ノート:
- このチュートリアルではOracle Cloudへのアクセスが必要です。無料アカウントにサインアップするには、Oracle Cloud Infrastructure Free Tierの開始を参照してください。
- Oracle Cloud Infrastructure資格証明、テナンシおよびコンパートメントの値の例を使用します。演習を完了する場合は、これらの値をクラウド環境に固有の値に置き換えてください。
Apache Spark StreamingでOCIデータ・フローを使用して、スケーラブルでほぼリアルタイムのアプリケーションでKafkaトピックを処理します
イントロダクション
Oracle Cloud Infrastructure (OCI) Data Flowは、Apache Sparkというオープンソース・プロジェクトの管理対象サービスです。基本的に、Sparkでは、大規模処理ファイル、ストリーミングおよびデータベース操作に使用できます。非常に高いスケーラブルな処理でアプリケーションを構築できます。Sparkでは、クラスタ化されたマシンをスケーリングして使用し、最小構成でジョブを解析できます。
Sparkを管理対象サービス(データ・フロー)として使用すると、多くのスケーラブル・サービスを追加して、クラウド処理能力を乗算できます。データ・フローには、Sparkストリーミングを処理する機能があります。
ストリーミング・アプリケーションでは、24時間を超えることが多く、数週間または数か月間続く長期間の継続実行が必要です。予期しない障害が発生した場合、ストリーミング・アプリケーションは、誤った計算結果を生成せずに障害発生時点から再起動する必要があります。データ・フローは、Spark構造化ストリーミング・チェックポイントに依存して、オブジェクト・ストレージ・バケットに格納できる処理済オフセットを記録します。
ノート:データをバッチ戦略として処理する必要がある場合は、次の記事をお読みください: Oracle Cloud Infrastructure Data FlowでのAutonomous DatabaseおよびKafkaでの大規模ファイルの処理
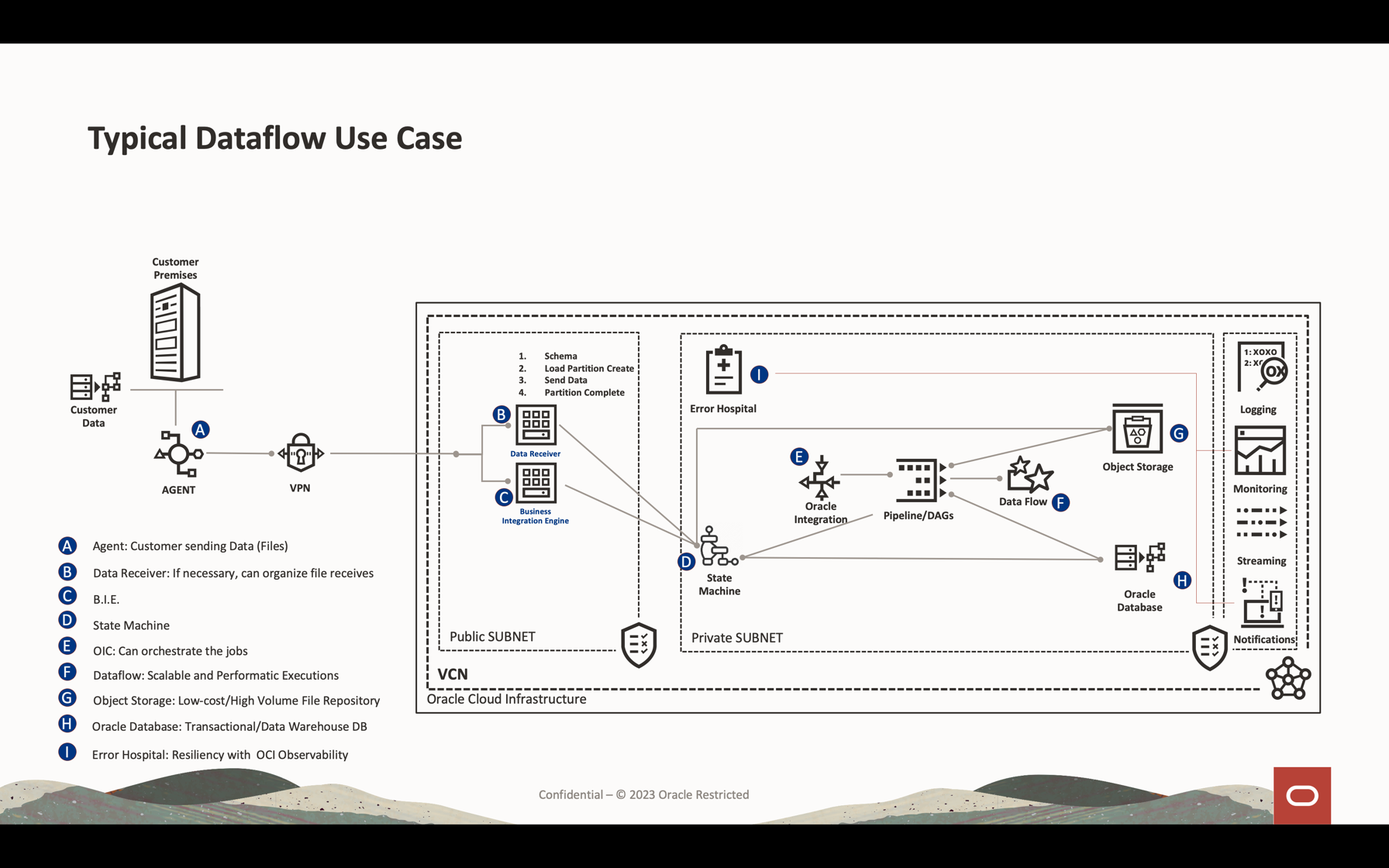
このチュートリアルでは、データ・ボリューム・ストリーミングの処理、データベースの問合せおよびデータのマージ/結合に使用される最も一般的なアクティビティを確認して、メモリー内の別の表を形成したり、データをほぼリアルタイムで任意の宛先に送信できます。この大量のデータをデータベースおよびKafkaキューに書き込むことができ、非常に低コストで非常に効果的なパフォーマンスを実現できます。
目的
- データ・フローを使用して、スケーラブルでほぼリアルタイムのアプリケーションにおいて大量のデータを処理する方法を説明します。
前提条件
-
運用中のOracle Cloudテナント: 1か月あたりUS$ 300.00の無料のOracle Cloudアカウントを作成して、このチュートリアルを試すことができます。無料Oracle Cloudアカウントを作成を参照してください
-
ローカル・マシンにインストールされたOCI CLI (Oracle Cloudコマンドライン・インタフェース): これは、OCI CLIをインストールするためのリンクです。
