Note :
- Ce tutoriel nécessite l'accès à Oracle Cloud. Pour vous inscrire à un compte gratuit, voir Introduction à l' niveau gratuit d'Oracle Cloud Infrastructure.
- Il utilise des exemples de valeurs pour les données d'identification, la location et les compartiments Oracle Cloud Infrastructure. À la fin de votre laboratoire, remplacez ces valeurs par celles propres à votre environnement en nuage.
Exécuter le modèle LLM Mistral sur l'instance de calcul A10 pour OCI avec le gestionnaire de ressources Oracle à l'aide d'un déploiement en un clic
Présentation
Le service de calcul d'Oracle Cloud Infrastructure (OCI) vous permet de créer différents types de forme pour tester les modèles d'unité de traitement graphique pour l'intelligence artificielle (IA) déployés localement. Dans ce tutoriel, nous utiliserons la forme A10 avec des ressources de VCN et de sous-réseau préexistantes que vous pouvez sélectionner dans le gestionnaire de ressources Oracle.
Le code Terraform inclut également la configuration de l'instance pour exécuter un ou plusieurs modèles Mistral Virtual Large Language Model (vLLM) local pour les tâches de traitement du langage naturel.
Objectifs
- Créez une forme A10 sur le service de calcul OCI, téléchargez le modèle LLM d'intelligence artificielle Mistral et interrogez le modèle vLLM local.
Préalables
-
Assurez-vous de disposer d'un réseau en nuage virtuel (VCN) OCI et d'un sous-réseau où la machine virtuelle sera déployée.
-
Comprendre les composants du réseau et leurs relations. Pour plus d'informations, voir Aperçu du service de réseau.
-
Compréhension du réseautage dans le nuage. Pour plus d'informations, regardez la vidéo suivante : Vidéo sur le service de réseau dans le nuage EP.01 : Réseaux en nuage virtuels.
-
Conditions :
- Type d'instance : Forme A10 avec un GPU Nvidia.
- Système d'exploitation : Oracle Linux.
- Sélection d'image : Le script de déploiement sélectionne la dernière image Oracle Linux avec prise en charge des processeurs graphiques.
- Marqueurs : Ajoute un marqueur à structure libre GPU_TAG = "A10-1".
- Taille du volume de démarrage : 250 Go.
- Initialisation : Utilise cloud-init pour télécharger et configurer les modèles Mistral vLLM.
Tâche 1 : Télécharger le code Terraform pour un déploiement en un clic
Téléchargez le code Terraform ORM à partir d'ici : orm_stack_a10_gpu-main.zip, pour mettre en oeuvre les modèles vLLM Mistral localement, ce qui vous permettra de sélectionner un VCN existant et un sous-réseau pour tester le déploiement local des modèles vLLM Mistral dans une forme d'instance A10.
Une fois le code Terraform ORM téléchargé localement, procédez comme suit : Création d'une pile à partir d'un dossier pour charger la pile et exécuter l'application du code Terraform.
Note : Assurez-vous d'avoir créé un réseau en nuage virtuel (VCN) OCI et un sous-réseau où la machine virtuelle sera déployée.
Tâche 2 : Créer un VCN sur OCI (facultatif s'il n'est pas déjà créé)
Pour créer un VCN dans Oracle Cloud Infrastructure, voir : Vidéo expliquant comment créer un réseau en nuage virtuel sur OCI.
ou
Pour créer un VCN, procédez de la façon suivante :
-
Connectez-vous à la console OCI, entrez Nom du locataire en nuage, Nom d'utilisateur et Mot de passe.
-
Cliquez sur le menu hamburger (≡) dans le coin supérieur gauche.
-
Allez à Réseau, Réseaux en nuage virtuels et sélectionnez le compartiment approprié dans la section Portée de la liste.
-
Sélectionnez VCN avec connectivité Internet, et cliquez sur Démarrer l'Assistant VCN.
-
Dans la page Créer un VCN avec connectivité Internet, entrez les informations suivantes et cliquez sur Suivant.
