Integrazione di Vision con Oracle Analytics Cloud (OAC)
Crea un flusso di integrazione dati che utilizza il kit SDK Vision per rilevare gli oggetti nelle immagini e proiettare tali informazioni in una tabella di un data warehouse. Questi dati di output vengono quindi utilizzati da Oracle Analytics Cloud per creare visualizzazioni e trovare pattern.
Questo è il flusso di alto livello del sistema tra Vision e OAC: 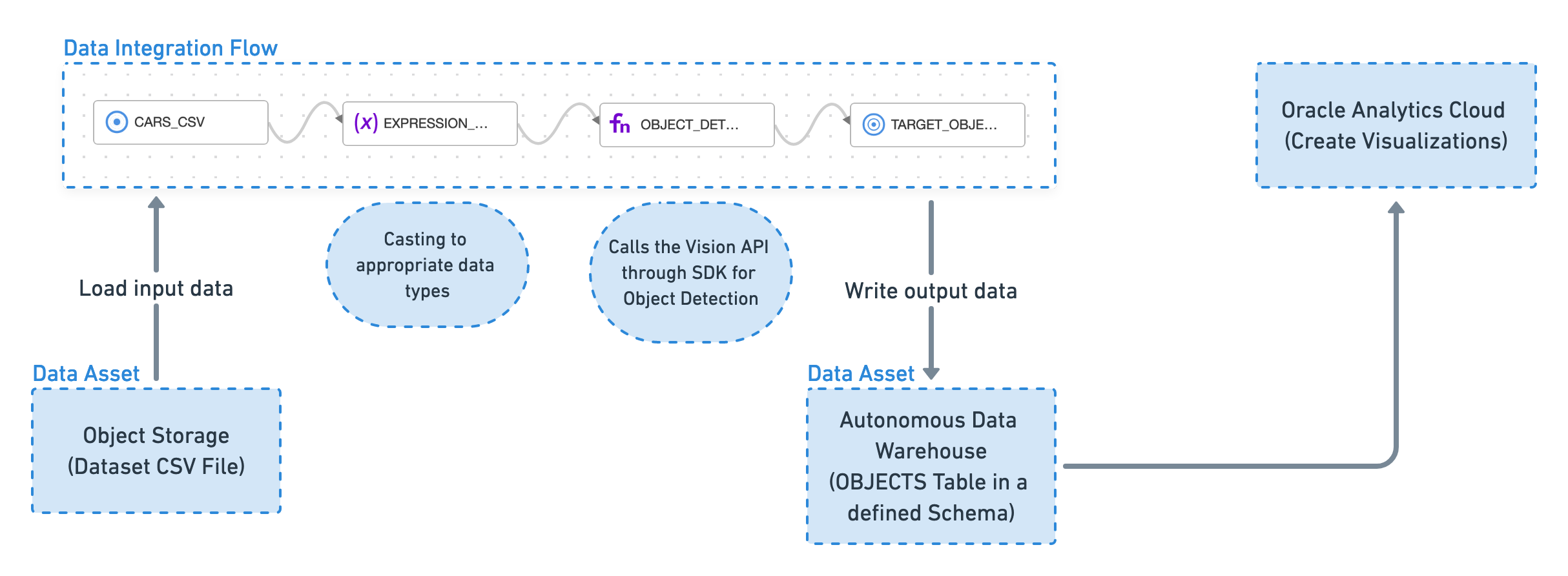
Informazioni preliminari
Per seguire questa esercitazione, è necessario essere in grado di creare reti VCN, funzioni e gateway API e utilizzare Data Integration and Vision.
Parlare con l'amministratore dei criteri richiesti.
Impostazione dei criteri necessari
Attenersi alla procedura riportata di seguito per impostare i criteri necessari.
1. Creare una rete cloud virtuale
Creare una VCN da utilizzare come home per la funzione serverless e il gateway API creato in seguito nell'esercitazione.
1.1 Creazione di una VCN con accesso a Internet
Attenersi alla procedura riportata di seguito per creare una VCN con accesso a Internet.
- Nel menu di navigazione selezionare Networking.
- Seleziona reti cloud virtuali.
- Fare clic su Avvia procedura guidata VCN.
- Selezionare Crea VCN con connettività Internet.
- Selezionare Avvia procedura guidata VCN.
- Immettere un nome per la VCN. Evitare di inserire informazioni riservate.
- Selezionare Successivo.
- Selezionare Crea.
1.2 Accesso alla VCN da Internet
Per consentire il traffico sulla porta 443, è necessario aggiungere una nuova regola di entrata con conservazione dello stato per la subnet regionale pubblica.
Prima di provare a eseguire questo task, completare la 1.1 Creazione di una VCN con accesso a Internet.
Il gateway API comunica sulla porta 443, che non è aperta per impostazione predefinita.
2. Creazione di un gateway API
Un gateway API consente di aggregare tutte le funzioni create in un unico endpoint che può essere utilizzato dagli utenti.
Completare 1. Creare una rete cloud virtuale prima di provare a eseguire questo task.
