContentsManager.region_name="<region>"','--ServerApp.root_dir=""'] - Utilisez
sudopour redémarrer JupyterHub.sudo systemctl restart jupyterhub.service
Intégration avec le stockage d'objets
Intégrer Spark au service de stockage d'objets à utiliser avec les grappes du service de mégadonnées.
Dans JupyterHub, pour que Spark fonctionne avec le stockage d'objets, vous devez définir certaines propriétés de système et les alimenter dans les propriétés spark.driver.extraJavaOption et spark.executor.extraJavaOptions des configurations de Spark.
Avant de pouvoir intégrer JupyterHub avec le stockage d'objets, vous devez :
- Créer un seau dans le magasin d'objets pour stocker des données.
- Créer une clé d'API de stockage d'objets.
Les propriétés que vous devez définir dans les configurations de Spark sont les suivantes :
-
TenantID -
Userid -
Fingerprint -
PemFilePath -
PassPhrase -
Region
Extrayez les valeurs de ces propriétés :
- Ouvrez le menu de navigation et sélectionnez Analyse et intelligence artificielle. Sous Lac de données, sélectionnez Service de mégadonnées.
- Dans la page de liste Grappes, sélectionnez la grappe avec laquelle vous voulez travailler. Si vous avez besoin d'aide pour trouver la page de liste ou la grappe, voir Liste des grappes d'un compartiment.
-
Pour voir les grappes d'un autre compartiment, changez de compartiment.
Vous devez être autorisé à travailler dans un compartiment pour voir les ressources qu'il contient. Si vous n'êtes pas certain du compartiment à utiliser, communiquez avec un administrateur. Pour plus d'informations, voir Présentation des compartiments.
- Dans la page des détails de la grappe, sélectionnez Clés d'API du service de stockage d'objets.
- Dans le menu de la clé d'API à afficher, sélectionnez Voir le fichier de configuration.
Le fichier de configuration contient tous les détails des propriétés de système, à l'exception de la phrase secrète. La phrase secrète est spécifiée lors de la création de la clé d'API de stockage d'objets et vous devez récupérer et utiliser la même phrase secrète.
- Accédez à JupyterHub.
- Ouvrez un nouveau carnet.
- Copiez et collez les commandes suivantes pour vous connecter à Spark.
import findspark findspark.init() import pyspark - Copiez et collez les commandes suivantes pour créer une session Spark avec les configurations spécifiées. Remplacez les variables par les valeurs de propriétés de système que vous avez extraites précédemment.
from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .enableHiveSupport() \ .config("spark.driver.extraJavaOptions", "-DBDS_OSS_CLIENT_REGION=<Region> -DBDS_OSS_CLIENT_AUTH_TENANTID=<TenantId> -DBDS_OSS_CLIENT_AUTH_USERID=<UserId> -DBDS_OSS_CLIENT_AUTH_FINGERPRINT=<FingerPrint> -DBDS_OSS_CLIENT_AUTH_PEMFILEPATH=<PemFile> -DBDS_OSS_CLIENT_AUTH_PASSPHRASE=<PassPhrase>")\ .config("spark.executor.extraJavaOptions" , "-DBDS_OSS_CLIENT_REGION=<Region> -DBDS_OSS_CLIENT_AUTH_TENANTID=<TenantId> -DBDS_OSS_CLIENT_AUTH_USERID=<UserId> -DBDS_OSS_CLIENT_AUTH_FINGERPRINT=<FingerPrint> -DBDS_OSS_CLIENT_AUTH_PEMFILEPATH=<PemFile> -DBDS_OSS_CLIENT_AUTH_PASSPHRASE=<PassPhrase>")\ .appName("<appname>") \ .getOrCreate() - Copiez et collez les commandes suivantes pour créer les répertoires et le fichier de stockage d'objets et pour stocker les données au format Parquet.
demoUri = "oci://<BucketName>@<Tenancy>/<DirectoriesAndSubDirectories>/" parquetTableUri = demoUri + "<fileName>" spark.range(10).repartition(1).write.mode("overwrite").format("parquet").save(parquetTableUri) - Copiez et collez la commande suivante pour lire des données à partir du stockage d'objets.
spark.read.format("parquet").load(parquetTableUri).show() - Exécutez le carnet avec toutes ces commandes.
