Progettazione di una tabella in Oracle NoSQL Database Cloud Service
Scopri come progettare e configurare le tabelle in Oracle NoSQL Database Cloud Service.
Questo articolo contiene i seguenti argomenti:
Campi tabella
Scopri come progettare e configurare i dati utilizzando i campi tabella.
Un'applicazione può scegliere di utilizzare tabelle senza schema, in cui una riga è costituita da campi chiave e un singolo campo dati JSON. Una tabella senza schema offre flessibilità in ciò che può essere memorizzato in una riga.
In alternativa, l'applicazione può scegliere di utilizzare tabelle di schema fisso, in cui tutti i campi della tabella sono definiti come tipi specifici.
Le tabelle dello schema fisso con dati digitati sono più sicure da utilizzare dal punto di vista dell'applicazione e dell'efficienza dello storage. Anche se è possibile modificare lo schema delle tabelle di schema fisso, la loro struttura di tabella non può essere facilmente modificata. Una tabella senza schema è flessibile e la struttura della tabella può essere facilmente modificata.
Infine, un'applicazione può anche utilizzare un approccio modello dati ibrido in cui una tabella può avere dati digitati e campi dati JSON.
Gli esempi riportati di seguito illustrano come progettare e configurare i dati per tutti e tre gli approcci.
Esempio 1: progettazione di una tabella Schemaless
Sono disponibili più opzioni per memorizzare le informazioni sui pattern di navigazione nella tabella. Un'opzione consiste nel definire una tabella che utilizza un ID cookie come chiave e mantiene i dati di segmentazione dell'audience come un singolo campo JSON.
// schema less, data is stored in a JSON field
CREATE TABLE audience_info (
cookie_id LONG,
audience_data JSON,
PRIMARY KEY(cookie_id))In questo caso, la tabella audience_info può contenere un oggetto JSON, ad esempio:
{
"cookie_id": "",
"audience_data": {
"ipaddr" : "
10.0.00.xxx",
"audience_segment: {
"sports_lover" : "2018-11-30",
"book_reader" : "2018-12-01"
}
}
}L'applicazione avrà un campo chiave e un campo dati per questa tabella. Hai la flessibilità di ciò che hai scelto di memorizzare come informazioni nel tuo campo audience_data. Pertanto, è possibile modificare facilmente i tipi di informazioni disponibili.
Esempio 2: progettazione di una tabella di schema fissa
È possibile memorizzare informazioni sui pattern di navigazione creando la tabella con campi dichiarati in modo più esplicito:
// fixed schema, data is stored in typed fields.
CREATE TABLE audience_info(
cookie_id LONG,
ipaddr STRING,
audience_segment RECORD(sports_lover TIMESTAMP(9),
book_reader TIMESTAMP(9)),
PRIMARY KEY(cookie_id))In questo esempio, la tabella contiene un campo chiave e due campi dati. I tuoi dati sono più compatti e puoi garantire che tutti i campi di dati siano accurati.
Esempio 3: progettazione di una tabella ibrida
È possibile memorizzare informazioni sui pattern di navigazione utilizzando i campi di dati digitati e JSON nella tabella.
// mixed, data is stored in both typed and JSON fields.
CREATE TABLE audience_info (
cookie_id LONG,
ipaddr STRING,
audience_segment JSON,
PRIMARY KEY(cookie_id))Chiavi primarie e chiavi delle partizioni
Scopri lo scopo delle chiavi primarie e delle chiavi partizione durante la progettazione dell'applicazione.
Le chiavi primarie e le chiavi di partizione sono elementi importanti dello schema e consentono di accedere e distribuire i dati in modo efficiente. Le chiavi primarie e le chiavi di partizione vengono create solo quando si crea una tabella. Rimangono in posizione per la vita del tavolo e non possono essere cambiati o eliminati.
Chiavi primarie
Quando si crea la tabella, è necessario designare una o più colonne chiave primaria. Una chiave primaria identifica in modo univoco ogni riga della tabella. Per semplici operazioni CRUD, Oracle NoSQL Database Cloud Service utilizza la chiave primaria per recuperare una riga specifica da leggere o modificare. Ad esempio, si consideri che una tabella contiene i seguenti campi:
-
productName -
productType -
productLine
Per esperienza, si sa che il nome del prodotto è importante e univoco per ogni riga, quindi si imposta productName come chiave primaria. Quindi, è possibile recuperare le righe di interesse in base a productName. In tal caso, utilizzare un'istruzione come questa per definire la tabella.