- NOM du VCN : Entrez
OCI_HOL_VCN. - COMPARTMENT : Sélectionnez le compartiment approprié.
- BLOCK CIDR du VCN : Entrez
10.0.0.0/16. - Blocs CIDR de sous-réseau PUBLIC : Entrez
10.0.2.0/24. - Bloc CIDR de sous-réseau privé : Entrez
10.0.1.0/24. - Résolution DNS : Sélectionnez Utiliser les HOSTNAMES DNS dans ce VCN.
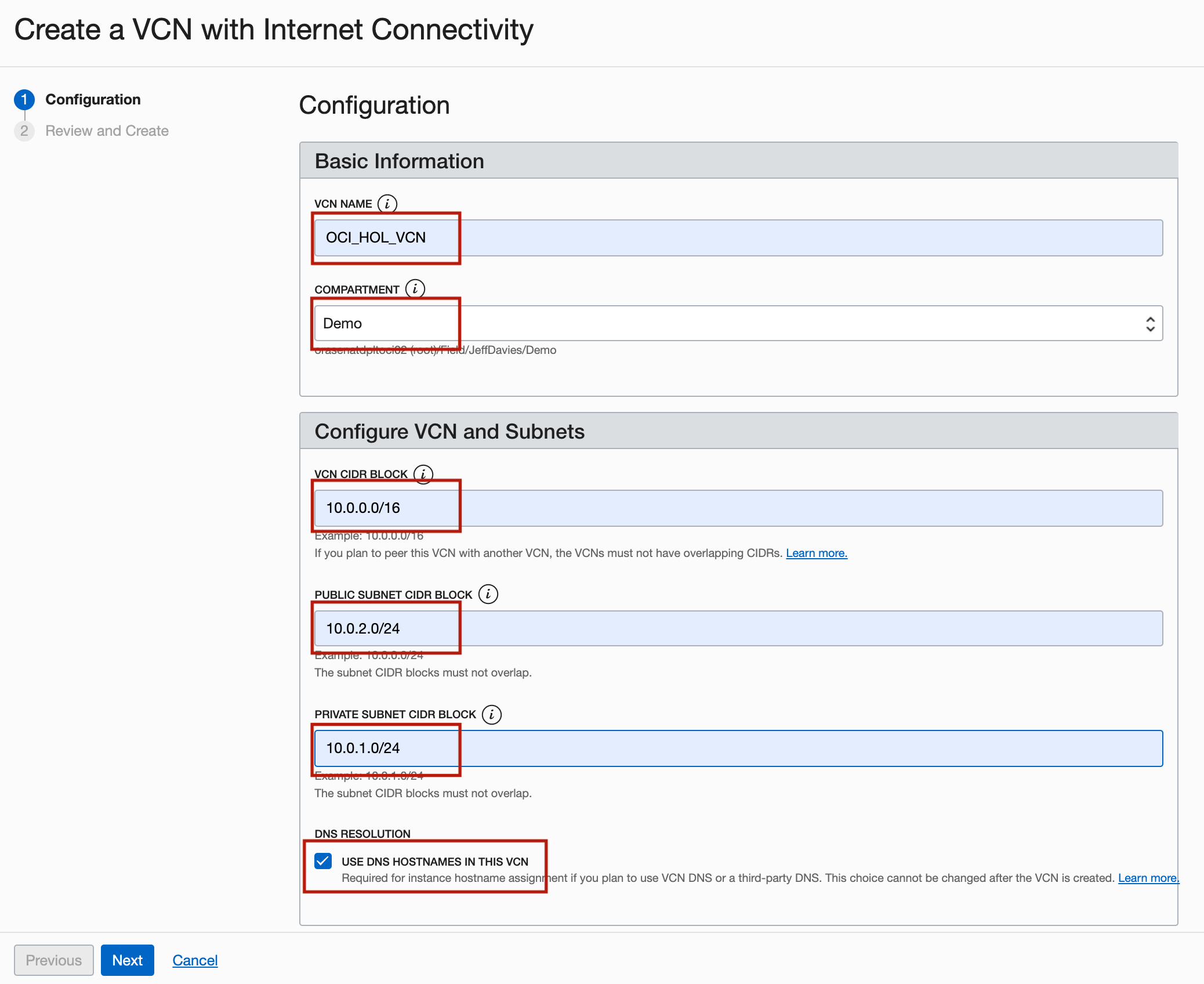
- NOM du VCN : Entrez
-
Dans la page Vérifier, vérifiez vos paramètres et cliquez sur Créer.
