Flux de données
Un flux de données est un programme visuel représentant le flux des données provenant de ressources de données sources, telles qu'une base de données ou un fichier plat, vers des ressources de données cibles, telles qu'un lac de données ou un entrepôt de données.
Les pages suivantes décrivent comment lister, créer et gérer des flux de données dans le service d'intégration de données :
- Liste des flux de données
- Création d'un flux de données
- Utilisation des opérateurs de flux de données
- Utilisation des paramètres de flux de données
- Modification d'un flux de données
- Actualisation des entités d'un flux de données
- Déplacement d'un flux de données
- Duplication d'un flux de données
- Suppression d'un flux de données
- Informations de référence sur les fonctions (flux de données)
Le concepteur d'interface utilisateur intuitive du service d'intégration de données s'ouvre lorsque vous créez, consultez ou modifiez un flux de données.
Voir Concepts de conception pour un aperçu général des concepts de base du concepteur interactif. Vous pouvez également regarder la vidéo interactive sur le concepteur de flux de données du service d'intégration de données pour une présentation pratique des flux de données.
Les pages suivantes décrivent comment exporter et importer un flux de données :
Concepts relatifs à la conception
Les concepts de base suivants sont utiles lors de l'utilisation du concepteur interactif dans le service d'intégration de données.
Un schéma définit la forme des données dans un système source ou cible. Lors de l'utilisation d'un flux de données dans le service d'intégration de données, la dérive de schéma survient lors de la modification des définitions de données.
Par exemple, un attribut peut être ajouté à la source ou en être supprimé, ou un attribut dans la cible peut être renommé. Si vous ne gérez pas la dérive de schéma, les processus d'extraction, transformation et chargement peuvent échouer ou la qualité des données peut perdre.
Par défaut, le service d'intégration de données gère la dérive de schéma pour vous. Lorsque vous configurez un opérateur Source dans le concepteur de flux de données, après avoir sélectionné une entité de données, sélectionnez l'onglet Options avancées du panneau Propriétés. La case Autoriser la dérive de schéma est cochée indique que la dérive de schéma est activée.
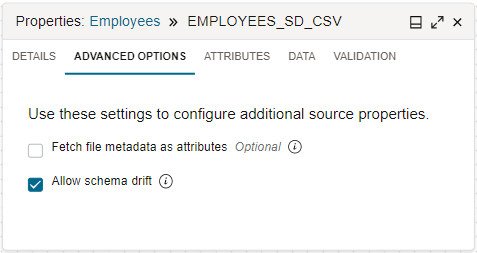
Lorsque la dérivation de schéma est activée, le service d'intégration de données peut détecter les modifications de définition de schéma dans les entités de données spécifiées lors de la conception et de l'exécution du flux. Toutes les modifications sont automatiquement récupérées et le schéma est adapté pour tenir compte des nouveaux attributs, des attributs supprimés, des noms d'attribut modifiés, des types de données modifiés, etc.
Si vous désélectionnez la case Autoriser la dérive de schéma, vous désactivez celle-ci pour verrouiller les définitions de schéma lors de la définition du flux de données. Lorsque la dérive de schéma est désactivée, le service d'intégration de données utilise une forme fixe de l'entité de données spécifiée même lorsque la forme sous-jacente a changé.
Si la dérive de schéma n'est pas gérée, les flux de données peuvent devenir vulnérables aux modifications de source de données en amont. Grâce à la dérive de schéma, les flux de données sont plus résilients et s'adaptent automatiquement à toutes les modifications. Vous n'avez pas besoin de reconcevoir les flux de données lorsqu'une définition de schéma est modifiée.
Pour un fichier JSON, la dérive de schéma est désactivée par défaut et ne peut pas être activée si un schéma personnalisé est utilisé pour déduire la forme de l'entité. Si vous voulez que la dérive de schéma soit disponible et activée, modifiez la source JSON dans le flux de données ou la tâche de chargement de données et décochez la case Utiliser un schéma personnalisé.
Dans le service d'intégration de données, une opération de données dans un flux de données peut être poussée vers un système de données source ou cible pour traitement.
Par exemple, une opération de tri ou de filtrage peut être effectuée dans le système source pendant la lecture des données. Si l'une des sources d'une opération de jointure se trouve dans le même système que la cible, l'opération de données peut être poussée vers le système cible.
Le service d'intégration de données peut utiliser la poussée vers le bas dans un flux de données lorsque vous utilisez des systèmes de données relationnels qui prennent en charge la poussée vers le bas. La liste actuelle comprend les bases de données Oracle, Oracle Autonomous AI Lakehouse, Oracle Autonomous AI Transaction Processing et MySQL.