-
ローカル・マシンにインストールされているApache Sparkアプリケーション。ローカルおよびデータ・フローでの開発方法を理解するには、ローカルでのOracle Cloud Infrastructure Data Flowアプリケーションの開発、クラウドへのデプロイを参照してください。
ノート: これは、Apache Sparkをインストールするための公式ページです。オペレーショナル・システム(Linux/Mac OS/Windows)のタイプごとにApache Sparkをインストールする別の手順があります。
-
Spark Submit CLIがインストールされています。これは、Spark Submit CLIをインストールするためのリンクです。
-
ローカル・マシンにインストールされたMaven。
-
OCIの概念の知識:
- 区分
- IAMポリシー
- テナント
- リソースのOCID
タスク1: Object Storage構造の作成
Object Storageは、デフォルトのファイル・リポジトリとして使用されます。他のタイプのファイル・リポジトリを使用できますが、Object Storageは、パフォーマンスに優れたファイルを操作するためのシンプルで低コストの方法です。このチュートリアルでは、両方のアプリケーションがオブジェクト・ストレージから大きなCSVファイルをロードし、Apache Sparkが高速で大量のデータを処理するスマートさを示します。
-
コンパートメントの作成: クラウド・リソースを編成および分離するには、コンパートメントが重要です。IAMポリシーによってリソースを分離できます。
-
このリンクを使用して、コンパートメントのポリシーを理解および設定できます: コンパートメントの管理
-
1つのコンパートメントを作成して、このチュートリアルの2つのアプリケーションのすべてのリソースをホストします。analyticsという名前のコンパートメントを作成します。
-
Oracle Cloudのメイン・メニューに移動し、「アイデンティティとセキュリティ」、「コンパートメント」を検索します。「コンパートメント」セクションで、「コンパートメントの作成」をクリックし、名前を入力します。
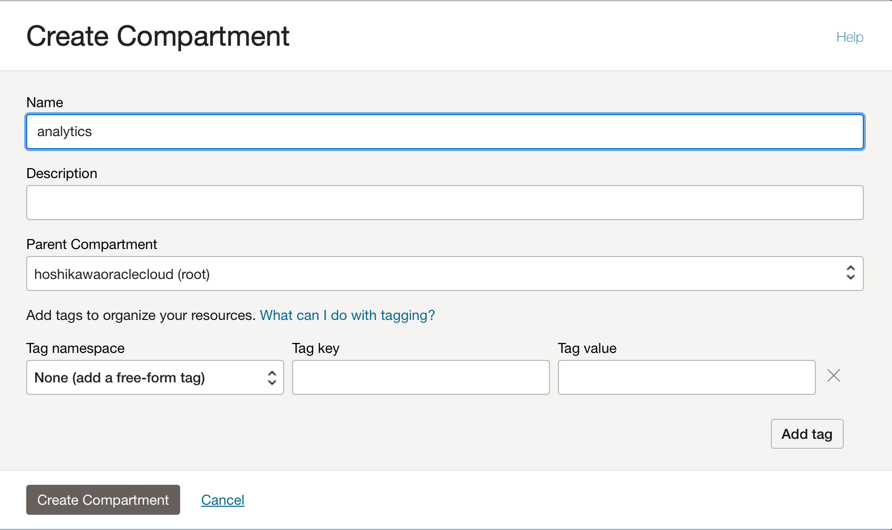
ノート: ユーザーのグループへのアクセス権を付与し、ユーザーを含める必要があります。
-
「コンパートメントの作成」をクリックして、コンパートメントを含めます。
-
-
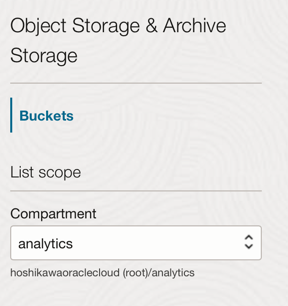
オブジェクト・ストレージでのバケットの作成: バケットはオブジェクトを格納するための論理コンテナであるため、このデモに使用されるすべてのファイルはこのバケットに格納されます。
-
Oracle Cloudのメイン・メニューに移動し、「ストレージ」および「バケット」を検索します。「バケット」セクションで、前に作成したコンパートメント(分析)を選択します。
-
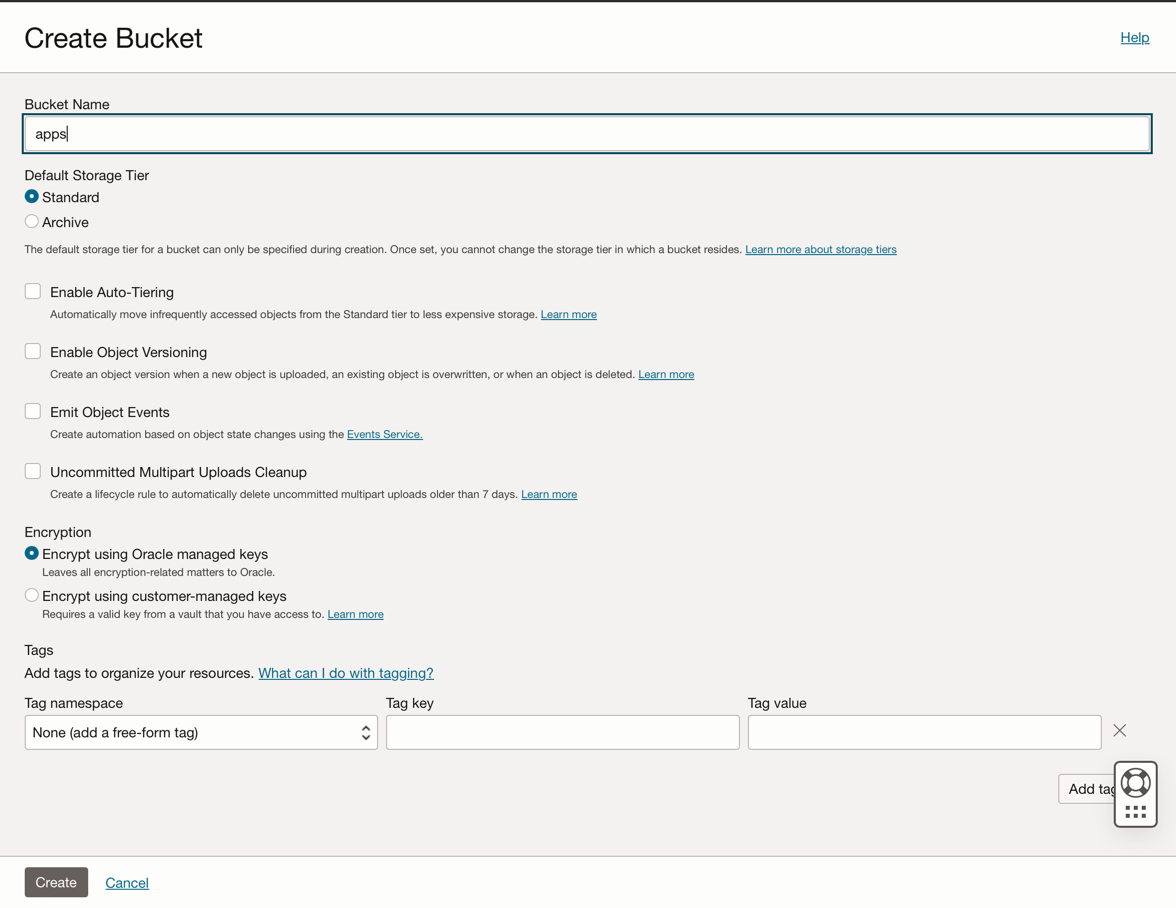
「バケットの作成」をクリックします。4つのバケットを作成します: apps、data、dataflow-logs、Wallet
-
これらの4つのバケットとともにバケット名情報を入力し、デフォルトの選択で他のパラメータを保守します。
