Nota:
- Questa esercitazione richiede l'accesso a Oracle Cloud. Per iscriversi a un account gratuito, consulta Inizia a utilizzare Oracle Cloud Infrastructure Free Tier.
- Utilizza valori di esempio per le credenziali, la tenancy e i compartimenti di Oracle Cloud Infrastructure. Al termine del laboratorio, sostituisci questi valori con quelli specifici del tuo ambiente cloud.
Uso di Flusso dati OCI con Apache Spark Streaming per elaborare un argomento Kafka in un'applicazione scalabile e quasi in tempo reale
Introduzione
Oracle Cloud Infrastructure (OCI) Data Flow è un servizio gestito per il progetto open source denominato Apache Spark. Fondamentalmente, con Spark puoi usarlo per file di elaborazione di grandi dimensioni, streaming e operazioni di database. Puoi creare applicazioni con un'elaborazione estremamente scalabile. Spark può ridimensionare e utilizzare computer in cluster per simulare i job con una configurazione minima.
Grazie a Spark come servizio gestito (Data Flow), puoi aggiungere molti servizi scalabili per moltiplicare la potenza dell'elaborazione cloud. Il flusso di dati consente di elaborare Spark Streaming.
Le applicazioni di streaming richiedono un'esecuzione continua per un lungo periodo di tempo che spesso si estende oltre le 24 ore e può durare anche settimane o addirittura mesi. In caso di errori imprevisti, le applicazioni di streaming devono riavviarsi dal punto di errore senza produrre risultati computazionali errati. Data Flow si basa sul checkpoint di streaming strutturato da Spark per registrare l'offset elaborato che può essere memorizzato nel bucket di storage degli oggetti.
Nota: se è necessario elaborare i dati come strategia batch, è possibile leggere questo articolo: Elabora file di grandi dimensioni in Autonomous Database e Kafka con Oracle Cloud Infrastructure Data Flow
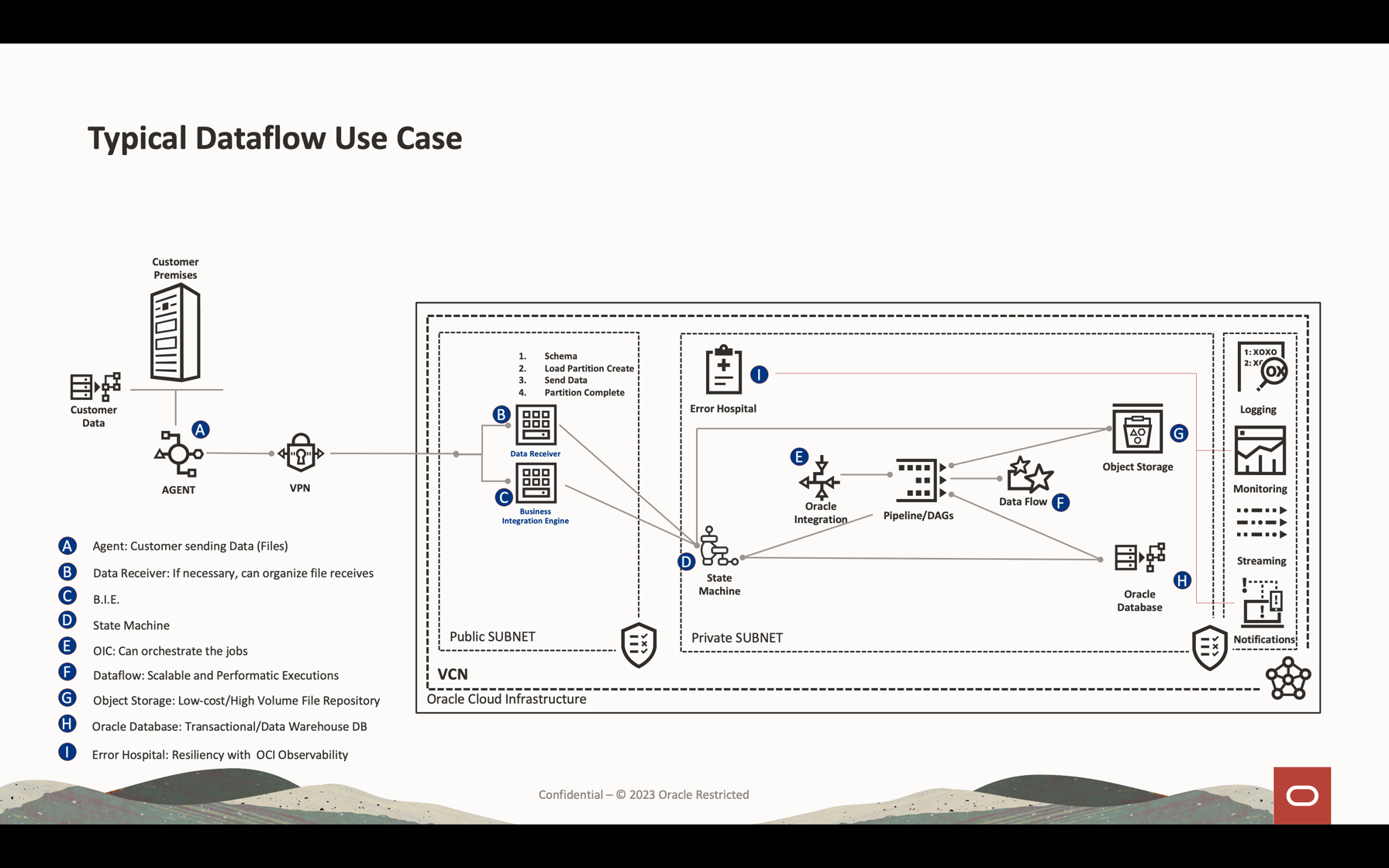
Questa esercitazione descrive le attività più comuni utilizzate per elaborare lo streaming dei volumi di dati, eseguire query sul database e unire/join i dati per formare un'altra tabella in memoria o inviare i dati a qualsiasi destinazione quasi in tempo reale. Puoi scrivere questi enormi dati nel tuo database e in una coda Kafka con prestazioni molto basse ed estremamente efficaci.
Obiettivi
- Scopri come utilizzare Data Flow per elaborare una grande quantità di dati in un'applicazione scalabile e quasi in tempo reale.
Prerequisiti
-
tenant operativo Oracle Cloud: puoi creare un account Oracle Cloud gratuito con 300,00 USD per un mese per provare questa esercitazione. Consulta la sezione relativa alla creazione di un account Oracle Cloud gratuito
-
CLI OCI (Oracle Cloud Command Line Interface) installato nel computer locale: si tratta del collegamento per installare l'CLI OCI.
-
Un'applicazione Apache Spark installata nel computer locale. Esamina Sviluppare le applicazioni Oracle Cloud Infrastructure Data Flow a livello locale, eseguire la distribuzione nel cloud per comprendere come sviluppare localmente e nel flusso di dati.
Nota: questa è la pagina ufficiale da installare: Apache Spark. Esistono procedure alternative per installare Apache Spark per ogni tipo di sistema operativo (Linux/Mac OS/Windows).
-
CLI Spark Submit installato. Si tratta del collegamento per installare l'interfaccia CLI Spark Submit.
-
Maven installato nel computer locale.
-
Conoscenza dei concetti di OCI:
- Compartimenti
- Criteri IAM
- Tenancy
- OCID delle risorse
Task 1: Creare la struttura di storage degli oggetti
Lo storage degli oggetti verrà utilizzato come repository di file predefinito. Puoi usare altri tipi di repository di file, ma lo storage degli oggetti è un modo semplice e a basso costo per manipolare i file con prestazioni. In questa esercitazione, entrambe le applicazioni caricheranno un file CSV di grandi dimensioni dallo storage degli oggetti, mostrando in che modo Apache Spark è veloce ed efficace per elaborare un elevato volume di dati.
-
Crea un compartimento: i compartimenti sono importanti per organizzare e isolare le tue risorse cloud. Puoi isolare le tue risorse in base ai criteri IAM.
-
È possibile utilizzare questo collegamento per comprendere e impostare i criteri per i compartimenti: Gestione dei compartimenti
-
Crea un compartimento per ospitare tutte le risorse delle 2 applicazioni in questa esercitazione. Creare un compartimento denominato analytics.
-
Andare al menu principale di Oracle Cloud e cercare: Identity & Security, Compartimenti. Nella sezione Compartimenti, fare clic su Crea compartimento e immettere il nome.
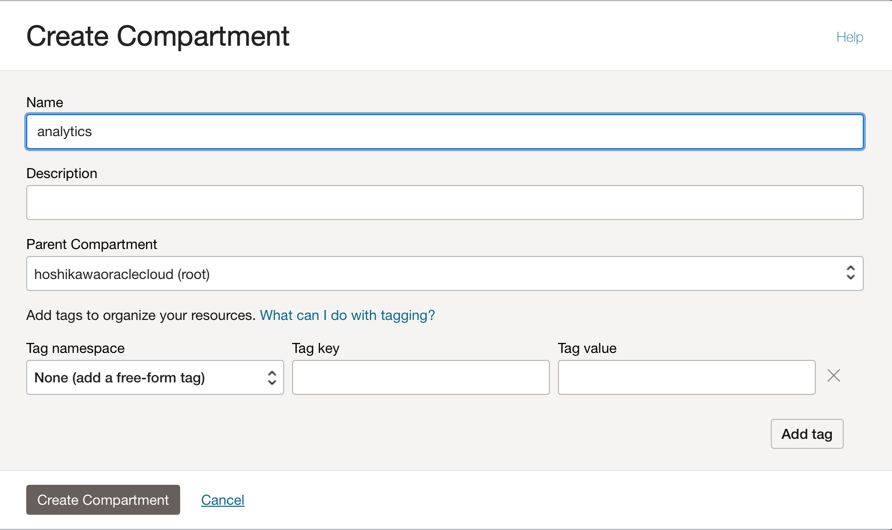
Nota: è necessario concedere l'accesso a un gruppo di utenti e includere l'utente.
-
Fare clic su Crea compartimento per includere il compartimento.
-
-
Crea il tuo bucket nello storage degli oggetti: i bucket sono container logici per la memorizzazione degli oggetti. Tutti i file utilizzati per questa demo verranno quindi memorizzati in questo bucket.
-
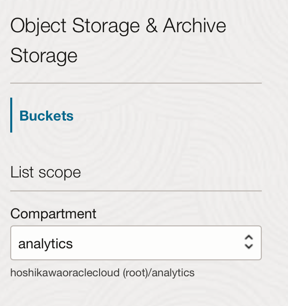
Vai al menu principale di Oracle Cloud e cerca Storage e Bucket. Nella sezione Bucket selezionare il compartimento (analitica), creato in precedenza.
