Remarque :
- Ce tutoriel nécessite l'accès à Oracle Cloud. Pour vous inscrire pour obtenir un compte gratuit, reportez-vous à Introduction à Oracle Cloud Infrastructure Free Tier.
- Il utilise des exemples de valeur pour les informations d'identification, la location et les compartiments Oracle Cloud Infrastructure. A la fin de l'exercice, remplacez ces valeurs par celles propres à votre environnement cloud.
Rationalisez les analyses à l'aide d'Oracle Cloud Infrastructure Streaming et d'Oracle Database
Introduction
Oracle Cloud Infrastructure Streaming est un service de diffusion en continu hautement évolutif et hautement disponible sur Oracle Cloud Infrastructure (OCI). Le service Stream est entièrement sans serveur et compatible avec l'API Apache Kafka.
L'accès Oracle SQL à Kafka est un package Oracle PL/SQL et un préprocesseur de table externe. Elle permet à Oracle Database de lire et de traiter les événements et les messages des rubriques Kafka sous forme de vues ou de tables dans Oracle Database. Une fois que les données de Kafka se trouvent dans une table Oracle Database ou sont visibles dans une vue Oracle Database, elles peuvent être interrogées avec la puissance complète d'Oracle PL/SQL, comme toutes les autres données d'Oracle Database.
Lorsque vous extrayez des données avec un accès Oracle SQL aux vues Kafka activées, les données ne sont pas conservées dans Oracle Database. Toutefois, lorsque vous utilisez l'accès Oracle SQL aux tables optimisées Kafka, il est conservé dans Oracle Database. L'accès Oracle SQL à Kafka offre donc aux développeurs une flexibilité totale quant à la persistance des données de diffusion en continu sur Oracle Database. Pour obtenir une présentation détaillée et un cas d'emploi pratique de l'accès Oracle SQL à Kafka, reportez-vous à ce billet de blog intitulé Intégration de données in-Motion à des données inactives à l'aide de l'accès Oracle SQL aux vues Kafka.
En bref, l'accès Oracle SQL à Kafka permet de traiter les données en mouvement avec des données inactives (dans les tables Oracle Database) à l'aide d'Oracle PL/SQL. Ainsi, les applications, par exemple JDBC (Java Database Connectivity) peuvent traiter des événements en temps réel à partir de Kafka et des données critiques d'Oracle Database, dans le cadre de transactions Oracle Database offrant des garanties ACID. Cela est difficile lorsqu'une application extrait séparément des événements Kafka et des données d'Oracle Database.

Avantages
- Les clients peuvent utiliser l'accès Oracle SQL à Kafka pour exécuter des travaux d'analyse de flux en temps réel à l'aide d'Oracle PL/SQL en lisant directement les données à partir du service Stream, sans jamais les déplacer vers une banque de données externe.
- Les clients peuvent également utiliser l'accès Oracle SQL à Kafka uniquement pour le déplacement de données du service Stream vers Oracle Database sans aucun traitement.
- L'opération de traitement de flux peut être effectuée dans le cadre d'une transaction Oracle ACID contrôlée par l'application.
- L'accès Oracle SQL à Kafka fonctionne uniquement comme un consommateur Kafka et jamais comme un producteur Kafka. La gestion complète de la contrepartie est gérée par OSaK. Il stocke ces informations dans des tables de métadonnées dans Oracle Database. Par conséquent, l'accès Oracle SQL à Kafka permet la sémantique de traitement exactement une fois, car il peut valider le décalage de partition pour Kafka et le service de flux et les données d'application, dans une transaction Oracle Database compatible ACID unique vers Oracle Database. Cela évite de perdre ou de relire des enregistrements de transmission en continu.
Cas d'emploi
Imaginez tout cas d'emploi dans lequel vous voulez associer ou joindre vos données de diffusion en continu à vos données relationnelles, par exemple :
- Vous voulez combiner les données de transmission en continu de vos appareils IoT de discussion (probablement présents sur site client) avec les informations client pertinentes, stockées dans votre base de données Oracle Database relationnelle d'informations source.
- Vous voulez calculer des moyennes mobiles exponentielles précises pour les prix des stocks qui sont transmis au service Stream. Vous devez effectuer cette opération avec une sémantique exactement une fois. Vous voulez combiner ces données avec des informations statiques à propos de ce stock, telles que son nom, son ID d'entreprise, sa capitalisation boursière, etc., stockées dans votre instance Oracle Database.
Notez que l'accès Oracle SQL à Kafka étant un package PL/SQL qui doit être installé manuellement sur l'hôte du serveur Oracle, il ne peut fonctionner qu'avec des installations Oracle Database autonomes (sur site ou sur le cloud). Il ne peut pas fonctionner avec des offres Oracle Database sans serveur comme Oracle Autonomous Database sur Oracle Cloud Infrastructure (OCI).
Le service Stream étant compatible avec Kafka, il fonctionne parfaitement avec l'accès Oracle SQL à Kafka. A partir de l'accès Oracle SQL au point de vue Kafka, un pool de flux de données de service Stream est un cluster Kafka et un flux de service Stream est un sujet du cluster Kafka.
Ce tutoriel montre combien nous pouvons facilement intégrer l'accès Oracle SQL à Kafka avec le service Stream.
Remarque : si vous connaissez déjà l'accès Oracle SQL à Kafka, au service Stream et à Kafka, et que vous voulez utiliser l'accès Oracle SQL à Kafka avec le service Stream, vous pouvez passer directement à l'étape 2.1 de la configuration des clusters Oracle Cloud Infrastructure Streaming pour l'accès Oracle SQL à Kafka. Passez en revue le reste du tutoriel si nécessaire.
Prérequis
- Location ou compte OCI avec autorisation de créer et d'utiliser le service Stream.
- Cluster Apache Kafka 0.10.2 ou version ultérieure. Le service Stream répond à ce besoin.
- Oracle Database 12.2 ou version ultérieure où l'accès Oracle SQL à Kafka sera installé (la version 19c est utilisée dans ce tutoriel). Nous utilisons Oracle Linux en tant que système d'exploitation de plate-forme pour Oracle Database. Les instructions générales restent les mêmes pour les autres plates-formes.