-
バケットごとに、「作成」をクリックします。作成されたバケットを確認できます。
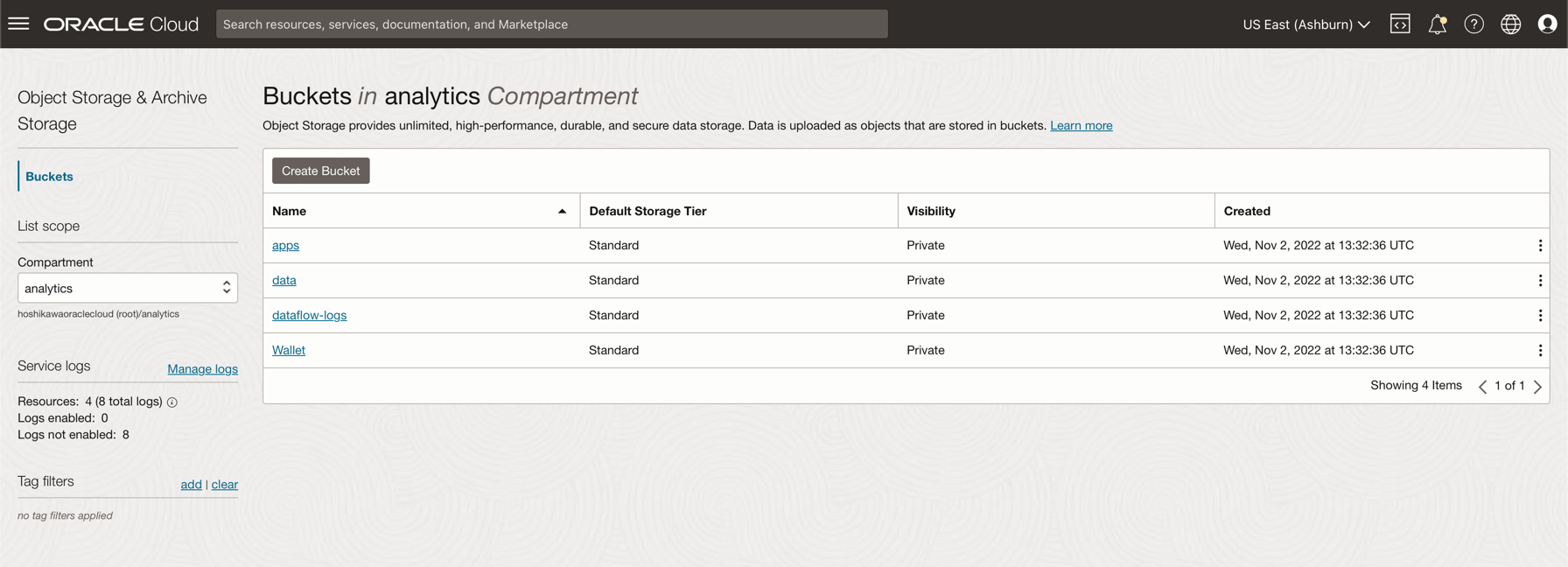
-
ノート:バケットのIAMポリシーを確認します。デモ・アプリケーションでこれらのバケットを使用する場合は、ポリシーを設定する必要があります。オブジェクト・ストレージの概要およびIAMポリシーで、概念および設定を確認できます。
タスク2: Autonomous Databaseの作成
Oracle Cloud Autonomous Databaseは、Oracle Databaseの管理対象サービスです。このチュートリアルでは、アプリケーションはセキュリティ上の理由からWalletを介してデータベースに接続します。
-
Autonomous Databaseのプロビジョニングの説明に従って、Autonomous Databaseをインスタンス化します。
-
Oracle Cloudのメイン・メニューから、「データ・ウェアハウス」オプションを選択し、「Oracle Database」および「Autonomous Data Warehouse」を選択して、コンパートメント分析を選択し、チュートリアルに従ってデータベース・インスタンスを作成します。
-
インスタンスに「Processed Logs」という名前を付け、データベース名として「logs」を選択し、アプリケーションのコードを変更する必要はありません。
-
ADMINパスワードを入力し、Wallet zipファイルをダウンロードします。
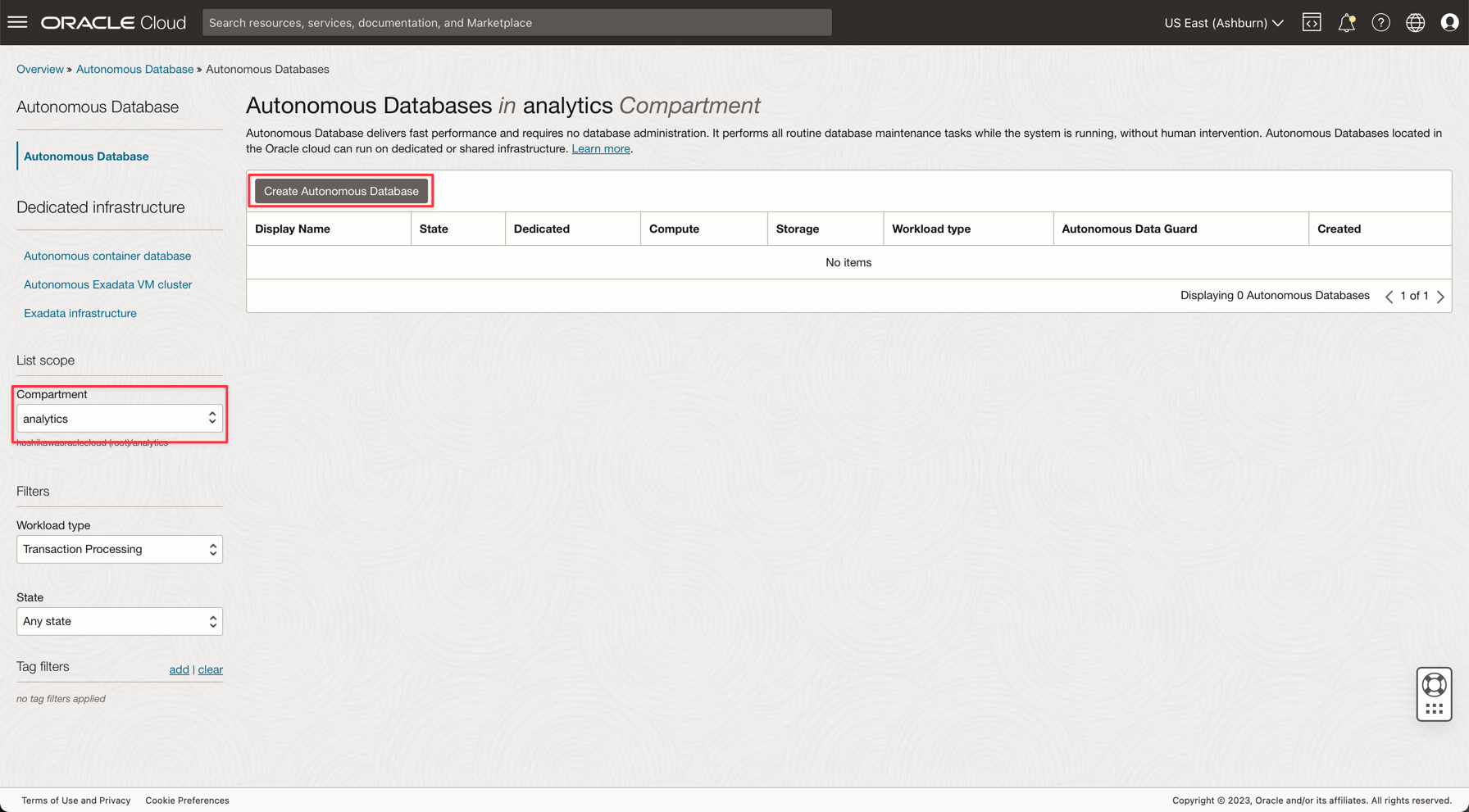
-
データベースの作成後、ADMINユーザー・パスワードを設定し、Wallet zipファイルをダウンロードできます。
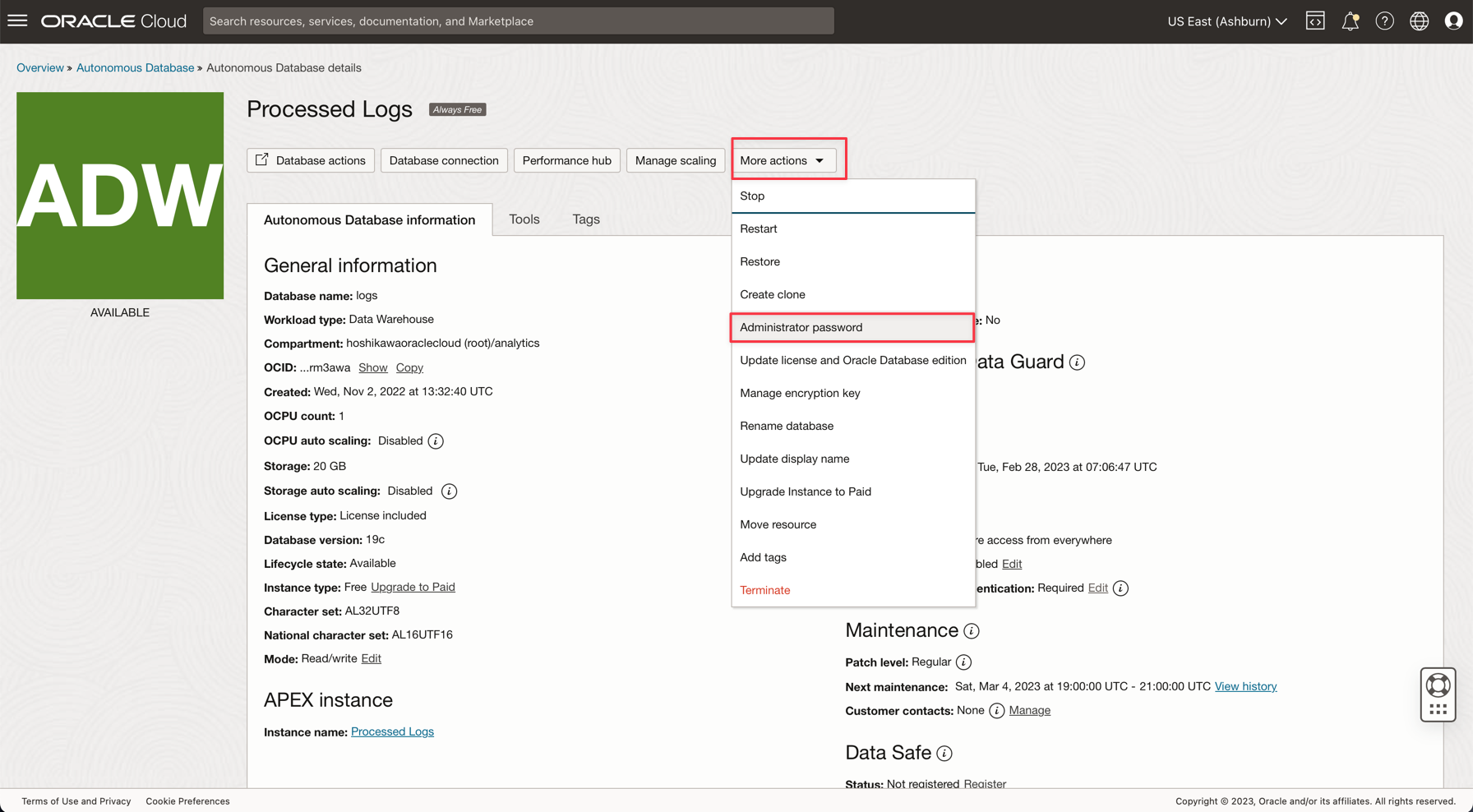
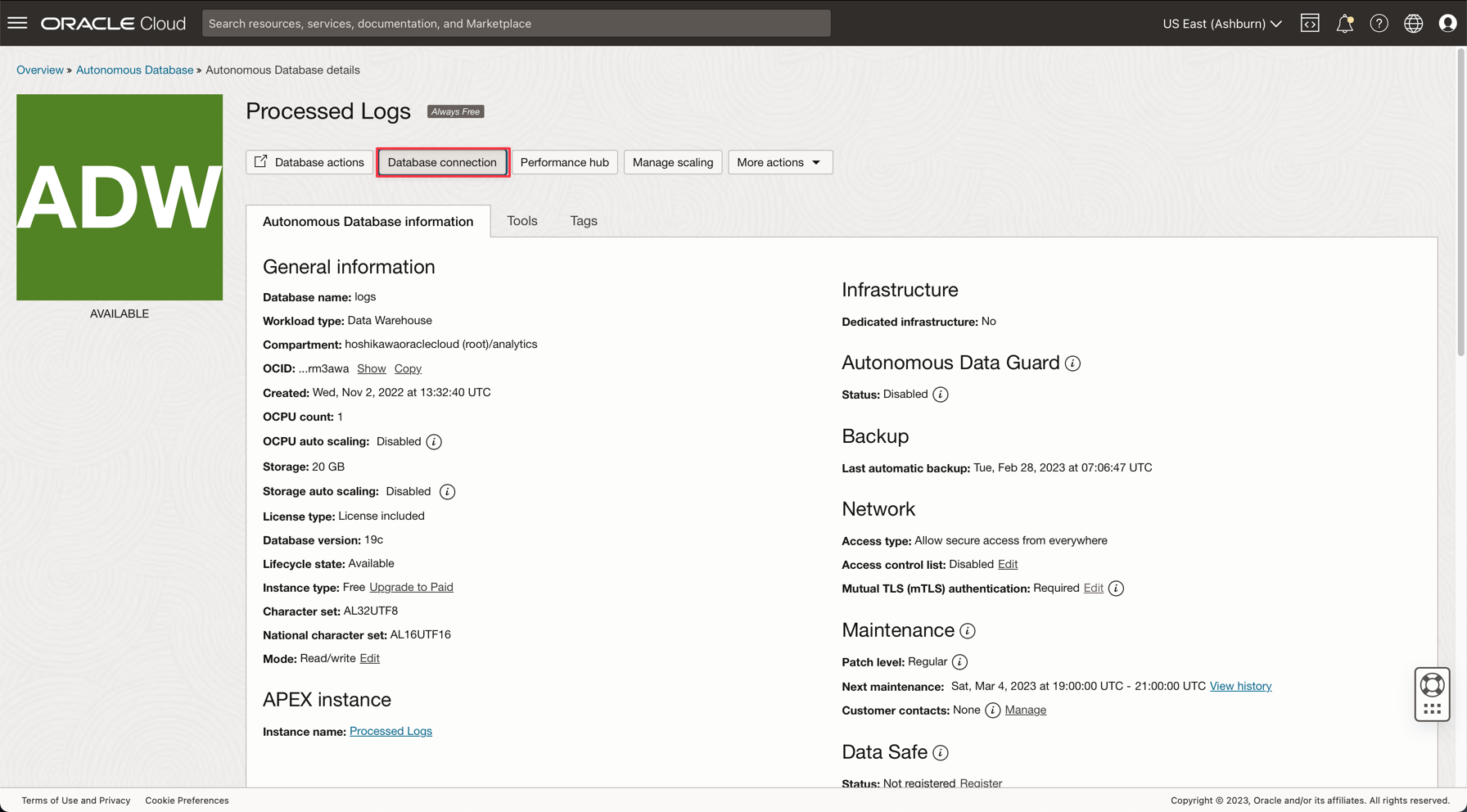
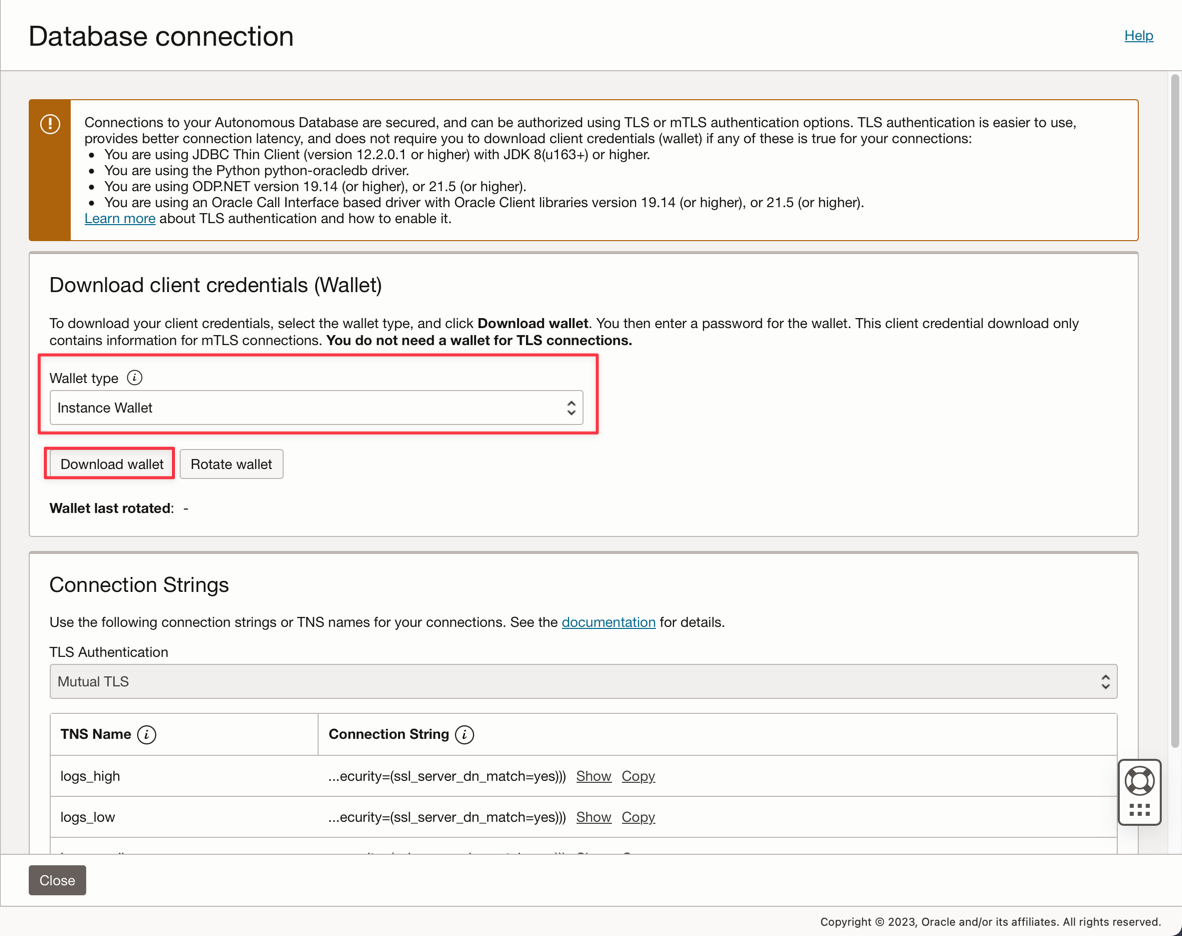
-
Wallet zipファイル(
Wallet_logs.zip)を保存し、ADMINパスワードに注釈を付けます。アプリケーション・コードを設定する必要があります。 -
「ストレージ」、「バケット」に移動します。analyticsコンパートメントに変更すると、Walletバケットが表示されます。これをクリックします。
-
Wallet zipファイルをアップロードするには、「Upload」をクリックして、Wallet_logs.zipファイルを添付します。
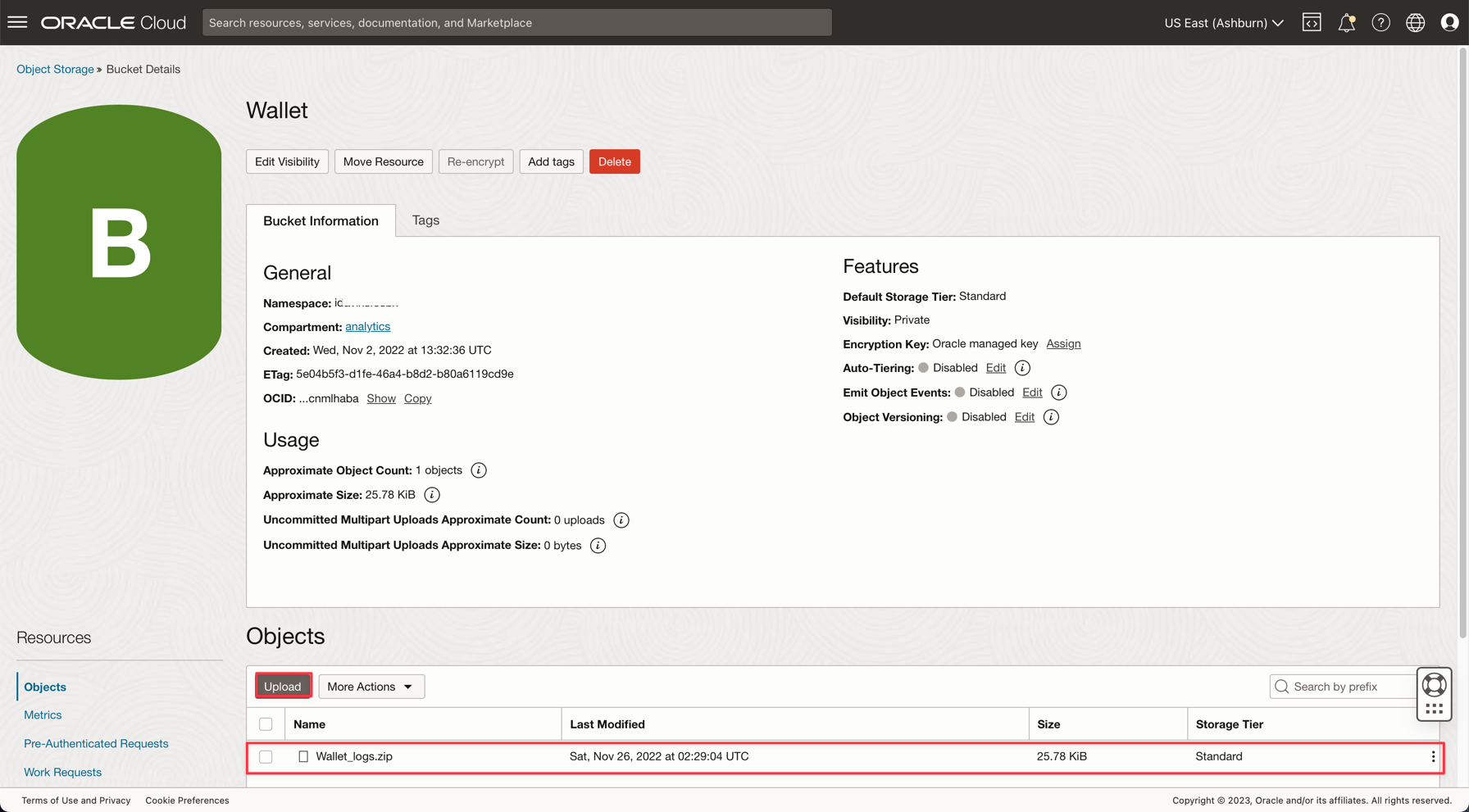
ノート: Autonomous DatabaseにアクセスするためのIAMポリシーを確認します(Autonomous DatabaseのIAMポリシー)。
タスク3: CSVサンプル・ファイルのアップロード
Apache Sparkのパワーを示すために、アプリケーションは1,000,000行のCSVファイルを読み取ります。このデータは、1つのコマンドラインでAutonomous Data Warehouseデータベースに挿入され、Kafkaストリーミング(Oracle Cloud Streaming)で公開されます。これらのリソースはすべてスケーラブルで、大量のデータに適しています。
