Utilisation d'Oracle NoSQL Database Migrator
Découvrez Oracle NoSQL Database Migrator et comment l'utiliser pour la migration de données.
Oracle NoSQL Database Migrator est un outil qui vous permet de migrer des tables Oracle NoSQL d'une source de données à une autre. Cet outil peut fonctionner sur des tables dans Oracle NoSQL Database Cloud Service, Oracle NoSQL Database on-premise et AWS S3. L'outil Migrator prend en charge plusieurs formats de données et types de média physique différents. Les formats de données pris en charge sont les fichiers JSON, Parquet, JSON au format MongoDB, JSON au format DynamoDB et CSV. Les types de support physique pris en charge sont les fichiers, OCI Object Storage, Oracle NoSQL Database sur site, Oracle NoSQL Database Cloud Service et AWS S3.
Cet article comprend les rubriques suivantes :
Présentation
Oracle NoSQL Database Migrator vous permet de déplacer des tables Oracle NoSQL d'une source de données à une autre, telles qu'Oracle NoSQL Database sur site ou dans le cloud, ou même un fichier JSON simple.
Il peut arriver que vous deviez migrer des tables NoSQL depuis ou vers une instance Oracle NoSQL Database. Par exemple, une équipe de développeurs qui améliorent une application NoSQL Database peut vouloir tester le code mis à jour dans l'instance Oracle NoSQL Database Cloud Service (NDCS) locale à l'aide de Cloudsim. Pour vérifier tous les cas de test possibles, ils doivent configurer des données de test similaires aux données réelles. Pour ce faire, ils doivent copier les tables NoSQL de l'environnement de production vers leur instance NDCS locale, l'environnement cloudsim. Dans un autre cas, les développeurs NoSQL peuvent avoir besoin de déplacer leurs données d'application d'un environnement on-premise vers le cloud, et inversement, à des fins de développement ou de test.
Dans de tels cas, et bien d'autres encore, vous pouvez utiliser Oracle NoSQL Database Migrator pour déplacer vos tables NoSQL d'une source de données à une autre, comme Oracle NoSQL Database on-premise ou dans le cloud, ou même un fichier JSON simple. Vous pouvez également copier des tables NoSQL à partir d'un fichier d'entrée JSON au format MongoDB, d'un fichier d'entrée JSON au format DynamoDB (stocké dans une source AWS S3 ou à partir de fichiers), ou d'un fichier CSV dans votre base de données NoSQL sur site ou dans le cloud.
Comme illustré dans la figure suivante, l'utilitaire NoSQL Database Migrator agit comme un connecteur ou un canal entre la source de données et la cible (appelé récepteur). En substance, cet utilitaire exporte les données de la source sélectionnée et les importe dans le puits. Cet outil est orienté table, c'est-à-dire que vous ne pouvez déplacer les données qu'au niveau table. Une seule tâche de migration fonctionne sur une seule table et prend en charge la migration des données de table de la source vers le récepteur dans différents formats de données.
Oracle NoSQL Database Migrator est conçu pour prendre en charge d'autres sources et puits à l'avenir. Pour obtenir la liste des sources et des puits pris en charge par Oracle NoSQL Database Migrator à partir de la version actuelle, reportez-vous à Sources et puits pris en charge. 
Description de l'illustration migrator_overview.png ci-après
Terminologie utilisée avec Oracle NoSQL Database Migrator
En savoir plus sur les différents termes utilisés dans le diagramme ci-dessus, en détail.
-
Source : entité à partir de laquelle les tables NoSQL sont exportées pour migration. Voici quelques exemples de sources : Oracle NoSQL Database sur site ou dans le cloud, fichier JSON, fichier JSON au format MongoDB, fichier JSON au format DynamoDB et fichiers CSV.
-
Disque : entité qui importe les tables NoSQL à partir de NoSQL Database Migrator. Voici quelques exemples de puits : Oracle NoSQL Database on-premise ou cloud et fichier JSON.
L'outil NoSQL Database Migrator prend en charge différents types de sources et de puits (c'est-à-dire des supports physiques ou des référentiels de données) et formats de données (c'est-à-dire la façon dont les données sont représentées dans la source ou le puits). Les formats de données pris en charge sont les fichiers JSON, Parquet, JSON au format MongoDB, JSON au format DynamoDB et CSV. Les types de source et de récepteur pris en charge sont les fichiers, OCI Object Storage, Oracle NoSQL Database sur site et Oracle NoSQL Database Cloud Service.
-
Tuyau de migration : les données d'une source seront transférées vers le récepteur par NoSQL Database Migrator. Cela peut être visualisé comme un tuyau de migration.
-
Transformations : vous pouvez ajouter des règles pour modifier les données de table NoSQL dans le canal de migration. Ces règles sont appelées transformations. Oracle NoSQL Database Migrator autorise uniquement les transformations de données au niveau des champs ou des colonnes de niveau supérieur. Elle ne vous permet pas de transformer les données des champs imbriqués. Voici quelques exemples de transformations autorisées :
-
Supprimer ou ignorer une ou plusieurs colonnes,
-
Renommez une ou plusieurs colonnes ou
-
Regroupez plusieurs colonnes en un seul champ, généralement un champ JSON.
-
-
Fichier de configuration : un fichier de configuration permet de définir tous les paramètres requis pour l'activité de migration au format JSON. Par la suite, vous transmettez ce fichier de configuration en tant que paramètre unique à la commande
runMigratorà partir de l'interface de ligne de commande. Un format de fichier de configuration standard se présente comme indiqué ci-dessous.{ "source": { "type" : <source type>, //source-configuration for type. }, "sink": { "type" : <sink type>, //sink-configuration for type. }, "transforms" : { //transforms configuration. }, "migratorVersion" : "<migrator version>", "abortOnError" : <true|false> }Grouper Paramètres Obligatoire (O/N) Description Valeurs prises en charge sourcetypeY (Oui) Représente la source à partir de laquelle migrer les données. La source fournit des données et des métadonnées (le cas échéant) pour la migration. Pour connaître la valeur typepour chaque source, reportez-vous à la section Supported Sources and Sinks.sourceconfiguration source pour le type Y (Oui) Définit la configuration de la source. Ces paramètres de configuration sont spécifiques au type de source sélectionné ci-dessus. Pour obtenir la liste complète des paramètres de configuration pour chaque type de source, reportez-vous à Modèles de configuration source. sinktypeY (Oui) Représente le récepteur vers lequel migrer les données. Le récepteur est la cible ou la destination de la migration. Pour connaître la valeur typepour chaque source, reportez-vous à la section Supported Sources and Sinks.sinksink-configuration pour le type Y (Oui) Définit la configuration de l'évier. Ces paramètres de configuration sont spécifiques au type d'évier sélectionné ci-dessus. Pour obtenir la liste complète des paramètres de configuration de chaque type de récepteur, reportez-vous à la section Sink Configuration Templates. transformstransforms configuration N Définit les transformations à appliquer aux données du canal de migration. Pour obtenir la liste complète des transformations prises en charge par NoSQL Data Migrator, reportez-vous à Modèles de configuration de transformation. - migratorVersionN Version de l'outil de migration de données NoSQL - - abortOnErrorN Indique si l'activité de migration doit être arrêtée en cas d'erreur.
La valeur par défaut est true, ce qui indique que la migration s'arrête chaque fois qu'elle rencontre une erreur de migration.
Si vous définissez cette valeur sur false, la migration se poursuit même en cas d'échec d'enregistrements ou d'autres erreurs de migration. Les enregistrements en échec et les erreurs de migration seront consignés en tant qu'avertissements sur le terminal CLI.true, false
Remarque : étant donné que le fichier JSON est sensible à la casse, tous les paramètres définis dans le fichier de configuration sont sensibles à la casse, sauf indication contraire.
Sources et récepteurs pris en charge
Cette rubrique fournit la liste des sources et des puits pris en charge par le migrateur Oracle NoSQL Database.
Vous pouvez utiliser n'importe quelle combinaison d'une source valide et d'un récepteur de cette table pour l'activité de migration. Toutefois, vous devez vous assurer qu'au moins l'une des extrémités, c'est-à-dire la source ou le récepteur, doit être un produit Oracle NoSQL. Vous ne pouvez pas utiliser NoSQL Database Migrator pour déplacer les données de table NoSQL d'un fichier à un autre.
| Type (valeur) | Format (valeur) | Source valide | Evier valide |
|---|---|---|---|
Oracle NoSQL Database (nosqldb) |
S/O | Y (Oui) | Y (Oui) |
Oracle NoSQL Database Cloud Service (nosqldb_cloud) |
S/O | Y (Oui) | Y (Oui) |
Système de fichiers (file) |
JSON (json) |
Y (Oui) | Y (Oui) |
Système de fichiers (file) |
JSON MongoDB (mongodb_json) |
Y (Oui) | N |
Système de fichiers (file) |
JSON DynamoDB (dynamodb_json) |
Y (Oui) | N |
Système de fichiers (file) |
Parquet (parquet) |
N | Y (Oui) |
Système de fichiers (file) |
CSV (csv) |
Y (Oui) | N |
OCI Object Storage (object_storage_oci) |
JSON (json) |
Y (Oui) | Y (Oui) |
OCI Object Storage (object_storage_oci) |
JSON MongoDB (mongodb_json) |
Y (Oui) | N |
OCI Object Storage (object_storage_oci) |
Parquet (parquet) |
N | Y (Oui) |
OCI Object Storage (object_storage_oci) |
CSV (csv) |
Y (Oui) | N |
| AWS S3 | JSON DynamoDB (dynamodb_json) |
Y (Oui) | N |
Remarque : De nombreux paramètres de configuration sont communs à la configuration source et de récepteur. Pour plus de commodité, la description de ces paramètres est répétée pour chaque source et puits dans les sections de documentation, qui expliquent les formats des fichiers de configuration pour différents types de sources et de puits. Dans tous les cas, la syntaxe et la sémantique des paramètres portant le même nom sont identiques.
Sécurité des sources et des récepteurs
Certains types de source et de récepteur ont des informations de sécurité facultatives ou obligatoires à des fins d'authentification.
Toutes les sources et tous les puits qui utilisent des services dans Oracle Cloud Infrastructure (OCI) peuvent utiliser certains paramètres pour fournir des informations de sécurité facultatives. Ces informations peuvent être fournies à l'aide d'un fichier de configuration OCI ou du principal d'instance.
Les sources et les puits Oracle NoSQL Database nécessitent des informations de sécurité obligatoires si l'installation est sécurisée et utilise une authentification basée sur Oracle Wallet. Ces informations peuvent être fournies en ajoutant un fichier JAR au répertoire <MIGRATOR_HOME>/lib.
Authentification à l'aide de principaux d'instance
Les principaux d'instance sont une fonctionnalité de service IAM qui permet aux instances d'être des acteurs autorisés (ou principaux) pouvant effectuer une action sur les ressources de service. Chaque instance de calcul possède sa propre identité et est authentifiée à l'aide des certificats qu'elle lui a ajoutés.
Oracle NoSQL Database Migrator fournit une option permettant de se connecter à des sources et des puits NoSQL Cloud et OCI Object Storage à l'aide de l'authentification par principal d'instance. Elle n'est prise en charge que lorsque l'outil NoSQL Database Migrator est utilisé dans une instance de calcul OCI, par exemple, l'outil NoSQL Database Migrator exécuté sur une machine virtuelle hébergée sur OCI. Pour activer cette fonctionnalité, utilisez l'attribut useInstancePrincipal du fichier de configuration source et de récepteur NoSQL Cloud. Pour plus d'informations sur les paramètres de configuration des différents types de sources et de puits, reportez-vous aux sections Source Configuration Templates et Sink Configuration Templates.
Pour plus d'informations sur les principaux d'instance, reportez-vous à Appel de services à partir d'une instance.
Autorisation dans les sources et les puits Oracle NoSQL Database Cloud Service
L'accès aux ressources dans Oracle NoSQL Database Cloud Service, telles que les tables, les tablespaces et les API, est géré via des stratégies Identity and Access Management (IAM). Ainsi, seuls les utilisateurs ou les applications disposant des droits d'accès de table appropriés à inspecter, lire, utiliser ou gérer au sein d'un compartiment spécifique peuvent interagir avec ces ressources. Pour plus d'informations, voir Gestion de l'accès aux tables NDCS.
Lorsque vous utilisez l'utilitaire de migration pour importer ou exporter des données à partir de tables Oracle NoSQL Database Cloud Service, vos droits d'accès IAM effectifs déterminent les ressources à partir desquelles vous pouvez lire ou écrire. Si un utilisateur d'un groupe défini tente une action au-delà de ses privilèges autorisés, l'utilitaire de migration renvoie l'erreur d'autorisation correspondante, telle que fournie par OCI IAM.
Par exemple, OCI IAM refuse toute tentative d'import de données dans une table Oracle NoSQL Database Cloud Service si votre groupe d'utilisateurs dispose uniquement du droit d'accès en lecture sur la table. Un message d'erreurs semblable au suivant s'affiche dans les journaux :
[INSUFFICIENT_PERMISSION] Authorization failed or requested resource not foundWorkflow pour Oracle NoSQL Database Migrator
Découvrez les différentes étapes à suivre pour migrer vos données NoSQL à l'aide de l'utilitaire de migration Oracle NoSQL Database.
Le flux de haut niveau des tâches impliquées dans l'utilisation de NoSQL Database Migrator est illustré dans la figure ci-dessous.
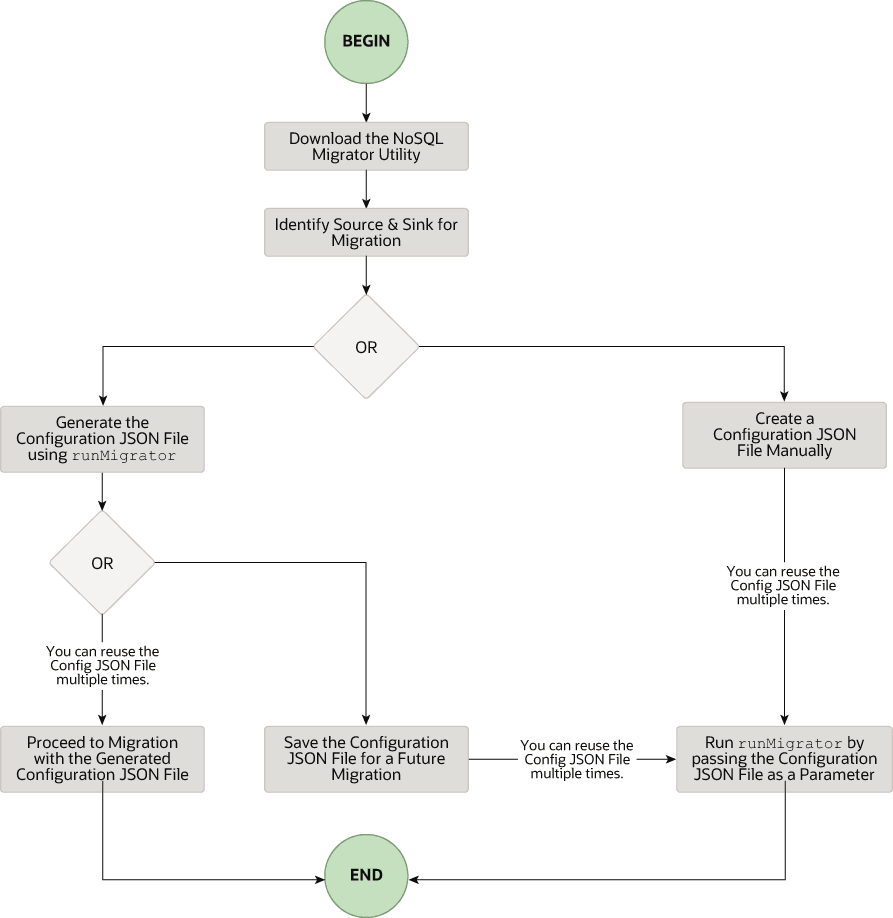
Description de l'illustration migrator_flow.png ci-après
Télécharger l'utilitaire NoSQL Data Migrator
L'utilitaire de migration Oracle NoSQL Database peut être téléchargé à partir de la page Téléchargements Oracle NoSQL. Une fois que vous l'avez téléchargé et décompressé sur votre ordinateur, vous pouvez accéder à la commande runMigrator à partir de l'interface de ligne de commande.
Remarque : l'utilitaire de migration Oracle NoSQL Database requiert l'exécution de Java 11 ou de versions supérieures.
Identifier la source et l'évier
Avant d'utiliser le migrateur, vous devez identifier la source de données et le récepteur. Par exemple, si vous souhaitez migrer une table NoSQL à partir d'Oracle NoSQL Database sur site vers un fichier au format JSON, votre source sera Oracle NoSQL Database et le récepteur sera un fichier JSON. Assurez-vous que la source et le récepteur identifiés sont pris en charge par le migrateur Oracle NoSQL Database en faisant référence aux sources et aux puits pris en charge. Il s'agit également d'une phase appropriée pour déterminer le schéma de la table NoSQL dans la cible ou le récepteur, et pour les créer.
-
Identifier le schéma de table de récepteur : si le récepteur est Oracle NoSQL Database sur site ou dans le cloud, vous devez identifier le schéma de la table de récepteur et vous assurer que les données source correspondent au schéma cible. Si nécessaire, utilisez des transformations pour mettre en correspondance les données source avec la table de récepteur.
-
Schéma par défaut : NoSQL Database Migrator permet de créer une table de récepteur avec le schéma par défaut sans avoir à prédéfinir le schéma de la table.
JSON au format MongoDB :
Si la source est un fichier JSON au format MongoDB, le schéma par défaut de la table sera le suivant :
CREATE TABLE IF NOT EXISTS <tablename>(id STRING, document JSON,PRIMARY KEY(SHARD(id))Où :
-
tablename = valeur fournie pour l'attribut de table dans la configuration.
-
id = valeur _id de chaque document du fichier source JSON exporté par MongoDB.
-
document = Pour chaque document du fichier exporté MongoDB, le contenu excluant le champ
_idest agrégé dans la colonne du document.
Remarque :
- Si la valeur _id n'est pas fournie en tant que chaîne dans le fichier JSON au format MongoDB, NoSQL Database Migrator la convertit en chaîne avant de l'insérer dans le schéma par défaut.
- Si la table
<tablename>existe déjà dans Oracle NoSQL Database on-premise ou dans le cloud et que vous voulez migrer des données vers la table à l'aide de la configurationdefaultSchema, vous devez vous assurer que la table existante comporte la colonne ID en minuscules (ID) et est de type STRING.
JSON au format DynamoDB :
Si la source est un fichier JSON au format DynamoDB, le schéma par défaut de la table sera le suivant :
CREATE TABLE IF NOT EXISTS <tablename>(DDBPartitionKey_name DDBPartitionKey_type, [DDBSortKey_name DDBSortKey_type],DOCUMENT JSON, PRIMARY KEY(SHARD(DDBPartitionKey_name),[DDBSortKey_name]))Où :
-
tablename = valeur fournie pour la table sink dans la configuration
-
DDBPartitionKey_name = valeur fournie pour la clé de partition dans la configuration
-
DDBPartitionKey_type = valeur fournie pour le type de données de la clé de partition dans la configuration
-
DDBSortKey_name = valeur fournie pour la clé de tri dans la configuration, le cas échéant
-
DDBSortKey_type = valeur fournie pour le type de données de la clé de tri dans la configuration, le cas échéant
-
DOCUMENT = Tous les attributs à l'exception de la clé de partitionnement et de tri d'un élément de table DynamoDB agrégé en une colonne NoSQL JSON
Si le format source est un fichier CSV, aucun schéma par défaut n'est pris en charge pour la table cible. Vous pouvez créer un fichier de schéma avec une définition de table contenant le même nombre de colonnes et le même type de données que le fichier CSV source. Pour plus d'informations sur la création du fichier de schéma, reportez-vous à Fourniture d'un schéma de table.
Autres sources valides :
Pour toutes les autres sources, le schéma par défaut est le suivant :
CREATE TABLE IF NOT EXISTS <tablename> (id LONG GENERATED ALWAYS AS IDENTITY, document JSON, PRIMARY KEY(id))Où :
-
tablename = valeur fournie pour l'attribut de table dans la configuration.
-
id = Valeur LONG générée automatiquement.
-
document = L'enregistrement JSON fourni par la source est agrégé dans la colonne de document.
-
-
-
Fourniture d'un schéma de table : NoSQL Database Migrator permet à la source de fournir des définitions de schéma pour les données de table à l'aide de l'attribut schemaInfo. L'attribut schemaInfo est disponible dans toutes les sources de données qui n'ont pas encore de schéma implicite défini. Les banques de données de récepteur peuvent choisir l'une des options suivantes.