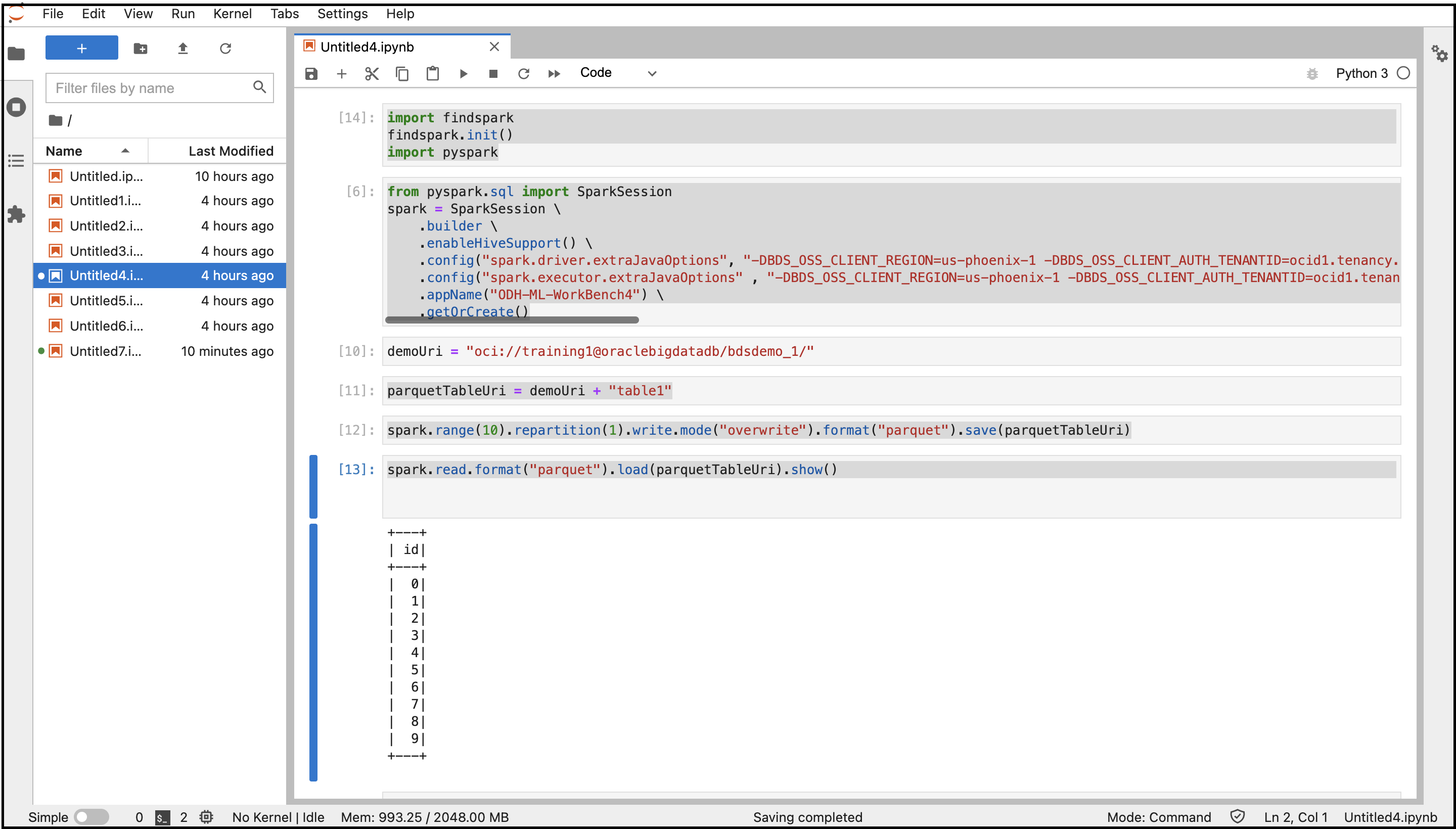
La sortie du code est affichée. Vous pouvez naviguer jusqu'au seau de stockage d'objets à partir de la console et rechercher le fichier créé dans le seau.
Gérer les utilisateurs et les autorisations
Utilisez l'une des deux méthodes d'authentification pour authentifier les utilisateurs dans JupyterHub afin qu'ils puissent créer des carnets et, éventuellement, administrer JupyterHub.
Par défaut, les grappes ODH 1.x prennent en charge l'authentification native. Toutefois, l'authentification pour JupyterHub et les autres services de mégadonnées doit être gérée différemment. Pour générer des carnets d'utilisateur unique, l'utilisateur qui se connecte à JupyterHub doit être présent sur l'hôte Linux et avoir les autorisations nécessaires pour écrire dans le répertoire racine dans HDFS. Sinon, le générateur échoue car le processus de carnet est déclenché en tant qu'utilisateur Linux.
Pour plus d'informations sur l'authentification native, voir Authentification native.
Pour plus d'informations sur l'authentification LDAP pour le service de mégadonnées 3.0.26 ou une version antérieure, voir Authentification LDAP.
L'authentification native dépend de la base de données d'utilisateurs JupyterHub pour l'authentification des utilisateurs.
L'authentification native s'applique aux grappes qui sont hautement disponibles et à celles qui ne le sont pas. Reportez-vous à NativeAuthenticator pour plus de détails sur l'authentificateur natif.
Ces préalables doivent être satisfaits pour autoriser un utilisateur dans une grappe hautement disponible pour le service de mégadonnées à l'aide de l'authentification native.
Ces préalables doivent être satisfaits pour autoriser un utilisateur dans une grappe non hautement disponible du service de mégadonnées à l'aide de l'authentification native.
Les administrateurs sont responsables de la configuration et de la gestion de JupyterHub. Les administrateurs sont également responsables de l'autorisation des utilisateurs qui viennent de s'inscrire à JupyterHub.
Avant l'ajout d'un utilisateur administrateur, les conditions requises doivent être remplies pour une grappe non hautement disponible.
- Accédez à Apache Ambari.