Par défaut, le service d'intégration de données utilise la poussée vers le bas lorsque cela est nécessaire. Lorsque vous configurez un opérateur Source dans le concepteur de flux de données, après avoir sélectionné une entité de données, sélectionnez l'onglet Options avancées du panneau Propriétés. La case Autoriser la descente est cochée, ce qui indique que la descente est activée.
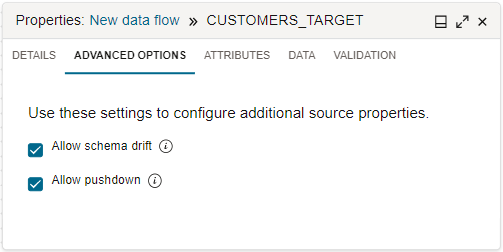
Lorsque la poussée vers le bas est activée, le service d'intégration de données convertit la logique de traitement de données applicable en énoncés SQL qui sont ensuite exécutés directement sur la base de données relationnelle. Avec la poussée du traitement des données vers la base de données, le volume de données extraites et chargées diminue.
Si vous désélectionnez la case Autoriser la poussée vers le bas, vous désactivez la poussée vers le bas. Lorsque la poussée vers le bas est désactivée, le service d'intégration de données extrait toutes les données du système source et les traite sur les grappes Apache Spark affectées à l'espace de travail.
En laissant le service d'intégration de données utiliser la poussée vers le bas, les performances sont améliorées car :
- La puissance de traitement de la base de données est utilisée.
- La quantité de données ingérées pour le traitement est inférieure.
Selon l'optimisation, le service d'intégration de données peut utiliser une poussée vers le bas partielle ou complète dans un flux de données. Une poussée vers le bas partielle est effectuée lorsqu'un système de données relationnel pris en charge est utilisé sur la source ou la cible. Une poussée vers le bas complète est effectuée lorsque les conditions suivantes sont présentes :
- Une seule cible existe dans le flux de données.
- Dans un flux de données avec une seule source, la source et la cible utilisent la même connexion à un système de données relationnel pris en charge.
- Dans un flux de données comportant plusieurs sources, toutes les sources doivent également utiliser la même base de données et la même connexion.
- L'ensemble des opérateurs et des fonctions de transformation du flux de données peuvent générer un code SQL de poussée vers le bas valide.
La préparation des données garantit que les processus d'intégration de données ingèrent des données précises et pertinentes avec moins d'erreurs afin de produire des données de qualité pour en tirer des données clés plus fiables.
La préparation des données consiste notamment à nettoyer et à valider les données afin de limiter les erreurs, ainsi qu'à les transformer et à les enrichir avant de les charger dans les systèmes cibles. Par exemple, les données peuvent provenir de différentes sources avec différents formats et même contenir des informations en double. La préparation des données peut comprendre la suppression des attributs et rangées en double, l'adoption d'un format standard pour tous les attributs de date et le masquage de données sensibles telles que les mots de passe et les données de carte de crédit.
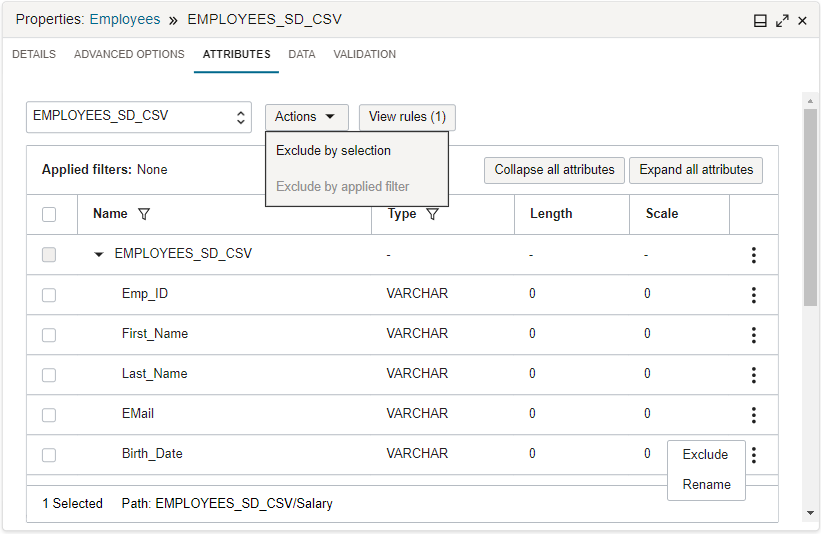
Le service d'intégration de données fournit des opérateurs et des fonctions de mise en forme prêts à l'emploi et des transformations que vous pouvez utiliser dans des outils interactifs pour préparer les données lorsque vous concevez la logique des processus d'ETC. Par exemple, l'onglet Attributs vous permet de rechercher des attributs entrants à l'aide d'un modèle et d'appliquer une règle d'exclusion.
