Présentation du masquage des données
Le masquage des données consiste à remplacer définitivement les données confidentielles par des données fictives mais réalistes pour protéger les informations confidentielles.
Défi
La quantité de données que les organisations collectent et gèrent, y compris les données confidentielles et personnelles, augmente tous les jours. D'importantes menaces de sécurité ont rendu nécessaire la limitation de l'exposition des données confidentielles. En même temps, différentes lois et normes sur la confidentialité des données (RGPD, PCI-DSS et HIPAA par exemple) rendent obligatoires la protection des données personnelles. Les environnements de base de données de production en direct contiennent des données importantes et confidentielles. Pour répondre aux exigences de sécurité et de conformité, vous devez protéger ces données. En général, les organisations implémentent plusieurs contrôles de sécurité dans leurs environnements de production afin de garantir un contrôle strict de l'accès aux données confidentielles.
La collecte des données vous permet probablement d'améliorer vos produits et services, de fournir une meilleure expérience utilisateur, et de soutenir et développer votre activité. Pour exploiter au mieux les données collectées, vous devez les partager avec différentes équipes, en interne et en externe, dans le cadre de différents cas d'emploi tels que le développement, le test, la formation et l'analyse des données. La copie des données de production à des fins autres que de production entraîne la prolifération des données confidentielles, étend les limites de sécurité et de conformité, et augmente la probabilité de violation des données. Si les données ne sont pas protégées, les sous-traitants ou les collaborateurs externes peuvent accéder aux données et, éventuellement, les déplacer. Les normes de confidentialité des données telles que PCI-DSS et RGPD mettent également l'accent sur la protection des informations confidentielles dans les environnements autres que de production, car ces environnements ne sont généralement pas protégés ou surveillés au même titre que les systèmes de production.
Le défi est de réduire la propagation et l'exposition inutiles des données confidentielles tout en conservant leur utilité à des fins autres que de production.
Solution
Même dans les environnements autres que de production, vous devez protéger vos données confidentielles et respecter les réglementations en matière de confidentialité des données. La solution recommandée est de masquer vos données confidentielles avant de les utiliser dans des environnements autres que de production. De cette façon, vous réduisez les données confidentielles et diminuez ainsi les limites de risque et de conformité.
Le masquage des données, également appelé masquage des données statiques, est le processus qui consiste à remplacer définitivement les données confidentielles par des données fictives réalistes. Il permet de générer des données réalistes et entièrement fonctionnelles avec des caractéristiques semblables à celles des données d'origine, dans le but de remplacer des informations sensibles ou confidentielles. Le masquage des données limite la prolifération des données confidentielles en les rendant anonymes, tout en vous permettant d'utiliser des données de type production. Il garantit qu'aucune personne malveillante ne puisse tirer parti de ces données fictives, même en cas d'accès.
Le masquage des données est idéal dans pratiquement toute situation lorsque des données confidentielles ou réglementées doivent être partagées avec des utilisateurs autres que de production. Il peut s'agir d'utilisateurs internes, tels que des développeurs d'application, ou des partenaires commerciaux externes, tels que des sociétés de test, des fournisseurs et des clients. Le masquage des données diffère du cryptage, qui masque (cache) simplement les données et où les données d'origine peuvent être extraites avec l'accès ou la clé appropriés. Avec le masquage des données, vous ne pouvez pas extraire les données confidentielles d'origine ni y accéder.
L'un des aspects clés du masquage des données consiste à remplacer les informations confidentielles par des données fictives, sans rompre la sémantique et la structure des données. Les données masquées doivent être réalistes et réussir des vérifications spécifiques, telles que la validation de Luhn. Par exemple, un numéro de carte de crédit masqué ne doit pas seulement être un numéro de carte de crédit valide, mais également un numéro de carte Visa, Mastercard, American Express ou Discover valide. L'échec du maintien de l'intégrité des données peut interrompre l'application correspondante. Les formats de masquage prédéfinis garantissent que les données générées réussissent les vérifications de validation courantes.
