Pianificazione delle esecuzioni dei job di Data Science
In questa esercitazione viene utilizzato Data Integration per pianificare le esecuzioni dei job per i job di Data Science.
I task chiave includono come:
- Creare un job con un artifact del job Data Science.
- Impostare un task REST per creare un job con le stesse specifiche del job creato con l'artifact.
- Impostare una schedulazione e assegnarla al task REST.
- Chiedere allo scheduler dei task di creare i job di Data Science.
Informazioni preliminari
Per eseguire correttamente questa esercitazione, è necessario disporre dei seguenti elementi:
-
Un account a pagamento Oracle Cloud Infrastructure o un nuovo account con promozioni Oracle Cloud, vedi Richiedi e gestisci le promozioni gratuite di Oracle Cloud.
- Un computer MacOS, Linux o Windows.
1. Prepara
Creare e impostare gruppi dinamici, criteri, un compartimento e un progetto Data Science per l'esercitazione.
Eseguire l'esercitazione sulla configurazione manuale di una tenancy di Data Science con le seguenti specifiche:
Se in precedenza è stata eseguita la configurazione manuale di una tenancy di Data Science, assicurarsi di leggere i passi successivi e di incorporare i criteri applicabili a questa esercitazione.
Consente al servizio Data Integration di creare aree di lavoro.
In questo passo è possibile aggiungere aree di lavoro di Data Integration a data-science-dynamic-group. data-science-dynamic-group-policy consente a tutti i membri di questo gruppo dinamico di gestire data-science-family. In questo modo, le risorse dell'area di lavoro, come le pianificazioni dei task, possono creare i job di Data Science.
2. Imposta esecuzione job
Creare un artifact del job Python hello world da utilizzare nelle esecuzioni di job e job:
Eseguire hello_world_job:
Quando si crea un job, si impostano l'infrastruttura e gli artifact per il job. Successivamente, si crea un'esecuzione di job che esegue il provisioning dell'infrastruttura, esegue l'artifact del job e, al termine del job, annulla il provisioning e distrugge le risorse utilizzate.
-
Nella pagina
hello_world_job, selezionare Avvia esecuzione job. -
Selezionare il compartimento
data-science-work. -
Nome dell'esecuzione del job,
hello_world_job_run_test. - Saltare le sezioni Override configurazione log e Override configurazione job.
- Selezionare Start.
- Nel trail che visualizza la pagina corrente, che ora è la pagina dei dettagli dell'esecuzione del job, selezionare Esecuzione job per tornare indietro e ottenere la lista delle esecuzioni dei job.
- Per hello_world_job_run_test, attendere che lo stato passi da Accettato a In corso e infine a Riuscito prima di passare al passo successivo.
Per utilizzare hello_world_job per la pianificazione, è necessario preparare alcune informazioni sul job:
3. Imposta il task
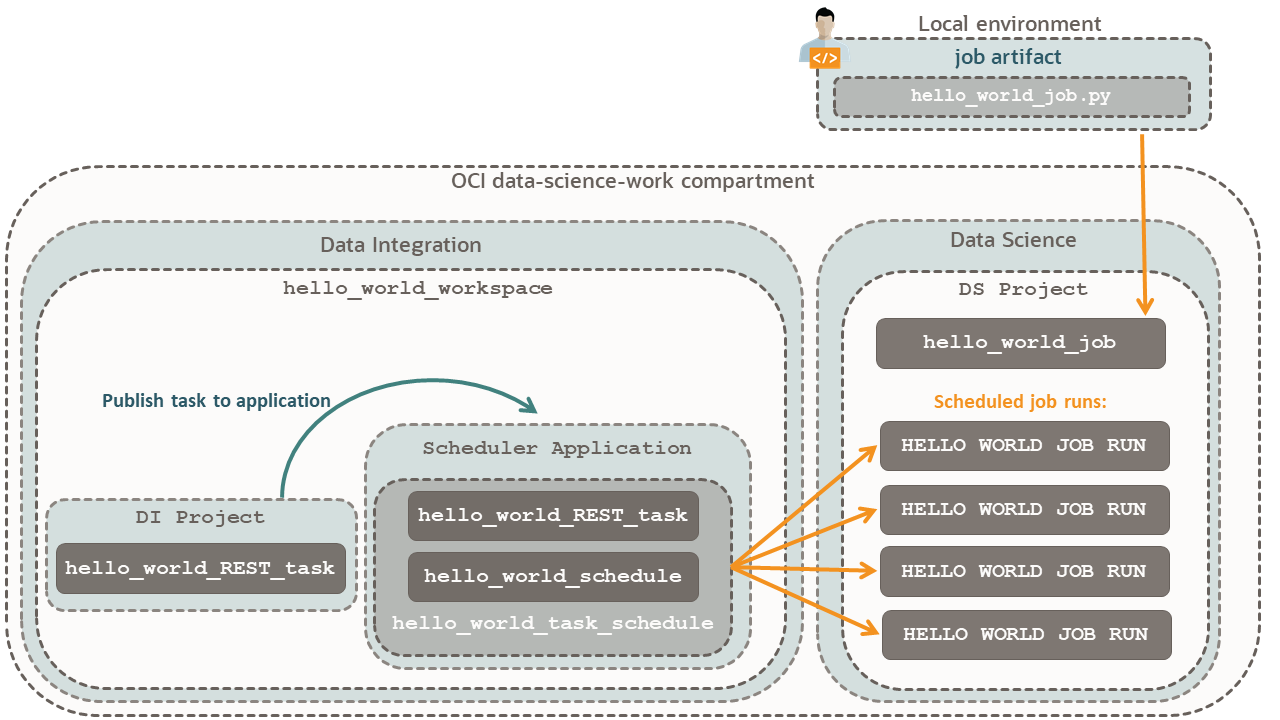
Per una relazione visiva dei componenti, fare riferimento al diagramma dello scheduler.