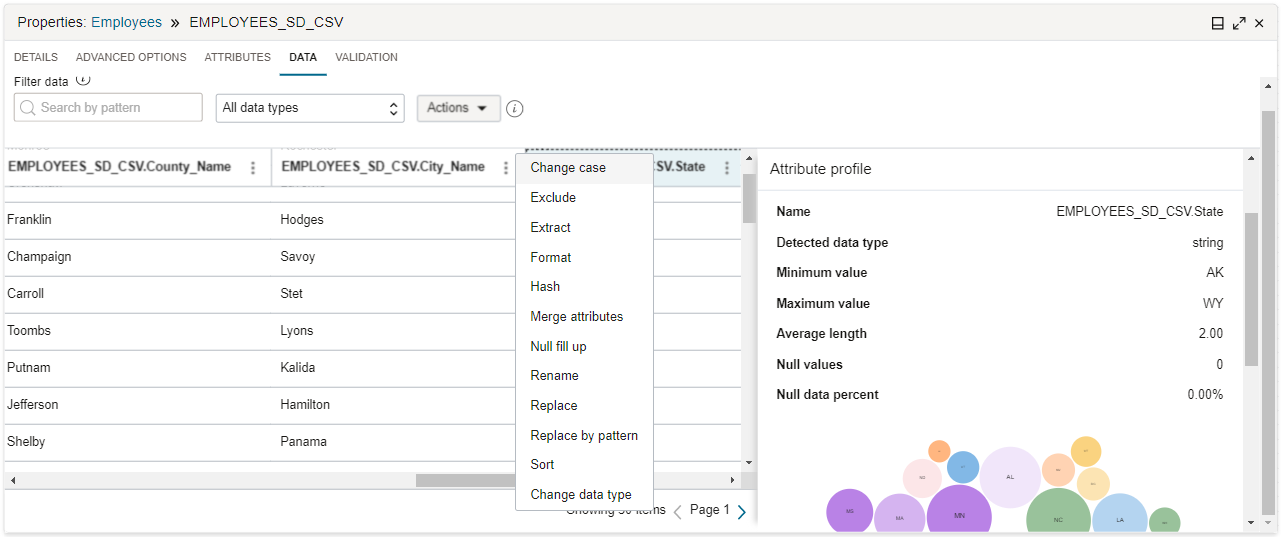
Dans l'onglet Données, vous pouvez appliquer des transformations à un seul attribut ou vous pouvez filtrer les attributs par modèle de nom ou par type de données, puis appliquer des transformations à un groupe d'attributs. Vous pouvez également prévisualiser les résultats des transformations de données dans l'onglet Données, sans avoir à exécuter l'ensemble du flux de données.
Dans le service d'intégration de données, vous utilisez l'onglet Mappage pour décrire le flux de données des attributs sources vers les attributs cibles.
Une cible peut être une entité de données existante ou nouvelle. Dans un flux de données, l'onglet Mappage s'applique uniquement à un opérateur Cible pour une entité de données existante. Pour les entités de données cibles existantes, les attributs sources et tous les attributs personnalisés provenant d'opérations en amont sont mappés aux attributs de la cible.