Exigences générales en matière de masquage de données
Les organisations masquent généralement les données à l'aide de solutions ou de scripts personnalisés. Bien que ces solutions internes puissent fonctionner pour quelques colonnes, elles ne fonctionnent pas pour les applications volumineuses avec des bases de données distribuées et des milliers de colonnes. Une solution de masquage des données d'entreprise doit pouvoir satisfaire les exigences de masquage des données suivantes :
-
Localiser les données confidentielles parmi de nombreuses applications, bases de données et environnements.
-
Masquer correctement des données confidentielles comportant des formes différentes, telles que les noms, les numéros de sécurité sociale, les adresses électroniques, les numéros de carte de crédit (Mastercard, Visa, etc.) et les groupes sanguins.
-
Garantir que les données masquées sont irréversibles, c'est-à-dire que personne ne doit être en mesure d'extraire les données d'origine à partir des données masquées.
-
Garantir que les données masquées sont assez réalistes pour pouvoir être utilisées dans des conditions autres que de production, telles que le développement et l'analyse.
-
Garantir que les applications continuent de fonctionner avec les données masquées.
Masquage des données dans Oracle Data Safe
La fonctionnalité Masquage des données d'Oracle Data Safe répond aux exigences courantes de masquage des données, et plus encore. Il simplifie le processus de masquage des données dans vos bases de données autres que de production grâce à une solution automatisée, flexible et facile à utiliser. Il permet d'effectuer les tâches suivantes :
-
Optimiser la valeur métier des données sans exposer les données confidentielles.
-
Réduire la limite de conformité en ne multipliant pas les données de production confidentielles.
-
Masquer les bases de données Oracle.
-
Utiliser différentes techniques de masquage pour répondre aux exigences spécifiques de votre entreprise.
-
Préserver l'intégrité des données en vous assurant que les données masquées continuent de fonctionner avec les applications.
Stratégies et formats de masquage
Grâce au repérage de données et au masquage des données dans Oracle Data Safe, vous pouvez masquer les données confidentielles dans les bases de données cible. Le repérage de données permet de repérer les données confidentielles et les relations référentielles (parent-enfant) dans une base de données cible, ainsi que de générer un modèle de données confidentielles contenant l'ensemble des métadonnées et des colonnes confidentielles. Le masquage des données vous permet de créer une stratégie de masquage pour le modèle de données confidentielles, puis d'appliquer cette stratégie à une base de données cible afin de masquer ses données confidentielles. Le masquage des données garantit l'intégrité référentielle en masquant de manière cohérente les colonnes associées.
Lors de la création d'une stratégie de masquage, vous devez sélectionner un format de masquage pour chaque colonne confidentielle du modèle de données confidentielles. Un format de masquage définit la logique permettant de masquer les données dans une colonne de base de données. Oracle Data Safe sélectionne automatiquement un format de masquage prédéfini par défaut pour chaque colonne confidentielle. Toutefois, vous pouvez modifier les sélections si nécessaire. Oracle Data Safe fournit un ensemble complet de formats de masquage prédéfinis pour les données personnelles et confidentielles courantes, telles que les noms, les identifiants nationaux, les numéros de carte de crédit, les numéros de téléphone et les croyances religieuses. Par exemple, le format de masquage Adresse électronique remplace les valeurs par des adresses électroniques aléatoires. Vous pouvez également créer vos propres formats de masquage, utiliser le masquage conditionnel et implémenter le masquage de groupe.
L'un des aspects clés du masquage des données consiste à remplacer les informations confidentielles par des données fictives, sans rompre la sémantique et la structure des données. Les données masquées doivent être réalistes et réussir des vérifications spécifiques, telles que la validation de Luhn. Par exemple, un numéro de carte de crédit masqué ne doit pas seulement être un numéro de carte de crédit valide, mais également un numéro de carte Visa, Mastercard, American Express ou Discover valide. L'échec du maintien de l'intégrité des données peut interrompre l'application correspondante. Les formats de masquage prédéfinis garantissent que les données générées réussissent les vérifications de validation courantes.
Comme pour les modèles de données confidentielles, Oracle Data Safe stocke vos stratégies et vos formats de masquage définis par l'utilisateur dans des compartiments d'Oracle Data Safe. Vous pouvez les déplacer d'un compartiment vers un autre et les supprimer si nécessaire. Pour appliquer des stratégies de masquage à des bases de données cible dans plusieurs régions ou simplement pour modifier manuellement des stratégies de masquage dans un éditeur de texte, vous pouvez télécharger des stratégies de masquage au format XML.