-
次の2つのリンクをダウンロードし、データ・バケットにアップロードします:
-
ノート:
- organizations.csvには、ローカルマシン上でアプリケーションをテストするだけの100行しかありません。
- organizations1M.csvには1,000,000行が含まれ、データ・フロー・インスタンスでの実行に使用されます。
-
Oracle Cloudのメイン・メニューから、「ストレージ」および「バケット」に移動します。データ・バケットをクリックし、前のステップの2つのファイルをアップロードします。

-
ADWデータベースへの補助表のアップロード
-
このファイルをダウンロードしてADWデータベースにアップロードします: GDP PER CAPTA COUNTRY.csv
-
Oracle Cloudのメイン・メニューから、「Oracle Database」および「Autonomous Data Warehouse」を選択します。
-
「処理済ログ」インスタンスをクリックして詳細を表示します。
-
「データベース・アクション」をクリックして、データベース・ユーティリティに移動します。

-
ADMINユーザーの資格証明を入力します。
-
「SQL」オプションをクリックして、問合せユーティリティに移動します。
-
「データ・ロード」をクリックします。
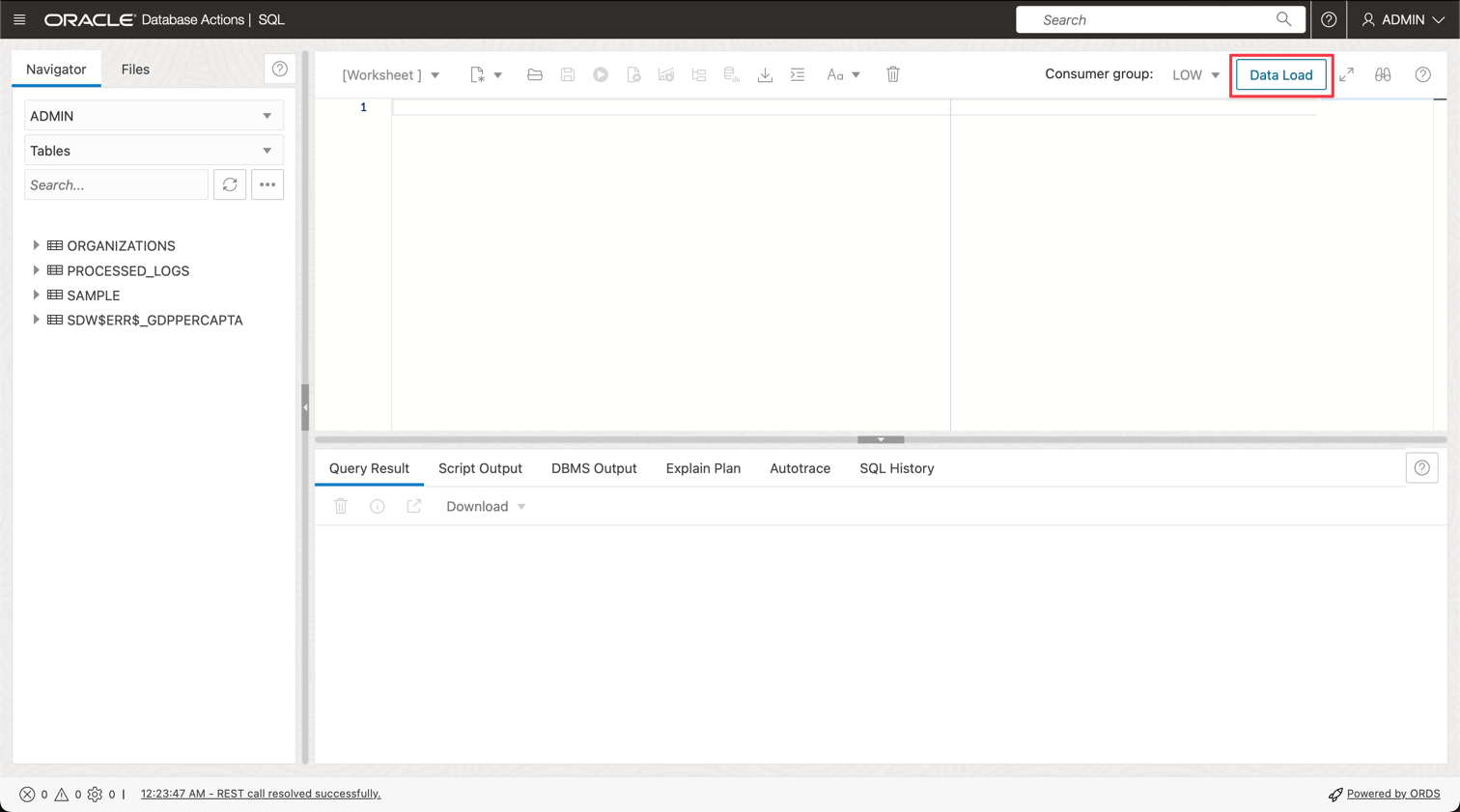
-
GDP PER CAPTA COUNTRY.csvファイルをコンソールパネルにドロップして、データをテーブルにインポートします。
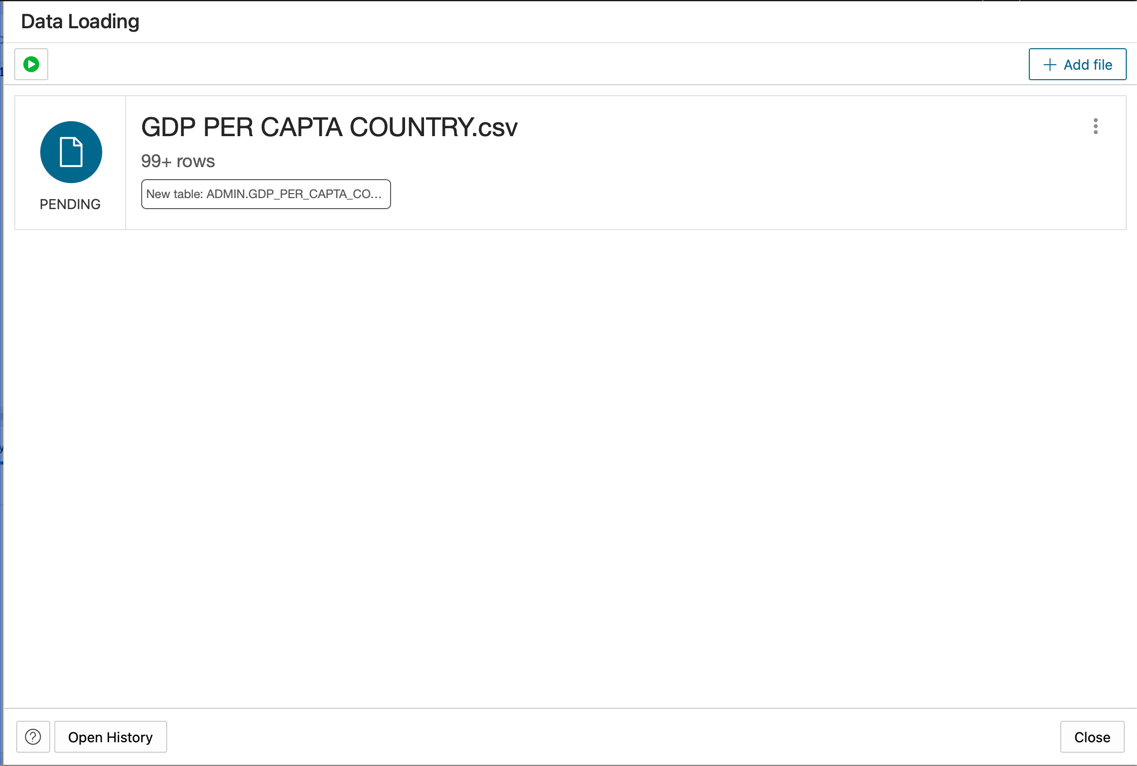
-
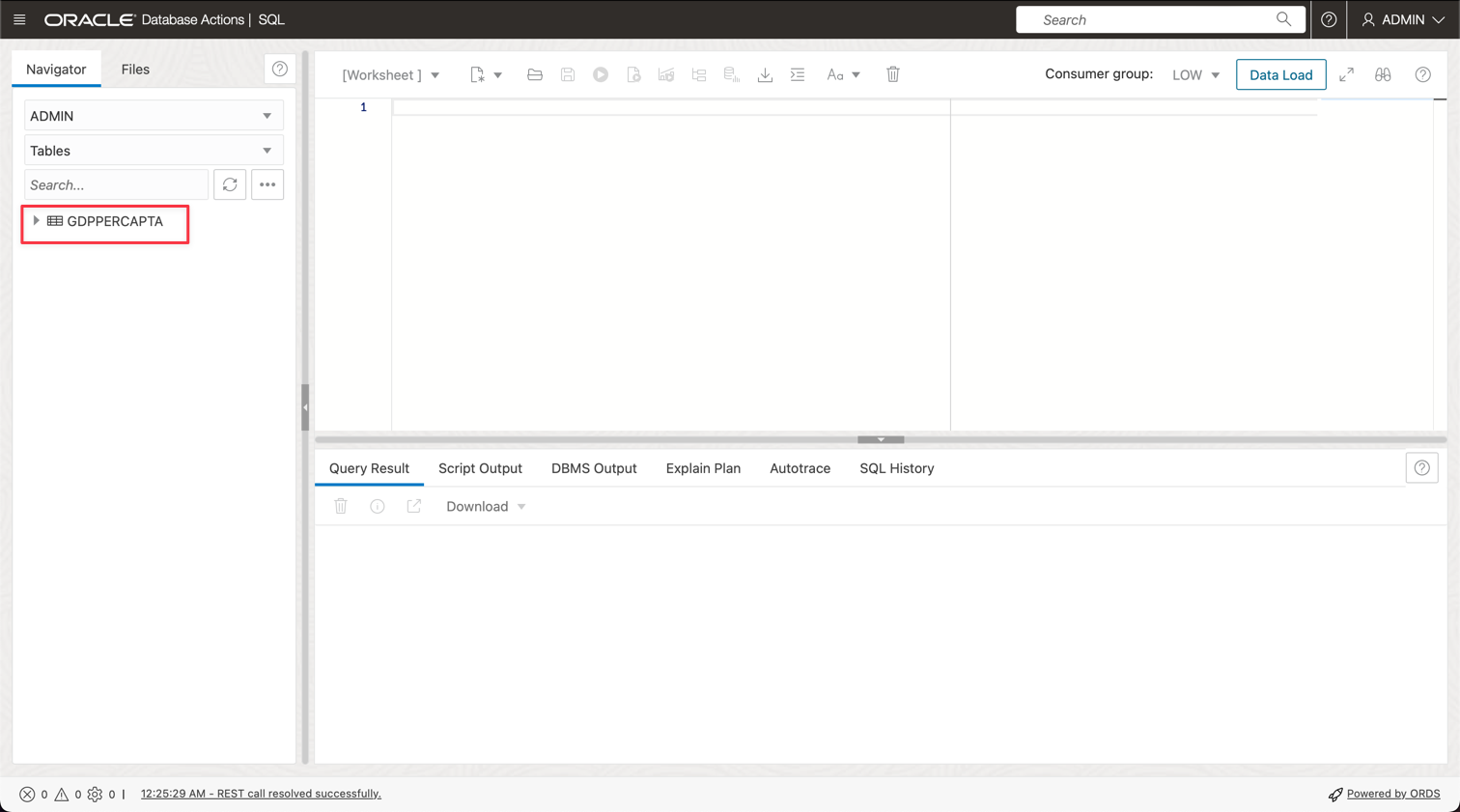
GDPPERCAPTAという名前の新しい表が正常にインポートされたことを確認できます。
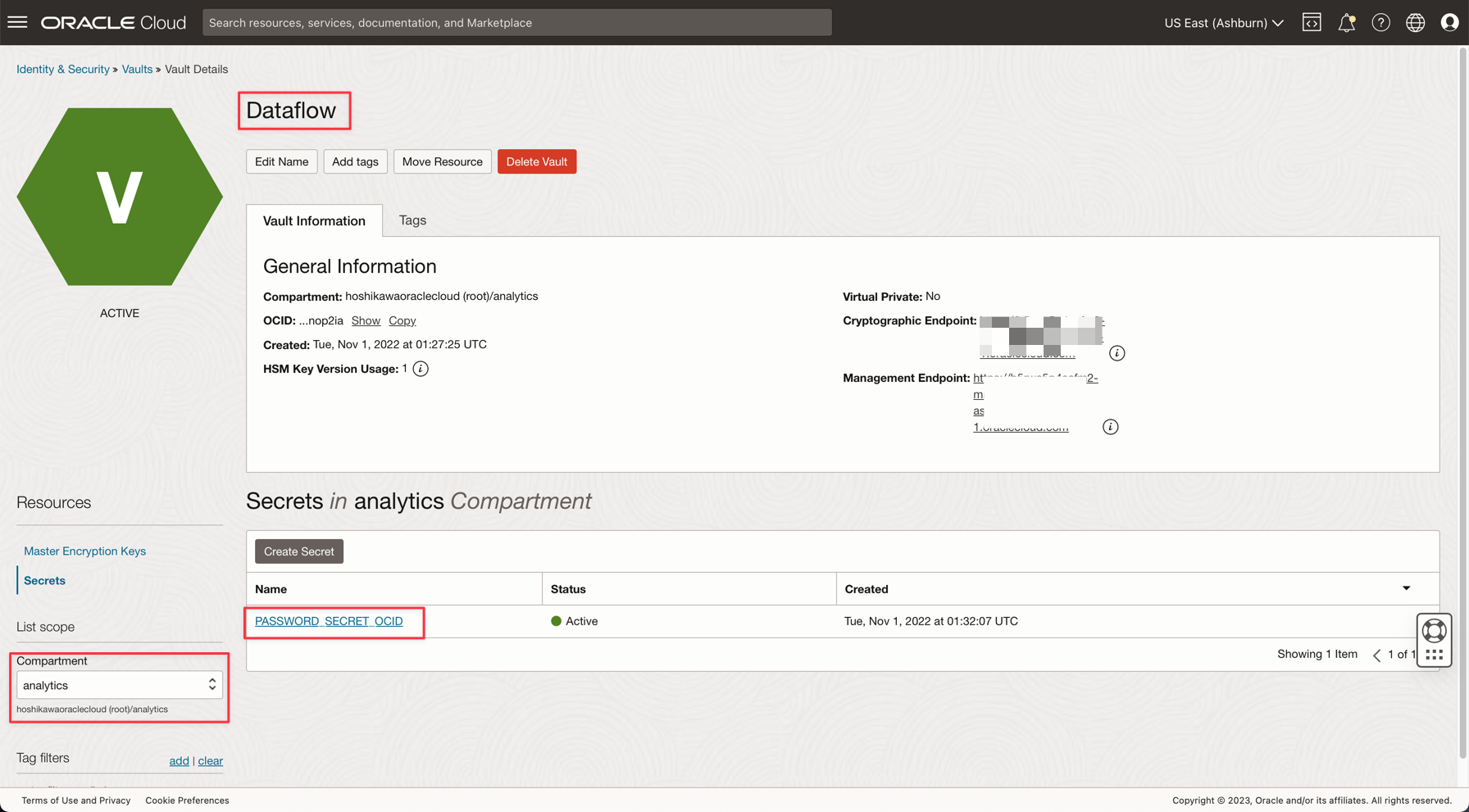
タスク4: ADW ADMINパスワード用のシークレットVaultの作成
セキュリティ上の理由から、ADW ADMINパスワードはVaultに保存されます。Oracle Cloud Vaultはこのパスワードをセキュリティでホストでき、アプリケーション上でOCI認証を使用してアクセスできます。
-
次のドキュメントの説明に従って、ボールトにシークレットを作成します: Vaultへのデータベース管理パスワードの追加
-
アプリケーションでPASSWORD_SECRET_OCIDという名前の変数を作成し、OCIDを入力します。

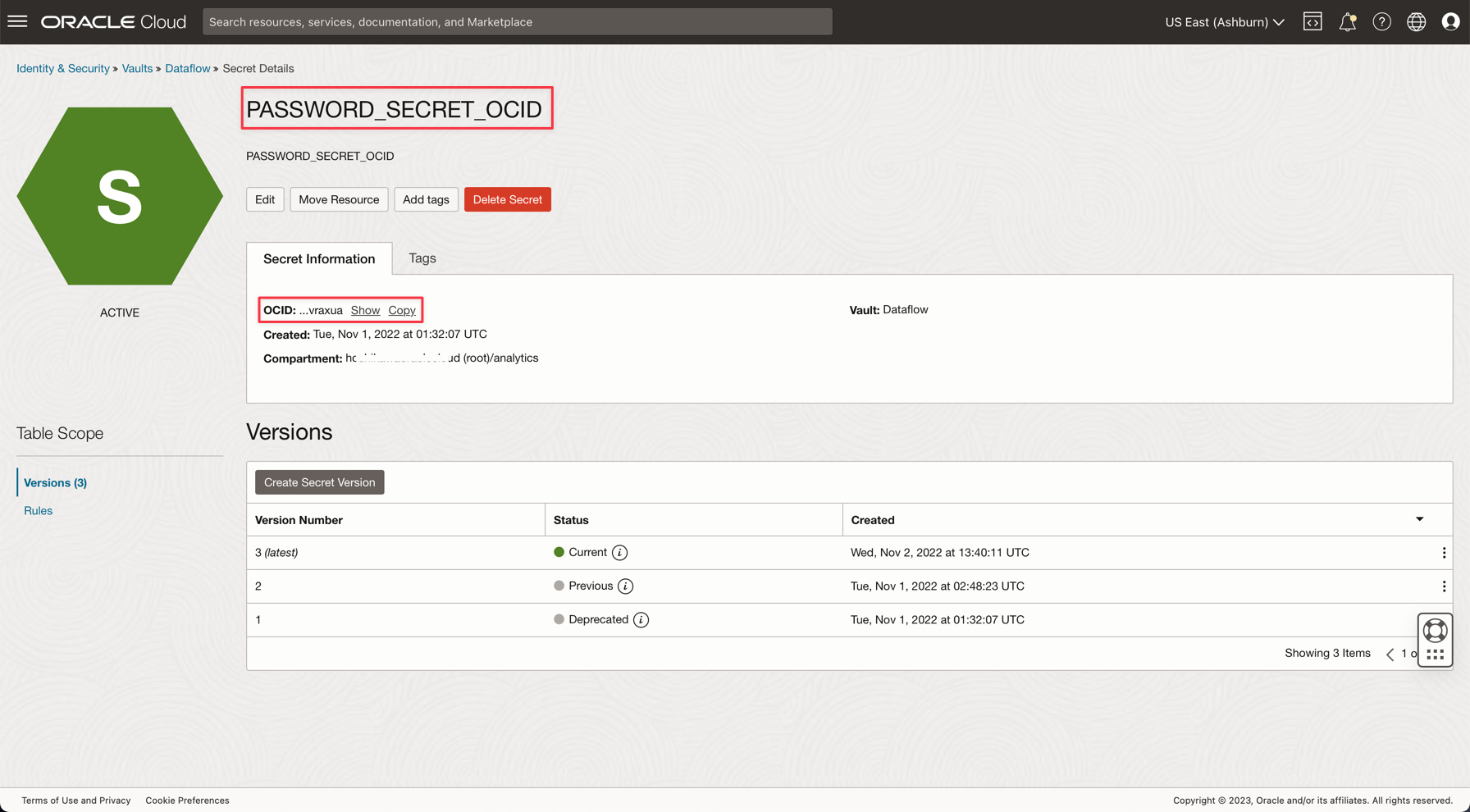
ノート: OCI VaultのIAMポリシーを確認します(OCI Vault IAMポリシー)。
タスク5: Kafkaストリーミングの作成(Oracle Cloud Streaming)
Oracle Cloud Streamingは、マネージド・ストリーミング・サービスなどのKafkaです。Kafka APIおよび共通SDKを使用してアプリケーションを開発できます。このチュートリアルでは、ストリーミングのインスタンスを作成し、大量のデータを公開して消費するために、両方のアプリケーションで実行されるように構成します。
