Remarques :
- Ce tutoriel nécessite l'accès à Oracle Cloud. Pour vous inscrire à un compte gratuit, reportez-vous à Introduction à Oracle Cloud Infrastructure Free Tier.
- Il utilise des exemples de valeur pour les informations d'identification, la location et les compartiments Oracle Cloud Infrastructure. Lorsque vous terminez votre atelier, remplacez ces valeurs par celles propres à votre environnement cloud.
Analysez des documents PDF en langage naturel avec OCI Generative AI
Introduction
Oracle Cloud Infrastructure Generative AI (OCI Generative AI) est une solution d'intelligence artificielle générative avancée qui permet aux entreprises et aux développeurs de créer des applications intelligentes à l'aide de modèles de langage de pointe. Basée sur des technologies puissantes telles que les grands modèles de langage (LLM), cette solution permet l'automatisation de tâches complexes, rendant les processus plus rapides, plus efficaces et accessibles grâce aux interactions en langage naturel.
L'une des applications les plus percutantes d'OCI Generative AI est l'analyse de documents PDF. Les entreprises traitent fréquemment d'importants volumes de documents, tels que les contrats, les rapports financiers, les manuels techniques et les documents de recherche. La recherche manuelle d'informations dans ces fichiers peut prendre du temps et être sujette à des erreurs.
Avec l'utilisation de l'intelligence artificielle générative, il est possible d'extraire des informations instantanément et précisément, permettant aux utilisateurs d'interroger des documents complexes simplement en formulant des questions en langage naturel. Cela signifie qu'au lieu de lire des pages entières pour trouver une clause spécifique dans un contrat ou un point de données pertinent dans un rapport, les utilisateurs peuvent simplement demander au modèle, qui renvoie rapidement la réponse en fonction du contenu analysé.
Au-delà de la récupération d'informations, OCI Generative AI peut également être utilisé pour résumer de longs documents, comparer du contenu, classer des informations et même générer des informations stratégiques. Ces capacités rendent la technologie essentielle pour divers domaines, tels que le droit, la finance, les soins de santé et l'ingénierie, optimisant la prise de décision et augmentant la productivité.
En intégrant cette technologie à des outils tels que les services Oracle AI, OCI Data Science et les API de traitement des documents, les entreprises peuvent créer des solutions intelligentes qui transforment complètement leur façon d'interagir avec leurs données, ce qui rend la récupération des informations plus rapide et plus efficace.
Prérequis
- Installez Python
version 3.10ou une version ultérieure et l'interface de ligne de commande Oracle Cloud Infrastructure (interface de ligne de commande OCI).
Tâche 1 : installer des packages Python
Le code Python nécessite certaines bibliothèques pour l'utilisation d'OCI Generative AI. Exécutez la commande suivante pour installer les packages Python requis.
pip install -r requirements.txt
Tâche 2 : comprendre le code Python
Il s'agit d'une démonstration d'OCI Generative AI pour interroger les fonctionnalités d'Oracle SOA Suite et d'Oracle Integration. Les deux outils sont actuellement utilisés pour les stratégies d'intégration hybride, ce qui signifie qu'ils fonctionnent dans des environnements cloud et on-premise.
Puisque ces outils partagent des fonctionnalités et des processus, ce code aide à comprendre comment implémenter la même approche d'intégration dans chaque outil. En outre, il permet aux utilisateurs d'explorer les caractéristiques et les différences communes.
Téléchargez le code Python à partir d'ici :
Vous pouvez trouver les documents PDF ici :
Créez un dossier nommé Manuals et déplacez-y ces fichiers PDF.
-
Importer des bibliothèques:
Importe les bibliothèques nécessaires pour le traitement des fichiers PDF, OCI Generative AI, la vectorisation du texte et le stockage dans les bases de données vectorielles (recherche de similarité Facebook AI (FAISS) et ChromaDB).