3. Crea una funzione di integrazione
Attenersi alla procedura riportata di seguito per creare una funzione di arricchimento che può essere richiamata da Oracle Cloud Infrastructure Data Integration.
Crea una funzione serverless che viene eseguita solo su richiesta. La funzione è conforme allo schema richiesto per essere utilizzato da Data Integration. La funzione serverless chiama l'API di Vision tramite Python SDK.
3.1 Creazione di un'applicazione
Per aggiungere una funzione, prima è necessario creare un'applicazione.
Completare 2. Creazione di un gateway API prima di provare a eseguire questo task.
3.2 Creazione di una funzione
Per creare una funzione nell'applicazione, procedere come segue.
Completare la 3.1 Creazione di un'applicazione prima di provare a eseguire questo task.
Il modo più veloce è far sì che il sistema generi un modello Python.
Contenuto consigliato per func.yaml.
schema_version: 20180708
name: object-detection
version: 0.0.1
runtime: python
build_image: fnproject/python:3.8-dev
run_image: fnproject/python:3.8
entrypoint: /python/bin/fdk /function/func.py handler
memory: 256
timeout: 300Contenuto consigliato per requirements.txt.
fdk>=0.1.40
oci
https://objectstorage.us-ashburn-1.oraclecloud.com/n/axhheqi2ofpb/b/vision-oac/o/vision_service_python_client-0.3.9-py2.py3-none-any.whl
pandas
requestsContenuto consigliato per func.py.
import io
import json
import logging
import pandas
import requests
import base64
from io import StringIO
from fdk import response
import oci
from vision_service_python_client.ai_service_vision_client import AIServiceVisionClient
from vision_service_python_client.models.analyze_image_details import AnalyzeImageDetails
from vision_service_python_client.models.image_object_detection_feature import ImageObjectDetectionFeature
from vision_service_python_client.models.inline_image_details import InlineImageDetails
def handler(ctx, data: io.BytesIO=None):
signer = oci.auth.signers.get_resource_principals_signer()
resp = do(signer,data)
return response.Response(
ctx, response_data=resp,
headers={"Content-Type": "application/json"}
)
def vision(dip, txt):
encoded_string = base64.b64encode(requests.get(txt).content)
image_object_detection_feature = ImageObjectDetectionFeature()
image_object_detection_feature.max_results = 5
features = [image_object_detection_feature]
analyze_image_details = AnalyzeImageDetails()
inline_image_details = InlineImageDetails()
inline_image_details.data = encoded_string.decode('utf-8')
analyze_image_details.image = inline_image_details
analyze_image_details.features = features
try:
le = dip.analyze_image(analyze_image_details=analyze_image_details)
except Exception as e:
print(e)
return ""
if le.data.image_objects is not None:
return json.loads(le.data.image_objects.__repr__())
return ""
def do(signer, data):
dip = AIServiceVisionClient(config={}, signer=signer)
body = json.loads(data.getvalue())
input_parameters = body.get("parameters")
col = input_parameters.get("column")
input_data = base64.b64decode(body.get("data")).decode()
df = pandas.read_json(StringIO(input_data), lines=True)
df['enr'] = df.apply(lambda row : vision(dip,row[col]), axis = 1)
#Explode the array of aspects into row per entity
dfe = df.explode('enr',True)
#Add a column for each property we want to return from imageObjects struct
ret=pandas.concat([dfe,pandas.DataFrame((d for idx, d in dfe['enr'].iteritems()))], axis=1)
#Drop array of aspects column
ret = ret.drop(['enr'],axis=1)
#Drop the input text column we don't need to return that (there may be other columns there)
ret = ret.drop([col],axis=1)
if 'name' not in ret.columns:
return pandas.DataFrame(columns=['id','name','confidence','x0','y0','x1','y1','x2','y2','x3','y3']).to_json(orient='records')
for i in range(4):
ret['x' + str(i)] = ret.apply(lambda row: row['bounding_polygon']['normalized_vertices'][i]['x'], axis=1)
ret['y' + str(i)] = ret.apply(lambda row: row['bounding_polygon']['normalized_vertices'][i]['y'], axis=1)
ret = ret.drop(['bounding_polygon'],axis=1)
rstr=ret.to_json(orient='records')
return rstr3.3 Distribuzione della funzione
Distribuire la funzione nell'applicazione
Completare la 3.2 Creazione di una funzione prima di provare a eseguire questo task.
3.4 Richiamo della funzione
Prova la funzione chiamandola.
Completare la 3.3 Distribuzione della funzione prima di provare a eseguire questo task.