-
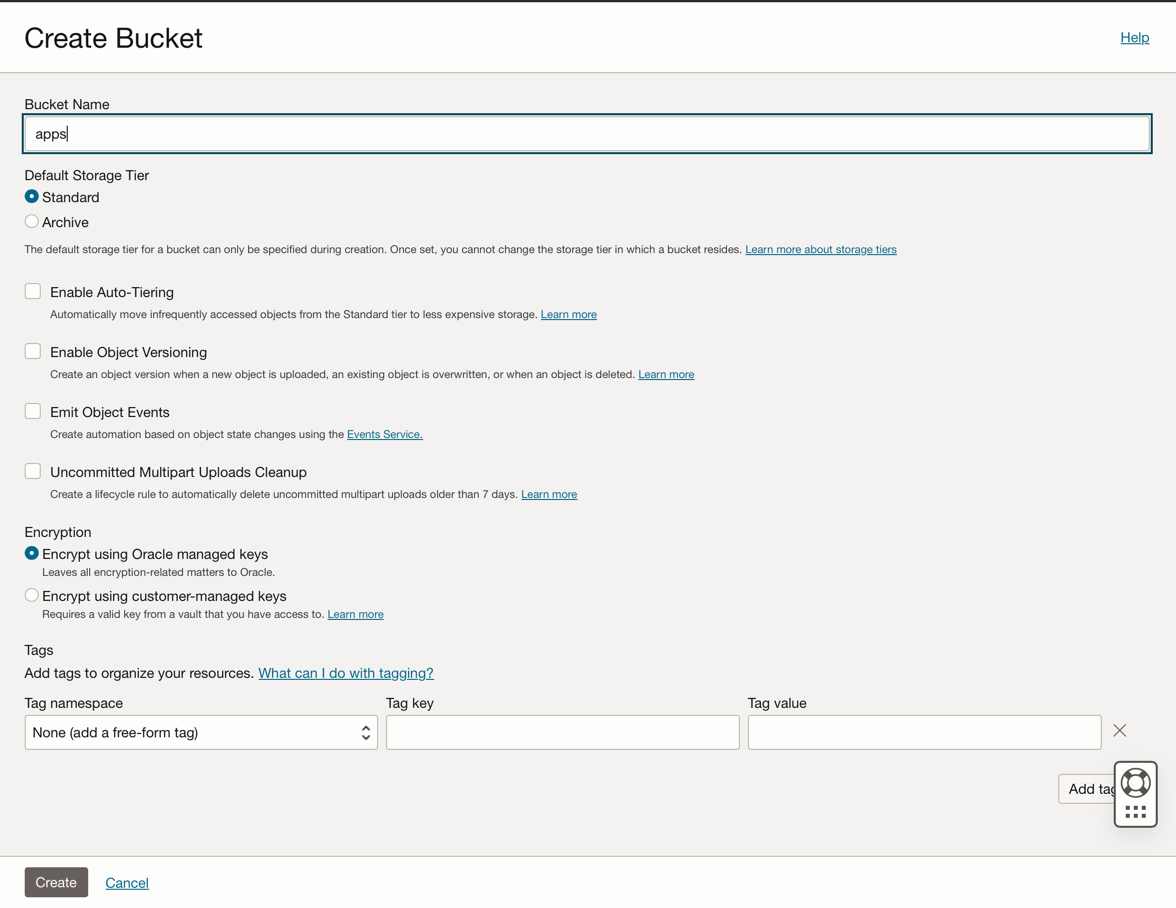
Fare clic su Crea bucket. Crea 4 bucket: applicazioni, dati, dataflow-log, wallet
-
Immettere le informazioni relative al nome bucket con questi 4 bucket e mantenere gli altri parametri con la selezione predefinita.
-
Per ogni bucket, fare clic su Crea. È possibile visualizzare i bucket creati.
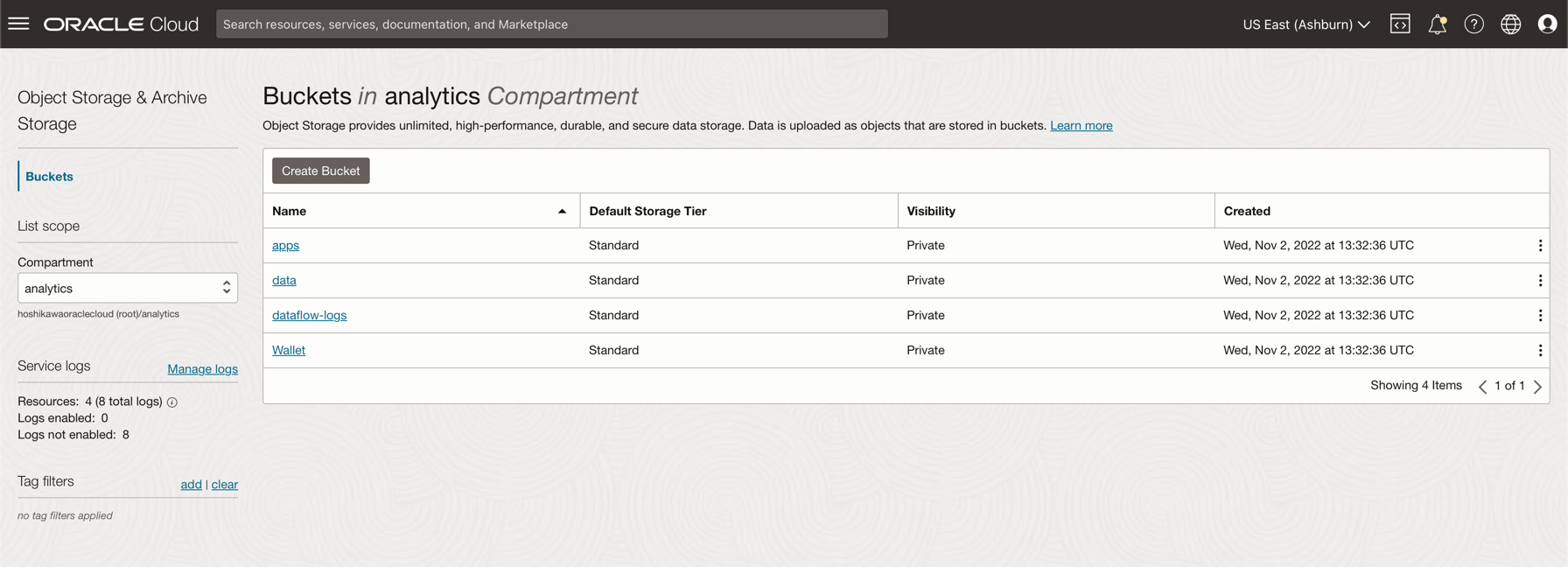
-
Nota: per il bucket, consulta i criteri IAM. È necessario impostare i criteri se si desidera utilizzare questi bucket nelle applicazioni demo. Puoi consultare i concetti e impostare qui la panoramica dello storage degli oggetti e i criteri IAM.
Task 2: creare Autonomous Database
Oracle Cloud Autonomous Database è un servizio gestito per Oracle Database. Per questa esercitazione, le applicazioni si connetteranno al database tramite un wallet per motivi di sicurezza.
-
Creare un'istanza di Autonomous Database come descritto di seguito. Provisioning di Autonomous Database.
-
Nel menu principale di Oracle Cloud selezionare l'opzione Data Warehouse, selezionare Oracle Database e Autonomous Data Warehouse, selezionare l'analitica del compartimento in uso e seguire l'esercitazione per creare l'istanza del database.
-
Assegnare al nome dell'istanza i log elaborati, scegliere log come nome del database e non è necessario modificare alcun codice nelle applicazioni.
-
Immettere la password ADMIN e scaricare il file zip del wallet.
-
Dopo aver creato il database, è possibile impostare la password utente ADMIN e scaricare il file zip Wallet.
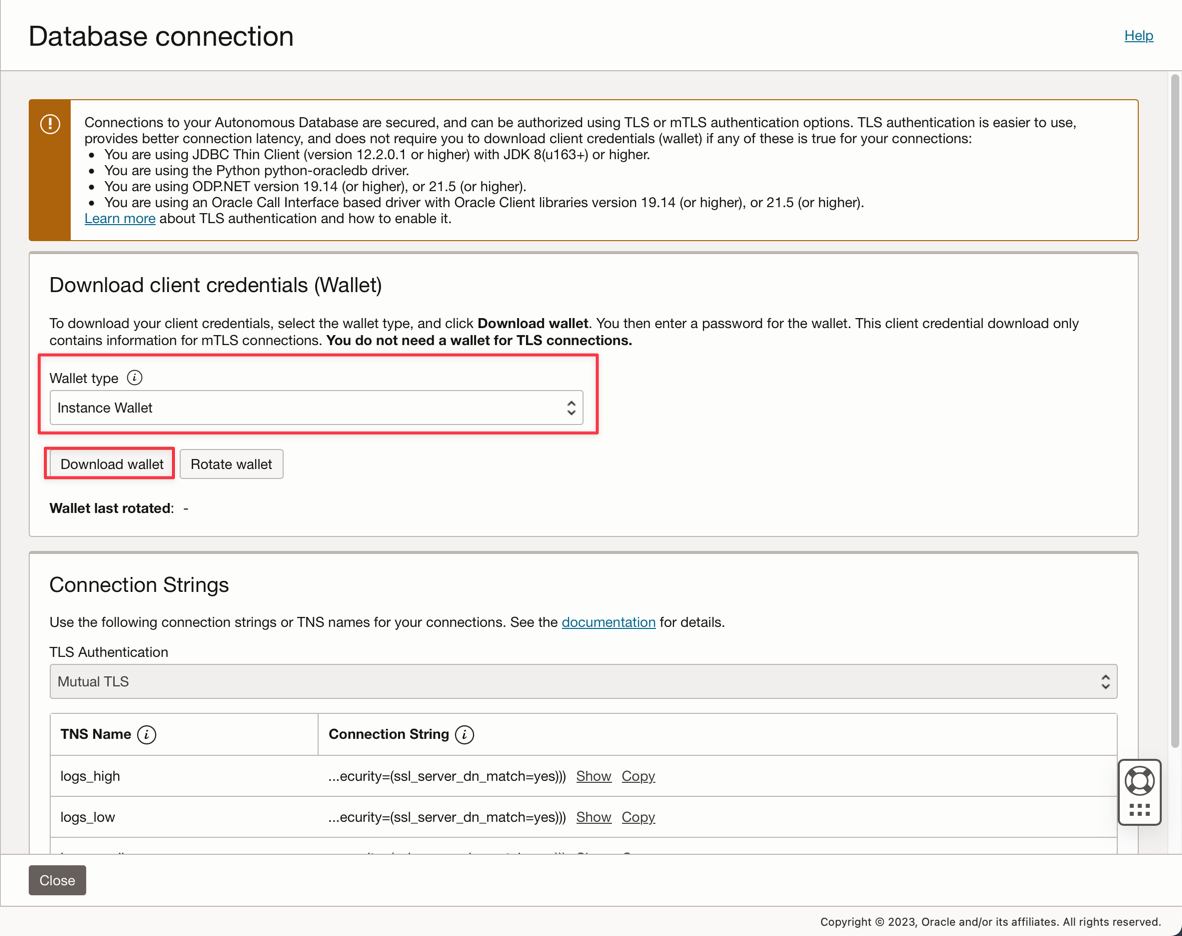
-
Salvare il file zip del wallet (
Wallet_logs.zip) e annotare la password ADMIN, sarà necessario impostare il codice applicazione. -
Andare a Storage, Bucket. Modificare l'impostazione nel compartimento analytics e il bucket Wallet verrà visualizzato. Fai clic su di esso.
-
Per caricare il file zip del wallet, fare clic su Carica e allegare il file Wallet_logs.zip.