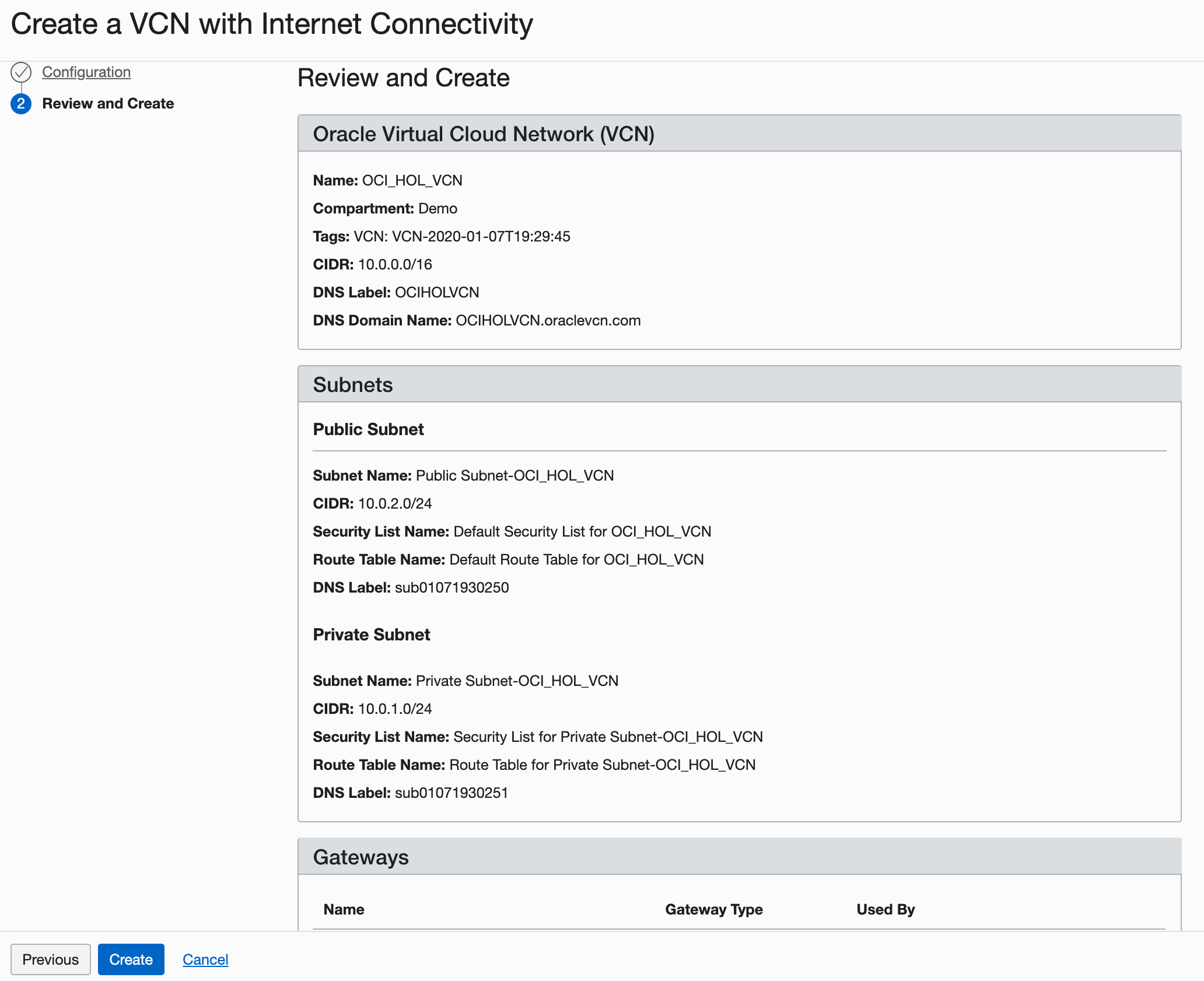
Description de l'illustration setupVCN4.png
La création du VCN prendra un moment et un écran de progression vous tiendra informé du flux de travail.

