Remarque :
- Ce tutoriel nécessite un accès à Oracle Cloud. Pour vous inscrire à un compte gratuit, reportez-vous à Introduction au niveau gratuit d'Oracle Cloud Infrastructure.
- Il utilise des exemples de valeur pour les informations d'identification Oracle Cloud Infrastructure, la location et les compartiments. A la fin de votre atelier, remplacez ces valeurs par celles propres à votre environnement cloud.
Utilisation d'OCI Data Flow avec Apache Spark Streaming pour traiter un sujet Kafka dans une application évolutive et quasiment en temps réel
Introduction
Oracle Cloud Infrastructure (OCI) Data Flow est un service géré pour le projet open source nommé Apache Spark. Fondamentalement, avec Spark, vous pouvez l'utiliser pour le traitement massif de fichiers, la transmission en continu et les opérations de base de données. Vous pouvez créer des applications avec un traitement très évolutif. Spark peut redimensionner et utiliser des machines en cluster pour paralléliser des travaux avec une configuration minimale.
Avec Spark en tant que service géré (Data Flow), vous pouvez ajouter de nombreux services évolutifs pour multiplier la puissance du traitement cloud. Data Flow a la possibilité de traiter Spark Streaming.
Les applications Streaming nécessitent une exécution continue pendant une longue période qui s'étend souvent au-delà de 24 heures et peut durer aussi longtemps que des semaines, voire des mois. En cas de panne inattendue, les applications de transmission en continu doivent redémarrer à partir du point de panne sans produire de résultats de calcul incorrects. Data Flow s'appuie sur des points de reprise de transmission en continu structuré Spark pour enregistrer le décalage traité qui peut être stocké dans votre bucket Object Storage.
Remarque : si vous devez traiter les données en tant que stratégie de traitement par lots, vous pouvez lire cet article : Traiter des fichiers volumineux dans Autonomous Database et Kafka avec Oracle Cloud Infrastructure Data Flow

Dans ce tutoriel, vous pouvez voir les activités les plus courantes utilisées pour traiter la diffusion en continu de volume de données, interroger la base de données et fusionner/joindre les données pour former une autre table en mémoire ou envoyer des données vers n'importe quelle destination quasiment en temps réel. Vous pouvez écrire ces données massives dans votre base de données et dans une file d'attente Kafka avec des performances très économiques et très efficaces.
Objectifs
- Découvrez comment utiliser Data Flow pour traiter une grande quantité de données dans une application évolutive et quasiment en temps réel.
Prérequis
-
Locataire Oracle Cloud opérationnel : vous pouvez créer un compte Oracle Cloud gratuit avec 300,00 USD par mois pour tester ce tutoriel. Reportez-vous à Création d'un compte Oracle Cloud gratuit
-
Interface de ligne de commande OCI (interface de ligne de commande Oracle Cloud) installée sur votre ordinateur local : lien permettant d'installer l'interface de ligne de commande OCI.
-
Application Apache Spark installée sur votre ordinateur local. Reportez-vous à Développement local d'applications Oracle Cloud Infrastructure Data Flow et déploiement vers le cloud pour comprendre le développement en local et dans Data Flow.
Remarque : il s'agit de la page officielle à installer : Apache Spark. Il existe d'autres procédures pour installer Apache Spark pour chaque type de système opérationnel (Linux/Mac OS/Windows).
-
Interface de ligne de commande de soumission Spark installée. Lien permettant d'installer l'interface de ligne de commande de soumission Spark.
-
Maven installé sur votre ordinateur local.
-
Connaissance des concepts OCI :
- Catégories
- Stratégies IAM
- Location
- OCID de vos ressources
Tâche 1 : création de la structure Object Storage
Object Storage sera utilisé comme référentiel de fichiers par défaut. Vous pouvez utiliser d'autres types de référentiel de fichiers, mais Object Storage est un moyen simple et économique de manipuler des fichiers avec de meilleures performances. Dans ce tutoriel, les deux applications chargeront un fichier CSV volumineux à partir du stockage d'objets, indiquant comment Apache Spark est rapide et intelligent pour traiter un volume élevé de données.
-
Créer un compartiment : les compartiments sont importants pour organiser et isoler les ressources cloud. Vous pouvez isoler vos ressources en fonction des stratégies IAM.
-
Vous pouvez utiliser ce lien pour comprendre et configurer les stratégies des compartiments : Gestion des compartiments
-
Créez un compartiment pour héberger toutes les ressources des 2 applications de ce tutoriel. Créez un compartiment nommé analytics.
-
Accédez au menu principal Oracle Cloud et recherchez : Identité et sécurité, Compartiments. Dans la section Compartiments, cliquez sur Créer un compartiment et entrez le nom.

