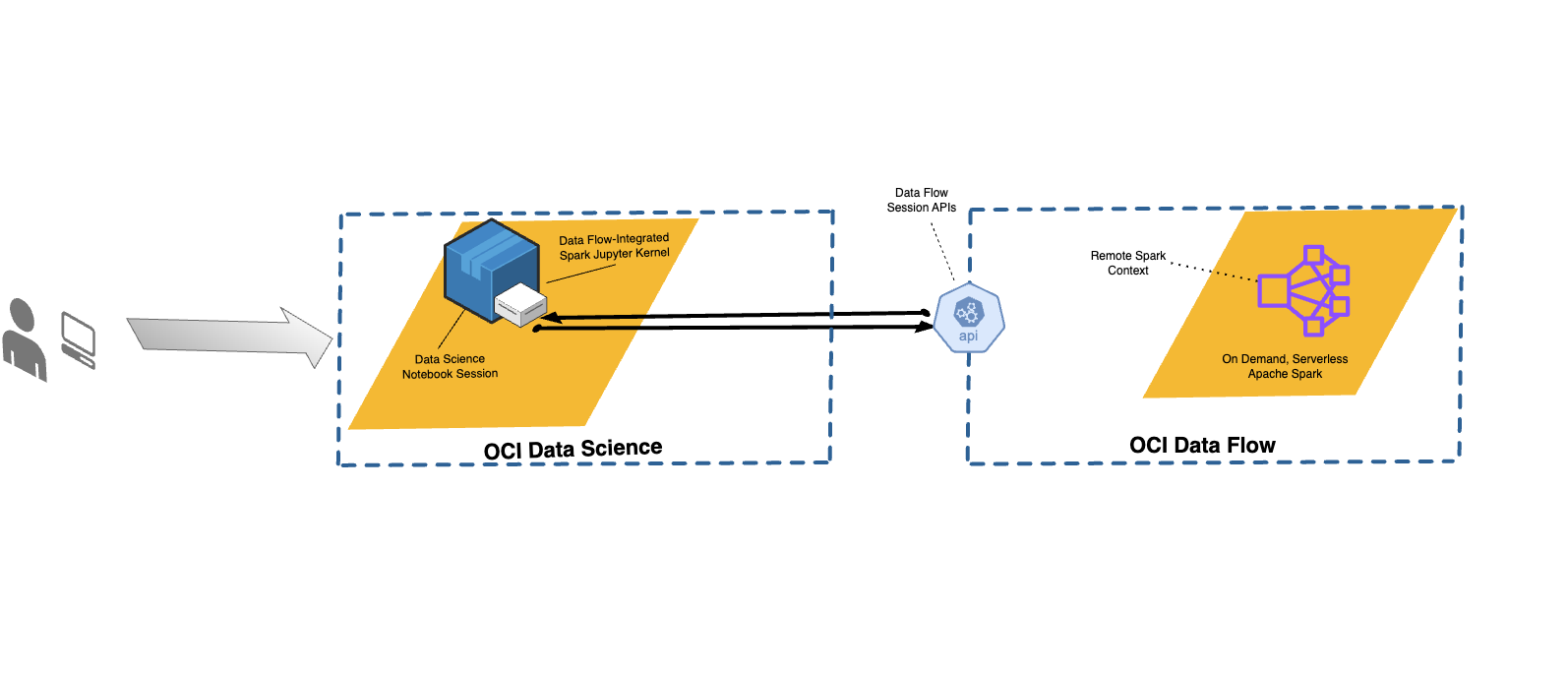
Intégration de Data Flow à Data Science
Avec Data Flow, vous pouvez configurer des blocs-notes Data Science pour exécuter des applications de manière interactive sur Data Flow.
Data Flow utilise les blocs-notes Jupyter entièrement gérés pour permettre aux analystes des données et aux ingénieurs de données de créer, de visualiser, de collaborer et de déboguer des applications d'ingénierie et de sciences des données. Vous pouvez écrire ces applications en Python, en Scala et en PySpark. Vous pouvez également connecter une sesession de bloc-notes Data Science à Data Flow pour exécuter les applications. Les noyaux et noyaux Data Flow et les applications sont exécutés sur Oracle Cloud Infrastructure Data Flow.
Apache Spark est un système de calcul distribué conçu pour traiter les données à l'échelle. Il prend en charge les traitements de flux de données, batch et SQL, ainsi que les tâches d'apprentissage automatique à grande échelle. Spark SQL fournit une prise en charge de type base de données. Pour interroger des données structurées, utilisez Spark SQL. Il s'agit d'une implémentation SQL de norme ANSI.
Les session Data Flow prennent en charge le redimensionnement automatique de fonctionnalités de cluster de Data Flow. Pour plus d'informations, reportez-vous à la section Redimensionnement automatique dans la documentation Data Flow.
Les sessions Data Flow prennent en charge l'utilisation d'environnements conda en tant qu'environnements d'exécution Spark personnalisables.
- Limites
-
-
Les sessions Data Flow peuvent durer jusqu'à 7 jours ou 10 080 minutes (maxDurationInMinutes).
- La valeur de délai d'inactivité par défaut des sessions Data Flow est de 8 heures (480) (idleTimeoutInMinutes). Vous pouvez configurer une autre valeur.
