Modelli AI per documenti pre-addestrati
Vision fornisce modelli AI di documenti pre-addestrati che consentono di organizzare ed estrarre testo e struttura dai documenti aziendali.
Le funzionalità AnalyzeDocument e DocumentJob di Vision stanno passando a un nuovo servizio, Document Understanding. Di seguito sono riportate le funzioni interessate.
- Rilevamento delle tabelle
- Classificazione dei documenti
- Estrazione chiave-valore incasso
- OCR documento
Casi d'uso
I modelli AI di documenti pre-addestrati ti consentono di automatizzare le operazioni di back-office ed elaborare le ricevute in modo più accurato.
- Ricerca intelligente
- Arricchisci i file basati su immagini con metadati, inclusi il tipo di documento e i campi chiave, per un recupero più semplice.
- Reporting spese
- Estrai le informazioni richieste dagli incassi per automatizzare i flussi di lavoro aziendali. Ad esempio, le note spese dei dipendenti, la conformità delle spese e il rimborso.
- Elaborazione NLP (Natural Language Processing) a valle
- Estrai il testo dai file PDF e organizzalo come input per l'NLP, in tabelle o in parole e righe.
- Acquisizione punti fedeltà
- Automatizza i calcoli dei punti fedeltà dalle ricevute, in base al numero di articoli o all'importo totale pagato.
Formati supportati:
Vision supporta diversi formati di documento.
- JPEG
- PNG
- TIFF
Modelli pre-addestrati
Vision ha cinque tipi di modello pre-addestrato.
riconoscimento ottico dei caratteri (OCR)
Vision è in grado di rilevare e riconoscere il testo in un documento. La classificazione della lingua identifica la lingua di un documento, quindi OCR disegna caselle di delimitazione attorno al testo stampato o scritto a mano che trova in un'immagine e digitalizza il testo.
Se si dispone di un PDF con testo, Vision trova il testo in tale documento ed estrae il testo. Vengono quindi fornite caselle di delimitazione per il testo identificato. Il rilevamento del testo può essere utilizzato con i modelli AI documento o Analisi immagine.
Vision fornisce un punteggio di affidabilità per ogni raggruppamento di testo. Il punteggio di affidabilità è un numero decimale. I punteggi più vicini a 1 indicano una maggiore fiducia nel testo estratto, mentre i punteggi più bassi indicano un punteggio di affidabilità più basso. L'intervallo del punteggio di affidabilità per ogni etichetta è compreso tra 0 e 1.
Il supporto OCR è limitato all'inglese. Se si sa che il testo nelle immagini è in inglese, impostare la lingua su
Eng.- Estrazione parola
- Estrazione righe di testo
- Punteggio affidabilità
- Polighi di delimitazione
- Richiesta singola
- Richiesta batch
- Sebbene la classificazione delle lingue identifichi diverse lingue, l'OCR è limitato all'inglese.
Esempio di utilizzo di OCR in Vision.
- Documento di input
-
Input OCR

.{ "analyzeDocumentDetails": { "compartmentId": "", "document": { "namespaceName": "", "bucketName": "", "objectName": "", "source": "OBJECT_STORAGE" }, "features": [ { "featureType": "TEXT_DETECTION" }, { "featureType": "LANGUAGE_CLASSIFICATION", "maxResults": 5 } ] } } - output:
- Output OCR
 Risposta API:
Risposta API: { "documentMetadata": { "pageCount": 1, "mimeType": "image/jpeg" }, "pages": [ { "pageNumber": 1, "dimensions": { "width": 361, "height": 600, "unit": "PIXEL" }, "detectedLanguages": [ { "languageCode": "ENG", "confidence": 0.9999994 }, { "languageCode": "ARA", "confidence": 4.7619238e-7 }, { "languageCode": "NLD", "confidence": 7.2325456e-8 }, { "languageCode": "CHI_SIM", "confidence": 3.0645523e-8 }, { "languageCode": "ITA", "confidence": 8.6900076e-10 } ], "words": [ { "text": "Example", "confidence": 0.99908227, "boundingPolygon": { "normalizedVertices": [ { "x": 0.0664819944598338, "y": 0.011666666666666667 }, { "x": 0.22160664819944598, "y": 0.011666666666666667 }, { "x": 0.22160664819944598, "y": 0.035 }, { "x": 0.0664819944598338, "y": 0.035 } ] } ... "detectedLanguages": [ { "languageCode": "ENG", "confidence": 0.9999994 } ], ...