Lors de la configuration d'un travail de masquage des données, vous pouvez télécharger les scripts à exécuter sur la base de données cible avant et/ou après le travail de masquage des données. Par exemple, vous pouvez télécharger un script à exécuter avant le masquage pour créer une colonne sur la base de données cible, à utiliser pour le format de masquage Substitution déterministe. Vous pouvez également télécharger un script à exécuter après le masquage pour enlever cette colonne une fois le masquage de données terminé.
Caractéristiques des formats de masquage
Les formats de masquage de données présentent des caractéristiques. Ils peuvent notamment être combinables, réversibles et déterministes, et garantir l'unicité. Oracle Data Safe dispose d'un large éventail de formats de masquage prédéfinis et de base. Certains formats de masquage prennent en charge les caractères sur deux octets, par exemple les caractères japonais, asiatiques et cyrillique.
Combinable
Un format de masquage est considéré comme combinable lorsqu'il peut être combiné avec d'autres formats de masquage de base ou avec d'autres formats de masquage prédéfinis à l'aide de conditions.
Par exemple, supposons que vous voulez masquer une colonne contenant des données au format 999-999, où 9 représente un chiffre. Vous voulez remplacer les trois premiers chiffres par un nombre à trois chiffres fixes, conserver le trait d'union et remplacer les trois derniers chiffres par des chiffres aléatoires. Pour générer les données attendues, vous pouvez combiner trois formats de masquage de base : Nombre fixe, Chaîne fixe et Nombre aléatoire, comme illustré dans l'exemple suivant. Les résultats de ces trois formats de masquage sont concaténés afin de générer les valeurs masquées, par exemple, 678-333, 678-110, 678-656 et 678-999.
FIXED NUMBER 678
FIXED STRING "-"
RANDOM NUMBER [START:100 END: 999]Un autre exemple utilise un format de masquage de base avec un format de masquage prédéfini. Supposons que vous souhaitez masquer un numéro de sécurité sociale. La logique est la suivante : si le numéro de sécurité sociale existe, il est remplacé par un numéro de sécurité sociale prédéfini. Sinon, il est remplacé par un numéro aléatoire.
Unicité
Un format de masquage est qualifié d'unicité s'il garantit l'unicité des données masquées générées. Ce type de format de masquage est utile pour masquer les colonnes possédant des contraintes d'unicité. Par exemple, vous pouvez masquer une colonne d'ID d'employé avec des valeurs masquées d'ID uniques. Deux lignes ne peuvent pas avoir le même ID.
Réversible
Un format de masquage est réversible lorsqu'il peut extraire les données de l'ancienne colonne à partir de données masquées. Le masquage des données consiste généralement à remplacer les données de façon permanente, de manière qu'aucune donnée d'origine ne puisse être extraite. Mais vous aurez peut-être parfois besoin de consulter les données d'origine. Le masquage réversible est utile lorsque les entreprises doivent masquer et envoyer leurs données à un tiers pour l'analyse, la génération de rapports ou tout autre objectif de processus métier. Lorsque les données traitées sont renvoyées par le tiers, les données d'origine peuvent alors être récupérées. Le format de masquage Cryptage déterministe prend en charge le masquage réversible.
Déterministe
L'une des principales exigences du masquage des données dans les bases de données volumineuses ou les environnements possédant plusieurs bases de données est de masquer certaines données de manière cohérente. Pour une entrée donnée, la sortie doit toujours être la même. En même temps, la sortie masquée ne doit pas être prévisible. Le format de masquage déterministe génère un résultat cohérent pour une entrée donnée dans les bases de données et les travaux de masquage des informations. Ce masquage est utile pour conserver l'intégrité des données dans plusieurs applications et préserver l'intégrité du système dans un environnement possédant un accès avec connexion unique.
Prenons comme exemple trois applications : une application de gestion du capital humain, une application de gestion de la relation client et un entrepôt de données de vente. Ces trois applications peuvent contenir des champs clés en commun, tels que EMPLOYEE_ID, qui doivent être masqués de façon cohérente dans ces applications. Les techniques de masquage déterministe peuvent être utilisées ici pour garantir cette cohérence.