{"data":"eyJpZCI6MSwiaW5wdXRUZXh0IjoiaHR0cHM6Ly9pbWFnZS5jbmJjZm0uY29tL2FwaS92MS9pbWFnZS8xMDYxOTYxNzktMTU3MTc2MjczNzc5MnJ0czJycmRlLmpwZyJ9", "parameters":{"column":"inputText"}}{"id":1,"inputText":"https://<server-name>/api/v1/image/106196179-1571762737792rts2rrde.jpg"}echo '{"data":"<data-payload>", "parameters":{"column":"inputText"}}' | fn invoke <application-name> object-detection[{"id":1,"confidence":0.98330873,"name":"Traffic Light","x0":0.0115499255,"y0":0.4916201117,"x1":0.1609538003,"y1":0.4916201117,"x2":0.1609538003,"y2":0.9927374302,"x3":0.0115499255,"y3":0.9927374302},{"id":1,"confidence":0.96953976,"name":"Traffic Light","x0":0.8684798808,"y0":0.1452513966,"x1":1.0,"y1":0.1452513966,"x2":1.0,"y2":0.694972067,"x3":0.8684798808,"y3":0.694972067},{"id":1,"confidence":0.90388376,"name":"Traffic sign","x0":0.4862146051,"y0":0.4122905028,"x1":0.8815201192,"y1":0.4122905028,"x2":0.8815201192,"y2":0.7731843575,"x3":0.4862146051,"y3":0.7731843575},{"id":1,"confidence":0.8278353,"name":"Traffic sign","x0":0.2436661699,"y0":0.5206703911,"x1":0.4225037258,"y1":0.5206703911,"x2":0.4225037258,"y2":0.9184357542,"x3":0.2436661699,"y3":0.9184357542},{"id":1,"confidence":0.73488903,"name":"Window","x0":0.8431445604,"y0":0.730726257,"x1":0.9992548435,"y1":0.730726257,"x2":0.9992548435,"y2":0.9893854749,"x3":0.8431445604,"y3":0.9893854749}]4. Aggiunta di un criterio funzioni
Creare un criterio in modo che la funzione possa essere utilizzata con Vision.
Completare 3. Creare una funzione di integrazione prima di provare a eseguire questo task.
5. Creazione di un'area di lavoro Oracle Cloud Infrastructure Data Integration
Prima di poter utilizzare Data Integration, assicurarsi di disporre dei diritti di utilizzo della funzionalità.
Completare 4. Aggiunta di un criterio delle funzioni prima di eseguire questo task.
Creare i criteri che consentono di utilizzare Data Integration.
6. Aggiunta di criteri di integrazione dei dati
Aggiornare il criterio in modo da poter utilizzare Data Integration.
Completare 5. Creazione di un'area di lavoro di Oracle Cloud Infrastructure Data Integration prima di provare a eseguire questo task.
7. Preparare le origini dati e i lavandini
Si stanno utilizzando le immagini di parcheggio auto insieme alla data in cui le immagini sono state acquisite come dati di esempio.
Raccogliere 10 immagini (o più) di auto parcheggiate come origine dati su cui eseguire l'analisi di rilevamento degli oggetti utilizzando Data Integration e Vision.
7.1 Caricamento dei dati di esempio
Caricare i dati di esempio delle immagini dell'auto parcheggiata nel bucket.
Completare 6. Aggiunta di criteri di integrazione dati prima di provare a eseguire questo task.
-
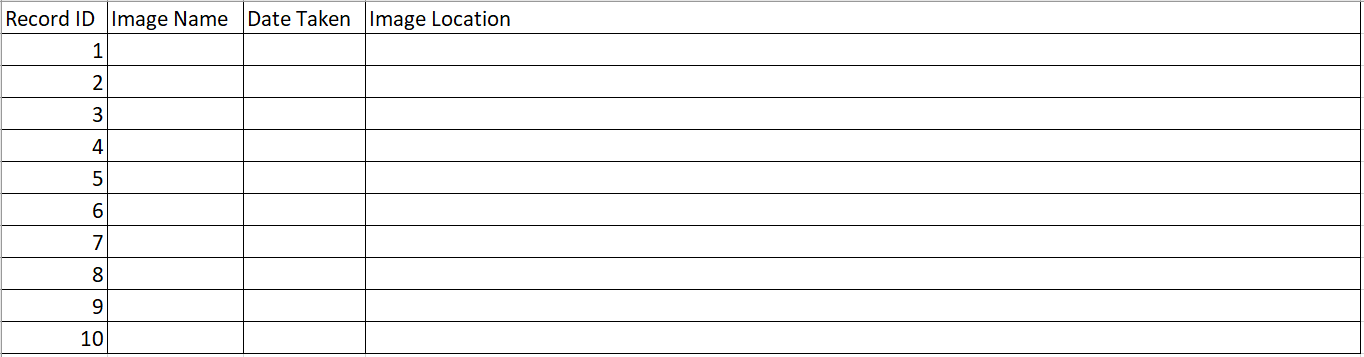
Creare un file CSV con una tabella di quattro colonne e 10 righe. I nomi delle colonne sono ID record, Nome immagine, Data scelta e Posizione immagine. Compilare la colonna ID record da 1 a 10.
File dati di esempio
7.2 Creazione di un bucket temporaneo
In Data Integration è necessaria una posizione di staging in cui eseguire il dump dei file intermedi prima di pubblicare i dati in un data warehouse.
Completare 7.1 Caricamento dei dati di esempio prima di provare a eseguire questo task.
- Nel menu di navigazione della console selezionare Memorizzazione.
- Selezionare Bucket.
- Selezionare Crea bucket.
-
Darle un nome appropriato, ad esempio
data-staging. Evitare di inserire informazioni riservate. - Selezionare Crea.
