Interrogation de données externes avec Data Catalog
Oracle Cloud Infrastructure Data Catalog est le service de gestion des métadonnées d'Oracle Cloud qui vous aide à repérer les données et à prendre en charge la gouvernance des données. Il fournit un inventaire des ressources, un glossaire métier et un metastore commun pour les lacs de données.
Autonomous AI Database peut exploiter ces métadonnées pour simplifier considérablement la gestion de l'accès à la banque d'objets de votre lac de données. Au lieu de définir manuellement des tables externes pour accéder à votre lac de données, utilisez les tables externes qui sont définies et gérées automatiquement. Ces tables se trouvent dans les schémas protégés par Autonomous AI Database qui sont tenus à jour avec les modifications apportées à Data Catalog.
Pour plus d'informations sur Data Catalog, reportez-vous à la documentation Data Catalog.
A propos de l'interrogation avec Data Catalog
En effectuant une synchronisation avec les métadonnées Data Catalog, Autonomous AI Database crée automatiquement des tables externes pour chaque entité logique collectée par Data Catalog. Ces tables externes sont définies dans des schémas de base de données entièrement gérés par le processus de synchronisation des métadonnées. Les utilisateurs peuvent immédiatement interroger les données sans avoir à dériver manuellement le schéma (colonnes et types de données) pour les sources de données externes et à créer manuellement des tables externes.
La synchronisation est dynamique, ce qui permet de maintenir la base de données Autonomous AI à jour en ce qui concerne les modifications apportées aux données sous-jacentes, ce qui réduit les coûts d'administration car elle gère automatiquement des centaines à des milliers de tables. Elle permet également à plusieurs instances de base de données d'IA autonome de partager le même catalogue de données, ce qui permet de réduire les coûts de gestion et de fournir un ensemble commun de définitions métier.
Les dossiers/buckets Data Catalog sont des conteneurs qui sont synchronisés avec les schémas de base de données Autonomous AI. Les entités logiques au sein de ces dossiers/buckets sont mises en correspondance avec des tables externes de base de données Autonomous AI. Les schémas et tables externes suivants sont générés et gérés automatiquement via le processus de synchronisation :
-
Les dossiers/buckets sont mis en correspondance avec des schémas de base de données à des fins d'organisation uniquement.
-
L'entreprise doit être cohérente avec le lac de données et minimiser la confusion lors de l'accès aux données via différents chemins.
-
Data Catalog est la source de vérité pour les tables contenues dans les schémas. Les modifications apportées dans le catalogue de données mettent à jour les tables du schéma lors d'une synchronisation ultérieure.
Pour utiliser cette fonctionnalité, un administrateur de catalogue de données de base de données lance une connexion à une instance Data Catalog, sélectionne les ressources de données et les entités logiques à synchroniser et exécute la synchronisation. Le processus de synchronisation crée des schémas et des tables externes en fonction des ressources de données et des entités logiques collectées par Data Catalog sélectionnées. Dès que les tables externes sont créées, les analystes de données peuvent commencer à interroger leurs données sans avoir à dériver manuellement le schéma pour les sources de données externes et à créer des tables externes.
Remarque
Remarque : le package DBMS_DCAT est disponible pour effectuer les tâches requises pour interroger les ressources de données de banque d'objets Data Catalog. Reportez-vous à Package DBMS_DCAT.
Concepts liés à l'interrogation avec Data Catalog
Vous devez comprendre les concepts suivants pour effectuer des requêtes avec Data Catalog.
Catalogue de données
Data Catalog collecte les ressources de données qui pointent vers les sources de données de banque d'objets à interroger avec Autonomous AI Database. Dans Data Catalog, vous pouvez indiquer comment les données sont organisées lors de la collecte, en prenant en charge différents modèles d'organisation des fichiers. Dans le cadre du processus de collecte Data Catalog, vous pouvez sélectionner les buckets et les fichiers à gérer au sein de la ressource. Pour plus d'informations, reportez-vous à Présentation de Data Catalog.
Banques d'objets
Les banques d'objets ont des buckets contenant une variété d'objets. Certains types d'objet courants trouvés dans ces buckets incluent les fichiers CSV, parquet, avro, json et ORC. Les buckets ont généralement une structure ou un modèle de conception pour les objets qu'ils contiennent. Il existe de nombreuses façons de structurer les données et de nombreuses façons d'interpréter ces modèles.
