Utilisation de JupyterHub dans Big Data Service 3.0.27 ou version ultérieure
Utilisez JupyterHub pour gérer les blocs-notes ODH 2.x de Big Data Service 3.0.27 ou version ultérieure pour des groupes d'utilisateurs.
Prérequis
Accès à JupyterHub
- Accédez à Apache Ambari.
- Dans la barre d'outils latérale, sous Services, sélectionnez JupyterHub.
Gérer JupyterHub
Un utilisateur JupyterHub admin peut effectuer les tâches suivantes pour gérer les blocs-notes dans JupyterHub sur les noeuds ODH 2.x Big Data Service 3.0.27 ou versions ultérieures.
Pour gérer les services Oracle Linux 7 à l'aide de la commande systemctl, reportez-vous à Utilisation des services système.
Pour vous connecter à une instance Oracle Cloud Infrastructure, reportez-vous à Connexion à votre instance.
En tant qu'administrateur, vous pouvez arrêter ou désactiver JupyterHub pour ne pas consommer de ressources, comme la mémoire. Le redémarrage peut également aider à résoudre des problèmes ou des comportements inattendus.
Arrêtez ou démarrez JupyterHub via Ambari pour les clusters Big Data Service 3.0.27 ou versions ultérieures.
En tant qu'administrateur, vous pouvez ajouter le serveur JupyterHub à un noeud Big Data Service.
Cette option est disponible pour les clusters Big Data Service 3.0.27 ou versions ultérieures.
- Accédez à Apache Ambari.
- Dans la barre d'outils latérale, sélectionnez Hôtes.
- Pour ajouter le serveur JupyterHub, sélectionnez un hôte sur lequel JupyterHub n'est pas installé.
- Sélectionnez Ajouter.
- Sélectionnez JupyterHub Server.
En tant qu'administrateur, vous pouvez déplacer le serveur JupyterHub vers un autre noeud Big Data Service.
Cette option est disponible pour les clusters Big Data Service 3.0.27 ou versions ultérieures.
- Accédez à Apache Ambari.
- Dans la barre d'outils latérale, sous Services, sélectionnez JupyterHub.
- Sélectionnez Actions, puis Déplacer le serveur JupyterHub.
- Sélectionnez Suivant.
- Sélectionnez l'hôte vers lequel déplacer le serveur JupyterHub.
- Terminez l'assistant de déplacement.
En tant qu'administrateur, vous pouvez exécuter des vérifications de service/d'état JupyterHub via Ambari.
Cette option est disponible pour les clusters Big Data Service 3.0.27 ou versions ultérieures.
- Accédez à Apache Ambari.
- Dans la barre d'outils latérale, sous Services, sélectionnez JupyterHub.
- Sélectionnez Actions, puis Exécuter la vérification de service.
Gestion des utilisateurs et des droits d'accès
Utilisez l'une des deux méthodes d'authentification pour authentifier les utilisateurs auprès de JupyterHub afin qu'ils puissent créer des blocs-notes et, éventuellement, administrer JupyterHub sur des clusters ODH 2.x Big Data Service 3.0.27 ou versions ultérieures.
Les utilisateurs JupyterHub doivent être ajoutés en tant qu'utilisateurs de système d'exploitation sur tous les noeuds de cluster Big Data Service pour les clusters Big Data Service non Active Directory (AD), où les utilisateurs ne sont pas automatiquement synchronisés sur tous les noeuds de cluster. Les administrateurs peuvent utiliser le script de gestion des utilisateurs JupyterHub pour ajouter des utilisateurs et des groupes avant de se connecter à JupyterHub.
Prérequis
Avant d'accéder à JupyterHub, procédez comme suit :
- Connectez-vous via SSH au noeud sur lequel JupyterHub est installé.
- Accédez à
/usr/odh/current/jupyterhub/install. - Pour fournir les détails de tous les utilisateurs et groupes dans le fichier
sample_user_groups.json, exécutez la commande suivante :sudo python3 UserGroupManager.py sample_user_groups.json Verify user creation by executing the following command: id <any-user-name>
Types d'authentification pris en charge
- NativeAuthenticator : cet authentificateur est utilisé pour les applications JupyterHub de petite ou moyenne taille. L'inscription et l'authentification sont implémentées comme natives dans JupyterHub sans dépendre de services externes.