-
Utilisez le schéma par défaut défini par NoSQL Database Migrator.
-
Utilisez le schéma fourni par la source.
-
Remplacez le schéma fourni par la source en définissant son propre schéma. Par exemple, si vous souhaitez transformer les données du schéma source en un autre schéma, vous devez remplacer le schéma fourni par la source et utiliser la fonction de transformation de l'outil NoSQL Database Migrator.
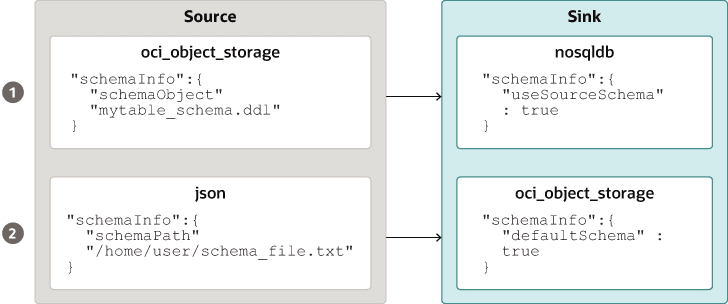
Description de l'illustration source_sink_schema_example.png
Le fichier de schéma de table, par exemple,
mytable_schema.ddlpeut inclure des instructions LDD de table. L'outil NoSQL Database Migrator exécute ce fichier de schéma de table avant de lancer la migration. L'outil de migration ne prend en charge qu'une seule instruction LDD par ligne dans le fichier de schéma. Exemple :CREATE TABLE IF NOT EXISTS(id INTEGER, name STRING, age INTEGER, PRIMARY KEY(SHARD(ID))) -
Remarque : la migration échoue si la table est présente au niveau du récepteur et que le script LDD dans le fichier schemaPath est différent de la table.
- Créer une table de récepteur : une fois que vous avez identifié le schéma de la table de récepteur, créez la table de récepteur via l'interface de ligne de commande d'administration ou à l'aide de l'attribut
schemaInfodu fichier de configuration de récepteur. Reportez-vous à Modèles de configuration de récepteur.
Remarque : si la source est un fichier CSV, créez un fichier avec les commandes LDD pour le schéma de la table cible. Indiquez le chemin d'accès au fichier dans le paramètre schemaInfo.schemaPath du fichier de configuration du récepteur.
Exécutez la commande runMigrator.
Le fichier exécutable runMigrator est disponible dans les fichiers NoSQL Database Migrator extraits. Vous devez installer Java 11 ou une version supérieure et bash sur votre système pour pouvoir exécuter la commande runMigrator.
Vous pouvez exécuter la commande runMigrator de deux manières :
-
En créant le fichier de configuration à l'aide des options d'exécution de la commande
runMigrator, comme indiqué ci-dessous.[~]$ ./runMigrator configuration file is not provided. Do you want to generate configuration? (y/n) [n]: y ... ...-
Lorsque vous appelez l'utilitaire
runMigrator, il fournit une série d'options d'exécution et crée le fichier de configuration en fonction de vos choix pour chaque option. -
Une fois que l'utilitaire a créé le fichier de configuration, vous pouvez soit poursuivre l'activité de migration au cours de la même exécution, soit enregistrer le fichier de configuration pour une migration future.
-
Quelle que soit votre décision de poursuivre ou de différer l'activité de migration avec le fichier de configuration généré, le fichier sera disponible pour les modifications ou la personnalisation afin de répondre à vos besoins futurs. Vous pouvez utiliser le fichier de configuration personnalisé pour la migration ultérieurement.
-
-
En transmettant un fichier de configuration créé manuellement (au format JSON) comme paramètre d'exécution à l'aide de l'option
-cou--config. Vous devez créer le fichier de configuration manuellement avant d'exécuter la commanderunMigratoravec l'option-cou--config. Pour obtenir de l'aide sur les paramètres de configuration de source et de récepteur, reportez-vous à Référence Oracle NoSQL Database Migrator.[~]$ ./runMigrator -c </path/to/the/configuration/json/file>
Remarque : NoSQL Database Migrator utilise des unités de lecture lors de l'export de données à partir d'une table Oracle NoSQL Cloud Service vers n'importe quel lien valide.
Journalisation de la progression du migrateur
L'outil NoSQL Database Migrator fournit des options qui permettent d'afficher les messages de trace, de débogage et de progression dans une sortie standard ou dans un fichier. Cette option peut être utile pour suivre la progression de l'opération de migration, en particulier pour les tables ou les jeux de données très volumineux.
-
Niveaux de journalisation
Pour contrôler le comportement de journalisation via l'outil NoSQL Database Migrator, transmettez le paramètre d'exécution -log-level ou -l à la commande
runMigrator. Vous pouvez indiquer la quantité d'informations de journal à écrire en transmettant la valeur de niveau de journalisation appropriée.$./runMigrator --log-level <loglevel>Par exemple :
$./runMigrator --log-level debugTableau - Niveaux de journalisation pris en charge pour NoSQL Database Migrator
Niveau de journalisation Description avertissement Imprime les erreurs et les avertissements. info (default) Imprime le statut de progression de la migration des données, tel que la validation de la source, la validation du récepteur, la création de tables et le nombre d'enregistrements de données migrés. debug Imprime des informations de débogage supplémentaires. all Imprime tout. Ce niveau active tous les niveaux de journalisation. -
Fichier journal:
Vous pouvez spécifier le nom du fichier journal à l'aide du paramètre –log-file ou -f. Si –log-file est transmis en tant que paramètre d'exécution à la commande
runMigrator, NoSQL Database Migrator écrit tous les messages de journal dans le fichier else vers la sortie standard.$./runMigrator --log-file <log file name>Par exemple :
$./runMigrator --log-file nosql_migrator.log
Limitation
Oracle NoSQL Database Migrator ne verrouille pas la base de données lors de la sauvegarde et ne bloque pas les autres utilisateurs. Par conséquent, il est fortement recommandé de ne pas effectuer les activités suivantes lorsqu'une tâche de migration est en cours d'exécution :
-
Toutes les opérations LMD/DLD sur la table source.
-
Toute modification liée à la topologie sur le magasin de données.
Migrer les métadonnées de durée de vie pour les lignes de table
Découvrez comment migrer des données de durée de vie de la source vers le récepteur.
Time to Live (TTL) est un mécanisme qui vous permet de faire expirer automatiquement les lignes du tableau. La durée de Vie est exprimée sous la formes d'une durée pendant laquelle les données sont autorisées à résider dans la banque. Les données qui ont atteint leur valeur de délai d'expiration ne peuvent plus être extraites et n'apparaîtront dans aucune statistique de stockage.
Vous pouvez choisir d'inclure les métadonnées de durée de vie des lignes de table avec les données réelles lors de la migration des tables Oracle NoSQL Database. NoSQL Database Migrator fournit des paramètres de configuration pour la prise en charge de l'export et de l'import des métadonnées de durée de vie des lignes de table pour les types de source suivants :
Table - Migration des métadonnées de durée de vie
| Types de source | Paramètre de configuration source | Paramètre de configuration du récepteur |
|---|---|---|
| Oracle NoSQL Database | includeTTL |
includeTTL |
| Oracle NoSQL Database Cloud Service | includeTTL |
includeTTL |
| Fichier JSON formaté DynamoDB | ttlAttributeName |
includeTTL |
| Fichier JSON formaté DynamoDB stocké dans AWS S3 | ttlAttributeName |
includeTTL |
Export de métadonnées de durée de vie dans Oracle NoSQL Database et Oracle NoSQL Database Cloud Service
NoSQL Database Migrator fournit le paramètre de configuration includeTTL pour la prise en charge de l'export des métadonnées de durée de vie des lignes de table.
Lorsqu'une table est exportée, les données de durée de vie sont exportées pour les lignes de table dont le délai d'expiration est valide. Si une ligne n'expire pas, l'objet JSON _metadata n'est pas inclus explicitement dans les données exportées car sa valeur d'expiration est toujours
- NoSQL Database Migrator exporte le délai d'expiration de chaque ligne en millisecondes depuis l'époque UNIX (1er janvier 1970). Exemple :
//Row 1
{
"id" : 1,
"name" : "xyz",
"age" : 45,
"_metadata" : {
"expiration" : 1629709200000 //Row Expiration time in milliseconds
}
}
//Row 2
{
"id" : 2,
"name" : "abc",
"age" : 52,
"_metadata" : {
"expiration" : 1629709400000 //Row Expiration time in milliseconds
}
}
//Row 3 No Metadata for below row as it will not expire
{
"id" : 3,
"name" : "def",
"age" : 15
}Import des métadonnées de durée de vie
Vous pouvez éventuellement importer des métadonnées de durée de vie à l'aide du paramètre de configuration includeTTL dans le modèle de configuration du récepteur.
L'heure de référence par défaut de l'opération d'import est l'heure actuelle, en millisecondes, obtenue à partir de System.currentTimeMillis(), de l'ordinateur sur lequel l'outil NoSQL Database Migrator est exécuté. Toutefois, vous pouvez également définir une heure de référence personnalisée à l'aide du paramètre de configuration ttlRelativeDate si vous souhaitez prolonger la durée d'expiration et importer des lignes qui, autrement, expireraient immédiatement. L'extension est calculée comme suit et ajoutée au délai d'expiration.
Extended time = expiration time - reference timeL'opération d'import gère les cas d'utilisation suivants lors de la migration de lignes de table contenant des métadonnées de durée de vie. Ces cas d'utilisation ne sont applicables que lorsque le paramètre de configuration includeTTL est défini sur True.
-
Cas d'utilisation 1 : aucune information sur les métadonnées de durée de vie n'est présente dans la ligne de la table d'import.
Si la ligne que vous voulez importer ne contient pas d'informations sur la durée de vie, NoSQL Database Migrator définit la durée de vie = 0 pour la ligne.
-
Cas d'emploi 2 : la valeur de durée de vie de la ligne de la table source a expiré par rapport à l'heure de référence à laquelle la ligne de la table est importée.
La ligne de table expirée est ignorée et n'est pas écrite dans le magasin.
-
Cas d'emploi 3 : la valeur de durée de vie de la ligne de la table source n'a pas expiré par rapport à l'heure de référence à laquelle la ligne de la table est importée.
La ligne du tableau est importée avec une valeur de durée de vie. Cependant, la valeur de durée de vie importée peut ne pas correspondre à la valeur de durée de vie exportée d'origine en raison des contraintes de fenêtre d'heure et de jour entières dans la classe TimeToLive. Exemple :
Prenons l'exemple d'une ligne de table exportée :
{ "id" : 8, "name" : "xyz", "_metadata" : { "expiration" : 1734566400000 //Thursday, December 19, 2024 12:00:00 AM in UTC } }L'heure de référence lors de l'importation est 1734480000000, qui est le mercredi 18 décembre 2024 12:00:00.
Ligne de table importée
{ "id" : 8, "name" : "xyz", "_metadata" : { "ttl" : 1734739200000 //Saturday, December 21, 2024 12:00:00 AM } }
Import de métadonnées TTL dans un fichier JSON formaté DynamoDB et un fichier JSON formaté DynamoDB stockés dans AWS S3
NoSQL Database Migrator fournit un paramètre de configuration supplémentaire, ttlAttributeName, pour prendre en charge l'import des métadonnées TTL à partir des éléments de fichier JSON au format DynamoDB.
Les fichiers JSON exportés par DynamoDB incluent un attribut spécifique dans chaque élément pour stocker l'horodatage d'expiration de la durée de vie. Pour importer éventuellement les valeurs de durée de vie des fichiers JSON exportés par DynamoDB, vous devez fournir le nom de l'attribut spécifique en tant que valeur au paramètre de configuration ttlAttributeName dans le fichier JSON formaté DynamicoDB ou le fichier JSON formaté DynamicoDB stocké dans les fichiers de configuration source AWS S3. Vous devez également définir le paramètre de configuration includeTTL dans le modèle de configuration du récepteur. Les puits valides sont Oracle NoSQL Database et Oracle NoSQL Database Cloud Service. NoSQL Database Migrator stocke les informations de durée de vie dans l'objet JSON _metadata pour l'élément importé.
L'opération d'import gère les cas d'utilisation suivants lors de la migration des éléments de table des fichiers JSON exportés DynamoDB :
-
Cas d'emploi 1 : la valeur du paramètre de configuration ttlAttributeName est définie sur le nom d'attribut TTL indiqué dans le fichier JSON exporté DynamoDB.
NoSQL Database Migrator importe le délai d'expiration de cet élément en millisecondes depuis l'époque UNIX (1er janvier 1970).
Par exemple, considérons un élément dans le fichier JSON exporté DynamoDB :
{ "Item": { "DeptId": { "N": "1" }, "DeptName": { "S": "Engineering" }, "ttl": { "N": "1734616800" } } }Ici, l'attribut
ttlindique la valeur de durée de vie de l'élément. Si vous définissez le paramètre de configuration ttlAttributeName surttldans le fichier JSON au format DynamoDB ou le fichier JSON au format DynamoDB stocké dans le fichier de configuration source AWS S3, NoSQL Database Migrator importe le délai d'expiration de l'élément comme suit :{ "DeptId": 1, "document": { "DeptName": "Engineering" } "_metadata": { "expiration": 1734616800000 } }
Remarque : Vous pouvez indiquer le paramètre de configuration ttlRelativeDate dans le modèle de configuration du récepteur comme heure de référence pour le calcul de l'heure d'expiration.
-
Cas d'emploi 2 : la valeur du paramètre de configuration ttlAttributeName est définie, mais la valeur n'existe pas en tant qu'attribut dans l'élément du fichier JSON exporté DynamoDB.
NoSQL Database Migrator n'importe pas les informations de métadonnées de durée de vie pour l'élément donné.
-
Cas d'emploi 3 : la valeur du paramètre de configuration ttlAttributeName ne correspond pas au nom d'attribut dans l'élément du fichier JSON exporté DynamoDB. NoSQL Database Migrator gère l'import de l'une des manières suivantes en fonction de la configuration du récepteur :
-
Copie l'attribut en tant que champ normal s'il est configuré pour l'importation à l'aide du schéma par défaut.
-
Ignore l'attribut s'il est configuré pour l'import à l'aide d'un schéma défini par l'utilisateur.
-
Importer des données dans un puits avec une colonne IDENTITY
Découvrez comment importer des données dans un puits qui inclut une colonne IDENTITY.
Vous pouvez importer les données d'une source valide vers une table de récepteur (On-premises/Cloud Services) avec une colonne IDENTITY. Vous créez la colonne IDENTITY en tant que GENERATED TOUJOURS AS IDENTITY ou GENERATED BY DEFAULT AS IDENTITY. Pour plus d'informations sur la création de tables avec une colonne IDENTITY, reportez-vous à la rubrique Création de tables avec une colonne IDENTITY dans le manuel SQL Reference Guide.
Avant d'importer les données, assurez-vous que la table Oracle NoSQL Database au niveau du récepteur est vide si elle existe. Si la table de récepteur contient des données préexistantes, la migration peut entraîner des problèmes tels que l'écrasement des données existantes dans la table de récepteur ou l'omission des données source lors de l'importation.
Table d'évier avec la colonne IDENTITY GÉNÉRÉE TOUJOURS COMME IDENTITY
Prenons une table d'évier avec la colonne IDENTITY créée comme GENERATED TOUJOURS AS IDENTITY. L'importation de données dépend du fait que la source fournisse ou non les valeurs de la colonne IDENTITY et du paramètre de transformation ignoreFields dans le fichier de configuration.
Par exemple, vous voulez importer des données d'une source de fichier JSON vers la table Oracle NoSQL Database en tant que récepteur. Le schéma de la table du récepteur est le suivant :
CREATE TABLE IF NOT EXISTS migrateID(ID INTEGER GENERATED ALWAYS AS IDENTITY, name STRING, course STRING, PRIMARY KEY
(ID))L'utilitaire Migrator gère la migration des données comme décrit dans les cas suivants :
| Condition source | Action utilisateur | Résultat de la migration |
|---|---|---|
|
CAS 1 : Les données d'origine ne fournissent pas de valeur pour le champ IDENTITY de la table d'évier. Exemple : fichier source JSON |
Créez/générez le fichier de configuration. |
La migration des données a réussi. Les valeurs de colonne IDENTITY sont générées automatiquement. Données migrées dans la table de récepteur Oracle NoSQL Database |
|
CAS 2 : Les données source fournissent des valeurs pour le champ IDENTITY de la table de l'évier. Exemple : fichier source JSON |
Créez/générez le fichier de configuration. Vous indiquez une transformation ignoreFields pour la colonne ID dans le modèle de configuration du récepteur.
|
La migration des données a réussi. Les valeurs d'ID fournies sont ignorées et les valeurs de colonne IDENTITY sont générées automatiquement. Données migrées dans la table de récepteur Oracle NoSQL Database |
|
Vous créez/générez le fichier de configuration sans la transformation ignoreFields pour la colonne IDENTITY. |
Echec de la migration des données avec le message d'erreur suivant :
|
Pour plus d'informations sur les paramètres de configuration de transformation, reportez-vous à la rubrique Modèles de configuration de transformation.
Table d'évier avec la colonne IDENTITY GENERATED BY DEFAULT AS IDENTITY
Prenons une table de récepteur avec la colonne IDENTITY créée en tant que GENERATED BY DEFAULT AS IDENTITY. L'importation de données dépend du fait que la source fournisse ou non les valeurs de la colonne IDENTITY et du paramètre de transformation ignoreFields.
Par exemple, vous voulez importer des données d'une source de fichier JSON vers la table Oracle NoSQL Database en tant que récepteur. Le schéma de la table du récepteur est le suivant :
CREATE TABLE IF NOT EXISTS migrateID(ID INTEGER GENERATED BY DEFAULT AS IDENTITY, name STRING, course STRING, PRIMARY KEY
(ID))L'utilitaire Migrator gère la migration des données comme décrit dans les cas suivants :
| Condition source | Action utilisateur | Résultat de la migration |
|---|---|---|
|
CAS 1 : Les données d'origine ne fournissent pas de valeur pour le champ IDENTITY de la table d'évier. Exemple : fichier source JSON |
Créez/générez le fichier de configuration. |
La migration des données a réussi. Les valeurs de colonne IDENTITY sont générées automatiquement. Données migrées dans la table de récepteur Oracle NoSQL Database |
|
CAS 2 : Les données source fournissent des valeurs pour le champ IDENTITY de la table d'extraction et il s'agit d'un champ de clé primaire. Exemple : fichier source JSON |
Créez/générez le fichier de configuration. Vous indiquez une transformation ignoreFields pour la colonne ID dans le modèle de configuration du récepteur (Recommandé).
|
La migration des données a réussi. Les valeurs d'ID fournies sont ignorées et les valeurs de colonne IDENTITY sont générées automatiquement. Données migrées dans la table de récepteur Oracle NoSQL Database |
|
Vous créez/générez le fichier de configuration sans la transformation ignoreFields pour la colonne IDENTITY. |
La migration des données a réussi. Les valeurs Lorsque vous tentez d'insérer une ligne supplémentaire dans la table sans fournir de valeur de code, le générateur de séquences tente de générer automatiquement la valeur de code. La valeur de départ du générateur de séquences est 1. Par conséquent, la valeur d'ID générée peut potentiellement dupliquer l'une des valeurs d'ID existantes dans la table d'extraction. Etant donné qu'il s'agit d'une violation de la contrainte de clé primaire, une erreur est renvoyée et la ligne n'est pas insérée. Pour plus d'informations, voir Générateur de séquences. Pour éviter la violation de la contrainte de clé primaire, le générateur de séquences doit démarrer la séquence avec une valeur qui n'est pas en conflit avec les valeurs d'ID existantes dans la table de conversion. Pour utiliser l'attribut START WITH pour effectuer cette modification, reportez-vous à l'exemple ci-dessous : Exemple : données migrées dans la table de récepteur Oracle NoSQL Database Pour trouver la valeur appropriée que le générateur de séquences doit insérer dans la colonne ID, extrayez la valeur maximale du champ Sortie : La valeur maximale de la colonne La séquence commencera à 4. Maintenant, lorsque vous insérez des lignes dans la table d'extraction sans fournir les valeurs d'ID, le générateur de séquences génère automatiquement les valeurs d'ID à partir de 4, ce qui évite la duplication des ID. |
Pour plus d'informations sur les paramètres de configuration de transformation, reportez-vous à la rubrique Modèles de configuration de transformation.