Par exemple, un modèle de conception standard utilise des dossiers de niveau supérieur qui représentent des tables. Les fichiers d'un dossier donné partagent le même schéma et contiennent des données pour cette table. Les sous-dossiers sont souvent utilisés pour représenter les partitions de table (par exemple, un sous-dossier pour chaque jour). Data Catalog fait référence à chaque dossier de niveau supérieur en tant qu'entité logique et cette entité logique est mise en correspondance avec une table externe de base de données Autonomous AI.
Connexion
Une connexion est une connexion de base de données Autonomous AI à une instance Data Catalog. Pour chaque instance de base de données Autonomous AI, il peut y avoir des connexions à plusieurs instances Data Catalog. Les informations d'identification de base de données Autonomous AI doivent disposer de droits d'accès aux ressources Data Catalog collectées à partir du stockage d'objets.
Collecte
Processus Data Catalog qui analyse le stockage d'objets et génère les entités logiques à partir de vos ensembles de données.
Ressource de données
Une ressource de données dans Data Catalog représente une source de données, qui inclut des bases de données, Oracle Object Storage, Kafka, etc. Autonomous AI Database tire parti des ressources Oracle Object Storage pour la synchronisation des métadonnées.
Entité de données
Dans Data Catalog, une entité est une collection de données telle qu'une vue ou une table de base de données, ou un fichier unique, et possède généralement de nombreux attributs qui décrivent ses données.
Entité logique
Dans les lacs de données, de nombreux fichiers comprennent généralement une seule entité logique. Par exemple, vous pouvez avoir des fichiers de parcours de navigation quotidiens, et ces fichiers partagent le même schéma et le même type de fichier.
Une entité logique Data Catalog est un groupe de fichiers Object Storage dérivés lors de la collecte en appliquant des modèles de nom de fichier créés et affectés à une ressource de données.
Objet de données
Un objet de données Data Catalog fait référence aux ressources de données et aux entités de données.
Modèle de nom de fichier
Dans un lac de données, les données peuvent être organisées de différentes manières. En général, les dossiers capturent des fichiers du même schéma et du même type. Vous devez vous inscrire à Data Catalog pour savoir comment vos données sont organisées. Les modèles de nom de fichier permettent d'identifier la façon dont vos données sont organisées. Dans Data Catalog, vous pouvez définir des modèles de nom de fichier à l'aide d'expressions régulières. Lorsque Data Catalog collecte une ressource de données avec un modèle de nom de fichier affecté, des entités logiques sont créées en fonction du modèle de nom de fichier. En définissant et en affectant ces modèles aux ressources de données, plusieurs fichiers peuvent être regroupés en tant qu'entités logiques en fonction du modèle de nom de fichier.
Synchroniser (synchroniser)
Autonomous AI Database effectue des synchronisations avec Data Catalog pour maintenir automatiquement sa base de données à jour en ce qui concerne les modifications apportées aux données sous-jacentes. La synchronisation peut être effectuée manuellement ou selon une planification.
Le processus de synchronisation crée des schémas et des tables externes en fonction des ressources de données et des entités logiques Data Catalog. Ces schémas sont protégés, ce qui signifie que leurs métadonnées sont gérées par Data Catalog. Si vous souhaitez modifier les métadonnées, vous devez effectuer les modifications dans Data Catalog. Les schémas de base de données Autonomous AI refléteront toutes les modifications après l'exécution de la prochaine synchronisation. Pour plus d'informations, reportez-vous à Mise en correspondance de la synchronisation.
Mappage de synchronisation
Le processus de synchronisation crée et met à jour les schémas de base de données Autonomous AI et les tables externes en fonction des ressources de données, des dossiers, des entités logiques, des attributs et des remplacements personnalisés pertinents de Data Catalog.
| Catalogue de données | Autonomous AI Database | Description du mappage |
|---|---|---|
| Ressource de données et dossier (bucket de stockage d'objets) | Nom de schéma | Valeurs par défaut : Par défaut, le nom de schéma généré dans la base de données Autonomous AI a le format suivant :
Personnalisations : Les valeurs par défautdata-asset-name et folder-name peuvent être personnalisées en définissant des propriétés personnalisées, des noms commerciaux et des noms d'affichage pour remplacer ces noms par défaut.