-
Oracle Cloudのメイン・メニューから、「アナリティクスとAI」、「ストリーム」に移動します。
-
コンパートメントをanalyticsに変更します。このデモのすべてのリソースは、このコンパートメントに作成されます。これにより、IAMをより安全で簡単に制御できます。
-
「Create Stream」をクリックします。
-
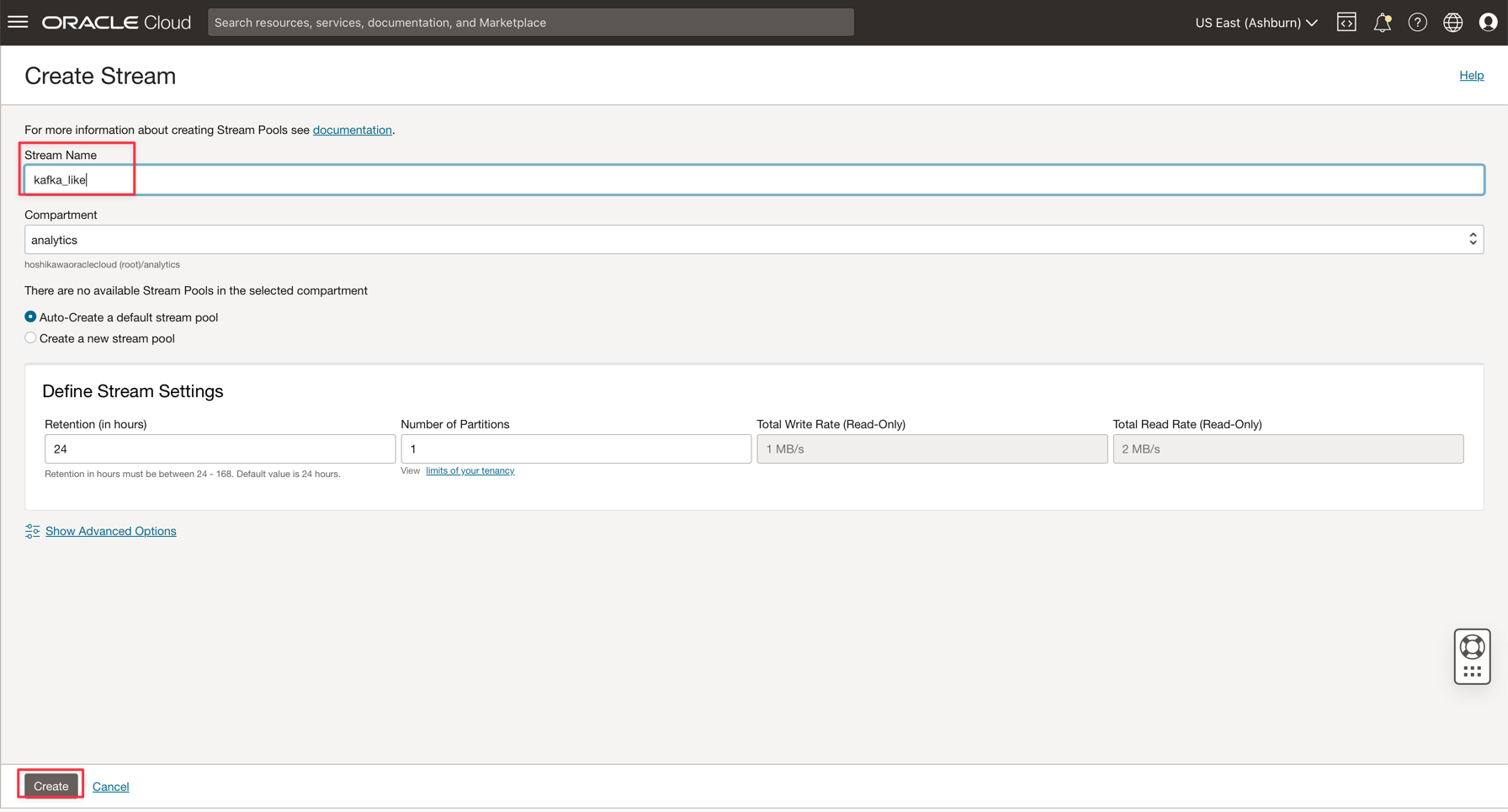
名前をkafka_like (たとえば)と入力し、他のすべてのパラメータをデフォルト値で保守できます。
-
「作成」をクリックしてインスタンスを初期化します。
-
「アクティブ」ステータスを待機します。これで、インスタンスを使用できます。
ノート:ストリーミング作成プロセスでは、「デフォルトのストリーム・プールの自動作成」オプションを選択して、デフォルト・プールを自動的に作成できます。
-
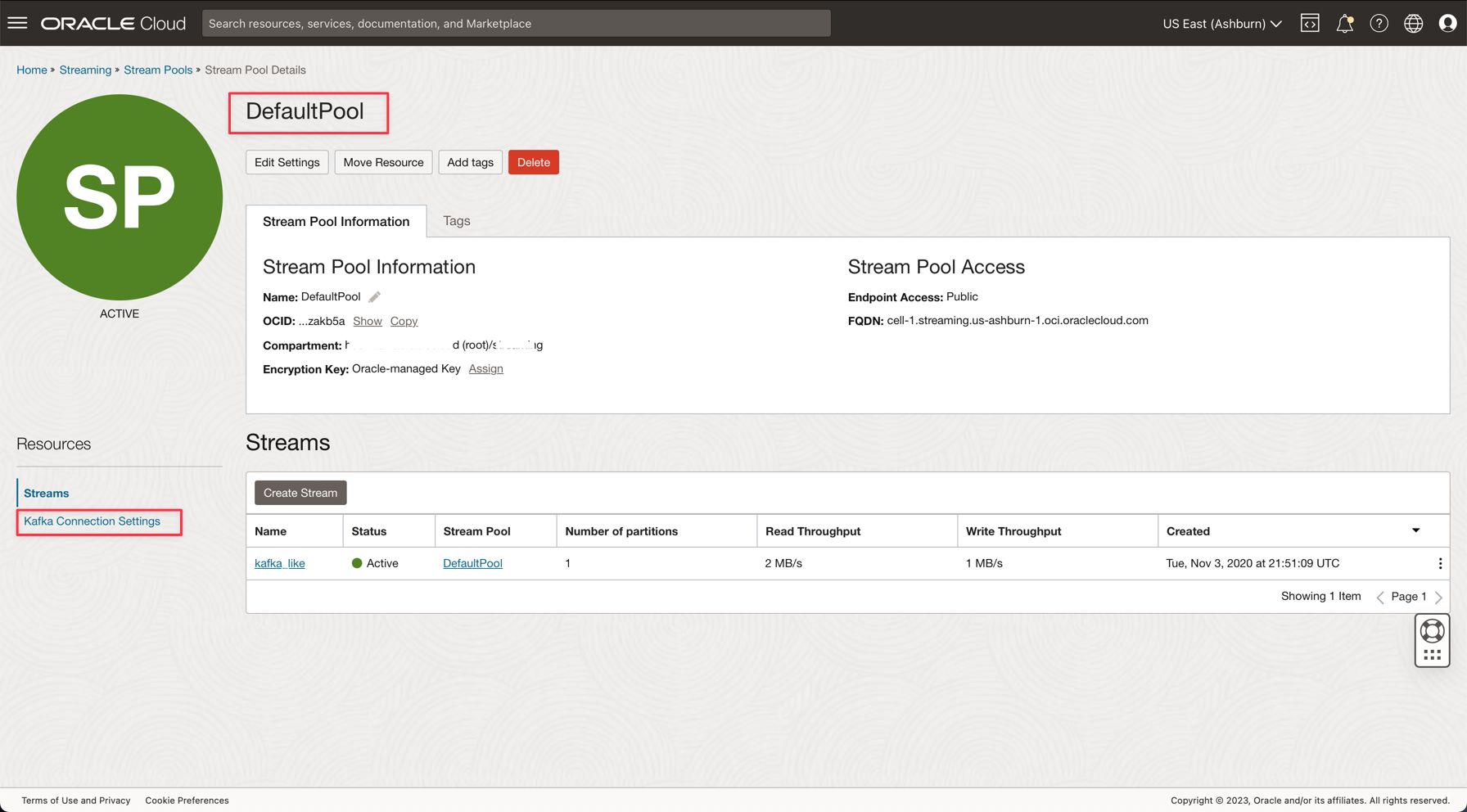
DefaultPoolリンクをクリックします。

-
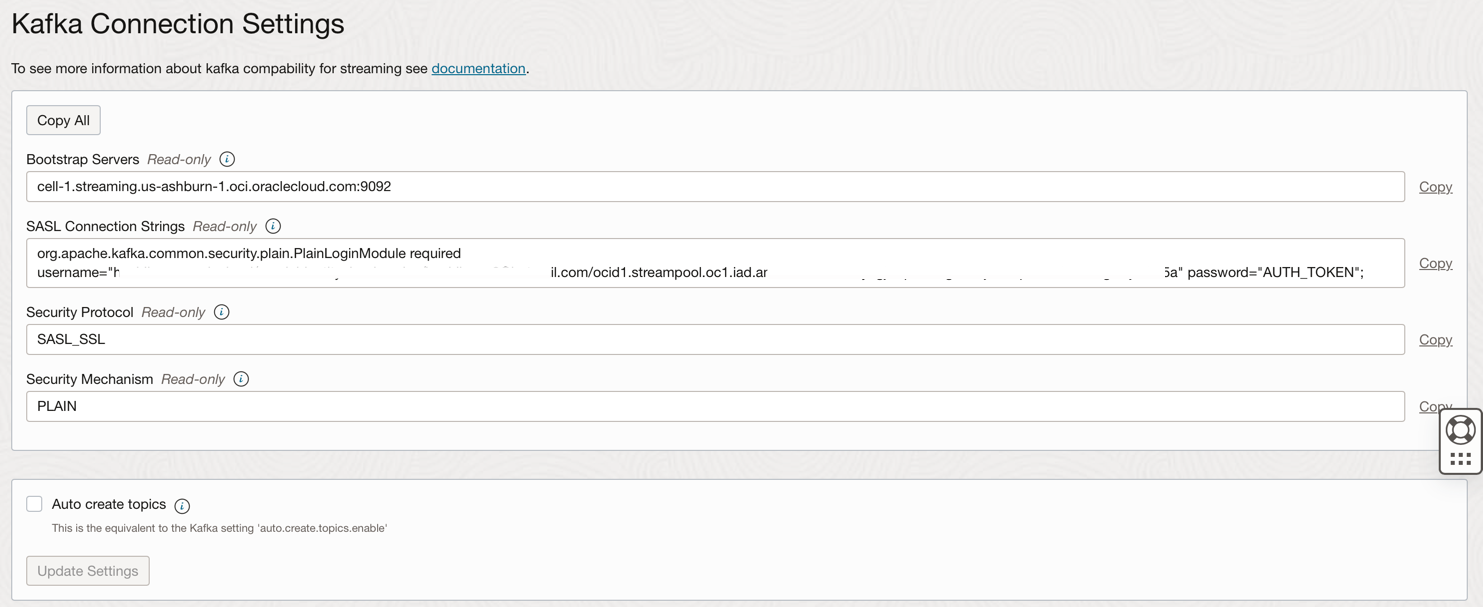
接続設定を表示します。
-
この情報は次のステップで必要になるため、注釈を付けます。
ノート: OCIストリーミングのIAMポリシーを確認します(OCIストリーミングのIAMポリシー)。
タスク6: KafkaにアクセスするためのAUTH TOKENの生成
OCI IAM上のユーザーに関連付けられた認証トークンを使用して、Oracle CloudのOCIストリーミング(Kafka API)およびその他のリソースにアクセスできます。Kafka接続設定では、SASL接続文字列には、前のタスクで説明したパスワードおよびAUTH_TOKEN値というパラメータがあります。OCIストリーミングへのアクセスを有効にするには、OCIコンソールのユーザーに移動し、AUTH TOKENを作成する必要があります。
-
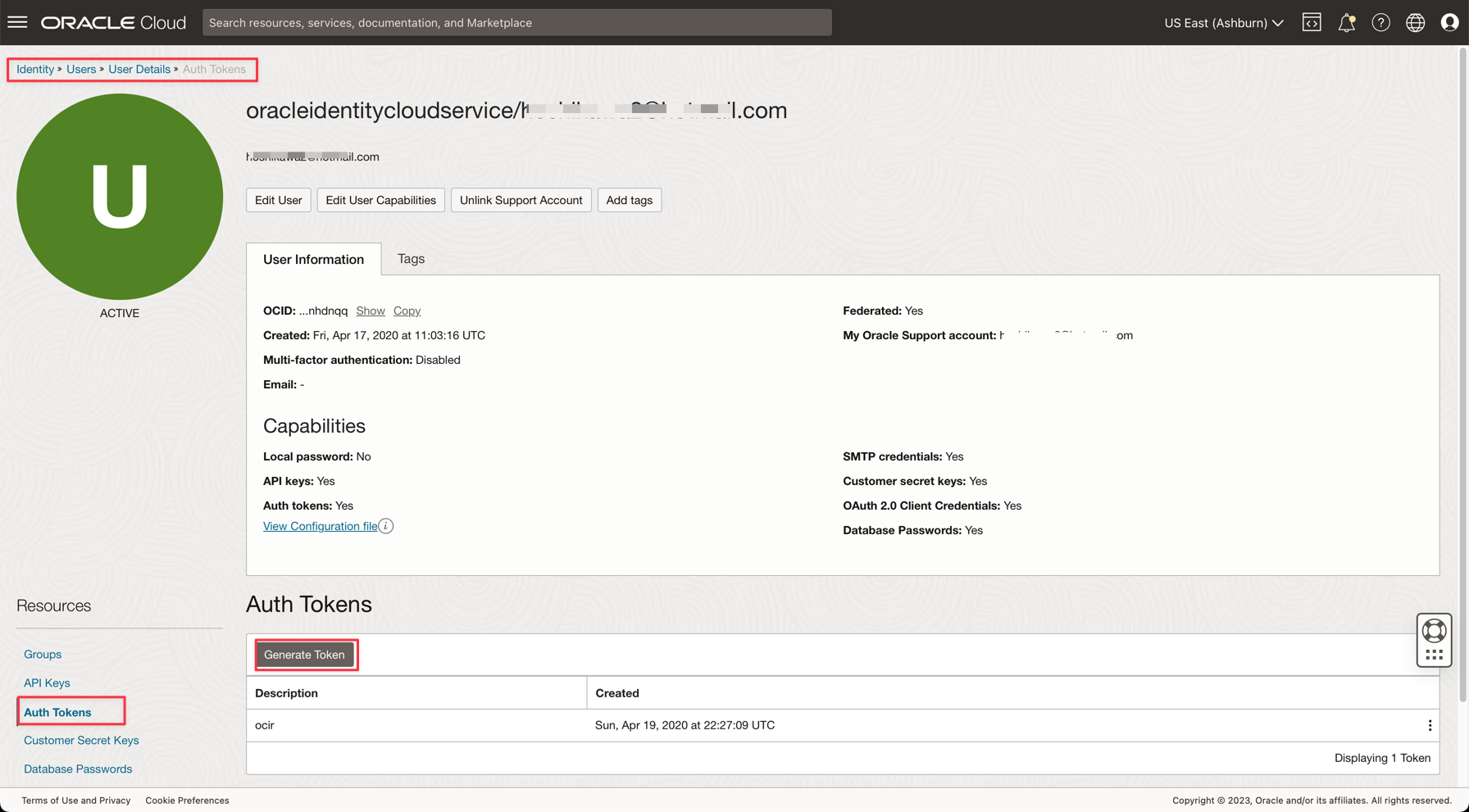
Oracle Cloudのメイン・メニューから、「アイデンティティとセキュリティ」、「ユーザー」に移動します。
ノート: AUTH TOKENを作成する必要があるユーザーは、これまでに作成されたリソースのOCI CLIおよびすべてのIAMポリシー構成で構成されているユーザーであることに注意してください。リソース:
- Oracle Cloud Autonomous Data Warehouse
- Oracle Cloudストリーミング
- Oracle Object Storage
- Oracle Data Flow
-
ユーザー名をクリックして詳細を表示します。
-
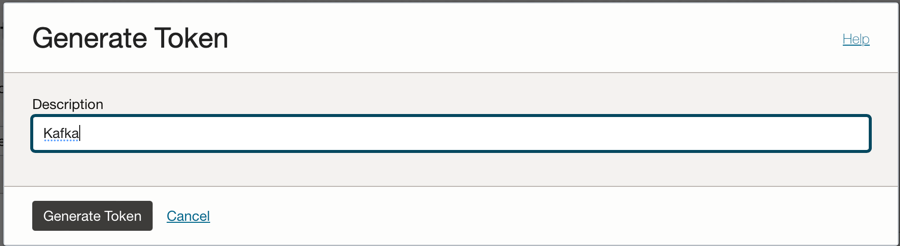
コンソールの左側にある「認証トークン」オプションをクリックし、「トークンの生成」をクリックします。
ノート: トークンはこのステップでのみ生成され、ステップの完了後は表示されません。そのため、値をコピーして保存します。トークン値を失った場合は、認証トークンを再度生成する必要があります。

タスク7: Demoアプリケーションの設定
このチュートリアルには、必要な情報を設定するデモ・アプリケーションがあります。