Filtrer les données à l'aide de prédicats de requête
Découvrez comment spécifier des prédicats de requête pour exporter uniquement les lignes de table qui correspondent aux critères de filtre.
Prédicat de requête
NoSQL Database Migrator fournit une option permettant de filtrer les données lors de l'export en indiquant un prédicat de requête. Le prédicat de requête indique les conditions qui doivent être remplies pour qu'une ligne soit exportée. L'utilitaire Migrator convertit le prédicat de requête en clause SQL WHERE et l'applique à la table indiquée afin de fournir une condition de filtre pour exporter uniquement les lignes correspondant à la condition indiquée. Vous pouvez utiliser des fonctions intégrées (modification_time(), expiration_time(), creation_time()) dans le prédicat de requête pour créer des options de filtre avancées.
Vous ne pouvez utiliser des prédicats d'interrogation que sur les sources Oracle NoSQL Database et Oracle NoSQL Database Cloud Service pour tous les puits pris en charge. Pour plus d'informations, reportez-vous à Oracle NoSQL Database et à Oracle NoSQL Database Cloud Service.
Pour une démonstration de cas d'utilisation, reportez-vous à Migration à partir d'Oracle NoSQL Database Cloud Service vers un fichier JSON.
Vider le filtre
L'utilitaire Migrator fournit une option pour faire écho à la requête SQL exécutée sur le back-end. Cette fonction vous aide à vérifier la requête générée et, si nécessaire, à affiner votre filtre avant d'exécuter la tâche de migration.
Vous pouvez exécuter l'utilitaire Migrator avec l'option de filtre de vidage comme suit :
[~/nosqlMigrator]$./runMigrator --dump-filter|df [optional-config-file]-
Avec le fichier de configuration : l'utilitaire de migration affiche le fichier de configuration fourni et la requête générée, comme indiqué dans l'exemple suivant :
[~/nosqlMigrator]./runMigrator --dump-filter migrator-config.json[INFO] Configuration for migration: { "source" : { "type" : "nosqldb", "storeName" : "kvstore", "helperHosts" : ["<hostname>:5000"], "table" : "users", "queryFilter" : "$row.address.city='Houston'", "includeTTL" : true, "requestTimeoutMs" : 5000 }, "sink" : { "type" : "file", "format" : "json", "useMultiFiles" : false, "schemaPath" : "<complete/path/to/the/JSON/file/with/DDL/commands/for/the/schema/definition>", "pretty" : true, "dataPath" : "<complete/path/to/directory>" }, "abortOnError" : true, "migratorVersion" : "1.8.0" } [INFO] Query for the migration: 'select $row, expiration_time($row) from users $row where $row.address.city='Houston'' -
Sans le fichier de configuration : l'utilitaire de migration collecte de manière interactive toutes les entrées requises pour générer le fichier de configuration, y compris le prédicat de requête. Il affiche ensuite le fichier de configuration et la requête générés.
Remarque :
L'option de filtre de vidage affiche uniquement le fichier de configuration et la requête. Il ne lance pas la migration des données. Après vérification, pour exécuter la migration, exécutez l'utilitaire Migrator avec votre fichier de configuration à l'aide de l'option
--cou--configcomme suit :$./runMigrator --config <complete/path/to/the/JSON/config/file>
Démonstrations de cas d'emploi pour Oracle NoSQL Database Migrator
Découvrez comment effectuer une migration de données à l'aide d'Oracle NoSQL Database Migrator pour des cas d'utilisation spécifiques. Vous trouverez des instructions systématiques détaillées avec des exemples de code pour effectuer la migration dans chacun des cas d'utilisation.
Cet article comprend les rubriques suivantes :
Migration à partir d'Oracle NoSQL Database Cloud Service vers un fichier JSON
Cet exemple montre comment utiliser le migrateur Oracle NoSQL Database pour copier des données et la définition de schéma d'une table NoSQL d'Oracle NoSQL Database Cloud Service (NDCS) vers un fichier JSON.
Cas d'emploi
Une organisation décide d'entraîner un modèle à l'aide des données NDCS (Oracle NoSQL Database Cloud Service) afin de prévoir les comportements futurs et de fournir des recommandations personnalisées. Ils peuvent prendre une copie périodique des données des tables NDCS dans un fichier JSON et les appliquer au moteur d'analyse pour analyser et entraîner le modèle. Cela les aide à séparer les requêtes analytiques des chemins critiques à faible latence.
Exemple
Pour la démonstration, examinons comment migrer la définition de données et de schéma d'une table NoSQL appelée myTable de NDCS vers un fichier JSON.
Prérequis
-
Identifiez la source et le récepteur de la migration.
-
Source : Oracle NoSQL Database Cloud Service,
-
Sink : fichier JSON
-
-
Identifiez vos informations d'identification cloud OCI et capturez-les dans le fichier de configuration OCI. Enregistrez le fichier de configuration dans
/home/.oci/config. Reportez-vous à Obtention d'informations d'identification.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Identifiez l'adresse de région et le nom du compartiment pour Oracle NoSQL Database Cloud Service.
-
endpoint :
us-ashburn-1 -
compartiment :
ocid1.compartment.oc1..aa..rhsmq
-
Procédure
Pour migrer la définition de données et de schéma de votre table d'Oracle NoSQL Database Cloud Service vers un fichier JSON, vous pouvez utiliser l'une des options suivantes :
-
Ouvrez l'invite de commande et accédez au répertoire dans lequel vous avez extrait l'utilitaire NoSQL Database Migrator.
-
Pour générer le fichier de configuration à l'aide de NoSQL Database Migrator, exécutez la commande
runMigratorsans paramètre d'exécution.[~/nosqlMigrator]$./runMigrator -
Comme vous n'avez pas fourni le fichier de configuration en tant que paramètre d'exécution, l'utilitaire vous invite à générer la configuration maintenant. Saisissez
**y**.Configuration file is not provided. Do you want to generate configuration? (y/n) [n]: y Generating a configuration file interactively. -
En fonction des invites de l'utilitaire, choisissez vos options pour la configuration source.
Enter a location for your config [./migrator-config.json]: /home/<user>/nosqlMigrator/NDCS2JSON Select the source: 1) nosqldb 2) nosqldb_cloud 3) file 4) object_storage_oci 5) aws_s3 #? 2 Configuration for source type=nosqldb_cloud Enter endpoint URL or region ID of the Oracle NoSQL Database Cloud: us-phoenix-1 Select the authentication type: 1) credentials_file 2) instance_principal 3) delegation_token 4) session_token 5) oke_workload_identity #? 1 Enter path to the file containing OCI credentials [/home/<user>/.oci/config]: Enter the profile name in OCI credentials file [DEFAULT]: Enter the compartment name or id of the table []: developers Enter table name: myTable Include TTL data? If you select 'yes' TTL of rows will also be included in the exported data.(y/n) [n]: Enter percentage of table read units to be used for migration operation. (1-100) [90]: Enter store operation timeout in milliseconds. (1-30000) [5000]: -
En fonction des invites de l'utilitaire, choisissez vos options pour la configuration Sink.
Select the sink: 1) nosqldb 2) nosqldb_cloud 3) file #? 3 Configuration for sink type=file Enter path to a directory to store JSON data: /home/<user>/nosqlMigrator would you like to export data to multiple files for each source?(y/n) [y]: n Would you like to store JSON in pretty format? (y/n) [n]: y Would you like to migrate the table schema also? (y/n) [y]: y Enter path to a file to store table schema: /home/<user>/nosqlMigrator/myTableSchema -
En fonction des invites de l'utilitaire, choisissez vos options pour les transformations de données source. La valeur par défaut est
n.Would you like to add transformations to source data? (y/n) [n]: -
Saisissez votre choix pour déterminer si la migration doit être effectuée en cas d'échec de la migration d'un enregistrement.
Would you like to continue migration in case of any record/row is failed to migrate?: (y/n) [n]: -
L'utilitaire affiche la configuration générée à l'écran.
generated configuration is: { "source": { "type": "nosqldb_cloud", "endpoint": "us-ashburn-1", "table": "myTable", "compartment": "ocid1.compartment.oc1..aa..rhsmq", "credentials": "/home/<user>/.oci/config", "credentialsProfile": "DEFAULT", "readUnitsPercent": 90, "requestTimeoutMs": 5000 }, "sink": { "type": "file", "format": "json", "useMultiFiles" : false, "schemaPath": "/home/<user>/nosqlMigrator/myTableSchema", "pretty": true, "dataPath": "/home/<user>/nosqlMigrator" }, "abortOnError": true, "migratorVersion": "1.8.0" } -
L'utilitaire vous invite à choisir de poursuivre ou non la migration avec le fichier de configuration généré. L'option par défaut est
y.Remarque : si vous sélectionnez
n, vous pouvez utiliser le fichier de configuration généré pour exécuter la migration à l'aide de l'option./runMigrator -cou./runMigrator --config.Would you like to run the migration with above configuration? If you select no, you can use the generated configuration file to run the migration using: ./runMigrator --config /home/<user>/nosqlMigrator/NDCS2JSON (y/n) [y]: -
NoSQL Database Migrator migre vos données et votre schéma de NDCS vers le fichier JSON.
Records provided by source=10,Records written to sink=10,Records failed=0,Records skipped=0. Elapsed time: 0min 1sec 277ms Migration completed.Validation
Pour valider la migration, vous pouvez accéder au répertoire de récepteur indiqué et visualiser le schéma et les données.
-- Exported myTable Data. JSON files are created in the supplied data path
[~/nosqlMigrator]$cat myTable_1_5.json
{
"id" : 10,
"document" : {
"course" : "Computer Science",
"name" : "Neena",
"studentid" : 105
}
}
{
"id" : 3,
"document" : {
"course" : "Computer Science",
"name" : "John",
"studentid" : 107
}
}
{
"id" : 4,
"document" : {
"course" : "Computer Science",
"name" : "Ruby",
"studentid" : 100
}
}
{
"id" : 6,
"document" : {
"course" : "Bio-Technology",
"name" : "Rekha",
"studentid" : 104
}
}
{
"id" : 7,
"document" : {
"course" : "Computer Science",
"name" : "Ruby",
"studentid" : 100
}
}
{
"id" : 5,
"document" : {
"course" : "Journalism",
"name" : "Rani",
"studentid" : 106
}
}
{
"id" : 8,
"document" : {
"course" : "Computer Science",
"name" : "Tom",
"studentid" : 103
}
}
{
"id" : 9,
"document" : {
"course" : "Computer Science",
"name" : "Peter",
"studentid" : 109
}
}
{
"id" : 1,
"document" : {
"course" : "Journalism",
"name" : "Tracy",
"studentid" : 110
}
}
{
"id" : 2,
"document" : {
"course" : "Bio-Technology",
"name" : "Raja",
"studentid" : 108
}
}-- Exported myTable Schema
[~/nosqlMigrator]$cat myTableSchema
CREATE TABLE IF NOT EXISTS myTable (id INTEGER, document JSON, PRIMARY KEY(SHARD(id)))-
Préparez le fichier de configuration (au format JSON) avec la source Oracle NoSQL Database Cloud Service (NDCS) et les détails du récepteur JSON. Reportez-vous à Modèles de configuration source et Modèles de configuration de récepteur.
Dans cet exemple, une table
usersest utilisée avec les données suivantes :{"id":10,"firstName":"John","lastName":"Smith","age":22,"income":45000,"address":{"city":"Santa Cruz","number":101,"phones":[{"area":408,"kind":"work","number":4538955},{"area":831,"kind":"home","number":7533341},{"area":831,"kind":"mobile","number":7533382}],"state":"CA","street":"Pacific Ave","zip":95008}} {"id":20,"firstName":"Jane","lastName":"Smith","age":22,"income":55000,"address":{"city":"San Jose","number":201,"phones":[{"area":608,"kind":"work","number":6538955},{"area":931,"kind":"home","number":9533341},{"area":931,"kind":"mobile","number":9533382}],"state":"CA","street":"Atlantic Ave","zip":95005}} {"id":30,"firstName":"Adam","lastName":"Smith","age":45,"income":75000,"address":{"city":"Houston","number":301,"phones":[{"area":618,"kind":"work","number":6618955},{"area":951,"kind":"home","number":9613341},{"area":981,"kind":"mobile","number":9613382}],"state":"TX","street":"Indian Ave","zip":95075}} {"id":40,"firstName":"Joanna","lastName":"Smith","age":null,"income":75000,"address":{"city":"Houston","number":401,"phones":[{"area":null,"kind":"work","number":1618955},{"area":451,"kind":"home","number":4613341},{"area":481,"kind":"mobile","number":4613382}],"state":"TX","street":"Tex Ave","zip":95085}}Veillez à inclure le paramètre
queryFilteravec le prédicat de requête approprié dans le modèle de configuration source afin d'exporter uniquement les lignes requises de la table. Pour plus de détails sur la création de prédicats de requête, reportez-vous à la table Exemples de prédicats de requête dans la rubrique Source de service NoSQL Database Cloud.Dans cet exemple, le prédicat de requête exporte des lignes avec le champ
citydans la colonne JSONaddress= 'Houston' de la tableusers.{ "source" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "users", "queryFilter" : "$row.address.city='Houston'", "compartment" : "ocid1.compartment.oc1..aa..rhsmq", "credentials" : "/home/<user>/.oci/config", "credentialsProfile" : "DEFAULT", "readUnitsPercent" : 90, "includeTTL" : true, "requestTimeoutMs" : 5000 }, "sink" : { "type" : "file", "format" : "json", "useMultiFiles" : true, "chunkSize" : 32, "schemaPath" : "/scratch/<user>/nosqlMigrator/tableschema.ddl", "pretty" : false, "dataPath" : "/scratch/<user>/nosqlMigrator" }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Ouvrez l'invite de commande et accédez au répertoire dans lequel vous avez extrait l'utilitaire NoSQL Database Migrator.
-
Exécutez la commande
runMigratoren transmettant le fichier de configuration. Utilisez l'option--configou-c.[~/nosqlMigrator]$./runMigrator --config <complete/path/to/the/JSON/config/file>Remarque :
Vous pouvez également exécuter la commande avec le
option permettant d'afficher et de vérifier la requête générée avant d'exécuter la tâche de migration comme suit. Pour plus d'informations, reportez-vous à
.
[~/nosqlMigrator]$./runMigrator --dump-filter <complete/path/to/the/JSON/config/file>L'utilitaire procède à la migration des données comme suit :
[INFO] creating source from given configuration: [INFO] [cloud source] : query = 'SELECT $row,expiration_time_millis($row) AS expiration FROM users $row where $row.address.city='Houston'' [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [json file sink] : writing table schema to /scratch/raumesh/nosqlMigrator/tableschema.ddl [INFO] migration started [INFO] Migration success for source users. read=2,written=2,failed=0 [INFO] Migration is successful for all the sources. [INFO] migration completed. Records provided by source=2, Records written to sink=2, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 182ms Migration completed.
Vérification
Pour vérifier la migration, vous pouvez accéder au répertoire de récepteur indiqué et afficher le schéma et les données. Seules les lignes de la colonne JSON address avec la valeur de champ city 'Houston' sont exportées.
-- Exported users data. Schema and JSON files are created in the supplied data paths.
[~/nosqlMigrator]: cat tableschema.ddl
CREATE TABLE IF NOT EXISTS users (id INTEGER, firstName STRING, lastName STRING, age INTEGER, income INTEGER, address JSON, PRIMARY KEY(SHARD(id)))[~/nosqlMigrator]: cat users_6_10.json
{"id":30,"firstName":"Adam","lastName":"Smith","age":45,"income":75000,"address":{"city":"Houston","number":301,"phones":[{"area":618,"kind":"work","number":6618955},{"area":951,"kind":"home","number":9613341},{"area":981,"kind":"mobile","number":9613382}],"state":"TX","street":"Indian Ave","zip":95075}}
{"id":40,"firstName":"Joanna","lastName":"Smith","age":null,"income":75000,"address":{"city":"Houston","number":401,"phones":[{"area":null,"kind":"work","number":1618955},{"area":451,"kind":"home","number":4613341},{"area":481,"kind":"mobile","number":4613382}],"state":"TX","street":"Tex Ave","zip":95085}}
bash-4.4$Migration d'une instance Oracle NoSQL Database sur site vers Oracle NoSQL Database Cloud Service
Cet exemple montre comment utiliser le migrateur Oracle NoSQL Database pour copier des données et la définition de schéma d'une table NoSQL d'Oracle NoSQL Database vers Oracle NoSQL Database Cloud Service (NDCS).
Cas d'emploi
En tant que développeur, vous étudiez les options permettant d'éviter la surcharge liée à la gestion des ressources, des clusters et du nettoyage de la mémoire pour vos charges globales NoSQL Database KVStore existantes. En tant que solution, vous décidez de migrer vos charges de travail de banque de clés KVStore on-premise existantes vers Oracle NoSQL Database Cloud Service, car NDCS les gère automatiquement.
Exemple
Pour la démonstration, examinons comment migrer la définition de données et de schéma d'une table NoSQL appelée myTable du fichier de clés NoSQL Database vers NDCS. Nous utiliserons également ce cas d'utilisation pour montrer comment exécuter l'utilitaire runMigrator en transmettant un fichier de configuration précréé.
Prérequis
-
Identifiez la source et le récepteur de la migration.
-
Source : Oracle NoSQL Database
-
Verrouillage : Oracle NoSQL Database Cloud Service
-
-
Identifiez vos informations d'identification cloud OCI et capturez-les dans le fichier de configuration OCI. Enregistrez le fichier de configuration dans
/home/.oci/config. Reportez-vous à Acquérir des informations d'identification dans Utilisation d'Oracle NoSQL Database Cloud Service.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Identifiez l'adresse de région et le nom du compartiment pour Oracle NoSQL Database Cloud Service.
-
endpoint :
us-phoenix-1 -
compartiment :
developers
-
-
Identifiez les détails suivants pour le fichier de clés sur site :
-
storeName :
kvstore -
helperHosts :
<hostname>:5000 -
table :
myTable
-
Procédure
Pour migrer la définition de schéma et de données de myTable du fichier de clés NoSQL Database vers NDCS, procédez comme suit :
-
Préparez le fichier de configuration (au format JSON) avec les détails Source et Sink identifiés. Reportez-vous à Modèles de configuration source et Modèles de configuration de récepteur.
{ "source" : { "type" : "nosqldb", "storeName" : "kvstore", "helperHosts" : ["<hostname>:5000"], "table" : "myTable", "requestTimeoutMs" : 5000 }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-phoenix-1", "table" : "myTable", "compartment" : "developers", "schemaInfo" : { "schemaPath" : "<complete/path/to/the/JSON/file/with/DDL/commands/for/the/schema/definition>", "readUnits" : 100, "writeUnits" : 100, "storageSize" : 1 }, "credentials" : "<complete/path/to/oci/config/file>", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Ouvrez l'invite de commande et accédez au répertoire dans lequel vous avez extrait l'utilitaire NoSQL Database Migrator.
-
Exécutez la commande
runMigratoren transmettant le fichier de configuration à l'aide des options--configou-c.[~/nosqlMigrator/nosql-migrator-1.8.0]$./runMigrator --config <complete/path/to/the/JSON/config/file> -
L'utilitaire procède à la migration des données, comme indiqué ci-dessous.
Records provided by source=10, Records written to sink=10, Records failed=0. Elapsed time: 0min 10sec 426ms Migration completed.
Validation
Pour valider la migration, vous pouvez vous connecter à la console NDCS et vérifier que myTable est créé avec les données source.
Migrer de la source de fichier JSON vers Oracle NoSQL Database Cloud Service
Cet exemple montre l'utilisation d'Oracle NoSQL Database Migrator pour copier des données d'une source de fichier JSON vers Oracle NoSQL Database Cloud Service.
Après avoir évalué plusieurs options, une organisation finalise Oracle NoSQL Database Cloud Service en tant que plate-forme NoSQL Database. Le contenu source étant au format de fichier JSON, l'entreprise cherche un moyen de le migrer vers Oracle NoSQL Database Cloud Service.
Dans cet exemple, vous apprendrez à migrer les données à partir d'un fichier JSON appelé SampleData.json. Exécutez l'utilitaire runMigrator en transmettant un fichier de configuration pré-créé. Si le fichier de configuration n'est pas fourni en tant que paramètre d'exécution, l'utilitaire runMigrator vous invite à générer la configuration via une procédure interactive.
Prérequis
-
Identifiez la source et le récepteur de la migration.
-
Source : fichier source JSON.
