Ingérer et transformer des données à l'aide d'un flux de données
Un flux de données est un diagramme logique représentant le flux des données provenant des ressources de données sources, telles qu'une base de données ou un fichier plat, vers les ressources de données cibles, telles qu'un lac de données ou un entrepôt de données.
Le flux des données de la source vers la cible peut subir une série de transformations pour agréger, nettoyer et façonner les données. Les experts en ingénierie des données et les développeurs ETC peuvent ensuite analyser ou recueillir des informations et utiliser ces données pour prendre des décisions d'affaires efficaces.
Dans ce tutoriel, vous allez :
- Créer un projet où vous pouvez enregistrer le flux de données.
- Ajouter des opérateurs Source et sélectionner les entités de données à utiliser dans le flux de données.
- Utiliser des opérateurs de mise en forme et appliquer des transformations.
- Identifier la ressource de données cible pour charger les données.
Avant de commencer
Pour ingérer et transformer des données à l'aide d'un flux de données, vous devez disposer des éléments suivants :
- Accès à un espace de travail d'intégration de données. Voir Se connecter au service d'intégration de données.
- Ressources de données sources et cibles créées.
-
Autorisation
PAR_MANAGEactivée pour le seau temporaire.allow any-user to manage buckets in compartment <compartment-name> where ALL {request.principal.type = 'disworkspace', request.principal.id = '<workspace-ocid>', request.permission = 'PAR_MANAGE'}Les bases de données autonomes utilisent le service de stockage d'objets pour stocker temporairement les données et ont besoin de demandes préauthentifiées.
1. Création d'un projet et d'un flux de données
Dans le service d'intégration de données pour Oracle Cloud Infrastructure, les flux de données et les tâches ne peuvent être créés que dans un projet ou un dossier.
Pour créer un projet et un flux de données :
2. Ajout d'opérateurs Source
Vous ajoutez des opérateurs Source pour identifier les entités de données à utiliser pour le flux de données. Dans ce tutoriel, une entité de données représente une table de base de données.
3. Filtrage et transformation des données
L'opérateur Filtrer produit un sous-ensemble des données provenant d'un opérateur en amont en fonction d'une condition.
-
Connectez REVENUE à FILTER_1 :
- Placez le curseur sur REVENUE.
- Faites glisser le cercle de connecteur à côté de REVENUE.

- Déposez le cercle du connecteur sur FILTER_1.

À l'aide de l'explorateur de données, vous pouvez explorer un échantillon de données, vérifier les métadonnées de profilage et appliquer des transformations dans l'onglet Données du panneau Propriétés. Des opérateurs Expression sont ajoutés au canevas pour chaque transformation appliquée.
-
Sélectionnez le menu des transformations (
 ) pour
) pour FILTER_2.CUSTOMERS_JSON.STATE_PROVINCE, puis sélectionnez Changer la casse.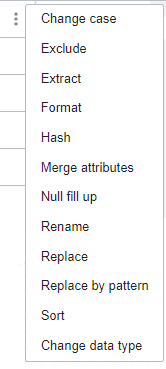
4. Création de jointures de données
Après avoir appliqué des filtres et des transformations, vous pouvez joindre les entités de données sources à l'aide d'un identificateur de client unique, puis charger les données dans une entité de données cible.
5. Ajout d'un opérateur Cible
Ressources supplémentaires
Étape suivante
Après avoir ingéré et transformé des données à l'aide d'un flux de données, créez une tâche d'intégration pour configurer et exécuter le flux de données.