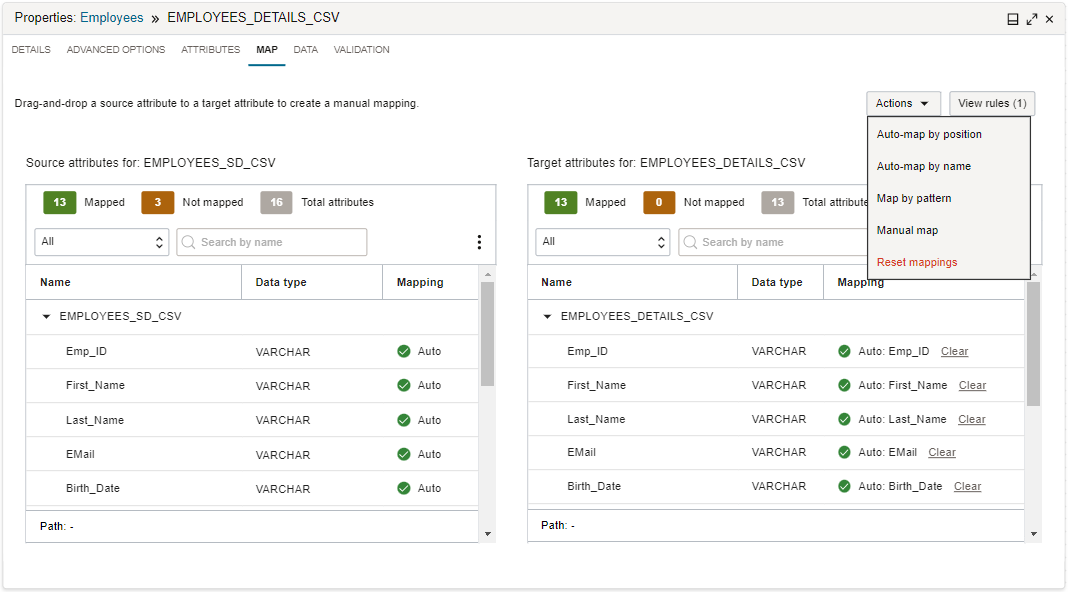
Vous pouvez choisir d'utiliser le mappage automatique ou le mappage manuel. Pour le mappage automatique, le service d'intégration de données peut mapper les attributs entrants aux attributs cibles portant le même nom, ou selon leur position dans les listes d'attributs. Pour un mappage manuel, vous pouvez faire glisser un attribut entrant de la liste source vers un attribut de la liste cible afin de créer un mappage. Vous pouvez également utiliser la boîte de dialogue Mapper un attribut pour créer un mappage en sélectionnant un attribut source et un attribut cible. Vous pouvez également utiliser un modèle d'attribut source et un modèle d'attribut cible pour créer le mappage.
Lorsque vous cochez la case Créer une entité de données pour un opérateur Cible, l'onglet Mappage n'est pas disponible. Le service d'intégration de données utilise les attributs sources entrants pour créer la table ou la structure de fichiers avec un mappage un à un.
Utilisation de l'interface de concepteur
Le concepteur du service d'intégration de données vous permet d'utiliser une interface utilisateur graphique pour créer un flux d'intégration de données.
Vous utilisez aussi un concepteur similaire pour créer un pipeline.
Les principales zones du concepteur sont les suivantes :

Outils pour vous aider à naviguer dans un flux de données ou un pipeline sur le canevas :
- View (Voir) : Sélectionnez ce menu pour ouvrir ou fermer les panneaux Properties (Propriétés), Operators (Opérateurs), Validation (Validation) et Parameters (Paramètres).
- Zoom avant : Vous permet de zoomer sur la conception.
- Zoom arrière : Vous permet d'effectuer un zoom arrière pour en voir plus.
- Réinitialiser le zoom : Retourne à la vue par défaut de la conception.
- Guide de grille : Permet d'activer et de désactiver les guides de grille.
- Disposition automatique : Organise les opérateurs sur le canevas.
- Supprimer : Permet de supprimer l'opérateur sélectionné du canevas.
- Annuler : Supprime la dernière action effectuée.
- Rétablir : Effectue la dernière action si vous aviez sélectionné Annuler.
Vous pouvez annuler et rétablir les types d'action suivants :
- Ajout et suppression d'un opérateur
- Ajout et suppression de connexions entre des opérateurs
- Modification de la position d'un opérateur sur le canevas
Le canevas est la zone de travail principale, où vous concevez le flux de données ou le pipeline.
Faites glisser des objets du panneau Opérateurs vers le canevas pour commencer.
