Présentation de Speech
Vous pouvez utiliser le service Speech pour convertir des fichiers multimédias en texte lisible stocké au format JSON et SRT.
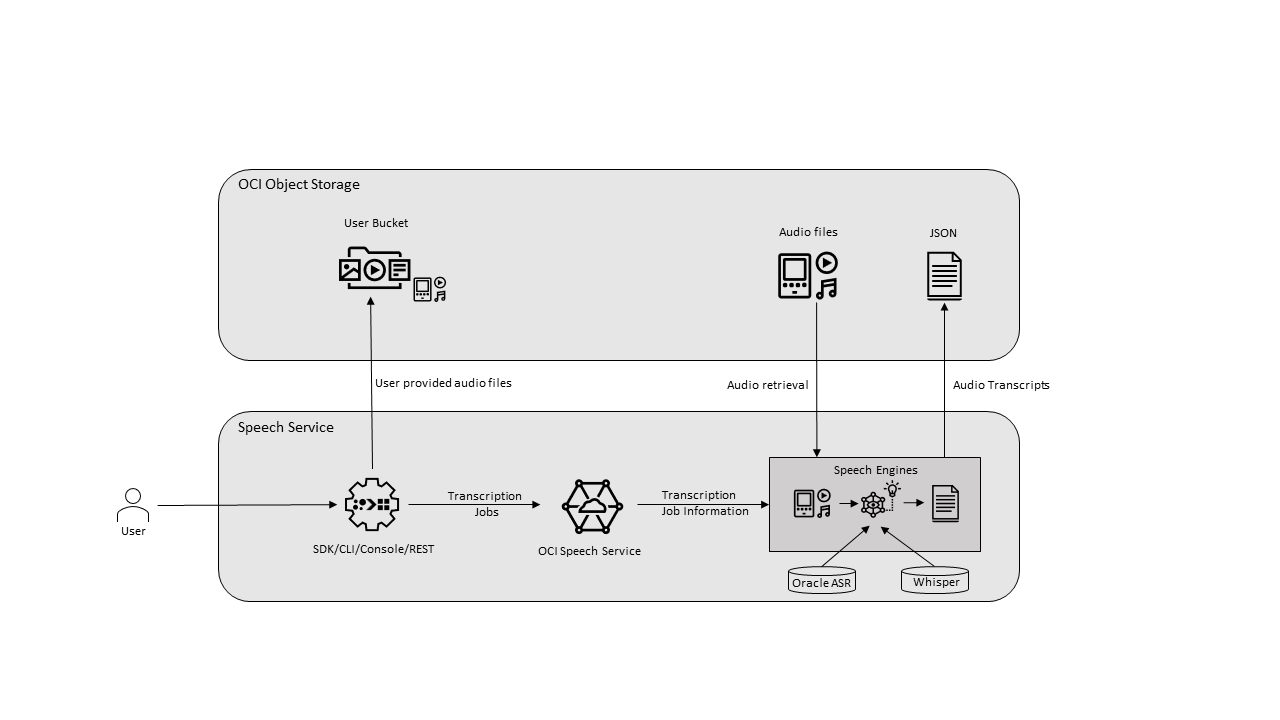
La parole exploite la puissance du langage parlé, ce qui vous permet de convertir facilement des fichiers multimédias contenant de la parole humaine en transcriptions de texte très précises. Le service est une application native Oracle Cloud Infrastructure (OCI) à laquelle vous pouvez accéder à l'aide de la console, de l'API REST, de l'interface de ligne de commande et du kit SDK. En outre, vous pouvez utiliser le service Speech dans une session de bloc-notes Data Science.
La parole utilise la technologie de reconnaissance vocale automatique (ASR) pour fournir une transcription grammaticalement correcte. Speech gère les enregistrements médiatiques de faible fidélité et transcrit les enregistrements difficiles tels que les réunions ou les appels des centres d'appels. Grâce à Speech, vous pouvez transformer les fichiers stockés dans Object Storage ou une ressource de données en texte exact, normalisé, horodaté et filtré de manière grossière. Cette fonctionnalité n'est disponible qu'avec le discours. Par exemple, vous pouvez indexer la sortie de la synthèse vocale (fichier texte) à l'aide du lac de données. Sans les services en aval, cette fonctionnalité n'existe pas dans Speech.
Les modèles Speech sont robustes aux environnements acoustiques et aux canaux d'enregistrement qui garantissent un service de transcription de bonne qualité.
Prise en charge de plusieurs formats de support par langue
Les formats de support suivants sont pris en charge pour toutes les langues prises en charge dans le service Speech :
AACAC3AMRAUFLACM4AMKVMP3MP4OGAOGGOPUSWAVWEBM
| Langue | Code de langue | Taux d'échantillonnage |
|---|---|---|
| Anglais - Etats-Unis | en-US |
>= 8 khz |
| Espagnol - Espagne | es-ES |
>= 8 khz |
| Portugais - Brésil | pt-BR |
>= 8 khz |
| Anglais - Royaume-Uni | en-GB |
>= 16 khz |
| Anglais - Australie | en-AU |
>= 16 khz |
| Anglais - Inde | en-IN |
>= 16 khz |
| Hindi-Inde | hi-IN |
>= 16 khz |
| Français-Français | fr-FR |
>= 16 khz |
| Allemand - Allemagne | de-DE |
>= 16 khz |
| Italien - Italie | it-IT |
>= 16 khz |
Pour de meilleurs résultats :
- Utilisez un format sans perte tel que FLAC ou WAV avec un codage PCM 16 bits.
