Oracle NoSQL Database Cloud Serviceでの表の設計
Oracle NoSQL Database Cloud Serviceで表を設計および構成する方法について学習します。
この記事には次のトピックが含まれます:
表フィールド
表フィールドを使用してデータを設計および構成する方法について学習します。
アプリケーションでは、行がキー・フィールドと単一のJSONデータ・フィールドで構成されるスキームレス表を使用するように選択することができます。スキーマレス表は、何を行に格納できるかという点で柔軟性があります。
また、アプリケーションでは、すべての表フィールドが特定の型として定義された固定スキーマ表を使用するように選択することもできます。
強制的に適用されることと、ストレージの効率という観点から、型指定されたデータからなる固定スキーマ表がより安全です。固定スキーマ表のスキーマは変更できますが、その表の構造は簡単には変更できません。スキーマレス表は柔軟性があり、表構造を簡単に変更できます。
最後に、アプリケーションでは、表に型指定されたデータとJSONデータ・フィールドを含めることができるハイブリッド・データ・モデルのアプローチを使用することもできます。
次の各例では、3つすべてのアプローチを使用してデータを設計および構成する方法を示します。
例1: スキーマレス表の設計
パターンの参照に関する情報を表に格納する場合、複数のオプションがあります。オプションの1つは、Cookie IDをキーとして使用し、オーディエンス・セグメンテーション・データを単一のJSONフィールドとして保持する表を定義することです。
// schema less, data is stored in a JSON field
CREATE TABLE audience_info (
cookie_id LONG,
audience_data JSON,
PRIMARY KEY(cookie_id))この場合、audience_info表には次のようなJSONオブジェクトを格納できます:
{
"cookie_id": "",
"audience_data": {
"ipaddr" : "
10.0.00.xxx",
"audience_segment: {
"sports_lover" : "2018-11-30",
"book_reader" : "2018-12-01"
}
}
}アプリケーションは、この表に対して1つのキー・フィールドと1つのデータ・フィールドを持つことになります。audience_dataフィールドに何を情報として格納するかは、柔軟に選択できます。したがって、使用可能な情報のタイプは簡単に変更できます。
例2: 固定スキーマ表の設計
より明示的に宣言されたフィールドからなる表を作成することにより、パターンの参照に関する情報を格納できます。
// fixed schema, data is stored in typed fields.
CREATE TABLE audience_info(
cookie_id LONG,
ipaddr STRING,
audience_segment RECORD(sports_lover TIMESTAMP(9),
book_reader TIMESTAMP(9)),
PRIMARY KEY(cookie_id))この例では、表は1つのキー・フィールドと2つのデータ・フィールドを持ちます。データはよりコンパクトになり、すべてのデータ・フィールドが正確であることを保証できます。
例3: ハイブリッド表の設計
型指定されたデータ・フィールドとJSONデータ・フィールドの両方を表で使用することにより、パターンの参照に関する情報を格納できます。
// mixed, data is stored in both typed and JSON fields.