- Java 8 ou version ultérieure installé sur l'hôte Oracle Database.
Accès à Oracle Cloud Infrastructure Streaming et Oracle SQL pour l'intégration Kafka
Créer un pool de flux de données et un flux de données dans Oracle Cloud Infrastructure
-
Connectez-vous à votre location/compte OCI et configurez un pool de flux de données de service Stream nommé StreampoolForOsak et le flux nommé StreamForOsak comme suit.

-
Nous créons maintenant un flux nommé StreamForOsak dans le streampool StreampoolForOsak que nous venons de créer.

Pour ces créations de ressource, vous pouvez utiliser n'importe lequel de vos compartiments existants. Pour plus de commodité, nous avons créé un compartiment nommé OssOsakIntegration et toutes les ressources se trouvent dans le même compartiment.
Dans la terminologie du service Stream, les rubriques Kafka sont appelées Streams. Par conséquent, à partir de l'accès Oracle SQL au point de vue Kafka, le flux de données StreamForOsak est une rubrique Kafka comportant trois partitions.
Nous avons maintenant terminé la création du flux de service Stream. Par la suite, les termes " Stream Service " et " Kafka " sont interchangeables. De même, les termes Stream et Kafka Topic sont interchangeables.
Création d'un utilisateur, d'un groupe et de stratégies dans Oracle Cloud Infrastructure
Si vous disposez déjà d'un utilisateur disposant des autorisations appropriées pour utiliser le service Stream, l'étape 2 peut être entièrement ignorée.
-
Pour utiliser les flux de service de flux avec un accès Oracle SQL à Kafka, nous devons créer un utilisateur OCI pour ce flux. Pour cela, nous créons un utilisateur avec le nom utilisateur OssOsakUser, à partir de la console Web OCI, comme suit :

-
Pour que l'utilisateur OssOsakUser s'authentifie auprès du service Stream (à l'aide des API Kafka), nous devons créer un jeton d'authentification pour ce nouvel utilisateur, comme suit :

Après avoir généré le jeton, vous obtenez en premier et la seule chance d'afficher et de copier le jeton d'authentification. Copiez donc le jeton d'authentification et conservez-le en toute sécurité à un endroit où vous pourrez y accéder ultérieurement. Vous en avez besoin ultérieurement, en particulier lorsque nous configurons le cluster Kafka pour l'accès Oracle SQL à Kafka. L'accès Oracle SQL à Kafka utilisera ce nom utilisateur, à savoir OssOsakUser et son jeton d'authentification, pour accéder au service de flux, à l'aide des API consommateur Kafka en interne.
-
OssOsakUser doit également disposer du bon ensemble de privilèges dans OCI IAM pour accéder au cluster de services Stream.
Dans OCI, les utilisateurs obtiennent des privilèges à l'aide des stratégies affectées aux groupes d'utilisateurs dont ils font partie. Par conséquent, nous devons créer un groupe pour OssOsakUser, suivi d'une stratégie pour ce groupe.
Créez un groupe d'utilisateurs comme indiqué ci-dessous :

-
Ajoutez l'utilisateur OssOsakUser au groupe d'utilisateurs OssOsakUserGroup.

-
Pour autoriser OssOsakUser à utiliser le flux de service de flux, en particulier pour publier et lire des messages à partir de ce flux, nous devons créer la stratégie suivante dans la location. Cette stratégie, une fois créée, accorde des privilèges à tous les utilisateurs du groupe OssOsakUserGroup. L'utilisateur OssOsakUser se trouvant dans le même groupe, il acquiert les mêmes privilèges.

Le fragment de code texte de la même stratégie ci-dessus est le suivant.
Allow group OssOsakUserGroup to manage streams in compartment OssOsakIntegration Allow group OssOsakUserGroup to manage stream-push in compartment OssOsakIntegration Allow group OssOsakUserGroup to manage stream-pull in compartment OssOsakIntegration Allow group OssOsakUserGroup to manage stream-family in compartment OssOsakIntegration
Installer l'accès Oracle SQL à Kafka sur un hôte Oracle Database
-
Le kit Oracle SQL d'accès à Kafka est disponible dans le cadre d'une instance SQL Developer largement utilisée.
Utilisez le lien SQL Developer officiel pour télécharger la dernière version de SQL Developer. A compter de la rédaction de ce tutoriel, la dernière version de SQL Developer est la version 20.4.
Veillez à télécharger Oracle SQL Developer pour la même plate-forme que votre hôte Oracle Database. Dans notre environnement de développement, nous téléchargons Oracle SQL Developer pour Oracle Linux RPM (comme Oracle Database est exécuté sur la plate-forme Oracle Linux).
Une fois le téléchargement terminé, extrayez le contenu du fichier RPM/zip d'Oracle SQL Developer vers n'importe quel répertoire/dossier à l'aide de la commande
unzipoutar.tar xvf sqldeveloper-20.4.0.379.2205-20.4.0-379.2205.noarch.rpm -
Accédez au répertoire dans lequel le contenu d'Oracle SQL Developer a été extrait et recherchez l'accès Oracle SQL au fichier ZIP Kafka nommé
orakafka.zipcomme suit :$ find . -name 'orakafta*' ./sqldeveloper/orakafta ./sqldeveloper/orakafta/orakafta.zipL'accès Oracle SQL au kit Kafka se trouve dans le fichier
orakafka.zip. Nous ne sommes pas intéressés par le reste du contenu du développeur SQL pour cette démonstration. En ce qui concerne l'installation et l'utilisation de l'accès Oracle SQL à Kafka,orakafka.zipest tout ce dont nous avons besoin. -
Copiez le fichier
orakafka.zipsur l'hôte Oracle Database à l'aide de la commandescpou de clients FTP basés sur l'interface graphique, comme FileZilla.Connectez-vous via SSH au noeud Oracle Database et déplacez
orakafka.zipvers/home/oracle(répertoire de base de l'utilisateur oracle) avecmv_ command. -
Pour les autres instructions d'installation d'un accès Oracle SQL à Kafka, nous devons passer à l'utilisateur oracle sur l'hôte Oracle Database.