- Utilisez un taux d'échantillonnage de 8 000 Hz pour les médias à faible fidélité et de 16 000 à 48 000 Hz pour les médias à haute fidélité.
Vous pouvez utiliser des fichiers multimédias WAV PCM 16 bits à canal unique avec un taux d'échantillonnage de 8 kHz ou 16 kHz. Nous recommandons Audacity (GUI) ou FFmpeg (ligne de commande) pour le transcodage de média. Une longueur de fichier média maximale de quatre heures et jusqu'à 2 Go est prise en charge.
La parole est sensible à la qualité des fichiers multimédia d'entrée. Les différents accents, les bruits de fond, le passage d'une langue à une autre, l'utilisation de langues de fusion ou plusieurs locuteurs en même temps ont un impact sur la qualité de la transcription.
La parole offre ces fonctionnalités
-
Transcriptions précises : fournit des fichiers JSON et de sous-titre SubRip (SRT) précis et faciles à utiliser écrits directement dans le bucket Object Storage de votre choix. Vous pouvez tirer parti de la transcription et l'intégrer directement aux applications, et l'utiliser pour la recherche et l'analyse de sous-titres ou de contenu.
- Modèle Whisper : les données multilingues sont collectées sur le Web et prennent en charge la transcription vocale en texte basée sur des fichiers pour plus de 50 langues.
-
JSON horodaté : la transcription fournit un horodatage pour chaque jeton (mot). Vous pouvez utiliser l'horodatage pour rechercher et trouver le texte que vous recherchez dans le fichier multimédia, puis passer rapidement à cet emplacement.
-
Multilingue : produit des transcriptions précises en anglais, anglais-Grande-Bretagne, anglais-Australie, anglais-Inde, espagnol, portugais, français, italien, allemand et hindi.
-
API asynchrone : API asynchrones simples avec traitement par lots des tâches de transcription. Les API permettent d'annuler des travaux qui ne sont pas encore traités, ce qui permet d'économiser du temps et de l'argent.
-
Normalisations de texte : fournit des normalisations de texte pour les nombres, les adresses, les devises, etc. Avec les normalisations de texte, vous obtenez une transcription de meilleure qualité à partir de l'intelligence artificielle, plus facile à lire et à comprendre.
-
Filtrage de la propagande : permet d'enlever, de masquer ou d'étiqueter les mots offensants de la transcription.
-
Score de confiance par mot et transcription : produit des scores de confiance de mot et de transcription sur le fichier JSON généré. Vous pouvez utiliser les scores de confiance pour identifier rapidement les mots qui nécessitent votre attention.
-
Légendes fermées : fournit un fichier SRT en tant que format de sortie supplémentaire. Utilisez la SRT pour ajouter des sous-titres aux fichiers vidéo.
-
Punctuation : le texte long requiert une ponctuation. Par conséquent, Speech ponctue automatiquement le contenu de transcription.
-
Prêt pour la téléphonie : les fichiers peuvent être 8 kHz ou 16 kHz et chacun d'eux est automatiquement détecté afin que le modèle correct soit appliqué. Avec cette capacité, vous pouvez transcrire des enregistrements téléphoniques.
-
Diarisation des intervenants : associe le texte de transcription à des intervenants spécifiques à l'aide de scénarios de compréhension du langage naturel, tels que l'extraction d'une prescription d'audio médical en identifiant le prestataire de services par rapport au patient. La diarisation des haut-parleurs est une combinaison de segmentation des haut-parleurs et de regroupement des haut-parleurs. La segmentation de haut-parleur permet de trouver les points de changement de haut-parleur dans un flux audio. Le regroupement des haut-parleurs regroupe des segments de parole en fonction des caractéristiques des haut-parleurs.
Concepts clés
Voici les concepts clés du service Speech :
- Travaux de retranscription
-
Un travail est une demande asynchrone unique provenant de la console ou de l'API Speech. Chaque travail est identifié de manière unique par un ID, que vous pouvez utiliser pour extraire le statut et les résultats du travail.
Un travail dans un locataire est traité de manière stricte en premier lieu. Chaque travail peut contenir jusqu'à 100 tâches. Si vous soumettez un travail qui dépasse le nombre maximal de tâches, ce travail échoue. Les emplois sont conservés pendant 90 jours.
- Traduction en direct
- Permet d'envoyer un flux audio au service et de recevoir les résultats en texte (format JSON et SRT) en temps réel.
- Tâches
-
Une tâche est le résultat d'un seul fichier traité dans un travail. Les travaux peuvent comporter plusieurs tâches en fonction de ce qui est stocké dans le bucket Object Storage que vous indiquez pour un travail.