-
SSOAuthenticator : cet authentificateur fournit une sous-classe de
jupyterhub.auth.Authenticatorqui agit en tant que fournisseur de services SAML2. Orientez-le vers un fournisseur d'identités SAML2 configuré de façon appropriée et activez l'accès avec connexion unique pour JupyterHub.
L'authentification native dépend de la base de données utilisateur JupyterHub pour l'authentification des utilisateurs.
L'authentification native s'applique aux clusters qu'ils soient hautement disponibles ou non. Pour plus d'informations sur l'authentificateur natif, reportez-vous à Authentificateur natif.
Ces prérequis doivent être respectés pour autoriser un utilisateur dans un cluster hautement disponible Big Data Service à l'aide de l'authentification native.
Ces prérequis doivent être respectés pour autoriser un utilisateur dans un cluster Big Data Service non hautement disponible à l'aide de l'authentification native.
Les administrateurs sont responsables de la configuration et la gestion de JupyterHub. Les administrateurs sont également chargés de l'autorisation des utilisateurs nouvellement inscrits sur JupyterHub.
Avant l'ajout d'un administrateur, les prérequis doivent être respectés pour un cluster non hautement disponible.
- Accédez à Apache Ambari.
- Dans la barre d'outils latérale, sous Services, sélectionnez JupyterHub.
- Sélectionnez Configurations, puis Configurations avancées.
- Sélectionnez Advanced jupyterhub-config.
-
Ajoutez un administrateur à
c.Authenticator.admin_users. - Sélectionnez Save (Enregistrer).
Avant d'ajouter d'autres utilisateurs, les prérequis doivent être respectés pour un cluster Big Data Service.
-
L'administrateur doit se connecter à JupyterHub et, à partir de la nouvelle option de menu permettant d'autoriser les utilisateurs connectés, autoriser le nouvel utilisateur.
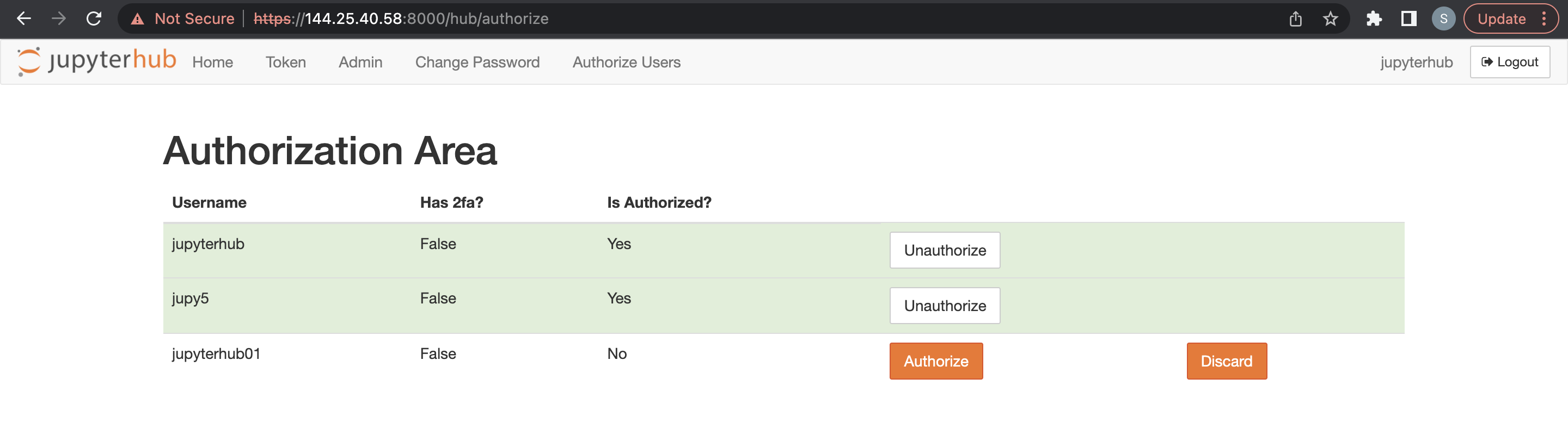
Un administrateur peut supprimer des utilisateurs JupyterHub.
- Accédez à JupyterHub.
- Ouvrez Fichier > HubControlPanel.
- Accédez à la page Autoriser des utilisateurs.
- Supprimez les utilisateurs voulus.
Vous pouvez utiliser l'authentification LDAP via Ambari pour les clusters ODH 2.x Big Data Service 3.0.27 ou versions ultérieures.