Assurez-vous que votre répertoire de travail actuel est
/home/oracle.orakafka.zipexiste déjà dans le même répertoire.[opc@dbass ~]$ sudo su - oracle Last login: Sat Feb 20 09:31:12 UTC 2021 [oracle@dbass ~]$ pwd /home/oracle [oracle@dbass ~]$ ls -al total 3968 drwx------ 6 oracle oinstall 4096 Feb 19 17:39 . drwxr-xr-x 5 root root 4096 Feb 18 15:15 .. -rw------- 1 oracle oinstall 4397 Feb 20 09:31 .bash_history -rw-r--r-- 1 oracle oinstall 18 Nov 22 2019 .bash_logout -rw-r--r-- 1 oracle oinstall 203 Feb 18 15:15 .bash_profile -rw-r--r-- 1 oracle oinstall 545 Feb 18 15:20 .bashrc -rw-r--r-- 1 oracle oinstall 172 Apr 1 2020 .kshrc drwxr----- 3 oracle oinstall 4096 Feb 19 17:37 .pki drwxr-xr-x 2 oracle oinstall 4096 Feb 18 15:20 .ssh -rw-r--r-- 1 oracle oinstall 4002875 Feb 19 17:38 orakafka.zip -
Extrayez ou décompressez
orakafka.zip. Cette opération crée un répertoire nomméorakafka-<version>avec le contenu extrait. Dans notre cas, il s'agit deorakafka-1.2.0comme suit :[oracle@dbass ~]$ unzip orakafka.zip Archive: orakafka.zip creating: orakafka-1.2.0/
extraction : orakafka-1.2.0/kit_version.txt
gonflement : orakafka-1.2.0/orakafka_distro_install.sh
extraction : orakafka-1.2.0/orakafka.zip
gonflement : orakafka-1.2.0/README
6. Now we follow the instructions found in the _**orakafka-1.2.0/README**_ for the setup of Oracle SQL access to Kafka. We follow _simple install_ for single-instance Oracle Database.
This README doc has instructions for Oracle SQL access to Kafka installation on Oracle Real Application Clusters (Oracle RAC) as well. By and large, in the case of Oracle RAC, we need to replicate the following steps on all nodes of Oracle RAC. Please follow the README for details.
[oracle@dbass ~]$ cd orakafka-1.2.0/
[oracle@dbass orakafka-1.2.0]$ ls -al
total 3944
drwxrwxr-x 2 oracle oinstall 4096 Feb 20 09:12 .
drwx—— 6 oracle oinstall 4096 Feb 19 17:39 ..
-rw-r–r– 1 oracle oinstall 6771 Oct 16 03:11 README
-rw-r–r– 1 oracle oinstall 5 Oct 16 03:11 kit_version.txt
-rw-rw-r– 1 oracle oinstall 3996158 Oct 16 03:11 orakafka.zip
-rwxr-xr-x 1 oracle oinstall 17599 Oct 16 03:11 orakafka_distro_install.sh
tar xvf sqldeveloper-20.4.0.379.2205-20.4.0-379.2205.noarch.rpm
7. As per _./orakafka-1.2.0/README_, we install Oracle SQL access to Kafka on the Oracle Database host with the help of _./orakafka-1.2.0/orakafka\_distro\_install.sh_ script. Argument -p lets us specify the location or base directory for the Oracle SQL access to Kafka installation on this host.
We choose the newly created empty directory named ora\_kafka\_home as the OSaK base directory on this host. So the full path of the OSaK base directory will be _/home/oracle/ora\_kafka\_home_.
[oracle@dbass ~]$ ./orakafka-1.2.0/orakafka_distro_install.sh -p ./ora_kafka_home/
Step Create Product Home::
————————————————————–
…../home/oracle/ora_kafka_home already exists..
Step Create Product Home: completed.
PRODUCT_HOME=/home/oracle/ora_kafka_home
Step Create app_data home::
————————————————————–
….. creating /home/oracle/ora_kafka_home/app_data and subdirectories
……Generated CONF_KIT_HOME_SCRIPT=/home/oracle/ora_kafka_home/app_data/scripts/configure_kit_home.sh
……Generated CONF_APP_DATA_HOME_SCRIPT=/home/oracle/ora_kafka_home/configure_app_data_home.sh
Step Create app_data home: completed.
APP_DATA_HOME=/home/oracle/ora_kafka_home/app_data
Step unzip_kit::
————————————————————–
…..checking for existing binaries in /home/oracle/ora_kafka_home/orakafka
…..unzip kit into /home/oracle/ora_kafka_home/orakafka
Archive: /home/oracle/orakafka-1.2.0/orakafka.zip
creating: /home/oracle/ora_kafka_home/orakafka/
extracting: /home/oracle/ora_kafka_home/orakafka/kit_version.txt
inflating: /home/oracle/ora_kafka_home/orakafka/README
creating: /home/oracle/ora_kafka_home/orakafka/doc/
inflating: /home/oracle/ora_kafka_home/orakafka/doc/README_INSTALL
creating: /home/oracle/ora_kafka_home/orakafka/jlib/
inflating: /home/oracle/ora_kafka_home/orakafka/jlib/osakafka.jar
inflating: /home/oracle/ora_kafka_home/orakafka/jlib/kafka-clients-2.5.0.jar
inflating: /home/oracle/ora_kafka_home/orakafka/jlib/slf4j-simple-1.7.28.jar
inflating: /home/oracle/ora_kafka_home/orakafka/jlib/lz4-java-no-jni-1.7.1.jar
inflating: /home/oracle/ora_kafka_home/orakafka/jlib/snappy-java-no-jni-1.1.7.3.jar
inflating: /home/oracle/ora_kafka_home/orakafka/jlib/zstd-no-jni-1.4.4-7.jar
inflating: /home/oracle/ora_kafka_home/orakafka/jlib/slf4j-api-1.7.30.jar
creating: /home/oracle/ora_kafka_home/orakafka/bin/
inflating: /home/oracle/ora_kafka_home/orakafka/bin/orakafka_stream.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/orakafka.sh
creating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/removeuser_cluster.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/setup_all.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/remove_cluster.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/verify_install.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/add_cluster.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/config_util.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/test_views.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/install.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/set_java_home.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/list_clusters.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/adduser_cluster.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/uninstall.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/test_cluster.sh
creating: /home/oracle/ora_kafka_home/orakafka/conf/
inflating: /home/oracle/ora_kafka_home/orakafka/conf/orakafka.properties.template
creating: /home/oracle/ora_kafka_home/orakafka/sql/
inflating: /home/oracle/ora_kafka_home/orakafka/sql/orakafkatab.plb
inflating: /home/oracle/ora_kafka_home/orakafka/sql/catnoorakafka.sql
inflating: /home/oracle/ora_kafka_home/orakafka/sql/catorakafka.sql
inflating: /home/oracle/ora_kafka_home/orakafka/sql/pvtorakafkaus.plb
inflating: /home/oracle/ora_kafka_home/orakafka/sql/orakafka_pkg_uninstall.sql
inflating: /home/oracle/ora_kafka_home/orakafka/sql/orakafkab.plb
inflating: /home/oracle/ora_kafka_home/orakafka/sql/pvtorakafkaub.plb
inflating: /home/oracle/ora_kafka_home/orakafka/sql/orakafka_pkg_install.sql
inflating: /home/oracle/ora_kafka_home/orakafka/sql/orakafkas.sql
creating: /home/oracle/ora_kafka_home/orakafka/lib/
inflating: /home/oracle/ora_kafka_home/orakafka/lib/libsnappyjava.so
inflating: /home/oracle/ora_kafka_home/orakafka/lib/libzstd-jni.so
inflating: /home/oracle/ora_kafka_home/orakafka/lib/liblz4-java.so
Step unzip_kit: completed.