- DataflowSparkStreamDemo:このアプリケーションはKafkaストリーミングに接続し、すべてのデータを消費し、GDPPERCAPTAという名前のADW表にマージします。ストリーム・データはGDPPERCAPTAとマージされ、CSVファイルとして保存されますが、別のKafkaトピックに公開できます。
-
次のリンクを使用してアプリケーションをダウンロードします:
-
Oracle Cloudコンソールで、次の詳細を確認します。
-
テナント・ネームスペース
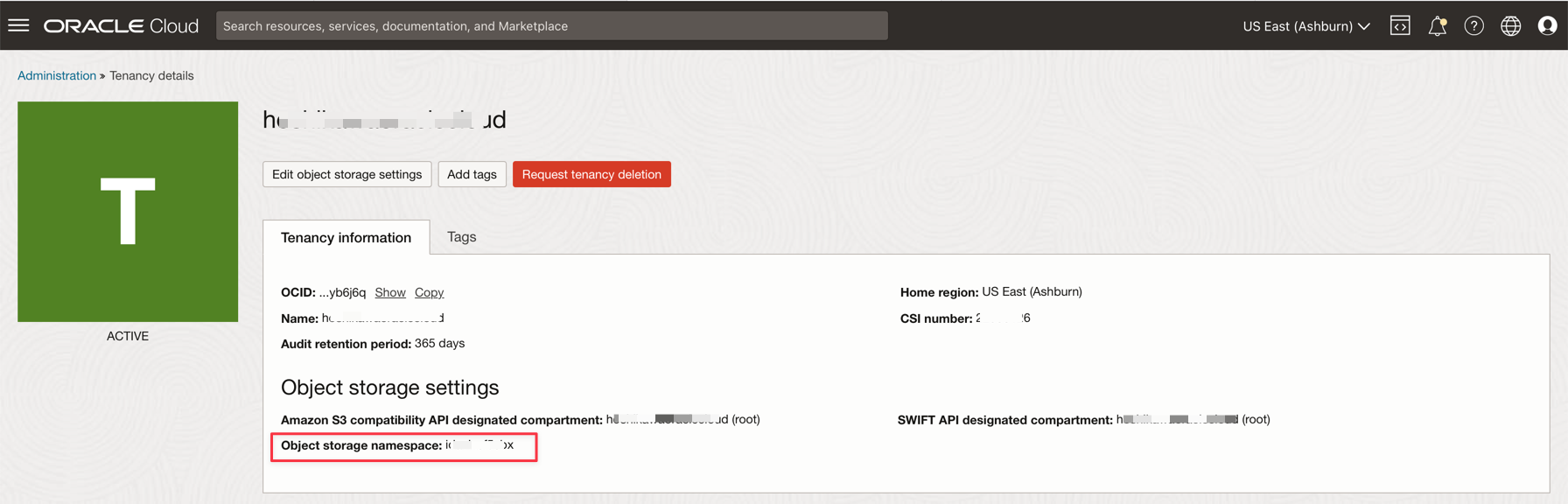
-
パスワード・シークレット
-
ストリーミング接続設定
-
認証トークン
-
-
ダウンロードしたzipファイル(
Java-CSV-DB.zipおよびJavaConsumeKafka.zip)を開きます。/src/main/java/exampleフォルダに移動し、Example.javaコードを見つけます。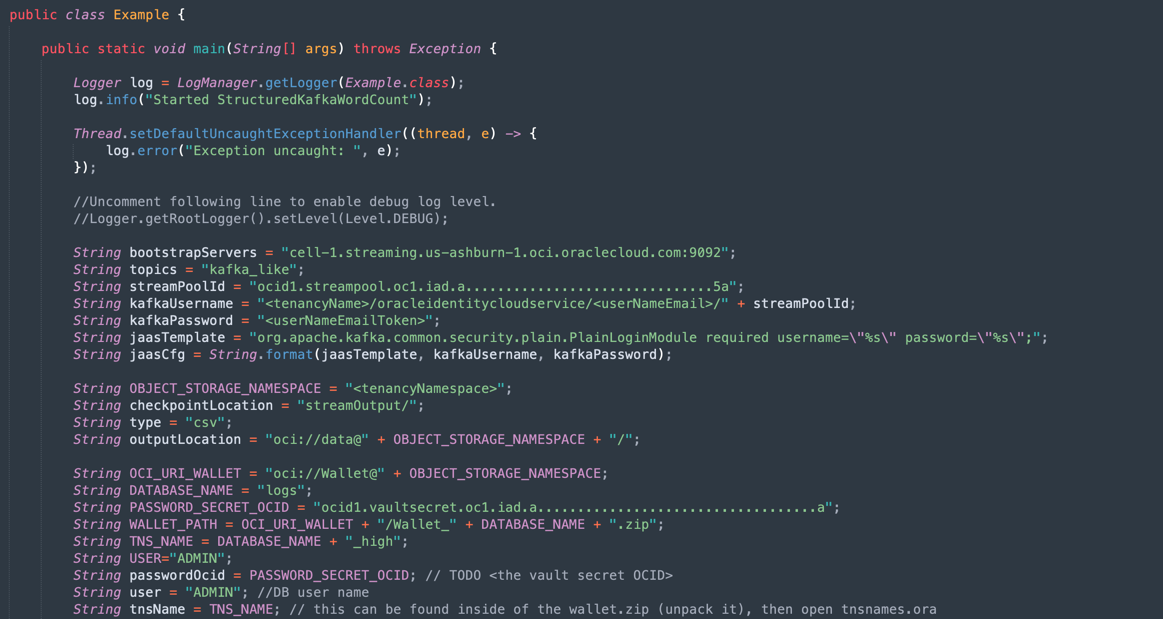
これらは、テナンシ・リソース値で変更する必要がある変数です。
変数名 リソース名 情報タイトル bootstrapServers ストリーミング接続設定 Bootstrapサーバー streamPoolId ストリーミング接続設定 SASL接続文字列のocid1.streampool.oc1.iad.....値 kafkaUsername ストリーミング接続設定 SASL接続文字列内の" " "内のusenameの値 kafkaPassword 認証トークン 値は作成ステップでのみ表示されます。 OBJECT_STORAGE_NAMESPACE テナント・ネームスペース テナント ネームスペース テナント・ネームスペース テナント PASSWORD_SECRET_OCID PASSWORD_SECRET_OCID OCID
ノート:このデモ用に作成されたすべてのリソースは、US-ASHBURN-1リージョンにあります。作業するリージョンをチェックインします。リージョンを変更する場合は、2つのコード・ファイルの2つのポイントを変更する必要があります。
Example.java: bootstrapServers変数を変更し、"us-ashburn-1"を新しいリージョンに置き換えます
OboTokenClientConfigurator.java: 新しいリージョンでCANONICAL_REGION_NAME変数を変更します。
タスク8: Javaコードの理解
このチュートリアルはJavaで作成され、このコードはPythonにも移植できます。効率性とスケーラビリティを証明するために、統合プロセスの一般的なユース・ケースでいくつかの可能性を示すアプリケーションを開発しました。したがって、アプリケーションのコードは次の例を示しています。
- Kafkaストリームに接続し、データを読み取ります
- ADW表でのJOINSの処理による有用な情報の構築
- Kafkaから有益な情報が得られるCSVファイルを出力します
このデモは、ローカル・マシンで実行し、データ・フロー・インスタンスにデプロイしてジョブ実行として実行できます。