Remarque : vous devez accorder l'accès à un groupe d'utilisateurs et inclure votre utilisateur.
-
Cliquez sur Créer un compartiment pour inclure le compartiment.
-
-
Créez votre bucket dans Object Storage : les buckets sont des conteneurs logiques pour le stockage d'objets. Tous les fichiers utilisés pour cette démo seront donc stockés dans ce bucket.
-
Accédez au menu principal Oracle Cloud et recherchez Stockage et Buckets. Dans la section Buckets, sélectionnez votre compartiment (analytiques), créé précédemment.

-
Cliquez sur Créer un bucket. Créer 4 buckets : apps, data, dataflow-logs, Wallet

-
Entrez les informations de nom de bucket avec ces 4 buckets et conservez les autres paramètres avec la sélection par défaut.
-
Pour chaque bucket, cliquez sur Créer. Vous pouvez voir les buckets créés.

-
Remarque : vérifiez les stratégies IAM pour le bucket. Vous devez configurer les stratégies si vous souhaitez utiliser ces buckets dans vos applications de démonstration. Vous pouvez consulter les concepts et effectuer la configuration ici Présentation d'Object Storage et Stratégies IAM.
Tâche 2 : création d'Autonomous Database
Oracle Cloud Autonomous Database est un service géré pour Oracle Database. Pour ce tutoriel, les applications se connecteront à la base de données via un portefeuille pour des raisons de sécurité.
-
Instanciez Autonomous Database comme décrit ici : Provisionnement d'Autonomous Database.
-
Dans le menu principal Oracle Cloud, sélectionnez l'option Data Warehouse, sélectionnez Oracle Database et Autonomous Data Warehouse, sélectionnez votre compartiment analytiques et suivez le tutoriel pour créer l'instance de base de données.
-
Nommez votre instance Journaux traités, choisissez Journaux comme nom de base de données et vous n'avez pas besoin de modifier de code dans les applications.
-
Entrez le mot de passe ADMIN et téléchargez le fichier ZIP du portefeuille.

-
Après avoir créé la base de données, vous pouvez configurer le mot de passe utilisateur ADMIN et télécharger le fichier ZIP Wallet.



-
Enregistrez votre fichier ZIP de portefeuille (
Wallet_logs.zip) et annotez votre mot de passe ADMIN. Vous devez configurer le code de l'application. -
Accédez à Stockage, Buckets. Passez au compartiment analytics et le bucket Wallet apparaît. Cliquez dessus.
-
Pour télécharger le fichier ZIP de portefeuille, cliquez simplement sur Télécharger et joignez le fichier Wallet_logs.zip.

