Modèles d'IA de document préentraînés
Vision fournit des modèles d'IA de documents préentraînés qui vous permettent d'organiser et d'extraire du texte et de la structure à partir de documents commerciaux.
Les fonctionnalités AnalyzeDocument et DocumentJob de Vision passent à un nouveau service, Document Understanding. Les fonctions suivantes sont concernées :
- Détection de table
- Classification de documents
- Extraction de valeur-clé de réception
- Documenter la reconnaissance optique de caractères
Cas d'emploi
Les modèles d'IA de documents préentraînés vous permettent d'automatiser les opérations de back-office et de traiter les reçus avec plus de précision.
- Recherche intelligente
- Enrichissez les fichiers basés sur une image avec des métadonnées, y compris le type de document et les champs clés, pour faciliter l'extraction.
- Reporting des charges
- Extraire les informations requises des réceptions pour automatiser les workflows opérationnels. Par exemple, les notes de frais des employés, la conformité des dépenses et les remboursements.
- Traitement du langage naturel en aval (NLP)
- Extrayez du texte à partir de fichiers PDF et organisez-le comme entrée pour le traitement du langage naturel, soit dans des tableaux, soit dans des mots et des lignes.
- Capture des points de fidélité
- Automatiser le calcul des points de fidélité à partir des reçus, en fonction du nombre d'articles ou du montant total payé.
Formats pris en charge
Vision prend en charge plusieurs formats de document.
- JPEG
- PNG
- TIFF
Modèles préentraînés
Vision a cinq types de modèle préentraîné.
Reconnaissance optique des caractères (OCR)
Vision peut détecter et reconnaître le texte d'un document. La classification des langues identifie la langue d'un document, puis OCR dessine des zones englobantes autour du texte imprimé ou écrit à la main qu'il trouve dans une image et numérise le texte.
Si vous avez un PDF avec du texte, Vision trouve le texte dans ce document et extrait le texte. Il fournit ensuite des zones englobantes pour le texte identifié. La détection de texte peut être utilisée avec des modèles d'IA de documents ou d'analyse d'images.
Vision fournit un score de confiance pour chaque regroupement de texte. Le score de confiance est un nombre décimal. Les scores plus proches de 1 indiquent une confiance plus élevée dans le texte extrait, tandis que les scores inférieurs indiquent un score de confiance inférieur. La plage du score de confiance pour chaque étiquette est comprise entre 0 et 1.
La prise en charge d'OCR est limitée à l'anglais. Si vous savez que le texte des images est en anglais, définissez la langue sur
Eng.- Extraction de mots
- Extraction de ligne de texte
- Score de fiabilité
- Polygone limitant
- Demande unique
- Demande en batch
- Bien que la classification linguistique identifie plusieurs langues, la ROC est limitée à l'anglais.
Exemple d'utilisation de la reconnaissance optique de caractères dans Vision.
- Document d'entrée
-
Saisie OCR

.{ "analyzeDocumentDetails": { "compartmentId": "", "document": { "namespaceName": "", "bucketName": "", "objectName": "", "source": "OBJECT_STORAGE" }, "features": [ { "featureType": "TEXT_DETECTION" }, { "featureType": "LANGUAGE_CLASSIFICATION", "maxResults": 5 } ] } } - Sortie :
- Sortie OCR
 Réponse d'API :
Réponse d'API : { "documentMetadata": { "pageCount": 1, "mimeType": "image/jpeg" }, "pages": [ { "pageNumber": 1, "dimensions": { "width": 361, "height": 600, "unit": "PIXEL" }, "detectedLanguages": [ { "languageCode": "ENG", "confidence": 0.9999994 }, { "languageCode": "ARA", "confidence": 4.7619238e-7 }, { "languageCode": "NLD", "confidence": 7.2325456e-8 }, { "languageCode": "CHI_SIM", "confidence": 3.0645523e-8 }, { "languageCode": "ITA", "confidence": 8.6900076e-10 } ], "words": [ { "text": "Example", "confidence": 0.99908227, "boundingPolygon": { "normalizedVertices": [ { "x": 0.0664819944598338, "y": 0.011666666666666667 }, { "x": 0.22160664819944598, "y": 0.011666666666666667 }, { "x": 0.22160664819944598, "y": 0.035 }, { "x": 0.0664819944598338, "y": 0.035 } ] } ... "detectedLanguages": [ { "languageCode": "ENG", "confidence": 0.9999994 } ], ...