Successfully installed orakafka kit in /home/oracle/ora_kafka_home
8. Configure JAVA\_HOME for Oracle SQL access to Kafka. We find the Java path on the node as follows:
[oracle@dbass ~]$ java -XshowSettings:properties -version 2>&1 > /dev/null | grep 'java.home'
java.home = /usr/java/jre1.8.0_271-amd64
[oracle@dbass ~]$ export JAVA_HOME=/usr/java/jre1.8.0_271-amd64
To set Java home for OSaK, we use the script _/home/oracle/ora\_kafka\_home/orakafka/bin/orakafka.sh_ script, with _set\_java\_home_ option.
[oracle@dbass bin]$ pwd
/home/oracle/ora_kafka_home/orakafka/bin
[oracle@dbass bin]$ ./orakafka.sh set_java_home -p $JAVA_HOME
Step1: Check for valid JAVA_HOME
————————————————————–
Found /usr/java/jre1.8.0_271-amd64/bin/java, JAVA_HOME path is valid.
Step1 succeeded.
Step2: JAVA version check
————————————————————–
java version “1.8.0_271”
Java(TM) SE Runtime Environment (build 1.8.0_271-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.271-b09, mixed mode)
Java version >= 1.8
Step2 succeeded.
Step3: Creating configure_java.sh script
————————————————————–
Wrote to /home/oracle/ora_kafka_home/app_data/scripts/configure_java.sh
Step3 succeeded.
Successfully configured JAVA_HOME in /home/oracle/ora_kafka_home/app_data/scripts/configure_java.sh
The above information is written to /home/oracle/ora_kafka_home/app_data/logs/set_java_home.log.2021.02.20-04.38.23
[oracle@dbass bin]$
9. Verify installation of OSaK with _verify\_install_ option of script _orakafka.sh_ as follows:
[oracle@dbass ~]$ cd ora_kafka_home/
[oracle@dbass ora_kafka_home]$ cd orakafka/bin/
[oracle@dbass bin]$ ./orakafka.sh verify_install
Vérifiez la propriété de tous les fichiers/dirs - transmis
Vérifiez les privilèges de répertoire - transmis
Vérifiez les fichiers exécutables attendus - transmis
Les informations ci-dessus sont écrites dans /home/oracle/ora_kafka_home/app_data/logs/verify_install.log.2021.02.19-18.10.15
### Set Up Oracle Cloud Infrastructure Stream Clusters for Oracle SQL Access to Kafka
1. Under _ora\_kafka\_home_, that is _/home/oracle/ora\_kafka\_home_, we have two more READMEs as follows:
[oracle@dbass ~]$ trouver ora_kafka_home/ -name "README*"
ora_kafka_home/orakafka/README
ora_kafka_home/orakafka/doc/README_INSTALL
_~/ora\_kafka\_home/orakafka/README_ is the readme for this release of OSaK that we have installed. Please read through this readme.
And _ora\_kafka\_home/orakafka/doc/README\_INSTALL_ is the README for the actual setup of a Kafka cluster for Oracle SQL access to Kafka. The rest of the steps 2 onwards below follow this README by and large. As per the same, we will leverage _~/ora\_kafka\_home/orakafka/bin/orakafka.s_h script, for adding a Kafka cluster, adding an Oracle Database user for using the Kafka cluster in the next steps.
2. Add our Stream service stream pool to Oracle SQL access to Kafka.
As mentioned earlier, from the Oracle SQL access to Kafka point of view, the Stream service stream pool is a Kafka cluster.
We use the _add\_cluster_ option of the _orakafka.sh_ script to add the cluster to OSaK. We use the _\-c_ argument to name the cluster as _kc1_.
[oracle@dbass bin]$ pwd
/home/oracle/ora_kafka_home/orakafka/bin
[oracle@dbass bin]$ ./orakafka.sh add_cluster -c kc1
Step1 : Création du répertoire de configuration du cluster de systèmes de fichiers
---------------------
Création du répertoire du cluster de systèmes de fichiers terminée.
Configurez les propriétés de sécurité à l'adresse /home/oracle/ora_kafka_home/app_data/clusters/KC1/conf/orakafka.properties.
Step1 a réussi.
Step2 : Générer DDL pour créer le répertoire de base de données de configuration de cluster
---------------------
Exécutez le script SQL suivant lorsque vous êtes connecté en tant que sysdba
pour créer le répertoire de base de données de configuration de cluster :
@/home/oracle/ora_kafka_home/app_data/scratch/orakafka_create_KC1_CONF_DIR.sql
Step2 a généré le script.