-
Une fois le VCN créé, cliquez sur Voir le réseau en nuage virtuel.
Dans le monde réel, vous allez créer plusieurs réseaux en nuage virtuels en fonction de leur besoin d'accès (les ports à ouvrir) et de ceux auxquels ils peuvent accéder.
Tâche 3 : Voir les détails de la configuration cloud-init
Le script cloud-init installe toutes les dépendances nécessaires, démarre Docker, télécharge et démarre les modèles Mistral vLLM. Vous pouvez trouver le code suivant dans le fichier cloudinit.sh téléchargé dans la tâche 1.
dnf install -y dnf-utils zip unzip
dnf config-manager --add-repo=https://download.docker.com/linux/centos/docker-ce.repo
dnf remove -y runc
dnf install -y docker-ce --nobest
systemctl enable docker.service
dnf install -y nvidia-container-toolkit
systemctl start docker.service
...
Cloud-init téléchargera tous les fichiers nécessaires à l'exécution du modèle Mistral en fonction de votre jeton d'API prédéfini dans Hugging Face.
La création de jeton d'API sélectionnera le modèle Mistral en fonction de votre entrée de l'interface utilisateur ORM, ce qui permettra l'authentification nécessaire pour télécharger les fichiers de modèle localement. Pour plus d'informations, voir Jetons d'accès d'utilisateur.
Tâche 4 : Surveiller le système
Suivez l'achèvement du script cloud-init et l'utilisation des ressources GPU avec les commandes suivantes (si nécessaire).
-
Surveiller l'achèvement d'init en nuage :
tail -f /var/log/cloud-init-output.log. -
Surveillez l'utilisation des GPU :
nvidia-smi dmon -s mu -c 100. -
Déployer et interagir avec le modèle vLLM Mistral à l'aide de Python : (Modifiez les paramètres uniquement si nécessaire (la commande est déjà incluse dans le script
cloud-init) :python -O -u -m vllm.entrypoints.openai.api_server \ --host 0.0.0.0 \ --model "/home/opc/models/${MODEL}" \ --tokenizer hf-internal-testing/llama-tokenizer \ --max-model-len 16384 \ --enforce-eager \ --gpu-memory-utilization 0.8 \ --max-num-seqs 2 \ >> "${MODEL}.log" 2>&1 &
Tâche 5 : Tester l'intégration du modèle
Interagissez avec le modèle des façons suivantes à l'aide des commandes ou des détails du carnet Jupyter.
-
Testez le modèle à partir de l'interface de ligne de commande une fois le script
cloud-initterminé.curl -X 'POST' 'http://0.0.0.0:8000/v1/chat/completions' \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -d '{ "model": "/home/opc/models/'"$MODEL"'", "messages": [{"role":"user", "content":"Write a small poem."}], "max_tokens": 64 }' -
Testez le modèle à partir du carnet Jupyter (Assurez-vous d'ouvrir le port
8888).import requests import json import os # Retrieve the MODEL environment variable model = os.environ.get('MODEL') url = 'http://0.0.0.0:8000/v1/chat/completions' headers = { 'accept': 'application/json', 'Content-Type': 'application/json', } data = { "model": f"/home/opc/models/{model}", "messages": [{"role": "user", "content": "Write a short conclusion."}], "max_tokens": 64 } response = requests.post(url, headers=headers, json=data) if response.status_code == 200: result = response.json() # Pretty print the response for better readability formatted_response = json.dumps(result, indent=4) print("Response:", formatted_response) else: print("Request failed with status code:", response.status_code) print("Response:", response.text) -
Intégrer Gradio à l'agent conversationnel pour interroger le modèle.