- Accettare tutti i valori predefiniti.
7.3 Preparazione del database di destinazione
Configurare il database Autonomous Data Warehouse di destinazione per aggiungere uno schema e una tabella.
Completare la 7.2 Creazione di un bucket di staging prima di provare a eseguire questo task.
7.4 Creazione di una tabella per proiettare i dati analizzati
Creare una tabella per memorizzare qualsiasi informazione sugli oggetti rilevati.
Prima di eseguire questo task, completare 7.3 Preparazione del database di destinazione.
8. Uso di un flusso di dati in integrazione dei dati
Creare i componenti necessari per creare un flusso di dati in Data Integration.
Il flusso di dati è: 
Tutte le risorse di storage di base sono state create nei capitoli precedenti. In Data Integration è possibile creare gli asset dati per ciascuno degli elementi del flusso di dati.
8.1 Creazione di un asset dati per l'origine e l'area intermedia
Creare un asset dati per i dati di origine e area intermedia.
Completare 7. Preparare le origini dati e i lavandini prima di provare a eseguire questo task.
8.2 Creazione di un asset dati per la destinazione
Creare un asset dati per il data warehouse di destinazione.
Prima di provare a eseguire questo task, completare la 8.1 Creazione di un asset dati per l'origine e l'area intermedia.
8.3 Creazione di un flusso di dati
Creare un flusso di dati in Data Integration per includere i dati dal file.
Prima di provare a eseguire questo task, completare la 8.2 Creazione di un asset dati per la destinazione.
- Nella pagina dei dettagli del progetto Vision Lab, selezionare Flussi di dati.
- Selezionare Crea flusso dati.
- Nel designer del flusso di dati, selezionare il pannello Proprietà.
-
In Nome, immettere
lab-data-flow. - Selezionare Crea.
8.4 Aggiunta di un'origine dati
A questo punto, aggiungere un'origine dati al flusso di dati.
Completare la 8.3 Creazione di un flusso di dati prima di eseguire questo task.
Dopo aver creato il flusso di dati in 8.3 Creazione di un flusso di dati, il designer rimane aperto ed è possibile aggiungervi un'origine dati mediante i passi riportati di seguito.
8.5 Aggiunta di un'espressione
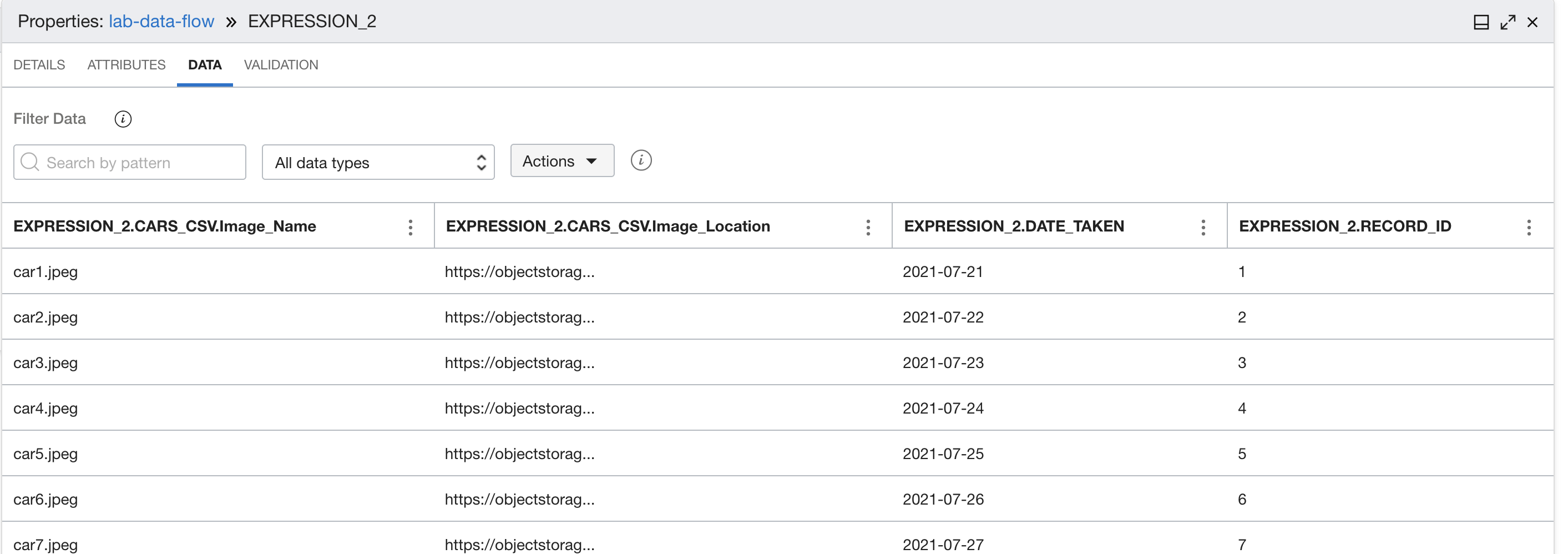
Aggiungere un'espressione per modificare il formato di ID in numero intero e il formato del campo date_taken in una data.