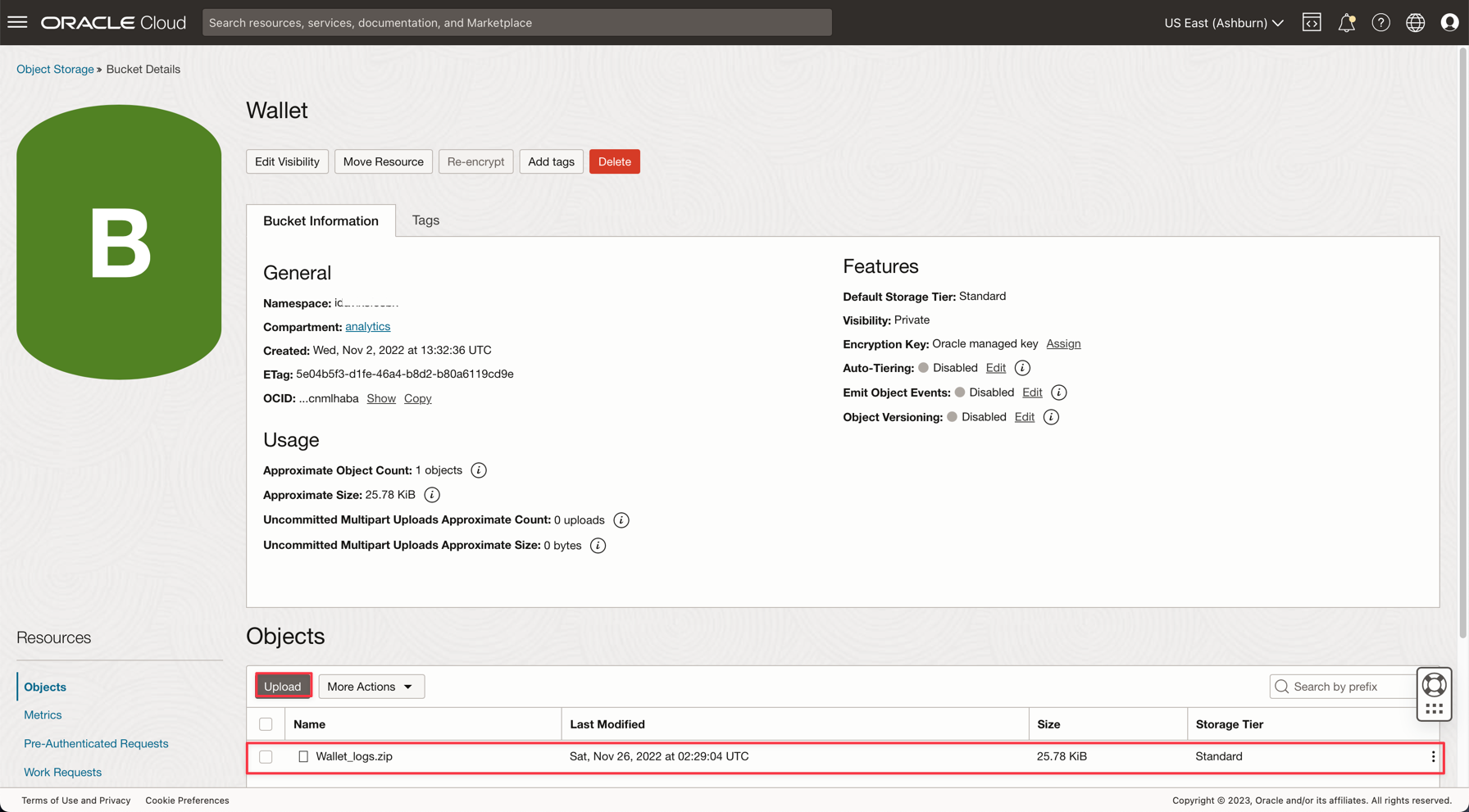
Nota: per accedere ad Autonomous Database, consultare i criteri IAM qui: criterio IAM per Autonomous Database
Task 3: caricare i file di esempio CSV
Per dimostrare la potenza di Apache Spark, le applicazioni leggeranno un file CSV con 1.000.000 righe. Questi dati verranno inseriti nel database Autonomous Data Warehouse con una sola riga di comando e pubblicati in streaming Kafka (Oracle Cloud Streaming). Tutte queste risorse sono scalabili e perfette per volumi di dati elevati.
-
Scaricare questi 2 collegamenti e caricarli nel bucket dati:
-
Nota:
- organizations.csv contiene solo 100 righe, solo per eseguire il test delle applicazioni sul computer locale.
- organizations1M.csv contiene 1.000.000 righe e verrà utilizzato per l'esecuzione nell'istanza di Flusso dati.
-
Dal menu principale di Oracle Cloud, vai a Storage e Bucket. Fare clic sul bucket dati e caricare i 2 file del passo precedente.

-
Carica una tabella ausiliaria nel database ADW
-
Scaricare questo file per il caricamento nel database ADW: GDP PER CAPTA COUNTRY.csv
-
Nel menu principale di Oracle Cloud selezionare Oracle Database e Autonomous Data Warehouse.
-
Fare clic sull'istanza Log elaborati per visualizzare i dettagli.
-
Fare clic su Azioni database per accedere alle utility del database.
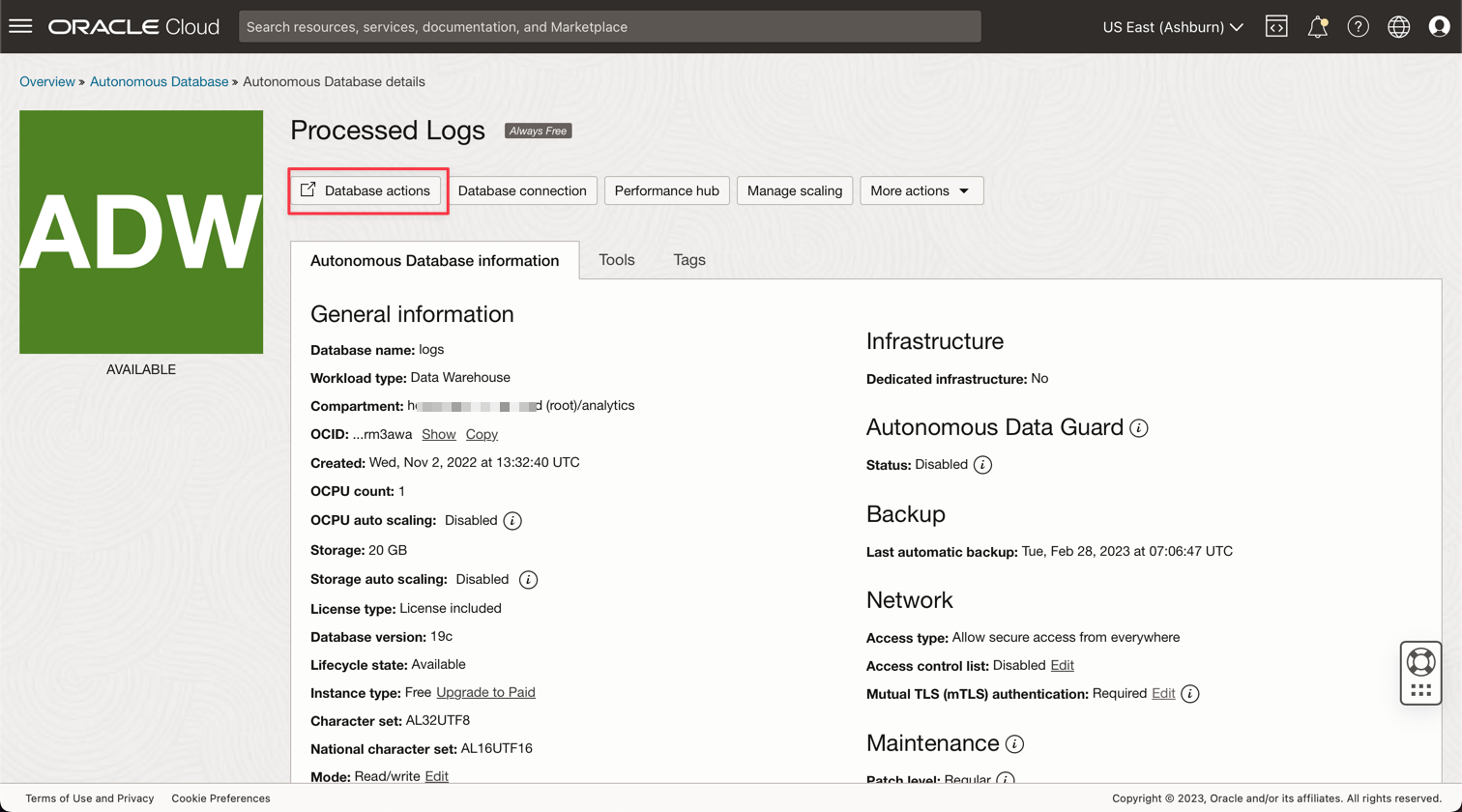
-
Immettere le credenziali per l'utente ADMIN.
-
Fare clic sull'opzione SQL per accedere alle utility di query.
-
Fare clic su Caricamento dati.
-
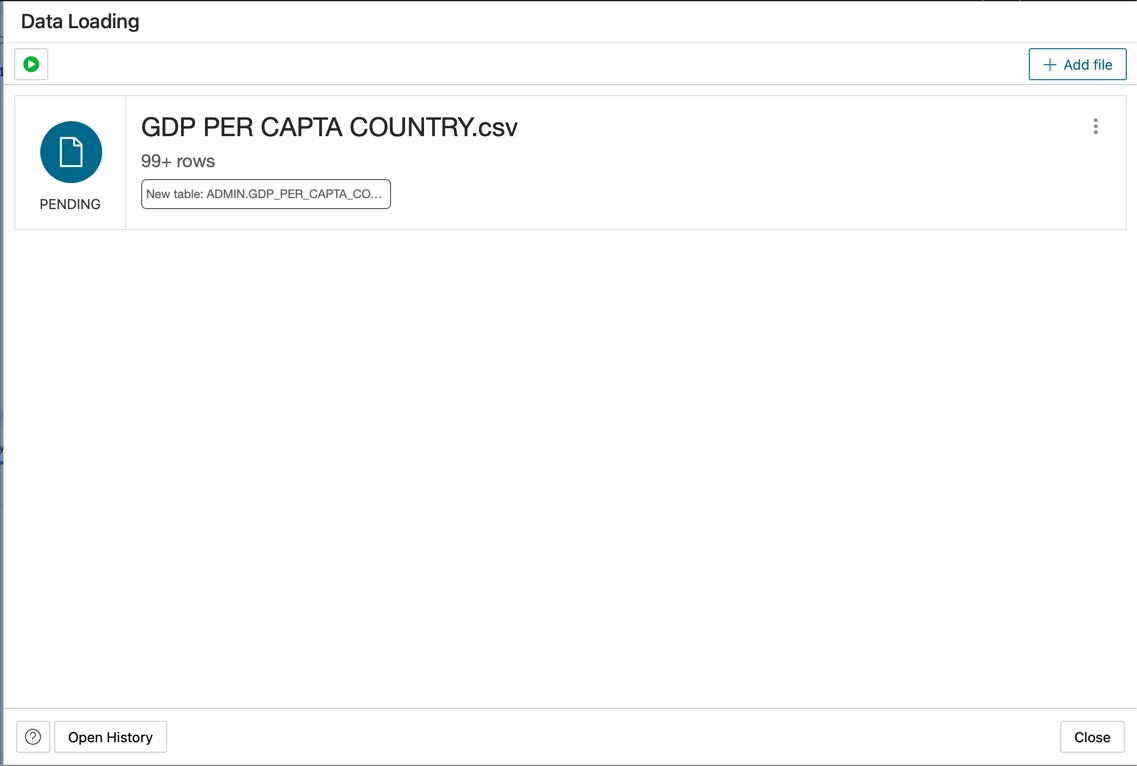
Rilasciare il file GDP PER CAPTA COUNTRY.csv nel pannello della console e procedere all'importazione dei dati in una tabella.
-
L'importazione della nuova tabella denominata GDPPERCAPTA è riuscita.