Utilisation de l'authentification LDAP à l'aide d'Ambari
Pour utiliser l'authentification LDAP, vous devez mettre à jour le fichier de configuration JupyterHub avec les détails de connexion LDAP.
Utilisez Ambari pour l'authentification LDAP sur les clusters Big Data Service 3.0.27 ou versions ultérieures.
Pour plus d'informations sur l'authentificateur LDAP, reportez-vous à Authentificateur LDAP.
pConfigure Authentification SSO dans Big Data Service 3.0.27 ou version ultérieure du service ODH 2.x JupyterHub.
Vous pouvez utiliser le domaine d'identité Oracle pour configurer l'authentification SSO dans les clusters ODH 2.x JupyterHub Big Data Service 3.0.27 ou versions ultérieures.
Vous pouvez utiliser OKTA pour configurer l'authentification SSO dans des clusters ODH 2.x JupyterHub Big Data Service 3.0.27 ou versions ultérieures.
En tant qu'administrateur, vous pouvez gérer les configurations JupyterHub via Ambari pour les clusters ODH 2.x 3.0.27 ou versions ultérieures de Big Data Service.
Génération dynamique de blocs-notes
Les configurations Spawner suivantes sont prises en charge sur les clusters Big Data Service 3.0.27 et versions ultérieures ODH 2.x.
Renseignez les champs suivants :
- Authentification native :
- Se connecter à l'aide des informations d'identification utilisateur connectées
- Entrer le nom utilisateur.
- Entrer le mot de passe.
- Utilisation de SamlSSOAuthenticator :
- Connectez-vous avec la connexion SSO.
- Terminez la connexion avec l'application SSO configurée.
Génération dynamique de blocs-notes sur un cluster hautement disponible
Pour le cluster intégré AD :
- Connectez-vous à l'aide de l'une des méthodes précédentes. L'autorisation fonctionne uniquement si l'utilisateur est présent sur l'hôte Linux. JupyterHub recherche l'utilisateur sur l'hôte Linux pendant la tentative de génération dynamique du serveur de bloc-notes.
- Vous êtes redirigé vers une page Options de serveur sur laquelle vous devez demander un ticket Kerberos. Ce ticket peut être demandé à l'aide du principal Kerberos et du fichier keytab, ou du mot de passe Kerberos. L'administrateur de cluster peut fournir le principal Kerberos et le fichier keytab, ou le mot de passe Kerberos. Le ticket Kerberos est nécessaire pour accéder aux répertoires HDFS et aux autres services Big Data que vous voulez utiliser.
Génération dynamique de blocs-notes sur un cluster non HA
Pour le cluster intégré AD :
Connectez-vous à l'aide de l'une des méthodes précédentes. L'autorisation fonctionne uniquement si l'utilisateur est présent sur l'hôte Linux. JupyterHub recherche l'utilisateur sur l'hôte Linux pendant la tentative de génération dynamique du serveur de bloc-notes.
- Configurez des clés SSH/jetons d'accès pour le noeud de cluster Big Data Service.
- Sélectionnez le mode de persistance de bloc-notes Git.
Pour configurer la connexion Git pour JupyterHub, procédez comme suit :
- Jetons d'accès pour le noeud de cluster Big Data Service.
- Sélectionner le mode de persistance de bloc-notes en tant que Git
Génération d'une paire de clés SSH
Utilisation de jetons d'accès
Vous pouvez utiliser des jetons d'accès comme suit :
- GitHub:
- Connectez-vous à votre compte GitHub.
- Accédez à Paramètres > Paramètres du développeur > Jetons d'accès personnel.
- Générez un nouveau jeton d'accès avec les droits d'accès appropriés.
- Utilisez le jeton d'accès comme mot de passe lorsque vous êtes invité à vous authentifier.
- GitLab:
- Connectez-vous à votre compte GitHub.
- Accédez à Paramètres > Jetons d'accès.
- Générez un nouveau jeton d'accès avec les droits d'accès appropriés.
- Utilisez le jeton d'accès comme mot de passe lorsque vous êtes invité à vous authentifier.
- BitBucket:
- Connectez-vous à votre compte BitBucket.
- Accédez à Paramètres > Mots de passe d'application.
- Générez un nouveau jeton de mot de passe d'application avec les autorisations appropriées.
- Utilisez le nouveau mot de passe de l'application comme mot de passe lorsque vous êtes invité à vous authentifier.
Sélectionner le mode de persistance en tant que Git
- Accédez à Apache Ambari.