Prenons un autre exemple. Supposons que deux valeurs, Joe et Tom, sont masquées par Henry et Peter en utilisant une technique de masquage déterministe. Lorsque vous répétez cette technique sur une autre base de données, Bob et Tom (le cas échéant) peuvent être remplacés par Louise et Peter. Même si les données diffèrent d'une exécution à l'autre, Tom est toujours remplacé par Peter.
Les formats Cryptage déterministe, Substitution déterministe, Expression SQL et Fonction définie par l'utilisateur prennent en charge le masquage déterministe.
Caractéristiques de chaque format de masquage des données
| Format de masquage | Prend en charge les caractères sur deux octets* | Prend en charge les colonnes de LOB | Combinable | Déterministe | Réversible | Unicité |
|---|---|---|---|---|---|---|
| Age | Numéro - Sans objet | Non | Oui | Non | Non | Non |
| ABN (Australian Business Number) | Numéro - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Australie - Numéro de société | Numéro - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Numéro Medicare australien | Numéro - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Australie - Numéro de fournisseur Medicare | Numéro - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Australie - Numéro de fichier fiscal | Numéro - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Numéro de compte bancaire | Numéro - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Numéro d'identification de la banque | Numéro - Sans objet | Non | Oui, si les valeurs masquées générées réussissent la validation de la fonction de post-traitement | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Groupe sanguin | Non | Non | Oui | Non | Non | Non |
| Code postal du Canada | Non | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Numéro d'assurance sociale du Canada | Numéro - Sans objet | Non | Oui, si les valeurs masquées générées réussissent la validation de la fonction de post-traitement | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Numéro d'assurance sociale (avec trait d'union) du Canada | Numéro - Sans objet | Non | Oui, si les valeurs masquées générées réussissent la validation de la fonction de post-traitement | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Numéro d'identification de résident (PRC) pour la Chine | Numéro - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Numéro de carte de crédit | Numéro - Sans objet | Non | Oui, si les valeurs masquées générées réussissent la validation de la fonction de post-traitement | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Numéro de carte de crédit (conservation du type et du format) | Numéro - Sans objet | Non | Oui, si les valeurs masquées générées réussissent la validation de la fonction de post-traitement | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Numéro de carte de crédit - American Express | Numéro - Sans objet | Non | Oui, si les valeurs masquées générées réussissent la validation de la fonction de post-traitement | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Numéro de carte de crédit - Discover | Numéro - Sans objet | Non | Oui, si les valeurs masquées générées réussissent la validation de la fonction de post-traitement | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Numéro de carte de crédit - Mastercard | Numéro - Sans objet | Non | Oui, si les valeurs masquées générées réussissent la validation de la fonction de post-traitement | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Numéro de carte de crédit - Visa | Numéro - Sans objet | Non | Oui, si les valeurs masquées générées réussissent la validation de la fonction de post-traitement | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Date d'expiration de carte | Numéro - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Date passée | Numéro - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Supprimer les lignes | Numéro - Sans objet | Non | Non | Sans objet | Non | Sans objet |
| Date de cryptage déterministe | Oui | Non | Non | Oui | Oui | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF dépasse le nombre de valeurs distinctes présentes dans la colonne d'entrée et que toutes les valeurs d'entrée se situent dans la plage de format prise en charge. |
| Substitution déterministe | Oui | Non | Non | Oui, tant que les valeurs de la colonne de substitution ne changent pas et si vous indiquez la même valeur prédéfinie | Non | Non |
| Adresse électronique | Non | Non | Oui | Non | Non | Non |