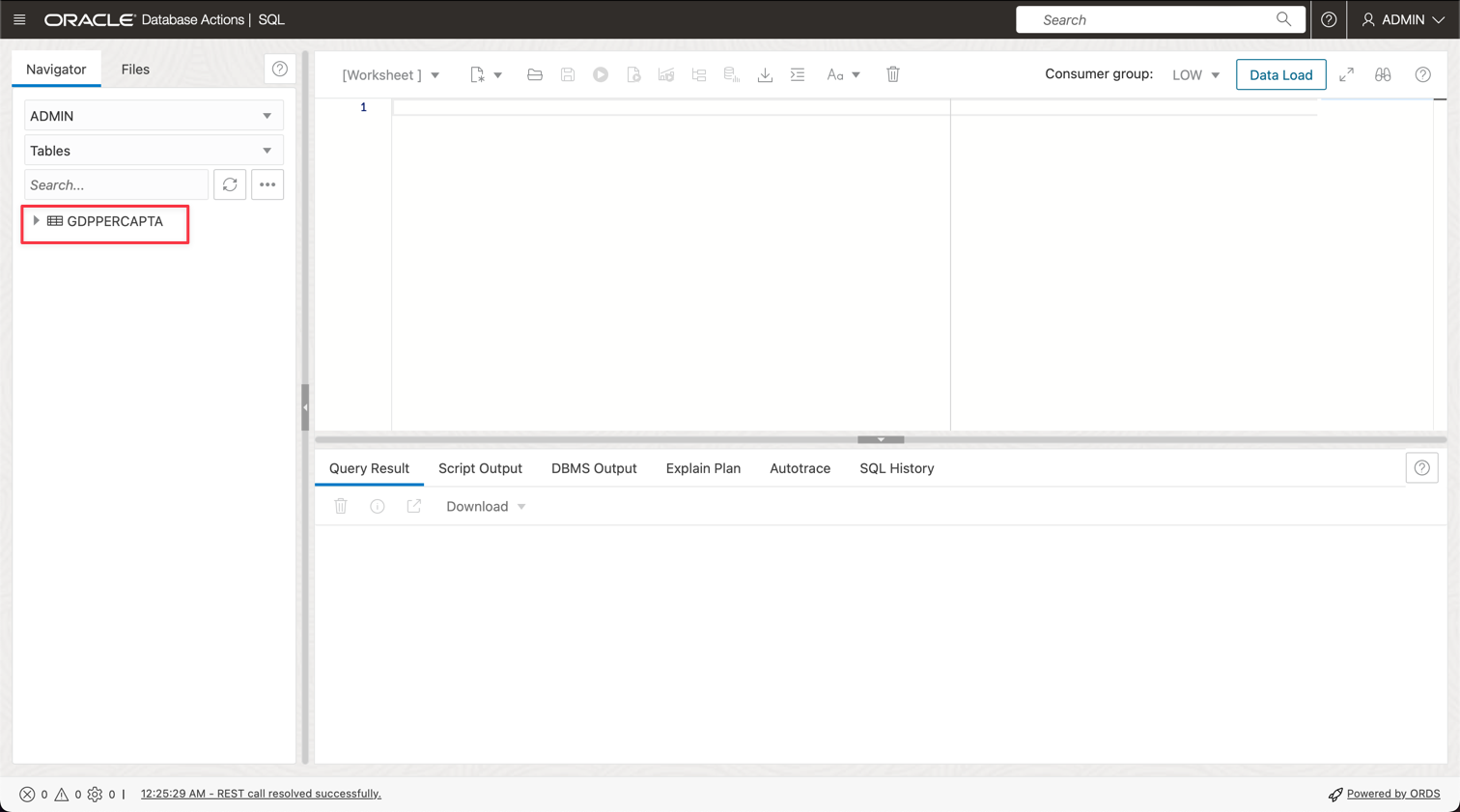
Task 4: creare un vault segreto per la password ADW ADMIN
Per motivi di sicurezza, la password ADW ADMIN verrà salvata in un vault. Oracle Cloud Vault può ospitare questa password con sicurezza ed è possibile accedervi nell'applicazione mediante l'autenticazione OCI.
-
Creare il segreto in un vault come descritto nella seguente documentazione: Aggiungere la password amministratore del database al vault
-
Creare una variabile denominata PASSWORD_SECRET_OCID nelle applicazioni e immettere l'OCID.
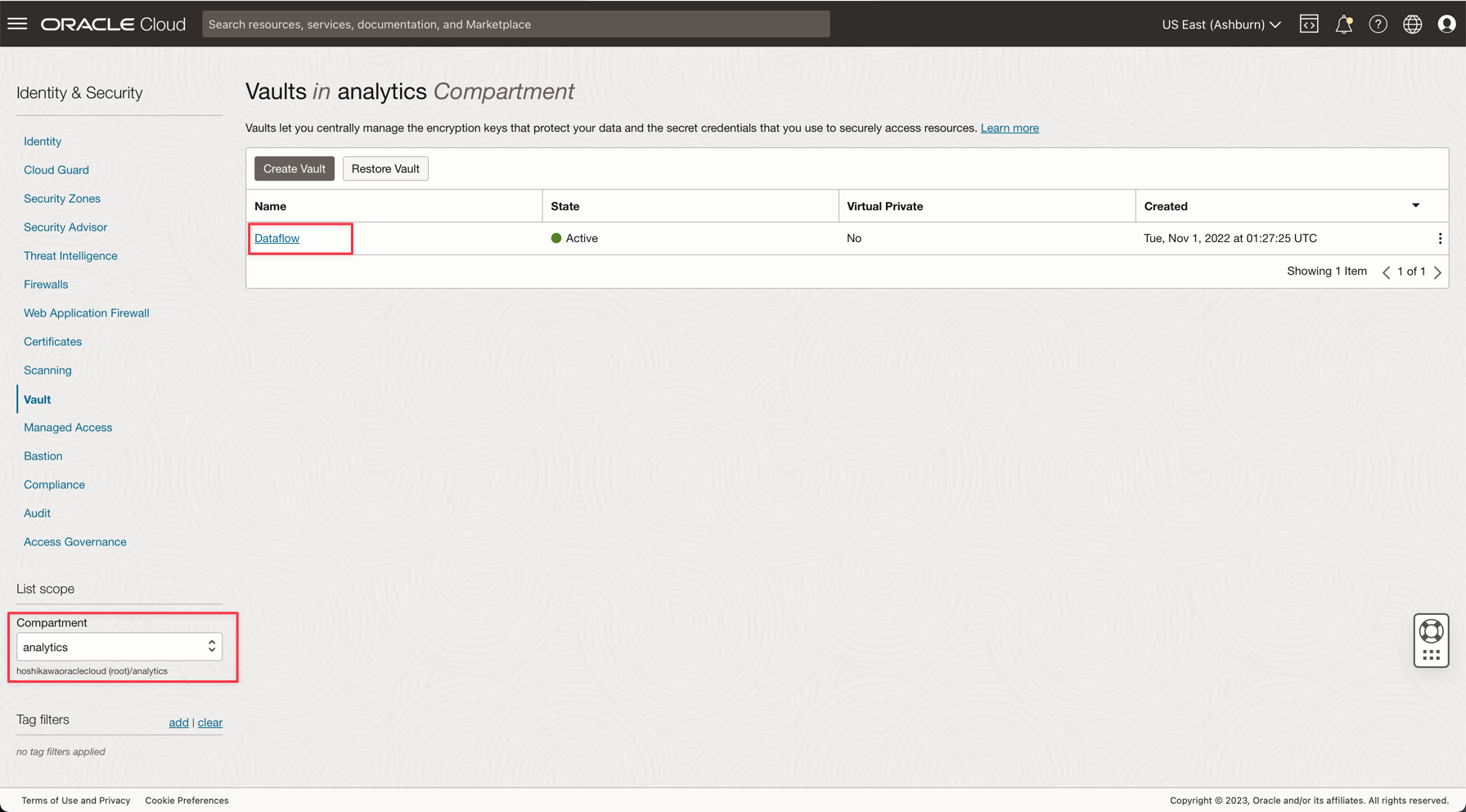
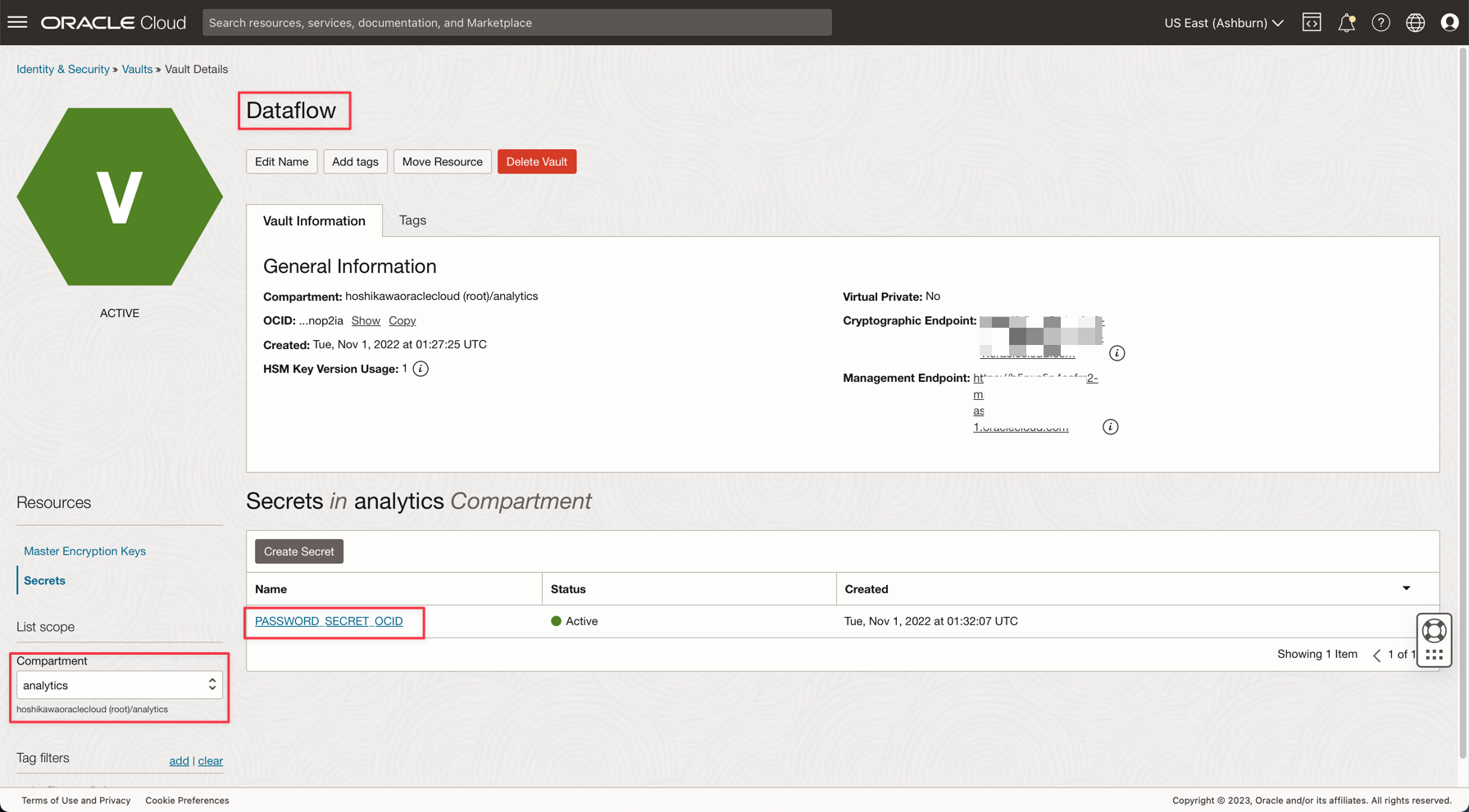

Nota: rivedere il criterio IAM per il vault OCI qui: Criterio IAM di OCI Vault.
Task 5: Creare un servizio di streaming Kafka (Oracle Cloud Streaming)
Il servizio di streaming gestito è Oracle Cloud Streaming. Puoi sviluppare applicazioni utilizzando le API Kafka e gli SDK comuni. In questa esercitazione, creerai un'istanza di streaming e ne configurerai l'esecuzione in entrambe le applicazioni per pubblicare e utilizzare un elevato volume di dati.
-
Dal menu principale di Oracle Cloud, vai a Analytics & AI, Streams.