Remarque : passez en revue les stratégies IAM permettant d'accéder à Autonomous Database ici : Stratégie IAM pour Autonomous Database
Tâche 3 : chargement des exemples de fichiers CSV
Pour démontrer la puissance d'Apache Spark, les applications lisent un fichier CSV de 1 000 000 lignes. Ces données seront insérées dans la base de données Autonomous Data Warehouse avec une seule ligne de commande et publiées sur une diffusion en continu Kafka (Oracle Cloud Streaming). Toutes ces ressources sont évolutives et parfaites pour un volume de données élevé.
-
Téléchargez ces 2 liens et téléchargez-les vers le bucket data :
-
Remarque :
- organizations.csv comporte seulement 100 lignes, uniquement pour tester les applications sur votre ordinateur local.
- organizations1M.csv contient 1 000 000 lignes et sera utilisé pour s'exécuter sur l'instance Data Flow.
-
Dans le menu principal d'Oracle Cloud, accédez à Stockage et à Buckets. Cliquez sur le bucket data et téléchargez les 2 fichiers de l'étape précédente.


-
Télécharger une table auxiliaire vers la base de données ADW
-
Téléchargez ce fichier pour le téléchargement vers la base de données ADW : GDP PER CAPTA COUNTRY.csv
-
Dans le menu principal d'Oracle Cloud, sélectionnez Oracle Database et Autonomous Data Warehouse.
-
Cliquez sur l'instance Journaux traités pour visualiser les détails.
-
Cliquez sur Actions de base de données pour accéder aux utilitaires de base de données.

-
Entrez vos informations d'identification pour l'utilisateur ADMIN.

-
Cliquez sur l'option SQL pour accéder aux utilitaires de requête.

-
Cliquez sur Chargement des données.

-
Déposez le fichier GDP PER CAPTA COUNTRY.csv dans le panneau de la console et procédez à l'importation des données dans une table.

-
La nouvelle table nommée GDPPERCAPTA a été importée.

Tâche 4 : création d'un coffre secret pour votre mot de passe ADMIN ADW
Pour des raisons de sécurité, le mot de passe ADMIN ADW sera enregistré dans un coffre. Oracle Cloud Vault peut héberger ce mot de passe en toute sécurité et est accessible sur votre application avec l'authentification OCI.
-
Créez votre clé secrète dans un coffre, comme décrit dans la documentation suivante : Ajoutez le mot de passe d'administrateur de base de données à Vault
-
Créez une variable nommée PASSWORD_SECRET_OCID dans vos applications et entrez l'OCID.



Remarque : vérifiez la stratégie IAM pour OCI Vault ici : stratégie IAM OCI Vault.
Tâche 5 : création d'une diffusion en continu Kafka (Oracle Cloud Streaming)
Oracle Cloud Streaming est un service Kafka de diffusion en continu géré. Vous pouvez développer des applications à l'aide des API Kafka et des SDK courants. Dans ce tutoriel, vous allez créer une instance de Streaming et la configurer pour l'exécuter dans les deux applications afin de publier et d'utiliser un grand volume de données.
-
Dans le menu principal d'Oracle Cloud, accédez à Analytics et IA, Streams.
-
Remplacez le compartiment par analytics. Chaque ressource de cette démonstration sera créée sur ce compartiment. Le service IAM est ainsi plus sécurisé et plus facile à contrôler.
-
Cliquez sur Créer un flux de données.

-
Entrez le nom kafka_like (par exemple) et vous pouvez conserver tous les autres paramètres avec les valeurs par défaut.

-
Cliquez sur Créer pour initialiser l'instance.
-
Attendez le statut Active. Vous pouvez désormais utiliser l'instance.
Remarque : lors du processus de création de la transmission en continu, vous pouvez sélectionner l'option Créer automatiquement un pool de flux de données par défaut pour créer automatiquement votre pool par défaut.
-
Cliquez sur le lien DefaultPool.

-
Affichez le paramètre de connexion.