SampleData.jsonest le fichier source. Il contient plusieurs documents JSON avec un document par ligne, délimité par un nouveau caractère de ligne.{"id":6,"val_json":{"array":["q","r","s"],"date":"2023-02-04T02:38:57.520Z","nestarray":[[1,2,3],[10,20,30]],"nested":{"arrayofobjects":[{"datefield":"2023-03-04T02:38:57.520Z","numfield":30,"strfield":"foo54"},{"datefield":"2023-02-04T02:38:57.520Z","numfield":56,"strfield":"bar23"}],"nestNum":10,"nestString":"bar"},"num":1,"string":"foo"}} {"id":3,"val_json":{"array":["g","h","i"],"date":"2023-02-02T02:38:57.520Z","nestarray":[[1,2,3],[10,20,30]],"nested":{"arrayofobjects":[{"datefield":"2023-02-02T02:38:57.520Z","numfield":28,"strfield":"foo3"},{"datefield":"2023-02-02T02:38:57.520Z","numfield":38,"strfield":"bar"}],"nestNum":10,"nestString":"bar"},"num":1,"string":"foo"}} {"id":7,"val_json":{"array":["a","b","c"],"date":"2023-02-20T02:38:57.520Z","nestarray":[[1,2,3],[10,20,30]],"nested":{"arrayofobjects":[{"datefield":"2023-01-20T02:38:57.520Z","numfield":28,"strfield":"foo"},{"datefield":"2023-01-22T02:38:57.520Z","numfield":38,"strfield":"bar"}],"nestNum":10,"nestString":"bar"},"num":1,"string":"foo"}} {"id":4,"val_json":{"array":["j","k","l"],"date":"2023-02-03T02:38:57.520Z","nestarray":[[1,2,3],[10,20,30]],"nested":{"arrayofobjects":[{"datefield":"2023-02-03T02:38:57.520Z","numfield":28,"strfield":"foo"},{"datefield":"2023-02-03T02:38:57.520Z","numfield":38,"strfield":"bar"}],"nestNum":10,"nestString":"bar"},"num":1,"string":"foo"}} -
Verrouillage : Oracle NoSQL Database Cloud Service.
-
-
Identifiez vos informations d'identification cloud OCI et capturez-les dans le fichier de configuration OCI. Enregistrez le fichier de configuration dans le répertoire
/home/<user>/.oci/config. Pour plus de détails, reportez-vous à Obtention d'informations d'identification dans Utilisation d'Oracle NoSQL Database Cloud Service.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... region=us-ashburn-1 key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Identifiez l'adresse de région et le nom du compartiment pour Oracle NoSQL Database Cloud Service.
-
endpoint :
us-ashburn-1 -
compartiment :
Training-NoSQL
-
-
Identifiez les détails suivants pour le fichier source JSON :
-
schemaPath :
<absolute path to the schema definition file containing DDL statements for the NoSQL table at the sink>.Dans cet exemple, le fichier LDD est
schema_json.ddl.create table Migrate_JSON (id INTEGER, val_json JSON, PRIMARY KEY(id));Oracle NoSQL Database Migrator fournit une option permettant de créer une table avec le schéma par défaut si
schemaPathn'est pas fourni. Pour plus d'informations, reportez-vous à la rubrique Identifier la source et le récepteur dans le workflow pour Oracle NoSQL Database Migrator. -
Chemin de données :
<absolute path to a file or directory containing the JSON data for migration>.
-
Procédure
Pour migrer le fichier source JSON de SampleData.json vers Oracle NoSQL Database Cloud Service, procédez comme suit :
-
Préparez le fichier de configuration (au format JSON) avec les détails de la source et du récepteur identifiés. Reportez-vous à Modèles de configuration source et Modèles de configuration de récepteur.
{ "source" : { "type" : "file", "format" : "json", "schemaInfo" : { "schemaPath" : "[~/nosql-migrator-1.8.0]/schema_json.ddl" }, "dataPath" : "[~/nosql-migrator-1.8.0]/SampleData.json" }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "Migrate_JSON", "compartment" : "Training-NoSQL", "includeTTL" : false, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "useSourceSchema" : true }, "credentials" : "/home/<user>/.oci/config", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Ouvrez l'invite de commande et accédez au répertoire dans lequel vous avez extrait l'utilitaire de migration Oracle NoSQL Database.
-
Exécutez la commande
runMigratoren transmettant le fichier de configuration à l'aide des options--configou-c.[~/nosql-migrator-1.8.0]$./runMigrator --config <complete/path/to/the/config/file> -
L'utilitaire procède à la migration des données, comme indiqué ci-dessous. La table
Migrate_JSONest créée au niveau du récepteur avec le schéma fourni dansschemaPath.creating source from given configuration: source creation completed creating sink from given configuration: sink creation completed creating migrator pipeline migration started [cloud sink] : start loading DDLs [cloud sink] : executing DDL: create table Migrate_JSON (id INTEGER, val_json JSON, PRIMARY KEY(id)),limits: [100, 60, 1] [cloud sink] : completed loading DDLs [cloud sink] : start loading records [json file source] : start parsing JSON records from file: SampleData.json [INFO] migration completed. Records provided by source=4, Records written to sink=4, Records failed=0, Records skipped=0. Elapsed time: 0min 5sec 778ms Migration completed.
Validation
Pour valider la migration, vous pouvez vous connecter à la console Oracle NoSQL Database Cloud Service et vérifier que la table Migrate_JSON est créée avec les données source. Pour connaître la procédure d'accès à la console, reportez-vous à l'article Accès au service à partir de la console Infrastructure dans le document Oracle NoSQL Database Cloud Service.
Figure - Tables de la console Oracle NoSQL Database Cloud Service
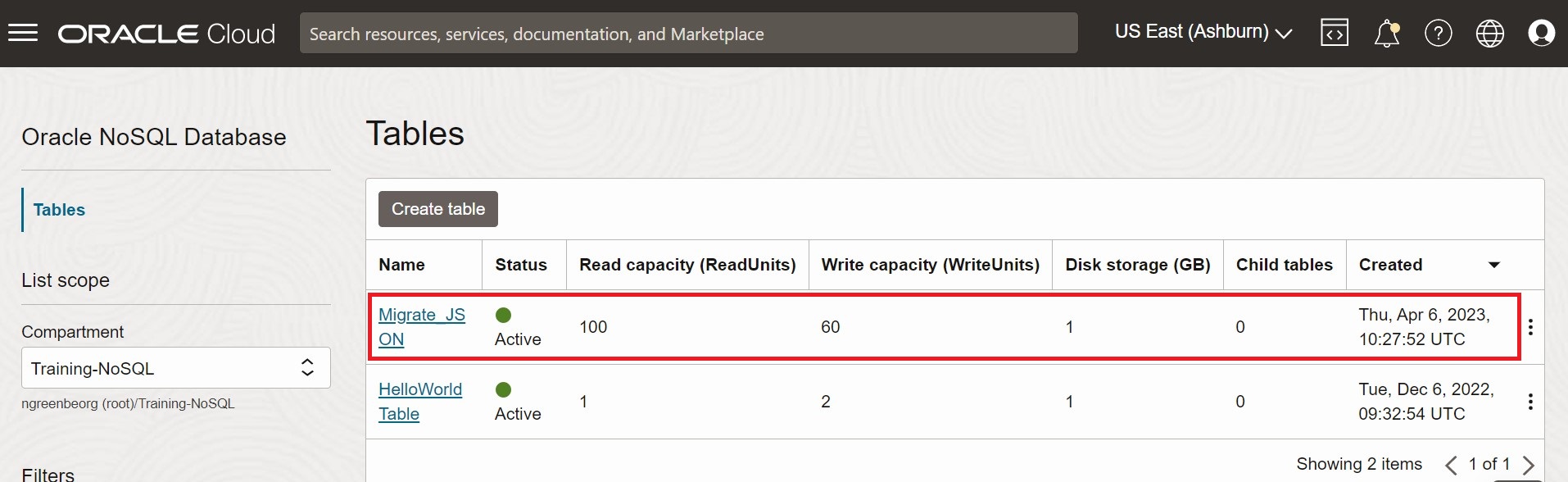
Description de l'illustration migrate_json1.png
Figure - Données de table de la console Oracle NoSQL Database Cloud Service
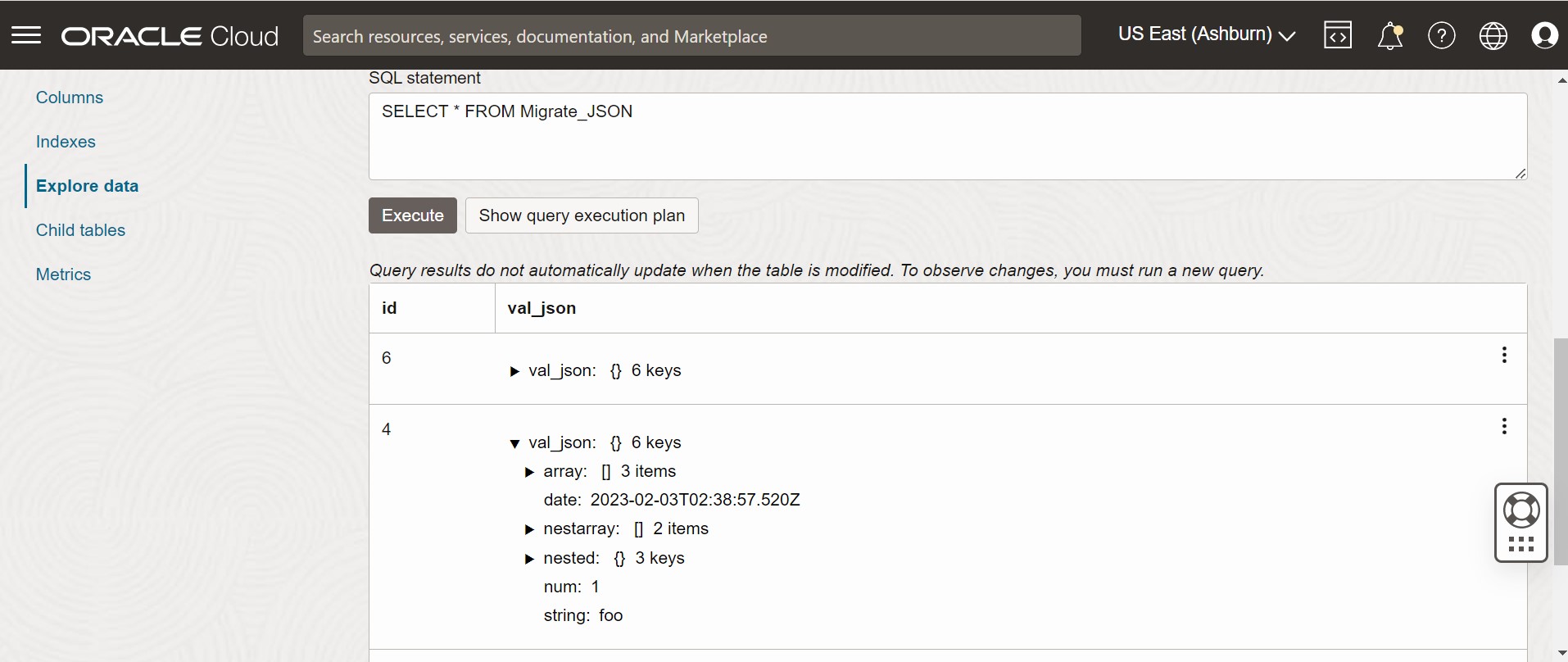
Description de l'illustration migrate_json2.png
Migration à partir d'un fichier JSON MongoDB vers Oracle NoSQL Database Cloud Service
Cet exemple montre comment utiliser le migrateur Oracle NoSQL Database pour copier des données au format MongoDB vers Oracle NoSQL Database Cloud Service (NDCS).
Cas d'emploi
Après avoir évalué plusieurs options, une organisation finalise Oracle NoSQL Database Cloud Service en tant que plate-forme NoSQL Database. Les tables et les données sont dans MongoDB et l'organisation souhaite migrer les deux vers Oracle NDCS.
Vous pouvez copier un fichier ou un répertoire contenant les données JSON exportées par MongoDB pour la migration en indiquant le fichier ou le répertoire dans le modèle de configuration source.
Considérons les deux exemples de fichiers JSON suivants exportés à partir de MongoDB pour illustrer notre cas d'utilisation.
Un exemple de fichier JSON au format MongoDB est le suivant :
{"_id":0,"name":"Aimee Zank","scores":[{"score":1.463179736705023,"type":"exam"},{"score":11.78273309957772,"type":"quiz"},{"score":35.8740349954354,"type":"homework"}]}
{"_id":1,"name":"Aurelia Menendez","scores":[{"score":60.06045071030959,"type":"exam"},{"score":52.79790691903873,"type":"quiz"},{"score":71.76133439165544,"type":"homework"}]}
{"_id":2,"name":"Corliss Zuk","scores":[{"score":67.03077096065002,"type":"exam"},{"score":6.301851677835235,"type":"quiz"},{"score":66.28344683278382,"type":"homework"}]}
{"_id":3,"name":"Bao Ziglar","scores":[{"score":71.64343899778332,"type":"exam"},{"score":24.80221293650313,"type":"quiz"},{"score":42.26147058804812,"type":"homework"}]}
{"_id":4,"name":"Zachary Langlais","scores":[{"score":78.68385091304332,"type":"exam"},{"score":90.2963101368042,"type":"quiz"},{"score":34.41620148042529,"type":"homework"}]}Un exemple de fichier JSON au format MongoDB exporté à partir d'une application Spring est le suivant :
{"_id":{"$oid":"63d3a87cf564fc21dac3838d"},"firstName":"John","lastName":"Smith","address":{"Country":"France"},"_class":"com.example.demo.Customer"}
{"_id":{"$oid":"63d3a87cf564fc21dac3838e"},"firstName":"Sam","lastName":"David","address":{"Country":"USA"},"_class":"com.example.demo.Customer"}
{"_id":"3","firstName":"Dona","lastName":"William","address":{"Country":"England"},"_class":"com.example.demo.Customer"}MongoDB prend en charge deux types d'extension pour les fichiers JSON formatés : Mode canonique et Mode détendu. Vous pouvez fournir le fichier JSON au format MongoDB qui est généré à l'aide de l'outil mongoexport en mode canonique ou détendu. NoSQL Database Migrator prend en charge les deux modes.
Pour plus d'informations sur le fichier JSON étendu MongoDB (v2), reportez-vous à mongoexport_formats.
Pour plus d'informations sur la génération du fichier JSON au format MongoDB, reportez-vous à mongoexport.
Exemple
Pour la démonstration, examinons comment migrer un fichier JSON au format MongoDB vers NDCS. Nous allons utiliser un fichier de configuration créé manuellement pour cet exemple.
Prérequis
-
Identifiez la source et le récepteur de la migration.
-
Source : Fichier JSON au format MongoDB
-
Verrouillage : Oracle NoSQL Database Cloud Service
-
- Extrayez les données de MongoDB à l'aide de l'utilitaire mongoexport. Reportez-vous à mongoexport.
-
Identifiez vos informations d'identification cloud OCI et capturez-les dans le fichier de configuration OCI. Enregistrez le fichier de configuration dans le répertoire
/home/<user>/.oci/config. Pour plus d'informations, reportez-vous à Obtention d'informations d'identification.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Identifiez l'adresse de région et le nom du compartiment pour Oracle NoSQL Database Cloud Service.
-
endpoint :
us-ashburn-1 -
compartiment :
ocid1.compartment.oc1..aaaaaaaaadeskhnnfkenws4k2vdyklcc32hfpzzz4z3zum3ubhmpz6zxnoza
-
Procédure
Pour migrer les données JSON au format MongoDB vers Oracle NoSQL Database Cloud Service, vous pouvez choisir l'une des options suivantes :
-
Préparez le fichier de configuration (au format JSON) avec les détails Source et Sink identifiés. Reportez-vous à Modèles de configuration source et Modèles de configuration de récepteur.
Ici, vous définissez le paramètre de configuration
defaultSchemasur True. Par conséquent, NoSQL Database Migrator crée une table avec le schéma par défaut au niveau du récepteur.{ "source" : { "type" : "file", "format" : "mongodb_json", "dataPath" : "<complete/path/to/the/MongoDB/Formatted/JSON/file>" }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "mongoImport", "compartment" : "ocid1.compartment.oc1..aaaaaaaaadeskhnnfkenws4k2vdyklcc32hfpzzz4z3zum3ubhmpz6zxnoza", "includeTTL" : false, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "defaultSchema" : true }, "credentials" : "<complete/path/to/the/oci/config/file>", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" }Le schéma par défaut de la source de fichier JSON au format MongoDB est le suivant :
CREATE TABLE IF NOT EXISTS <tablename>(id STRING, document JSON,PRIMARY KEY(SHARD(id));Où :
-
tablename= valeur fournie pour l'attributtabledans la configuration. -
id= valeur_idde chaque document du fichier source JSON exporté par MongoDB. -
document= Pour chaque document du fichier exporté MongoDB, le contenu excluant le champ_idest agrégé dans la colonnedocument.
Remarque : si la table
<tablename>existe déjà dans Oracle NoSQL Database Cloud Service et que vous souhaitez migrer des données vers la table à l'aide de la configurationdefaultSchema, vous devez vous assurer que la table existante a la colonne ID en minuscules (id) et est de type STRING. -
-
Ouvrez l'invite de commande et accédez au répertoire dans lequel vous avez extrait l'utilitaire NoSQL Database Migrator.
-
Exécutez la commande
runMigratoren transmettant le fichier de configuration. Utilisez l'option--configou-c.$./runMigrator --config <complete/path/to/the/JSON/config/file> -
L'utilitaire procède à la migration des données, comme indiqué ci-dessous.
[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [cloud sink] : start loading DDLs [INFO] [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS mongoImport (id STRING, document JSON, PRIMARY KEY(SHARD(id))),limits: [100, 60, 1] [INFO] [cloud sink] : completed loading DDLs [INFO] migration started [INFO] [mongo file source] : start parsing MongoDB JSON records from file: mongoDBSample.json [INFO] Migration success for source mongoDBSample. read=5,written=5,failed=0 [INFO] Migration is successful for all the sources. [INFO] migration completed. Records provided by source=5, Records written to sink=5, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 448ms Migration completed.
Vérification
Pour vérifier la migration, vous pouvez vous connecter à la console Oracle NoSQL Database Cloud Service et vérifier que la table mongoImport est créée avec les données source. Pour connaître la procédure d'accès à la console, reportez-vous à l'article Accès au service à partir de la console Infrastructure.
-
Préparez le fichier de configuration (au format JSON) avec les détails Source et Sink identifiés. Reportez-vous à Modèles de configuration source et Modèles de configuration de récepteur.
Ici, vous indiquez le fichier contenant l'instruction LDD de la table de récepteur dans le paramètre
schemaPathdu modèle de configuration source. Par conséquent, définissez le paramètre de configurationuseSourceSchemasur True dans le modèle de configuration du récepteur.Vous pouvez générer un schéma personnalisé comme suit :
-
Notez les noms et les types de données de chaque colonne à partir des données JSON au format MongoDB. Utilisez ces informations pour créer un fichier LDD de schéma pour la table Oracle NoSQL Database Cloud Service.
-
Dans le fichier de schéma, nommez la première colonne (clé primaire)
idde type STRING. Incluez le même nom et le même type pour les colonnes restantes que ceux enregistrés dans le fichier JSON au format MongoDB. -
Enregistrez le fichier de schéma et notez son chemin complet.
Le schéma défini par l'utilisateur suivant est utilisé dans cet exemple :
CREATE TABLE IF NOT EXISTS sampleMongoDBImp (id STRING, name STRING, scores JSON, PRIMARY KEY(SHARD(id)));Vous devez inclure une transformation
renameFieldsdemandant à NoSQL Database Migrator de convertir la colonne_idenidlors de la création de la table. Pour plus d'informations sur les paramètres, reportez-vous à la section Transformation Configuration Templates. NoSQL Database Migrator crée une table avec le schéma personnalisé au niveau du récepteur.{ "source" : { "type" : "file", "format" : "mongodb_json", "schemaInfo" : { "schemaPath" : "<complete/path/to/the/schema/file>" }, "dataPath" : "<complete/path/to/the/MongoDB/Formatted/JSON/file>" }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "sampleMongoDBImp", "compartment" : "ocid1.compartment.oc1..aaaaaaaaadeskhnnfkenws4k2vdyklcc32hfpzzz4z3zum3ubhmpz6zxnoza", "includeTTL" : true, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "useSourceSchema" : true }, "credentials" : "<complete/path/to/the/oci/config/file>", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : false, "requestTimeoutMs" : 5000 }, "transforms": { "renameFields" : { "_id":"id" } }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
-
Ouvrez l'invite de commande et accédez au répertoire dans lequel vous avez extrait l'utilitaire NoSQL Database Migrator.
