Nota
- Questa esercitazione richiede l'accesso a Oracle Cloud. Per iscriversi a un account gratuito, consulta Inizia a utilizzare Oracle Cloud Infrastructure Free Tier.
- Utilizza valori di esempio per le credenziali, la tenancy e i compartimenti di Oracle Cloud Infrastructure. Quando completi il tuo laboratorio, sostituisci questi valori con quelli specifici del tuo ambiente cloud.
Analizza i documenti PDF in linguaggio naturale con OCI Generative AI
Introduzione
Oracle Cloud Infrastructure Generative AI (OCI Generative AI) è una soluzione avanzata di intelligenza artificiale generativa che consente alle aziende e agli sviluppatori di creare applicazioni intelligenti utilizzando modelli linguistici all'avanguardia. Basata su tecnologie potenti come i Large Language Models (LLM), questa soluzione consente l'automazione di attività complesse, rendendo i processi più veloci, efficienti e accessibili attraverso le interazioni con il linguaggio naturale.
Una delle applicazioni più efficaci di OCI Generative AI è l'analisi dei documenti PDF. Le aziende spesso si occupano di grandi volumi di documenti, come contratti, report finanziari, manuali tecnici e documenti di ricerca. La ricerca manuale di informazioni in questi file può essere dispendiosa in termini di tempo e soggetta a errori.
Con l'uso dell'intelligenza artificiale generativa, è possibile estrarre informazioni in modo istantaneo e accurato, consentendo agli utenti di interrogare documenti complessi semplicemente formulando domande in linguaggio naturale. Ciò significa che invece di leggere intere pagine per trovare una clausola specifica in un contratto o un datapoint rilevante in un report, gli utenti possono semplicemente chiedere al modello, che restituisce rapidamente la risposta in base al contenuto analizzato.
Oltre al recupero delle informazioni, OCI Generative AI può essere utilizzata anche per riepilogare documenti lunghi, confrontare i contenuti, classificare le informazioni e persino generare insight strategici. Queste funzionalità rendono la tecnologia essenziale per vari campi, come legale, finanziario, sanitario e ingegneristico, ottimizzando il processo decisionale e aumentando la produttività.
Integrando questa tecnologia con strumenti come i servizi Oracle AI, OCI Data Science e le API per l'elaborazione dei documenti, le aziende possono creare soluzioni intelligenti che trasformano completamente il modo in cui interagiscono con i propri dati, rendendo il recupero delle informazioni più veloce ed efficace.
Prerequisiti
- Installare Python
version 3.10o versione successiva e l'interfaccia della riga di comando di Oracle Cloud Infrastructure (OCI CLI).
Task 1: Installa pacchetti Python
Il codice Python richiede determinate librerie per utilizzare l'AI generativa OCI. Eseguire il comando seguente per installare i pacchetti Python necessari.
pip install -r requirements.txt
Task 2: Comprendere il codice Python
Questa è una demo di OCI Generative AI per l'esecuzione di query sulle funzionalità di Oracle SOA Suite e Oracle Integration. Entrambi gli strumenti sono attualmente utilizzati per le strategie di integrazione ibrida, il che significa che operano sia in ambienti cloud che on-premise.
Poiché questi strumenti condividono funzionalità e processi, questo codice aiuta a capire come implementare lo stesso approccio di integrazione in ogni strumento. Inoltre, consente agli utenti di esplorare caratteristiche e differenze comuni.
Scarica il codice Python da qui:
Potete trovare i documenti PDF qui:
Creare una cartella denominata Manuals e spostarla in tale cartella.
-
Importa librerie:
Importa le librerie necessarie per l'elaborazione dei PDF, OCI Generative AI, la vettorializzazione del testo e lo storage nei database vettoriali (Facebook AI Similarity Search (FAISS) e ChromaDB).
-
UnstructuredPDFLoaderviene utilizzato per estrarre il testo dai PDF. -
ChatOCIGenAIconsente l'uso dei modelli di AI generativa OCI per rispondere alle domande. -
OCIGenAIEmbeddingscrea incorporamenti (rappresentazioni vettoriali) di testo per la ricerca semantica.
-
-
Carica ed elabora PDF:
Elenca i file PDF da elaborare.
-
UnstructuredPDFLoaderlegge ogni documento e lo divide in pagine per facilitare l'indicizzazione e la ricerca. -
Gli ID documento vengono memorizzati per riferimento futuro.