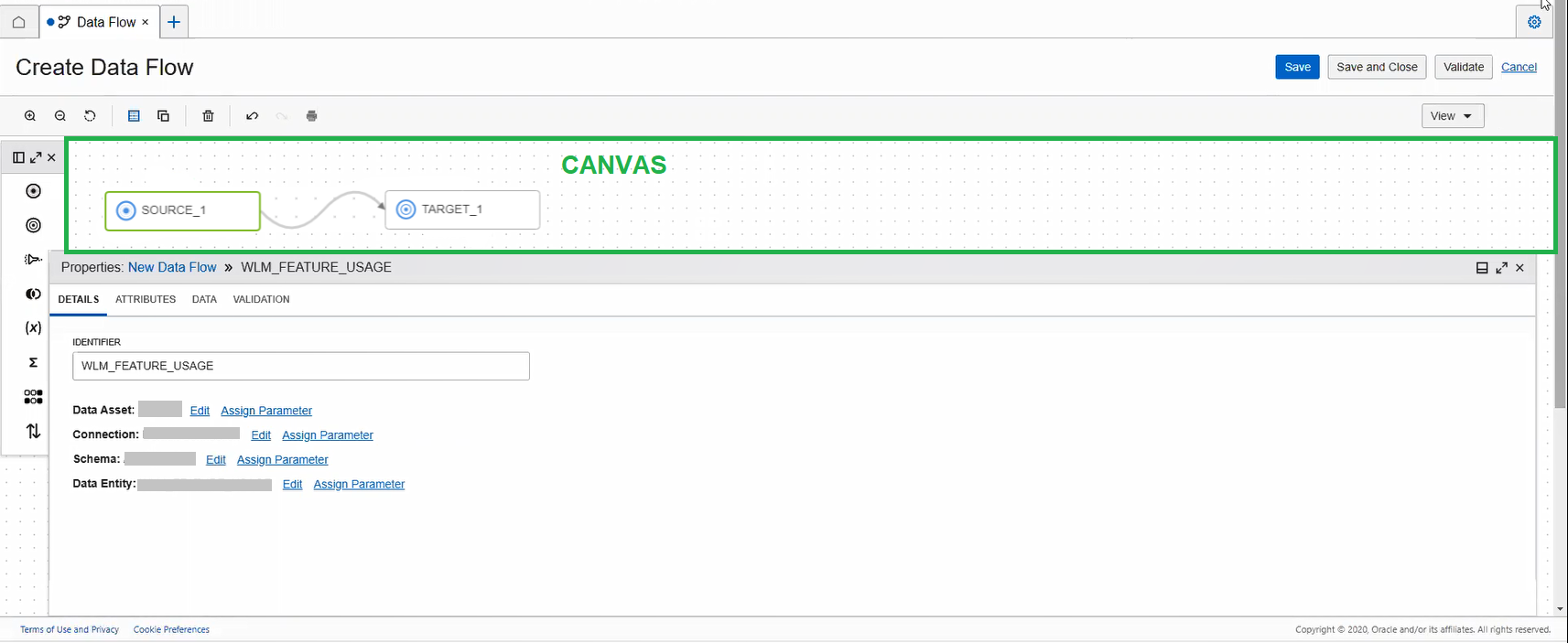
Vous commencez par un canevas vide pour un flux de données. Pour qu'un flux de données soit valide, vous devez définir au moins une source et une cible.
Pour un pipeline, vous commencez par un canevas avec un opérateur Démarrer et un opérateur Fin. La conception de pipeline doit inclure au moins un opérateur de tâche pour être valide.

Pour connecter deux opérateurs, survolez le premier avec le pointeur de la souris jusqu'à ce que le symbole de connexion (petit cercle) apparaisse sur son côté droit. Puis faites glisser le connecteur vers l'opérateur auquel vous souhaitez le connecter. La connexion est valide lorsqu'une ligne relie les deux opérateurs.
Pour insérer un opérateur entre deux opérateurs connectés, cliquez avec le bouton droit de la souris sur la ligne de connexion et utilisez le menu Insérer.
Pour supprimer une connexion, cliquez sur une ligne avec le bouton droit de la souris et sélectionnez Supprimer.
Pour dupliquer un opérateur source, cible ou expression, cliquez avec le bouton droit de la souris sur l'icône de l'opérateur et sélectionnez Dupliquer.
Le panneau Opérateurs affiche les opérateurs que vous pouvez ajouter à un flux de données ou à un pipeline.
Faites glisser des opérateurs du panneau Opérateurs vers le canevas pour concevoir le flux de données ou le pipeline. Chaque opérateur a son propre jeu de propriétés, que vous configurez dans le panneau Propriétés.
Pour un flux de données, vous pouvez ajouter des opérateurs d'entrée, de sortie et de mise en forme.
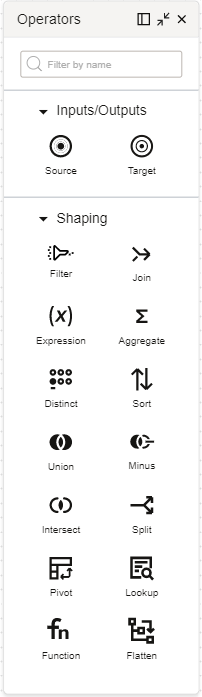
Pour un pipeline, vous ajoutez des opérateurs d'entrée, de sortie et de tâche pour construire une séquence.

À propos des opérateurs
Les opérateurs suivants peuvent être utilisés dans un flux de données :
- Entrées/sorties
-
- Source : Représente une entité de données source qui sert d'entrée dans un flux de données.
- Cible : Représente une entité de données cible qui sert d'entité de sortie pour stocker les données transformées.
- Mise en forme
-
- Filtre : Sélectionne certains attributs du port entrant pour continuer vers l'aval jusqu'au port sortant.