-
Exécutez la commande
runMigratoren transmettant le fichier de configuration. Utilisez l'option--configou-c.$./runMigrator --config <complete/path/to/the/JSON/config/file> -
L'utilitaire procède à la migration des données, comme indiqué ci-dessous.
[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [cloud sink] : start loading DDLs [INFO] [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS sampleMongoDBImp (id INTEGER, name STRING, scores JSON, PRIMARY KEY(SHARD(id))),limits: [100, 60, 1] [INFO] [cloud sink] : completed loading DDLs [INFO] migration started [INFO] [mongo file source] : start parsing MongoDB JSON records from file: mongoDBSample.json [INFO] Migration success for source mongoDBSample. read=5,written=5,failed=0 [INFO] Migration is successful for all the sources. [INFO] migration completed. Records provided by source=5, Records written to sink=5, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 438ms Migration completed.
Vérification
Pour vérifier la migration, vous pouvez vous connecter à la console Oracle NoSQL Database Cloud Service et vérifier que la table sampleMongoDBImp est créée avec les données source. Pour connaître la procédure d'accès à la console, reportez-vous à l'article Accès au service à partir de la console Infrastructure.
-
Dans ce cas d'utilisation, nous utiliserons l'exemple de fichier JSON au format MongoDB exporté à partir d'une application Spring comme source. Pour plus d'informations sur ce format, reportez-vous à Données de printemps.
-
Préparez le fichier de configuration (au format JSON) avec les détails Source et Sink identifiés. Reportez-vous à Modèles de configuration source et Modèles de configuration de récepteur.
Ici, vous indiquez le fichier contenant l'instruction LDD de la table de récepteur dans le paramètre
schemaPathdu modèle de configuration source. Par conséquent, définissez le paramètre de configurationuseSourceSchemasur True dans le modèle de configuration du récepteur.Vous pouvez générer un schéma personnalisé comme suit :
-
Notez les noms et les types de données de chaque colonne à partir des données JSON au format MongoDB.
-
Dans le fichier de schéma, nommez la première colonne (clé primaire)
idde type STRING. Regroupez les champs restants dans un champ nommékv_json_de type JSON, en respectant le format de données Spring. Pour plus d'informations, reportez-vous au modèle de persistance de la structure de données de printemps. -
Enregistrez le fichier de schéma et notez son chemin complet.
Le schéma défini par l'utilisateur suivant est utilisé dans cet exemple :
CREATE TABLE IF NOT EXISTS sampleMongoDBSpringImp(id STRING, kv_json_ JSON, PRIMARY KEY(SHARD(id)))Pour l'exemple de données Spring indiqué ci-dessus, vous devez inclure les transformations suivantes :
-
Transformation
renameFieldspour convertir la colonne_idenid -
Transformation
ignoreFieldspour ignorer la colonne_classet ne pas l'inclure dans la table de récepteur -
Transformation
aggregateFieldspour agréger les champs restants (autres queid) en un champ de type JSON
Pour plus d'informations sur les paramètres, reportez-vous à la section Transformation Configuration Templates. NoSQL Database Migrator crée une table avec le schéma personnalisé au niveau du récepteur.
{ "source": { "type": "file", "format": "mongodb_json", "schemaInfo": { "schemaPath": "<complete/path/to/the/schema/file>" }, "dataPath": "<complete/path/to/the/MongoDB/Formatted/JSON/file>" }, "sink": { "type": "nosqldb_cloud", "endpoint": "us-ashburn-1", "table": "sampleMongoDBSpringImp", "compartment": "ocid1.compartment.oc1..aaaaaaaaadeskhnnfkenws4k2vdyklcc32hfpzzz4z3zum3ubhmpz6zxnoza", "includeTTL": true, "schemaInfo": { "readUnits": 100, "writeUnits": 60, "storageSize": 1, "useSourceSchema": true }, "credentials": "<complete/path/to/the/oci/config/file>", "credentialsProfile": "DEFAULT", "writeUnitsPercent": 90, "overwrite": false, "requestTimeoutMs": 5000 }, "transforms": { "renameFields": { "_id": "id" }, "ignoreFields": ["_class"], "aggregateFields": { "fieldName": "kv_json_", "skipFields": ["id"] } }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
-
Ouvrez l'invite de commande et accédez au répertoire dans lequel vous avez extrait l'utilitaire NoSQL Database Migrator.
-
Exécutez la commande
runMigratoren transmettant le fichier de configuration. Utilisez l'option--configou-c.$./runMigrator --config <complete/path/to/the/JSON/config/file> -
L'utilitaire procède à la migration des données, comme indiqué ci-dessous.
creating source from given configuration: source creation completed creating sink from given configuration: sink creation completed creating migrator pipeline [cloud sink] : start loading DDLs [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS sampleMongoDBSpringImp (id STRING, kv_json_ JSON, PRIMARY KEY(SHARD(id))),limits: [100, 60, 1] [cloud sink] : completed loading DDLs migration started [mongo file source] : start parsing MongoDB JSON records from file: mongodbspring.json Migration success for source mongodbspring. read=3,written=3,failed=0 Migration is successful for all the sources. migration completed. Records provided by source=3, Records written to sink=3, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 393ms Migration completed.
Vérification
Pour vérifier la migration, vous pouvez vous connecter à la console Oracle NoSQL Database Cloud Service et vérifier que la table sampleMongoDBImp est créée avec les données source. Pour connaître la procédure d'accès à la console, reportez-vous à l'article Accès au service à partir de la console Infrastructure.
Migration à partir d'un fichier JSON DynamoDB vers Oracle NoSQL Database Cloud Service
Cet exemple montre comment utiliser Oracle NoSQL Database Migrator pour copier le fichier JSON DynamoDB vers NoSQL Database Cloud Service.
Cas d'emploi
Après avoir évalué plusieurs options, une organisation finalise Oracle NoSQL Database Cloud Service sur une base de données DynamoDB. L'organisation souhaite migrer ses tables et données de DynamoDB vers Oracle NoSQL Database Cloud Service.
Pour plus d'informations, reportez-vous à Mise en correspondance de la table DynamoDB avec la table Oracle NoSQL.
Vous pouvez migrer un fichier ou un répertoire contenant les données JSON exportées par DynamoDB à partir d'un système de fichiers en indiquant le chemin dans le modèle de configuration source.
Un exemple de fichier JSON au format DynamoDB est le suivant :
{"Item":{"Id":{"N":"101"},"Phones":{"L":[{"L":[{"S":"555-222"},{"S":"123-567"}]}]},"PremierCustomer":{"BOOL":false},"Address":{"M":{"Zip":{"N":"570004"},"Street":{"S":"21 main"},"DoorNum":{"N":"201"},"City":{"S":"London"}}},"FirstName":{"S":"Fred"},"FavNumbers":{"NS":["10"]},"LastName":{"S":"Smith"},"FavColors":{"SS":["Red","Green"]},"Age":{"N":"22"},"ttl": {"N": "1734616800"}}}
{"Item":{"Id":{"N":"102"},"Phones":{"L":[{"L":[{"S":"222-222"}]}]},"PremierCustomer":{"BOOL":false},"Address":{"M":{"Zip":{"N":"560014"},"Street":{"S":"32 main"},"DoorNum":{"N":"1024"},"City":{"S":"Wales"}}},"FirstName":{"S":"John"},"FavNumbers":{"NS":["10"]},"LastName":{"S":"White"},"FavColors":{"SS":["Blue"]},"Age":{"N":"48"},"ttl": {"N": "1734616800"}}}Vous exportez la table DynamoDB vers le stockage AWS S3 comme indiqué dans Exportation des données de la table DynamoDB vers Amazon S3.
Exemple
Dans cette démonstration, vous allez apprendre à migrer un fichier JSON DynamoDB vers Oracle NoSQL Database Cloud Service. Vous allez utiliser un fichier de configuration créé manuellement pour cet exemple.
Prérequis
-
Identifiez la source et le récepteur de la migration.
-
Source : Fichier JSON DynamoDB
-
Verrouillage : Oracle NoSQL Database Cloud Service
-
-
Pour importer des données de table DynamoDB vers Oracle NoSQL Database, vous devez d'abord exporter la table DynamoDB vers S3. Reportez-vous aux étapes fournies dans Export des données de table DynamoDB vers Amazon S3 pour exporter votre table. Lors de l'export, vous sélectionnez le format DynamoDB JSON. Les données exportées contiennent des données de table DynamoDB dans plusieurs fichiers
gzip, comme indiqué ci-dessous./ 01639372501551-bb4dd8c3 |-- 01639372501551-bb4dd8c3 ==> exported data prefix |----data |------sxz3hjr3re2dzn2ymgd2gi4iku.json.gz ==>table data |----manifest-files.json |----manifest-files.md5 |----manifest-summary.json |----manifest-summary.md5 |----_started -
Vous devez télécharger les fichiers depuis AWS S3. La structure des fichiers après le téléchargement sera comme indiqué ci-dessous.
download-dir/01639372501551-bb4dd8c3 |----data |------sxz3hjr3re2dzn2ymgd2gi4iku.json.gz ==>table data |----manifest-files.json |----manifest-files.md5 |----manifest-summary.json |----manifest-summary.md5 |----_started -
Identifiez vos informations d'identification cloud OCI et capturez-les dans le fichier de configuration OCI. Enregistrez le fichier de configuration dans le répertoire
/home/<user>/.oci/config. Pour plus de détails, reportez-vous à Obtention d'informations d'identification dans Utilisation d'Oracle NoSQL Database Cloud Service.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... region=us-ashburn-1 key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Identifiez l'adresse de région et le nom du compartiment pour Oracle NoSQL Database Cloud Service.
-
endpoint :
us-ashburn-1 -
compartiment :
Training-NoSQL
-
Procédure
Pour migrer les données JSON DynamoDB vers Oracle NoSQL Database, procédez comme suit :
-
Préparez le fichier de configuration (au format JSON) avec les détails de la source et du récepteur identifiés. Pour plus d'informations, reportez-vous aux sections Source Configuration Templates et Sink Configuration Templates.
Remarque : si les éléments de table JSON exportés par DynamoDB contiennent un attribut de durée de vie, pour éventuellement importer les valeurs de durée de vie, indiquez l'attribut dans le paramètre de configuration
ttlAttributeNamedu modèle de configuration source et définissez le paramètre de configurationincludeTTLsur True dans le modèle de configuration du récepteur. Pour plus d'informations, reportez-vous à Migration des métadonnées de durée de vie des lignes de table.Ici, vous définissez le paramètre de configuration
defaultSchemasur True. Par conséquent, NoSQL Database Migrator crée le schéma par défaut au niveau du récepteur. Vous devez indiquerDDBPartitionKeyet le type de colonne NoSQL correspondant. Sinon, une erreur s'affiche.Pour plus de détails sur le schéma par défaut d'une source JSON exportée DynamoDB, reportez-vous à la rubrique Identifier la source et le récepteur dans Workflow pour Oracle NoSQL Data Migrator.
{ "source" : { "type" : "file", "format" : "dynamodb_json", "ttlAttributeName" : "ttl", "dataPath" : "complete/path/to/the/DynamoDB/Formatted/JSON/file" }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-sanjose-1", "table" : "sampledynDBImp", "compartment" : "ocid 1.compartment.oc1..aaaaaaaa......smq", "includeTTL" : true, "schemaInfo" : { "readUnits" : 10, "writeUnits" : 10, "storageSize" : 1, "schemaPath" : "complete/path/to/the/DDl/file" }, "credentials" : "/home/<username>/.oci/config", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" }Le schéma par défaut suivant est utilisé dans cet exemple :
CREATE TABLE IF NOT EXISTS sampledynDBImp (Id INTEGER, document JSON, PRIMARY KEY(SHARD(Id))) -
Ouvrez l'invite de commande et accédez au répertoire dans lequel vous avez extrait l'utilitaire NoSQL Database Migrator.
-
Exécutez la commande
runMigratoren transmettant des fichiers de configuration distincts. Utilisez l'option--configou-c../runMigrator --config <complete/path/to/the/JSON/config/file> -
L'utilitaire procède à la migration des données comme illustré dans l'exemple suivant :
[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [cloud sink] : start loading DDLs [INFO] [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS sampledynDBImp (Id INTEGER, document JSON, PRIMARY KEY(SHARD(Id))) [INFO] [cloud sink] : completed loading DDLs [INFO] migration started [INFO] Start writing data to OnDB Sink [INFO] executing for source:DynamoSample [INFO] [DDB file source] : start parsing JSON records from file: DynamoSample.json.gz [INFO] Writing data to OnDB Sink completed. [INFO] migration completed. Records provided by source=2, Records written to sink=2, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 45ms Migration completed.
Vérification
Pour valider la migration, vous pouvez vous connecter à la console Oracle NoSQL Database Cloud Service et vérifier que la table sampledynDBImp est créée avec les données source.
-
Préparez le fichier de configuration (au format JSON) avec les détails de la source et du récepteur identifiés. Pour plus d'informations, reportez-vous aux sections Source Configuration Templates et Sink Configuration Templates.
Remarque : si les éléments de table JSON exportés par DynamoDB contiennent un attribut de durée de vie, pour éventuellement importer les valeurs de durée de vie, indiquez l'attribut dans le paramètre de configuration
ttlAttributeNamedu modèle de configuration source et définissez le paramètre de configurationincludeTTLsur True dans le modèle de configuration du récepteur.Ici, vous définissez le paramètre de configuration
defaultSchemasur False. Par conséquent, vous indiquez le fichier contenant l'instruction DDL de la table de récepteur dans le paramètreschemaPath. Pour plus d'informations, reportez-vous à Mise en correspondance de types DynamoDB avec des types Oracle NoSQL.Le schéma défini par l'utilisateur suivant est utilisé dans cet exemple :
CREATE TABLE IF NOT EXISTS sampledynDBImp (Id INTEGER, document JSON, PRIMARY KEY(SHARD(Id)))NoSQL Database Migrator utilise le fichier de schéma pour créer la table au niveau du récepteur dans le cadre de la migration. Tant que les données de clé primaire sont fournies, l'enregistrement JSON d'entrée sera inséré. Sinon, une erreur s'affiche.
Remarque :
-
Si la table de base de données Dynamo a un type de données qui n'est pas pris en charge dans NoSQL Database, la migration échoue.
-
Si les données d'entrée ne contiennent pas de valeur pour une colonne particulière (autre que la clé primaire), la valeur par défaut de la colonne est utilisée. La valeur par défaut doit faire partie de la définition de colonne lors de la création de la table. Par exemple,
id INTEGER not null default 0. Si la colonne n'a pas de définition par défaut, SQL NULL est inséré si aucune valeur n'est fournie pour la colonne. -
Si vous modélisez la table DynamoDB en tant que document JSON, veillez à utiliser la transformation
AggregateFieldsafin d'agréger les données de clé secondaire en une colonne JSON. Pour obtenir des détails, reportez-vous à aggregateFields.
Generated configuration is { "source" : { "type" : "file", "format" : "dynamodb_json", "ttlAttributeName" : "ttl", "dataPath" : "complete/path/to/the/DynamoDB/Formatted/JSON/file" }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-sanjose-1", "table" : "sampledynDBImp", "compartment" : "ocid 1.compartment.oc1..aaaaaaaa......smq", "includeTTL" : true, "schemaInfo" : { "readUnits" : 10, "writeUnits" : 10, "storageSize" : 1, "schemaPath" : "complete/path/to/the/DDl/file" }, "credentials" : "/home/<username>/.oci/config", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
-
Ouvrez l'invite de commande et accédez au répertoire dans lequel vous avez extrait l'utilitaire NoSQL Database Migrator.
-
Exécutez la commande
runMigratoren transmettant des fichiers de configuration distincts. Utilisez l'option--configou-c../runMigrator --config <complete/path/to/the/JSON/config/file> -
L'utilitaire procède à la migration des données comme illustré dans l'exemple suivant :
[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [cloud sink] : start loading DDLs [INFO] [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS sampledynDBImp (Id INTEGER, document JSON, PRIMARY KEY(SHARD(Id))) [INFO] [cloud sink] : completed loading DDLs [INFO] migration started [INFO] Start writing data to OnDB Sink [INFO] executing for source:DynamoSample [INFO] [DDB file source] : start parsing JSON records from file: DynamoSample.json.gz [INFO] Writing data to OnDB Sink completed. [INFO] migration completed. Records provided by source=2, Records written to sink=2, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 45ms Migration completed.
Vérification
Pour valider la migration, vous pouvez vous connecter à la console Oracle NoSQL Database Cloud Service et vérifier que la table sampledynDBImp est créée avec les données source.
Migrer du fichier JSON DynamoDB dans AWS S3 vers Oracle NoSQL Database Cloud Service
Cet exemple montre comment utiliser Oracle NoSQL Database Migrator pour copier le fichier JSON DynamoDB stocké dans une banque AWS S3 vers Oracle NoSQL Database Cloud Service (NDCS).
Cas d'emploi:
Après avoir évalué plusieurs options, une organisation finalise Oracle NoSQL Database Cloud Service sur une base de données DynamoDB. L'organisation souhaite migrer ses tables et données de DynamoDB vers Oracle NoSQL Database Cloud Service.
Pour plus d'informations, reportez-vous à Mise en correspondance de la table DynamoDB avec la table Oracle NoSQL.
Vous pouvez migrer un fichier contenant les données JSON exportées par DynamoDB à partir du stockage AWS S3 en indiquant le chemin dans le modèle de configuration source.
Un exemple de fichier JSON au format DynamoDB est le suivant :
{"Item":{"Id":{"N":"101"},"Phones":{"L":[{"L":[{"S":"555-222"},{"S":"123-567"}]}]},"PremierCustomer":{"BOOL":false},"Address":{"M":{"Zip":{"N":"570004"},"Street":{"S":"21 main"},"DoorNum":{"N":"201"},"City":{"S":"London"}}},"FirstName":{"S":"Fred"},"FavNumbers":{"NS":["10"]},"LastName":{"S":"Smith"},"FavColors":{"SS":["Red","Green"]},"Age":{"N":"22"}}}
{"Item":{"Id":{"N":"102"},"Phones":{"L":[{"L":[{"S":"222-222"}]}]},"PremierCustomer":{"BOOL":false},"Address":{"M":{"Zip":{"N":"560014"},"Street":{"S":"32 main"},"DoorNum":{"N":"1024"},"City":{"S":"Wales"}}},"FirstName":{"S":"John"},"FavNumbers":{"NS":["10"]},"LastName":{"S":"White"},"FavColors":{"SS":["Blue"]},"Age":{"N":"48"}}}Vous exportez la table DynamoDB vers le stockage AWS S3 comme indiqué dans Exportation des données de la table DynamoDB vers Amazon S3.
Exemple :
Pour cette démonstration, vous allez apprendre à migrer un fichier JSON DynamoDB dans une source AWS S3 vers NDCS. Vous allez utiliser un fichier de configuration créé manuellement pour cet exemple.
Prérequis
-
Identifiez la source et le récepteur de la migration.
-
Source : Fichier JSON DynamicoDB dans AWS S3
-
Récepteur : Oracle NoSQL Database Cloud Service
-
-
Identifiez la table dans AWS DynamoDB qui doit être migrée vers NDCS. Connectez-vous à votre console AWS à l'aide de vos informations d'identification. Accédez à DynamoDB. Sous Tables, choisissez la table à migrer.
-
Créez un bucket d'objet et exportez la table vers S3. Depuis votre console AWS, accédez à S3. Sous buckets, créez un bucket d'objet. Revenez à DynamoDB et cliquez sur Exports vers S3. Indiquez la table source et le bucket S3 de destination, puis cliquez sur Exporter.
Reportez-vous aux étapes fournies dans Export de données de table DynamoDB vers Amazon S3 pour exporter votre table. Lors de l'export, vous sélectionnez le format JSON DynamicoDB. Les données exportées contiennent des données de table DynamoDB dans plusieurs fichiers
gzip, comme indiqué ci-dessous./ 01639372501551-bb4dd8c3 |-- 01639372501551-bb4dd8c3 ==> exported data prefix |----data |------sxz3hjr3re2dzn2ymgd2gi4iku.json.gz ==>table data |----manifest-files.json |----manifest-files.md5 |----manifest-summary.json |----manifest-summary.md5 |----_started -
Vous avez besoin d'informations d'identification AWS (y compris l'ID de clé d'accès et la clé d'accès secrète) et de fichiers de configuration (informations d'identification et éventuellement de configuration) pour accéder à AWS S3 à partir du migrateur NoSQL Database. Pour plus d'informations sur les fichiers de configuration, reportez-vous à Définition et affichage des paramètres de configuration. Pour plus d'informations sur la création de clés d'accès, reportez-vous à Création d'une paire de clés.