-
-
Configurare il modello AI generativa OCI:
Configura il modello
Llama-3.1-405bospitato in OCI per generare risposte in base ai documenti caricati.Definisce parametri quali
temperature(controllo della casualità),top_p(controllo della diversità) emax_tokens(limite token).
Nota: la versione LLaMA disponibile potrebbe cambiare nel tempo. Controllare la versione corrente nella tenancy e aggiornare il codice, se necessario.
-
Creare incorporamenti e indicizzazione vettoriale:
Utilizza il modello di incorporamento di Oracle per trasformare il testo in vettori numerici, facilitando le ricerche semantiche nei documenti.

-
FAISS memorizza le integrazioni dei documenti PDF per query rapide.
-
retrieverconsente di recuperare gli estratti più rilevanti in base alla somiglianza semantica della query dell'utente.

-
-
Nella prima esecuzione dell'elaborazione, i dati vettoriali verranno salvati in un database FAISS.

-
Definire il prompt:
Crea un prompt intelligente per il modello generativo, guidandolo a considerare solo i documenti pertinenti per ogni query.
Ciò migliora l'accuratezza delle risposte ed evita informazioni non necessarie.

-
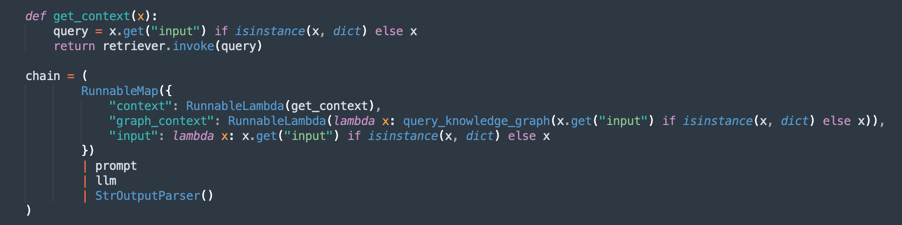
Creazione della catena di elaborazione (RAG - Retrieval-Augmented Generation):
Implementa un flusso RAG in cui:
retrievercerca gli estratti dei documenti più rilevanti.promptorganizza la query per un contesto migliore.llmgenera una risposta in base ai documenti recuperati.StrOutputParserformatta l'output finale.

-
Loop domanda e risposta:
Gestisce un ciclo in cui gli utenti possono porre domande sui documenti caricati.
-
L'intelligenza artificiale risponde utilizzando la knowledge base estratta dai PDF.
-
Se si immette
quit, il programma viene chiuso.

-
Ora è possibile scegliere 3 opzioni per elaborare i documenti. Si può pensare:
- Quanti poteri avete da elaborare?
- Quanto tempo è necessario per elaborare?
- Qual è la qualità delle sue risposte?
Sono pertanto disponibili le opzioni riportate di seguito.
Chunking a dimensioni fisse: questa è un'alternativa più rapida all'elaborazione dei documenti. Può essere sufficiente per ottenere ciò che si desidera.
Chunking semantico: questo processo sarà più lento del Chunking a dimensione fissa, ma offrirà più chunking di qualità.
Chunking semantico con GraphRAG: fornirà un metodo più preciso perché organizzerà i testi di chunking e i grafici della conoscenza.
Chunking a dimensione fissa
Scaricare il codice da qui: oci_genai_llm_context_fast.py.
-
Che cosa è Fixed Size Chunking?
Fixed Size Chunking è una strategia di frammentazione del testo semplice ed efficiente in cui i documenti sono divisi in blocchi in base a limiti di dimensione predefiniti, tipicamente misurati in token, caratteri o righe.
Questo metodo non analizza il significato o la struttura del testo. Semplicemente taglia il contenuto a intervalli fissi, indipendentemente dal fatto che il taglio avvenga nel mezzo di una frase, paragrafo o idea.
-
Come funziona il Chunking a dimensioni fisse:
-
Regola di esempio: suddivide il documento ogni 1000 token (o ogni 3000 caratteri).
-
Overlap facoltativo: per ridurre il rischio di frazionamento del context rilevante, alcune implementazioni aggiungono una sovrapposizione tra chunk consecutivi (ad esempio, sovrapposizione di 200 token) per garantire che context importante non venga perso al limite.
-
-
Vantaggi del Chunking a misura fissa:
-
Elaborazione rapida: non c'è bisogno di analisi semantica, inferenza LLM o comprensione del contenuto. Basta contare e tagliare.
-
Basso consumo di risorse: uso minimo di CPU/GPU e memoria, rendendolo scalabile per set di dati di grandi dimensioni.
