Esempio di topologie GoldenGate OCI
Prima di creare le distribuzioni OCI GoldenGate, esaminare queste topologie di esempio per pianificare il numero di risorse di cui la soluzione ha bisogno.
Di quante risorse ho bisogno?
Distribuzioni
Per determinare il numero di implementazioni di cui la soluzione ha bisogno, considera i tipi di tecnologie tra cui stai replicando i dati.
Ad esempio, se i database di origine e di destinazione sono database AI autonomi, è necessario un solo tipo di distribuzione Oracle.

Descrizione dell'illustrazione atp-adw.png
Vedere Replica dati tra database cloud nella stessa area.
Se stai replicando i dati tra due tecnologie diverse, hai bisogno di due implementazioni OCI GoldenGate. Ad esempio, se il database di origine è di tipo MySQL e la destinazione è di tipo Big Data, è necessario:
-
Crea una distribuzione MySQL per l'origine MySQL
-
Creare una distribuzione Big Data per la destinazione Big Data
Questa soluzione richiede anche un percorso di distribuzione. Per informazioni dettagliate, vedere gli esempi seguenti.
connessioni
È necessario creare una connessione per ogni tecnologia di origine e di destinazione, quindi assegnare le connessioni alla distribuzione appropriata. Utilizzando l'esempio da MySQL a Big Data, è necessario:
-
Creare una connessione al database MySQL di origine, quindi assegnarla alla distribuzione MySQL
-
Creare una connessione alla tecnologia Big Data di destinazione, quindi assegnarla alla distribuzione Big Data
Esempio: Azure SQL Managed Instance to Autonomous AI Transaction Processing
In questo esempio, Azure SQL Managed Instance è la tecnologia di origine e Autonomous AI Transaction Processing (ATP) è la destinazione.
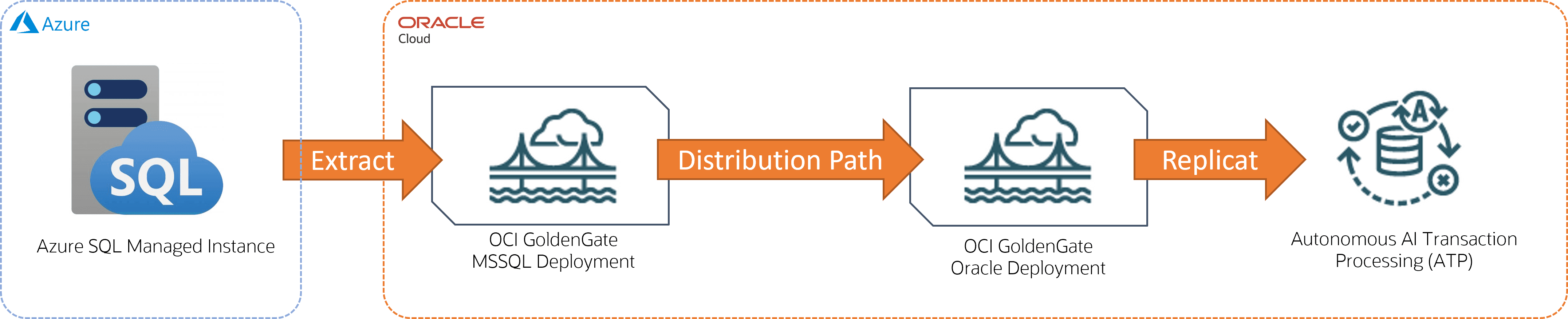
Descrizione dell'illustrazione azure-atp.png
Per questo scenario di replica è necessario:
-
Due implementazioni:
-
Distribuzione di Microsoft SQL Server per il database di origine
-
Distribuzione Oracle per il database di destinazione
-
-
Connessioni:
-
Connessione all'istanza gestita SQL di Azure, quindi assegnata alla distribuzione di Microsoft SQL Server
-
Connessione a Autonomous AI Transaction Processing, quindi assegnata alla distribuzione Oracle
-
-
Processi:
-
Processo di estrazione creato nella distribuzione di origine
-
Percorso di distribuzione creato nella distribuzione di origine
-
Replicat creato nella distribuzione di destinazione
-
Questo scenario di replica è disponibile come avvio rapido.
Esempio: Autonomous AI Transaction Processing to Apache Kafka
In questo esempio, Autonomous AI Transaction Processing (ATP) è la tecnologia di origine e Apache Kafka è la destinazione.
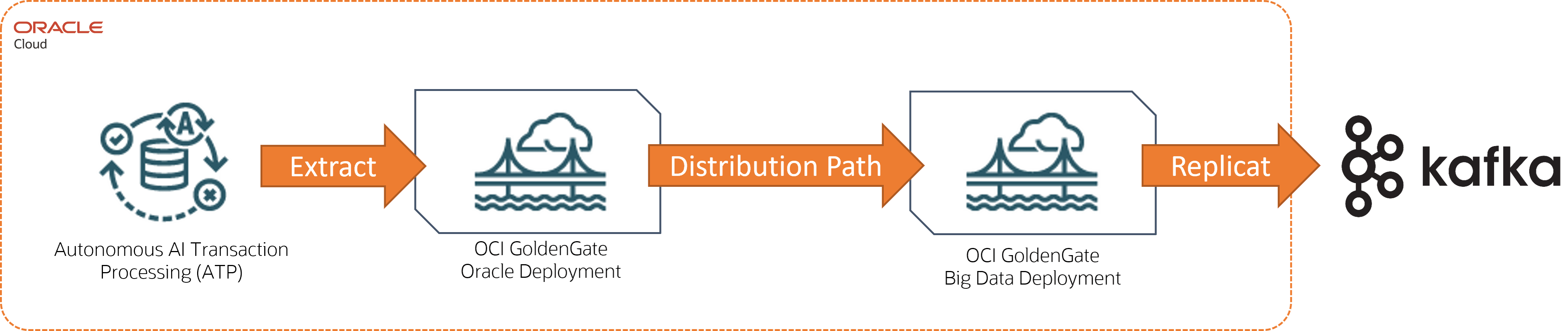
Descrizione dell'illustrazione atp-kafka.png
Per questo scenario di replica è necessario:
-
Due implementazioni:
-
Distribuzione Oracle per il database di origine
-
Implementazione di Big Data per la tecnologia di destinazione
-
-
Connessioni:
-
Connessione a Autonomous AI Transaction Processing, quindi assegnata alla distribuzione Oracle
-
Connessione ad Apache Kafka, quindi assegnata alla distribuzione Big Data
-
-
Processi:
-
Processo di estrazione creato nella distribuzione di origine
-
Percorso di distribuzione creato nella distribuzione di origine
-
Replicat creato nella distribuzione di destinazione
-
Questo scenario di replica è disponibile come avvio rapido.
Esempio: da PostgreSQL a Autonomous AI Transaction Processing
In questo esempio, PostgreSQL è la tecnologia di origine e Autonomous AI Transaction Processing (ATP) è la destinazione.