-
UnstructuredPDFLoaderpermet d'extraire du texte à partir de PDF. -
ChatOCIGenAIpermet d'utiliser les modèles OCI Generative AI pour répondre aux questions. -
OCIGenAIEmbeddingscrée des incorporations (représentations vectorielles) de texte pour la recherche sémantique.
-
-
Charger et traiter les fichiers PDF :
Répertorie les fichiers PDF à traiter.
-
UnstructuredPDFLoaderlit chaque document et le divise en pages pour faciliter l'indexation et la recherche. -
Les codes document sont stockés pour référence ultérieure.

-
-
Configurez le modèle OCI Generative AI :
Configure le modèle
Llama-3.1-405bhébergé sur OCI pour générer des réponses en fonction des documents chargés.Définit des paramètres tels que
temperature(contrôle du caractère aléatoire),top_p(contrôle de la diversité) etmax_tokens(limite de jeton).
Remarque : la version disponible de LLaMA peut changer au fil du temps. Vérifiez la version actuelle dans votre location et mettez à jour votre code si nécessaire.
-
Créer des incorporations et un index vectoriel :
Utilise le modèle d'intégration d'Oracle pour transformer le texte en vecteurs numériques, ce qui facilite les recherches sémantiques dans les documents.

-
FAISS stocke les incorporations des documents PDF pour des requêtes rapides.
-
retrieverpermet de récupérer les extraits les plus pertinents en fonction de la similarité sémantique de la requête de l'utilisateur.

-
-
Lors de la première exécution du traitement, les données vectorielles seront enregistrées sur une base de données FAISS.

-
Définissez l'invite :
Crée une invite intelligente pour le modèle génératif, qui le guide pour ne prendre en compte que les documents pertinents pour chaque requête.
Cela améliore la précision des réponses et évite les informations inutiles.

-
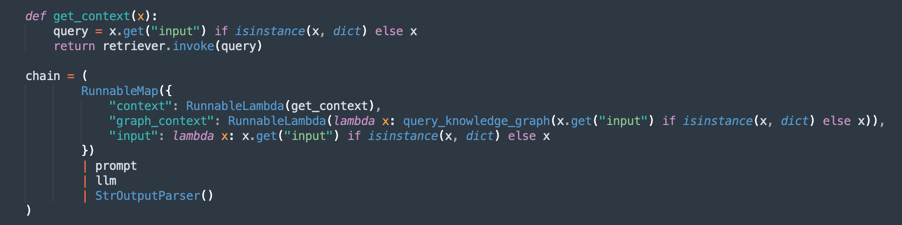
Créez la chaîne de traitement (RAG - Retrieval-Augmented Generation) :
Implémente un flux RAG, où :
retrieverrecherche les extraits de documents les plus pertinents.promptorganise la requête pour améliorer le contexte.llmgénère une réponse basée sur les documents extraits.StrOutputParserformate la sortie finale.

-
Boucle de question et de réponse :
Maintient une boucle dans laquelle les utilisateurs peuvent poser des questions sur les documents chargés.
-
L'IA répond en utilisant la base de connaissances extraite des PDF.
-
Si vous entrez
quit, il quitte le programme.

-
Maintenant, vous pouvez choisir 3 options pour traiter les documents. Vous pouvez penser :
- Combien de puissance avez-vous à traiter ?
- Combien de temps avez-vous à traiter ?
- Quelle est la qualité de vos réponses ?
Vous disposez donc des options suivantes :
Répartition par blocs de taille fixe : alternative plus rapide au traitement de vos documents. Cela peut être suffisant pour obtenir ce que vous voulez.
Groupement sémantique : ce processus sera plus lent que le segmentage de taille fixe, mais il fournira plus de segmentation de qualité.
Groupement sémantique avec GraphRAG : il fournit une méthode plus précise car il organise les textes de segmentation et les graphiques de connaissances.
Découpage de taille fixe
Téléchargez le code à partir d'ici : oci_genai_llm_context_fast.py.
-
Qu'est-ce que le découpage à taille fixe ?