-
Annotez ces informations comme vous en aurez besoin à l'étape suivante.
Remarque : passez en revue les stratégies IAM pour OCI Streaming ici : Stratégie IAM pour OCI Streaming.
Tâche 6 : génération d'un TOKEN AUTH pour accéder à Kafka
Vous pouvez accéder à OCI Streaming (API Kafka) et à d'autres ressources dans Oracle Cloud avec un jeton d'authentification associé à votre utilisateur sur OCI IAM. Dans les paramètres de connexion Kafka, les chaînes de connexion SASL comportent un paramètre nommé password et une valeur AUTH_TOKEN, comme décrit dans la tâche précédente. Pour activer l'accès à OCI Streaming, vous devez accéder à votre utilisateur sur la console OCI et créer un TOKEN AUTH.
-
Dans le menu principal d'Oracle Cloud, accédez à Identité et sécurité, Utilisateurs.
Remarque : l'utilisateur dont vous avez besoin pour créer l'élément AUTH TOKEN est configuré avec l'interface de ligne de commande OCI et toutes les configurations Stratégies IAM pour les ressources créées jusqu'à présent. Les ressources sont les suivantes :
- Oracle Cloud Autonomous Data Warehouse
- Oracle Cloud Streaming
- Oracle Object Storage
- Oracle Data Flow
-
Cliquez sur votre nom utilisateur pour afficher les détails.

-
Cliquez sur l'option Jetons d'authentification sur le côté gauche de la console et cliquez sur Générer un jeton.
Remarque : le jeton sera généré uniquement à cette étape et ne sera plus visible une fois l'étape terminée. Copiez la valeur et enregistrez-la. Si vous perdez la valeur de jeton, vous devez à nouveau générer le jeton d'authentification.


Tâche 7 : Configurer l'application Demo
Ce tutoriel dispose d'une application de démonstration pour laquelle nous allons configurer les informations requises.
- DataflowSparkStreamDemo : cette application se connectera à Kafka Streaming, utilisera toutes les données et fusionnera avec une table ADW nommée GDPPERCAPTA. Les données de flux seront fusionnées avec GDPPERCAPTA et seront enregistrées en tant que fichier CSV, mais elles peuvent être exposées à un autre sujet Kafka.
-
Téléchargez l'application à l'aide du lien suivant :
-
Recherchez les détails suivants dans la console Oracle Cloud :
-
Espace de noms de location


-
Clé secrète de mot de passe
-
Paramètres de connexion de transmission en continu
-
Jeton d'authentification
-
-
Ouvrez le fichier ZIP téléchargé (
Java-CSV-DB.zipetJavaConsumeKafka.zip). Accédez au dossier /src/main/java/example et recherchez le code Example.java.
Il s'agit des variables à modifier avec les valeurs des ressources de votre location.
NOM VARIABLE NOM DE RESSOURCE TITRE DES INFORMATIONS bootstrapServers Paramètres de connexion de transmission en continu serveurs de démarrage streamPoolId Paramètres de connexion de transmission en continu Valeur ocid1.streampool.oc1.iad..... dans la chaîne de connexion SASL kafkaUsername Paramètres de connexion de transmission en continu valeur usename in " " dans la chaîne de connexion SASL kafkaPassword Jeton d'authentification La valeur est affichée uniquement à l'étape de création OBJECT_STORAGE_NAMESPACE ESPACE DE NOMS DE LOCATION LOCATION ESPACE DE NOMS ESPACE DE NOMS DE LOCATION LOCATION PASSWORD_SECRET_OCID PASSWORD_SECRET_OCID OCID
Remarque : toutes les ressources créées pour cette démonstration se trouvent dans la région US-ASHBURN-1. Vérifiez la région que vous souhaitez utiliser. Si vous modifiez la région, vous devez modifier 2 points dans 2 fichiers de code :
Example.java : modifiez la variable bootstrapServers en remplaçant "us-ashburn-1" par la nouvelle région.
OboTokenClientConfigurator.java : modifiez la variable CANONICAL_REGION_NAME avec votre nouvelle région
Tâche 8 : comprendre le code Java
Ce tutoriel a été créé en Java et ce code peut également être porté en Python. Pour prouver l'efficacité et l'évolutivité, l'application a été développée pour montrer certaines possibilités dans un cas d'utilisation commun d'un processus d'intégration. Le code de l'application présente donc les exemples suivants :
- Se connecter au flux Kafka et lire les données
- Traiter les jointures avec une table ADW pour créer des informations utiles
- La sortie d'un fichier CSV contenant toutes les informations utiles provient de Kafka
Cette démonstration peut être exécutée sur votre ordinateur local et déployée dans l'instance Data Flow pour être exécutée en tant que travail.
Remarque : pour le travail Data Flow et votre machine locale, utilisez la configuration de l'interface de ligne de commande OCI pour accéder aux ressources OCI. Du côté du flux de données, tout est préconfiguré. Il n'est donc pas nécessaire de modifier les paramètres. Côté machine locale, vous devez avoir installé l'interface de ligne de commande OCI et configuré le locataire, l'utilisateur et la clé privée pour accéder à vos ressources OCI.
Affichons le code Example.java dans les sections :
-
Initialisation Apache Spark : cette partie du code représente l'initialisation Spark. De nombreux paramètres permettant d'exécuter des processus d'exécution sont configurés automatiquement. Il est donc très facile d'utiliser le moteur Spark. L'initialisation diffère si vous êtes en cours d'exécution dans Data Flow ou sur votre ordinateur local. Si vous êtes dans Data Flow, vous n'avez pas besoin de charger le fichier ZIP de portefeuille ADW. La tâche de chargement, de décompression et de lecture des fichiers de portefeuille est automatique dans l'environnement Data Flow, mais dans l'ordinateur local, elle doit être effectuée à l'aide de certaines commandes.