-
Facile da implementare: funziona con script semplici o librerie di elaborazione testo standard.
-
-
Limiti del Chunking a dimensione fissa:
-
Pessima consapevolezza semantica: i chunk possono tagliare frasi, paragrafi o sezioni logiche, portando a idee incomplete o frammentate.
-
Ridotta precisione di recupero: in applicazioni come la ricerca semantica o la Retrieval-Augmented Generation (RAG), limiti di chunk scadenti possono influire sulla pertinenza e sulla qualità delle risposte recuperate.
-
-
Quando utilizzare il Chunking a dimensione fissa:
-
Quando la velocità di elaborazione e la scalabilità sono priorità assolute.
-
Per pipeline di inclusione di documenti su larga scala in cui la precisione semantica non è fondamentale.
-
Come primo passo in scenari in cui il perfezionamento o l'analisi semantica successivi avverranno a valle.
-
Questo è un metodo molto semplice per dividere il testo.

-
Questo è il processo principale di chunking fisso.

Nota: scaricare questo codice per elaborare il chunking fisso in modo più rapido :
oci_genai_llm_context_fast.py -
Chunking semantico
Scaricare il codice da qui: oci_genai_llm_context.py.
-
Che cosa è Semantic Chunking?
Il chunking semantico è una tecnica di pre-elaborazione del testo in cui documenti di grandi dimensioni (come PDF, presentazioni o articoli) vengono suddivisi in parti più piccole chiamate chunks, con ogni chunk che rappresenta un blocco di testo semanticamente coerente.
A differenza del tradizionale chunking a dimensione fissa (ad esempio, suddividendo ogni 1000 token o ogni X caratteri), Semantic Chunking utilizza l'intelligenza artificiale (in genere Large Language Models - LLM) per rilevare i confini dei contenuti naturali, rispettando argomenti, sezioni e context.
Invece di tagliare il testo in modo arbitrario, Semantic Chunking cerca di preservare il significato completo di ogni sezione, creando pezzi standalone e sensibili al contesto.
-
Perché il chunking semantico può rendere l'elaborazione più lenta?
Un processo di chunking tradizionale, basato su dimensioni fisse, è veloce. Il sistema conta solo token o caratteri e taglia di conseguenza. Con Semantic Chunking, sono necessari diversi passaggi aggiuntivi per l'analisi semantica:
- Lettura e interpretazione dell'intero testo (o dei blocchi di grandi dimensioni) prima della divisione: l'LLM deve comprendere il contenuto per identificare i limiti di chunk migliori.
- Esecuzione di prompt LLM o modelli di classificazione degli argomenti: il sistema spesso interroga l'LLM con domande come È la fine di un'idea? o Questo paragrafo inizia una nuova sezione?
- Memoria e uso di CPU/GPU più elevati: poiché il modello elabora blocchi di testo più grandi prima di prendere decisioni di chunk, il consumo di risorse è significativamente più elevato.
- Processo decisionale sequenziale e incrementale: il chunking semantico funziona spesso in passi (ad esempio, analizzando blocchi da 10.000 token e quindi perfezionando i limiti dei chunk all'interno di quel blocco), il che aumenta il tempo di elaborazione totale.
Nota:
- A seconda della potenza di elaborazione del computer, si attenderà molto tempo per finalizzare la prima esecuzione utilizzando Semantic Chunking.
- È possibile utilizzare questo algoritmo per produrre chunk personalizzati utilizzando l'AI generativa OCI.
-
Come funziona Semantic Chunking:
-
smart_split_text(): separa l'intero testo in piccole porzioni di 10 KB (è possibile configurare per adottare altre strategie). Il meccanismo percepisce l'ultimo paragrafo. Se parte del paragrafo è nella parte successiva del testo, questa parte verrà ignorata nell'elaborazione e verrà aggiunta al successivo gruppo di testo di elaborazione. -
semantic_chunk(): questo metodo utilizzerà il meccanismo LLM OCI per separare i paragrafi. Include l'intelligenza per identificare i titoli, i componenti di una tabella, i paragrafi per eseguire un pezzo intelligente. La strategia consiste nell'utilizzare la tecnica Semantic Chunk. Ci vorrà più tempo per completare la missione rispetto alla lavorazione comune. Quindi, la prima elaborazione richiederà molto tempo, ma la successiva caricherà tutti i dati pre-salvati FAISS. -
split_llm_output_into_chapters(): questo metodo finalizza il chunk separando i capitoli.