****SUMMARY*****
Tâches TODO :
- Configurez les propriétés de sécurité à l'adresse /home/oracle/ora_kafka_home/app_data/clusters/KC1/conf/orakafka.properties
- Exécutez le code SQL suivant lorsque vous êtes connecté en tant que sysdba :
@/home/oracle/ora_kafka_home/app_data/scratch/orakafka_create_KC1_CONF_DIR.sql
Les informations ci-dessus sont écrites dans /home/oracle/ora_kafka_home/app_data/logs/add_cluster.log.2021.02.20-05.23.30
[oracle@dbass bin]$
We get two TODO tasks as per output from the above execution of the _add\_cluster_ command.
1. For the first task, we add security properties for our Stream service stream to `/home/oracle/ora_kafka_home/app_data/clusters/KC1/conf/orakafka.properties`.
Where to get Kafka-compatible security configs for the Stream service cluster also known as (AKA) streampool? We get these security configs from the OCI web console as shown below.
Please take note of the bootstrap server endpoint(_cell-1.streaming.ap-mumbai-1.oci.oraclecloud.com:9092_ from the screenshot below) as well. It is not related to the security configs of the cluster, but we need it in later steps for connecting to our Stream service and Kafka cluster.

We write the above config values to OSaK in the following format, to `/home/oracle/ora_kafka_home/app_data/clusters/KC1/conf/orakafka.properties` file using any text editor like say vi.

For clarity, we have the same configs in text format as follows:
```
security.protocol=SASL_SSL
sasl.mechanism=PLAIN
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<YOUR_TENANCY_NAME>/<YOUR_OCI_USERID_HERE>/<YOUR_OCI_STREAMPOOL_OCID>" password=" YOUR_AUTH_TOKEN";
sasl.plain.username="<YOUR_TENANCY_NAME>/<YOUR_OCI_USERID_HERE>/<YOUR_OCI_STREAMPOOL_OCID>"
sasl.plain.password ="YOUR_AUTH_TOKEN";
```
**Note:** default Kafka Consumer Configs are already pre-populated in _orakafka.properties_ for this cluster. If there is a need, one can modify these configs.
2. For the second TODO task, do SQL script execution as follows:
```
[oracle@dbass ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Sat Feb 20 05:37:28 2021
Version 19.9.0.0.0
Copyright (c) 1982, 2020, Oracle. All rights reserved.
Connected to:
Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production
Version 19.9.0.0.0
SQL> alter session set container=p0;
Session altered.
SQL> @/home/oracle/ora_kafka_home/app_data/scratch/orakafka_create_KC1_CONF_DIR.sql
Creating database directory "KC1_CONF_DIR"..
Directory created.
The above information is written to /home/oracle/ora_kafka_home/app_data/logs/orakafka_create_KC1_CONF_DIR.log
Disconnected from Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production
Version 19.9.0.0.0
```
Take note of directory object _KC1\_CONF\_DIR_ created by the above SQL script.
**Note:** As dictated in add\_cluster output, we run the SQL script as a _SYSDBA_ user, inside the PDB of our interest (_p0_ PDB here).
3. To make sure that the cluster configuration is working, we can leverage the _test\_cluster_ option of script _orakafka.sh_.
We pass cluster name with -c argument and bootstrap server with -b argument. We have from bootstrap server info from step 4.2.1.
```
[oracle@dbass bin]$ pwd
/home/oracle/ora_kafka_home/orakafka/bin
[oracle@dbass bin]$ ./orakafka.sh test_cluster -c kc1 -b cell-1.streaming.ap-mumbai-1.oci.oraclecloud.com:9092
Kafka cluster configuration test succeeded.
Kafka cluster configuration test - "KC1"
------------------------------------------------------
KAFKA_BOOTSTRAP_SERVERS=cell-1.streaming.ap-mumbai-1.oci.oraclecloud.com:9092
LOCATION_FILE="/home/oracle/ora_kafka_home/app_data/clusters/KC1/logs/orakafka_stream_KC1.loc"
ora_kafka_operation=metadata
kafka_bootstrap_servers=cell-1.streaming.ap-mumbai-1.oci.oraclecloud.com:9092
List topics output:
StreamForOsak,3
...
For full log, please look at /home/oracle/ora_kafka_home/app_data/clusters/KC1/logs/test_KC1.log.2021.02.20-09.01.12
Test of Kafka cluster configuration for "KC1" completed.
The above information is written to /home/oracle/ora_kafka_home/app_data/logs/test_cluster.log.2021.02.20-09.01.12
[oracle@dbass bin]$
```
As you can see our Kafka cluster configuration test succeeded! We get the list of topics, AKA the Stream service streams in the output here. Topic names are followed by the number of partitions for that stream. Here we have the number of partitions as three, as the Stream service stream StreamForOsak has exactly three partitions.
3. Configure an Oracle Database user for the added Kafka cluster.
We already have created an Oracle Pluggable Databases (PDB) level Oracle Database user with username books\_admin, for the PDB named _p0_. We use the _adduser\_cluster_ option to grant required permissions for user books\_admin on Kafka cluster _kc1_.
[oracle@dbass bin]$ ./orakafka.sh adduser_cluster -c kc1 -u books_admin
Step1: Generate DDL to grant permissions on cluster configuration directory to "BOOKS_ADMIN"
--------------------------------------------------------------------------------------------
Execute the following script while connected as sysdba
to grant permissions on cluster conf directory :
@/home/oracle/ora_kafka_home/app_data/scratch/orakafka_adduser_cluster_KC1_user1.sql
Step1 successfully generated script.
***********SUMMARY************
TODO tasks:
1. Execute the following SQL while connected as sysdba:
@/home/oracle/ora_kafka_home/app_data/scratch/orakafka_adduser_cluster_KC1_user1.sql
The above information is written to /home/oracle/ora_kafka_home/app_data/logs/adduser_cluster.log.2021.02.20-10.45.57
[oracle@dbass bin]$
Comme pour l'étape précédente, nous avons une tâche TODO à effectuer.
Selon le résultat, nous disposons d'un script SQL généré automatiquement. Nous devons exécuter ce script (en tant que sysdba), afin d'accorder à l'utilisateur Oracle Database les droits d'accès books_admin sur le répertoire de configuration du cluster kc1.
Dans notre cas, ce répertoire est /home/oracle/ora_kafka_home/app_data/clusters/KC1.