-
Lisez la clé secrète ADW Vault : cette partie du code accède à votre coffre pour obtenir la clé secrète de votre instance Autonomous Data Warehouse.

-
Interroger une table ADW : Cette section indique comment exécuter une requête sur une table.

-
Opérations Kafka : préparation de la connexion à OCI Streaming à l'aide de l'API Kafka.
Remarque : Oracle Cloud Streaming est compatible avec la plupart des API Kafka.

Un processus permet d'analyser les données JSON provenant de la rubrique Kafka dans un ensemble de données avec la structure correcte (ID d'organisation, nom, pays).
-
Fusionner les données d'un ensemble de données Kafka et d'un ensemble de données Autonomous Data Warehouse : cette section explique comment exécuter une requête avec 2 ensembles de données.

-
Sortie dans un fichier CSV : voici comment les données fusionnées génèrent la sortie dans un fichier CSV.

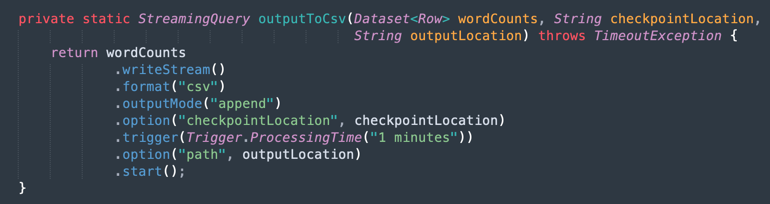
Tâche 9 : packager votre application avec Maven
Avant d'exécuter le travail dans Spark, il est nécessaire de packager votre application avec Maven.
-
Accédez au dossier /DataflowSparkStreamDemo et exécutez la commande suivante :
mvn package -
Vous pouvez voir Maven démarrer le package.

-
Si tout est correct, le message Success s'affiche.