- Dans la barre d'outils latérale, sous Services, sélectionnez JupyterHub.
- Sélectionnez Configurations, puis Paramètres.
- Recherchez le mode de persistance de bloc-notes, puis sélectionnez Git dans la liste déroulante.
- Sélectionnez Actions, puis Tout redémarrer.
- Accédez à Apache Ambari.
- Dans la barre d'outils latérale, sous Services, sélectionnez JupyterHub.
- Sélectionnez Configurations, puis Paramètres.
- Recherchez le mode de persistance de bloc-notes, puis sélectionnez HDFS dans la liste déroulante.
- Sélectionnez Actions, puis Tout redémarrer.
En tant qu'administrateur, vous pouvez stocker les blocs-notes des utilisateurs individuels dans Object Storage au lieu de HDFS. Lorsque vous passez le gestionnaire de contenu de HDFS vers Object Storage, les blocs-notes existants ne sont pas copiés vers Object Storage. Les nouveaux blocs-notes sont enregistrés dans Object Storage.
Montage du bucket Oracle Object Storage à l'aide de rclone avec l'authentification du principal utilisateur
Vous pouvez monter Oracle Object Storage à l'aide de rclone avec l'authentification de principal utilisateur (clés d'API) sur un noeud de cluster Big Data Service à l'aide de rclone et de fuse3, adaptés aux utilisateurs JupyterHub.
Gestion des environnements conda dans JupyterHub
Vous pouvez gérer les environnements conda sur les clusters ODH 2.x Big Data Service 3.0.28 ou versions ultérieures.
- Créez un environnement conda avec des dépendances spécifiques et créez quatre noyaux (Python/PySpark/Spark/SparkR) qui pointent vers l'environnement conda créé.
- Les environnements conda et les noyaux créés à l'aide de cette opération sont disponibles pour tous les utilisateurs de serveur de bloc-notes.
- Une opération de création d'environnement conda distincte consiste à découpler l'opération avec le redémarrage du service.
- JupyterHub est installé via l'interface utilisateur Ambari.
- Vérifiez l'accès Internet au cluster pour télécharger les dépendances lors de la création de conda.
- Les environnements conda et les noyaux créés à l'aide de cette opération sont disponibles pour tous les utilisateurs de serveur de bloc-notes.
- Fournir :
- Configurations supplémentaires conda pour éviter l'échec de la création conda. Pour plus d'informations, reportez-vous à conda create.
- Dépendances au format standard requirements
.txt. - Nom d'environnement conda inexistant.
- Supprimez manuellement les environnements conda ou les noyaux.
Cette opération crée un environnement conda avec des dépendances spécifiées et crée le noyau indiqué (Python/PySpark/Spark/SparkR) pointant vers l'environnement conda créé.
- Si l'environnement conda indiqué existe déjà, l'opération passe directement à l'étape de création du noyau
- Les environnements conda ou les noyaux créés à l'aide de cette opération ne sont disponibles que pour un utilisateur spécifique
- Exécutez manuellement le script python
kernel_install_script.pyen mode sudo :'/var/lib/ambari-server/resources/mpacks/odh-ambari-mpack-2.0.8/stacks/ODH/1.1.12/services/JUPYTER/package/scripts/'Exemple :
sudo python kernel_install_script.py --conda_env_name conda_jupy_env_1 --conda_additional_configs '--override-channels --no-default-packages --no-pin -c pytorch' --custom_requirements_txt_file_path ./req.txt --kernel_type spark --kernel_name spark_jupyterhub_1 --user jupyterhub
Prérequis
- Vérifiez l'accès Internet au cluster pour télécharger les dépendances lors de la création de conda. Sinon, la création échoue.
- S'il existe un noyau nommé
--kernel_name, une exception est générée. - Entrez les informations suivantes :
- Configurations conda pour éviter l'échec de la création. Pour plus d'informations, reportez-vous à https://conda.io/projects/conda/en/latest/commands/create.html.
- Dépendances fournies au format
.txtdes exigences standard.
- Supprimez manuellement les environnements conda ou les noyaux pour n'importe quel utilisateur.