import requests import gradio as gr import os def interact_with_model(prompt): model = os.getenv("MODEL") # Retrieve the MODEL environment variable within the function url = 'http://0.0.0.0:8000/v1/chat/completions' headers = { 'accept': 'application/json', 'Content-Type': 'application/json', } data = { "model": f"/home/opc/models/{model}", "messages": [{"role": "user", "content": prompt}], "max_tokens": 64 } response = requests.post(url, headers=headers, json=data) if response.status_code == 200: result = response.json() completion_text = result["choices"][0]["message"]["content"].strip() # Extract the generated text return completion_text else: return {"error": f"Request failed with status code {response.status_code}"} # Example Gradio interface iface = gr.Interface( fn=interact_with_model, inputs=gr.Textbox(lines=2, placeholder="Write a prompt..."), outputs=gr.Textbox(type="text", placeholder="Response..."), title="Mistral 7B Chat Interface", description="Interact with the Mistral 7B model deployed locally via Gradio.", live=True ) # Launch the Gradio interface iface.launch(share=True)
Tâche 6 : Déployer le modèle à l'aide de Docker (si nécessaire)
Vous pouvez également déployer le modèle à l'aide de Docker et d'une source externe.
docker run --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--env "HUGGING_FACE_HUB_TOKEN=$ACCESS_TOKEN" \
-p 8000:8000 \
--ipc=host \
--restart always \
vllm/vllm-openai:latest \
--model mistralai/$MODEL \
--max-model-len 16384
Vous pouvez interroger le modèle de l'une des façons suivantes :
-
Interrogez le modèle démarré avec Docker et une source externe à l'aide de l'interface de ligne de commande.
curl -X 'POST' 'http://0.0.0.0:8000/v1/chat/completions' \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -d '{ "model": "mistralai/'"$MODEL"'", "messages": [{"role": "user", "content": "Write a small poem."}], "max_tokens": 64 }' -
Interrogez le modèle avec Docker à partir d'une source externe à l'aide du carnet Jupyter.
import requests import json import os # Retrieve the MODEL environment variable model = os.environ.get('MODEL') url = 'http://0.0.0.0:8000/v1/chat/completions' headers = { 'accept': 'application/json', 'Content-Type': 'application/json', } data = { "model": f"mistralai/{model}", "messages": [{"role": "user", "content": "Write a short conclusion."}], "max_tokens": 64 } response = requests.post(url, headers=headers, json=data) if response.status_code == 200: result = response.json() # Pretty print the response for better readability formatted_response = json.dumps(result, indent=4) print("Response:", formatted_response) else: print("Request failed with status code:", response.status_code) print("Response:", response.text) -
Interrogez le modèle avec Docker à partir d'une source externe à l'aide du carnet Jupyter et de l'agent conversationnel Gradio.
import requests import gradio as gr import os # Function to interact with the model via API def interact_with_model(prompt): url = 'http://0.0.0.0:8000/v1/chat/completions' headers = { "accept": "application/json", "Content-Type": "application/json", } # Retrieve the MODEL environment variable model = os.environ.get('MODEL') data = { "model": f"mistralai/{model}", "messages": [{"role": "user", "content": prompt}], "max_tokens": 64 } response = requests.post(url, headers=headers, json=data) if response.status_code == 200: result = response.json() completion_text = result["choices"][0]["message"]["content"].strip() # Extract the generated text return completion_text else: return {"error": f"Request failed with status code {response.status_code}"} # Example Gradio interface iface = gr.Interface( fn=interact_with_model, inputs=gr.Textbox(lines=2, placeholder="Write a prompt..."), outputs=gr.Textbox(type="text", placeholder="Response..."), title="Model Interface", # Set a title for your Gradio interface description="Interact with the model deployed via Gradio.", # Set a description live=True ) # Launch the Gradio interface iface.launch(share=True) -
Modèle exécuté avec docker à l'aide des fichiers locaux déjà téléchargés (commence plus rapidement).