Tâche 10 : vérifier l'exécution
-
Testez votre application sur votre machine Spark locale en exécutant la commande suivante :
spark-submit --class example.Example target/consumekafka-1.0-SNAPSHOT.jar -
Accédez à votre instance Kafka Oracle Cloud Streaming et cliquez sur Produire un message de test pour générer des données afin de tester votre application en temps réel.
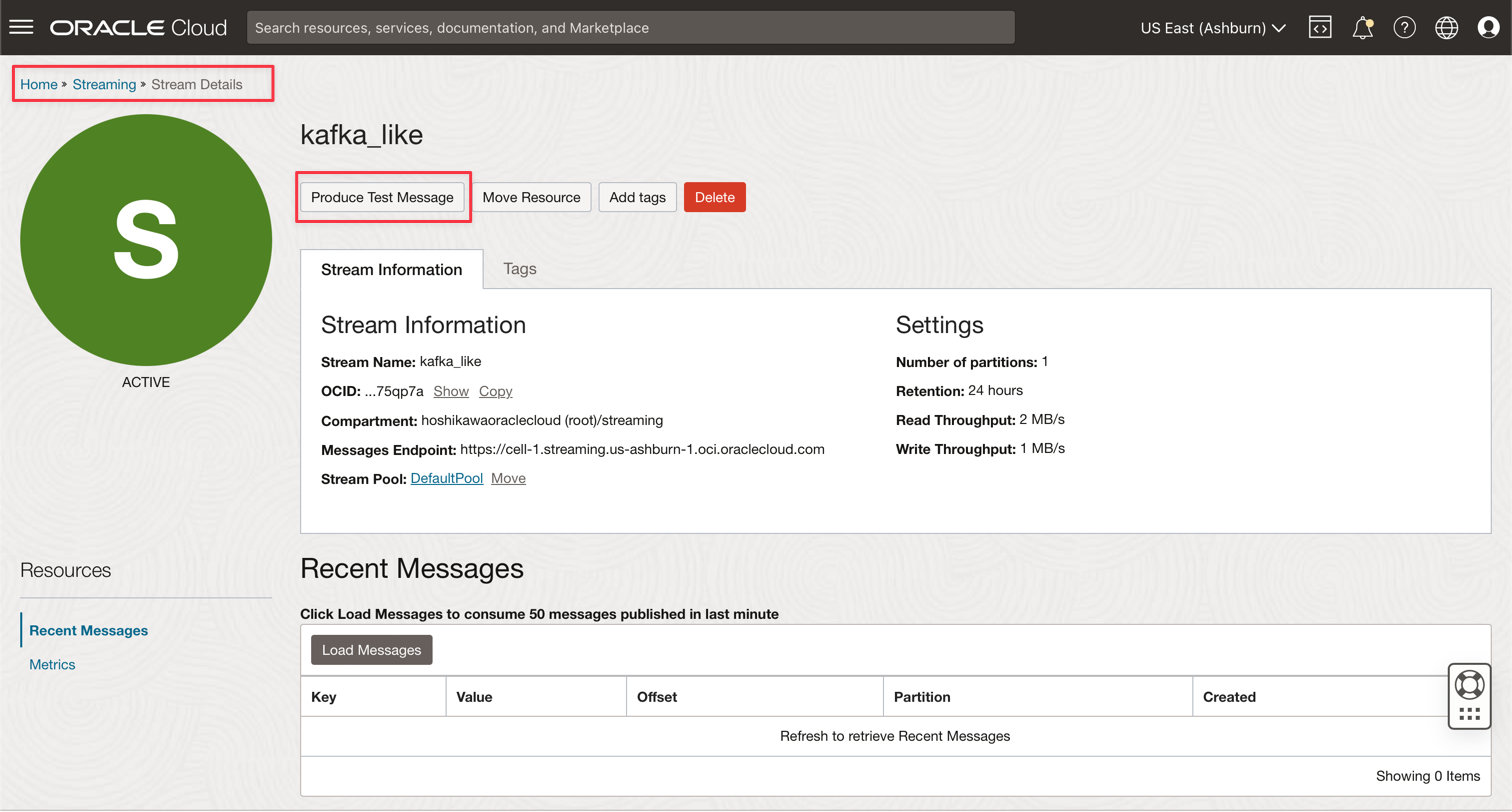
-
Vous pouvez placer ce message JSON dans la rubrique Kafka.
{"Organization Id": "1235", "Name": "Teste", "Country": "Luxembourg"}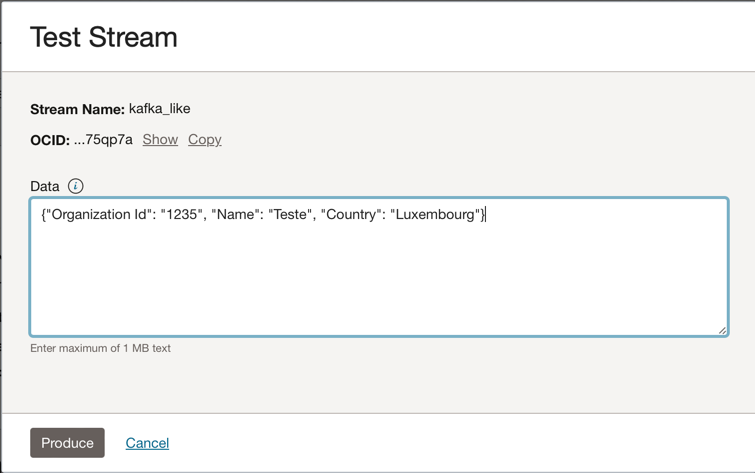
-
Chaque fois que vous cliquez sur Produire, vous envoyez un message à l'application. Le journal de sortie de l'application se présente comme suit :
-
Données lues dans la rubrique kafka.

-
Il s'agit des données fusionnées à partir de la table ADW.

-
Tâche 11 : création et exécution d'un travail Data Flow
Désormais, avec les deux applications exécutées avec succès sur votre machine Spark locale, vous pouvez les déployer dans Oracle Cloud Data Flow de votre location.
Remarque : reportez-vous à la documentation Spark Streaming pour configurer l'accès à des ressources telles qu'Oracle Object Storage et Oracle Streaming (Kafka) : Activer l'accès au flux de données.
-
Téléchargez les packages vers Object Storage.
- Avant de créer une application Data Flow, vous devez télécharger l'application d'artefact Java (votre fichier ***-SNAPSHOT.jar) vers le bucket Object Storage nommé apps.
-
Créez une application Data Flow.
-
Sélectionnez le menu principal Oracle Cloud et accédez à Analytics et IA et à Data Flow. Veillez à sélectionner le compartiment analytics avant de créer une application Data Flow.
-
Cliquez sur Créer une application.

-
Renseignez les paramètres comme celui-ci.

-
Cliquez sur Créer.
-
Après la création, cliquez sur le lien Redimensionner la démo pour afficher les détails. Pour exécuter un travail, cliquez sur RUN.
Remarque : cliquez sur Afficher les options avancées pour activer la sécurité OCI pour le type d'exécution Flux Spark.

-
-
Activez les options suivantes.

-
Cliquez sur Exécuter pour exécuter le travail.
-
Confirmez les paramètres et cliquez à nouveau sur Exécuter.

-
Vous pouvez visualiser le statut du travail.

-
Attendez que le statut passe à Succès et que vous puissiez voir les résultats.

-
Liens connexes
Remerciements
- Auteur - Cristiano Hoshikawa (ingénieur solutions Oracle LAD A-Team)
Ressources de formation supplémentaires
Explorez d'autres ateliers sur docs.oracle.com/learn ou accédez à davantage de contenu de formation gratuit sur le canal Oracle Learning YouTube. En outre, accédez à education.oracle.com/learning-explorer pour devenir un explorateur Oracle Learning.
Pour consulter la documentation produit, consultez Oracle Help Center.
Use OCI Data Flow with Apache Spark Streaming to process a Kafka topic in a scalable and near real-time application
F79979-02
May 2023
Copyright © 2023, Oracle and/or its affiliates.