Exemples :
|
| Entité logique | Table externe | Les entités logiques sont mises en correspondance avec des tables externes. Si l'entité logique a un attribut partitionné, elle est mise en correspondance avec une table externe partitionnée. Le nom de la table externe est dérivé du nom d'affichage ou du nom fonctionnel de l'entité logique correspondante. Si Par exemple, si |
| Attributs de l'entité logique | Colonnes de la table externe | Noms de colonne : Les noms de colonne de table externe sont dérivés des noms d'affichage d'attribut ou des noms fonctionnels de l'entité logique correspondante. Pour les entités logiques dérivées des fichiers Parquet, Avro et ORC, le nom de colonne est toujours le nom d'affichage de l'attribut car il représente le nom de champ dérivé des fichiers source. Pour les attributs correspondant à une entité logique dérivée de fichiers CSV, les champs d'attribut suivants sont utilisés par ordre de priorité pour générer le nom de colonne :
Type de colonne : la propriété personnalisée Pour les attributs correspondant à une entité logique dérivée de fichiers Avro avec les types de données Longueur de colonne : la propriété personnalisée Précision de colonne : la propriété personnalisée Pour les attributs correspondant à une entité logique dérivée de fichiers Avro avec les types de données Echelle de colonne : la propriété personnalisée |
Workflow standard avec Data Catalog
Il existe un workflow standard d'actions effectuées par les utilisateurs qui souhaitent effectuer une requête avec Data Catalog.
L'administrateur Database Data Catalog crée une connexion entre l'instance Autonomous AI Database et une instance Data Catalog, puis configure et exécute une synchronisation (synchronisation) entre Data Catalog et Autonomous AI Database. La synchronisation crée des tables et des schémas externes dans l'instance de base de données Autonomous AI en fonction du contenu de Data Catalog synchronisé.
L'administrateur des requêtes de catalogue de données ou l'administrateur de base de données accorde l'accès READ aux tables externes générées afin que les analystes de données et les autres utilisateurs de base de données puissent parcourir et interroger les tables externes.
Le tableau ci-dessous décrit chaque action en détail. Pour obtenir une description des différents types d'utilisateur inclus dans ce tableau, reportez-vous à Utilisateurs et rôles Data Catalog.
Remarque
Remarque : le package DBMS_DCAT est disponible pour effectuer les tâches requises pour interroger les ressources de données de banque d'objets Data Catalog. Reportez-vous à Package DBMS_DCAT.
| Action | Qui est l'utilisateur ? | Description |
|---|---|---|
| Créer des politiques | Administrateur Database Data Catalog | Le principal de ressource de base de données Autonomous AI ou les informations d'identification utilisateur de base de données Autonomous AI doivent disposer des droits d'accès appropriés pour gérer Data Catalog et lire à partir du stockage d'objets. Plus d'informations : informations d'identification requises et stratégies IAM. |
| Créer des informations d'identification | Administrateur Database Data Catalog | Assurez-vous que les informations d'identification de base de données sont en place pour accéder à Data Catalog et interroger la banque d'objets. L'utilisateur appelle Plus d'informations : Procédure DBMS_CLOUD CREATE_CREDENTIAL Utiliser le principal de ressource avec DBMS_CLOUD. |
| Créer des connexions à Data Catalog | Administrateur Database Data Catalog | Afin de lancer une connexion entre une instance de base de données Autonomous AI et une instance Data Catalog, l'utilisateur appelle La connexion à l'instance Data Catalog doit utiliser un objet d'informations d'identification de base de données disposant de privilèges Oracle Cloud Infrastructure (OCI) suffisants. Par exemple, le jeton de service de principal de ressource pour l'instance de base de données Autonomous AI ou un utilisateur OCI disposant de privilèges suffisants peut être utilisé. Une fois la connexion établie, l'instance Data Catalog est mise à jour avec l'espace de noms Plus d'informations : Procédure SET_DATA_CATALOG_CONN, Procédure UNSET_DATA_CATALOG_CONN. |