- Jointure : Relie des données provenant de plusieurs sources. Les types de jointures prises en charge sont Interne, Externe droite, Externe gauche et Externe complète.
- Expression : Effectue une transformation sur une seule rangée de données.
- Agréger : Effectue des calculs, tels que la somme ou le comptage, sur un groupe de rangées ou sur toutes les rangées.
- Distinct : Retourne les rangées distinctes avec des valeurs uniques.
- Trier : permet d'effectuer le tri des données en ordre ascendant ou descendant.
- Union : Effectue une opération d'union sur un maximum de 10 opérateurs Source.
- Soustraction : Effectue une opération de soustraction sur deux sources et retourne les rangées présentes dans une source, mais non dans l'autre.
- Insérer : Effectue une opération d'intersection sur deux sources ou plus et retourne les rangées présentes dans les sources connectées.
- Fractionner : Effectue une opération de fractionnement pour diviser une source de données d'entrée en deux ports de sortie ou plus en fonction des conditions de fractionnement.
- Faire pivoter : Effectue une transformation à l'aide d'expressions de fonction d'agrégation et des valeurs d'un attribut spécifié en tant que clé pivot, ce qui produit plusieurs nouveaux attributs dans la sortie.
- Consultation : Effectue une interrogation, puis une transformation à l'aide d'une source d'entrée principale, d'une source d'entrée de consultation et d'une condition de consultation.
- Function: Invokes an Oracle Cloud Infrastructure Oracle Function from within a data flow in Data Integration.
- Aplatir : Permet d'annuler l'analyse d'une structure de fichiers complexe de la racine à l'attribut de type de données hiérarchique que vous sélectionnez.
En savoir plus sur l'utilisation des opérateurs de flux de données.
- Entrées/sorties
-
- Commencer : Représente le début d'un pipeline. Il n'y a qu'un seul opérateur Démarrer dans un pipeline. L'opérateur Démarrer peut avoir des liens vers plus d'une tâche.
- Fin : Représente la fin d'un pipeline. Il n'y a qu'un seul opérateur Fin dans un pipeline. L'opérateur Fin peut avoir des liens à plus d'un noeud amont.
- Expression : Vous permet de créer de nouveaux champs dérivés dans un pipeline, de manière similaire à l'opérateur Expression dans un flux de données.
- Fusion : Effectue une fusion de tâches exécutées en parallèle. La condition de fusion spécifiée détermine comment effectuer les opérations subséquentes en aval.
- Décision : Permet de spécifier un flux de branchement de pipeline à l'aide d'une condition de décision. En fonction des sorties en amont, l'expression de condition spécifiée doit être évaluée à une valeur booléenne, qui détermine le branchement en aval suivant.
- Tâches
-
- Intégration : Se lie à une tâche d'intégration.
- Chargeur de données : Se lie à une tâche de chargement de données.
- Pipeline : Se lie à une tâche de pipeline.
- SQL : Se lie à une tâche SQL.
- Flux de données OCI : Se lie à une application dans Oracle Cloud Infrastructure Data Flow.
- REST : Se lie à une tâche REST.
Utilisation du panneau Opérateurs
Pour travailler plus efficacement, vous pouvez ancrer le panneau Opérateurs à gauche de l'écran. Vous pouvez développer le panneau ou le réduire pour afficher uniquement des icônes, à l'aide de l'icône Développer ou Réduire. Vous pouvez également fermer le panneau. Si le panneau est fermé, vous pouvez l'ouvrir à partir du menu Voir de la barre d'outils du concepteur.
Le panneau Propriétés vous permet de configurer le flux de données ou votre pipeline et ses opérateurs.
Utilisez l'onglet Validation pour valider l'ensemble du flux de données ou du pipeline.
Dans l'onglet Paramètres, vous pouvez voir tous les paramètres définis au niveau du flux de données ou du pipeline, y compris les paramètres générés par le système. Les paramètres définis par l'utilisateur peuvent être supprimés et, s'il y a lieu, leurs valeurs par défaut peuvent être modifiées.
Pour un flux de données, après avoir ajouté un opérateur sur le canevas, sélectionnez l'opérateur et utilisez le panneau Propriétés pour le configurer. Vous pouvez :
- Spécifier les détails de l'opérateur, tels que son identificateur, et configurer ses paramètres dans l'onglet Details (Détails).
- Voir les attributs entrant et sortant de l'opérateur dans l'onglet Attributs.
- Mapper les attributs entrants aux attributs de l'entité de données cible pour un opérateur Cible dans l'onglet Mappage.