CREATE TABLE audience_info (
cookie_id LONG,
ipaddr STRING,
audience_segment JSON,
PRIMARY KEY(cookie_id))主キーとシャード・キー
アプリケーション設計中の主キーとシャード・キーの目的について学習します。
主キーおよびシャード・キーはスキーマの重要な要素であり、データへの効率的なアクセスと分散に役立ちます。主キーとシャード・キーを作成するのは、表を作成するときのみです。これらは、表の存続期間中はそのまま維持され、変更や削除はできません。
主要キー
表を作成するときには、1つ以上の主キー列を指定する必要があります。主キーは、表のすべての行を一意に識別します。単純なCRUD操作の場合、Oracle NoSQL Database Cloud Serviceは、主キーを使用して、読取りまたは変更対象の特定の行を取得します。たとえば、表に次のフィールドがある場合を考えてみます:
-
productName -
productType -
productLine
製品名が重要であり、それが行ごとに一意であることが経験からわかっているため、productNameを主キーとして設定します。次に、productNameに基づいて、目的の行を取得します。このような場合、次のような文を使用して表を定義します。
/* Create a new table called users. */
CREATE TABLE if not exists myProducts
(
productName STRING,
productType STRING,
productLine INTEGER,
PRIMARY KEY (productName)
)"シャード・鍵
シャード・キーの主な目的は、効率を高めるためにOracle NoSQL Database Cloud Serviceクラスタ全体にデータを分散し、参照およびアクセスが容易になるようにシャード・キーがローカルに共有するレコードを配置することです。シャード・キーを共有するレコードは同じ物理的ロケーションに格納され、アトミックかつ効率的にアクセスできます。
主キーとシャード・キーの設計は、プロビジョニングされたスループットのスケーリングと実現に影響を及ぼします。たとえば、レコード間でシャード・キーを共有している場合、1回のアトミック操作で複数の表の行を削除したり、1回のアトミック操作で表の行のサブセットを取得することができます。適切に設計されたシャード・キーは、スケーラビリティを実現できるだけでなく、データの適用に必要なサイクル数を減らすことでパフォーマンスを改善したり、単一のシャードからデータを取得することができます。
たとえば、次の3つの主キー・フィールドを指定したとします:
PRIMARY KEY (productName, productType, productLine)アプリケーションでproductName列とproductType列を使用した問合せが頻繁に行われていることがわかっているため、これらのフィールドはシャード・キーとして指定することが適切です。シャード・キーの指定によって、この2つの列に対するすべての行は必ず同じシャードに格納されます。この2つのフィールドをシャード・キーにしないで、問合せ頻度が最も高い列を任意のシャードに格納することもできます。この場合、両方のフィールドのすべての行を検索するのに、1つのシャードではなくすべてのデータ・ストレージをスキャンする必要があります。
シャード・キーは、キー値の問合せを効率化するために、同じシャード上の記憶域を指定します。ただし、最適なパフォーマンスを実現するためにはデータをシャード間で分散する必要があるため、一意の値をほとんど持たないシャード・キーは避ける必要があります。
ノート:表の作成時にシャード・キーを指定しない場合、Oracle NoSQL Database Cloud Serviceではシャード編成に主キーが使用されます。
シャード・キーの選択時に考慮する重要な要因
-
カーディナリティ:カーディナリティの低いフィールド(ユーザーの国など)では、レコードが数個のシャード上にまとめられます。また、これらのシャードでは頻繁にデータ・リバランスを行う必要があるため、ホット・シャードの問題が発生する可能性が高まります。一方、各シャード・キーのカーディナリティが高い場合、シャード・キーはデータ・セット内のレコードの均一なスライスを表すことができます。たとえば、
customerID、userID、productIDなどのID番号は、シャード・キーの候補として適しています。 -