Creare un'area di lavoro per ospitare un progetto con un task che crea esecuzioni di job.
Questa area di lavoro utilizza datascience-vcn e il job Data Science creato utilizza l'opzione Networking predefinito disponibile in Data Science. Poiché hai concesso al servizio Data Integration l'accesso a tutte le risorse nel compartimento data-science-work, non importa che le VCN siano diverse. Data Integration dispone di uno scheduler in datascience-vcn, creando esecuzioni di job nella VCN di rete di rete predefinita.
Nel file hello_world_workspace aggiornare il nome del progetto generato dal sistema.
È possibile modificare il nome del progetto in modo che sia chiaro che il progetto è un progetto Data Integration e non un progetto Data Science.
Creare un task e definire i parametri dell'API REST per la creazione di un'esecuzione job.
Dopo che l'area di lavoro mostra che il task REST è stato creato con esito positivo, fare clic su Salva e chiudi.
Nel corpo della richiesta del task REST, assegnare i valori ai parametri necessari per la creazione di un'esecuzione di job. Utilizzare gli stessi valori di
hello_world_job creati in Data Science nella sezione Crea un job di questa esercitazione.Riferimenti:
Crea un'applicazione scheduler che esegue il task REST in base a una pianificazione.
-
Nell'area di lavoro
hello_world_workspace, nel pannello Azioni rapide selezionare Crea applicazione. -
Nome dell'applicazione,
Scheduler Application. - Selezionare Crea.
Aggiungere il file hello_world_REST_task al file Scheduler Application:
-
Nel trail che visualizza la pagina corrente, passare all'area di lavoro
hello_world_workspacee selezionare il collegamento Progetti. - Selezionare Progetto ID.
- Selezionare Task.
-
Nell'elenco Task, selezionare il menu Azioni (tre punti) per
hello_world_REST_task, quindi selezionare Pubblica nell'applicazione. - Per Nome applicazione, selezionare Applicazione scheduler.
- Selezionare Pubblica.
Prima di pianificare hello_world_REST_task, eseguire il test del task eseguendolo manualmente:
Verificare che l'esecuzione del job di Data Science visualizzi il task eseguito da Data Integration.
4. Pianifica ed esegui il task
Creare una pianificazione per l'esecuzione del file hello_world_REST_task pubblicato.
- In questo passo è possibile impostare una pianificazione in
Scheduler Application.Nel passo successivo è possibile associare la pianificazione al filehello_world_REST_task.
Riferimento: pianificazione dei task pubblicati
Assegnare il file hello_world_schedule al file hello_world_REST_task pubblicato:
Verificare che l'esecuzione del job di Data Science visualizzi il task pianificato da Data Integration.
Dopo aver ricevuto uno o più job eseguiti, questa esercitazione viene completata. Ora è possibile disabilitare lo scheduler e arrestare le nuove esecuzioni di job.
-
In
hello_world_workspace, fare clic su Applicazioni, quindi suScheduler Application. - Nel pannello di navigazione a sinistra selezionare Task.
-
Selezionare
hello_world_REST_task. -
Nell'elenco delle pianificazioni dei task fare clic su
hello_world_REST_task_schedule. - Selezionare Disable.
- Nella finestra di dialogo di conferma selezionare Disabilita.
- Se sono state create più pianificazioni task per questa esercitazione, disabilitarle tutte.
Pagina successiva
Sono state pianificate correttamente le esecuzioni dei job Data Science.
Per ulteriori informazioni sui job di Data Science, consultare le sezioni riportate di seguito nella documentazione di Data Science.
Per ulteriori informazioni su Data Science, consulta le esercitazioni su Data Science e i video di apprendimento su Data Science.