-
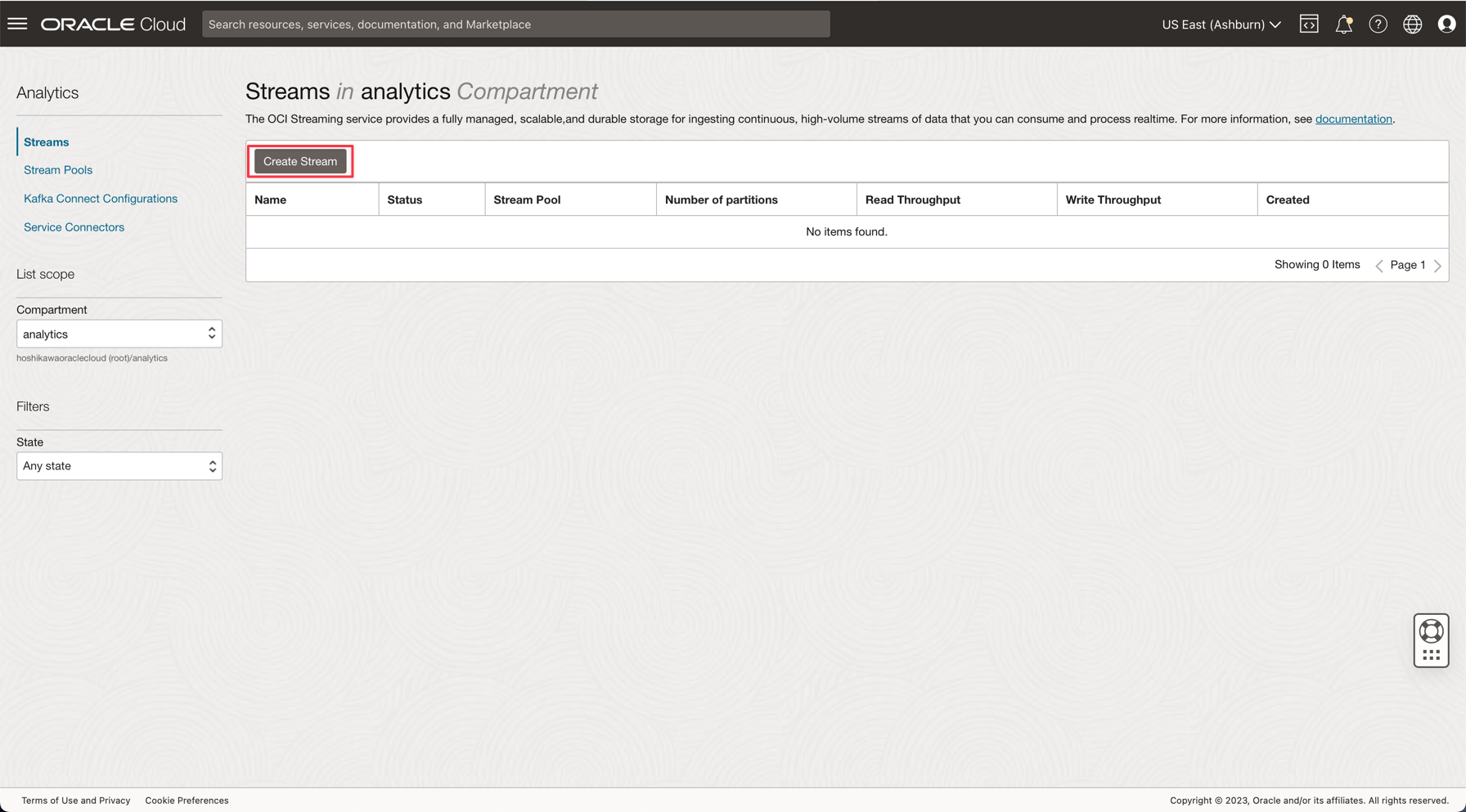
Modificare il compartimento in analytics. Ogni risorsa in questa demo verrà creata in questo compartimento. Questo sistema è più sicuro e facile da controllare grazie a IAM.
-
Fare clic su Crea flusso.
-
Immettere il nome kafka_like (ad esempio) e mantenere tutti gli altri parametri con i valori predefiniti.
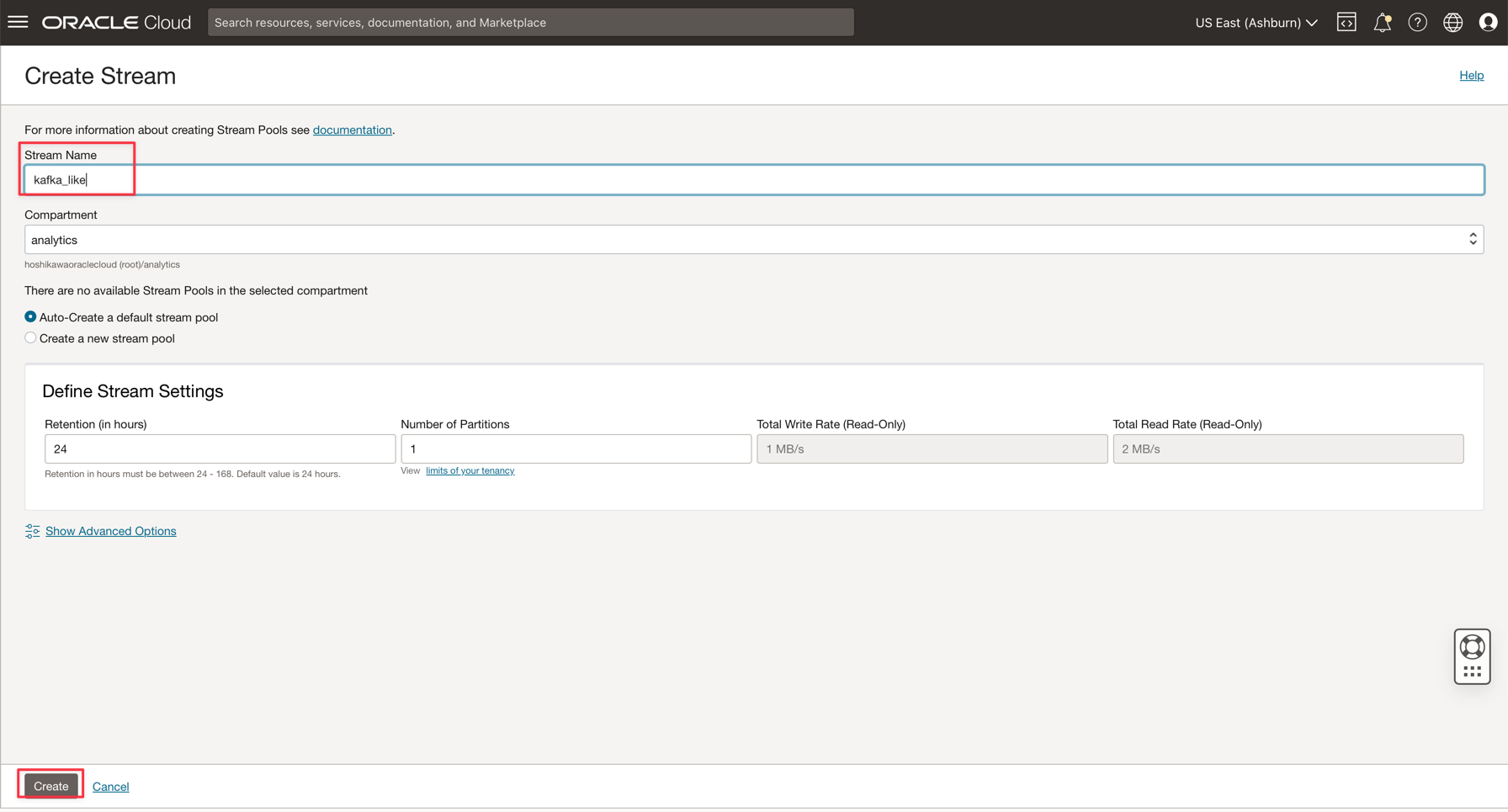
-
Fare clic su Crea per inizializzare l'istanza.
-
Attendere lo stato Attivo. Ora puoi usare l'istanza.
Nota: nel processo di creazione dello streaming è possibile selezionare l'opzione Creazione automatica di un pool di flussi predefinito per creare automaticamente il pool predefinito.
-
Fare clic sul collegamento DefaultPool.

-
Visualizzare l'impostazione di connessione.
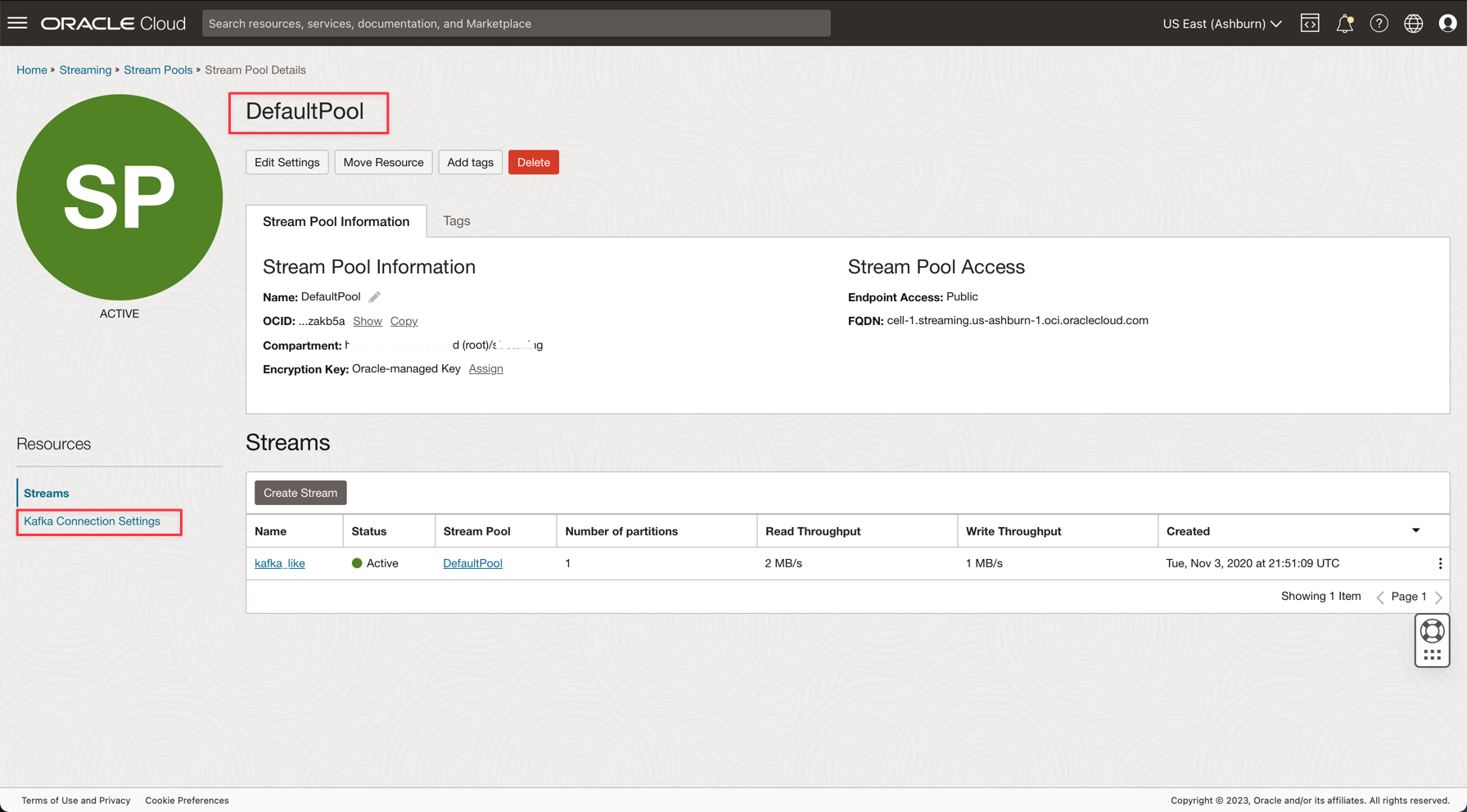
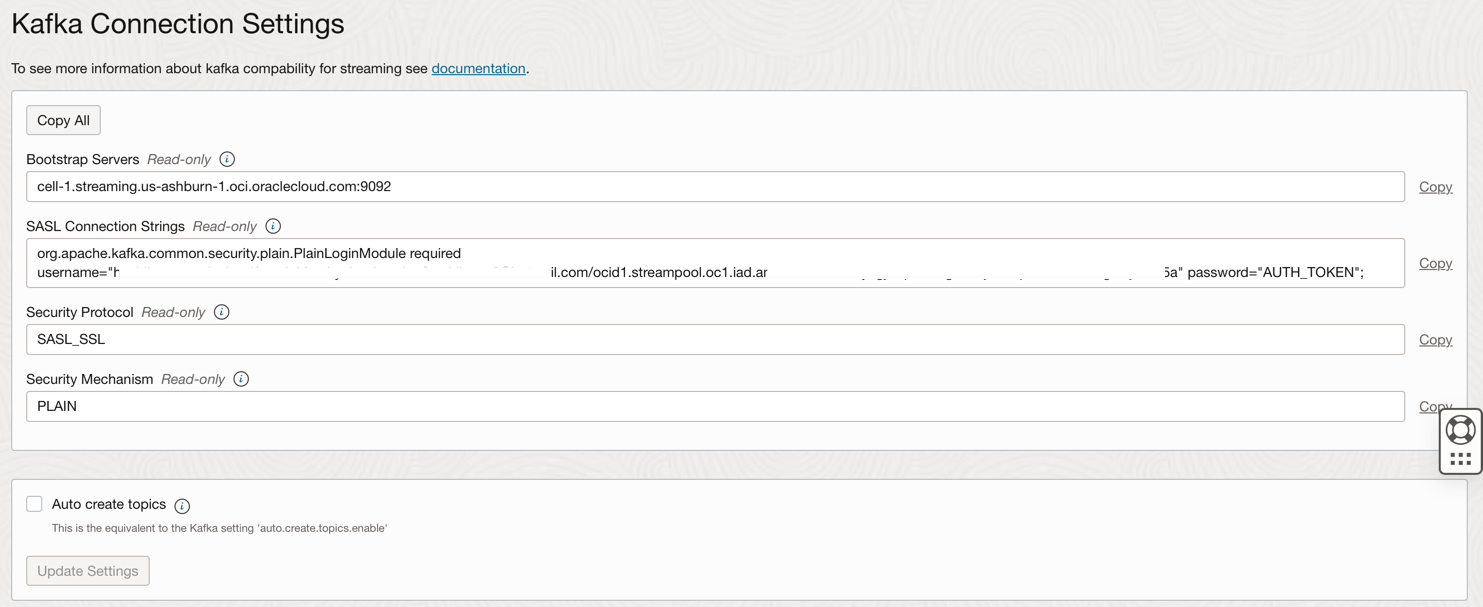
-
Annotare queste informazioni come saranno necessarie nel passo successivo.