| Créer une synchronisation sélective | Administrateur Database Data Catalog | Créez un travail de synchronisation en sélectionnant les objets Data Catalog à synchroniser. L'utilisateur peut :
Pour plus d'informations, reportez-vous à Procédure CREATE_SYNC_JOB, Procédure DROP_SYNC_JOB, Mappage de synchronisation. |
| Synchroniser avec Data Catalog | Administrateur Database Data Catalog | L'utilisateur lance une opération de synchronisation. La synchronisation est lancée manuellement via l'appel de procédure L'opération de synchronisation crée, modifie et supprime les tables et schémas externes en fonction du contenu du catalogue de données et des sélections de synchronisation. La configuration manuelle est appliquée à l'aide des propriétés personnalisées du catalogue de données. Pour plus d'informations, reportez-vous à Procédure RUN_SYNC, Procédure CREATE_SYNC_JOB, Mappage de synchronisation. |
| Surveiller les journaux de synchronisation et d'affichage | Administrateur Database Data Catalog | L'utilisateur peut visualiser le statut de synchronisation en interrogeant la vue USER_LOAD_OPERATIONS. Une fois le processus de synchronisation terminé, l'utilisateur peut consulter un journal des résultats de la synchronisation, y compris des détails sur les mappings d'entités logiques avec des tables externes.Plus d'informations : [Surveillance et dépannage des chargements](load-data-cloud-monitor.html#GUID-657A579F-CF44-458B-8C97-3E50D0C98006) |
| Accorder des privilèges | Administrateur de requête de catalogue de données de base de données, administrateur de base de données | L'administrateur de requête de catalogue de données de base de données ou l'administrateur de base de données doit accorder READ sur les tables externes générées aux utilisateurs des analystes de données. Cela permet aux analystes de données d'interroger les tables externes générées. |
| Parcourir et interroger des tables externes | Analyste de données | Les analystes de données peuvent interroger les tables externes via n'importe quel outil ou application prenant en charge Oracle SQL. Les analystes de données peuvent examiner les schémas et les tables synchronisés dans les schémas DCAT$* et interroger les tables à l'aide d'Oracle SQL. Plus d'informations : Mappage de synchronisation |
| Mettre fin aux connexions à Data Catalog | Administrateur Database Data Catalog | Pour enlever une association Data Catalog existante, l'utilisateur appelle la procédure UNSET_DATA_CATALOG_CONN. Cette action n'est effectuée que si vous ne prévoyez plus d'utiliser le catalogue de données et les tables externes dérivées du catalogue. Cette action supprime les métadonnées du catalogue de données et supprime les tables externes synchronisées de l'instance de base de données Autonomous AI. Les propriétés personnalisées des stratégies Data Catalog et OCI ne sont pas affectées. Plus d'informations : Procédure UNSET_DATA_CATALOG_CONN |
Exemple : scénario MovieStream
Dans ce scénario, Moviestream capture des données dans une zone de renvoi sur le stockage d'objets. Une grande partie de ces données, mais pas nécessairement toutes, est ensuite utilisée pour alimenter une base de données d'IA autonome. Avant d'alimenter la base de données Autonomous AI, les données sont transformées, nettoyées et ensuite stockées dans la zone "Gold".
Data Catalog est utilisé pour collecter ces sources, puis fournir un contexte métier aux données. Les métadonnées Data Catalog sont partagées avec Autonomous AI Database, ce qui permet aux utilisateurs d'Autonomous AI Database d'interroger ces sources de données à l'aide d'Oracle SQL. Ces données peuvent être chargées dans la base de données Autonomous AI ou interrogées dynamiquement à l'aide de tables externes.
Pour plus d'informations sur l'utilisation de Data Catalog, reportez-vous à la documentation Data Catalog.
-
Banque d'objets - Vérifier les buckets, les dossiers et les fichiers
-
Examinez les buckets de la banque d'objets.
Par exemple, les buckets de destination (
moviestream_landing) et de zone gold (moviestream_gold) dans le stockage d'objets sont les suivants : -
Vérifiez les dossiers et les fichiers dans les buckets de la banque d'objets.