-
Identifiez vos informations d'identification cloud OCI et capturez-les dans le fichier de configuration OCI. Enregistrez le fichier de configuration dans un répertoire
.ocisous votre répertoire de base (~/.oci/config). Pour plus d'informations, reportez-vous à Obtention d'informations d'identification.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Identifiez l'adresse de région et le nom du compartiment pour Oracle NoSQL Database Cloud Service. Exemple :
-
endpoint :us-phoenix-1
-
compartiment : développeurs
-
Procédure
Pour migrer les données JSON DynamoDB vers Oracle NoSQL Database Cloud Service, utilisez l'une des options suivantes :
-
Préparez le fichier de configuration (au format JSON) avec les détails de la source et du récepteur identifiés. Pour plus d'informations, reportez-vous aux sections Source Configuration Templates et Sink Configuration Templates.
Remarque : si les éléments de votre fichier JSON DynamoDB dans AWS S3 contiennent un attribut de durée de vie, pour éventuellement importer les valeurs de durée de vie, indiquez l'attribut dans le paramètre de configuration
ttlAttributeNamedu modèle de configuration source et définissez le paramètre de configurationincludeTTLsur True dans le modèle de configuration de récepteur. Pour plus d'informations, reportez-vous à Migration des métadonnées de durée de vie des lignes de table.Définissez
defaultSchemasurTRUE. Par conséquent, l'utilitaire de migration crée le schéma par défaut au niveau du récepteur. Vous devez indiquerDDBPartitionKeyet le type de colonne NoSQL correspondant. Sinon, une erreur est générée.{ "source" : { "type" : "aws_s3", "format" : "dynamodb_json", "s3URL" : "<https://<bucket-name>.<s3_endpoint>/export_path>", "credentials" : "</path/to/aws/credentials/file>", "credentialsProfile" : <"profile name in aws credentials file"> }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "<region_name>", "table" : "<table_name>", "compartment" : "<compartment_name>", "schemaInfo" : { "defaultSchema" : true, "readUnits" : 100, "writeUnits" : 60, "DDBPartitionKey" : "<PrimaryKey:Datatype>", "storageSize" : 1 }, "credentials" : "<complete/path/to/the/oci/config/file>", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" }Pour une source JSON DynamoDB, le schéma par défaut de la table sera le suivant :
CREATE TABLE IF NOT EXISTS <TABLE_NAME>(DDBPartitionKey_name DDBPartitionKey_type, [DDBSortKey_name DDBSortKey_type], DOCUMENT JSON, PRIMARY KEY(SHARD(DDBPartitionKey_name),[DDBSortKey_name]))Où :
TABLE_NAME = valeur fournie pour le récepteur 'table' dans la configuration
DDBPartitionKey_name = valeur fournie pour la clé de partition dans la configuration
DDBPartitionKey_type = valeur fournie pour le type de données de la clé de partition dans la configuration
DDBSortKey_name = valeur fournie pour la clé de tri dans la configuration, le cas échéant
DDBSortKey_type = valeur fournie pour le type de données de la clé de tri dans la configuration, le cas échéant
DOCUMENT = Tous les attributs à l'exception de la partition et de la clé de tri d'un élément de table Dynamo DB regroupés dans une colonne NoSQL JSON
-
Ouvrez l'invite de commande et accédez au répertoire dans lequel vous avez extrait l'utilitaire NoSQL Database Migrator.
-
Exécutez la commande
runMigratoren transmettant le fichier de configuration. Utilisez l'option--configou-c.[~/nosqlMigrator]$./runMigrator --config <complete/path/to/the/JSON/config/file> -
L'utilitaire procède à la migration des données, comme indiqué ci-dessous.
Records provided by source=7.., Records written to sink=7, Records failed=0, Records skipped=0. Elapsed time: 0 min 2sec 50ms Migration completed.
Vérification
Vous pouvez vous connecter à la console Oracle NoSQL Database Cloud Service et vérifier que la table est créée avec les données source.
-
Préparez le fichier de configuration (au format JSON) avec les détails de la source et du récepteur identifiés. Pour plus d'informations, reportez-vous aux sections Source Configuration Templates et Sink Configuration Templates.
Remarque : si les éléments de votre fichier JSON DynamoDB dans AWS S3 contiennent un attribut de durée de vie, pour éventuellement importer les valeurs de durée de vie, indiquez l'attribut dans le paramètre de configuration ttlAttributeName du modèle de configuration source et définissez le paramètre de configuration includeTTL sur True dans le modèle de configuration sink. Pour plus d'informations, reportez-vous à Migration des métadonnées de durée de vie des lignes de table.
Pour indiquer un fichier de schéma défini par l'utilisateur dans le modèle de configuration de récepteur, définissez defaultSchema sur
FALSEet indiquez schemaPath en tant que fichier contenant votre instruction DDL. Pour plus d'informations, reportez-vous à Mise en correspondance de types DynamoDB avec des types Oracle NoSQL.Remarque : si la table de base de données Dynamo a un type de données qui n'est pas pris en charge dans NoSQL, la migration échoue.
Un exemple de fichier de schéma est présenté ci-dessous.
CREATE TABLE IF NOT EXISTS sampledynDBImp (AccountId INTEGER,document JSON, PRIMARY KEY(SHARD(AccountId)));Le fichier de schéma est utilisé pour créer la table au niveau du puits dans le cadre de la migration. Tant que les données de clé primaire sont fournies, l'enregistrement JSON d'entrée est inséré, sinon il génère une erreur.
Remarque :
- Si les données d'entrée ne contiennent pas de valeur pour une colonne particulière (autre que la clé primaire), la valeur par défaut de la colonne est utilisée. La valeur par défaut doit faire partie de la définition de colonne lors de la création de la table. Par exemple,
id INTEGER not null default 0. Si la colonne n'a pas de définition par défaut, SQL NULL est inséré si aucune valeur n'est fournie pour la colonne. - Si vous modélisez la table DynamoDB en tant que document JSON, veillez à utiliser la transformation
AggregateFieldsafin d'agréger les données de clé secondaire en une colonne JSON. Pour en savoir plus, reportez-vous à aggregateFields.
{ "source" : { "type" : "aws_s3", "format" : "dynamodb_json", "s3URL" : "<https://<bucket-name>.<s3_endpoint>/export_path>", "credentials" : "</path/to/aws/credentials/file>", "credentialsProfile" : <"profile name in aws credentials file"> }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "<region_name>", "table" : "<table_name>", "compartment" : "<compartment_name>", "schemaInfo" : { "defaultSchema" : false, "readUnits" : 100, "writeUnits" : 60, "schemaPath" : "<full path of the schema file with the DDL statement>", "storageSize" : 1 }, "credentials" : "<complete/path/to/the/oci/config/file>", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "requestTimeoutMs" : 5000 }, "transforms": { "aggregateFields" : { "fieldName" : "document", "skipFields" : ["AccountId"] } }, "abortOnError" : true, "migratorVersion" : "1.8.0" } - Si les données d'entrée ne contiennent pas de valeur pour une colonne particulière (autre que la clé primaire), la valeur par défaut de la colonne est utilisée. La valeur par défaut doit faire partie de la définition de colonne lors de la création de la table. Par exemple,
-
Ouvrez l'invite de commande et accédez au répertoire dans lequel vous avez extrait l'utilitaire NoSQL Database Migrator.
-
Exécutez la commande
runMigratoren transmettant le fichier de configuration. Utilisez l'option--configou-c.[~/nosqlMigrator]$./runMigrator --config <complete/path/to/the/JSON/config/file> -
L'utilitaire procède à la migration des données, comme indiqué ci-dessous.
Records provided by source=7.., Records written to sink=7, Records failed=0, Records skipped=0. Elapsed time: 0 min 2sec 50ms Migration completed.
Vérification
Vous pouvez vous connecter à la console Oracle NoSQL Database Cloud Service et vérifier que la table est créée avec les données source.
Migrer entre les régions Oracle NoSQL Database Cloud Service
Cet exemple montre l'utilisation d'Oracle NoSQL Database Migrator pour effectuer une migration inter-région.
Cas d'emploi
Une organisation utilise Oracle NoSQL Database Cloud Service pour stocker et gérer ses données. Il décide de répliquer les données d'une région existante vers une région plus récente à des fins de test avant de pouvoir lancer la nouvelle région pour l'environnement de production.
Dans ce cas d'utilisation, vous apprendrez à utiliser NoSQL Database Migrator pour copier les données de la table user_data dans la région Ashburn vers la région Phoenix.
Exécutez l'utilitaire runMigrator en transmettant un fichier de configuration pré-créé. Si vous ne fournissez pas le fichier de configuration en tant que paramètre d'exécution, l'utilitaire runMigrator vous invite à générer la configuration via une procédure interactive.
Prérequis
-
Téléchargez Oracle NoSQL Database Migrator à partir de la page Téléchargements Oracle NoSQL et extrayez le contenu sur votre ordinateur. Pour plus d'informations, reportez-vous à Workflow pour Oracle NoSQL Database Migrator.
-
Identifiez la source et le récepteur de la migration.
-
Source : table
user_datadans la région Ashburn.La table
user_datainclut les données suivantes :{"id":40,"firstName":"Joanna","lastName":"Smith","otherNames":[{"first":"Joanna","last":"Smart"}],"age":null,"income":75000,"address":{"city":"Houston","number":401,"phones":[{"area":null,"kind":"work","number":1618955},{"area":451,"kind":"home","number":4613341},{"area":481,"kind":"mobile","number":4613382}],"state":"TX","street":"Tex Ave","zip":95085},"connections":[70,30,40],"email":"joanna.smith123@reachmail.com","communityService":"**"} {"id":10,"firstName":"John","lastName":"Smith","otherNames":[{"first":"Johny","last":"Good"},{"first":"Johny2","last":"Brave"},{"first":"Johny3","last":"Kind"},{"first":"Johny4","last":"Humble"}],"age":22,"income":45000,"address":{"city":"Santa Cruz","number":101,"phones":[{"area":408,"kind":"work","number":4538955},{"area":831,"kind":"home","number":7533341},{"area":831,"kind":"mobile","number":7533382}],"state":"CA","street":"Pacific Ave","zip":95008},"connections":[30,55,43],"email":"john.smith@reachmail.com","communityService":"****"} {"id":20,"firstName":"Jane","lastName":"Smith","otherNames":[{"first":"Jane","last":"BeGood"}],"age":22,"income":55000,"address":{"city":"San Jose","number":201,"phones":[{"area":608,"kind":"work","number":6538955},{"area":931,"kind":"home","number":9533341},{"area":931,"kind":"mobile","number":9533382}],"state":"CA","street":"Atlantic Ave","zip":95005},"connections":[40,75,63],"email":"jane.smith201@reachmail.com","communityService":"*****"} {"id":30,"firstName":"Adam","lastName":"Smith","otherNames":[{"first":"Adam","last":"BeGood"}],"age":45,"income":75000,"address":{"city":"Houston","number":301,"phones":[{"area":618,"kind":"work","number":6618955},{"area":951,"kind":"home","number":9613341},{"area":981,"kind":"mobile","number":9613382}],"state":"TX","street":"Indian Ave","zip":95075},"connections":[60,45,73],"email":"adam.smith201reachmail.com","communityService":"***"}Identifiez l'adresse de région ou l'adresse de service et le nom de compartiment de la source.
-
endpoint :
us-ashburn-1 -
compartiment :
ocid1.compartment.oc1..aaaaaaaahcrgrgptoaq4cgpoymd32ti2ql4sdpu5puroausdf4og55z4tnya
-
-
Dissipateur : table
user_datadans la région Phoenix.Identifiez l'adresse de région ou l'adresse de service et le nom du compartiment pour le récepteur.
-
endpoint :
us-phoenix-1 -
compartiment :
ocid1.compartment.oc1..aaaaaaaaleiwplazhwmicoogv3tf4lum4m4nzbcv5wfjmoxuz3doreagvdma
Identifiez le schéma de la table de récepteur.
Vous pouvez utiliser le même schéma et le même nom de table que la table source. Pour plus d'informations sur les autres options de schéma, reportez-vous à la rubrique Identification de la source et du récepteur dans Workflow pour Oracle NoSQL Database Migrator.
-
-
-
Identifiez vos informations d'identification cloud OCI pour les deux régions et capturez-les dans le fichier de configuration. Enregistrez le fichier de configuration sur votre ordinateur à l'emplacement
/home/<user>/.oci/config. Pour plus d'informations, reportez-vous à Obtention d'informations d'identification.Remarque :
-
Si les régions appartiennent à des locations différentes, vous devez fournir des profils différents dans le fichier
/home//.oci/configavec les informations d'identification cloud OCI appropriées pour chacune d'entre elles. -
Si les régions sont sous la même location, vous pouvez avoir un seul profil dans le fichier
/home//.oci/config.
-
Dans cet exemple, les régions sont sous des locations différentes. Le profil DEFAULT inclut les informations d'identification OCI pour la région Ashburn et DEFAULT2 inclut les informations d'identification OCI pour la région Phoenix.
Dans le paramètre endpoint du fichier de configuration du migrateur (modèles de configuration source et de récepteur), vous pouvez indiquer l'URL de l'adresse de service ou l'ID de région des régions. Pour obtenir la liste des régions de données prises en charge pour Oracle NoSQL Database Cloud Service et leurs URL d'adresse de service, reportez-vous à Régions de données et URL de service associées dans le document Oracle NoSQL Database Cloud Service.
[DEFAULT]
user=ocid1.user.oc1....
fingerprint=fd:96:....
tenancy=ocid1.tenancy.oc1....
region=us-ashburn-1
key_file=</fully/qualified/path/to/the/private/key/>
pass_phrase=abcd
[DEFAULT2]
user=ocid1.user.oc1....
fingerprint=1b:68:....
tenancy=ocid1.tenancy.oc1....
region=us-phoenix-1
key_file=</fully/qualified/path/to/the/private/key/>
pass_phrase=23456Procédure
Pour migrer la table user_data de la région Ashburn vers la région Phoenix, procédez comme suit :
-
Préparez le fichier de configuration (au format JSON) avec les détails de la source et du récepteur identifiés. Reportez-vous aux sections Source Configuration Templates et Sink Configuration Templates.
{ "source" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "user_data", "compartment" : "ocid1.compartment.oc1..aaaaaaaahcrgrgptoaq4cgpoymd32ti2ql4sdpu5puroausdf4og55z4tnya", "credentials" : "/home/<user>/.oci/config", "credentialsProfile" : "DEFAULT", "readUnitsPercent" : 100, "includeTTL" : false, "requestTimeoutMs" : 5000 }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-phoenix-1", "table" : "user_data", "compartment" : "ocid1.compartment.oc1..aaaaaaaaleiwplazhwmicoogv3tf4lum4m4nzbcv5wfjmoxuz3doreagvdma", "includeTTL" : false, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "useSourceSchema" : true }, "credentials" : "/home/<user>/.oci/config", "credentialsProfile" : "DEFAULT2", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Sur votre ordinateur, accédez au répertoire dans lequel vous avez extrait l'utilitaire NoSQL Database Migrator. Vous pouvez accéder à la commande
runMigratordepuis l'interface de ligne de commande. -
Exécutez la commande
runMigratoren transmettant le fichier de configuration à l'aide de l'option –config ou -c.[~/nosql-migrator]$./runMigrator --config <complete/path/to/the/config/file> -
L'utilitaire procède à la migration des données comme indiqué ci-dessous. La table
user_dataest créée au niveau du récepteur avec le même schéma que la table source que vous avez configuré le paramètre useSourceSchema comme vrai dans le modèle de configuration du récepteur.creating source from given configuration: source creation completed creating sink from given configuration: sink creation completed creating migrator pipeline migration started [cloud sink] : start loading DDLs [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS user_data (id INTEGER, firstName STRING, lastName STRING, otherNames ARRAY(RECORD(first STRING, last STRING)), age INTEGER, income INTEGER, address JSON, connections ARRAY(INTEGER), email STRING, communityService STRING, PRIMARY KEY(SHARD(id))),limits: [100, 60, 1] [cloud sink] : completed loading DDLs [cloud sink] : start loading records migration completed. Records provided by source=5, Records written to sink=5, Records failed=0, Records skipped=0. Elapsed time: 0min 5sec 603ms Migration completed.Remarque :
-
Si la table existe déjà dans le puits avec le même schéma que la table source, les lignes avec les mêmes clés primaires sont écrasées car vous avez indiqué le paramètre d'écrasement True dans le modèle de configuration.
-
Si la table existe déjà au niveau du puits avec un schéma différent de celui de la table source, la migration échoue.
-
Validation
Pour valider la migration, vous pouvez vous connecter à la console Oracle NoSQL Database Cloud Service dans la région Phoenix. Vérifiez que les données source de la table user_data dans la région Ashburn sont copiées dans la table user_data de cette région. Pour connaître la procédure d'accès à la console, reportez-vous à l'article Accès au service à partir de la console Infrastructure.
Migrer d'Oracle NoSQL Database Cloud Service vers OCI Object Storage
Cet exemple montre l'utilisation d'Oracle NoSQL Database Migrator à partir d'un shell Cloud Shell.
Cas d'emploi
Une entreprise de démarrage prévoit d'utiliser Oracle NoSQL Database Cloud Service comme solution de stockage de données. L'entreprise souhaite utiliser Oracle NoSQL Database Migrator pour copier des données d'une table dans Oracle NoSQL Database Cloud Service vers OCI Object Storage afin d'effectuer des sauvegardes périodiques de ses données. Par mesure économique, ils souhaitent exécuter l'utilitaire NoSQL Database Migrator à partir de Cloud Shell, qui est accessible à tous les utilisateurs OCI.
Dans ce cas d'utilisation, vous apprendrez à copier l'utilitaire NoSQL Database Migrator vers une instance Cloud Shell de la région abonnée et à effectuer une migration de données. Vous migrez les données source de la table Oracle NoSQL Database Cloud Service vers un fichier JSON dans OCI Object Storage.
Exécutez l'utilitaire runMigrator en transmettant un fichier de configuration pré-créé. Si vous ne fournissez pas le fichier de configuration en tant que paramètre d'exécution, l'utilitaire runMigrator vous invite à générer la configuration via une procédure interactive.
Prérequis
-
Téléchargez Oracle NoSQL Database Migrator à partir de la page Téléchargements Oracle NoSQL vers votre ordinateur local.
-
Lancez Cloud Shell à partir du menu Outils de développement de la console cloud. Le navigateur Web ouvre votre répertoire personnel. Cliquez sur le menu Cloud Shell dans l'angle supérieur droit de la fenêtre Cloud Shell et sélectionnez l'option Télécharger dans la liste déroulante. Dans la fenêtre contextuelle, faites glisser le package Oracle NoSQL Database Migrator à partir de votre ordinateur local ou cliquez sur l'option Sélectionner à partir de votre ordinateur, sélectionnez le package à partir de votre ordinateur local et cliquez sur le bouton Télécharger. Vous pouvez également glisser-déplacer le package de migration Oracle NoSQL Database directement de votre ordinateur local vers votre répertoire de base dans Cloud Shell. Extrayez le contenu du package.
-
Identifiez la source et le récepteur de la sauvegarde.
-
Source : table
NDCSuploaddans la région Ashburn d'Oracle NoSQL Database Cloud Service.Pour la démonstration, tenez compte des données suivantes dans le tableau
NDCSupload:{"id":1,"name":"Jane Smith","email":"iamjane@somemail.co.us","age":30,"income":30000.0} {"id":2,"name":"Adam Smith","email":"adam.smith@mymail.com","age":25,"income":25000.0} {"id":3,"name":"Jennifer Smith","email":"jenny1_smith@mymail.com","age":35,"income":35000.0} {"id":4,"name":"Noelle Smith","email":"noel21@somemail.co.us","age":40,"income":40000.0}Identifiez l'adresse et l'ID de compartiment de la source. Pour l'adresse, vous pouvez indiquer l'identificateur de région ou l'adresse de service. Pour obtenir la liste des régions de données prises en charge dans Oracle NoSQL Database Cloud Service, reportez-vous à Régions de données et URL de service associées.
-
endpoint :
us-ashburn-1 -
ID de compartiment :
ocid1.compartment.oc1..aaaaaaaahcrgrgptoaq4cgpoymd32ti2ql4sdpu5puroausdf4og55z4tnya
-
-
Disque : fichier JSON dans le bucket OCI Object Storage.