ノート:データ・フロー・ジョブおよびローカル・マシンの場合は、OCI CLI構成を使用してOCIリソースにアクセスします。データ・フロー側では、すべてが事前構成されているため、パラメータを変更する必要はありません。ローカル・マシン側で、OCI CLIをインストールし、OCIリソースにアクセスするためのテナント、ユーザーおよび秘密キーを構成しておく必要があります。
Example.javaコードをセクションに表示します:
-
Apache Sparkの初期化: コードのこの部分は、Sparkの初期化を表します。実行プロセスを実行する多くのパラメータは自動的に構成されるため、Sparkエンジンを操作することは非常に簡単です。初期化は、データ・フロー内またはローカル・マシンで実行している場合に異なります。データ・フローでは、ADW Wallet zipファイルをロードする必要はなく、Walletファイルのロード、圧縮解除および読取りのタスクはデータ・フロー環境内で自動ですが、ローカル・マシンではいくつかのコマンドを実行する必要があります。
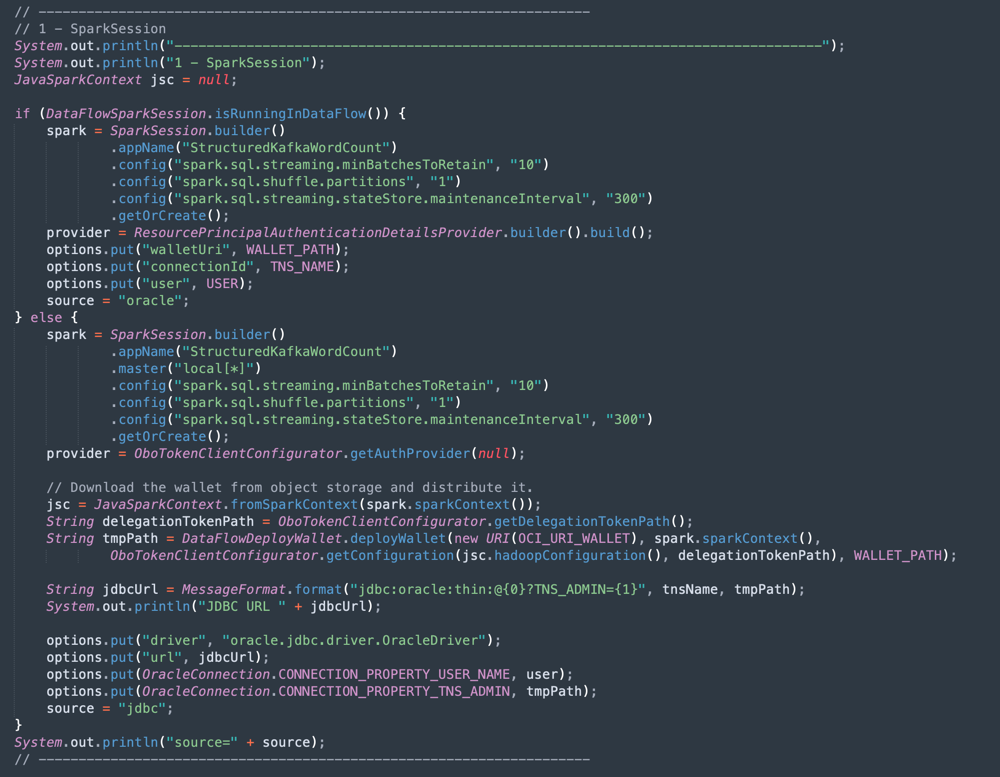
-
ADW Vaultシークレットを読む: コードのこの部分はボールトにアクセスし、Autonomous Data Warehouseインスタンスのシークレットを取得します。
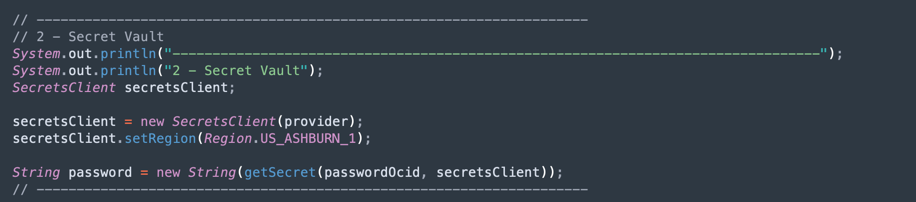
-
ADW表の問合せ: この項では、表に対する問合せを実行する方法を示します。

-
Kafka操作: これは、Kafka APIを使用してOCIストリーミングに接続するための準備です。
ノート: Oracle Cloud Streamingは、ほとんどのKafka APIと互換性があります。
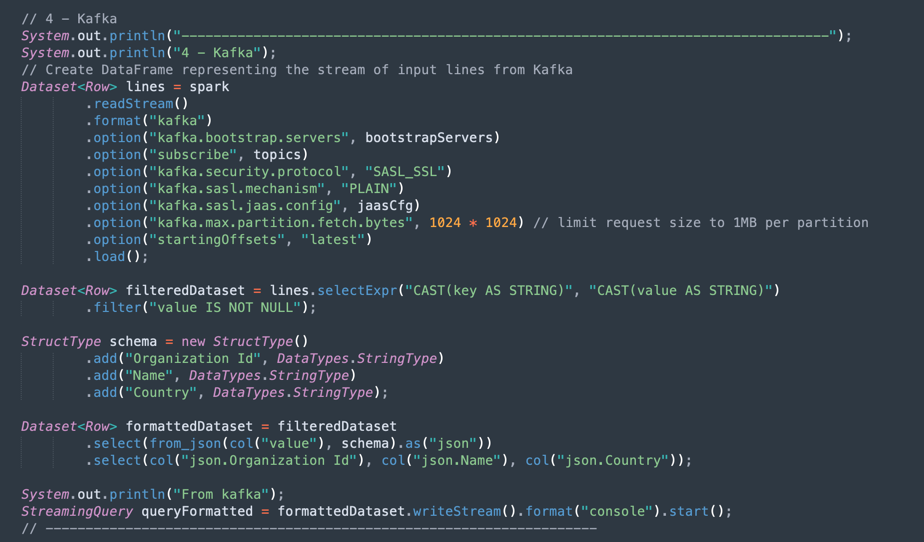
Kafkaトピックから取得したJSONデータを正しい構造(組織ID、名前、国)でデータセットに解析するプロセスがあります。
-
KafkaデータセットおよびAutonomous Data Warehouseデータセットのデータのマージ: この項では、2つのデータセットを使用して問合せを実行する方法を示します。

-
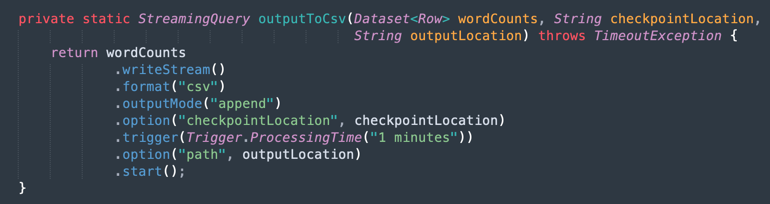
CSVファイルへの出力: マージされたデータが出力をCSVファイルに生成する方法を次に示します。

タスク9: Mavenを使用したアプリケーションのパッケージ化
Sparkでジョブを実行する前に、Mavenでアプリケーションをパッケージ化する必要があります。
-
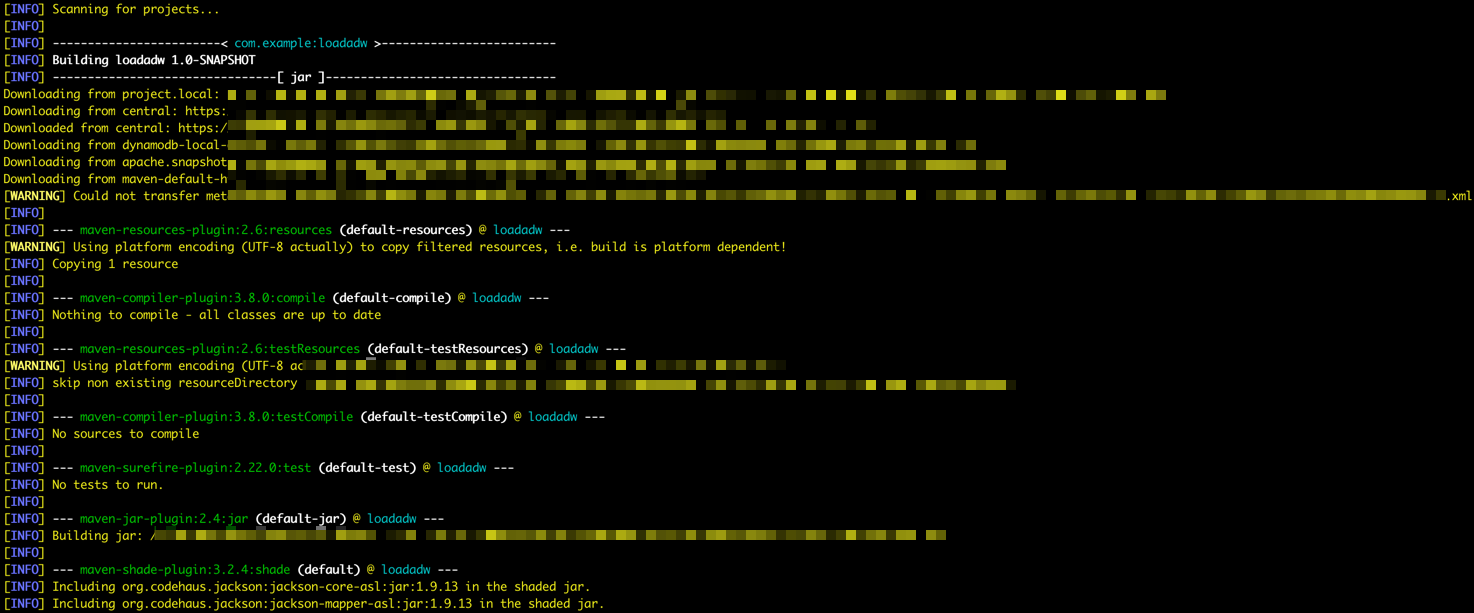
/DataflowSparkStreamDemoフォルダに移動し、次のコマンドを実行します。
mvn package -
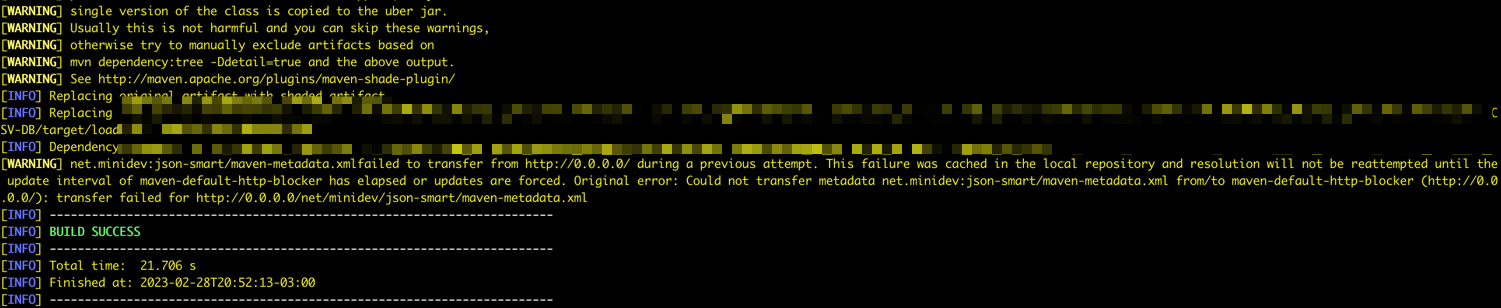
Mavenがパッケージを開始していることがわかります。
-
すべてが正しい場合は、「成功」メッセージが表示されます。
タスク10: 実行の確認
-
次のコマンドを実行して、ローカルSparkマシンでアプリケーションをテストします:
spark-submit --class example.Example target/consumekafka-1.0-SNAPSHOT.jar -