Le découpage par blocs de taille fixe est une stratégie de découpage de texte simple et efficace dans laquelle les documents sont divisés en blocs en fonction de limites de taille prédéfinies, généralement mesurées en jetons, caractères ou lignes.
Cette méthode n'analyse pas la signification ou la structure du texte. Il découpe simplement le contenu à intervalles fixes, que la coupe se produise au milieu d'une phrase, d'un paragraphe ou d'une idée.
-
Fonctionnement du découpage par bloc de taille fixe :
-
Exemple de règle : fractionnez le document tous les 1000 jetons (ou tous les 3000 caractères).
-
Rupture facultative : pour réduire le risque de fractionnement d'un context pertinent, certaines implémentations ajoutent un chevauchement entre des blocs consécutifs (par exemple, chevauchement de 200 jetons) afin de garantir que le context important n'est pas perdu à la limite.
-
-
Avantages du découpage par bloc de taille fixe :
-
Traitement rapide : aucune analyse sémantique, inférence LLM ou compréhension du contenu n'est nécessaire. Comptez et coupez.
-
Utilisation faible des ressources : utilisation minimale de la CPU/GPU et de la mémoire, ce qui la rend évolutive pour les ensembles de données volumineux.
-
Facile à implémenter : fonctionne avec des scripts simples ou des bibliothèques de traitement de texte standard.
-
-
Limites du découpage par bloc de taille fixe :
-
Mauvaise conscience sémantique : les blocs peuvent couper des phrases, des paragraphes ou des sections logiques, ce qui entraîne des idées incomplètes ou fragmentées.
-
Précision d'extraction réduite : dans des applications telles que la recherche sémantique ou la génération augmentée par extraction (RAG), des limites de bloc médiocres peuvent affecter la pertinence et la qualité des réponses extraites.
-
-
Quand utiliser le découpage par bloc de taille fixe :
-
Lorsque la vitesse de traitement et l'évolutivité sont des priorités absolues.
-
Pour les pipelines d'ingestion de documents à grande échelle où la précision sémantique n'est pas critique.
-
Comme première étape dans les scénarios où un affinement ultérieur ou une analyse sémantique se produira en aval.
-
Il s'agit d'une méthode très simple pour fractionner le texte.

-
C'est le processus principal du découpage fixe.

Remarque : téléchargez ce code pour traiter le blocage fixe plus plus rapidement :
oci_genai_llm_context_fast.py -
Chunking sémantique
Téléchargez le code à partir d'ici : oci_genai_llm_context.py.
-
Qu'est-ce que le découpage sémantique ?
Le découpage sémantique est une technique de prétraitement de texte dans laquelle des documents volumineux (tels que des PDF, des présentations ou des articles) sont divisés en parties plus petites appelées parties, chaque partie représentant un bloc de texte sémantiquement cohérent.
Contrairement au découpage traditionnel de taille fixe (par exemple, fractionnement tous les 1000 jetons ou tous les X caractères), le découpage sémantique utilise l'intelligence artificielle (généralement les grands modèles de langage - LLM) pour détecter les limites de contenu naturel, en respectant les sujets, les sections et le context.
Au lieu de couper du texte arbitrairement, Semantic Chunking tente de préserver la pleine signification de chaque section, en créant des pièces autonomes et contextuelles.
-
Pourquoi le découpage sémantique peut-il ralentir le traitement ?
Un processus de découpage traditionnel, basé sur une taille fixe, est rapide. Le système compte simplement les jetons ou les caractères et les coupe en conséquence. Avec le découpage sémantique, plusieurs étapes supplémentaires d'analyse sémantique sont nécessaires :
- Lecture et interprétation du texte complet (ou des blocs volumineux) avant le fractionnement : le LLM doit comprendre le contenu pour identifier les meilleures limites de bloc.
- Exécution d'invites ou de modèles de classification de sujet LLM : le système interroge souvent le LLM avec des questions telles que Est-ce la fin d'une idée ? ou Ce paragraphe commence-t-il une nouvelle section ?.