- Modèles
-
Les modèles acoustiques et linguistiques préentraînés, y compris les modèles Whisper, alimentent le processus de transcription du travail.
Authentification et autorisation
Chaque service d'OCI s'intègre à IAM pour l'authentification et l'autorisation, sur toutes les interfaces (console, kit SDK ou interface de ligne de commande, et API REST).
Un administrateur de votre organisation doit configurer des groupes , des compartiments et des stratégies qui déterminent les services et les ressources auxquels les utilisateurs peuvent accéder, ainsi que le type d'accès. Par exemple, les stratégies déterminent qui peut créer des utilisateurs, créer et gérer le réseau cloud, lancer des instances, créer des buckets, télécharger des objets, etc. Pour plus d'informations, reportez-vous à Introduction aux stratégies.
- Pour plus de détails sur l'écriture de stratégies vocales, reportez-vous à A propos des stratégies vocales.
- Afin d'obtenir plus de détails sur l'écriture de stratégies pour d'autres services, reportez-vous à Référence de stratégie.
Si vous êtes un utilisateur standard (pas un administrateur) et que vous avez besoin des ressources OCI de votre entreprise, demandez à l'administrateur de configurer pour vous un ID utilisateur. L'administrateur peut confirmer les compartiments que vous devez utiliser.
Identificateurs de ressource
Le service Speech prend en charge les travaux et les tâches en tant que ressources OCI. La plupart des types de ressource possèdent un identificateur unique affecté par Oracle appelé ID Oracle Cloud (OCID). Pour plus d'informations sur le format OCID et les autres moyens d'identifier vos ressources, reportez-vous à Identificateurs de ressource.
Régions et domaines de disponibilité
Le discours est disponible dans toutes les régions commerciales OCI. Reportez-vous à A propos des régions et des domaines de disponibilité afin d'obtenir la liste des régions disponibles pour OCI, ainsi que les emplacements, identifiants de région, clés de région et domaines de disponibilité associés.
La synthèse vocale n'est disponible que dans la région commerciale Ouest des Etats-Unis (Phoenix).
Méthodes d'accès
Vous pouvez accéder à Speech à l'aide de la console (interface basée sur un navigateur), de l'interface de ligne de commande ou de l'API REST. Les instructions concernant la console, l'interface de ligne de commande et l'API sont incluses dans les rubriques de ce guide.
Pour accéder à la console, vous devez utiliser un navigateur pris en charge. Pour accéder à la page de connexion à la console, ouvrez le menu de navigation en haut de cette page et cliquez sur Console Infrastructure. Vous êtes invité à saisir votre locataire cloud, votre nom utilisateur et votre mot de passe.
Pour obtenir la liste des kits SDK disponibles, reportez-vous à Kits SDK et interface de ligne de commande. Pour obtenir des informations générales sur l'utilisation des API, reportez-vous à API REST.
Limites de service
Dans chaque région activée pour votre location, les limites suivantes s'appliquent :
Limites de fichier
-
La taille de fichier maximale est de 2 Go.
-
La durée du fichier est de 4 heures au maximum.
Limites de travail
Synthèse vocale
La synthèse vocale prend en charge un maximum de 10000 caractères par demande.
Traduction en direct
La transcription en direct prend en charge un maximum de 10 sessions simultanées par location. Vous pouvez augmenter la limite en ouvrant une demande de service auprès du support technique Oracle. Pour plus d'informations, reportez-vous à Demande d'augmentation de limite de service.
Comparer les modèles Whisper et Oracle ASR
Comparez le modèle Whisper et le modèle Oracle ASR pour créer des travaux de transcription.
En plus du modèle vocal Oracle ASR natif, Speech prend en charge le modèle Whisper de OpenAI. Whisper est formé sur un grand corpus de données multilingues collectées sur le Web et prend en charge la transcription vocale-texte basée sur des fichiers pour plus de 50 langues. Ce modèle utilise les mêmes endpoints de service et interfaces API et SDK que le modèle Oracle ASR pour vous offrir flexibilité et compatibilité. En outre, le modèle Whisper utilise la diarisation pour étiqueter les haut-parleurs individuels dans l'enregistrement.
Utilisez la comparaison suivante des modèles Whisper et Oracle ASR pour sélectionner le modèle approprié lors de la création d'un travail de transcription.
| Fonction | Modèle Oracle ASR | Modèle Whisper dans OCI Speech |
|---|---|---|
| Transcriptions en temps réel | Pris en charge | Pris en charge |
| Taille de fichier volumineuse | Jusqu'à 2 Go | Jusqu'à 2 Go |
| Horodatage au niveau du mot | Pris en charge | Pris en charge |
| Format de fichier | AAC, AC3, AMR, AU, FLAC, M4A, MKV, MP3, MP4, OGA, OGG, OPUS, WAV, WEBM | AAC, AC3, AMR, AU, FLAC, M4A, MKV, MP3, MP4, OGA, OGG, OPUS, WAV, WEBM |
| Prise en charge multilingue | Anglais, espagnol, français, allemand, italien, portugais et hindi | Identique au modèle Oracle ASR et à 50 autres langues* |
| Diarisation | Pris en charge | Pris en charge |