Exemples de topologies OCI GoldenGate
Avant de créer vos déploiements OCI GoldenGate, consultez ces exemples de topologies pour vous aider à planifier le nombre de ressources dont votre solution a besoin.
De combien de ressources ai-je besoin ?
Déploiements
Pour déterminer le nombre de déploiements dont votre solution a besoin, prenez en compte les types de technologies entre lesquelles vous répliquez des données.
Par exemple, si vos bases de données source et cible sont des bases de données Autonomous AI, vous n'avez besoin que d'un seul type de déploiement Oracle.

Description de l'illustration atp-adw.png ci-après
Reportez-vous à Réplication d'informations entre des bases de données cloud d'une même région.
Si vous répliquez des données entre deux technologies différentes, vous avez besoin de deux déploiements OCI GoldenGate. Par exemple, si votre base de données source est de type MySQL et que votre cible est de type Big Data, vous devez :
-
Créer un déploiement MySQL pour votre source MySQL
-
Créer un déploiement Big Data pour votre cible Big Data
Cette solution nécessite également un chemin de distribution. Pour plus de détails, reportez-vous aux exemples suivants.
Connexions
Vous devez créer une connexion pour chaque technologie source et cible, puis affecter les connexions au déploiement approprié. En utilisant l'exemple MySQL vers Big Data, vous devez :
-
Créer une connexion à la base de données MySQL source, puis l'affecter au déploiement MySQL
-
Créer une connexion au déploiement Big Data cible, puis l'affecter au déploiement Big Data
Exemple : Azure SQL Managed Instance to Autonomous AI Transaction Processing
Dans cet exemple, Azure SQL Managed Instance est la technologie source et Autonomous AI Transaction Processing (ATP) est la cible.
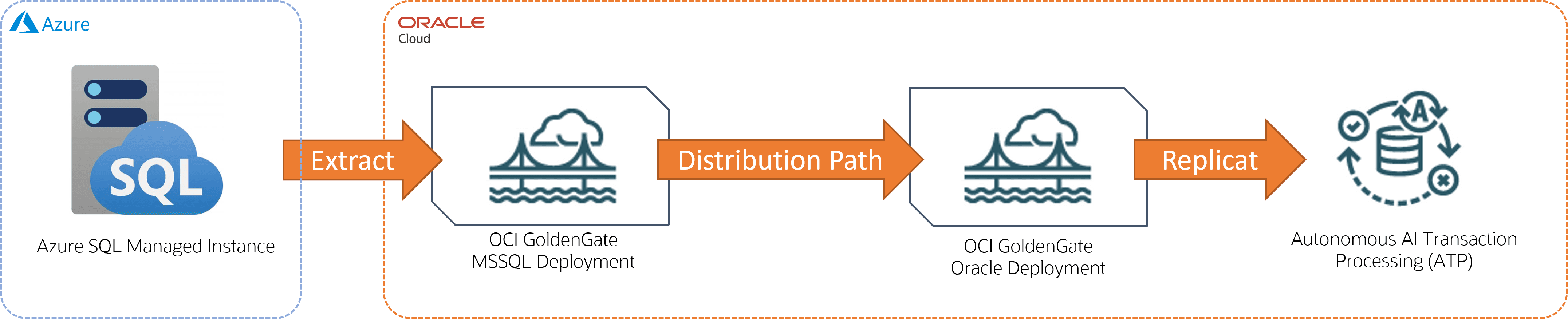
Description de l'illustration azure-atp.png ci-après
Pour ce scénario de réplication, vous devez :
-
Deux déploiements :
-
Déploiement de Microsoft SQL Server pour la base de données source
-
Déploiement Oracle pour la base de données cible
-
-
Connexions:
-
Connexion à l'instance gérée Azure SQL, puis affectation au déploiement Microsoft SQL Server
-
Connexion au traitement des transactions Autonomous AI, puis affectée au déploiement Oracle
-
-
Processus :
-
Processus Extract créé dans le déploiement source
-
Chemin de distribution créé dans le déploiement source
-
Une réplication créée dans le déploiement cible
-
Ce scénario de réplication est disponible en tant que quickstart.
Exemple : traitement des transactions d'IA autonome vers Apache Kafka
Dans cet exemple, le traitement des transactions d'IA autonome (ATP) est la technologie source et Apache Kafka est la cible.
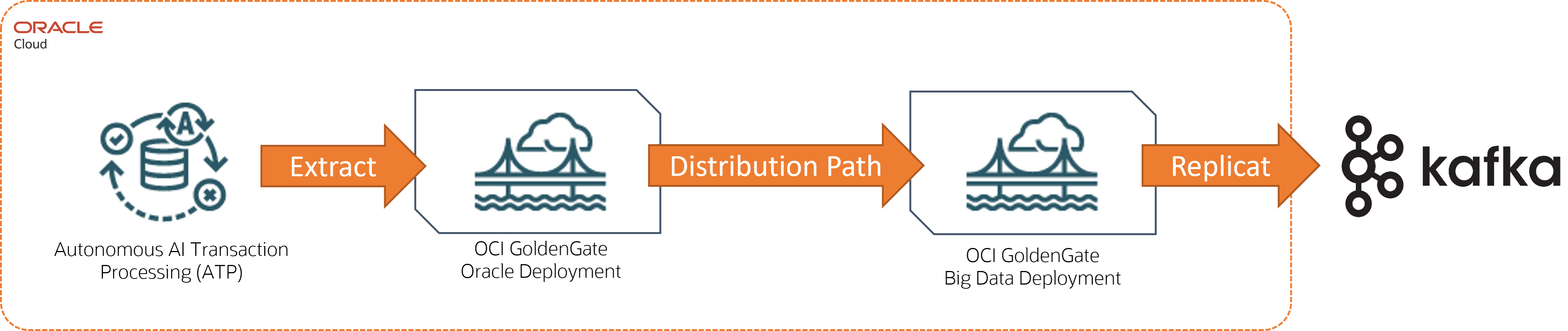
Description de l'image atp-kafka.png
Pour ce scénario de réplication, vous devez :
-
Deux déploiements :
-
Déploiement Oracle pour la base de données source
-
Un déploiement Big Data pour la technologie cible
-
-
Connexions:
-
Connexion au traitement des transactions Autonomous AI, puis affectée au déploiement Oracle
-
Connexion à Apache Kafka, puis affectation au déploiement Big Data
-
-
Processus :
-
Processus Extract créé dans le déploiement source
-
Chemin de distribution créé dans le déploiement source
-
Une réplication créée dans le déploiement cible
-
Ce scénario de réplication est disponible en tant que démarrage rapide.
Exemple : traitement des transactions PostgreSQL vers Autonomous AI
Dans cet exemple, PostgreSQL est la technologie source et le traitement des transactions d'IA autonome (ATP) est la cible.