Identifiez l'adresse, l'espace de noms, le bucket et le préfixe de région pour OCI Object Storage. Pour plus de détails, reportez-vous à Accès à Oracle Cloud Object Storage. Pour obtenir la liste des adresses de service OCI Object Storage, reportez-vous à Adresses Object Storage.
-
endpoint :
us-ashburn-1 -
bucket :
Migrate_oci -
préfixe :
Delegation -
namespace : <> Si vous ne fournissez pas d'espace de noms, l'utilitaire utilise l'espace de noms par défaut de la location.
Remarque : si le bucket Object Storage se trouve dans un autre compartiment, assurez-vous que vous disposez des privilèges nécessaires pour écrire des objets dans le bucket. Pour plus de détails sur la définition des stratégies, reportez-vous à Ecriture d'objets dans Object Storage.
-
-
Procédure
Pour effectuer une migration d'Oracle NoSQL Database Cloud Service vers OCI Object Storage, effectuez les opérations suivantes dans la fenêtre Cloud Shell :
-
Préparez un fichier de configuration de migrateur,
migrator-config.json, avec la source Oracle NoSQL Database Cloud Service et le récepteur OCI Object Storage. Pour les modèles, reportez-vous aux sections Source Configuration Templates et Sink Configuration Templates. Veillez à définir le paramètreuseDelegationTokensurtruedans les modèles de configuration source et de récepteur.Le modèle de configuration suivant est utilisé dans ce cas d'utilisation :
{ "source" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "NDCSupload", "compartment" : "ocid1.compartment.oc1..aaaaaaaahcrgrgptoaq4cgpoymd32ti2ql4sdpu5puroausdf4og55z4tnya", "useDelegationToken" : true, "readUnitsPercent" : 90, "includeTTL" : true, "requestTimeoutMs" : 5000 }, "sink" : { "type" : "object_storage_oci", "format" : "json", "endpoint" : "us-ashburn-1", "namespace" : "", "bucket" : "Migrate_oci", "prefix" : "Delegation", "chunkSize" : 32, "compression" : "", "useDelegationToken" : true }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
A partir de Cloud Shell, accédez au répertoire dans lequel vous avez extrait l'utilitaire NoSQL Database Migrator.
-
Exécutez la commande
runMigratoren transmettant le fichier de configuration à l'aide des options--configou-c.[~/nosql-migrator]$./runMigrator --config <complete/path/to/the/config/file> -
L'utilitaire NoSQL Database Migrator procède à la migration des données. Comme vous avez défini le paramètre useDelegationToken sur true, Cloud Shell s'authentifie automatiquement à l'aide du jeton de délégation lors de l'exécution de l'utilitaire de migration de base de données NoSQL. NoSQL Database Migrator copie les données de la table
NDCSuploadvers un fichier JSON dans le bucket Object StorageMigrate_oci. Vérifiez la réussite de la sauvegarde des données dans les journaux.[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] migration started [INFO] [OCI OS sink] : writing table schema to Delegation/Schema/schema.ddl [INFO] [OCI OS sink] : start writing records with prefix Delegation [INFO] migration completed. Records provided by source=4,Records written to sink=4,Records failed=0. Elapsed time: 0min 0sec 486ms Migration completed.Remarque :
Les données sont copiées dans le fichier :
Migrate_oci/NDCSupload/Delegation/Data/000000.jsonSelon le paramètre chunkSize dans le modèle de configuration sink, les données source peuvent être divisées en plusieurs fichiers JSON dans le même répertoire.
Le schéma est copié dans le fichier :
Migrate_oci/NDCStable1/Delegation/Schema/schema.ddl
Validation
Pour valider la sauvegarde de données, connectez-vous à la console Oracle NoSQL Database Cloud Service. Parcourez les menus, Storage > Object Storage & Archive Storage > Buckets. Accédez aux fichiers à partir du répertoire NDCSupload/Delegation dans le bucket Migrate_oci. Pour connaître la procédure d'accès à la console, reportez-vous à l'article Accès au service à partir de la console Infrastructure.
Migrer d'OCI Object Storage vers Oracle NoSQL Database Cloud Service à l'aide de l'authentification OKE
Cet exemple montre comment utiliser Oracle NoSQL Database Migrator avec l'authentification d'identité de charge globale OKE pour copier des données d'un fichier JSON dans OCI Object Storage vers la table Oracle NoSQL Database Cloud Service.
Cas d'emploi
En tant que développeur, vous étudiez une option permettant de restaurer des données à partir d'un fichier JSON dans un bucket OCI Object Storage (O/S OCI) vers une table Oracle NoSQL Database Cloud Service (NDCS) à l'aide de NoSQL Database Migrator dans une application en conteneur. Une application en conteneur est un environnement virtualisé qui regroupe l'application et toutes ses dépendances (comme les bibliothèques, les fichiers binaires et les fichiers de configuration) dans un package. L'application peut ainsi être exécutée de manière cohérente dans différents environnements, quelle que soit l'infrastructure sous-jacente.
Vous voulez exécuter NoSQL Database Migrator dans un pod Oracle Cloud Infrastructure Container Engine for Kubernetes (OKE). Pour accéder en toute sécurité au système d'exploitation OCI et aux services NDCS à partir du pod OKE, vous utiliserez la méthode WIA (Workload Identity Authentication).
Dans cette démonstration, vous allez créer une image docker pour NoSQL Database Migrator, copier l'image dans un référentiel de Container Registry, créer un cluster OKE et déployer l'image Migrator dans le pod de cluster OKE pour exécuter l'utilitaire Migrator. Vous y trouverez un fichier de configuration NoSQL Database Migrator créé manuellement pour exécuter l'utilitaire Migrator en tant qu'application conteneurisée.
Prérequis
-
Identifiez la source et le récepteur de la migration.
-
Source : fichiers JSON et fichier de schéma dans le bucket de système d'exploitation OCI.
Identifiez l'adresse, l'espace de noms, le bucket et le préfixe de région pour le bucket de système d'exploitation OCI dans lequel les fichiers et le schéma JSON source sont disponibles. Pour plus de détails, reportez-vous à Accès à Oracle Cloud Object Storage. Pour obtenir la liste des adresses de service de système d'exploitation OCI, reportez-vous à Adresses Object Storage.
-
endpoint :
us-ashburn-1 -
bucket :
Migrate_oci -
préfixe :
userSession -
espace de noms :
idhkv1iewjzj
Le nom d'espace de noms d'un bucket est identique à l'espace de noms de sa location et est généré automatiquement lors de la création de la location. Vous pouvez obtenir le nom de l'espace de noms comme suit :
-
Dans la console Oracle NoSQL Database Cloud Service, accédez à Stockage > Buckets.
-
Sélectionnez votre compartiment dans Portée de la liste et sélectionnez le bucket. La page Détails du bucket affiche le nom dans le paramètre Espace de noms.
Si vous ne fournissez pas de nom d'espace de noms de système d'exploitation OCI, l'utilitaire de migration utilise l'espace de noms par défaut de la location.
-
-
Verrouillage : table
usersdans Oracle NoSQL Database Cloud Service.Identifiez l'adresse de région ou l'adresse de service, ainsi que le nom du compartiment du récepteur :
-
endpoint :
us-ashburn-1 -
compartiment :
ocid1.compartment.oc1..aaaaaaaaleiwplazhwmicoogv3tf4lum4m4nzbcv5wfjmoxuz3doreagvdma
Identifiez le schéma de la table de récepteur.
Pour utiliser le nom de table et le schéma stockés dans le bucket de système d'exploitation OCI, définissez le paramètre
useSourceSchemasur True. Pour plus d'informations sur les autres options de schéma, reportez-vous à la rubrique Identifier la source et le récepteur dans Workflow pour Oracle NoSQL Database Migrator.Remarque : assurez-vous que vous disposez des privilèges d'écriture sur le compartiment dans lequel vous restaurez des données dans la table NDCS. Pour plus de détails, reportez-vous à Gestion des compartiments.
-
-
-
Préparez une image Docker pour NoSQL Database Migrator et déplacez-la vers Container Registry.
-
Obtenez l'espace de noms de location à partir de la console OCI.
Connexion à la console Oracle NoSQL Database Cloud Service. Dans la barre de navigation, sélectionnez le menu Profil, puis Location : <Nom de l'entité>.
Copiez le nom de l'espace de noms Object Storage, qui est l'espace de noms de location, dans le presse-papiers.
-
Créez une image Docker pour l'utilitaire de migration.
Accédez au répertoire dans lequel vous avez extrait l'utilitaire NoSQL Database Migrator. Le package de migration inclut un fichier docker nommé Dockerfile. A partir d'une interface de commande, utilisez la commande suivante pour créer une image Docker de l'utilitaire de migration :
#Command: docker build -t nosqlmigrator:<tag> .#Example: docker build -t nosqlmigrator:1.0 .Vous pouvez indiquer un identificateur de version pour l'image Docker dans l'option
tag. Vérifiez l'image Docker à l'aide de la commande suivante :#Command: Docker images#Example output ------------------------------------------------------------------------------------------ REPOSITORY TAG IMAGE ID CREATED SIZE localhost/nosqlmigrator 1.0 e1dcec27a5cc 10 seconds ago 487 MB quay.io/podman/hello latest 83fc7ce1224f 10 months ago 580 kB docker.io/library/openjdk 17-jdk-slim 8a3a2ffec52a 2 years ago 406 MB ------------------------------------------------------------------------------------------ -
Générez un token d'authentification.
Vous avez besoin d'un jeton d'authentification pour vous connecter au registre de conteneurs afin de stocker l'image Docker du migrateur. Si vous n'avez pas encore de jeton d'authentification, vous devez en générer un. Pour plus d'informations, reportez-vous à Obtention d'un jeton d'authentification.
-
Stockez l'image Docker du migrateur dans Container Registry.
Pour accéder à l'image Docker de migrateur à partir du pod Kubernetes, vous devez stocker l'image dans n'importe quel registre public ou privé. Par exemple, Docker, Artifact Hub, OCI Container Registry, etc. sont quelques registres. Dans cette démonstration, nous utilisons Container Registry. Pour plus d'informations, reportez-vous à Présentation de Container Registry.
-
A partir de la console OCI, créez un référentiel dans Container Registry. Pour plus de détails, reportez-vous à Création d'un référentiel.
Pour cette démonstration, vous allez créer le référentiel
okemigrator.Figure - Référentiel dans Container Registry
-
Connectez-vous au registre de conteneurs à partir de votre interface de commande à l'aide de la commande suivante :
#Command: docker login <region-key>.ocir.io -u <tenancy-namespace>/<user name>password: <Auth token>#Example: docker login iad.ocir.io -u idhx..xxwjzj/rx..xxxxh@oracle.com password: <Auth token>#Output: Login Succeeded!Dans la commande ci-dessus,
region-key: indique la clé de la région dans laquelle vous utilisez Container Registry. Pour plus de détails, reportez-vous à Disponibilité par région.tenancy-namespace: indique l'espace de noms de location que vous avez copié à partir de la console OCI.user name: indique le nom utilisateur de la console OCI.password: indique le jeton d'authentification. -
Balisez et propagez votre image Docker de migrateur vers Container Registry à l'aide des commandes suivantes :
#Command: docker tag <Migrator Docker image> <region-key>.ocir.io/<tenancy-namespace>/<repo>:<tag> docker push <region-key>.ocir.io/<tenancy-namespace>/<repo>:<tag>#Example: docker tag localhost/nosqlmigrator:1.0 iad.ocir.io/idhx..xxwjzj/okemigrator:1.0 docker push iad.ocir.io/idhx..xxwjzj/okemigrator:1.0Dans la commande ci-dessus,
repo: indique le nom du référentiel que vous avez créé dans Container Registry.tag: indique l'identificateur de version de l'image Docker.#Output: Getting image source signatures Copying blob 0994dbbf9a1b done | Copying blob 37849399aca1 done | Copying blob 5f70bf18a086 done | Copying blob 2f263e87cb11 done | Copying blob f941f90e71a8 done | Copying blob c82e5bf37b8a done | Copying blob 2ad58b3543c5 done | Copying blob 409bec9cdb8b done | Copying config e1dcec27a5 done | Writing manifest to image destination
-
-
-
Configurez un cluster OKE avec WIA vers NDCS et le système d'exploitation OCI.
-
Créez un cluster Kubernetes à l'aide d'OKE.
A partir de la console OCI, définissez et créez un cluster Kubernetes en fonction de la disponibilité des ressources réseau à l'aide d'OKE. Vous avez besoin d'un cluster Kubernetes pour exécuter l'utilitaire de migration en tant qu'application en conteneur. Pour plus d'informations sur la création de cluster, reportez-vous à Création de clusters Kubernetes à l'aide de workflows de console.
Pour cette démonstration, vous pouvez créer un cluster géré à noeud unique à l'aide du workflow de création rapide détaillé dans le lien ci-dessus.
Figure - Cluster Kubernetes pour le conteneur de migration
-
Configurez WIA à partir de la console OCI pour accéder aux autres ressources OCI à partir du cluster Kubernetes.
Pour accorder à l'utilitaire de migration l'accès au bucket de système d'exploitation NDCS et OCI lors de l'exécution à partir des pods de cluster Kubernetes, vous devez configurer WIA. Suivez les étapes ci-dessous :
-
Configurez le fichier de configuration kubeconfig du cluster.
-
Dans la console OCI, ouvrez le cluster Kubernetes que vous avez créé et cliquez sur le bouton Accéder au cluster.
-
Dans la boîte de dialogue Accéder au cluster, cliquez sur Accès à Cloud Shell.
-
Cliquez sur Lancer Cloud Shell pour afficher la fenêtre Cloud Shell.
-
Exécutez la commande de l'interface de ligne de commande Oracle Cloud Infrastructure pour configurer le fichier kubeconfig. Vous pouvez copier la commande à partir de la boîte de dialogue Accéder au cluster. Le résultat suivant est attendu :
#Example: oci ce cluster create-kubeconfig --cluster-id ocid1.cluster.oc1.iad.aaa...muqzq --file $HOME/.kube/config --region us-ashburn-1 --token-version 2.0.0 --kube-endpoint PUBLIC_ENDPOINT#Output: New config written to the Kubeconfig file /home/<user>/.kube/config
-
-
Copiez l'OCID du cluster à partir de l'option
cluster-iddans la commande ci-dessus et enregistrez-le pour l'utiliser dans d'autres étapes.ocid1.cluster.oc1.iad.aaa...muqzq -
Créez un espace de noms pour le compte de service Kubernetes à l'aide de la commande suivante dans la fenêtre de shell cloud :
#Command: kubectl create namespace <namespace-name>#Example: kubectl create namespace migrator#Output: namespace/migrator created -
Créez un compte de service Kubernetes pour l'application Migrator dans un espace de noms à l'aide de la commande suivante dans la fenêtre de shell cloud :
#Command: kubectl create serviceaccount <service-account-name> --namespace <namespace-name>#Example: kubectl create serviceaccount migratorsa --namespace migrator#Output: serviceaccount/migratorsa created -
Définissez une stratégie IAM à partir de la console OCI pour permettre à la charge globale d'accéder aux ressources OCI à partir du cluster Kubernetes.
A partir de la console OCI, accédez aux menus Identité et sécurité > Identité > Stratégies. Créez les stratégies suivantes pour autoriser l'accès aux ressources
nosql-familyetobject-family. Utilisez l'OCID du cluster, de l'espace de noms et des valeurs de compte de service des étapes précédentes.#Command: Allow <subject> to <verb> <resource-type> in <location> where <conditions>#Example: Allow any-user to manage nosql-family in compartment Training-NoSQL where all { request.principal.type = 'workload', request.principal.namespace = 'migrator', request.principal.service_account = 'migratorsa', request.principal.cluster_id = 'ocid1.cluster.oc1.iad.aaaaaaaa2o6h5noeut7i4xr2bp4aohcc2ncozgvn3nny3uqu7cvp2rwmuqzq'} Allow any-user to manage object-family in compartment Training-NoSQL where all { request.principal.type = 'workload', request.principal.namespace = 'migrator', request.principal.service_account = 'migratorsa', request.principal.cluster_id = 'ocid1.cluster.oc1.iad.aaaaaaaa2o6h5noeut7i4xr2bp4aohcc2ncozgvn3nny3uqu7cvp2rwmuqzq'}Pour plus de détails sur la création de stratégies, reportez-vous à Utilisation de la console pour créer une stratégie.
-
-
Procédure
Pour migrer du fichier JSON dans le bucket de système d'exploitation OCI vers la table NDCS, effectuez les opérations suivantes à partir de la fenêtre Cloud Shell :
-
Préparez un fichier de configuration de migrateur,
migrator-config.json, avec la source de système d'exploitation OCI et le récepteur NDCS. Pour les modèles, reportez-vous aux sections Source Configuration Templates et Sink Configuration Templates.Pour utiliser OKE WIA afin d'accéder au bucket de système d'exploitation OCI et à NDCS, définissez le paramètre
useOKEWorkloadIdentitysur True dans les modèles de configuration source et de récepteur. Ici, vous allez utiliser le schéma source du fichier LDD de schéma dans le bucket de système d'exploitation OCI. Par conséquent, définissez le paramètreuseSourceSchemasur True dans le modèle de configuration du récepteur.Remarque : lorsque vous utilisez OKE WIA, vous ne pouvez pas générer le fichier de configuration Migrator de manière interactive. Vous devez préparer le fichier de configuration manuellement en vous référant aux modèles de configuration source et de récepteur.
{ "source" : { "type" : "object_storage_oci", "format" : "json", "endpoint" : "us-ashburn-1", "namespace" : "", "bucket" : "Migrate_oci", "prefix" : "userSession", "useOKEWorkloadIdentity" : true }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "users", "compartment" : "Training-NoSQL", "includeTTL" : true, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "useSourceSchema" : true }, "useOKEWorkloadIdentity" : true, "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Créez une ressource de carte de configuration (configmap) pour transmettre le fichier d'entrée de configuration
migrator-config.jsonau conteneur Migrator lors de l'exécution dans le pod Kubernetes. Le configmap monte le fichier de configuration du migrateur dans le système de fichiers du conteneur en tant que volume de montage.#Command: kubectl create configmap oci-migrator-config --from-file=<Migrator configuration file> -n <namespace-name>#Example: kubectl create configmap oci-migrator-config --from-file=migrator-config.json -n migrator#Output: configmap/oci-migrator-config created -
Créez une clé secrète de registre Docker qui inclut les informations d'identification OCI à utiliser lors de l'extraction de l'image Docker de migrateur de Container Registry vers le pod Kubernetes.
#Command: kubectl create secret docker-registry ocirsecret --docker-server=<region-key>.ocir.io --docker-username='tenancy-namespace/username' --docker-password='auth token' --docker-email='<user Email>' -n <namespace-name>#Example: kubectl create secret docker-registry ocirsecret --docker-server=iad.ocir.io --docker-username='idhx..xxwjzj/rx..xxxxh@oracle.com' --docker-password='<Auth token>' --docker-email='rx..xxxxh@oracle.com' -n migrator#Output: secret/ocirsecret created -
Créez un fichier manifeste que vous utiliserez pour spécifier l'image Docker du migrateur. Veillez à fournir les valeurs des étapes précédentes pour l'espace de noms, le nom du compte de service Kubernetes, le nom de l'image Docker, la clé secrète de registre Docker et le fichier configmap. Vous pouvez vous référer à l'exemple de fichier manifeste suivant :
#migrator-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nosql-migrator spec: replicas: 1 selector: matchLabels: app: nosql-migrator template: metadata: labels: app: nosql-migrator spec: serviceAccountName: migratorsa automountServiceAccountToken: true containers: - name: nosqlmigrator image: iad.ocir.io/idhx..xxwjzj/okemigrator:1.0 imagePullPolicy: Always args: ["--config", "/config/migrator-config.json", "--log-level", "DEBUG"] volumeMounts: - name: config-volume mountPath: /config # Mount the file here imagePullSecrets: - name: ocirsecret volumes: - name: config-volume configMap: name: oci-migrator-config -
Déployez l'image Docker du migrateur dans le pod Kubernetes à l'aide de la commande suivante. OKE exécute l'utilitaire Migrator dans un conteneur sur l'un des noeuds du cluster Kubernetes.
#Command: kubectl create -f <manifest file> -n <namespace-name>#Example: kubectl create -f migrator-deployment.yaml -n migrator#Output: deployment.apps/nosql-migrator created -
Vous pouvez consulter les journaux à l'aide des commandes suivantes :
-
Extrayez le nom du pod sur lequel l'utilitaire Migrator s'exécute.