- Dans la barre d'outils latérale, sous Services, sélectionnez JupyterHub.
- Sélectionnez Configs, puis Advanced Configs.
- Sélectionnez Advanced jupyterhub-config.
-
Ajoutez l'utilisateur administrateur à
c.Authenticator.admin_users. - Sélectionnez enregistrer.
Avant d'ajouter d'autres utilisateurs, les conditions requises doivent être remplies pour une grappe du service de mégadonnées.
-
L'administrateur doit se connecter à JupyterHub et, à partir de la nouvelle option de menu permettant d'autoriser les utilisateurs connectés, il doit autoriser le nouvel utilisateur.
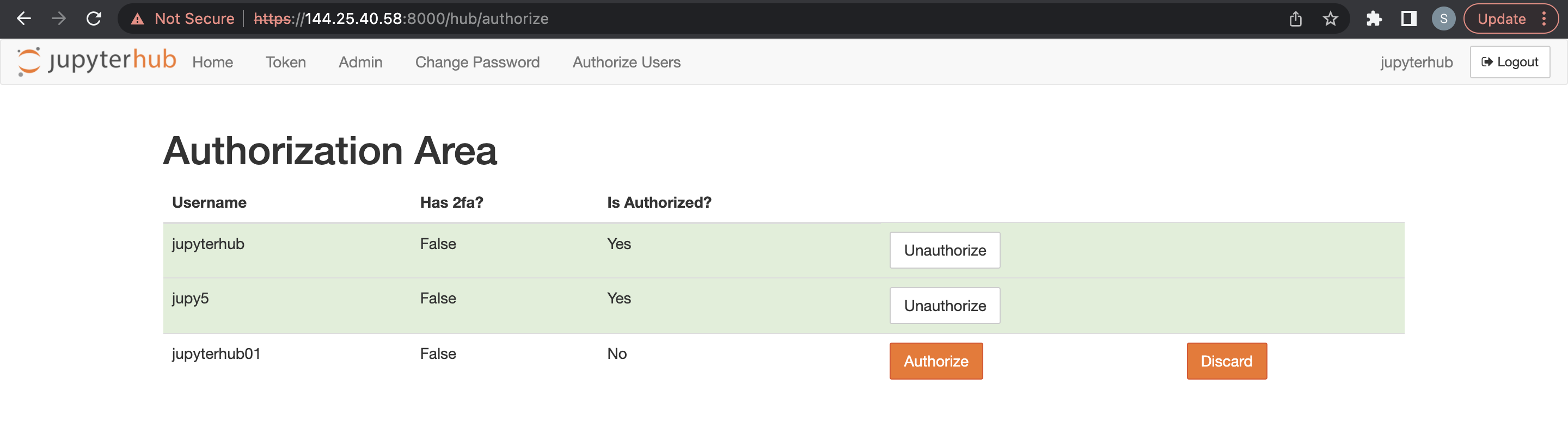
Un administrateur peut supprimer des utilisateurs JupyterHub.
- Accédez JupyterHub.
- Ouvrez File (Fichier) > HubControlPanel.
- Naviguez jusqu'à la page Authorize Users (Autoriser des utilisateurs).
- Supprimez les utilisateurs voulus.
Vous pouvez utiliser l'authentification LDAP au moyen d'un navigateur pour les clusters ODH 1.x du service de mégadonnées 3.0.26 ou antérieurs.
Intégrer à Trino
- Trino doit être installé et configuré dans la grappe du service de mégadonnées.
- Installez le module Python suivant dans le noeud JupyterHub (un1 pour la haute disponibilité / un0 pour la grappe non hautement disponible) Note
Ignorez cette étape si le module Trino-Python est déjà présent dans le noeud.python3.6 -m pip install trino[sqlalchemy] Offline Installation: Download the required python module in any machine where we have internet access Example: python3 -m pip download trino[sqlalchemy] -d /tmp/package Copy the above folder content to the offline node & install the package python3 -m pip install ./package/* Note : trino.sqlalchemy is compatible with the latest 1.3.x and 1.4.x SQLAlchemy versions. BDS cluster node comes with python3.6 and SQLAlchemy-1.4.46 by default.
Si Trino-Ranger-Plugin est activé, assurez-vous d'ajouter l'utilisateur keytab fourni dans les politiques Trino Ranger respectives. Voir Intégration de Trino à Ranger.
Par défaut, Trino utilise le nom principal complet de Kerberos en tant qu'utilisateur. Par conséquent, lors de l'ajout ou de la mise à jour de politiques trino-ranger, vous devez utiliser le nom principal complet de Kerberos comme nom d'utilisateur.
Pour l'exemple de code suivant, utilisez jupyterhub@BDSCLOUDSERVICE.ORACLE.COM comme utilisateur dans les politiques trino-ranger.
Si le plugiciel Trino-Ranger est activé, veillez à ajouter l'utilisateur keytab fourni dans les politiques Trino Ranger respectives. Pour plus de détails, voir Activation de Ranger pour Trino.
Fournissez les autorisations Ranger pour JupyterHub aux politiques suivantes :
-
all - catalog, schema, table, column -
all - function