/* Create a new table called users. */
CREATE TABLE if not exists myProducts
(
productName STRING,
productType STRING,
productLine INTEGER,
PRIMARY KEY (productName)
)"Chiavi partizione
Lo scopo principale delle chiavi delle partizioni è quello di distribuire i dati nel cluster Oracle NoSQL Database Cloud Service per una maggiore efficienza e di posizionare i record che condividono localmente la chiave delle partizioni per un facile riferimento e accesso. I record che condividono la chiave di partizione vengono memorizzati nella stessa posizione fisica e sono accessibili in modo atomico ed efficiente.
La progettazione delle chiavi principale e shard ha implicazioni sulla scalabilità e sul raggiungimento del throughput di cui è stato eseguito il provisioning. Ad esempio, quando i record condividono le chiavi partizione, è possibile eliminare più righe di tabella in un'operazione atomica o recuperare un subset di righe nella tabella in un'unica operazione atomica. Oltre a consentire la scalabilità, le chiavi delle partizioni ben progettate possono migliorare le prestazioni richiedendo meno cicli per inserire i dati o ottenere i dati da una singola partizione.
Si supponga, ad esempio, di designare tre campi chiave primaria:
PRIMARY KEY (productName, productType, productLine)Poiché l'applicazione esegue frequentemente query utilizzando le colonne productName e productType, è opportuno specificare tali campi come chiavi partizione. La designazione della chiave della partizione garantisce che tutte le righe di queste due colonne siano memorizzate nella stessa partizione. Se questi due campi non sono chiavi di partizione, le colonne interrogate più di frequente potrebbero essere memorizzate in qualsiasi partizione. Quindi, l'individuazione di tutte le righe per entrambi i campi richiede la scansione di tutto lo storage dei dati, anziché di una partizione.
Le chiavi delle partizioni designano lo storage sulla stessa partizione per facilitare query efficienti per i valori delle chiavi. Tuttavia, poiché si desidera che i dati vengano distribuiti tra le partizioni per ottenere prestazioni ottimali, è necessario evitare chiavi di partizione con pochi valori univoci.
Nota: se non si designano le chiavi partizione durante la creazione di una tabella, Oracle NoSQL Database Cloud Service utilizza le chiavi primarie per l'organizzazione delle partizioni.
Fattori importanti da considerare quando si sceglie una chiave partizione
-
Cardinalità: i campi con cardinalità bassa, ad esempio il paese di origine di un utente, raggruppano i record in alcune partizioni. A loro volta, tali partizioni richiedono un ribilanciamento frequente dei dati, aumentando la probabilità di problemi di partizione a caldo. Invece, ogni chiave di partizione dovrebbe avere una cardinalità elevata, in cui la chiave di partizione può esprimere una fetta uniforme di record nel set di dati. Ad esempio, i numeri di identità come
customerID,userIDoproductIDsono validi candidati per una chiave partizione. -
Atomicità: solo gli oggetti che condividono la chiave partizione possono partecipare a una transazione. Se sono necessarie transazioni ACID che si estendono su più record, scegliere una chiave partizione che consenta di soddisfare tale requisito.
Quali sono le procedure consigliate da seguire?
-
Distribuzione uniforme delle chiavi di partizione: quando le chiavi di partizione sono distribuite in modo uniforme, nessuna singola partizione limita la capacità del sistema.
-
Isolamento delle query: le query devono essere indirizzate a una partizione specifica per massimizzare l'efficienza e le prestazioni. Se le query non vengono isolate in una singola partizione, la query viene applicata a tutte le partizioni meno efficienti e aumenta la latenza delle query.
Vedere Creazione di tabelle per informazioni su come assegnare chiavi primarie e partizioni utilizzando l'oggetto TableRequest.
Tempo TTL
Scopri come specificare le ore di scadenza per tabelle e righe utilizzando la funzione Time-to-Live (TTL).
Molte applicazioni gestiscono dati con una durata utile limitata. Time-to-Live (TTL) è un meccanismo che consente di impostare un intervallo di tempo sulle righe della tabella, dopo il quale le righe scadono automaticamente e non sono più disponibili. Indica il periodo di tempo in cui i dati possono rimanere in Oracle NoSQL Database Cloud Service. I dati che raggiungono l'ora di scadenza non possono più essere recuperati e non vengono visualizzati in alcuna statistica di memorizzazione.
Per impostazione predefinita, ogni tabella creata ha un valore TTL pari a zero, che indica che non esiste un'ora di scadenza. È possibile dichiarare un valore TTL quando si crea una tabella, specificando il TTL con un numero, seguito da HOURS o DAYS. Le righe di tabella ereditano il valore TTL della tabella in cui risiedono, a meno che non si imposti esplicitamente un valore TTL per le righe di tabella. L'impostazione del valore TTL di una riga comporta l'override del valore TTL della tabella. Se si modifica il valore TTL della tabella dopo che la riga ha un valore TTL, il valore TTL della riga persiste.