Nota: scaricare questo codice per elaborare il chunking semantico:
oci_genai_llm_context.py -
Chunking semantico con GraphRAG
Scaricare il codice da qui: oci_genai_llm_graphrag.py.
GraphRAG (Graph-Augmented Retrieval-Augmented Generation) è un'architettura AI avanzata che combina il recupero tradizionale basato su vettori con grafici della conoscenza strutturati. In una pipeline RAG standard, un modello di linguaggio recupera i blocchi di documenti pertinenti utilizzando la somiglianza semantica da un database vettoriale (come FAISS). Tuttavia, il recupero basato su vettori opera in modo non strutturato, basandosi esclusivamente su incorporamenti e metriche di distanza, che a volte perdono significati contestuali o relazionali più profondi.
GraphRAG migliora questo processo introducendo un livello di grafico knowledge, in cui entità, concetti, componenti e relative relazioni sono rappresentati in modo esplicito come nodi e bordi. Questo context basato su grafico consente al modello di linguaggio di ragionare su relazioni, gerarchie e dipendenze che la somiglianza vettoriale da sola non può acquisire.
-
Perché combinare il chunking semantico con GraphRAG?
Il chunking semantico è il processo di suddivisione intelligente di documenti di grandi dimensioni in unità significative o "chunks", in base alla struttura del contenuto, come capitoli, intestazioni, sezioni o divisioni logiche. Piuttosto che rompere i documenti puramente per limiti di carattere o ingenua divisione dei paragrafi, il chunking semantico produce chunk di alta qualità e sensibili al context che si allineano meglio con la comprensione umana.
-
Chunking semantico con GraphRAG Vantaggi:
-
Rappresentazione avanzata della conoscenza:
- I blocchi semantici conservano i confini logici nel contenuto.
- I Knowledge Graph estratti da questi chunk mantengono relazioni accurate tra entità, sistemi, API, processi o servizi.
-
Recupero contestuale multi-modale (il modello linguistico recupera entrambi):
- context non strutturato dal database vettoriale (similità semantica).
- context strutturato dal grafico della conoscenza (tripli entità-relazione).
- Questo approccio ibrido porta a risposte più complete e accurate.
-
Miglioramento delle capacità di ragionamento:
- Il recupero basato su grafici consente il ragionamento relazionale.
- LLM può rispondere a domande come:
- Da quali servizi dipende l'API Order?
- Quali componenti fanno parte di SOA Suite?
- Queste query relazionali sono spesso impossibili con approcci di sola incorporazione.
-
Maggiore spiegabilità e tracciabilità:
- Le relazioni grafiche sono leggibili e trasparenti.
- Gli utenti possono esaminare il modo in cui le risposte derivano dalle conoscenze sia testuali che strutturali.
-
Allucinazione ridotta: il grafico agisce come vincolo sull'LLM, ancorando le risposte alle relazioni verificate e alle connessioni fattuali estratte dai documenti di origine.
-
Scalabilità tra domini complessi:
- Nei domini tecnici (ad esempio, API, microservizi, contratti legali, standard sanitari), le relazioni tra i componenti sono importanti quanto i componenti stessi.
- GraphRAG combinato con scale di chunking semantico in modo efficace in questi contesti, preservando sia la profondità testuale che la struttura relazionale.
Nota:
- Scarica il codice per elaborare il chunking semantico con graphRAG da qui:
oci_genai_llm_graphrag.py. - Sarà necessario effettuare quanto riportato di seguito.
- Un docker installato e attivo per utilizzare il database del sistema operativo del grafico open source Neo4J da sottoporre a test.
- Installare la libreria Python neo4j.