Descrizione dell'illustrazione postgres-atp.png
Per questo scenario di replica è necessario:
-
Due implementazioni:
-
Una distribuzione PostgresSQL per il database di origine
-
Una distribuzione Oracle per la tecnologia di destinazione
-
-
Connessioni:
-
Connessione a PostgreSQL, quindi assegnata alla distribuzione PostgreSQL
-
Connessione a Autonomous AI Transaction Processing, quindi assegnata alla distribuzione Oracle
-
-
Processi:
-
Processo di estrazione creato nella distribuzione di origine
-
Percorso di distribuzione creato nella distribuzione di origine
-
Replicat creato nella distribuzione di destinazione
-
Questo scenario di replica è disponibile come avvio rapido.
Esempio: da PostgreSQL a MySQL
In questo esempio, PostgreSQL è la tecnologia di origine e MySQL è la destinazione.

Descrizione dell'illustrazione postgres-mysql.png
Per questo scenario di replica è necessario:
-
Due implementazioni:
-
Una distribuzione PostgresSQL per il database di origine
-
Una distribuzione MySQL per la tecnologia di destinazione
-
-
Connessioni:
-
Connessione a PostgreSQL, quindi assegnata alla distribuzione PostgreSQL
-
Una connessione a MySQL, quindi assegnata alla distribuzione MySQL
-
-
Processi:
-
Processo di estrazione creato nella distribuzione di origine
-
Percorso di distribuzione creato nella distribuzione di origine
-
Replicat creato nella distribuzione di destinazione
-
Questo scenario di replica è disponibile come avvio rapido.
Da PostgreSQL a Snowflake
In questo esempio, PostgreSQL è la tecnologia di origine e Snowflake è la destinazione.
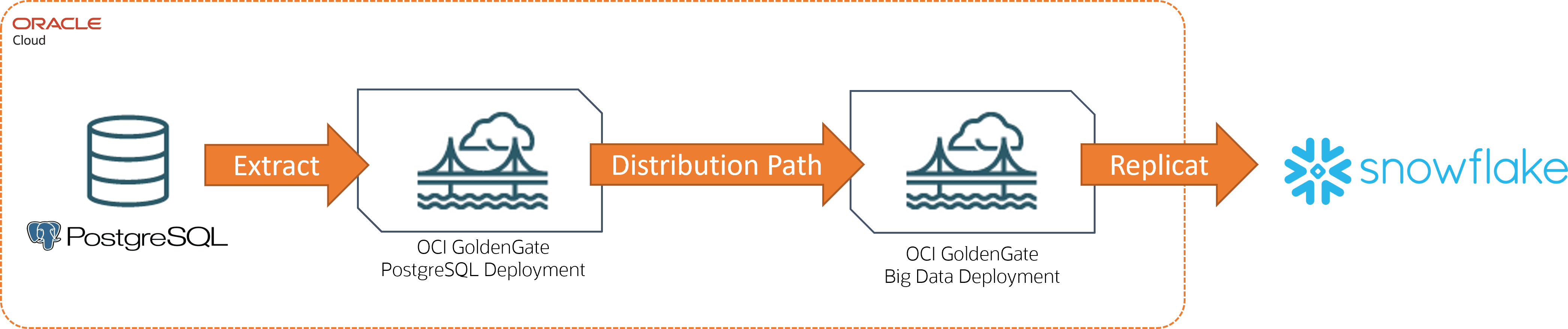
Descrizione dell'illustrazione postgres-snowflake.png
Per questo scenario di replica è necessario:
-
Due implementazioni:
-
Una distribuzione PostgresSQL per il database di origine
-
Implementazione di Big Data per la tecnologia di destinazione
-
-
Connessioni:
-
Connessione a PostgreSQL, quindi assegnata alla distribuzione PostgreSQL
-
Connessione a Snowflake, quindi assegnata alla distribuzione dei Big Data
-
-
Processi:
-
Processo di estrazione creato nella distribuzione di origine
-
Percorso di distribuzione creato nella distribuzione di origine
-
Replicat creato nella distribuzione di destinazione
-
Questo scenario di replica è disponibile come avvio rapido.