- Utilisation plus élevée de la mémoire et de l'UC/GPU : étant donné que le modèle traite des blocs de texte plus volumineux avant de prendre des décisions de découpage, la consommation des ressources est nettement plus élevée.
- Prise de décision séquentielle et incrémentielle : le découpage sémantique fonctionne souvent par étapes (par exemple, l'analyse de blocs de 10 000 jetons, puis l'affinage des limites de bloc à l'intérieur de ce bloc), ce qui augmente le temps de traitement total.
Remarque :
- En fonction de la puissance de traitement de votre machine, vous attendez longtemps avant de finaliser la première exécution à l'aide du découpage sémantique.
- Vous pouvez utiliser cet algorithme pour produire un découpage par bloc personnalisé à l'aide d'OCI Generative AI.
-
Comment fonctionne le découpage sémantique :
-
smart_split_text(): sépare le texte intégral en petits morceaux de 10 ko (vous pouvez configurer pour adopter d'autres stratégies). Le mécanisme perçoit le dernier paragraphe. Si une partie du paragraphe se trouve dans l'élément de texte suivant, cette partie sera ignorée dans le traitement et sera ajoutée au groupe de texte de traitement suivant. -
semantic_chunk(): cette méthode utilise le mécanisme OCI LLM pour séparer les paragraphes. Il comprend l'intelligence pour identifier les titres, les composants d'un tableau, les paragraphes pour exécuter un bloc intelligent. La stratégie consiste ici à utiliser la technique du bloc sémantique. Il aura fallu plus de temps pour terminer la mission par rapport au traitement commun. Ainsi, le premier traitement prendra beaucoup de temps, mais le suivant chargera toutes les données pré-enregistrées FAISS. -
split_llm_output_into_chapters(): cette méthode finalise le bloc, en séparant les chapitres.
Remarque : téléchargez ce code pour traiter le sectionnement sémantique :
oci_genai_llm_context.py -
Chunking sémantique avec GraphRAG
Téléchargez le code à partir d'ici : oci_genai_llm_graphrag.py.
GraphRAG (Graph-Augmented Retrieval-Augmented Generation) est une architecture d'IA avancée qui combine l'extraction vectorielle traditionnelle avec des graphiques de connaissances structurées. Dans un pipeline RAG standard, un modèle de langage extrait les morceaux de document pertinents à l'aide de la similarité sémantique à partir d'une base de données vectorielle (comme FAISS). Cependant, l'extraction vectorielle fonctionne de manière non structurée, en s'appuyant uniquement sur des incorporations et des mesures de distance, qui manquent parfois des significations contextuelles ou relationnelles plus profondes.
GraphRAG améliore ce processus en introduisant une couche de graphe de connaissances, dans laquelle les entités, les concepts, les composants et leurs relations sont explicitement représentés sous forme de noeuds et d'arêtes. Ce context basé sur des graphiques permet au modèle de langage de raisonner sur les relations, les hiérarchies et les dépendances que la similarité vectorielle ne peut pas capturer à elle seule.
-
Pourquoi combiner le découpage sémantique avec GraphRAG ?
Le découpage sémantique est le processus consistant à diviser intelligemment de grands documents en unités significatives ou "morceaux", en fonction de la structure du contenu, tels que des chapitres, des en-têtes, des sections ou des divisions logiques. Plutôt que de casser des documents uniquement par des limites de caractères ou un fractionnement de paragraphe naïf, le découpage sémantique produit des morceaux de meilleure qualité, sensibles au context, qui s'alignent mieux avec la compréhension humaine.
-
Chunking sémantique avec GraphRAG Avantages :
-
Représentation améliorée des connaissances :
- Les blocs sémantiques conservent des limites logiques dans le contenu.
- Les graphiques de connaissances extraits de ces blocs maintiennent des relations précises entre les entités, les systèmes, les API, les processus ou les services.
-
Extraction contextuelle multimodale (le modèle de langage extrait les deux) :
- context non structuré à partir de la base de données vectorielle (similarité sémantique).
- Structure du context à partir du graphique de connaissances (triples entité-relation).
- Cette approche hybride conduit à des réponses plus complètes et plus précises.
-
Fonctionnalités de raisonnement améliorées :
- L'extraction basée sur des graphiques permet le raisonnement relationnel.
- Le LLM peut répondre à des questions telles que :
- De quels services dépend l'API Order ?
- Quels composants font partie de SOA Suite ?
- Ces requêtes relationnelles sont souvent impossibles avec les approches d'intégration uniquement.
-
Explicabilité et traçabilité supérieures :
- Les relations graphiques sont lisibles par l'utilisateur et transparentes.
- Les utilisateurs peuvent examiner comment les réponses sont dérivées des connaissances textuelles et structurelles.
-
Hallucination réduite : le graphique agit comme une contrainte sur le LLM, ancrant les réponses aux relations vérifiées et aux connexions factuelles extraites des documents source.
-
Evolutivité dans les domaines complexes :
- Dans les domaines techniques (par exemple, API, microservices, contrats juridiques, normes de santé), les relations entre les composants sont aussi importantes que les composants eux-mêmes.
- GraphRAG combiné avec des échelles de découpage sémantique efficacement dans ces contextes, préservant à la fois la profondeur textuelle et la structure relationnelle.
Remarque :
- Téléchargez le code pour traiter le blocage sémantique avec graphRAG à partir d'ici :
oci_genai_llm_graphrag.py. - Vous aurez besoin de :
- docker installé et actif pour utiliser la base de données de système d'exploitation de graphique open source Neo4J à tester.
- Installez la bibliothèque Python neo4j.