Completare la 8.4 Aggiunta di un'origine dati prima di eseguire questo task.
-
Selezionare la scheda Dati per l'espressione per visualizzare i nuovi campi.
Campi dati
8.6 Aggiunta di una funzione
Aggiungere una funzione al flusso di dati per estrarre oggetti dalle immagini di input.
Completare 8.5 Aggiunta di un'espressione prima di provare a eseguire questo task.
8.7 Mapping dell'output alla tabella Data Warehouse
Mappare l'output dell'analisi delle opinioni alla tabella Data Warehouse.
Prima di eseguire questo task, completare 8.6 Aggiunta di una funzione.
-
Eseguire il mapping dell'output della funzione ai campi corretti nella tabella del database di destinazione. Utilizzare i mapping nella tabella riportata di seguito.
Mapping output funzione Nome Mapping RECORD_ID RECORD_ID IMAGE_NAME Image_Name DATE_TAKEN DATE_TAKEN IMAGE_LOCATION Image_Location OBJECT_NAME nome OBJECT_CONFIDENCE fiducia VERTICE X1 x0 VERTICE Y1 y0 VERTICE X2 x1 VERTICE Y2 y1 VERTICE X3 x2 VERTICE Y3 y2 VERTICE X4 x3 VERTICE Y4 y3 I mapping devono avere il seguente aspetto: Mapping da uno a quattro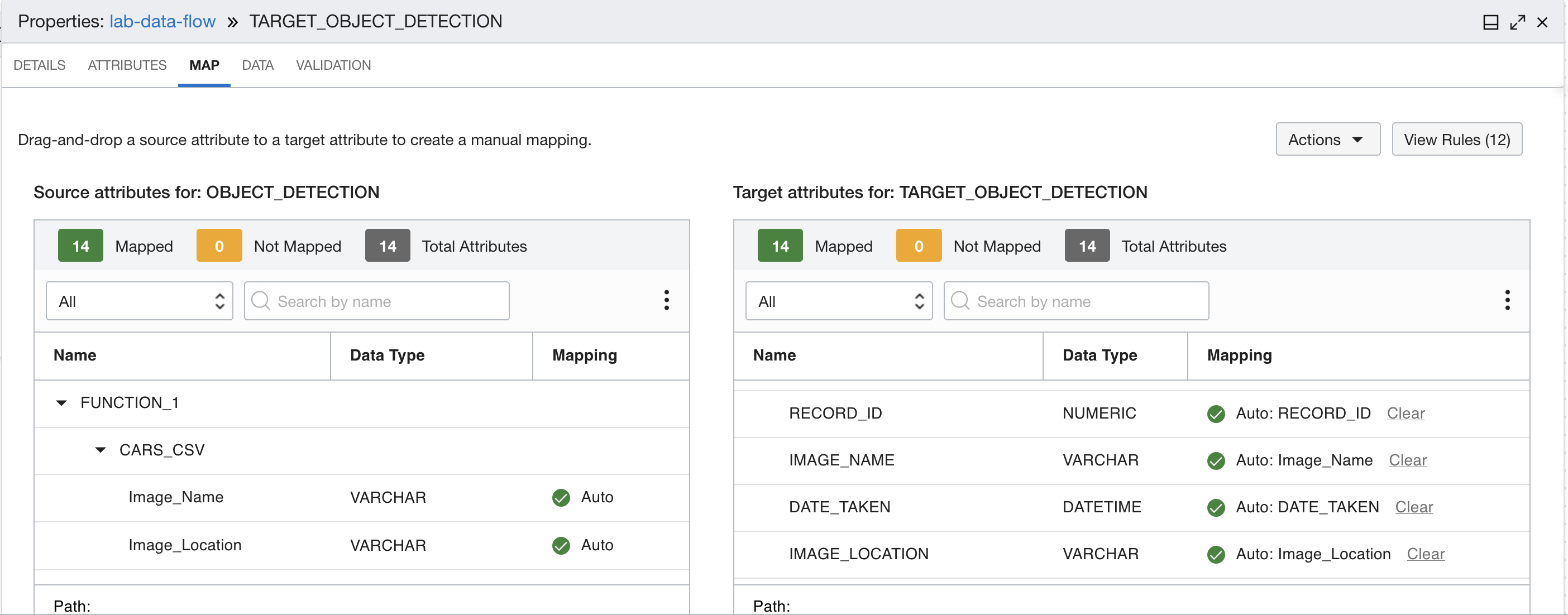 Mapping da cinque a otto
Mapping da cinque a otto 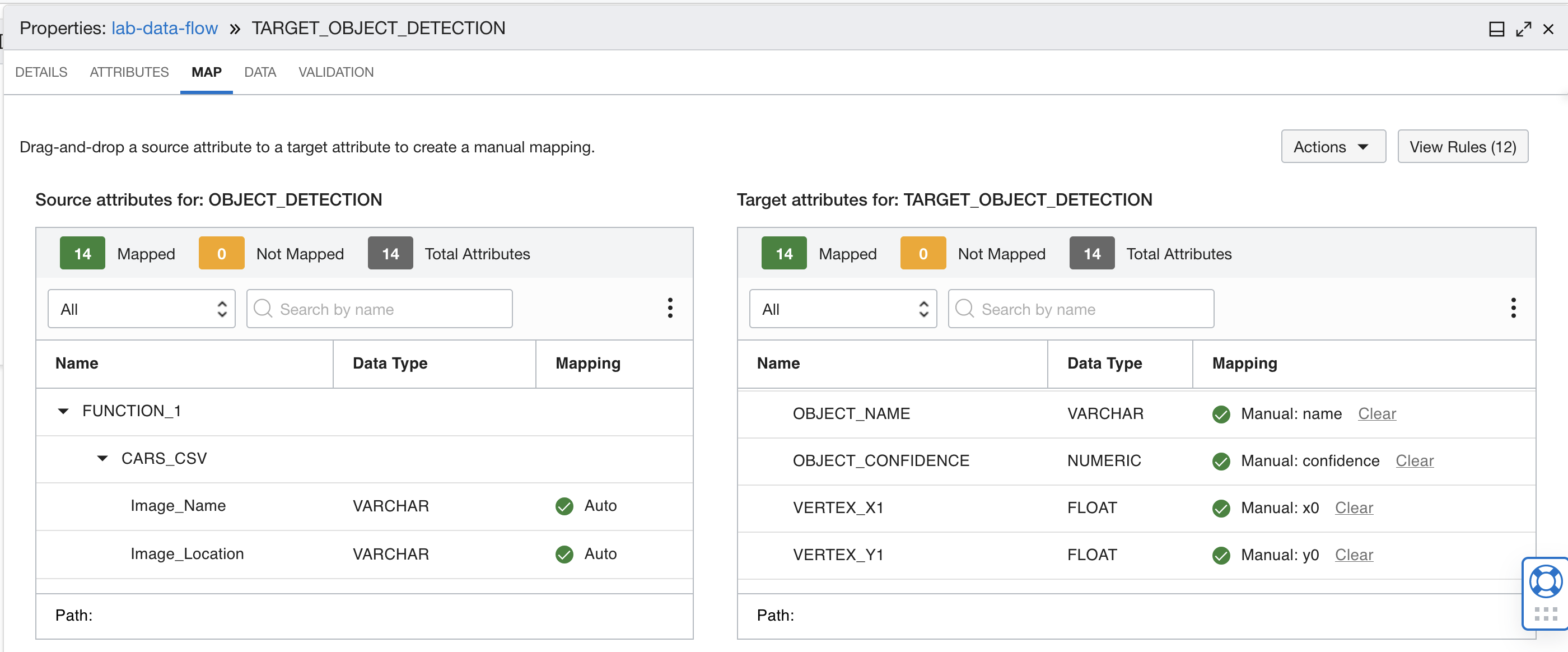 Mapping da nove a dodici
Mapping da nove a dodici 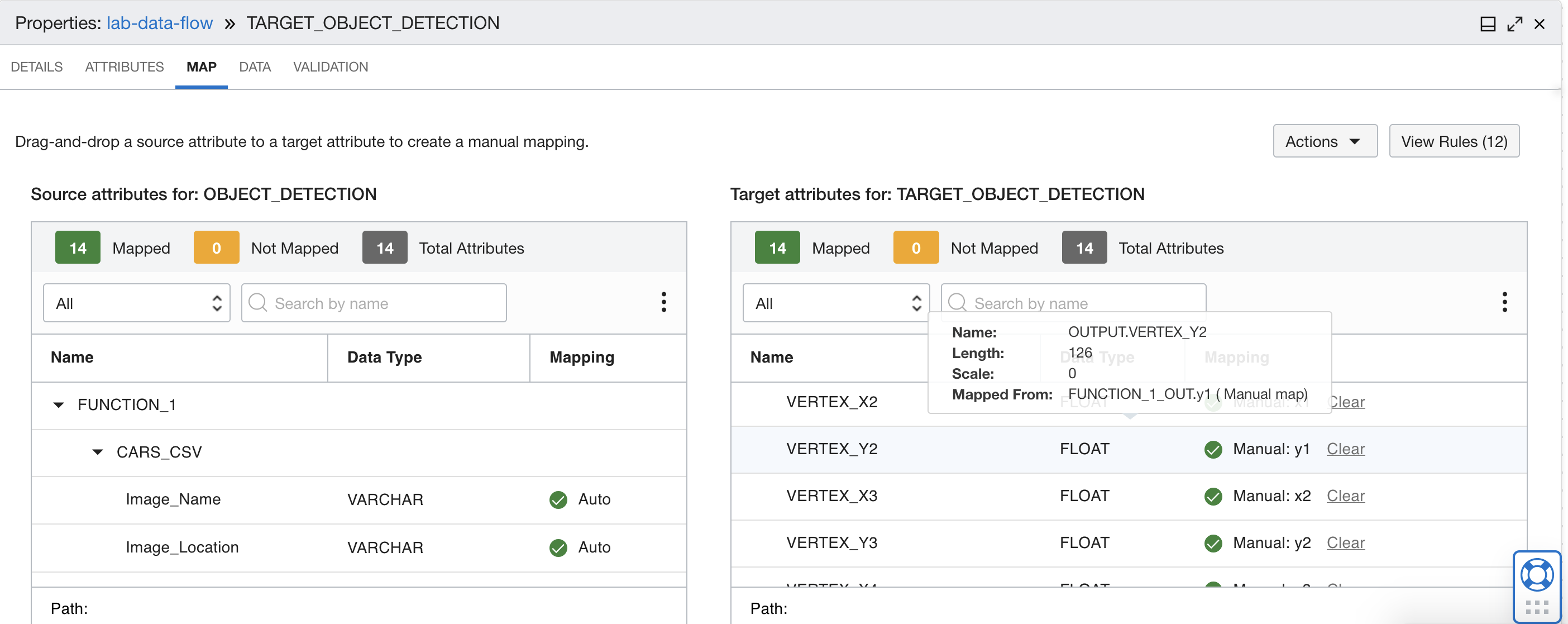 Mapping tredici e quattordici
Mapping tredici e quattordici 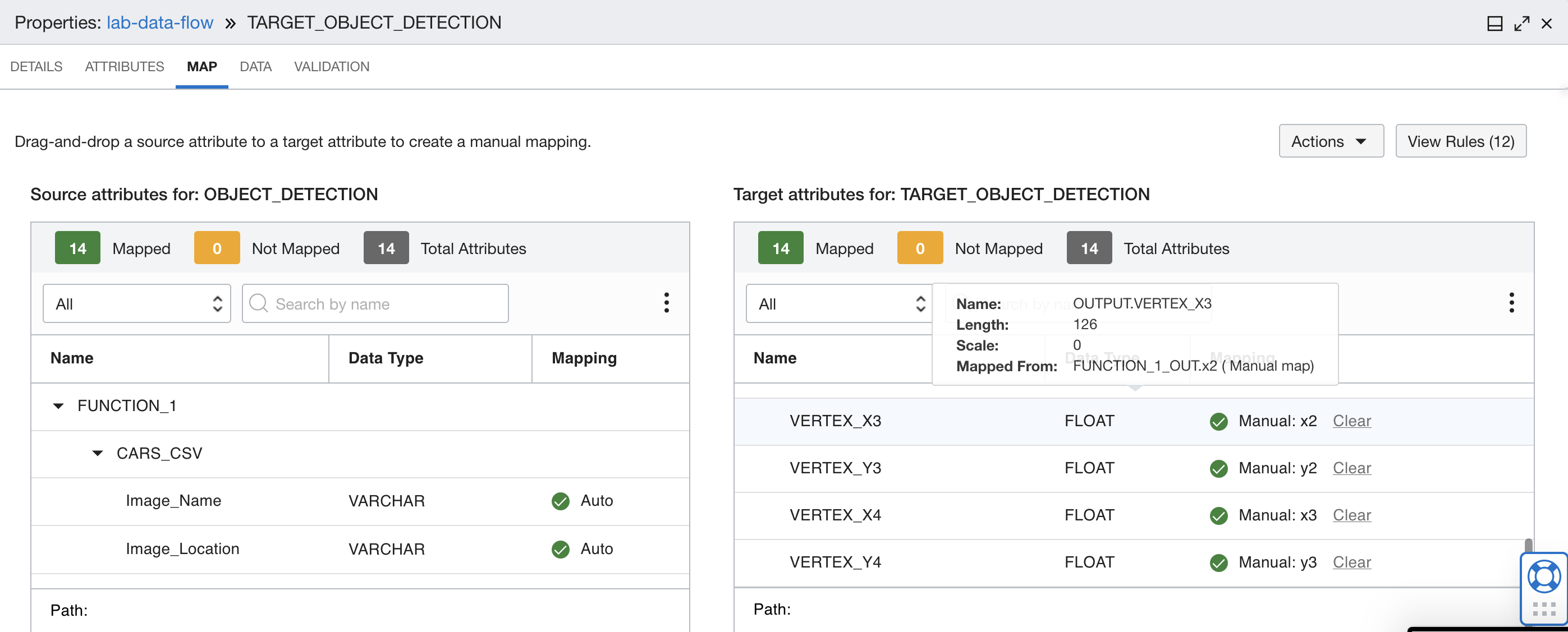
8.8 Esecuzione del flusso di dati
Eseguire il flusso di dati per popolare il database di destinazione.
Prima di eseguire questo task, completare la 8.7 Mapping dell'output alla tabella Data Warehouse.
9. Visualizzare i dati in Analytics Cloud
Visualizzare i dati creati mediante Analytics Cloud.
È necessario accedere ad Analytics Cloud e creare un'istanza di Analytics Cloud.
9.1 Creazione di un'istanza di Analytics Cloud
Attenersi alla procedura riportata di seguito per creare un'istanza di Analytics Cloud.
Completare 8. Prima di eseguire questo task, utilizzare un flusso dati in Data Integration.
- Dal menu di navigazione della console, selezionare Analytics & AI.
- Selezionare Analytics Cloud.
- Selezionare il compartimento,
- Selezionare Crea istanza.