Par exemple, les dossiers du bucket de destination (
moviestream_landing) dans le stockage d'objets sont les suivants :
-
-
Data Catalog - Créer des modèles de nom de fichier
-
Informez Data Catalog sur l'organisation des données à l'aide de modèles de nom de fichier. Il s'agit d'expressions régulières utilisées pour catégoriser les fichiers. Les modèles de nom de fichier sont utilisés par le collecteur Data Catalog pour dériver des entités logiques. Les deux modèles de nom de fichier suivants sont utilisés pour collecter les buckets dans l'exemple MovieStream. Pour plus d'informations sur la création de modèles de nom de fichier, reportez-vous à Collecte de fichiers Object Storage en tant qu'entités de données logiques.
Style Hive Style de dossier {bucketName:.*}/{logicalEntity:[^/]+}.db/{logicalEntity:[^/]+}/.*{bucketName:[\w]+}/{logicalEntity:[^/]+}(?<!.db)/.*$- Crée des entités logiques pour les sources qui contiennent ".db" comme première partie du nom de l'objet.
- Pour garantir l'unicité dans le bucket, le nom obtenu est (db-name).(nom du dossier)
- Crée une entité logique basée sur le nom du dossier hors de la racine
- Pour éviter la duplication avec Hive, les noms d'objet contenant ".db" sont ignorés.
-
Pour créer des modèles de nom de fichier, accédez à l'onglet Modèles de nom de fichier de votre catalogue de données et cliquez sur Créer un modèle de nom de fichier. Par exemple, l'onglet Créer un modèle de nom de fichier du catalogue de données
moviestreamest le suivant :
-
-
Catalogue de données - Création de ressources de données
-
Créez une ressource de données utilisée pour collecter des données à partir de votre banque d'objets.
Par exemple, une ressource de données nommée
phoenixObjStoreest créée dans le catalogue de donnéesmoviestream: -
Ajouter une connexion à votre ressource de données
Dans cet exemple, la ressource de données se connecte au compartiment de la ressource de stockage d'objet
moviestream. -
Associez maintenant vos modèles de nom de fichier à votre ressource de données. Sélectionnez Affecter des modèles de nom de fichier, vérifiez les modèles souhaités et cliquez sur Affecter.
Par exemple, voici les modèles affectés à la ressource de données
phoenixObjStore: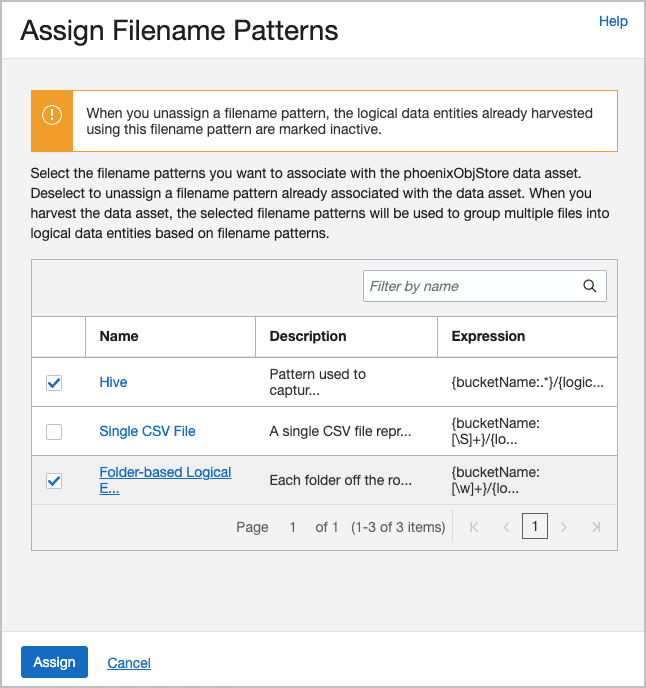
-
-
Data Catalog - Collecte de données à partir de la banque d'objets
-
Collecte de la ressource de données Data Catalog. Sélectionnez les buckets de banque d'objets contenant les données source.
Dans cet exemple, les buckets
moviestream_goldetmoviestream_landingde la banque d'objets sont sélectionnés pour la collecte. -
Une fois le travail exécuté, vous voyez les entités logiques. Utilisez Parcourir les ressources de données pour les vérifier.