Ce code comporte 2 méthodes :
-
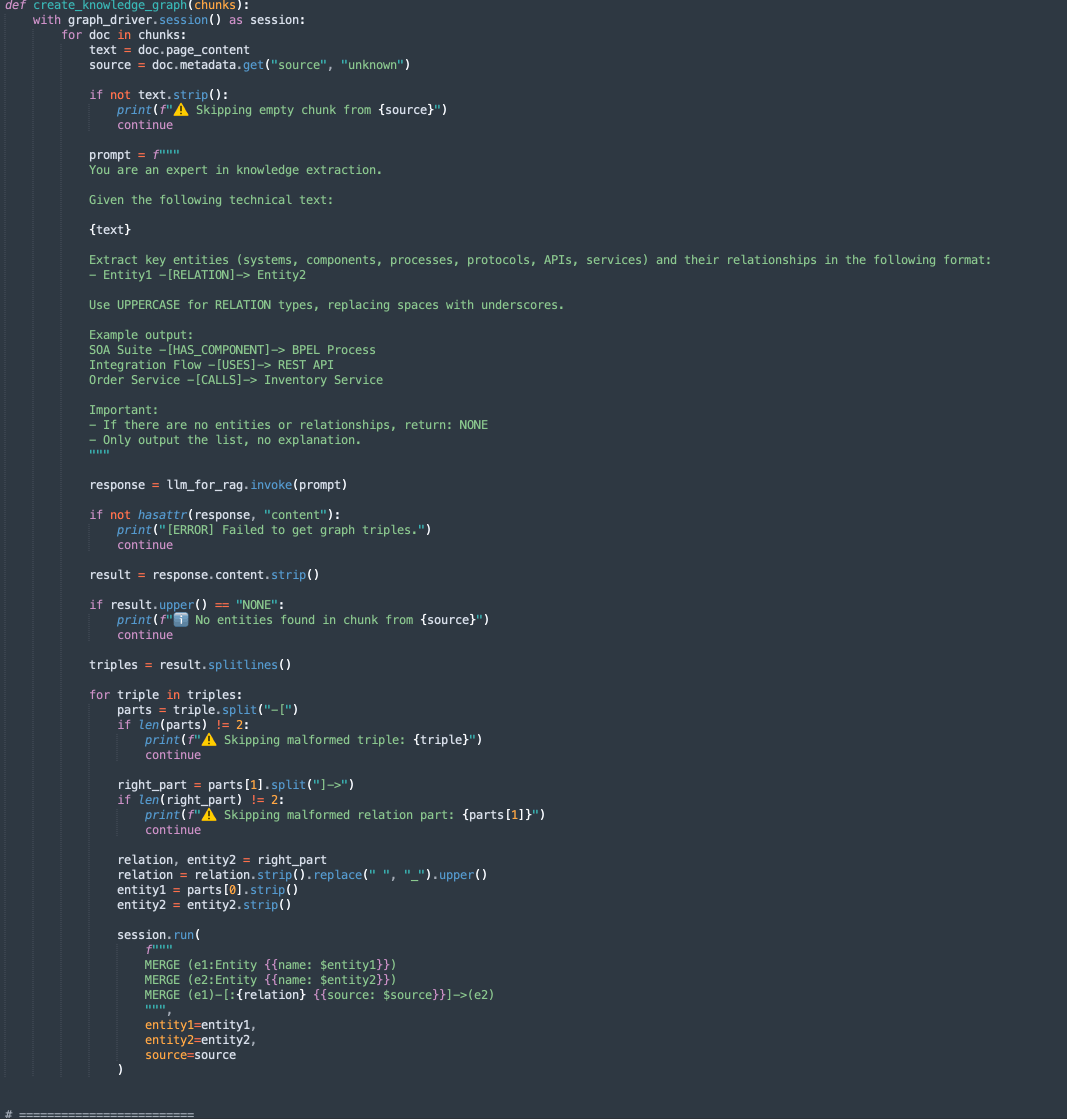
create_knowledge_graph:-
Cette méthode extrait automatiquement les entités et les relations des blocs de texte et les stocke dans un graphique de connaissances Neo4j.
-
Pour chaque bloc de document, il envoie le contenu à un LLM (Large Language Model) avec une invite demandant d'extraire les entités (telles que les systèmes, les composants, les services, les API) et leurs relations.
-
Il analyse chaque ligne, extrait Entity1, RELATION et Entity2.
-
Stocke ces informations en tant que noeuds et arêtes dans la base de données de graphes Neo4j à l'aide de requêtes Cypher :
MERGE (e1:Entity {name: $entity1}) MERGE (e2:Entity {name: $entity2}) MERGE (e1)-[:RELATION {source: $source}]->(e2)
-
-
-
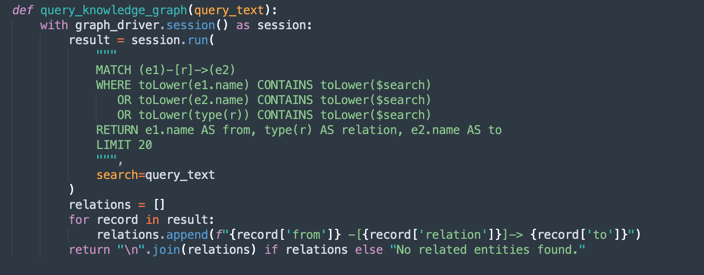
query_knowledge_graph:-
Cette méthode interroge le graphique de connaissances Neo4j pour extraire les relations associées à un mot-clé ou à un concept spécifique.
-
Exécute une requête Cypher qui recherche :
Any relationship (e1)-[r]->(e2) Where e1.name, e2.name, or the relationship type contains the query_text (case-insensitive). -
Renvoie jusqu'à 20 triples correspondants formatés comme suit :
Entity1 -[RELATION]-> Entity2
-
Remarque :
Neo4j Utilisation :
Cette implémentation utilise Neo4j en tant que base de données de graphe de connaissances intégrée à des fins de démonstration et de prototypage. Bien que Neo4j soit une base de données orientée graphe puissante et flexible adaptée au développement, aux tests et aux charges de travail de petite à moyenne taille, elle peut ne pas répondre aux exigences des charges de travail d'entreprise, critiques ou hautement sécurisées, en particulier dans les environnements qui exigent une haute disponibilité, une évolutivité et une conformité de sécurité avancée.