Classificazione documento
La classificazione del documento può essere utilizzata per classificare un documento.
- Fattura
- Ricevuta
- CV o curriculum vitae
- Modulo fiscale
- Patente di guida
- Passport
- Dichiarazione bancaria
- Seleziona
- Cedolino
- Altro
- Classifica documento
- Punteggio affidabilità
- Richiesta singola
- Richiesta batch
Esempio di classificazione dei documenti utilizzato in Vision.
- Documento di input
- Input classificazione documento
- output:
- Risposta API:
{ "documentMetadata": { "pageCount": 1, "mimeType": "image/jpeg" }, "pages": [ { "pageNumber": 1, "dimensions": { "width": 361, "height": 600, "unit": "PIXEL" }, "detectedDocumentTypes": [ { "documentType": "RECEIPT", "confidence": 1 }, { "documentType": "TAX_FORM", "confidence": 6.465067e-9 }, { "documentType": "CHECK", "confidence": 6.031838e-9 }, { "documentType": "BANK_STATEMENT", "confidence": 5.413888e-9 }, { "documentType": "PASSPORT", "confidence": 1.5554872e-9 } ], ... detectedDocumentTypes": [ { "documentType": "RECEIPT", "confidence": 1 } ], ...
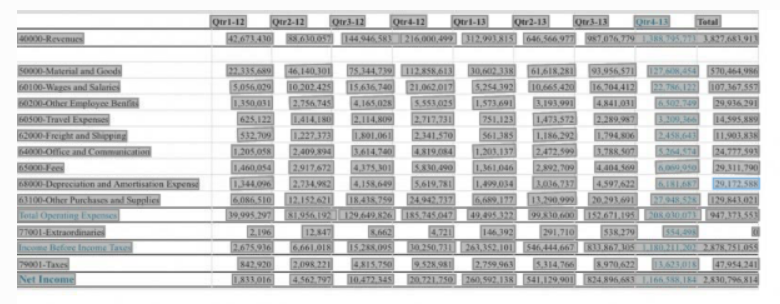
Estrazione tabelle
L'estrazione della tabella può essere utilizzata per identificare le tabelle in un documento ed estrarne il contenuto. Ad esempio, se una ricevuta PDF contiene una tabella che include le imposte e l'importo totale, Vision identifica la tabella ed estrae la struttura della tabella.
Vision fornisce il numero di righe e colonne per la tabella e il contenuto di ogni cella della tabella. Ogni cella ha un punteggio di affidabilità. Il punteggio di affidabilità è un numero decimale. I punteggi più vicini a 1 indicano una maggiore fiducia nel testo estratto, mentre i punteggi più bassi indicano un punteggio di affidabilità più basso. L'intervallo del punteggio di affidabilità per ogni etichetta è compreso tra 0 e 1.
- Estrazione tabella per tabelle con e senza bordi
- Polighi di delimitazione
- Punteggio affidabilità
- Richiesta singola
- Richiesta batch
- Solo lingua inglese
Esempio di utilizzo dell'estrazione tabella in Vision.