È possibile aggiornare il valore TTL per una riga di tabella in qualsiasi momento prima che la riga raggiunga l'ora di scadenza. Non è più possibile accedere ai dati scaduti. Pertanto, l'utilizzo dei valori TTL è più efficiente dell'eliminazione manuale delle righe, poiché viene evitato il sovraccarico di scrittura di una voce di log del database per l'eliminazione dei dati. I dati scaduti vengono rimossi dal disco dopo la data di scadenza.
Stati tabella e cicli di vita
Scopri i diversi stati delle tabelle e il loro significato (processo del ciclo di vita delle tabelle).
Ogni tabella passa attraverso una serie di stati diversi dalla creazione della tabella all'eliminazione (drop). Ad esempio, una tabella nello stato DROPPING non può passare allo stato ACTIVE, mentre una tabella nello stato ACTIVE può passare allo stato UPDATING. È possibile tenere traccia dei diversi stati delle tabelle monitorando il ciclo di vita delle tabelle. Questa sezione descrive i vari stati delle tabelle.
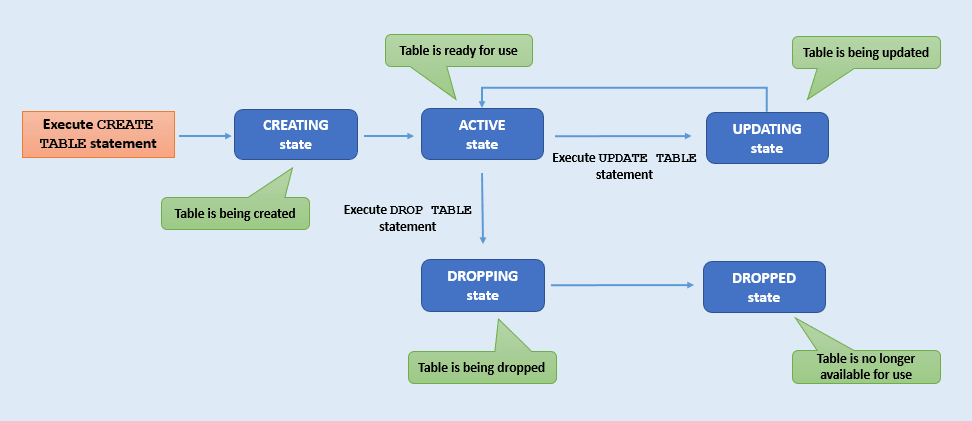
Descrizione dell'illustrazione table-state.png
| Stato tabella | Descrizione |
|---|---|
CREATING |
La tabella è in fase di creazione. Non è pronto per l'uso. |
UPDATING |
Aggiornamento della tabella in corso. Ulteriori modifiche alla tabella non sono possibili mentre la tabella si trova in questo stato. Una tabella si trova nello stato
|
ACTIVE |
La tabella può essere utilizzata nello stato corrente. La tabella potrebbe essere stata creata o modificata di recente, ma lo stato della tabella è ora stabile. |
DROPPING |
La tabella è in fase di eliminazione e non è possibile accedervi per alcuno scopo. |
DROPPED |
La tabella è stata eliminata e non esiste più per le attività di lettura, scrittura o query. Nota: una volta eliminata, è possibile creare di nuovo una tabella con lo stesso nome. |
Gerarchie tabella
Oracle NoSQL Database consente l'esistenza di tabelle in una relazione padre-figlio. Questo è noto come gerarchie di tabelle.
L'istruzione di creazione tabella consente di creare una tabella come figlio di un'altra tabella, che diventa quindi il padre della nuova tabella. Questa operazione viene eseguita utilizzando un nome composto (name_path) per la tabella figlio. Un nome composto è costituito da un numero N (N > 1) di identificatori separati da punti. L'ultimo identificativo è il nome locale della tabella figlio e i primi identificativi N-1 puntano al nome dell'elemento padre.
Caratteristiche delle tabelle padre-figlio:
-
Una tabella figlio eredita le colonne chiave primaria della relativa tabella padre.
-
Tutte le tabelle nella gerarchia hanno le stesse colonne chiave partizione, specificate nell'istruzione di creazione tabella della tabella radice.
-
Impossibile eliminare una tabella padre prima che i relativi figli vengano eliminati.
-
Un vincolo di integrità referenziale non viene applicato in una tabella padre-figlio.
È consigliabile utilizzare tabelle figlio quando è necessaria una qualche forma di normalizzazione dei dati. Le tabelle figlio possono anche essere una buona scelta durante la modellazione di relazioni da 1 a N e forniscono anche semantica delle transazioni ACID quando si scrivono più record in una gerarchia padre-figlio.