Pour les environnements de production et les scénarios d'entreprise, nous vous recommandons d'utiliser Oracle Database avec des fonctionnalités de graphique, qui offre :
Fiabilité et sécurité adaptées à l'entreprise.
Evolutivité pour les charges de travail stratégiques.
Modèles graphiques natifs (Graphique de propriétés et RDF) intégrés aux données relationnelles.
Fonctions avancées d'analyse, de sécurité, de haute disponibilité et de récupération après sinistre.
Intégration complète d'Oracle Cloud Infrastructure (OCI).
En utilisant Oracle Database pour les charges de travail basées sur des graphes, les entreprises peuvent unifier des données structurées, semi-structurées et graphiques au sein d'une plate-forme d'entreprise unique, sécurisée et évolutive.
Tâche 3 : exécuter une requête pour le contenu d'Oracle Integration et d'Oracle SOA Suite
Exécutez la commande suivante .
FOR FIXED CHUNKING TECHNIQUE (MORE FASTER METHOD)
python oci_genai_llm_context_fast.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
FOR SEMANTIC CHUNKING TECHNIQUE
python oci_genai_llm_context.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
FOR SEMANTIC CHUNKING COMBINED WITH GRAPHRAG TECHNIQUE
python oci_genai_llm_graphrag.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
Remarque : les paramètres
--deviceet--gpu_namepeuvent être utilisés pour accélérer le traitement en Python, à l'aide du GPU si votre machine en a un. Considérez que ce code peut également être utilisé avec des modèles locaux.
Le contexte fourni distingue Oracle SOA Suite et Oracle Integration. Vous pouvez tester le code en tenant compte des points suivants :
- L'interrogation doit être effectuée uniquement pour Oracle SOA Suite. Par conséquent, seuls les documents Oracle SOA Suite doivent être pris en compte.
- La requête doit être effectuée uniquement pour Oracle Integration. Par conséquent, seuls les documents Oracle Integration doivent être pris en compte.
- La requête nécessite une comparaison entre Oracle SOA Suite et Oracle Integration. Par conséquent, tous les documents doivent être pris en compte.
Nous pouvons définir le contexte suivant, ce qui aide grandement à interpréter correctement les documents.
L'exemple suivant illustre la comparaison entre Oracle SOA Suite et Oracle Integration.

Etapes suivantes
Ce code présente une application d'OCI Generative AI pour l'analyse PDF intelligente. Il permet aux utilisateurs d'interroger efficacement de grands volumes de documents à l'aide de recherches sémantiques et d'un modèle d'IA générative pour générer des réponses précises en langage naturel.
Cette approche peut être appliquée dans divers domaines, tels que le droit, la conformité, le support technique et la recherche universitaire, ce qui rend la recherche d'informations beaucoup plus rapide et plus intelligente.
Liens connexes
-
Combler le cloud et l'IA conversationnelle : LangChain et plateforme OCI Data Science
-
Introduction aux agents LangChain Python personnalisés et intégrés
-
Oracle Database Insider - Graph RAG : intégrer la puissance des graphes à l'IA générative
Accusés de réception
- Auteur - Cristiano Hoshikawa (ingénieur solutions d'équipe A Oracle LAD)
Ressources de formation supplémentaires
Explorez d'autres ateliers sur le site docs.oracle.com/learn ou accédez à d'autres contenus d'apprentissage gratuits sur le canal Oracle Learning YouTube. En outre, visitez le site education.oracle.com/learning-explorer pour devenir un explorateur Oracle Learning.
Pour obtenir de la documentation sur le produit, consultez Oracle Help Center.
Analyze PDF Documents in Natural Language with OCI Generative AI
G29539-05
Copyright ©2025, Oracle and/or its affiliates.