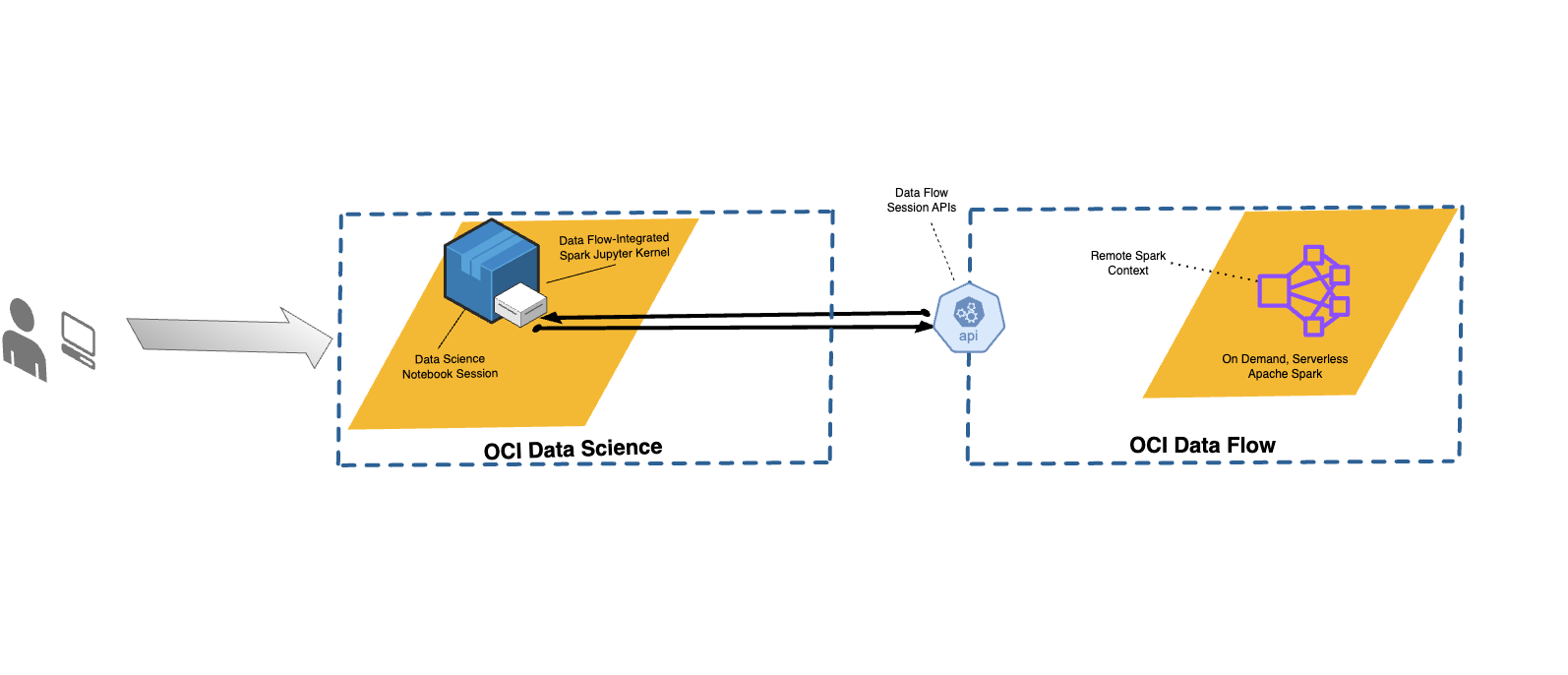
Integrazione di Data Flow e Data Science
Con Data Flow, puoi configurare i notebook Data Science per eseguire le applicazioni in modo interattivo su Data Flow.
Data Flow utilizza i notebook Jupyter completamente gestiti per consentire ai data scientist e ai data engineer di creare, visualizzare, collaborare ed eseguire il debug di applicazioni di data engineering e data science. È possibile scrivere queste applicazioni in Python, Scala e PySpark. È inoltre possibile connettere una sessione notebook Data Science a Data Flow per eseguire le applicazioni. I kernel e le applicazioni Data Flow vengono eseguiti su Oracle Cloud Infrastructure Data Flow .
Apache Spark è un sistema di calcolo distribuito progettato per elaborare i dati su larga scala. Supporta l'elaborazione SQL, batch e stream su larga scala e task di Machine Learning. Spark SQL fornisce supporto di tipo database. Per eseguire query sui dati strutturati, utilizzare Spark SQL. Si tratta di un'implementazione SQL standard ANSI.
Le sessioni di Data Flow supportano il ridimensionamento automatico delle funzionalità del cluster di Data Flow. Per ulteriori informazioni, vedere Ridimensionamento automatico nella documentazione di Data Flow.
Le sessioni di flusso di dati supportano l'uso di ambienti conda come ambienti runtime Spark personalizzabili.
- Limitazioni
-
-
Le sessioni di flusso dati durano fino a 7 giorni o 10.080 minuti (maxDurationInMinutes).
- Le sessioni di flusso dati hanno un valore di timeout inattività predefinito di 480 minuti (8 ore) (idleTimeoutInMinutes). È possibile configurare un valore diverso.