Classification de documents
La classification de document peut être utilisée pour classer un document.
- Facture
- Encaissement
- CV
- Déclaration de revenus
- Permis de conduire
- Passeport
- relevé bancaire
- Sélectionner
- Fiche de paie
- Autre
- Classer un document
- Score de fiabilité
- Demande unique
- Demande en batch
Exemple d'utilisation de la classification des documents dans Vision.
- Document d'entrée
- Entrée de classification de document
- Sortie :
- Réponse d'API :
{ "documentMetadata": { "pageCount": 1, "mimeType": "image/jpeg" }, "pages": [ { "pageNumber": 1, "dimensions": { "width": 361, "height": 600, "unit": "PIXEL" }, "detectedDocumentTypes": [ { "documentType": "RECEIPT", "confidence": 1 }, { "documentType": "TAX_FORM", "confidence": 6.465067e-9 }, { "documentType": "CHECK", "confidence": 6.031838e-9 }, { "documentType": "BANK_STATEMENT", "confidence": 5.413888e-9 }, { "documentType": "PASSPORT", "confidence": 1.5554872e-9 } ], ... detectedDocumentTypes": [ { "documentType": "RECEIPT", "confidence": 1 } ], ...
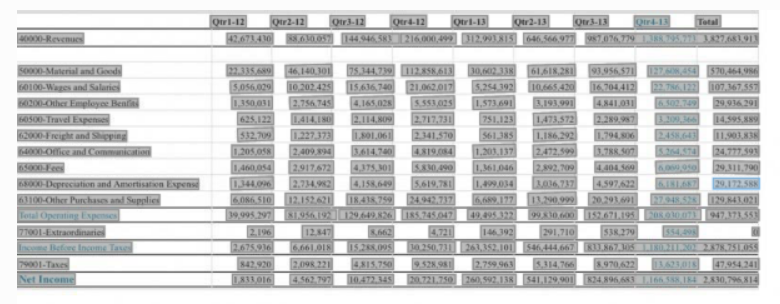
Extraction de table
L'extraction de table permet d'identifier les tables d'un document et d'en extraire le contenu. Par exemple, si un reçu PDF contient une table qui inclut les taxes et le montant total, Vision identifie la table et extrait la structure de la table.
Vision fournit le nombre de lignes et de colonnes de la table et le contenu de chaque cellule de la table. Chaque cellule a un score de confiance. Le score de confiance est un nombre décimal. Les scores plus proches de 1 indiquent une confiance plus élevée dans le texte extrait, tandis que les scores inférieurs indiquent un score de confiance inférieur. La plage du score de confiance pour chaque étiquette est comprise entre 0 et 1.
- Extraction de table pour tables avec et sans bordures
- Polygone limitant
- Score de fiabilité
- Demande unique
- Demande en batch
- Langue anglaise uniquement
Exemple d'utilisation de l'extraction de table dans Vision.
- Document d'entrée
- Entrée d'extraction de table
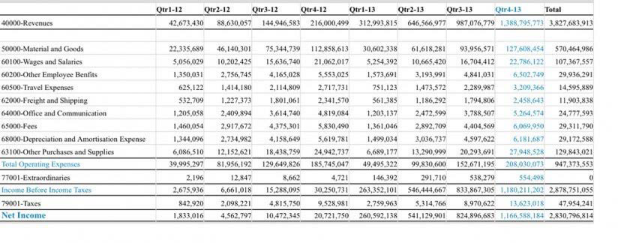
- Sortie :
- Sortie d'extraction de table
Extraction de valeur de clé (réceptions)
L'extraction des valeurs de clé peut être utilisée pour identifier les valeurs des clés prédéfinies dans un encaissement. Par exemple, si un reçu comprend un nom de commerçant, une adresse de commerçant ou un numéro de téléphone de commerçant, Vision peut identifier ces valeurs et les renvoyer sous forme de paire de valeurs de clé.