Dans cet exemple, vous examinez l'entité logique
customer-extensionet ses attributs.Si vous disposez d'un glossaire, Data Catalog recommande d'associer des catégories et des termes à l'entité et à ses attributs. Cela fournit un contexte métier pour les articles. Les schémas, les tables et les colonnes ne sont souvent pas explicites.
Dans notre exemple, nous voulons faire la différence entre les différents types de buckets et la signification de leur contenu :
-
Qu'est-ce qu'une zone d'atterrissage ?
-
à quel point les données sont-elles exactes ?
-
Quand a-t-il été mis à jour pour la dernière fois ?
-
définition d'une entité logique ou de son attribut
-
-
-
Base de données d'IA autonome - Connexion à Data Catalog
Connectez la base de données Autonomous AI à Data Catalog. Vous devez vous assurer que les informations d'identification utilisées pour établir cette connexion utilisent un principal OCI autorisé à accéder à la ressource Data Catalog. Pour plus d'informations, reportez-vous à Stratégies Data Catalog et à Accès aux ressources Cloud en configurant des stratégies et des rôles.
-
Connexion à Data Catalog
-- Variables are used to simplify usage later define oci_credential = 'OCI$RESOURCE_PRINCIPAL' define dcat_ocid = 'ocid1.datacatalog.oc1.iad.aaaaaaaardp66bg....twiq' define dcat_region='us-ashburn-1' define uri_root = 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/mytenancy/b/landing/o' define uri_private = 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/mytenancy/b/private_data/o' -- Run as admin ------- -- Enable resource principal support ------- exec dbms_cloud_admin.enable_resource_principal(); -- Test to make sure credential was created. Returns a row if it was successful select * from dba_credentials where credential_name = 'OCI$RESOURCE_PRINCIPAL' and owner = 'ADMIN'; -- Query a private bucket to test the principal and privileges. select * from dbms_cloud.list_objects('&oci_credential', '&uri_private/'); -------- -- Set the credentials to use for object store and data catalog -- Connect to Data Catalog -- Review connection --------- -- Set credentials exec dbms_dcat.set_data_catalog_credential(credential_name => '&oci_credential'); exec dbms_dcat.set_object_store_credential(credential_name => '&oci_credential'); -- Connect to Data Catalog begin dbms_dcat.set_data_catalog_conn ( region => '&dcat_region', catalog_id => '&dcat_ocid'); end; / -- Review the connection select * from all_dcat_connections; -
Synchronisez Data Catalog avec Autonomous AI Database. Ici, nous synchroniserons toutes les ressources de stockage d'objets :
-- Sync Data Catalog with Autonomous AI Database ---- Let's sync all of the assets. begin dbms_dcat.run_sync('{"asset_list":["*"]}'); end; / -- View log select type, start_time, status, logfile_table from user_load_operations; -- Logfile_Table will have the name of the table containing the full log. select * from dbms_dcat$1_log; -- View the new external tables select * from dcat_entities; select * from dcat_attributes; -
Base de données Autonomous AI - Commencer à exécuter des requêtes sur la banque d'objets.
-- Query the Data ! select *from dcat$phoenixobjstore_moviestream_gold.genre ;
-
-
Modifier les schémas pour les objets
Les noms de schéma par défaut sont plutôt compliqués. Simplifions-les en indiquant l'attribut personnalisé
Oracle-Db-Schemade la ressource et du dossier dans Data Catalog. Remplacez la ressource de données parPHXet les dossiers parlandingetgoldrespectivement. Le schéma est une concaténation des deux.-
Dans Data Catalog, accédez au bucket
moviestream_landinget remplacez la ressource parlandingetgold, respectivement.Avant modification :
Après modification :
-
Exécutez une autre synchronisation.
-
Exemple : Scénario de données partitionnées
Ce scénario montre comment créer des tables externes dans la base de données Autonomous AI basées sur des entités logiques Data Catalog collectées à partir de données partitionnées dans la banque d'objets.
L'exemple suivant est basé sur l'exemple : MovieStream Scenario et a été adapté pour illustrer l'intégration aux données partitionnées. Data Catalog est utilisé pour collecter ces sources, puis fournir un contexte métier aux données. Pour plus d'informations sur cet exemple, reportez-vous à Exemple : MovieStream Scenario.