- Aperçu d'un échantillon de données dans l'onglet Données.
- Valider la configuration de l'opérateur dans l'onglet Validation.
De même pour un pipeline, après avoir ajouté un opérateur sur le canevas, sélectionnez l'opérateur et utilisez le panneau Propriétés pour le configurer. Vous pouvez :
- Spécifiez un nom pour l'opérateur dans l'onglet Détails. Pour un opérateur Fusion, vous spécifiez une condition de fusion. Pour un opérateur Expression, vous ajoutez une ou plusieurs expressions. Pour les opérateurs de tâche, vous sélectionnez une tâche à lier à l'opérateur, et spécifiez quand la tâche s'exécute en fonction du statut d'exécution de l'opérateur amont.
Pour tous les opérateurs de tâche, vous pouvez sélectionner des tâches de conception à partir de projets dans l'espace de travail courant et des tâches publiées à partir de n'importe quelle application dans l'espace de travail courant. Avec les tâches REST publiées et les tâches de flux de données OCI, vous pouvez également sélectionner une tâche dans n'importe quelle application d'un autre espace de travail du même compartiment ou d'un autre compartiment.
- S'il y a lieu, indiquer les options d'exécution de tâche dans l'onglet Configuration.
- Le cas échéant, configurer les paramètres entrants dans l'onglet Configuration.
- Voir les sorties dans l'onglet Sortie, qui peuvent être utilisées comme entrées pour l'opérateur suivant dans le pipeline.
- Le cas échéant, valider la configuration de l'opérateur dans l'onglet Validation.
Utilisation du panneau Propriétés
Pour travailler plus efficacement, vous pouvez ancrer le panneau Propriétés au bas de l'écran. Vous pouvez développer le panneau ou le réduire à l'aide de l'icône Développer ou Réduire. Vous pouvez également fermer le panneau. Si le panneau est fermé, vous pouvez l'ouvrir à partir du menu Voir de la barre d'outils du concepteur.
En savoir plus sur les onglets du panneau Propriétés
Lorsque vous cliquez dans le canevas et aucun opérateur n'est sélectionné, le panneau Propriétés affiche les détails du flux de données ou du pipeline.
Lorsque vous sélectionnez différents opérateurs sur le canevas, le panneau Propriétés affiche les propriétés de l'opérateur ciblé. Vous pouvez voir, configurer et transformer les données à mesure qu'elles passent par l'opérateur à l'aide des onglets suivants dans le panneau Propriétés :
- Détails
-
Vous pouvez nommer un opérateur à l'aide du champ Identificateur dans l'onglet Détails. Pour les opérateurs Source et Cible, vous pouvez également sélectionner la ressource de données, la connexion, le schéma et l'entité de données. Si vous sélectionnez Autonomous AI Lakehouse ou Autonomous AI Transaction Processing comme ressource de données, l'option de sélection de l'emplacement temporaire est activée. L'emplacement temporaire vous permet de sélectionner le compartiment de stockage d'objets dans lequel placer les données avant qu'elles ne soient déplacées vers la cible.
Vous ne pouvez sélectionner la ressource de données, la connexion, le schéma et l'entité de données que dans l'ordre affiché dans l'onglet Détails. Par exemple, vous ne pouvez sélectionner la connexion qu'après avoir sélectionné la ressource de données. L'option de sélection du schéma est activée seulement après que la connexion a été sélectionnée, et ainsi de suite. Une sélection ne peut être effectuée que suivant la relation parent-enfant héritée de la sélection précédente. Après que vous avez fait une sélection, l'option Modifier est activée.
Vous pouvez affecter des paramètres à différents détails de chaque opérateur afin que ces détails ne soient pas liés au code compilé lorsque vous publiez le flux d'intégration des données. Voir Utilisation de paramètres dans les flux de données et Utilisation de paramètres dans les pipelines.
Pour les opérateurs de mise en forme, vous pouvez créer les conditions ou expressions à appliquer aux données lorsqu'elles passent par l'opérateur.
Pour un pipeline, utilisez l'onglet Détails pour indiquer le nom du pipeline ou de l'opérateur sélectionné. Pour les opérateurs de tâches, vous devez également indiquer la tâche à utiliser.
- Attributs
-
L'onglet Attributs n'apparaît que pour un flux de données.
Dans le menu, sélectionnez cette option pour afficher les attributs d'entrée liés à l'opérateur sur le côté gauche du canevas, ou les attributs de sortie passés à l'opérateur suivant qui lui est lié sur le côté droit.