- Extraire les valeurs pour les paires clé-valeur prédéfinies
- Polygone limitant
- Demande unique
- Demande en batch
- Prend en charge les reçus en anglais seulement.
- MerchantName
- Nom du commerçant émettant le reçu.
- MerchantPhoneNumber
- Numéro de téléphone du commerçant.
- MerchantAddress
- Adresse du commerçant.
- TransactionDate
- Date à laquelle l'encaissement a été émis.
- TransactionTime
- Heure à laquelle le reçu a été émis.
- Total
- Montant total de l'encaissement, après le lettrage de tous les frais et taxes.
- Sous-total
- Sous-total avant impôts.
- Tax
- Toutes les taxes de vente.
- Conseil
- Montant du pourboire donné par l'acheteur.
- ItemName
- Nom de l'élément.
- ItemPrice
- Prix unitaire de l'article.
- ItemQuantity
- Nombre de chaque article acheté.
- ItemTotalPrice
- Prix total de la ligne.
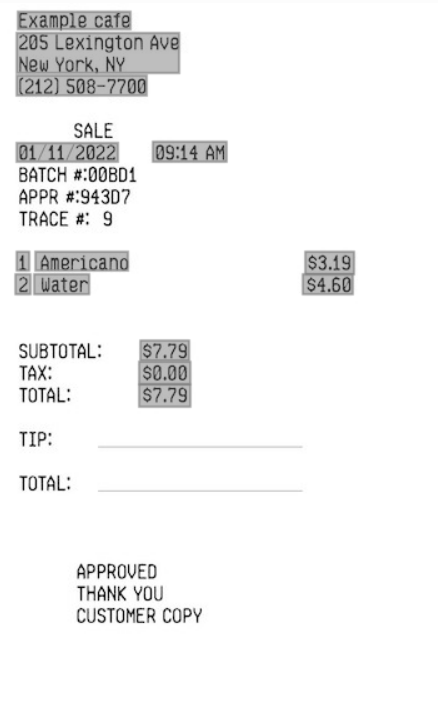
Exemple d'utilisation de l'extraction de valeur clé dans Vision.
- Document d'entrée
- Entrée d'extraction de valeur de clé (réceptions)
- Sortie :
- Sortie d'extraction de valeur de clé (réceptions)
PDF de reconnaissance optique des caractères (OCR)
OCR PDF génère un fichier PDF recherchable dans Object Storage. Par exemple, Vision peut prendre un fichier PDF avec du texte et des images et renvoyer un fichier PDF dans lequel vous pouvez rechercher le texte dans le PDF.
- Générer un PDF pouvant faire l'objet d'une recherche
- Demande unique
- Demande en batch
Exemple d'utilisation d'OCR PDF dans Vision.
- Entrée
-
Demande d'API
 d'entrée OCR ODF :
d'entrée OCR ODF :{ "analyzeDocumentDetails": { "compartmentId": "", "document": { "source": "INLINE", "data": "......" }, "features": [ { "featureType": "TEXT_DETECTION", "generateSearchablePdf": true } ] } } - Sortie :
- PDF pouvant faire l'objet d'une recherche.
Utilisation des modèles d'IA de document prédéfinis
Vision fournit des modèles préentraînés permettant aux clients d'extraire des informations sur leurs documents sans avoir besoin d'analystes de données.
Vous devez disposer des éléments suivants avant d'utiliser un modèle préentraîné :
-
Compte de location payant dans Oracle Cloud Infrastructure.
-
Bonne connaissance d'Oracle Cloud Infrastructure Object Storage.
Vous pouvez appeler les modèles d'IA de document préentraînés en tant que demande par lots à l'aide des API Rest, du SDK ou de l'interface de ligne de commande. Vous pouvez appeler les modèles d'IA de document préentraînés en tant que demande unique à l'aide de la console, des API Rest, du kit SDK ou de l'interface de ligne de commande.
Reportez-vous à la section Limites pour plus d'informations sur ce qui est autorisé dans les demandes en batch.