- Immettere un nome. Non inserire informazioni riservate
-
Selezionare
2 OCPUs. Come valori predefiniti vengono mantenuti gli altri parametri di configurazione. - Selezionare Crea.
9.2 Creazione di una connessione al data warehouse
Attenersi alla procedura riportata di seguito per impostare una connessione dall'istanza di Analytics Cloud al data warehouse.
Prima di provare a eseguire questo task, completare la 9.1 Creazione di un'istanza di Analytics Cloud.
9.3 Creazione di un data set
Per creare un set di dati, procedere come segue.
Prima di provare a eseguire questo task, completare la 9.2 Creazione di una connessione al data warehouse.
- Selezionare Dati.
- Selezionare Crea.
- Selezionare Crea un nuovo data set.
- Selezionare il data warehouse.
- Dal database USER1 trascinare la tabella OBJECTS nell'area di creazione.
- Salvare il data set.
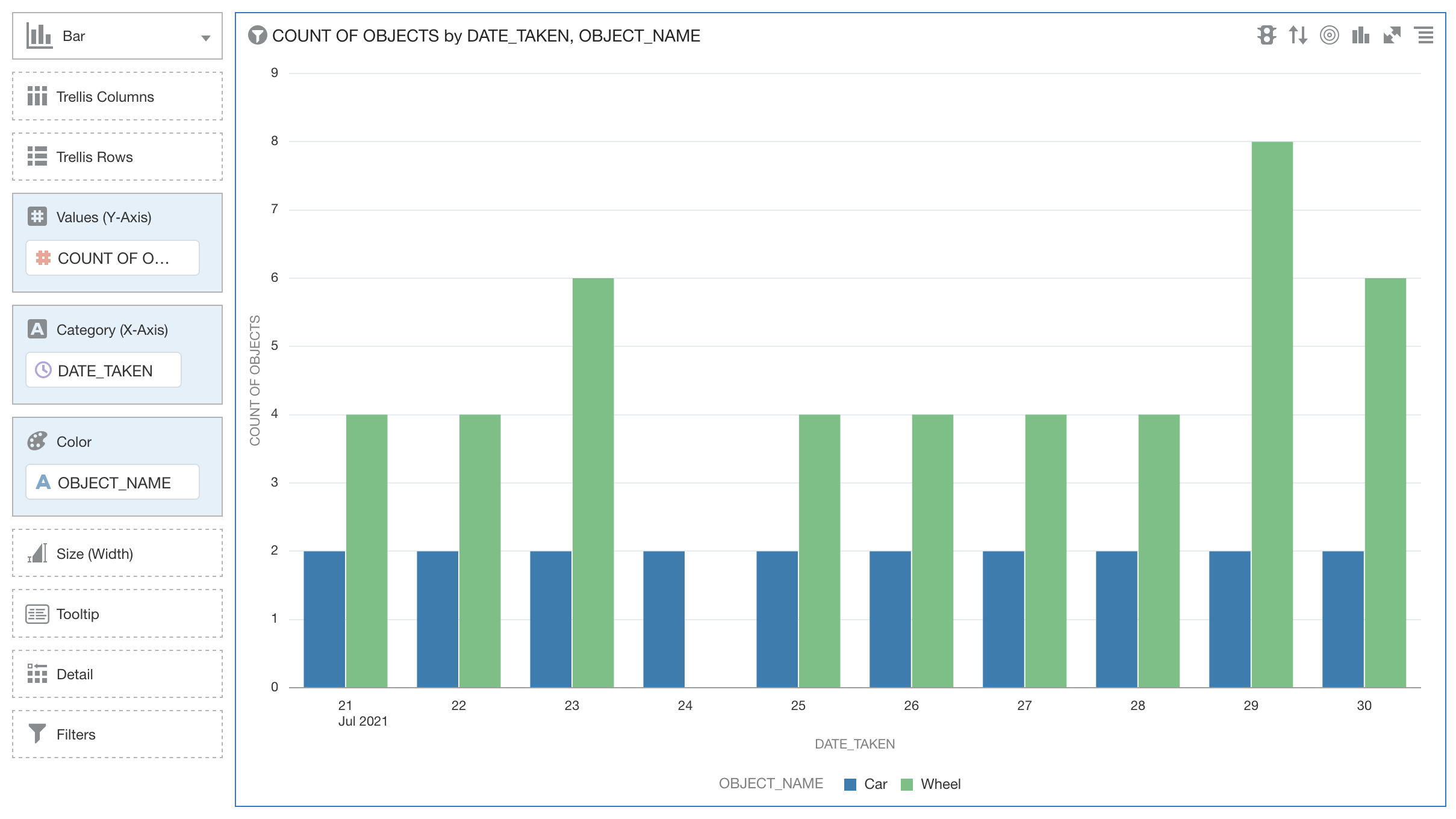
9.4 Creazione di una visualizzazione
Per visualizzare i dati in Analytics Cloud, attenersi alla procedura riportata di seguito.
Completare 9.3 Creazione di un data set prima di provare a eseguire questo task.
-
Per Colore, selezionare OBJECT_NAME.
Viene visualizzato un grafico simile al seguente: