Develop Oracle Cloud Infrastructure Data Flow Applications Locally, Deploy to The Cloud
Oracle Cloud Infrastructure Data Flow is a fully managed Apache Spark cloud service. It lets you run Spark applications at any scale, and with minimal administrative or set up work. Data Flow is ideal for scheduling reliable long-running batch processing jobs.
You can develop Spark applications without being connected to the cloud. You can quickly develop, test, and iterate them on your laptop computer. When they're ready, you can deploy them to Data Flow without any need to reconfigure them, make code changes, or apply deployment profiles.
- Most of the source code and libraries used to run Data Flow are hidden. You no longer need to match the Data Flow SDK versions, and no longer have third-party dependency conflicts with Data Flow.
- The SDKs are compatible with Spark, so you no longer need to move conflicting third-party dependencies, letting you separate your application from your libraries for faster, less complicated, smaller, and more flexible builds.
- The new template pom.xml file downloads and builds a near identical copy of Data Flow on your local machine. You can run the step debugger on your local machine to detect and resolve problems before running your Application on Data Flow. You can compile and run against the exact same library versions that Data Flow runs. Oracle can quickly decide if your issue is a problem with Data Flow or your application code.
Before You Begin
Before you begin to develop you appliations, you need the following set up and working:
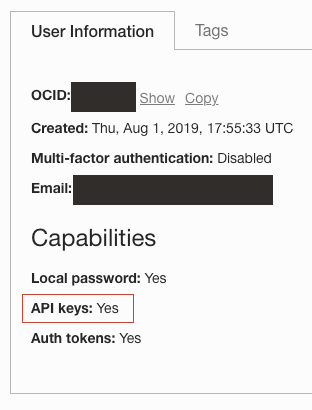
- An Oracle Cloud log in with the API Key capability enabled. Load your user under
Identity
/Users, and confirm you can create API Keys.
- An API key registered and deployed to your local environment. See Register an API Key for more information.
- A working local installation of Apache Spark 2.4.4, 3.0.2, 3.2.1, or 3.5.0. You can confirm it by running spark-shell in the command line interface.
- Apache Maven installed. The instructions and examples use Maven to download the dependencies you need.
Before you start, review run security in Data Flow. It uses a delegation token that lets it make cloud operations on your behalf. Anything your account can do in the Oracle Cloud Infrastructure Console your Spark job can do using Data Flow. When you run in local mode, you need to use an API key that lets your local application make authenticated requests to various Oracle Cloud Infrastructure services.
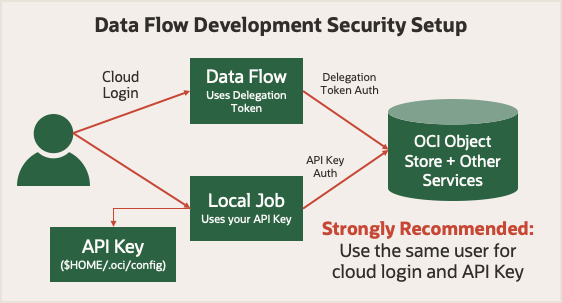
To keep things simple, use an API key generated for the same user as when you log into the Oracle Cloud Infrastructure Console. It means that your applications have the same privileges whether you run them locally or in Data Flow.
1. The Concepts of Developing Locally
- Customize your local Spark installation with Oracle Cloud Infrastructure library files, so that it resembles Data Flow's runtime environment.
- Detect where your code is running,
- Configure the Oracle Cloud Infrastructure HDFS client appropriately.
So that you can move seamlessly between your computer and Data Flow, you must use certain versions of Spark, Scala, and Python in your local set up. Add the Oracle Cloud Infrastructure HDFS Connector JAR file. Also add ten dependency libraries to your Spark installation that are installed when your application runs in Data Flow. These steps show you how to download and install these ten dependency libraries.