Ci sono 2 metodi in questo codice:
-
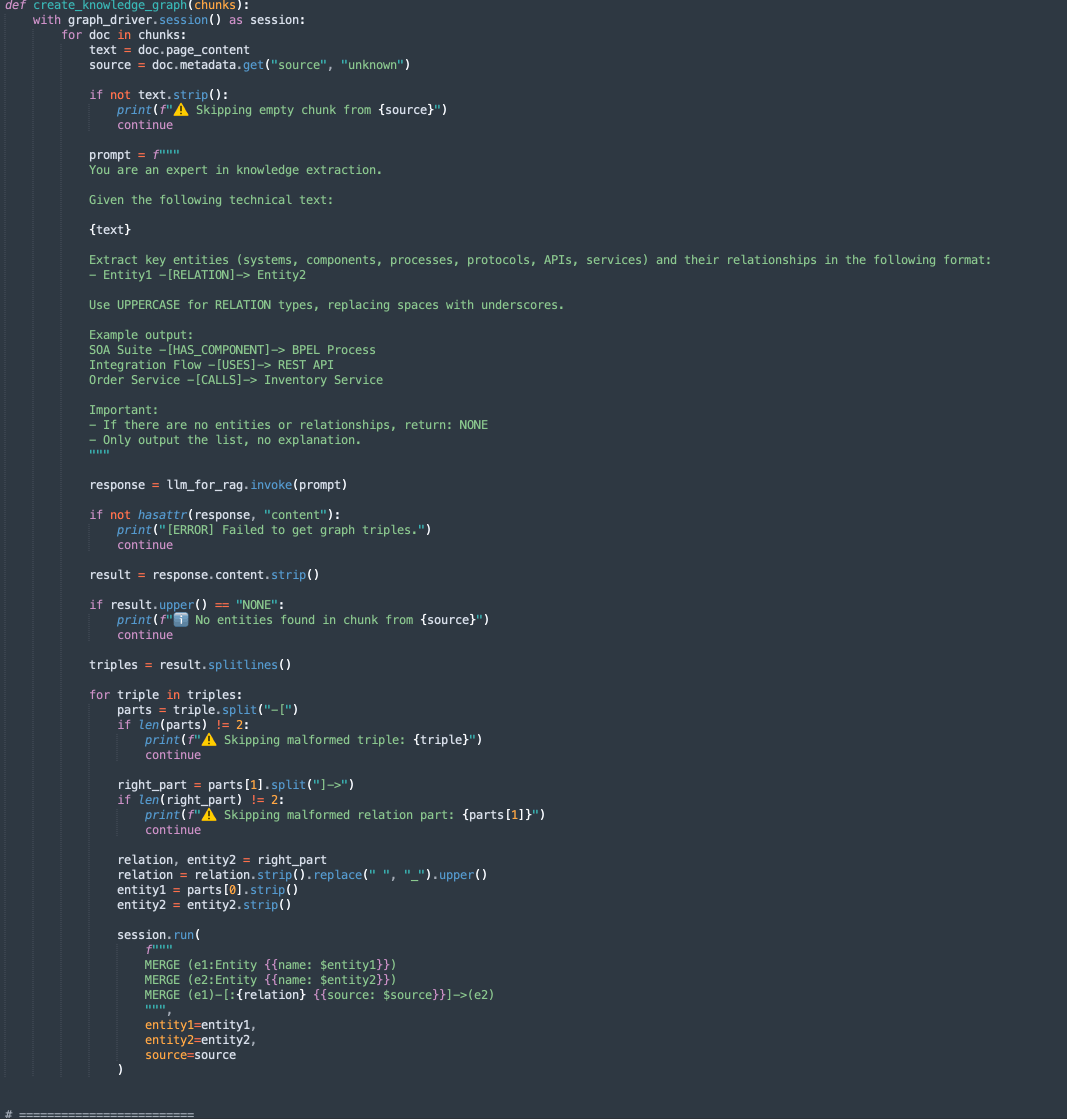
create_knowledge_graph:-
Questo metodo estrae automaticamente entità e relazioni da chunk di testo e le memorizza in un grafico knowledge Neo4j.
-
Per ogni documento chunk, invia il contenuto a un LLM (Large Language Model) con un prompt che chiede di estrarre entità (come sistemi, componenti, servizi, API) e le loro relazioni.
-
Analizza ogni riga, estrae Entity1, RELATION e Entity2.
-
Memorizza queste informazioni come nodi e bordi nel database del grafico Neo4j utilizzando le query Cypher:
MERGE (e1:Entity {name: $entity1}) MERGE (e2:Entity {name: $entity2}) MERGE (e1)-[:RELATION {source: $source}]->(e2)
-
-
-
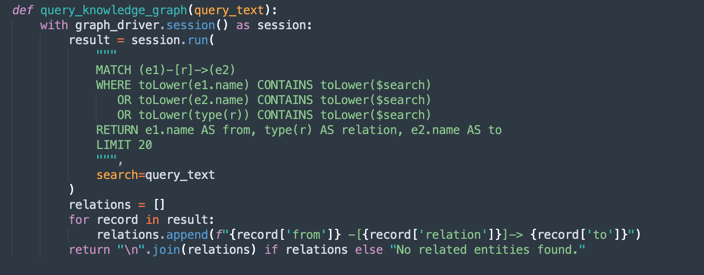
query_knowledge_graph:-
Questo metodo esegue una query sul grafico knowledge Neo4j per recuperare le relazioni correlate a una parola chiave o un concetto specifico.