Pour plus d'informations sur l'utilisation de Data Catalog, reportez-vous à la documentation Data Catalog.
-
Banque d'objets - Vérifier les buckets, les dossiers et les fichiers
-
Examinez les buckets de la banque d'objets.
Par exemple, les buckets de destination (
moviestream_landing) et de zone gold (moviestream_gold) dans le stockage d'objets sont les suivants : -
Vérifiez les dossiers et les fichiers dans les buckets de la banque d'objets.
Par exemple, les dossiers du bucket de destination (
moviestream_landing) dans le stockage d'objets sont les suivants :
-
-
Data Catalog - Créer des modèles de nom de fichier
-
Informez Data Catalog sur l'organisation des données à l'aide de modèles de nom de fichier. Il s'agit de préfixes de dossier ou d'expressions régulières utilisés pour catégoriser les fichiers. Les modèles de nom de fichier sont utilisés par le collecteur Data Catalog pour dériver des entités logiques. Lorsqu'un préfixe de dossier est indiqué, Data Catalog génère automatiquement des entités logiques à partir du préfixe de dossier indiqué dans la banque d'objets. Le modèle de nom de fichier suivant est utilisé pour collecter les buckets dans l'exemple MovieStream. Pour plus d'informations sur la création de modèles de nom de fichier, reportez-vous à Collecte de fichiers Object Storage en tant qu'entités de données logiques.
Préfixe de dossier Description workshop.db/Crée des entités logiques pour les sources qui contiennent le chemin "workshop.db" dans la banque d'objets. -
Pour créer des modèles de nom de fichier, accédez à l'onglet Modèles de nom de fichier de votre catalogue de données et cliquez sur Créer un modèle de nom de fichier. Par exemple, l'onglet Créer un modèle de nom de fichier du catalogue de données
moviestreamest le suivant :
-
-
Catalogue de données - Création de ressources de données
-
Créez une ressource de données utilisée pour collecter des données à partir de votre banque d'objets.
Par exemple, une ressource de données nommée
amsterdamObjStoreest créée dans le catalogue de donnéesmoviestream: -
Ajouter une connexion à votre ressource de données
Dans cet exemple, la ressource de données se connecte au compartiment de la ressource de stockage d'objet
moviestream. -
Associez maintenant vos modèles de nom de fichier à votre ressource de données. Sélectionnez Affecter des modèles de nom de fichier, vérifiez les modèles souhaités et cliquez sur Affecter.
Par exemple, voici les modèles affectés à la ressource de données
amsterdamObjStore:
-
-
Data Catalog - Collecte de données à partir de la banque d'objets
-
Collecte de la ressource de données Data Catalog. Sélectionnez les buckets de banque d'objets contenant les données source.
Dans cet exemple, les buckets
moviestream_goldetmoviestream_landingde la banque d'objets sont sélectionnés pour la collecte. -
Une fois le travail exécuté, vous voyez les entités logiques. Utilisez Parcourir les ressources de données pour les vérifier.
Dans cet exemple, vous examinez l'entité logique
sales_sample_parquetet ses attributs. Data Catalog a identifié l'attributmonthcomme partitionné.
-
-
Base de données d'IA autonome - Connexion à Data Catalog
Connectez la base de données Autonomous AI à Data Catalog. Vous devez vous assurer que les informations d'identification utilisées pour établir cette connexion utilisent un principal OCI autorisé à accéder à la ressource Data Catalog. Pour plus d'informations, reportez-vous à Stratégies Data Catalog et à Accès aux ressources Cloud en configurant des stratégies et des rôles.