Nota: rivedere i criteri IAM per lo streaming OCI qui: criterio IAM per lo streaming OCI.
Task 6: generare un TOKEN AUTH per accedere a Kafka
Puoi accedere a streaming OCI (API Kafka) e ad altre risorse in Oracle Cloud con un token di autenticazione associato al tuo utente su IAM OCI. Nelle impostazioni di connessione Kafka, le stringhe di connessione SASL hanno un parametro denominato password e un valore AUTH_TOKEN come descritto nel task precedente. Per abilitare l'accesso allo streaming OCI, è necessario andare all'utente nella console OCI e creare un TOKEN AUTH.
-
Dal menu principale di Oracle Cloud, andare a Identity & Security, Users.
Nota: tenere presente che l'utente necessario creare AUTH TOKEN è l'utente configurato con l'interfaccia CLI OCI e tutta la configurazione dei criteri IAM per le risorse create fino ad ora. Le risorse sono:
- Oracle Cloud Autonomous Data Warehouse
- Streaming di Oracle Cloud
- Memorizzazione oggetti Oracle
- Flusso di dati Oracle
-
Fare clic sul nome utente per visualizzare i dettagli.
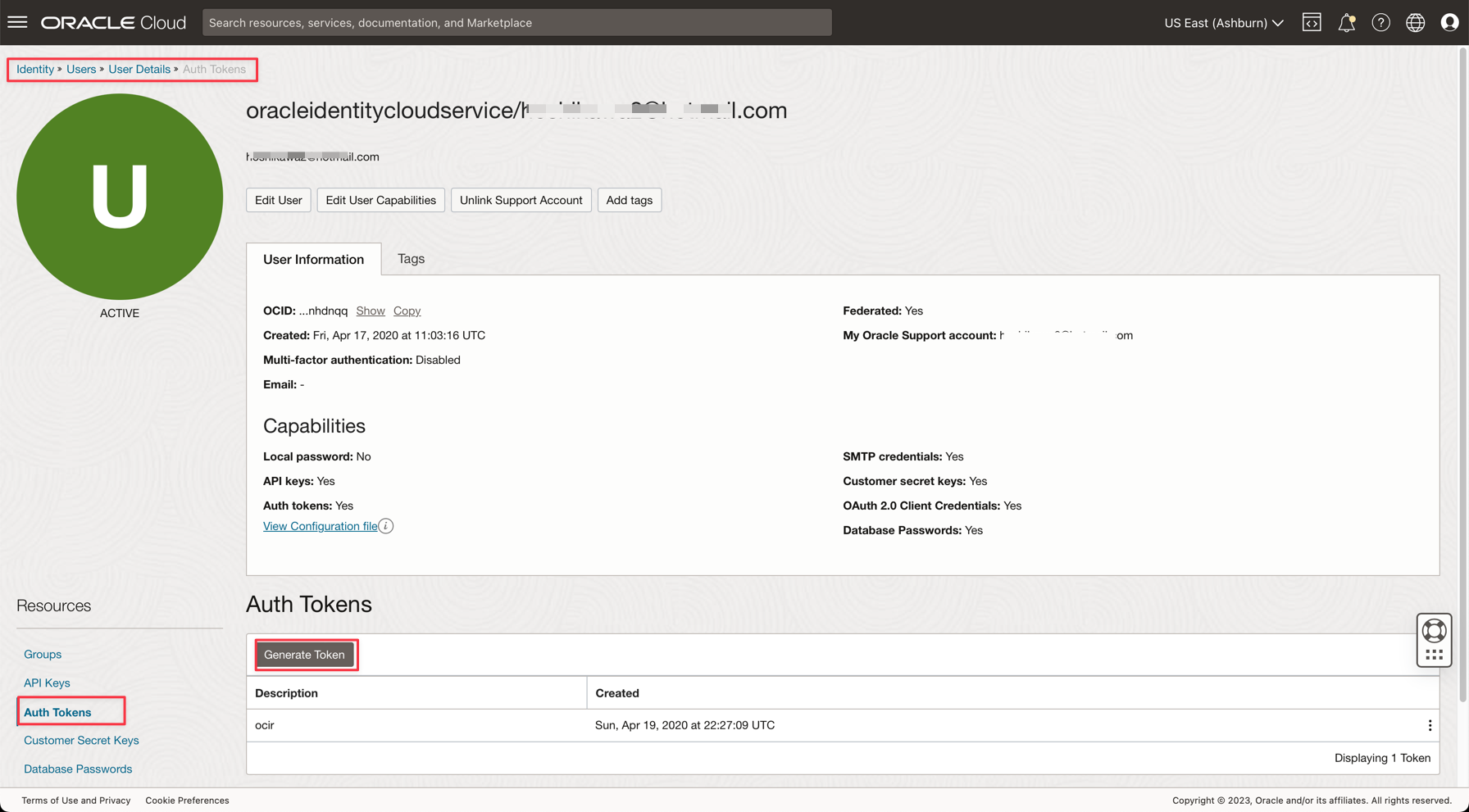
-
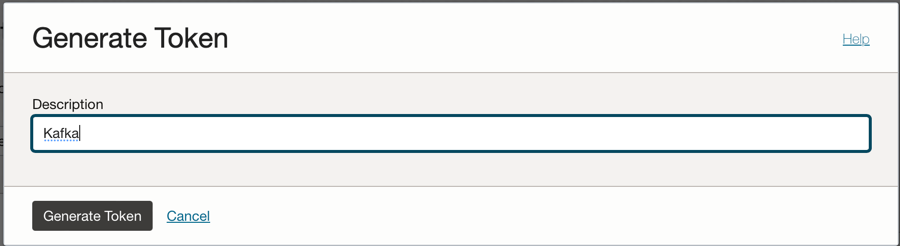
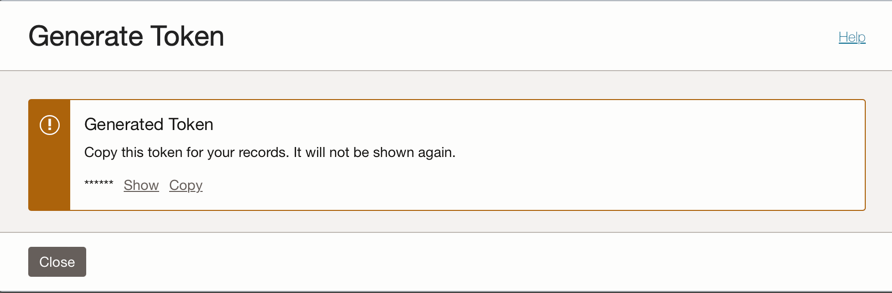
Fare clic sull'opzione Autorizza token sul lato sinistro della console e fare clic su Genera token.
Nota: il token verrà generato solo in questo passo e non sarà visibile dopo il completamento del passo. Quindi, copiare il valore e salvarlo. Se si perde il valore del token, è necessario generare di nuovo il token di autenticazione.
Task 7: impostazione dell'applicazione Demo
Questa esercitazione dispone di un'applicazione demo per la quale verranno impostate le informazioni richieste.
- DataflowSparkStreamDemo: questa applicazione si connetterà allo streaming Kafka e utilizzerà tutti i dati e si unirà con una tabella ADW denominata GDPPERCAPTA. I dati del flusso verranno uniti a GDPPERCAPTA e verranno salvati come file CSV, ma possono essere esposti a un altro argomento Kafka.
-
Scaricare l'applicazione utilizzando il collegamento seguente:
-
Trovare i dettagli riportati di seguito nella console di Oracle Cloud.
-
Spazio di nomi tenancy
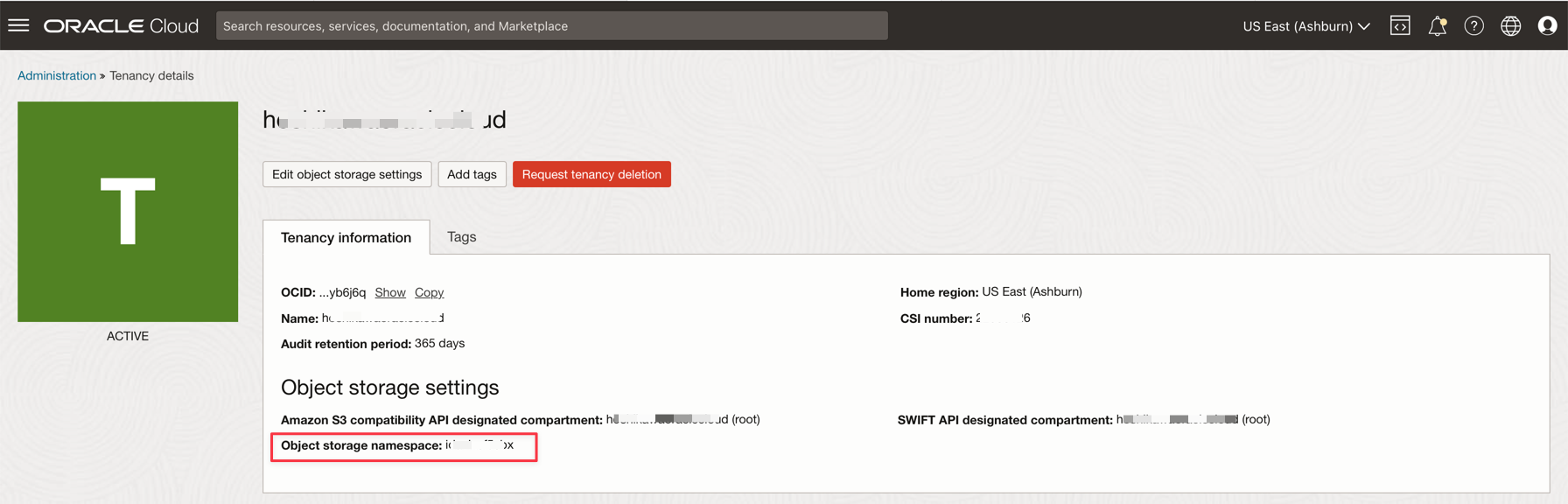
-
Segreto password
-
Impostazioni connessione streaming
-
Token di autorizzazione
-
-
Aprire il file zip scaricato (
Java-CSV-DB.zipeJavaConsumeKafka.zip). Passare alla cartella /src/main/java/example e trovare il codice Example.java.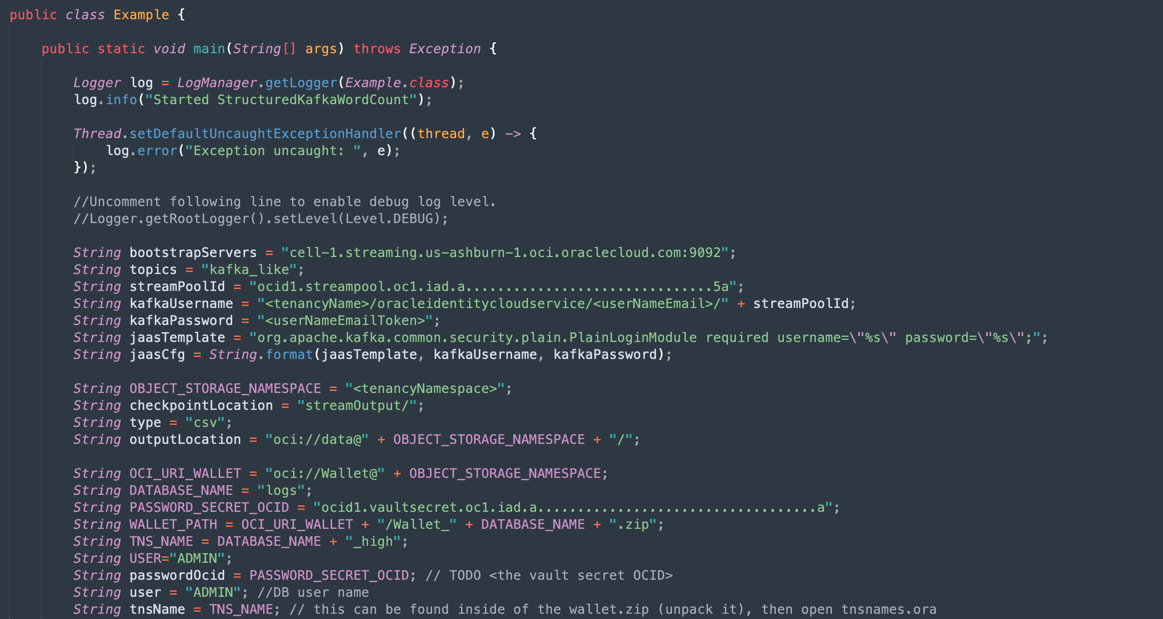
Queste sono le variabili che devono essere modificate insieme ai valori delle risorse della tenancy.