| Code d'identité personnelle finlandais | Numéro - Sans objet | Non | Oui, si les valeurs masquées générées réussissent la validation de la fonction de post-traitement | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Nombre fixe | Numéro - Sans objet | Oui | Oui | Oui | Non | Non |
| Chaîne fixe | Oui | Oui | Oui | Oui | Non | Non |
| Randomisation avec conservation du format | Non | Non | Oui | Non | Non | Non |
| Sexe | Non | Non | Oui | Non | Non | Non |
| Réorganisation des groupes | Oui | Non | Non | Non | Non | Oui, ce format de masquage garantit l'unicité des colonnes dotées des contraintes uniques |
| Taille (en centimètres) | Numéro - Sans objet | Non | Oui | Non | Non | Non |
| IBAN | Alphanumérique - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| IBAN (avec tiret) | Alphanumérique - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| CIM-9-CM | Alphanumérique - Sans objet | Non | Oui | Non | Non | Non |
| CIM-10-CM | Alphanumérique - Sans objet | Non | Oui | Non | Non | Non |
| Numéro d'identification | Numéro - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Code IFSC | Alphanumérique - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Numéro IMEI | Numéro - Sans objet | Non | Oui, si les valeurs masquées générées réussissent la validation de la fonction de post-traitement | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Revenus | Numéro - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| IPv4 | Numéro - Sans objet | Non | Oui | Non | Non | Non |
| IPv6 | Alphanumérique - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Double IPv6 | Alphanumérique - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Japon Mon numéro | Numéro - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Numéro d'immatriculation de résident (RRN) pour la Corée | Numéro - Sans objet | Non | Oui | Non | Non | Non |
| Adresse Mac (séparée par des cônes) | Numéro - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Adresse Mac (séparée par des points) | Numéro - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Adresse Mac (avec tiret) | Numéro - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Situation de famille | Non | Non | Oui | Non | Non | Non |
| ID RFC de la société pour le Mexique | Alphanumérique - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Code CURP pour le Mexique | Alphanumérique - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| ID RFC individuel pour le Mexique | Alphanumérique - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Numéro de service du citoyen néerlandais (BSN) | Numéro - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Valeur NULL | Numéro - Sans objet | Oui | Non | Oui | Non | Non |
| Masquage de modèle | Non | Non | Non | Non | Non | Non |
| Fonction à effectuer après le traitement | Oui | Non | Oui | Sans objet | Sans objet | Sans objet |
| Préserver données d'origine | Oui | Non | Non | Oui | Sans objet | Si les valeurs d'origine sont uniques, elles restent uniques après le masquage |
| Origine ethnique | Non | Non | Oui | Non | Non | Non |
| Date aléatoire | Numéro - Sans objet | Non | Oui | Non | Non | Oui. Le nombre total de valeurs distinctes dans la plage indiquée doit être supérieur ou égal au nombre de valeurs dans la colonne |
| Nombre décimal aléatoire | Numéro - Sans objet | Non | Oui | Non | Non | Oui. Le nombre total de valeurs distinctes dans la plage indiquée doit être supérieur ou égal au nombre de valeurs dans la colonne |
| Chiffres aléatoires | Numéro - Sans objet | Non | Oui | Non | Non | Oui. Toutefois, si vous n'indiquez pas une plage de longueur suffisante, vous risquer de manquer de valeurs uniques dans cette plage |
| Liste aléatoire | Oui | Non | Oui | Non | Non | Oui. La liste d'entrées doit comporter des valeurs uniques et le nombre de valeurs de la liste doit être supérieur ou égal au nombre de valeurs dans la colonne à masquer. |
| Nom aléatoire | Non | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Nombre aléatoire | Numéro - Sans objet | Non | Oui | Non | Non | Oui. Le nombre de valeurs distinctes dans la plage indiquée doit être supérieur ou égal au nombre de valeurs dans la colonne |
| Chaîne aléatoire | Non | Non | Oui | Non | Non | Oui. Le nombre de valeurs distinctes dans la plage indiquée doit être supérieur ou égal au nombre de valeurs dans la colonne |
| Substitution aléatoire | Oui | Non | Non | Non | Non | Oui. Le nombre de valeurs distinctes dans la colonne de substitution doit être supérieur ou égal au nombre de valeurs dans la colonne à masquer |
| Expression régulière | Oui | Oui - Caractère (CLOB) et Caractère national (NCLOB) uniquement | Non | Non | Non | Non |