-
Connexion à Data Catalog
-- Variables are used to simplify usage later define oci_credential = 'OCI$RESOURCE_PRINCIPAL' define dcat_ocid = 'ocid1.datacatalog.oc1.eu-amsterdam-1....leguurn3dmqa' define dcat_region='eu-amsterdam-1' define uri_root = 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/mytenancy/b/landing/o' define uri_private = 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/mytenancy/b/private_data/o' -- Run as admin ------- -- Enable resource principal support ------- exec dbms_cloud_admin.enable_resource_principal(); -- Test to make sure credential was created. Returns a row if it was successful select * from dba_credentials where credential_name = 'OCI$RESOURCE_PRINCIPAL' and owner = 'ADMIN'; -- Query a private bucket to test the principal and privileges. select * from dbms_cloud.list_objects('&oci_credential', '&uri_private/'); -------- -- Set the credentials to use for object store and data catalog -- Connect to Data Catalog -- Review connection --------- -- Set credentials exec dbms_dcat.set_data_catalog_credential(credential_name => '&oci_credential'); exec dbms_dcat.set_object_store_credential(credential_name => '&oci_credential'); -- Connect to Data Catalog begin dbms_dcat.set_data_catalog_conn ( region => '&dcat_region', catalog_id => '&dcat_ocid'); end; / -- Review the connection select * from all_dcat_connections; -
Synchronisez Data Catalog avec Autonomous AI Database. Ici, nous synchroniserons toutes les ressources de stockage d'objets :
-- Sync Data Catalog with Autonomous AI Database ---- Let's sync all of the assets. begin dbms_dcat.run_sync('{"asset_list":["*"]}'); end; / -- View log select type, start_time, status, logfile_table from user_load_operations; -- Logfile_Table will have the name of the table containing the full log. select * from dbms_dcat$1_log; -- View the new external tables select * from dcat_entities; select * from dcat_attributes; -
Base de données Autonomous AI - Commencer à exécuter des requêtes sur la banque d'objets.
-- Query the Data ! select count(*) from DCAT$AMSTERDAMOBJSTORE_MOVIESTREAM_LANDING.SALES_SAMPLE_PARQUET; -- Examine the generated partitioned table select dbms_metadata.get_ddl('TABLE','SALES_SAMPLE_PARQUET','DCAT$AMSTERDAMOBJSTORE_MOVIESTREAM_LANDING') from dual; CREATE TABLE "DCAT$AMSTERDAMOBJSTORE_MOVIESTREAM_LANDING"."SALES_SAMPLE_PARQUET" ( "MONTH" VARCHAR2(4000) COLLATE "USING_NLS_COMP", "DAY_ID" TIMESTAMP (6), "GENRE_ID" NUMBER(20,0), "MOVIE_ID" NUMBER(20,0), "CUST_ID" NUMBER(20,0), ... ) DEFAULT COLLATION "USING_NLS_COMP" ORGANIZATION EXTERNAL ( TYPE ORACLE_BIGDATA ACCESS PARAMETERS ( com.oracle.bigdata.fileformat=parquet com.oracle.bigdata.filename.columns=["MONTH"] com.oracle.bigdata.file_uri_list="https://swiftobjectstorage.eu-amsterdam-1.oraclecloud.com/v1/tenancy/moviestream_landing/workshop.db/sales_sample_parquet/*" ... ) ) REJECT LIMIT 0 PARTITION BY LIST ("MONTH") (PARTITION "P1" VALUES (('2019-01')) LOCATION ( 'https://swiftobjectstorage.eu-amsterdam-1.oraclecloud.com/v1/tenancy/moviestream_landing/workshop.db/sales_sample_parquet/month=2019-01/*'), PARTITION "P2" VALUES (('2019-02')) LOCATION ( 'https://swiftobjectstorage.eu-amsterdam-1.oraclecloud.com/v1/tenancy/moviestream_landing/workshop.db/sales_sample_parquet/month=2019-02/*'), ...PARTITION "P24" VALUES (('2020-12')) LOCATION ( 'https://swiftobjectstorage.eu-amsterdam-1.oraclecloud.com/v1/tenancy/moviestream_landing/workshop.db/sales_sample_parquet/month=2020-12/*')) PARALLEL
-
-
Modifier les schémas pour les objets
Les noms de schéma par défaut sont plutôt compliqués. Simplifions-les en indiquant l'attribut personnalisé
Oracle-Db-Schemade la ressource et du dossier dans Data Catalog. Remplacez la ressource de données parPHXet les dossiers parlandingetgoldrespectivement. Le schéma est une concaténation des deux.-
Dans Data Catalog, accédez au bucket
moviestream_landinget remplacez la ressource parlandingetgold, respectivement.Avant modification :
Après modification :
-
Exécutez une autre synchronisation.
-