- La session Data Flow est uniquement disponible via une session de bloc-notes Data Science.
- Seules les versions 3.5.0 et 3.2.1 de Spark sont prises en charge.
-
Regardez le tutoriel vidéo sur l'utilisation de Data Science avec le studio Data Flow. Pour plus d'informations sur l'intégration de Data Science et Data Flow, reportez-vous également à la documentation du kit SDK Oracle Accelerated Data Science.
Installation de l'environnement conda
Suivez ces étapes pour utiliser Data Flow avec Data Flow Magic.
Utilisation de Data Flow avec Data Science
Procédez comme suit pour exécuter une application en utilisant Data Flow avec Data Science.
-
Assurez-vous que les stratégies permettant d'utiliser un bloc-notes avec Data Flow sont configurées.
-
Assurez-vous que les stratégies Data Science sont correctement configurées.
- Pour obtenir la liste de toutes les commandes prises en charge, utilisez la commande
%help. - Les commandes des étapes suivantes s'appliquent à Spark 3.5.0 et à Spark 3.2.1. Spark 3.5.0 est utilisé dans les exemples. Définissez la valeur de
sparkVersionen fonction de la version de Spark utilisée.
Personnalisation d'un environnement Spark Data Flow avec un environnement conda
Vous pouvez utiliser un environnement conda publié comme environnement d'exécution.
Exécution de spark-nlp sur Data Flow
Suivez ces étapes pour installer Spark-nlp et l'exécuter sur Data Flow.
Vous devez avoir effectué les étapes 1 et 2 décrites dans Personnalisation d'un environnement Spark Data Flow avec un environnement conda. La bibliothèque spark-nlp est préinstallée dans l'environnement conda pyspark32_p38_cpu_v2.
Exemples
Voici des exemples d'utilisation des données FlowMagic.
PySpark
sc représente Spark et elle est disponible lorsque la commande magic %%spark est utilisée. La cellule suivante est un exemple d'utilisation de sc dans une cellule FlowMagic de données. La cellule appelle la méthode .parallelize() qui crée un RDD, numbers, à partir d'une liste de numéros. Les informations sur le RDD sont affichées. La méthode .toDebugString() renvoie la description du RDD.%%spark
print(sc.version)
numbers = sc.parallelize([4, 3, 2, 1])
print(f"First element of numbers is {numbers.first()}")
print(f"The RDD, numbers, has the following description\n{numbers.toDebugString()}")Spark SQL
L'option -c sql permet d'exécuter des commandes Spark SQL dans une cellule. Dans cette section, l'ensemble de données de Citi Bike est utilisé. La cellule suivante lit l'ensemble de données dans une trame de données Spark et l'enregistre sous forme de table. Cet exemple est utilisé pour afficher Spark SQL.
%%spark
df_bike_trips = spark.read.csv("oci://dmcherka-dev@ociodscdev/201306-citibike-tripdata.csv", header=False, inferSchema=True)
df_bike_trips.show()
df_bike_trips.createOrReplaceTempView("bike_trips")L'exemple suivant utilise l'option -c sql pour indiquer aux données FlowMagic que le contenu de la cellule est SparkSQL. L'option -o <variable> prend les résultats de l'opération Spark SQL et les stocke dans la variable définie. Dans ce cas,
df_bike_trips est une trame de données Pandas pouvant être utilisée dans le bloc-notes.%%spark -c sql -o df_bike_trips
SELECT _c0 AS Duration, _c4 AS Start_Station, _c8 AS End_Station, _c11 AS Bike_ID FROM bike_trips;df_bike_trips.head()sqlContext pour interroger la table :%%spark
df_bike_trips_2 = sqlContext.sql("SELECT * FROM bike_trips")
df_bike_trips_2.show()%%spark -c sql
SHOW TABLESWidget de visualisation automatique
Les données FlowMagic sont fournies avec autovizwidget, qui permet la visualisation des trames de données Pandas. La fonction display_dataframe() prend une trame de données Pandas en tant que paramètre et génère une interface utilisateur graphique interactive dans le bloc-notes. Elle comporte des onglets qui affichent la visualisation des données dans différents formulaires, tels que des tableaux, des graphiques à secteurs, des diagrammes en nuage de points et des graphiques en zone et à barres.
display_dataframe() avec la trame des données df_people qui a été créée dans la section Spark SQL du bloc-notes :from autovizwidget.widget.utils import display_dataframe
display_dataframe(df_bike_trips)Matplotlib
Une tâche courante des analystes de données consiste à visualiser leurs données. Avec des ensembles de données volumineux, il n'est généralement pas possible ni recommandé d'extraire les données du cluster Spark Data Flow vers la session de bloc-notes. Cet exemple montre comment utiliser les ressources côté serveur pour générer un tracé et l'inclure dans le bloc-notes.
%matplot plt pour afficher le graphique dans le bloc-notes, même s'il est affiché côté serveur :%%spark
import matplotlib.pyplot as plt
df_bike_trips.groupby("_c4").count().toPandas().plot.bar(x="_c4", y="count")
%matplot pltAutres exemples
D'autres exemples sont disponibles à partir de GitHub avec des échantillons Data Flow et des échantillons Data Science.