[oracle@dbass ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Sat Feb 20 10:56:17 2021
Version 19.9.0.0.0
Copyright (c) 1982, 2020, Oracle. All rights reserved.
Connected to:
Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production
Version 19.9.0.0.0
SQL> alter session set container=p0;
Session altered.
SQL> @/home/oracle/ora_kafka_home/app_data/scratch/orakafka_adduser_cluster_KC1_user1.sql
PL/SQL procedure successfully completed.
Granting permissions on "KC1_CONF_DIR" to "BOOKS_ADMIN"
Grant succeeded.`
`The above information is written to /home/oracle/ora_kafka_home/app_data/logs/orakafka_adduser_cluster_KC1_user1.log
Disconnected from Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production
Version 19.9.0.0.0
[oracle@dbass ~]$
-
Nous tirons désormais parti de l'option install d'orakafka.sh. Nous transmettons le répertoire parent (avec l'argument -p) pour les données de cet utilisateur liées à ses activités OSaK sur les clusters Kafka auxquels il est ajouté.
Cette commande génère automatiquement deux scripts DDL (Data Definition Language) :
[oracle@dbass bin]$ ./orakafka.sh install -u books_admin -r /home/oracle/ora_kafka_home/books_admin_user_data_dir Step1: Creation of filesystem location and default directories -------------------------------------------------------------- Created filesystem location directory at /home/oracle/ora_kafka_home/books_admin_user_data_dir/orakafka_location_dir Created filesystem default directory at /home/oracle/ora_kafka_home/books_admin_user_data_dir/orakafka_default_dir Step1 succeeded. Step2: Generate DDL for creation of DB location and default directories -------------------------------------------------------------- Execute the following SQL script while connected as sysdba to setup database directories: @/home/oracle/ora_kafka_home/app_data/scratch/setup_db_dirs_user1.sql On failure, to cleanup location and default directory setup, please run "./orakafka.sh uninstall -u 'BOOKS_ADMIN'" Step2 successfully generated script. Step3: Install ORA_KAFKA package in "BOOKS_ADMIN" user schema -------------------------------------------------------------- Execute the following script in user schema "BOOKS_ADMIN" to install ORA_KAFKA package in the user schema @/home/oracle/ora_kafka_home/app_data/scratch/install_orakafka_user1.sql On failure, to cleanup ORA_KAFKA package from user schema, please run "./orakafka.sh uninstall -u 'BOOKS_ADMIN'" Step3 successfully generated script. ***********SUMMARY************ TODO tasks: 1. Execute the following SQL while connected as sysdba: @/home/oracle/ora_kafka_home/app_data/scratch/setup_db_dirs_user1.sql 2. Execute the following SQL in user schema: @/home/oracle/ora_kafka_home/app_data/scratch/install_orakafka_user1.sql The above information is written to /home/oracle/ora_kafka_home/app_data/logs/install.log.2021.02.20-11.33.09 [oracle@dbass bin] -
La première tâche consiste à exécuter un script SQL pour enregistrer les deux répertoires /home/oracle/ora_kafka_home/books_admin_user_data_dir/orakafka_location_dir et /home/oracle/ora_kafka_home/books_admin_user_data_dir/orakafka_default_dir
avec Oracle DB, en tant qu'objets de répertoires.Comme indiqué dans la sortie, nous devons l'exécuter avec les privilèges SYSDBA, comme suit :
[oracle@dbass ~]$ sqlplus / as sysdba SQL*Plus: Release 19.0.0.0.0 - Production on Sat Feb 20 11:46:04 2021 Version 19.9.0.0.0 Copyright (c) 1982, 2020, Oracle. All rights reserved. Connected to: Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production Version 19.9.0.0.0 SQL> alter session set container=p0; Session altered. SQL> @/home/oracle/ora_kafka_home/app_data/scratch/setup_db_dirs_user1.sql Checking if user exists.. PL/SQL procedure successfully completed. Creating location and default directories.. PL/SQL procedure successfully completed. Directory created. Directory created. Grant succeeded. Grant succeeded. Creation of location dir "BOOKS_ADMIN_KAFKA_LOC_DIR" and default dir "BOOKS_ADMIN_KAFKA_DEF_DIR" completed. Grant of required permissions on "BOOKS_ADMIN_KAFKA_LOC_DIR","BOOKS_ADMIN_KAFKA_DEF_DIR" to "BOOKS_ADMIN" completed. The above information is written to /home/oracle/ora_kafka_home/app_data/logs/setup_db_dirs_user1.log Disconnected from Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production Version 19.9.0.0.0 [oracle@dbass ~]$Notez les objets de répertoire créés par les scripts SQL ci-dessus, à savoir BOOKS_ADMIN_KAFKA_LOC_DIR et BOOKS_ADMIN_KAFKA_DEF_DIR.
Passons maintenant à la deuxième tâche TODO.
-
Ici, nous exécutons un autre script SQL en tant que books_admin (et non sysdba) sur la base de données pluggable p0. Ce script installe l'accès Oracle SQL au package Kafka et aux objets du schéma appartenant à books_admin.
[oracle@dbass ~]$ sqlplus books_admin@p0pdb #p0pdb is tns entry for p0 pdb SQL*Plus: Release 19.0.0.0.0 - Production on Sat Feb 20 11:52:33 2021 Version 19.9.0.0.0 Copyright (c) 1982, 2020, Oracle. All rights reserved. Enter password: Last Successful login time: Fri Feb 19 2021 14:04:59 +00:00 Connected to: Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production Version 19.9.0.0.0 SQL> ALTER SESSION SET CONTAINER=p0; Session altered. SQL> @/home/oracle/ora_kafka_home/app_data/scratch/install_orakafka_user1.sql Verifying user schema.. PL/SQL procedure successfully completed. Verifying that location and default directories are accessible.. PL/SQL procedure successfully completed. Installing ORA_KAFKA package in user schema.. .. Creating ORA_KAFKA artifacts Table created. Table created. Table created. Table created. Package created. No errors. Package created. No errors. Package body created. No errors. Package body created. No errors. The above information is written to /home/oracle/ora_kafka_home/app_data/logs/install_orakafka_user1.log Disconnected from Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production Version 19.9.0.0.0 [oracle@dbass ~]$
Enregistrement du cluster Stream Service avec Oracle Database et création de vues pour le flux
Cette étape consiste à créer le cluster kc1 avec Oracle Database et des vues pour le flux StreamForOsak.
Toutes les requêtes SQL pour cette étape doivent être exécutées en tant qu'utilisateur books_admin et sur la base de données pluggable p0.
- Enregistrez le cluster avec un accès Oracle SQL à la procédure Kafka ORA_KAFKA.REGISTER_CLUSTER.
BEGIN
ORA_KAFKA.REGISTER_CLUSTER
('kc1', -- cluster name
'cell-1.streaming.ap-mumbai-1.oci.oraclecloud.com:9092', -- fill up your bootstrap server here
'BOOKS_ADMIN_KAFKA_DEF_DIR', -- default directory for external table created in previous steps
'BOOKS_ADMIN_KAFKA_LOC_DIR', -- this directory object too is created in previous steps
'KC1_CONF_DIR', --config dir for cluster
'Registering kc1 for this session'); --description
END;
/
- Créez une table Oracle Database nommée BOOKS, qui doit avoir le même schéma que les messages de notre rubrique Kafka StreamForOsak.
CREATE TABLE BOOKS ( -- reference table. It is empty table. Schema of this table must correspond to Kafka Messages
id int,
title varchar2(50),
author_name varchar2(50),
author_email varchar2(50),
publisher varchar2(50)
);
/
- Créez une vue pour notre sujet StreamForOsak avec la procédure stockée d'aide à partir de l'accès Oracle SQL à l'assistant de package Kafka CREATE_VIEWS comme suit.
DECLARE
application_id VARCHAR2(128);
views_created INTEGER;
BEGIN
ORA_KAFKA.CREATE_VIEWS
('kc1', -- cluster name
'OsakApp0', -- consumer group name that OSS or Kafka cluster sees.
'StreamForOsak', -- Kafka topic aka OSS stream name
'CSV', -- format type
'BOOKS', -- database reference table
views_created, -- output
application_id); --output
dbms_output.put_line('views created = ' || views_created);
dbms_output.put_line('application id = ' || application_id);
END;
/
L'accès Oracle SQL à Kafka prend en charge deux formats pour les messages Kafka, CSV et JSON. Ici, nous utilisons CSV. Par conséquent, un exemple de message Kafka conforme au schéma de la table BOOKS peut être 101, Famous Book, John Smith, john@smith.com, First Software.
tar xvf sqldeveloper-20.4.0.379.2205-20.4.0-379.2205.noarch.rpm
- L'étape ci-dessus permet de créer une vue pour chaque partition du sujet. Comme le sujet StreamForOsak comporte trois partitions, nous disposerons de trois vues. Le nom de chaque vue sera au format KV_<CLUSTER_NAME>_<GROUP_NAME>_TOPIC_<NUM_OF_PARTITION>.
Nous avons ici trois vues, comme illustré ci-dessous, une pour chaque partition.

Ainsi, la vue KV_KC1_OSAKAPP0_STREAMFOROSAK_0 est mappée à la partition 0, la vue KV_KC1_OSAKAPP0_STREAMFOROSAK_2 est mappée à la partition 1 et enfin, KV_KC1_OSAKAPP0_STREAMFOROSAK_0 est mappée à la partition 2 du sujet StreamForOsak.
Produire des données vers le flux
- Générez un message de test pour transmettre StreamForOsak, à l'aide du bouton Produire un message de test de la console Web Oracle Cloud Infrastructure (OCI), comme indiqué ci-dessous.

Lorsque nous cliquons sur Générer un message de test, une fenêtre contenant un champ dans laquelle entrer le message de test apparaît, comme illustré ci-dessous.

Nous saisissons le message suivant :
200, Andrew Miller Part 1, MS Brown, mb@example.com, First Software
Nous aurions également pu utiliser l'API Kafka Producer standard dans le kit SDK Java/Python ou OCI pour le service Stream, pour produire le message vers le flux de service Stream.
- Après avoir cliqué sur Produire dans la fenêtre ci-dessus, nous publions le message dans le flux StreamForOsak. L'utilitaire Charger le message permet de voir la partition vers laquelle le message a été envoyé.

Comme illustré ci-dessus, notre message a été envoyé dans la partition 2 du sujet StreamForOsak.
Extraire les messages du service de flux à l'aide de la configuration des vues de base de données par l'accès Oracle SQL aux procédures stockées Kafka
Nous pouvons exécuter une requête SQL simple :
SELECT * FROM KV_KC1_OSAKAPP0_STREAMFOROSAK_2_
Ou, comme illustré ci-dessous, nous pouvons simplement ouvrir le développeur SQL de vue pour voir les données dans la vue KV_KC1_OSAKAPP0_STREAMFOROSAK_2 :
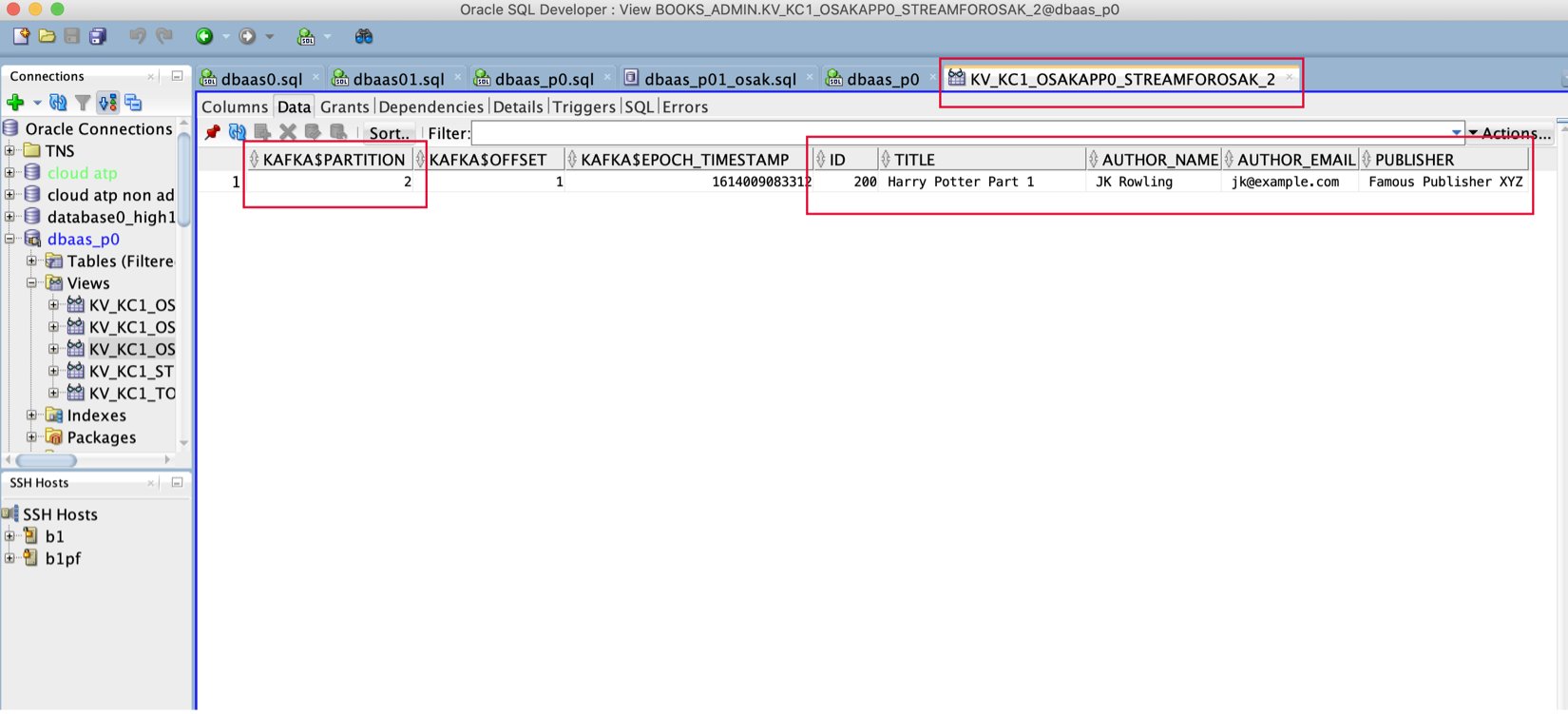
Nous avons choisi la vue KV_KC1_OSAKAPP0_STREAMFOROSAK_2, car elle correspond à la partition 2 du flux StreamForOsak. Chaque fois que nous exécutons la requête SQL SELECT pour cette vue, elle accède à la partition correspondante de la rubrique associée et extrait les nouveaux messages non validés (pour le groupe de consommateurs de ressources OsakApp0) sous forme de lignes dans la vue. Chaque message obtient sa propre ligne dans la vue. Notez que les données de ces vues ne sont pas conservées.
Les yeux curieux peuvent également observer qu'Oracle SQL accède aux extractions Kafka et stocke des informations de métadonnées telles que le décalage du message, sa partition et l'horodatage dans des colonnes supplémentaires.
Il est fort probable que vous souhaitiez interroger à nouveau cette vue et que, pour chaque exécution de la requête, vous souhaitiez que la vue se déplace séquentiellement dans le flux. Pour ce faire, vous pouvez facilement utiliser le fragment de code canonique suivant :
LOOP
ORA_KAFKA.NEXT_OFFSET(‘_KV_KC1_OSAKAPP0_STREAMFOROSAK_2_’);
SELECT * FROM KV_KC1_OSAKAPP0_STREAMFOROSAK_2_;
ORA_KAFKA.UPDATE_OFFSET(‘_KV_KC1_OSAKAPP0_STREAMFOROSAK_2_’);
COMMIT;
END LOOP;
Comme indiqué précédemment, lorsque nous utilisons l'accès Oracle SQL à Kafka, les décalages de flux sont gérés par Oracle Database et non par le service Stream. Ils résident dans des tables système qui suivent le positionnement des décalages pour toutes les partitions auxquelles accède la vue KV_KC1_OSAKAPP0_STREAMFOROSAK_2.
L'appel NEXT_OFFSET lie simplement la vue KV_KC1_OSAKAPP0_STREAMFOROSAK_2 à un nouvel ensemble de décalages qui représentent les nouvelles données de la partition Oracle Cloud Infrastructure Streaming à laquelle accède la vue. UPDATE_OFFSET indique le nombre de lignes lues pour chaque partition et avance les décalages vers de nouvelles positions.
COMMIT garantit que cette unité de travail est compatible ACID.
Conclusion
Dans ce tutoriel, nous avons abordé la manière d'installer l'accès Oracle SQL à Kafka et de l'utiliser avec le service Stream. Le service Stream étant compatible avec Kafka, il s'agit d'un cluster Kafka pour l'accès Oracle SQL à Kafka.
Notez que nous avons à peine rayé la surface en ce qui concerne les fonctionnalités offertes par l'accès Oracle SQL à Kafka. L'accès Oracle SQL à Kafka est hautement configurable. Nous pouvons même stocker les données de transmission en continu dans les tables Oracle Database, qui sont conservées sur le disque, contrairement aux vues. Pour plus d'informations, reportez-vous aux fichiers README fournis dans l'accès Oracle SQL à l'installation Kafka et aux références ci-dessous.
Liens connexes
- Documentation pour les développeurs PL/SQL Oracle permettant à Oracle SQL d'accéder à Kafka
- Blog Oracle sur l'accès Oracle SQL à Kafka
- Accès à Kafka via Oracle SQL dans Oracle Big Data SQL
- Oracle Cloud Infrastructure Streaming
- Compatibilité de l'API Kafka du service de flux de données
Remerciements
- Auteur - Mayur Raleraskar, architecte de solutions
""
Ressources de formation supplémentaires
Explorez d'autres exercices sur docs.oracle.com/learn ou accédez à davantage de contenu d'apprentissage gratuit sur le canal Oracle Learning YouTube. De plus, visitez le site education.oracle.com/learning-explorer pour devenir Oracle Learning Explorer.
Pour consulter la documentation du produit, consultez le centre d'aide Oracle.
Stream analytics using Oracle Cloud Infrastructure Streaming and Oracle Database
F50461-01
November 2021
Copyright © 2021, Oracle and/or its affiliates.