| Religion | Non | Non | Oui | Non | Non | Non |
| Orientation sexuelle | Non | Non | Oui | Non | Non | Non |
| Réorganisation | Oui | Non | Non | Non | Non | Oui, si les valeurs de colonne sont toutes uniques |
| Espagne - Numéro de Sécurité sociale | Numéro - Sans objet | Non | Oui, si les valeurs masquées générées réussissent la validation de la fonction de post-traitement | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Numéro de sécurité sociale espagnol (séparé par un éclair) | Numéro - Sans objet | Non | Oui, si les valeurs masquées générées réussissent la validation de la fonction de post-traitement | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Expression SQL | Oui. L'expression SQL fournie doit générer des caractères multioctets. | Oui | Non | Oui, en fonction de l'expression SQL définie | Non | Oui, mais l'unicité n'est pas garantie et dépend de l'expression SQL définie. Cependant, parce que ORA_HASH utilise un algorithme de 32 bits, et compte tenu du paradoxe de l'anniversaire ou du principe du pigeonhole, il y a un |
| 0,5 probabilité de collision après 232-1 valeurs uniques. | ||||||
| Stock | Numéro - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Sous-chaîne | Oui | Non | Oui | Oui | Non | Non |
| Code SWIFT/BIC (11 chiffres) | Alphanumérique - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Code SWIFT/BIC (8 chiffres) | Alphanumérique - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Tronquer les données | Oui | Non | Non | Sans objet | Sans objet | Sans objet |
| Numéro d'assurance nationale (format-réservation) (Royaume-Uni) | Alphanumérique - Sans objet | Non | Oui, si les valeurs masquées générées réussissent la validation de la fonction de post-traitement | Non | Non | Non |
| Numéro d'assurance nationale du Royaume-Uni (avec des espaces) | Numéro - Sans objet | Non | Oui, si les valeurs masquées générées réussissent la validation de la fonction de post-traitement | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Code postal du Royaume-Uni (avec des espaces) | Numéro - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| URL | Non | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| US - Numéro DEA | Alphanumérique - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Tél. (Etats-Unis) | Numéro - Sans objet | Non | Oui, si les valeurs masquées générées réussissent la validation de la fonction de post-traitement | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Numéro de téléphone des Etats-Unis (avec indicatif du pays) | Numéro - Sans objet | Non | Oui, si les valeurs masquées générées réussissent la validation de la fonction de post-traitement | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Numéro de sécurité sociale des Etats-Unis | Numéro - Sans objet | Non | Oui, si les valeurs masquées générées réussissent la validation de la fonction de post-traitement | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Numéro de sécurité sociale des Etats-Unis (avec tiret) | Numéro - Sans objet | Non | Oui, si les valeurs masquées générées réussissent la validation de la fonction de post-traitement | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Fonction définie par l'utilisateur | Oui | Non | Oui | Oui, selon la fonction définie | Non | Oui, selon la fonction définie |
| Numéro d'identification du véhicule (VIN) | Alphanumérique - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
| Poids (en livres) | Numéro - Sans objet | Non | Oui | Non | Non | Oui, si le nombre de valeurs distinctes pouvant être générées par la LMF est supérieur au nombre de valeurs distinctes dans la colonne |
*Si un format de masquage prend en charge les caractères sur deux octets, vous pouvez l'utiliser pour les caractères de langues telles que le japonais, le chinois et le cyrillique.
Tableau de bord de masquage des données
Le tableau de bord de masquage des données, comme illustré ci-dessous, fournit une vue d'ensemble des bases de données cible faisant l'objet d'un masquage dans les compartiments sélectionnés. Les deux graphiques en haut du tableau de bord se concentrent sur les cinq bases de données cible principales. Le premier graphique vous permet d'identifier les bases de données cible qui ont la plus grande concentration de colonnes masquées en affichant le pourcentage de colonnes masquées dans chacune des cinq bases de données cible principales. Le second graphique vous permet d'identifier les bases de données cible qui ont la plus grande concentration de valeurs masquées en affichant le pourcentage de valeurs masquées dans chacune des cinq cibles.
La table en dessous des graphiques présente les statistiques relatives aux bases de données cible dans les compartiments sélectionnés. Chaque base de données cible répertoriée doit avoir fait l'objet d'un masquage au moins une fois. Vous pouvez visualiser le nombre de stratégies de masquage créées pour chaque base de données cible, ainsi que le nombre de types de confidentialité masqués, de schémas masqués, de tables masquées, de colonnes masquées et de valeurs masquées qu'elle contient. S'il n'existe aucune base de données cible enregistrée et qu'il n'existe aucune donnée disponible, ces graphiques et cette table sont alimentés avec des exemples de données pour simuler un scénario réaliste mais fictif de masquage des données. Alternativement, vous pouvez choisir de sélectionner "Sample data on" ou "Sample data off" à l'aide de la bascule dans le coin supérieur droit.
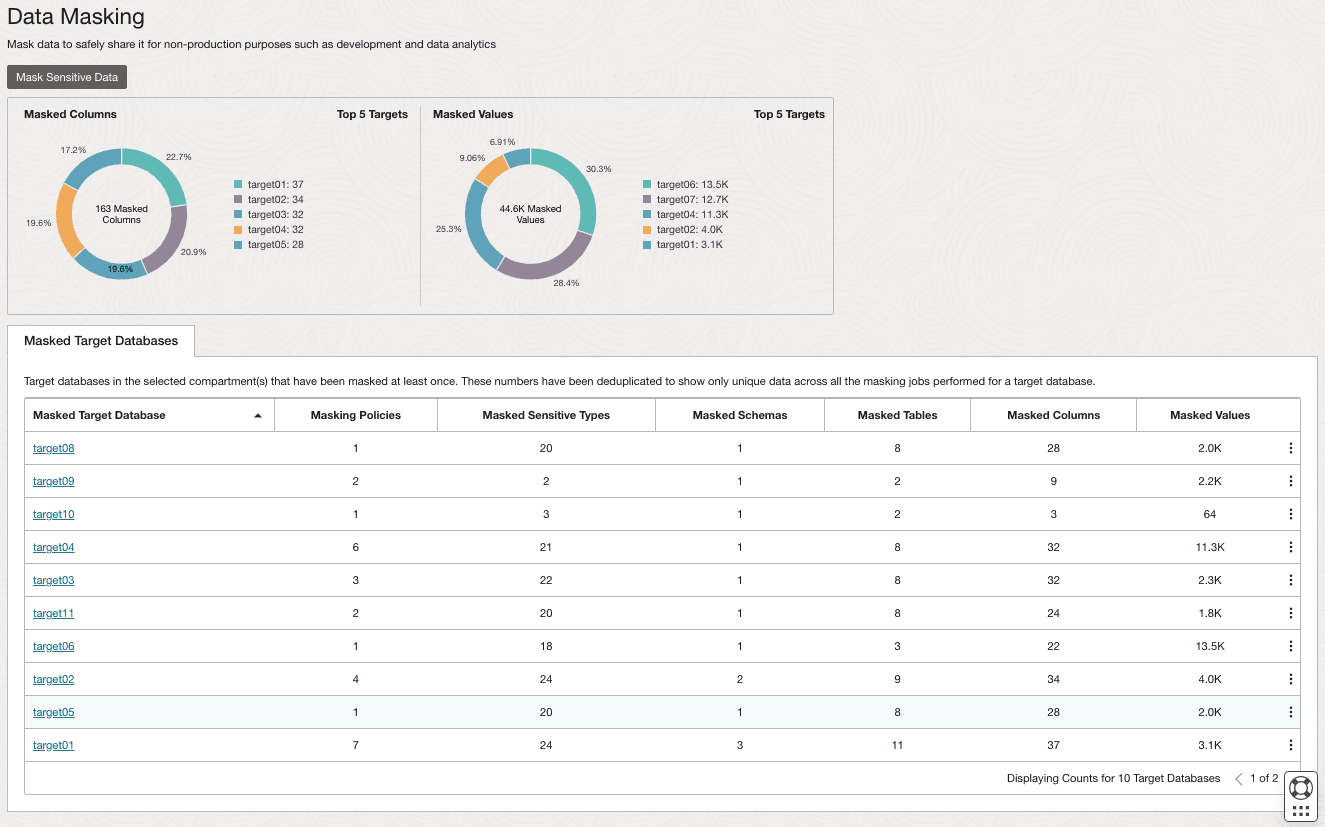
Description de l'image data-masking-dashboard.png
Vous pouvez sélectionner un nom de base de données cible pour afficher un récapitulatif de masquage qui lui est propre ainsi qu'un détail sur les stratégies de masquage associées. La capture d'écran suivante présente le récapitulatif et les détails d'une base de données cible.
Workflow de masquage des données
Oracle vous recommande d'utiliser l'approche et le workflow suivants pour masquer les données confidentielles à l'aide d'Oracle Data Safe.
-
Important : créez une sauvegarde de votre base de données de production. Par exemple, vous pouvez utiliser Recovery Manager (RMAN) et le service Oracle Cloud Storage (ou tout autre emplacement de sauvegarde) pour créer et stocker vos sauvegardes de production. Ne masquez jamais la base de données de production réelle.
-
Clonez la sauvegarde de votre base de données de production pour créer une base de données de préparation. N'exposez pas la base de données de préparation aux utilisateurs. Créez la base de données de préparation sur Oracle Cloud avec les services pris en charge.
-
Inscrivez votre base de données de préparation auprès d'Oracle Data Safe.
-
Utilisez le repérage de données pour repérer les données confidentielles dans la base de données de préparation et générer un modèle de données confidentielles.
-
Utilisez le masquage des données pour créer une stratégie de masquage qui associe des formats de masquage par défaut aux colonnes confidentielles. Vous pouvez modifier les formats selon vos besoins.
-
Exécutez une vérification de pré-masquage sur la base de données de préparation pour vérifier si elle est prête pour le masquage. Effectuer les recommandations de résolution avant de lancer un travail de masquage.
-
Exécutez un travail de masquage des données sur votre base de données de préparation pour masquer les données confidentielles à l'aide de la stratégie de masquage. Oracle Data Safe génère également un rapport sur le masquage des données qui présente les résultats du travail de masquage des données.
-
Vérifiez les données masquées en consultant le rapport Masquage des informations et en validant les données masquées.
-
Clonez la base de données de préparation pour créer une base de données test. Vous pouvez également exporter les données masquées à partir de la base de données de préparation, créer une base de données test, puis importer les données masquées dans la base de données test. Oracle recommande vivement de créer une base de données test au lieu d'accorder aux développeurs et utilisateurs de test un accès à la base de données de préparation.
-
Accordez aux développeurs et aux utilisateurs de test un accès à la base de données test.
Prérequis pour l'utilisation du masquage des données
Voici les prérequis pour utiliser le masquage des données :
-
Inscrivez les bases de données cible à utiliser avec Data Masking.
-
Accordez le rôle de masquage des données sur la base de données cible. Un administrateur de base de données peut accorder ce rôle au compte de service Oracle Data Safe sur la base de données cible.
-
Dans Oracle Cloud Infrastructure Identity and Access Management (IAM), obtenez le droit d'accès permettant d'utiliser la fonctionnalité de masquage des informations dans Oracle Data Safe. Un administrateur OCI peut accorder ces droits d'accès. Les ressources suivantes requièrent des droits d'accès :
-
data-safe-masking-policies -
data-safe-library-masking-formats -
data-safe-masking-reportsPour effectuer le masquage des données, un utilisateur aura besoin de droits d'accès
managesurdata-safe-masking-reportsdans le compartiment de la base de données cible. -
data-safe-masking-policy-health-report -
data-safe-work-requests
Au lieu d'accorder des droits d'accès de manière sélective, vous pouvez les accorder sur
data-safe-masking-familydans les compartiments pertinents. Cela inclura les droits d'accès sur toutes les ressources ci-dessus. Reportez-vous à data-safe-masking-family Resource. -
-
Les informations d'identification sont requises pour exécuter un travail de masquage uniquement si la stratégie de masquage utilise un ou plusieurs des éléments suivants. Le travail échoue si les informations d'identification ne sont pas fournies. Dans tous les autres cas, les informations d'identification sont facultatives. Les informations d'identification sont utilisées uniquement pour les vérifications préalables au masquage et l'exécution du travail de masquage.
-
Script à exécuter avant le masquage
-
Script à exécuter après le masquage
-
Format de masquage impliquant des fonctions définies par l'utilisateur (UDF), des expressions SQL ou des fonctions de post-traitement.
-