Sélectionnez l'icône de filtre dans la colonne Nom pour afficher le champ de filtre. Entrez un modèle regex simple ou des caractères génériques (tels que
?et*) dans le champ Filtre pour filtrer les attributs par modèle de nom. Le champ est insensible à la casse. Sélectionnez l'icône de filtre dans la colonne Type pour afficher le menu de types. Utilisez le menu pour sélectionner le filtre de type. Vous ne pouvez appliquer qu'un seul filtre de modèle de nom à la fois, mais pouvez appliquer plusieurs filtres de type. Par exemple, pour filtrer sur le modèle de nom *_CODE et sur le type numeric ou varchar, appliquez un filtre de modèle de nom (*_CODE) et deux filtres de type (numeric, varchar).Vous pouvez ensuite sélectionner des attributs à exclure ou sélectionner pour exclusion les attributs résultant des filtres appliqués. Utilisez le menu Actions pour exclure par une sélection ou selon les filtres appliqués. Les règles d'exclusion sélectionnées sont ajoutées au panneau Règles. Les filtres appliqués apparaissent en haut de la liste des attributs. Utilisez l'option Clear All (Tout effacer) pour réinitialiser les filtres appliqués.
Sélectionnez Voir les règles pour ouvrir le panneau règles et voir toutes les règles appliquées à l'entité de données. Vous pouvez également voir les règles à partir du message de réussite qui apparaît dans le coin supérieur droit après l'application des règles. Par défaut, la première règle du panneau Règles inclut tout. Vous pouvez également appliquer des actions à chaque règle, comme la reclasser dans la liste ou la supprimer.
- Mappage
-
L'onglet Mappage n'apparaît que pour un flux de données.
Cet onglet n'apparaît que pour un opérateur Cible. Il vous permet de mapper les attributs entrants aux attributs de l'entité de données cible, par position, nom, modèle ou mappage direct. Vous pouvez également utiliser le mappage automatique par nom ou supprimer les mappages.
- Données
-
L'onglet Données n'apparaît que pour un flux de données.
Accédez à l'onglet Données pour prévisualiser un échantillon de données afin de voir comment une règle de transformation affecte les données lorsqu'elles passent par l'opérateur.
Note
Assurez-vous que la ressource de données, la connexion, le schéma et l'entité de données sont configurés avant d'accéder à l'onglet Données.Vous pouvez filtrer les données par modèle de nom ou par type de données, et appliquer une règle d'exclusion aux données filtrées ou effectuer des transformations en masse à l'aide du menu Actions. Pour filtrer les données par modèle de nom, entrez un modèle rationnel simple avec des caractères génériques (tels que
?et*) dans le champ Rechercher par modèle. Pour filtrer les données par type de données, sélectionnez le type voulu dans le menu. Les transformations ne peuvent pas être appliquées pour un opérateur Cible, car les données sont en lecture seule.Lorsque vous ajoutez et supprimez des règles et des transformations, l'échantillonnage des données est mis à jour pour refléter ces changements. En savoir plus sur les transformations de données.
- Configuration
-
L'onglet Configuration s'affiche uniquement pour un pipeline. Si une tâche est disponible, vous pouvez reconfigurer les valeurs de paramètre associées à la tâche ou au flux de données sous-jacent, le cas échéant.
- Sortie
-
L'onglet Sortie s'affiche uniquement pour un pipeline.
Vous pouvez consulter la liste des sorties pouvant être utilisées comme entrées pour les opérateurs connectés dans le pipeline.
- Validation
- Utilisez l'onglet Validation pour vérifier que l'opérateur a été configuré correctement, afin d'éviter des erreurs plus tard lorsque vous exécutez le flux de données ou le pipeline. Par exemple, si vous oubliez d'affecter des opérateurs entrants ou sortants, des messages d'avertissement apparaissent dans le panneau Validation. Lorsque vous sélectionnez un message dans le panneau Validation, il cible cet opérateur pour que vous corrigiez l'erreur.
Le panneau Paramètres affiche les paramètres utilisés dans un flux de données ou un pipeline.
Vous pouvez également supprimer un paramètre du panneau Paramètres.
Vous pouvez afficher tous les messages d'erreur et d'avertissement pour un flux de données ou un pipeline dans le panneau Validation globale.
Dans la barre d'outils du canevas, sélectionnez Valider pour vérifier et déboguer le flux de données avant d'utiliser le flux de données dans une tâche d'intégration. De même, vérifiez et déboguez le pipeline avant de l'utiliser dans une tâche de pipeline. Le panneau Validation globale s'ouvre et affiche des messages d'erreur et d'avertissement à vérifier. La sélection d'un message vous amène à l'opérateur qui a produit le message d'erreur ou d'avertissement.