NOME VARIABILE NOME RISORSA TITOLO INFORMAZIONI bootstrapServers Impostazioni connessione streaming Server Bootstrap streamPoolId Impostazioni connessione streaming ocid1.streampool.oc1.iad..... valore nella stringa di connessione SASL kafkaUsername Impostazioni connessione streaming valore del nome utente all'interno di " " nella stringa di connessione SASL kafkaPassword Token di autorizzazione Il valore viene visualizzato solo nella fase di creazione OBJECT_STORAGE_NAMESPACE SPAZIO DI NOMI TENANCY TENANCY SPAZIO DEI NOMI SPAZIO DI NOMI TENANCY TENANCY PASSWORD_SECRET_OCID PASSWORD_SECRET_OCID OCID
Nota: tutte le risorse create per questa demo si trovano nell'area US-ASHBURN-1. Controllare l'area desiderata. Se si modifica l'area, è necessario modificare 2 punti in 2 file di codice:
Example.java: modificare la variabile bootstrapServers, sostituendo "us-ashburn-1" con la nuova area.
OboTokenClientConfigurator.java: modificare la variabile CANONICAL_REGION_NAME con la nuova area
Task 8: Comprendere il codice Java
Questa esercitazione è stata creata in Java e questo codice può essere applicato anche a Python. Per dimostrare l'efficienza e la scalabilità, l'applicazione è stata sviluppata per mostrare alcune possibilità in un caso d'uso comune di un processo di integrazione. Pertanto, il codice dell'applicazione mostra gli esempi riportati di seguito.
- Connessione al flusso Kafka e lettura dei dati
- Elabora JOINS con una tabella ADW per creare informazioni utili
- Output di un file CSV con tutte le informazioni utili provenienti da Kafka
Questa demo può essere eseguita nel computer locale e distribuita nell'istanza di Flusso dati da eseguire come esecuzione di un job.
Nota: per il job Flusso dati e il computer locale, utilizzare la configurazione dell'interfaccia CLI OCI per accedere alle risorse OCI. Dal lato Flusso dati, tutto è preconfigurato, quindi non è necessario modificare i parametri. Sul lato computer locale, dovresti aver installato l'interfaccia CLI OCI e configurato il tenant, l'utente e la chiave privata per accedere alle tue risorse OCI.
Vediamo il codice Example.java nelle sezioni:
-
Inizializzazione di Apache Spark: questa parte del codice rappresenta l'inizializzazione di Spark. Molti parametri per eseguire i processi di esecuzione sono configurati automaticamente, quindi è molto facile da utilizzare con il motore Spark. L'inizializzazione è diversa se è in esecuzione all'interno del flusso di dati o nel computer locale. Se si è in Flusso dati, non è necessario caricare il file zip del wallet ADW, il task di caricamento, annullamento della compressione e lettura dei file del wallet è automatico all'interno dell'ambiente Flusso dati, ma nel computer locale è necessario eseguire questa operazione con alcuni comandi.
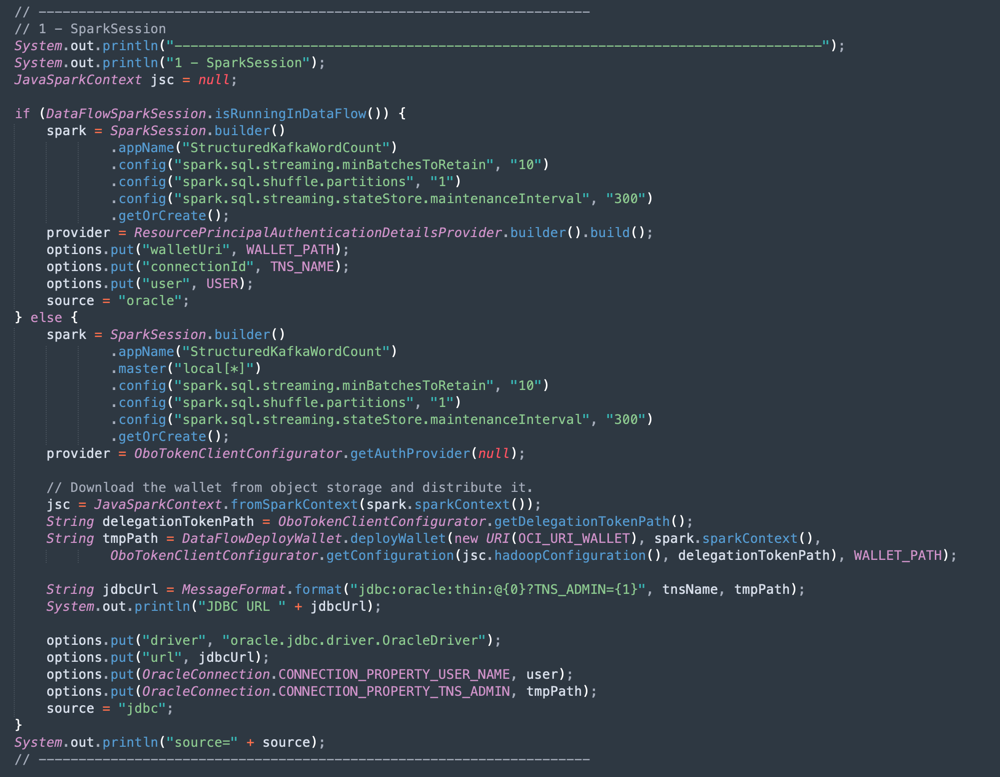
-
Leggi il segreto vault ADW: questa parte del codice accede al vault per ottenere il segreto per l'istanza di Autonomous Data Warehouse.
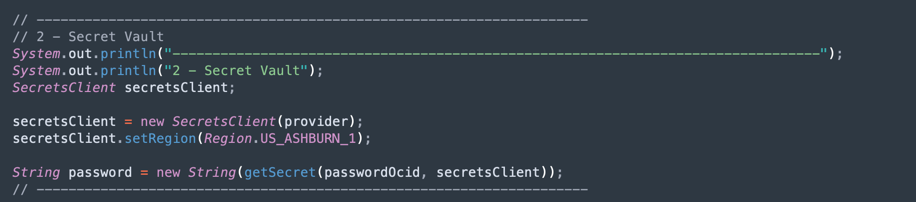
-
Eseguire una query su una tabella ADW: questa sezione mostra come eseguire una query su una tabella.

-
Operazioni Kafka: questa è la preparazione per la connessione allo streaming OCI utilizzando l'API Kafka.
Nota: Oracle Cloud Streaming è compatibile con la maggior parte delle API Kafka.
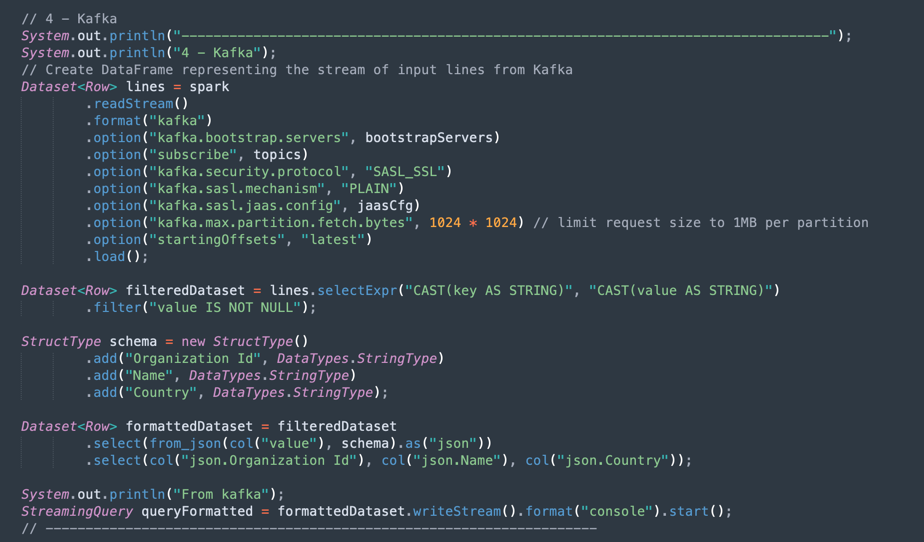
È disponibile un processo per analizzare i dati JSON provenienti dall'argomento Kafka in un set di dati con la struttura corretta (ID organizzazione, nome, paese).
-
Unisce i dati da un data set Kafka e da un data set Autonomous Data Warehouse: questa sezione mostra come eseguire una query con 2 set di dati.

-
Output in un file CSV: ecco come i dati uniti generano l'output in un file CSV.

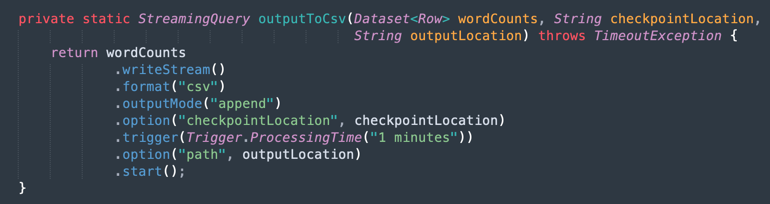
Task 9: creare un package per l'applicazione con Maven
Prima di eseguire il job in Spark, è necessario creare il package dell'applicazione con Maven.
-
Accedere alla cartella /DataflowSparkStreamDemo ed eseguire questo comando:
mvn package -
È possibile vedere Maven per l'avvio del packaging.
-
Se tutto è corretto, è possibile visualizzare il messaggio Operazione riuscita.
Task 10: verificare l'esecuzione
-
Esegui il test dell'applicazione nel computer Spark locale eseguendo questo comando:
spark-submit --class example.Example target/consumekafka-1.0-SNAPSHOT.jar -
Andare all'istanza Kafka di Oracle Cloud Streaming e fare clic su Produci messaggio di test per generare alcuni dati ed eseguire il test dell'applicazione in tempo reale.