原子性:同じシャード・キーを共有するオブジェクトのみがトランザクションに参加できます。複数のレコードにわたるACIDトランザクションが必要な場合は、その要件を満たすことができるシャード・キーを選択します。
ベスト・プラクティスは何か
-
シャード・キーの均一分散:シャード・キーを均等に分散している場合、1つのシャードでシステムの容量が制限されることはありません。
-
問合せの分離:効率とパフォーマンスを最大限にするために、問合せのターゲットを特定のシャードに制限する必要があります。問合せが単一のシャードに分離されていない場合、問合せはすべてのシャードに適用されるため、効率が低下し、問合せレイテンシも増加します。
TableRequestオブジェクトを使用して主キーおよびシャード・キーを割り当てる方法を学習するには、表の作成を参照してください。
存続時間
存続時間(TTL)機能を使用して表および行の有効期限を指定する方法について学習します。
多くのアプリケーションでは、限定的な存続期間が設定されたデータが処理されます。存続時間(TTL)は、表の行に時間枠を設定できるメカニズムであり、その時間枠を設定すると、行が自動的に期限切れになり、使用できなくなります。これは、データがOracle NoSQL Database Cloud Service内に存続できる期間です。有効期限に達したデータは取得できなくなり、どのストレージ統計にも表示されません。
デフォルトでは、作成するすべての表に、有効期限がないことを示す0のTTL値が設定されます。TTL値を宣言するには、表を作成するときに、数値でTTLを指定し、その後にHOURSまたはDAYSを指定します。表の行に明示的にTTL値を設定しないかぎり、表の行にはその行が存在する表のTTL値が継承されます。行のTTL値を設定すると、表のTTL値が上書きされます。行のTTL値がすで側にある場合に表のTTL値を変更すると、行のTTL値が残ります。
表の行のTTL値は、行が有効期限に達するまでいつでも更新できます。期限切れのデータにはアクセスできなくなります。したがって、TTL値を使用すると、データ削除のためにデータベース・ログ・エントリを書き込むオーバーヘッドを回避できるため、手動で行を削除するよりも効率的です。期限切れのデータは、有効期限後にディスクからパージされます。
表の状態およびライフ・サイクル
様々な表の状態とその重要度(表のライフ・サイクル・プロセス)について学習します。
それぞれの表は、表の作成から削除まで、一連の様々な状態を経過します。たとえば、DROPPING状態の表はACTIVE状態に移行できませんが、ACTIVE状態の表はUPDATING状態に変わることができます。表のライフ・サイクルをモニタリングすることにより、表の様々な状態をトラッキングできます。この項では、表の様々な状態について説明します。
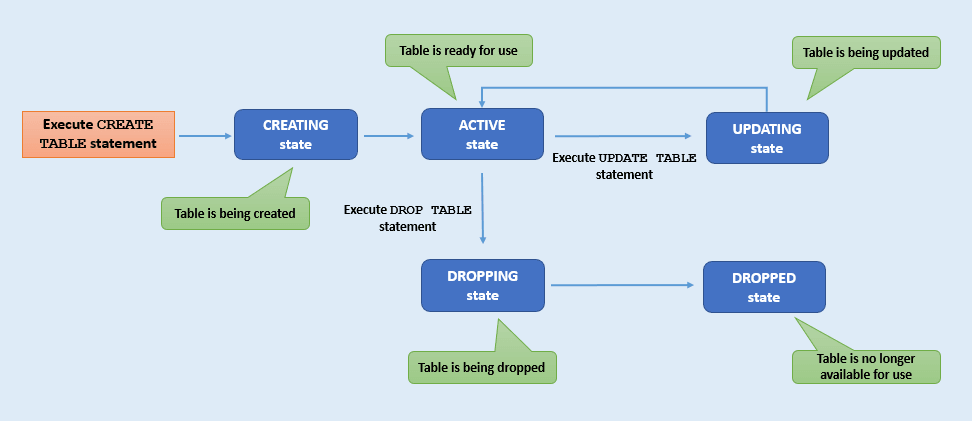
| 表の状態 | 説明 |
|---|---|
CREATING |
表は作成処理中です。これで、使用する準備ができていません。 |
UPDATING |
表の更新が進行中です。表がこの状態にある間、さらに表に変更を加えることはできません。 次の場合、表は
|
ACTIVE |
表は現在の状態で使用できます。表は最近作成または変更された可能性がありますが、表の状態は現在安定しています。 |
DROPPING |
表は削除中であり、どのような目的でもアクセスできません。 |
DROPPED |
表はすでに削除され、読取り、書込みまたは問合せのアクティビティの対象としてもう存在していません。 ノート:削除すると、同じ名前の表をもう一度作成できます。 |
表階層
Oracle NoSQL Databaseでは、表を親子関係にすることができます。これを表階層といいます。
CREATE TABLE文を使用すると、表を別の表の子として作成でき、その別の表が新しい表の親になります。これは、子表のコンポジット名(name_path)を使用して実行します。コンポジット名は、ドットで区切られたN個(N > 1)の識別子で構成されます。最後の識別子が子表のローカル名であり、最初のN-1の識別子が親の名前を示します。
親子表の特性:
-
子表は、親表の主キー列を継承します。
-
階層内のすべての表には同じシャード・キー列があり、これらはルート表のCREATE TABLE文に指定されています。
-
子が削除される前に親表を削除することはできません。
-
参照整合性制約は、親子表では適用されません。
なんらかの形式のデータ正規化が必要な場合、子表の使用を検討する必要があります。子表は、1対Nの関係をモデル化する場合にも適しており、また、親子階層に複数のレコードを記述する際にはACIDトランザクション・セマンティクスを提供します。