-
Esegue una query Cypher che cerca:
Any relationship (e1)-[r]->(e2) Where e1.name, e2.name, or the relationship type contains the query_text (case-insensitive). -
Restituisce fino a 20 tripli corrispondenti formattati come:
Entity1 -[RELATION]-> Entity2
-
Nota:
Neo4j Uso:
Questa implementazione utilizza Neo4j come database di knowledge graph incorporato a scopo dimostrativo e di prototipazione. Sebbene Neo4j sia un database a grafici potente e flessibile adatto per carichi di lavoro di sviluppo, test e di piccole e medie dimensioni, potrebbe non soddisfare i requisiti per carichi di lavoro di livello enterprise, mission-critical o altamente sicuri, soprattutto in ambienti che richiedono alta disponibilità, scalabilità e compliance di sicurezza avanzata.
Per gli ambienti di produzione e gli scenari aziendali, si consiglia di utilizzare Oracle Database con funzionalità Graph che offrono:
Affidabilità e sicurezza di livello Enterprise.
Scalabilità per i carichi di lavoro mission-critical.
Modelli grafici nativi (Property Graph e RDF) integrati con dati relazionali.
Funzionalità avanzate di analitica, sicurezza, alta disponibilità e disaster recovery.
Integrazione completa di Oracle Cloud Infrastructure (OCI).
Utilizzando Oracle Database per i carichi di lavoro grafici, le organizzazioni possono unificare dati strutturati, semistrutturati e grafici all'interno di un'unica piattaforma aziendale sicura e scalabile.
Task 3: Esegui query per i contenuti di Oracle Integration e Oracle SOA Suite
Eseguire il comando riportato di seguito.
FOR FIXED CHUNKING TECHNIQUE (MORE FASTER METHOD)
python oci_genai_llm_context_fast.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
FOR SEMANTIC CHUNKING TECHNIQUE
python oci_genai_llm_context.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
FOR SEMANTIC CHUNKING COMBINED WITH GRAPHRAG TECHNIQUE
python oci_genai_llm_graphrag.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
Nota: i parametri
--devicee--gpu_namepossono essere utilizzati per accelerare l'elaborazione in Python, utilizzando la GPU se il computer ne dispone. Si consideri che questo codice può essere utilizzato anche con i modelli locali.
Il contesto fornito distingue Oracle SOA Suite e Oracle Integration. È possibile eseguire il test del codice considerando i punti riportati di seguito.
- La query deve essere eseguita solo per Oracle SOA Suite: pertanto, devono essere considerati solo i documenti di Oracle SOA Suite.
- La query deve essere eseguita solo per Oracle Integration: pertanto, devono essere considerati solo i documenti di Oracle Integration.
- La query richiede un confronto tra Oracle SOA Suite e Oracle Integration: pertanto, tutti i documenti devono essere considerati.
Possiamo definire il seguente contesto, che aiuta notevolmente a interpretare correttamente i documenti.
L'immagine seguente mostra l'esempio di confronto tra Oracle SOA Suite e Oracle Integration.

Passi successivi
Questo codice illustra un'applicazione di OCI Generative AI per l'analisi PDF intelligente. Consente agli utenti di eseguire query su grandi volumi di documenti in modo efficiente utilizzando ricerche semantiche e un modello di intelligenza artificiale generativa per generare risposte accurate in linguaggio naturale.
Questo approccio può essere applicato in vari campi, come legale, compliance, supporto tecnico e ricerca accademica, rendendo il recupero delle informazioni molto più veloce e intelligente.
Collegamenti correlati
-
Bridging dell'AI cloud e conversazionale: piattaforma LangChain e OCI Data Science
-
Introduzione agli agenti LangChain Python personalizzati e integrati
Conferme
- Autore - Cristiano Hoshikawa (Solution Engineer A-Team di Oracle LAD)
Altre risorse di apprendimento
Esplora altri laboratori su docs.oracle.com/learn o accedi a più contenuti di formazione gratuiti sul canale YouTube di Oracle Learning. Inoltre, visitare education.oracle.com/learning-explorer per diventare Oracle Learning Explorer.
Per la documentazione del prodotto, visitare Oracle Help Center.
Analyze PDF Documents in Natural Language with OCI Generative AI
G29540-05
Copyright ©2025, Oracle and/or its affiliates.