#Command: kubectl get pods -n <namespace-name>#Example: kubectl get pods -n migrator#Output: NAME READY STATUS RESTARTS AGE nosql-migrator-ccdbf549-6sjjg 1/1 Running 0 56s -
Utilisez le nom du pod pour extraire les journaux du migrateur.
#Command: kubectl logs -f <kubernetes cluster pod name> -n <namespace-name>#Example: kubectl logs -f nosql-migrator-ccdbf549-6sjjg -n migrator#Output: SLF4J(I): Connected with provider of type [org.apache.logging.slf4j.SLF4JServiceProvider] [INFO] Configuration for migration: { "source" : { "type" : "object_storage_oci", "format" : "json", "endpoint" : "us-ashburn-1", "namespace" : "idhkv1iewjzj", "bucket" : "Migrate_oci", "prefix" : "userSession", "useOKEWorkloadIdentity" : true }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "users", "compartment" : "Training-NoSQL", "includeTTL" : true, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "useSourceSchema" : true }, "useOKEWorkloadIdentity" : true, "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } [INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] migration started [INFO] [cloud sink] : start loading DDLs [INFO] [cloud sink] : completed loading DDLs [INFO] [cloud sink] : start loading records [INFO] [OCI OS source] : start parsing JSON records from object: users/userSession/Data/users_1_5_0.json [INFO] [OCI OS source] : start parsing JSON records from object: users/userSession/Data/users_6_10_0.json [INFO] migration completed. Records provided by source=5, Records written to sink=5, Records failed=0, Records skipped=0. Elapsed time: 0min 1sec 15ms Migration completed.
Remarque :
Vous pouvez exécuter la migration des données de manière itérative comme suit :
-
Supprimez le conteneur
nosql-migratorà l'aide de la commande suivante :#Command: kubectl delete -f <manifest file> -n <namespace-name>#Example: kubectl delete -f migrator-deployment.yaml -n migrator#Output: deployment.apps "nosql-migrator" deleted -
Mettez à jour le fichier d'entrée de configuration
migrator-config.json. -
Supprimez et recréez le configmap à l'aide des commandes de l'étape 2.
Il n'est pas nécessaire de créer la clé secrète de registre Docker et le fichier manifeste à nouveau.
-
Déployez l'image Docker du migrateur dans le pod Kubernetes à l'aide du fichier manifeste (étape 5).
-
Vérification
Pour vérifier la restauration des données, connectez-vous à la console Oracle NoSQL Database Cloud Service. Dans la barre de navigation, accédez à Bases de données > Base de données NoSQL. Sélectionnez votre compartiment dans la liste déroulante pour visualiser la table users. Pour connaître la procédure d'accès à la console, reportez-vous à Accès au service à partir de la console Infrastructure.
Migrer d'Oracle NoSQL Database vers OCI Object Storage à l'aide de l'authentification par jeton de session
Cet exemple montre comment utiliser Oracle NoSQL Database Migrator avec l'authentification par jeton de session pour copier des données de la table Oracle NoSQL Database vers un fichier JSON dans un bucket OCI Object Storage.
Cas d'emploi
En tant que développeur, vous étudiez une option permettant de sauvegarder les données de table Oracle NoSQL Database vers OCI Object Storage (O/S OCI). Vous voulez utiliser l'authentification par jeton de session.
Dans cette démonstration, vous allez utiliser les commandes de l'interface de ligne de commande OCI pour créer un jeton de session. Vous allez créer manuellement un fichier de configuration Migrator et effectuer la migration des données.
Prérequis
-
Identifiez la source et le récepteur de la migration.
-
Source : table
usersdans Oracle NoSQL Database. -
Sink : fichier JSON dans le bucket de système d'exploitation OCI
Identifiez l'adresse, l'espace de noms, le bucket et le préfixe de région pour le système d'exploitation OCI. Pour plus de détails, reportez-vous à Accès à Oracle Cloud Object Storage. Pour obtenir la liste des adresses de service de système d'exploitation OCI, reportez-vous à Adresses Object Storage.
-
endpoint :
us-ashburn-1 -
bucket :
Migrate_oci -
préfixe :
userSession -
espace de noms :
idhkv1iewjzjLe nom d'espace de noms d'un bucket est identique à celui de la location. Il est généré automatiquement lors de la création de la location. Vous pouvez obtenir le nom de l'espace de noms comme suit :
-
Dans la console Oracle NoSQL Database Cloud Service, accédez à Stockage> Buckets.
-
Sélectionnez le compartiment dans Portée de la liste et sélectionnez le bucket. La page Détails du bucket affiche le nom dans le paramètre Espace de noms.
Si vous ne fournissez pas de nom d'espace de noms de système d'exploitation OCI, l'utilitaire de migration utilise l'espace de noms par défaut de la location.
-
-
Remarque : assurez-vous que vous disposez des privilèges nécessaires pour écrire des objets dans le bucket du système d'exploitation OCI. Pour plus de détails sur la définition des stratégies, reportez-vous à Ecriture dans Object Storage.
-
Pour générer un jeton de session, procédez comme suit :
-
Installez et configurez l'interface de ligne de commande OCI. Reportez-vous à Démarrage rapide.
-
Utilisez l'une des commandes de l'interface de ligne de commande OCI suivantes pour générer un jeton de session. Pour plus d'informations sur les options disponibles, reportez-vous à Authentification basée sur un jeton pour l'interface de ligne de commande.
# Create a session token using OCI CLI from a web browser: oci session authenticate --region <region_name> --profile-name <profile_name> # Example: oci session authenticate --region us-ashburn-1 --profile-name SESSIONPROFILEou
# Create a session token using OCI CLI without a web browser: oci session authenticate --no-browser --region <region_name> --profile-name <profile_name> # Example: oci session authenticate --no-browser --region us-ashburn-1 --profile-name SESSIONPROFILEDans la commande ci-dessus :
region_name: indique l'adresse de région pour le système d'exploitation OCI. Pour obtenir la liste des régions de données prises en charge dans Oracle NoSQL Database Cloud Service, reportez-vous à Régions de données et URL de service associées.profile_name: indique le profil utilisé par la commande de l'interface de ligne de commande OCI pour générer un jeton de session.La commande de l'interface de ligne de commande OCI crée une entrée dans le fichier de configuration OCI au niveau du chemin
$HOME/.oci/config, comme indiqué dans l'exemple suivant :[SESSIONPROFILE] fingerprint=f1:e9:b7:e6:25:ff:fe:05:71:be:e8:aa:cc:3d:0d:23 key_file=$HOME/.oci/sessions/SESSIONPROFILE/oci_api_key.pem tenancy=ocid1.tenancy.oc1..aaaaa ... d6zjq region=us-ashburn-1 security_token_file=$HOME/.oci/sessions/SESSIONPROFILE/tokensecurity_token_filepointe vers le chemin du jeton de session généré à l'aide de la commande de l'interface de ligne de commande OCI ci-dessus.Remarque :
-
Si le profil existe déjà dans le fichier de configuration OCI, la commande de l'interface de ligne de commande OCI remplace le profil par la configuration liée au jeton de session lors de la génération du jeton de session.
-
Spécifiez les éléments suivants dans votre modèle de configuration de récepteur :
-
Chemin du fichier de configuration OCI dans le paramètre d'informations d'identification.
-
Profil utilisé lors de la génération du jeton de session dans le paramètre CredentialsProfile.
"credentials" : "$HOME/.oci/config" "credentialsProfile" : "SESSIONPROFILE"L'utilitaire Migrator extrait automatiquement les détails du jeton de session généré à l'aide des paramètres ci-dessus. Si vous n'indiquez pas le paramètre d'informations d'identification, l'utilitaire de migration recherche le fichier d'informations d'identification dans le chemin
$HOME/.oci. Si vous n'indiquez pas le paramètre CredentialsProfile, l'utilitaire Migrator utilise le nom de profil par défaut (DEFAULT) du fichier de configuration OCI.- Le jeton de session est valide pendant 60 minutes. Pour prolonger la durée de la session, vous pouvez actualiser la session. Pour plus d'informations, reportez-vous à Actualisation d'un jeton.
-
-
Procédure
Pour migrer d'une table Oracle NoSQL Database vers un fichier JSON dans le bucket de système d'exploitation OCI, procédez comme suit :
-
Préparez le fichier de configuration (au format JSON) avec la source Oracle NoSQL Database et le fichier JSON dans le récepteur de bucket de système d'exploitation OCI. Pour les modèles, reportez-vous aux sections Source Configuration Templates et Sink Configuration Templates.
Pour utiliser l'authentification par jeton de session afin d'accéder au bucket de système d'exploitation OCI, définissez le paramètre useSessionToken sur True dans le modèle de configuration de récepteur. En conséquence, spécifiez le chemin de configuration dans le paramètre d'informations d'identification et le nom du profil dans le paramètre CredentialsProfile.
{ "source" : { "type" : "nosqldb", "storeName" : "kvstore", "helperHosts" : ["<hostname>:<port>"], "table" : "users", "includeTTL" : true, "requestTimeoutMs" : 5000 }, "sink" : { "type" : "object_storage_oci", "format" : "json", "endpoint" : "us-ashburn-1", "namespace" : "idhkv1iewjzj", "bucket" : "Migrate_oci", "prefix" : "userSession", "chunkSize" : 32, "compression" : "", "useSessionToken" : true, "credentials" : "$/home/.oci/config", "credentialsProfile" : "SESSIONPROFILE" }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Ouvrez l'invite de commande et accédez au répertoire dans lequel vous avez extrait l'utilitaire NoSQL Database Migrator.
-
Exécutez la commande runMigrator en transmettant l'option de fichier de configuration. Utilisez l'option
--configou-cpour transmettre le fichier de configuration comme suit :./runMigrator --config ./migrator-config.json -
L'utilitaire Migrator procède à la migration des données. Un exemple de sortie est présenté ci-dessous.
Avec le paramètre useSessionToken sur true, l'utilitaire Migrator s'authentifie automatiquement à l'aide du jeton de session. L'utilitaire de migration copie les données de la table
usersvers un fichier JSON dans le bucket de système d'exploitation OCI nomméMigrate_oci. Vérifiez la réussite de la sauvegarde des données dans les journaux.[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [OCI OS sink] : writing table schema to userSession/Schema/schema.ddl [INFO] migration started [INFO] Migration success for source users_6_10. read=2,written=2,failed=0 [INFO] Migration success for source users_1_5. read=3,written=3,failed=0 [INFO] Migration is successful for all the sources. [INFO] migration completed. Records provided by source=5, Records written to sink=5, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 982ms Migration completed.Remarque :
Selon le paramètre chunkSize du modèle de configuration sink, l'utilitaire Migrator divise les données source en plusieurs fichiers JSON dans le même répertoire. Dans cet exemple, l'utilitaire Migrator copie les données dans les fichiers
users_1_5_0.jsonetusers_6_10_0.jsondu répertoireMigrate_oci/userSession/Data.Le schéma de la table source est copié dans le fichier
schema.ddldu répertoireMigrate_oci/userSession/Schema.
Vérification
Pour vérifier la sauvegarde de données, connectez-vous à la console Oracle NoSQL Database Cloud Service. Parcourez les menus, Storage > Object Storage & Archive Storage > Buckets. Accédez aux fichiers à partir du répertoire userSession dans le bucket Migrate_oci. Pour connaître la procédure d'accès à la console, reportez-vous à Accès au service à partir de la console Infrastructure.
Migrer d'un fichier CSV à Oracle NoSQL Database Cloud Service
Cet exemple montre l'utilisation d'Oracle NoSQL Database Migrator pour copier des données d'un fichier CSV vers Oracle NoSQL Database Cloud Service.
Exemple
Après avoir évalué plusieurs options, une organisation finalise Oracle NoSQL Database Cloud Service en tant que plate-forme NoSQL Database. Le contenu source étant au format CSV, l'entreprise cherche un moyen de le migrer vers Oracle NoSQL Database Cloud Service.
Dans cet exemple, vous apprendrez à migrer les données à partir d'un fichier CSV appelé course.csv, qui contient des informations sur les différents cours proposés par une université. Vous générez le fichier de configuration de manière interactive à partir de l'utilitaire runMigrator.
Vous pouvez également préparer le fichier de configuration avec les détails de source et de récepteur identifiés. Reportez-vous à Référence Oracle NoSQL Database Migrator.
Prérequis
-
Identifiez la source de la migration.
-
Source : fichier CSV
Dans cet exemple, le fichier source est
course.csv1,"Computer Science", "San Francisco", "2500" 2,"Bio-Technology", "Los Angeles", "1200" 3,"Journalism", "Las Vegas", "1500" 4,"Telecommunication", "San Francisco", "2500" -
Le fichier CSV doit être conforme au format
RFC4180. -
Créez un fichier contenant les commandes LDD pour le schéma de la table cible,
course. La définition de la table doit correspondre au fichier de données CSV concernant le nombre de colonnes et leur type.Dans cet exemple, le fichier LDD est
mytable_schema.ddlcreate table course (id INTEGER, name STRING, location STRING, fees INTEGER, PRIMARY KEY(id));
-
-
Identifiez l'évier de migration.
-
Verrouillage : Oracle NoSQL Database Cloud Service
-
Identifiez vos informations d'identification cloud OCI et capturez-les dans le fichier de configuration. Enregistrez le fichier de configuration dans
/home/<user>/.oci/config. Pour plus d'informations, reportez-vous à Obtention d'informations d'identification.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... region=us-ashburn-1 key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Identifiez l'adresse de région et le nom du compartiment pour Oracle NoSQL Database Cloud Service.
-
endpoint :
us-ashburn-1 -
compartiment :
ocid1.compartment.oc1..aaaaaaaavjikiwmylfnpofefbdaleg6rqyf7cdnr5o6vozg4lyajeunrhsmq
-
-
Procédure
Pour migrer des données d'un fichier course.csv vers Oracle NoSQL Database Cloud Service, procédez comme suit :
-
Ouvrez l'invite de commande et accédez au répertoire dans lequel vous avez extrait l'utilitaire de migration Oracle NoSQL Database.
-
Pour générer le fichier de configuration à l'aide d'Oracle NoSQL Database Migrator, exécutez la commande
runMigratorsans paramètre d'exécution.[~/nosql-migrator-1.8.0]$./runMigrator -
Comme vous n'avez pas fourni le fichier de configuration en tant que paramètre d'exécution, l'utilitaire vous invite à générer la configuration maintenant. Saisissez
y.Vous pouvez choisir un emplacement pour le fichier de configuration ou conserver l'emplacement par défaut en appuyant sur
Enter key.Configuration file is not provided. Do you want to generate configuration? (y/n) [n]: y Generating a configuration file interactively. Enter a location for your config [./migrator-config.json]: ./migrator-config.json already exist. Do you want to overwrite?(y/n) [n]: y -
En fonction des invites de l'utilitaire, choisissez vos options pour la configuration source.
Select the source: 1) nosqldb 2) nosqldb_cloud 3) file 4) object_storage_oci 5) aws_s3 #? 3 Configuration for source type=file Select the source file format: 1) json 2) mongodb_json 3) dynamodb_json 4) csv #? 4 -
Indiquez le chemin d'accès au fichier CSV source. En outre, en fonction des invites de l'utilitaire, vous pouvez choisir de réorganiser les noms de colonne, de sélectionner la méthode d'encodage et de couper les espaces de fin de la table cible.
Enter path to a file or directory containing csv data: [~/nosql-migrator]/course.csv Does the CSV file contain a headerLine? (y/n) [n]: n Do you want to reorder the column names of NoSQL table with respect to CSV file columns? (y/n) [n]: n Provide the CSV file encoding. The supported encodings are: UTF-8,UTF-16,US-ASCII,ISO-8859-1. [UTF-8]: Do you want to trim the tailing spaces? (y/n) [n]: n -
En fonction des invites de l'utilitaire, choisissez l'option
nosqldb_cloudpour la configuration Sink.Select the sink: 1) nosqldb 2) nosqldb_cloud #? 2 -
Indiquez l'URL d'adresse ou l'ID de région de votre location, puis sélectionnez le type d'authentification permettant à l'utilitaire de migration d'accéder à Oracle NoSQL Database Cloud Service.
Configuration for sink type=nosqldb_cloud Enter endpoint URL or region ID of the Oracle NoSQL Database Cloud: us-ashburn-1 Select the authentication type: 1) credentials_file 2) instance_principal 3) delegation_token 4) session_token 5) oke_workload_identity #? 1 -
En fonction des invites de l'utilitaire, indiquez le nom du fichier d'informations d'identification à utiliser pour l'authentification, le profil d'informations d'identification, l'ID de compartiment et le nom de la table dans laquelle copier les données au niveau du puits.
Enter path to the file containing OCI credentials [/home/<user>/.oci/config]: Enter the profile name in OCI credentials file [DEFAULT]: Enter the compartment name or id of the table []: ua_nosql Enter table name: course -
Saisissez votre choix pour définir la valeur de durée de vie. La valeur par défaut est
n.Include TTL data? If you select 'yes' TTL value provided by the source will be set on imported rows. (y/n) [n]: y Would you like to provide TTL reference time?(y/n) [n]: n -
En fonction des invites de l'utilitaire, indiquez si la table cible doit être créée via l'outil de migration Oracle NoSQL Database. Si la table est déjà créée, il est suggéré de fournir
n. Si la table n'est pas créée, l'utilitaire demande le chemin du fichier contenant les commandes LDD pour le schéma de la table cible.Would you like to create table as part of migration process? Use this option if you want to create table through the migration tool. If you select yes, you will be asked to provide a file that contains table DDL or to use schema provided by the source or default schema. (y/n) [n]: y Enter path to a file containing table DDL: [~/nosql-migrator]/mytable_schema.ddl -
Entrez les valeurs de débit et l'allocation de stockage pour la table de récepteur.
Would you like to use on demand read and write units? (y/n) [n]: n Enter read throughput in KB of new table: 100 Enter write throughput in KB of new table: 60 Enter storage size in GB of new table: 1 Enter percentage of table write units to be used for migration operation. (1-100) [90]: 90 -
Saisissez vos choix pour déterminer si les enregistrements doivent être remplacés si la table est déjà disponible au niveau de l'évier. Vous pouvez également ajouter des transformations à vos données source.
would you like to overwrite records which are already present? If you select 'no' records with same primary key will be skipped [y/n] [y]: y Enter store operation timeout in milliseconds. [5000]: Would you like to add transformations to source data? (y/n) [n]: n Would you like to continue migration if any data fails to be migrated? (y/n) [n]: n -
L'utilitaire affiche la configuration générée à l'écran.
{ "source" : { "type" : "file", "format" : "csv", "dataPath" : "[~/nosql-migrator]/course.csv", "hasHeader" : false, "csvOptions" : { "encoding" : "UTF-8", "trim" : false } }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "course", "compartment" : "ua_nosql", "includeTTL" : true, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "schemaPath" : "[~/nosql-migrator]/mytable_schema.ddl" }, "credentials" : "/home/<user>/.oci/config", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Enfin, l'utilitaire vous invite à indiquer si la migration doit être effectuée à l'aide du fichier de configuration généré. L'option par défaut est
y.Remarque :
Si vous sélectionnez
n, la migration des données n'est pas lancée. Le fichier de configuration généré est enregistré dans le répertoire Migrator. Utilisez l'une des commandes suivantes pour exécuter l'utilitaire Migration avec l'option de fichier de configuration../runMigrator -c ./migrator-config.json./runMigrator --config ./migrator-config.jsonWould you like to run the migration with above configuration? If you select no, you can use the generated configuration file to run the migration using: ./runMigrator --config ./migrator-config.json (y/n) [y]: y -
NoSQL Database Migrator copie vos données du fichier CSV dans Oracle NoSQL Database Cloud Service.
creating source from given configuration: source creation completed creating sink from given configuration: sink creation completed creating migrator pipeline [cloud sink] : start loading DDLs [cloud sink] : executing DDL: create table if not exists course (id INTEGER, name STRING, location STRING, fees INTEGER, PRIMARY KEY(id)),limits: [100, 60, 1] [cloud sink] : completed loading DDLs migration started [csv file source] : start parsing CSV records from file: course.csv Migration success for source course. read=4,written=4,failed=0 Migration is successful for all the sources. migration completed. Records provided by source=4, Records written to sink=4, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 395ms Migration completed.
Vérification
Pour vérifier la migration, vous pouvez vous connecter à la console Oracle NoSQL Database Cloud Service et accéder à la table course. La table contient les données source. Pour connaître la procédure d'accès à la console, reportez-vous à l'article Accès au service à partir de la console Infrastructure dans le document Oracle NoSQL Database Cloud Service.