docker run --gpus all \ -v /home/opc/models/$MODEL/:/mnt/model/ \ --env "HUGGING_FACE_HUB_TOKEN=$TOKEN_ACCESS" \ -p 8000:8000 \ --env "TRANSFORMERS_OFFLINE=1" \ --env "HF_DATASET_OFFLINE=1" \ --ipc=host vllm/vllm-openai:latest \ --model="/mnt/model/" \ --max-model-len 16384 \ --tensor-parallel-size 2 -
Interrogez le modèle avec Docker à l'aide des fichiers locaux et de l'interface de ligne de commande.
curl -X 'POST' 'http://0.0.0.0:8000/v1/chat/completions' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{ > "model": "/mnt/model/", > "messages": [{"role": "user", "content": "Write a humorous limerick about the wonders of GPU computing."}], > "max_tokens": 64, > "temperature": 0.7, > "top_p": 0.9 > }' -
Interrogez le modèle avec Docker à l'aide des fichiers locaux et du carnet Jupyter.
import requests import json import os url = "http://0.0.0.0:8000/v1/chat/completions" headers = { "accept": "application/json", "Content-Type": "application/json", } # Assuming `MODEL` is an environment variable set appropriately model = f"/mnt/model/" # Adjust this based on your specific model path or name data = { "model": model, "messages": [{"role": "user", "content": "Write a humorous limerick about the wonders of GPU computing."}], "max_tokens": 64, "temperature": 0.7, "top_p": 0.9 } response = requests.post(url, headers=headers, json=data) if response.status_code == 200: result = response.json() # Extract the generated text from the response completion_text = result["choices"][0]["message"]["content"].strip() print("Generated Text:", completion_text) else: print("Request failed with status code:", response.status_code) print("Response:", response.text) -
Interrogez le modèle avec Docker à partir d'une source externe à l'aide du carnet Jupyter et de l'agent conversationnel Gradio.
import requests import gradio as gr import os # Function to interact with the model via API def interact_with_model(prompt): url = 'http://0.0.0.0:8000/v1/chat/completions' # Update the URL to match the correct endpoint headers = { "accept": "application/json", "Content-Type": "application/json", } # Assuming `MODEL` is an environment variable set appropriately model = "/mnt/model/" # Adjust this based on your specific model path or name data = { "model": model, "messages": [{"role": "user", "content": prompt}], "max_tokens": 64, "temperature": 0.7, "top_p": 0.9 } response = requests.post(url, headers=headers, json=data) if response.status_code == 200: result = response.json() completion_text = result["choices"][0]["message"]["content"].strip() return completion_text else: return {"error": f"Request failed with status code {response.status_code}"} # Example Gradio interface iface = gr.Interface( fn=interact_with_model, inputs=gr.Textbox(lines=2, placeholder="Write a humorous limerick about the wonders of GPU computing."), outputs=gr.Textbox(type="text", placeholder="Response..."), title="Model Interface", # Set your desired title here description="Interact with the model deployed locally via Gradio.", live=True ) # Launch the Gradio interface iface.launch(share=True)Note : Commandes de pare-feu pour ouvrir le port
8888pour le carnet Jupyter.sudo firewall-cmd --zone=public --permanent --add-port 8888/tcp sudo firewall-cmd --reload sudo firewall-cmd --list-all
Confirmation
-
Auteur - Bogdan Bazarca (ingénieur en nuage principal)
-
Contributeurs - Équipe Oracle NACI-AI-CN-DEV
Autres ressources d'apprentissage
Explorez d'autres laboratoires sur la page docs.oracle.com/learn ou accédez à plus de contenu d'apprentissage gratuit sur le canal YouTube d'Oracle Learning. De plus, visitez education.oracle.com/learning-explorer pour devenir un explorateur Oracle Learning.
Pour obtenir de la documentation sur le produit, visitez Oracle Help Center.
Run Mistral LLM Model on OCI Compute A10 Instance with Oracle Resource Manager using One Click Deployment
G11813-01
July 2024