| Spark Version | Scala Version | Python Version |
|---|---|---|
| 3.5.0 | 2.12.18 | 3.11.5 |
| 3.2.1 | 2.12.15 | 3.8 |
| 3.0.2 | 2.12.10 | 3.6.8 |
| 2.4.4 | 2.11.12 | 3.6.8 |
CONNECTOR=com.oracle.oci.sdk:oci-hdfs-connector:2.7.7.3
mkdir -p deps
touch emptyfile
mvn install:install-file -DgroupId=org.projectlombok -DartifactId=lombok -Dversion=1.16.7 -Dpackaging=jar -Dfile=emptyfile
mvn org.apache.maven.plugins:maven-dependency-plugin:2.7:get -Dartifact=$CONNECTOR -Ddest=deps
mvn org.apache.maven.plugins:maven-dependency-plugin:2.7:get -Dartifact=$CONNECTOR -Ddest=deps -Dtransitive=true -Dpackaging=pom
mvn org.apache.maven.plugins:maven-dependency-plugin:2.7:copy-dependencies -f deps/*.pom -DoutputDirectory=.
echo 'sc.getConf.get("spark.home")' | spark-shellscala> sc.getConf.get("spark.home")
res0: String = /usr/local/lib/python3.7/site-packages/pyspark/usr/local/lib/python3.7/site-packages/pyspark/jarsdeps directory contains many JAR files, most of which
are already available in the Spark installation. You only need to copy a subset of these
JAR files into the Spark environment:bcpkix-jdk15on-1.60.jar
bcprov-jdk15on-1.60.jar
guava-19.0.jar
jersey-media-json-jackson-2.27.jar
oci-hdfs-connector-2.7.7.3.jar
oci-java-sdk-addons-apache-1.5.12.jar
oci-java-sdk-common-1.5.12.jar
oci-java-sdk-objectstorage-1.5.12.jar
oci-java-sdk-objectstorage-extensions-1.5.12.jar
oci-java-sdk-objectstorage-generated-1.5.12.jardeps directory into the jars subdirectory you
found in step 2.import com.oracle.bmc.hdfs.BmcFilesystem

- You can use the value of
spark.masterin theSparkConfobject which is set to k8s://https://kubernetes.default.svc:443 when running in Data Flow. - The
HOMEenvironment variable is set to/home/dataflowwhen running in Data Flow.
In PySpark applications, a newly created SparkConf object is empty.
To see the correct values, use the getConf method of running
SparkContext.
| Launch Environment | spark.master setting |
|---|---|
| Data Flow | |
| Local spark-submit | spark.master: local[*] $HOME: Variable |
| Eclipse | Unset $HOME: Variable |
When you're running in Data Flow, don't change the value of
spark.master. If you do, your job doesn't use all the resources you provisioned. When your application runs in Data Flow, the Oracle Cloud Infrastructure HDFS Connector is automatically configured. When you run locally, you need to configure it yourself by setting the HDFS Connector configuration properties.
At a minimum, you need to update your SparkConf object to set values for
fs.oci.client.auth.fingerprint,
fs.oci.client.auth.pemfilepath,
fs.oci.client.auth.tenantId,
fs.oci.client.auth.userId, and
fs.oci.client.hostname.
If your API key has a passphrase, you need to set fs.oci.client.auth.passphrase.
These variables can be set after the session is created. Within your programming environment, use the respective SDKs to properly load your API Key configuration.
ConfigFileAuthenticationDetailsProvider as
appropriate:import com.oracle.bmc.auth.ConfigFileAuthenticationDetailsProvider;
import com.oracle.bmc.ConfigFileReader;
//If your key is encrypted call setPassPhrase:
ConfigFileAuthenticationDetailsProvider authenticationDetailsProvider = new ConfigFileAuthenticationDetailsProvider(ConfigFileReader.DEFAULT_FILE_PATH, "<DEFAULT>");
configuration.put("fs.oci.client.auth.tenantId", authenticationDetailsProvider.getTenantId());
configuration.put("fs.oci.client.auth.userId", authenticationDetailsProvider.getUserId());
configuration.put("fs.oci.client.auth.fingerprint", authenticationDetailsProvider.getFingerprint());
String guessedPath = new File(configurationFilePath).getParent() + File.separator + "oci_api_key.pem";
configuration.put("fs.oci.client.auth.pemfilepath", guessedPath);
// Set the storage endpoint:
String region = authenticationDetailsProvider.getRegion().getRegionId();
String hostName = MessageFormat.format("https://objectstorage.{0}.oraclecloud.com", new Object[] { region });
configuration.put("fs.oci.client.hostname", hostName);oci.config.from_file as
appropriate:import os
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
# Check to see if we're in Data Flow or not.
if os.environ.get("HOME") == "/home/dataflow":
spark_session = SparkSession.builder.appName("app").getOrCreate()
else:
conf = SparkConf()
oci_config = oci.config.from_file(oci.config.DEFAULT_LOCATION, "<DEFAULT>")
conf.set("fs.oci.client.auth.tenantId", oci_config["tenancy"])
conf.set("fs.oci.client.auth.userId", oci_config["user"])
conf.set("fs.oci.client.auth.fingerprint", oci_config["fingerprint"])
conf.set("fs.oci.client.auth.pemfilepath", oci_config["key_file"])
conf.set(
"fs.oci.client.hostname",
"https://objectstorage.{0}.oraclecloud.com".format(oci_config["region"]),
)
spark_builder = SparkSession.builder.appName("app")
spark_builder.config(conf=conf)
spark_session = spark_builder.getOrCreate()
spark_context = spark_session.sparkContext
In SparkSQL, the configuration is managed differently. These settings are passed using the
--hiveconf switch. To run Spark SQL queries, use a wrapper script
similar to the example. When you run your script in Data Flow, these settings are made for you
automatically.
#!/bin/sh
CONFIG=$HOME/.oci/config
USER=$(egrep ' user' $CONFIG | cut -f2 -d=)
FINGERPRINT=$(egrep ' fingerprint' $CONFIG | cut -f2 -d=)
KEYFILE=$(egrep ' key_file' $CONFIG | cut -f2 -d=)
TENANCY=$(egrep ' tenancy' $CONFIG | cut -f2 -d=)
REGION=$(egrep ' region' $CONFIG | cut -f2 -d=)
REMOTEHOST="https://objectstorage.$REGION.oraclecloud.com"
spark-sql \
--hiveconf fs.oci.client.auth.tenantId=$TENANCY \
--hiveconf fs.oci.client.auth.userId=$USER \
--hiveconf fs.oci.client.auth.fingerprint=$FINGERPRINT \
--hiveconf fs.oci.client.auth.pemfilepath=$KEYFILE \
--hiveconf fs.oci.client.hostname=$REMOTEHOST \
-f script.sql
The preceding examples only change the way you build your Spark Context. Nothing else in your Spark application needs to change, so you can develop other aspects of your Spark application as you would normally. When you deploy your Spark application to Data Flow, you don't need to change any code or configuration.
2. Creating "Fat JARs" for Java Applications
Java and Scala applications usually need to include more dependencies into a JAR file known as a "Fat JAR".
If you use Maven, you can do this using the Shade plugin. The following
examples are from Maven pom.xml files. You can use them as a
starting point for your project. When you build your application, the dependencies
are automatically downloaded and inserted into your runtime environment.
If using Spark 3.5.0 or 3.2.1, this chapter doesn't apply. Instead, follow chapter 2. Managing Java Dependencies for Apache Spark Applications in Data Flow.
This part pom.xml includes the proper Spark and Oracle Cloud Infrastructure library versions for Data Flow (Spark 3.0.2). It targets Java 8, and shades common conflicting class files.
<properties>
<oci-java-sdk-version>1.25.2</oci-java-sdk-version>
</properties>
<dependencies>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-hdfs-connector</artifactId>
<version>3.2.1.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-core</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-objectstorage</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<!-- spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.2</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.0</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>example.Example</mainClass>
</transformer>
</transformers>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<relocations>
<relocation>
<pattern>com.oracle.bmc</pattern>
<shadedPattern>shaded.com.oracle.bmc</shadedPattern>
<includes>
<include>com.oracle.bmc.**</include>
</includes>
<excludes>
<exclude>com.oracle.bmc.hdfs.**</exclude>
</excludes>
</relocation>
</relocations>
<artifactSet>
<excludes>
<exclude>org.bouncycastle:bcpkix-jdk15on</exclude>
<exclude>org.bouncycastle:bcprov-jdk15on</exclude>
<!-- Including jsr305 in the shaded jar causes a SecurityException
due to signer mismatch for class "javax.annotation.Nonnull" -->
<exclude>com.google.code.findbugs:jsr305</exclude>
</excludes>
</artifactSet>
</configuration>
</plugin>
</plugins>
</build>This part pom.xml includes the proper Spark and Oracle Cloud Infrastructure library versions for Data Flow ( Spark 2.4.4). It targets Java 8, and
shades common conflicting class files.
<properties>
<oci-java-sdk-version>1.15.4</oci-java-sdk-version>
</properties>
<dependencies>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-hdfs-connector</artifactId>
<version>2.7.7.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-core</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-objectstorage</artifactId>
<version>${oci-java-sdk-version}</version>
</dependency>
<!-- spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>2.4.4</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>2.4.4</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.0</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>example.Example</mainClass>
</transformer>
</transformers>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<relocations>
<relocation>
<pattern>com.oracle.bmc</pattern>
<shadedPattern>shaded.com.oracle.bmc</shadedPattern>
<includes>
<include>com.oracle.bmc.**</include>
</includes>
<excludes>
<exclude>com.oracle.bmc.hdfs.**</exclude>
</excludes>
</relocation>
</relocations>
<artifactSet>
<excludes>
<exclude>org.bouncycastle:bcpkix-jdk15on</exclude>
<exclude>org.bouncycastle:bcprov-jdk15on</exclude>
<!-- Including jsr305 in the shaded jar causes a SecurityException
due to signer mismatch for class "javax.annotation.Nonnull" -->
<exclude>com.google.code.findbugs:jsr305</exclude>
</excludes>
</artifactSet>
</configuration>
</plugin>
</plugins>
</build>3. Testing Your Application Locally
Before deploying your application, you can test it locally to be sure it works. There are
three techniques you can use, choose the one that works best for you. These examples
assume that your application artifact is named application.jar (for
Java) or application.py (for Python).
- Data Flow hides most of the source code and libraries it uses to run, so Data Flow SDK versions no longer need matching and third-party dependency conflicts with Data Flow ought not to happen.
- Spark has been upgraded so that the OCI SDKs are now compatible with it. This means that conflicting third-party dependencies don't need moving, so the application and libraries libraries can be separated for faster, less complicated, smaller, and more flexible builds.
- The new template pom.xml file downloads and build an almost identical copy of
Data Flow on a developer's local machine.
This means that:
- Developers can run the step debugger on their local machine to quickly detect and resolve problems before running on Data Flow.
- Developers can compile and run against the exact same library versions that Data Flow runs. So the Data Flow team can quickly decide if an issue is a problem with Data Flow or the application code.
Method 1: Run from your IDE
If you developed in an IDE like Eclipse, you needn't do anything more than click
Run, and choose the appropriate main class. 
When you run, it's normal to see Spark produce warning messages in the Console, which let you know Spark is being invoked. 
Method 2: Run PySpark from the Command Line
python3 application.py$ python3 example.py
Warning: Ignoring non-Spark config property: fs.oci.client.hostname
Warning: Ignoring non-Spark config property: fs.oci.client.auth.fingerprint
Warning: Ignoring non-Spark config property: fs.oci.client.auth.tenantId
Warning: Ignoring non-Spark config property: fs.oci.client.auth.pemfilepath
Warning: Ignoring non-Spark config property: fs.oci.client.auth.userId
20/08/01 06:52:00 WARN Utils: Your hostname resolves to a loopback address: 127.0.0.1; using 192.168.1.41 instead (on interface en0)
20/08/01 06:52:00 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
20/08/01 06:52:01 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableMethod 3: Use Spark-Submit
The spark-submit utility is included with your Spark distribution. Use
this method in some situations, for example, when a PySpark application requires extra
JAR files.
spark-submit:spark-submit --class example.Example example.jarBecause you need to provide the main class name to Data Flow, this code is a good way to confirm that you're using the correct class name. Remember that class names are case-sensitive.
spark-submit to run a PySpark application that
requires Oracle JDBC JAR files:
spark-submit \
--jars java/oraclepki-18.3.jar,java/ojdbc8-18.3.jar,java/osdt_cert-18.3.jar,java/ucp-18.3.jar,java/osdt_core-18.3.jar \
example.py4. Deploy the Application
- Copy the application artifact (
jarfile, Python script, or SQL script) to Oracle Cloud Infrastructure Object Storage. - If your Java application has dependencies not provided by Data Flow, remember to copy the assembly
jarfile. - Create a Data Flow Application that references this artifact within Oracle Cloud Infrastructure Object Storage.
After step 3, you can run the Application as many times as you want. For more information, the Getting Started with Oracle Cloud Infrastructure Data Flow tutorial takes you through this process step by step.
What's Next
Now you know how to develop your applications locally and deploy them to Data Flow.