- La sessione di flusso dati è disponibile solo tramite una sessione notebook di Data Science.
- Sono supportati solo Spark versione 3.5.0 e 3.2.1.
-
Guarda il video dell'esercitazione sull'utilizzo di Data Science con Data Flow Studio. Per ulteriori informazioni sull'integrazione di Data Science e Data Flow, consulta anche la documentazione di Oracle Accelerated Data Science SDK.
Installazione dell'ambiente Conda
Attenersi alla procedura descritta di seguito per utilizzare il flusso di dati con Magic.
Uso del flusso di dati con Data Science
Attenersi alla procedura riportata di seguito per eseguire un'applicazione utilizzando Data Flow con Data Science.
-
Assicurarsi di disporre dei criteri impostati per utilizzare un notebook con Data Flow.
-
Assicurarsi di avere impostato correttamente i criteri di Data Science.
- Per un elenco di tutti i comandi supportati, utilizzare il comando
%help. - I comandi riportati di seguito si applicano sia a Spark 3.5.0 che a Spark 3.2.1. Negli esempi viene utilizzato Spark 3.5.0. Impostare il valore di
sparkVersionin base alla versione di Spark utilizzata.
Personalizzazione di un ambiente Spark di flusso di dati con un ambiente Conda
È possibile utilizzare un ambiente Conda pubblicato come ambiente runtime.
Esecuzione di spark-nlp nel flusso di dati
Attenersi alla procedura riportata di seguito per installare Spark-nlp ed eseguirlo in Data Flow.
È necessario aver completato i passi 1 e 2 in Personalizzazione di un ambiente Spark di un flusso di dati con un ambiente Conda. La libreria spark-nlp è preinstallata nell'ambiente conda pyspark32_p38_cpu_v2.
Esempi
Di seguito sono riportati alcuni esempi di utilizzo dei dati FlowMagic.
PySpark
sc rappresenta il Spark ed è disponibile quando si utilizza il comando magic %%spark. La cella seguente è un esempio giocattolo di come utilizzare sc in una cella Data FlowMagic. La cella chiama il metodo .parallelize() che crea un RDD, numbers, da un elenco di numeri. Vengono stampate le informazioni sull'RDD. Il metodo .toDebugString() restituisce una descrizione dell'RDD.%%spark
print(sc.version)
numbers = sc.parallelize([4, 3, 2, 1])
print(f"First element of numbers is {numbers.first()}")
print(f"The RDD, numbers, has the following description\n{numbers.toDebugString()}")Spark SQL
L'uso dell'opzione -c sql consente di eseguire i comandi SQL Spark in una cella. In questa sezione viene utilizzato il set di dati citi Bike. La cella seguente legge il set di dati in un dataframe Spark e lo salva come tabella. Questo esempio viene utilizzato per mostrare Spark SQL.
%%spark
df_bike_trips = spark.read.csv("oci://dmcherka-dev@ociodscdev/201306-citibike-tripdata.csv", header=False, inferSchema=True)
df_bike_trips.show()
df_bike_trips.createOrReplaceTempView("bike_trips")L'esempio seguente utilizza l'opzione -c sql per indicare a Data FlowMagic che il contenuto della cella è SparkSQL. L'opzione -o <variable> acquisisce i risultati dell'operazione SQL Spark e li memorizza nella variabile definita. In questo caso, la
df_bike_trips è un dataframe Pandas disponibile per l'uso nel notebook.%%spark -c sql -o df_bike_trips
SELECT _c0 AS Duration, _c4 AS Start_Station, _c8 AS End_Station, _c11 AS Bike_ID FROM bike_trips;df_bike_trips.head()sqlContext per eseguire una query sulla tabella:%%spark
df_bike_trips_2 = sqlContext.sql("SELECT * FROM bike_trips")
df_bike_trips_2.show()%%spark -c sql
SHOW TABLESWidget di visualizzazione automatica
Data FlowMagic viene fornito con autovizwidget che consente la visualizzazione dei dataframe Pandas. La funzione display_dataframe() utilizza un dataframe Pandas come parametro e genera una GUI interattiva nel notebook. Sono disponibili schede che mostrano la visualizzazione dei dati in varie forme, ad esempio tabelle, grafici a torta, grafici a dispersione e grafici ad aree e a barre.
display_dataframe() con il dataframe df_people creato nella sezione SQL Spark del notebook:from autovizwidget.widget.utils import display_dataframe
display_dataframe(df_bike_trips)Matplotlib
Un compito comune che i data scientist devono eseguire è quello di visualizzare i propri dati. Con set di dati di grandi dimensioni, di solito non è possibile ed è quasi sempre preferibile estrarre i dati dal cluster Spark di Data Flow nella sessione notebook. Questo esempio mostra come utilizzare le risorse lato server per generare un grafico e includerlo nel notebook.
%matplot plt per visualizzare la trama nel notebook, anche se viene visualizzata sul lato server:%%spark
import matplotlib.pyplot as plt
df_bike_trips.groupby("_c4").count().toPandas().plot.bar(x="_c4", y="count")
%matplot pltUlteriori esempi
Sono disponibili altri esempi da GitHub con Esempi di flusso dati e Esempi di data science.