Configurations disponibles pour la personnalisation
-
--user(obligatoire) : système d'exploitation et utilisateur JupyterHub pour lesquels le noyau et l'environnement conda sont créés. -
--conda_env_name(obligatoire) : indiquez un nom unique pour l'environnement conda chaque fois qu'un environnement est créé pour--user. -
--kernel_name: (obligatoire) indiquez un nom de noyau unique. -
--kernel_type: (obligatoire) doit être l'un des éléments suivants (python / PysPark / Spark / SparkR) -
--custom_requirements_txt_file_path: (facultatif) si des dépendances Python/R/Ruby/Lua/Scala/Java/JavaScript/C/C++/FORTRAN, etc., sont installées à l'aide de canaux conda, vous devez spécifier ces bibliothèques dans un fichier.txtd'exigences et fournir le chemin complet.Pour plus d'informations sur un format standard permettant de définir le fichier
.txtd'exigences, reportez-vous à https://pip.pypa.io/en/stable/reference/requirements-file-format/. -
--conda_additional_configs: (facultatif)- Ce champ fournit des paramètres supplémentaires à ajouter à la fin de la commande de création conda par défaut.
- La commande de création conda par défaut est :
'conda create -y -p conda_env_full_path -c conda-forge pip python=3.8'. - Si
--conda_additional_configsest défini sur'--override-channels --no-default-packages --no-pin -c pytorch', l'exécution finale de la commande de création conda est'conda create -y -p conda_env_full_path -c conda-forge pip python=3.8 --override-channels --no-default-packages --no-pin -c pytorch'.
Configuration d'un environnement conda propre à l'utilisateur
Création d'un équilibreur de charge et d'un ensemble de back-ends
Pour plus d'informations sur la création d'ensembles de back-ends, reportez-vous à Création d'un ensemble de back-ends d'équilibreur de charge.
Pour plus d'informations sur la création d'un équilibreur de charge public, reportez-vous à Création d'un équilibreur de charge et renseignez les détails suivants.
Pour plus d'informations sur la création d'un équilibreur de charge public, reportez-vous à Création d'un équilibreur de charge et renseignez les détails suivants.
- Ouvrez le menu de navigation. Sélectionnez Fonctions de réseau, puis Équilibreurs de charge. Sélectionnez Equilibreur de charge. La page Equilibreurs de charge apparaît.
- Sélectionnez le compartiment dans la liste. Tous les équilibreurs de charge de ce compartiment sont répertoriés dans un tableau.
- Sélectionnez l'équilibreur de charge auquel ajouter un back-end. La page de détails de l'équilibreur de charge apparaît.
- Sélectionnez Ensembles de back-ends, puis l'ensemble de back-ends que vous avez créé dans Création de l'équilibreur de charge.
- Sélectionnez des adresses IP, puis entrez l'adresse IP privée requise du cluster.
- Entrez 8000 pour le Port.
- Sélectionnez Ajouter.
Pour plus d'informations sur la création d'un équilibreur de charge public, reportez-vous à Création d'un équilibreur de charge et renseignez les détails suivants.
-
Ouvrez un navigateur et entrez
https://<loadbalancer ip>:8000. - Sélectionnez le compartiment dans la liste. Tous les équilibreurs de charge de ce compartiment sont répertoriés dans un tableau.
- Assurez-vous qu'il redirige vers l'un des serveurs JupyterHub. Pour vérifier, ouvrez une session de terminal sur JupyterHub afin de trouver le noeud atteint.
- Après l'opération d'ajout de noeud, l'administrateur de cluster doit mettre à jour manuellement l'entrée d'hôte de l'équilibreur de charge dans les noeuds nouvellement ajoutés. Applicable à tous les ajouts de noeud au cluster. Par exemple, le noeud de processus actif, le calcul uniquement et les noeuds.
- Le certificat doit être mis à jour manuellement vers l'équilibreur de charge en cas d'expiration. Cette étape permet de s'assurer que l'équilibreur de charge n'utilise pas de certificats obsolètes et d'éviter les échecs de vérification de l'état/communication des ensembles de back-ends. Pour plus d'informations, reportez-vous à Mise à jour d'un certificat d'équilibreur de charge arrivant à expiration afin de mettre à jour le certificat expiré.
Lancer les noyaux Trino-SQL
Le noyau JupyterHub PyTrino fournit une interface SQL qui vous permet d'exécuter des requêtes Trino à l'aide de JupyterHub SQL. Cette fonctionnalité est disponible pour les clusters ODH 2.x Big Data Service 3.0.28 ou versions ultérieures.
Pour plus d'informations sur les paramètres SqlMagic, reportez-vous à https://jupysql.ploomber.io/en/latest/api/configuration.html#changing-configuration.