- Documento di input
- Input estrazione tabella

- output:
- Output estrazione tabella
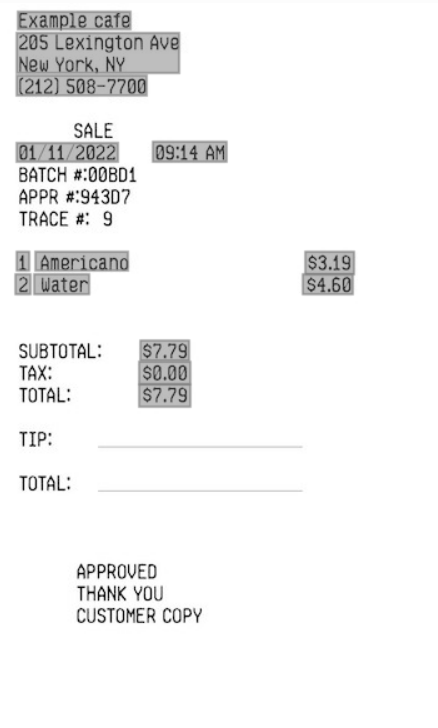
Estrazione valore chiave (incassi)
L'estrazione dei valori chiave può essere utilizzata per identificare i valori delle chiavi predefinite in una ricevuta. Ad esempio, se una ricevuta include un nome commerciante, un indirizzo commerciante o un numero di telefono commerciante, Vision può identificare questi valori e restituirli come coppia di valori chiave.
- Estrai valori per coppie di valori chiave predefinite
- Polighi di delimitazione
- Richiesta singola
- Richiesta batch
- Supporta le ricevute solo in inglese.
- MerchantName
- Nome del commerciante che emette l'incasso.
- MerchantPhoneNumber
- Numero di telefono del commerciante.
- MerchantAddress
- L'indirizzo del commerciante.
- TransactionDate
- La data di emissione della ricevuta.
- TransactionTime
- L'ora di emissione della ricevuta.
- Totale
- Importo totale dell'incasso, dopo l'applicazione di tutti gli addebiti e le imposte.
- Totale parziale
- Totale parziale al lordo delle imposte.
- Tax
- Eventuali imposte sulle vendite.
- Suggerimento
- L'importo della mancia dato dall'acquirente.
- ItemName
- Nome dell'articolo.
- ItemPrice
- Prezzo unitario dell'articolo.
- ItemQuantity
- Numero di articoli acquistati.
- ItemTotalPrice
- Prezzo totale della voce riga.
Esempio di utilizzo dell'estrazione dei valori chiave in Vision.
- Documento di input
- Input estrazione valore chiave (ricezioni)
- output:
- Output estrazione valore chiave (incassi)
Riconoscimento ottico caratteri (OCR) - PDF
OCR PDF genera un file PDF ricercabile nello storage degli oggetti. Ad esempio, Vision può acquisire un file PDF con testo e immagini e restituire un file PDF in cui è possibile cercare il testo nel PDF.
- Genera PDF ricercabile
- Richiesta singola
- Richiesta batch
Esempio di utilizzo del PDF OCR in Vision.
- Input
-
Richiesta API input ODF OCR
 :
:{ "analyzeDocumentDetails": { "compartmentId": "", "document": { "source": "INLINE", "data": "......" }, "features": [ { "featureType": "TEXT_DETECTION", "generateSearchablePdf": true } ] } } - output:
- PDF ricercabile.
Uso di modelli AI per i documenti predefiniti
Vision fornisce ai clienti modelli pre-addestrati per estrarre insight sui loro documenti senza dover ricorrere ai data scientist.
Prima di utilizzare un modello pre-addestrato, è necessario eseguire le operazioni riportate di seguito.
-
Account tenancy a pagamento in Oracle Cloud Infrastructure.
-
Familiarità con Oracle Cloud Infrastructure Object Storage.
Puoi chiamare i modelli AI dei documenti pre-addestrati come richiesta batch utilizzando le API Rest, l'SDK o l'interfaccia CLI. Puoi chiamare i modelli AI dei documenti pre-addestrati come una singola richiesta utilizzando la console, le API Rest, l'SDK o l'interfaccia CLI.
Per informazioni sugli elementi consentiti nelle richieste batch, vedere la sezione Limiti.