Description de l'illustration postgres-atp.png ci-après
Pour ce scénario de réplication, vous devez :
-
Deux déploiements :
-
Déploiement PostgresSQL pour la base de données source
-
Déploiement Oracle pour la technologie cible
-
-
Connexions:
-
Une connexion à PostgreSQL, puis affectée au déploiement PostgreSQL
-
Connexion au traitement des transactions Autonomous AI, puis affectée au déploiement Oracle
-
-
Processus :
-
Processus Extract créé dans le déploiement source
-
Chemin de distribution créé dans le déploiement source
-
Une réplication créée dans le déploiement cible
-
Ce scénario de réplication est disponible en tant que démarrage rapide.
Exemple : PostgreSQL vers MySQL
Dans cet exemple, PostgreSQL est la technologie source et MySQL est la cible.

Description de l'image postgres-mysql.png
Pour ce scénario de réplication, vous devez :
-
Deux déploiements :
-
Déploiement PostgresSQL pour la base de données source
-
Déploiement MySQL pour la technologie cible
-
-
Connexions:
-
Une connexion à PostgreSQL, puis affectée au déploiement PostgreSQL
-
Connexion à MySQL, puis affectée au déploiement MySQL
-
-
Processus :
-
Processus Extract créé dans le déploiement source
-
Chemin de distribution créé dans le déploiement source
-
Une réplication créée dans le déploiement cible
-
Ce scénario de réplication est disponible en tant que démarrage rapide.
De PostgreSQL à Snowflake
Dans cet exemple, PostgreSQL est la technologie source et Snowflake est la cible.
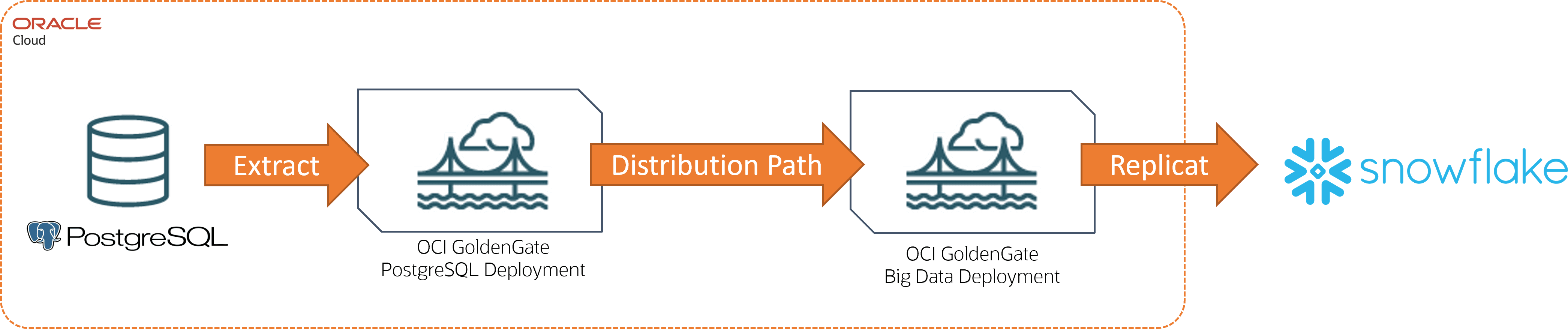
Description de l'illustration postgres-snowflake.png ci-après
Pour ce scénario de réplication, vous devez :
-
Deux déploiements :
-
Déploiement PostgresSQL pour la base de données source
-
Un déploiement Big Data pour la technologie cible
-
-
Connexions:
-
Une connexion à PostgreSQL, puis affectée au déploiement PostgreSQL
-
Une connexion à Snowflake, puis affectée au déploiement Big Data
-
-
Processus :
-
Processus Extract créé dans le déploiement source
-
Chemin de distribution créé dans le déploiement source
-
Une réplication créée dans le déploiement cible
-
Ce scénario de réplication est disponible en tant que démarrage rapide.