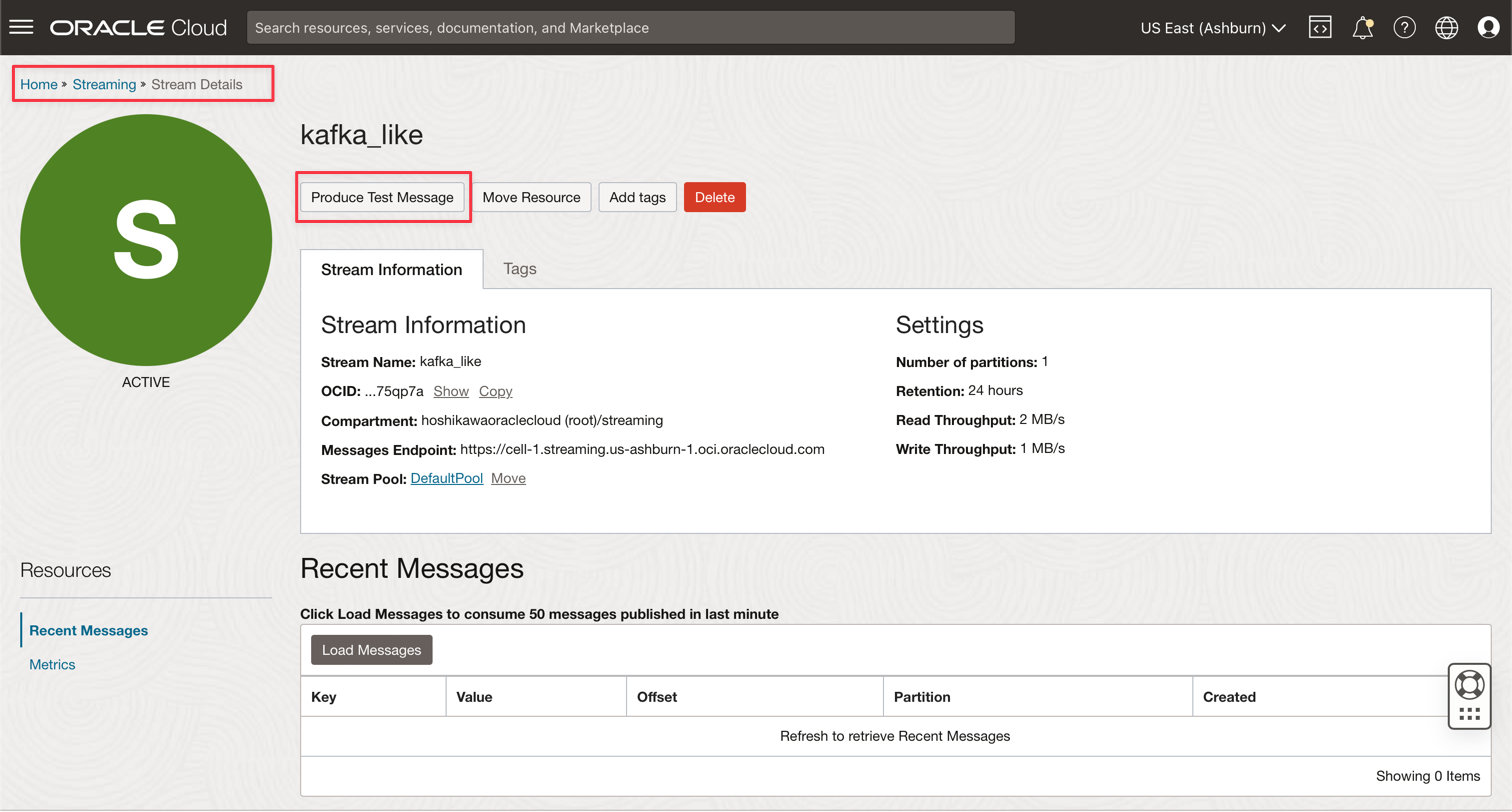
-
Puoi inserire questo messaggio JSON nell'argomento Kafka.
{"Organization Id": "1235", "Name": "Teste", "Country": "Luxembourg"}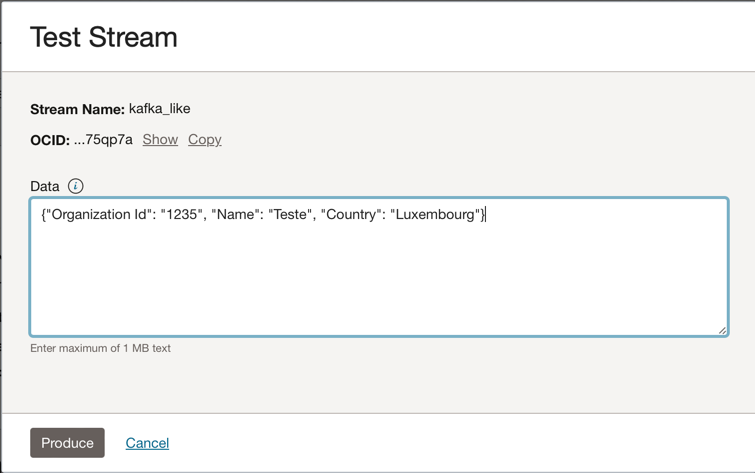
-
Ogni volta che si fa clic su Presenta, viene inviato un messaggio all'applicazione. Il log di output dell'applicazione è simile al seguente:
-
Questi sono i dati letti dall'argomento kafka.

-
Si tratta dei dati uniti dalla tabella ADW.

-
Task 11: creare ed eseguire un job di Flusso dati
Ora, con entrambe le applicazioni in esecuzione con successo nel tuo computer Spark locale, puoi distribuirle nel flusso di dati di Oracle Cloud nella tua tenancy.
Nota: consultare la documentazione di Spark Streaming per configurare l'accesso a risorse quali Oracle Object Storage e Oracle Streaming (Kafka): Abilita accesso a flusso dati
-
Carica i package nello storage degli oggetti.
- Prima di creare un'applicazione Flusso di dati, è necessario caricare l'applicazione artifact Java (il file ***-SNAPSHOT.jar) nel bucket Storage degli oggetti denominato apps.
-
Creare un'applicazione di flusso dati.
-
Selezionare il menu principale di Oracle Cloud e andare a Analitica e AI e Flusso di dati. Assicurarsi di selezionare il compartimento analytics prima di creare un'applicazione di flusso dati.
-
Fare clic su Crea applicazione.
-
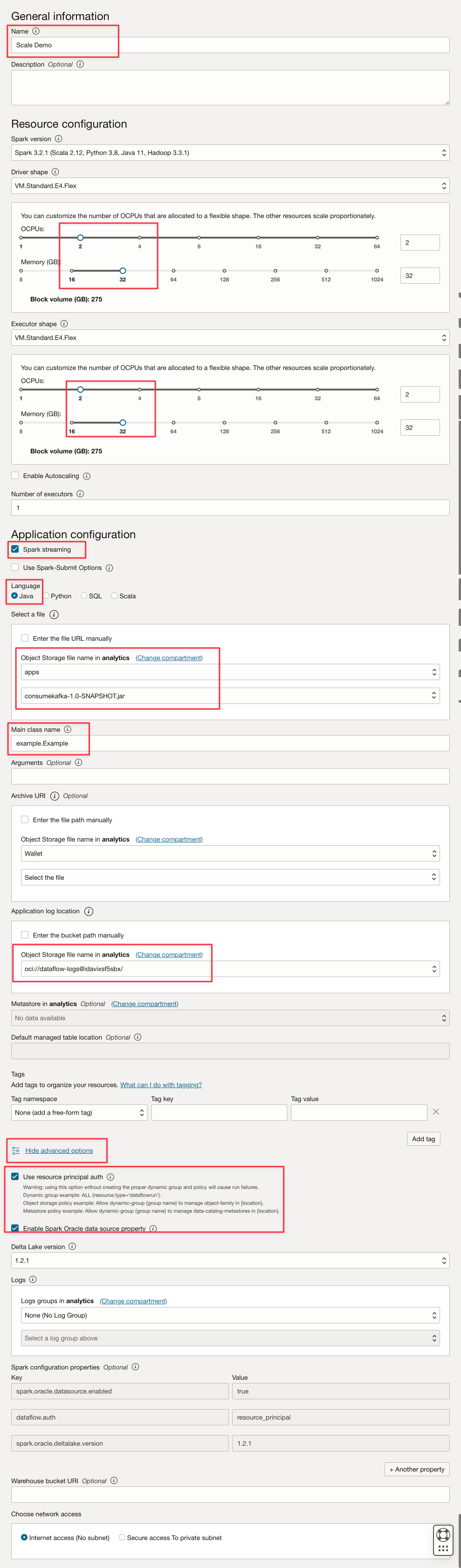
Compilare i parametri come questo.
-
Fare clic su Crea.
-
Dopo la creazione, fare clic sul collegamento Demo su scala per visualizzare i dettagli. Per eseguire un job, fare clic su RUN.
Nota: fare clic su Mostra opzioni avanzate per abilitare la sicurezza OCI per il tipo di esecuzione Flusso Spark.

-
-
Attivare le seguenti opzioni.

-
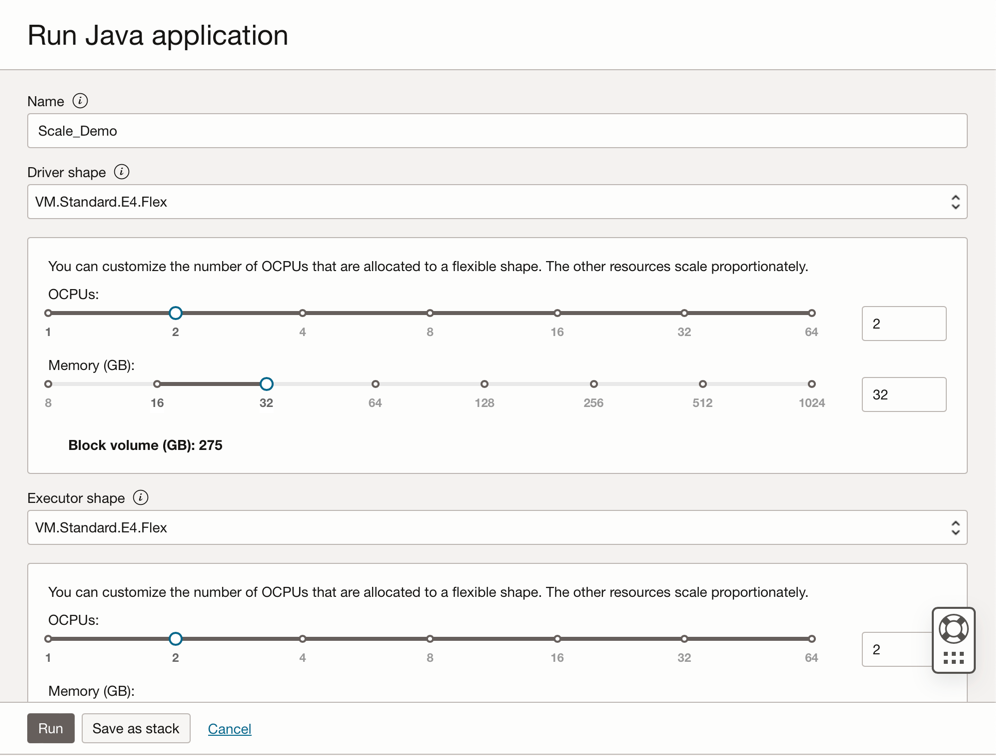
Fare clic su Esegui per eseguire il job.
-
Confermare i parametri e fare di nuovo clic su Esegui.
-
È possibile visualizzare lo stato del job.

-
Attendere che lo stato sia Riuscito ed è possibile visualizzare i risultati.

-
Collegamenti correlati
Approvazioni
- Autore - Cristiano Hoshikawa (Oracle LAD A-Team Solution Engineer)
Altre risorse di apprendimento
Esplora altri laboratori su docs.oracle.com/learn o accedi a contenuti di formazione gratuiti sul canale YouTube di Oracle Learning. Inoltre, visitare education.oracle.com/learning-explorer per diventare Explorer di Oracle Learning.
Per la documentazione sul prodotto, visitare il sito Oracle Help Center.
Use OCI Data Flow with Apache Spark Streaming to process a Kafka topic in a scalable and near real-time application
F79979-02
May 2023
Copyright © 2023, Oracle and/or its affiliates.