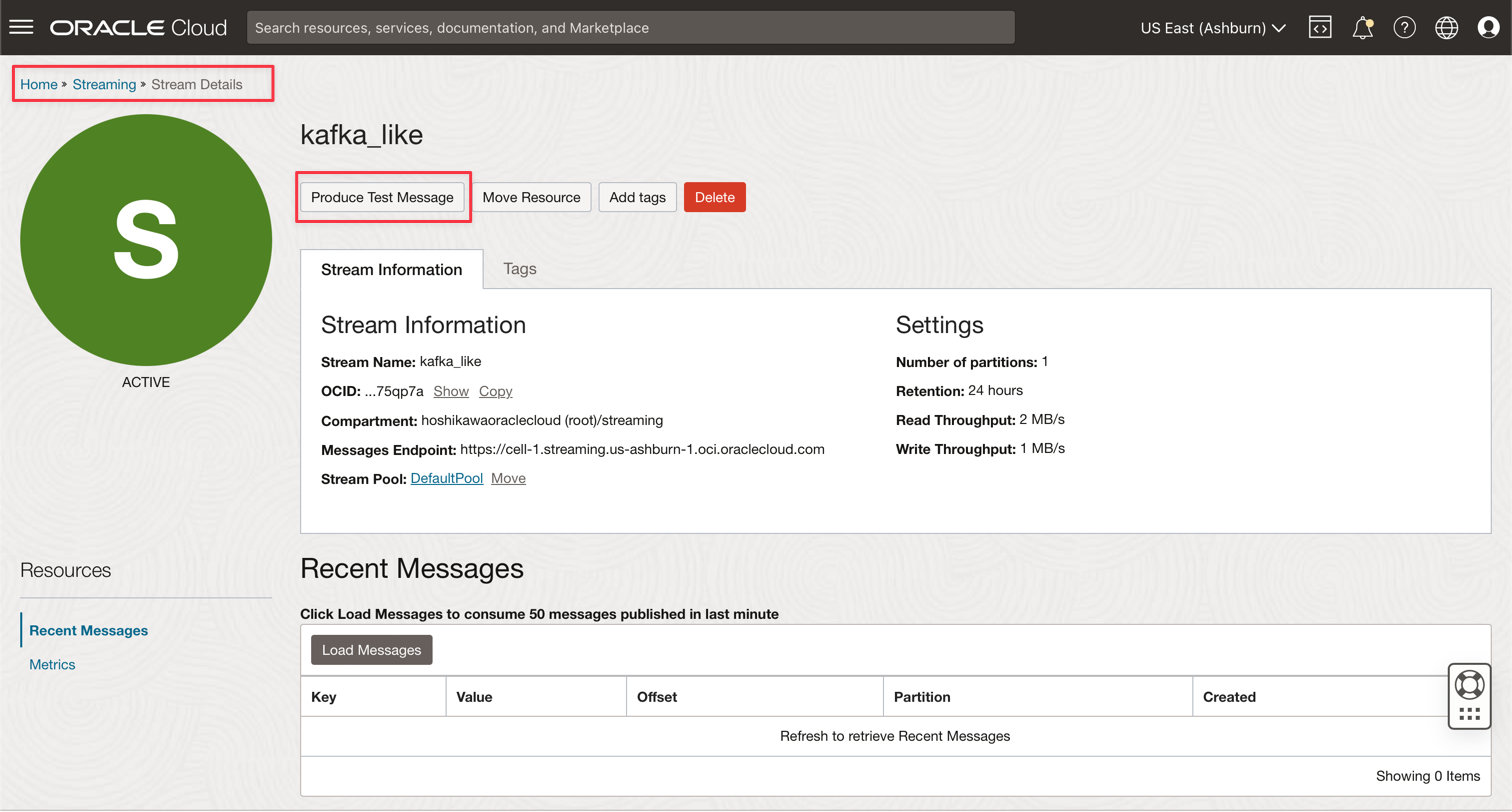
Oracle Cloud Streaming Kafkaインスタンスに移動し、「テスト・メッセージの作成」をクリックして、リアルタイム・アプリケーションをテストするためのデータを生成します。
-
このJSONメッセージをKafkaトピックに配置できます。
{"Organization Id": "1235", "Name": "Teste", "Country": "Luxembourg"}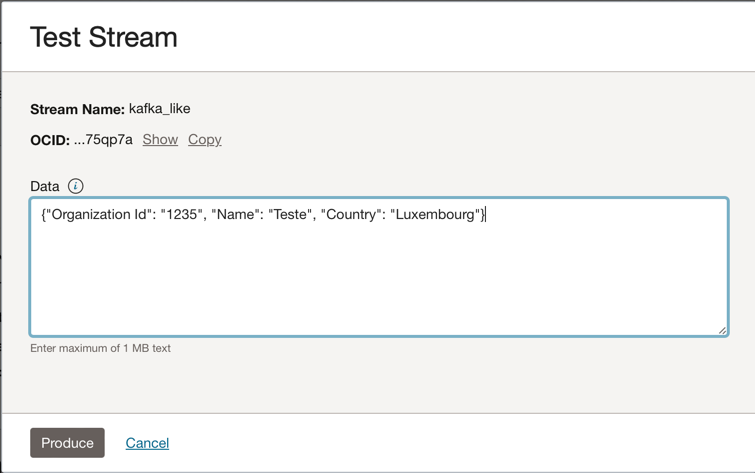
-
「生成」をクリックするたびに、アプリケーションに1つのメッセージを送信します。アプリケーションの出力ログは次のようになります。
-
これは、kafkaトピックから読み取られたデータです。

-
これはADW表からマージされたデータです。

-
タスク11: データ・フロー・ジョブの作成および実行
これで、両方のアプリケーションがローカルSparkマシンで成功して実行され、テナンシのOracle Cloudデータ・フローにデプロイできるようになりました。
ノート: Oracle Object StorageやOracle Streaming (Kafka)などのリソースへのアクセスを構成するには、Sparkストリーミングのドキュメントを参照してください: データ・フローへのアクセスの有効化
-
オブジェクト・ストレージにパッケージをアップロードします。
- データ・フロー・アプリケーションを作成する前に、Javaアーティファクト・アプリケーション(***-SNAPSHOT.jarファイル)をappsという名前のオブジェクト・ストレージ・バケットにアップロードする必要があります。
-
データ・フロー・アプリケーションの作成
-
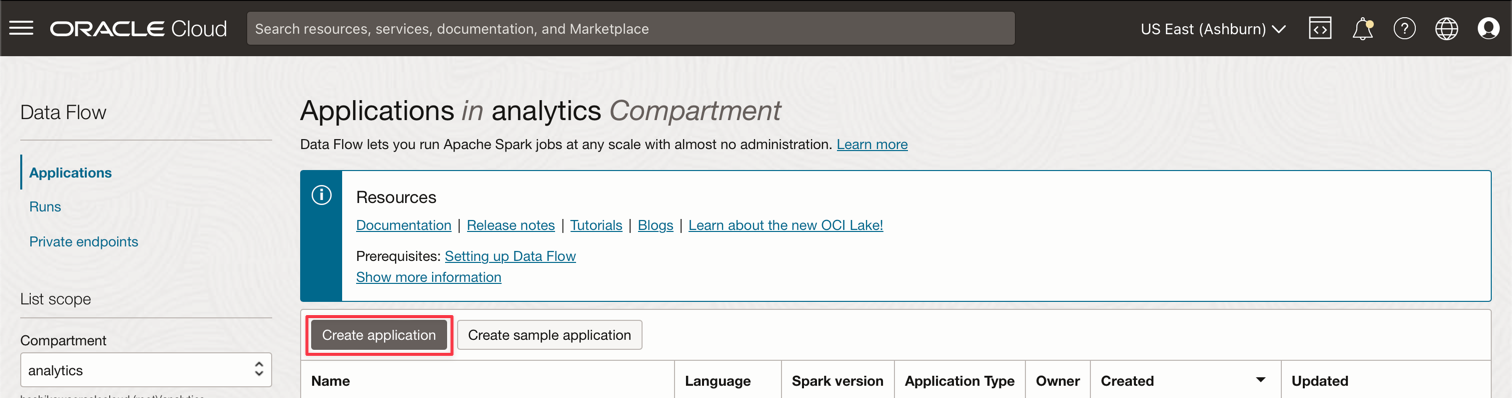
Oracle Cloudのメイン・メニューを選択し、「分析およびAI」および「データ・フロー」に移動します。データ・フロー・アプリケーションを作成する前に、必ずanalyticsコンパートメントを選択してください。
-
「アプリケーションの作成」をクリックします。
-
このようなパラメータを入力します。
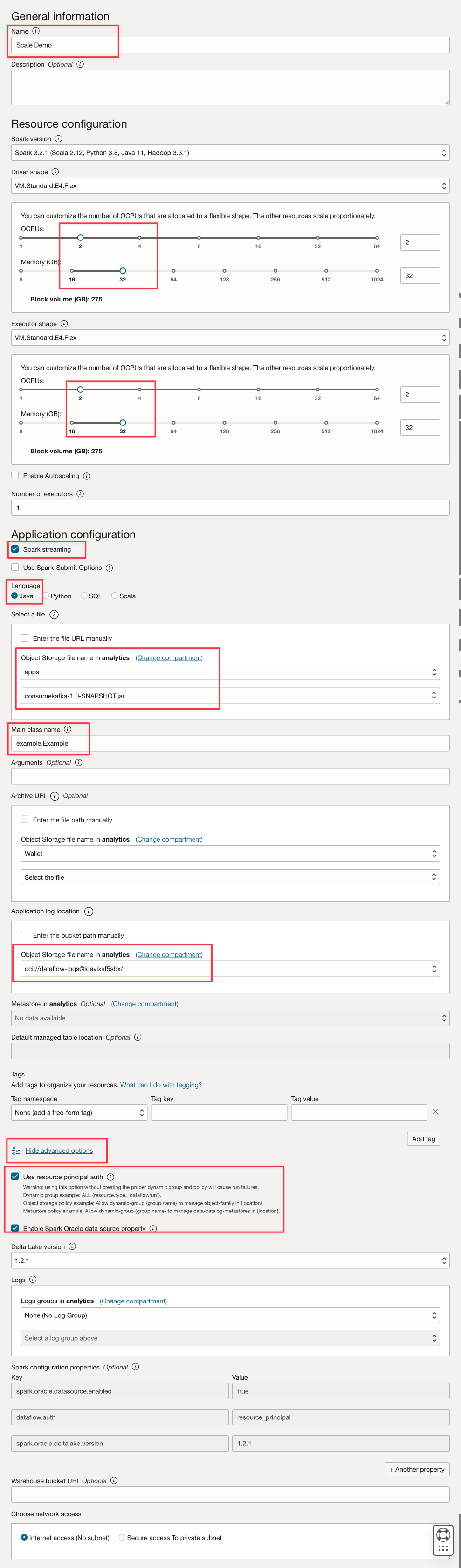
-
「作成」をクリックします。
-
作成後、「デモのスケーリング」リンクをクリックして詳細を表示します。ジョブを実行するには、「実行」をクリックします。
ノート: 「拡張オプションの表示」をクリックして、Sparkストリーム実行タイプのOCIセキュリティを有効にします。

-
-
次のオプションをアクティブ化します。

-
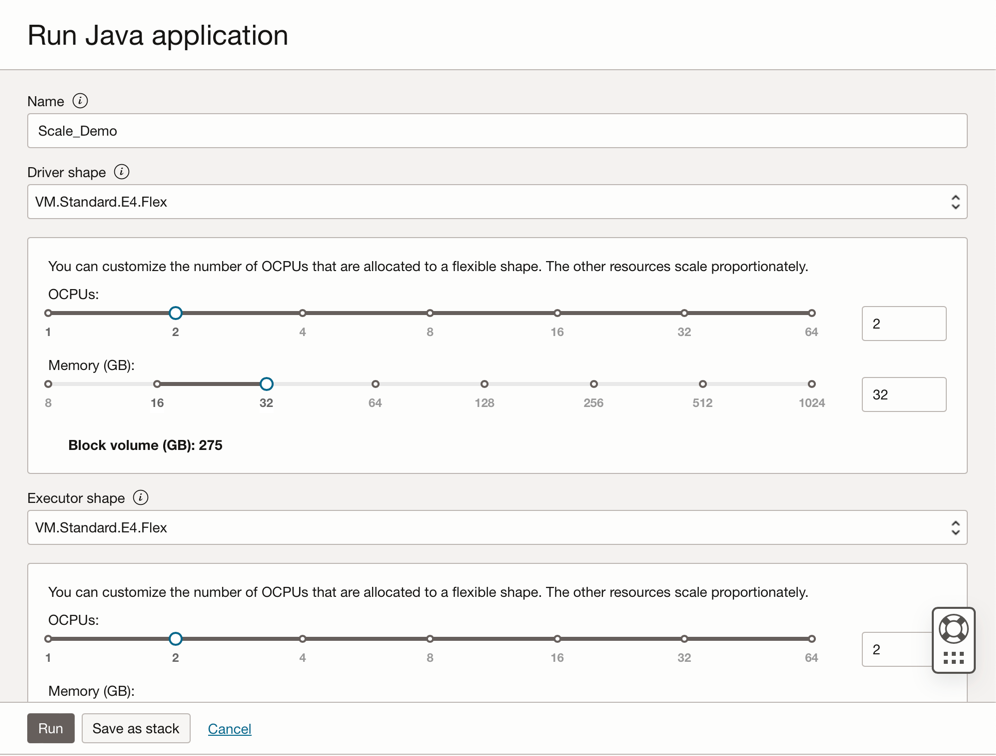
「実行」をクリックしてジョブを実行します。
-
パラメータを確認し、「実行」を再度クリックします。
-
ジョブのステータスを表示できます。

-
「ステータス」が「成功」になるまで待って、結果を確認できます。

-
関連リンク
謝辞
- 著者 - Cristiano Hoshikawa (Oracle LAD Aチーム・ソリューション・エンジニア)
その他の学習リソース
docs.oracle.com/learnで他のラボをご覧いただくか、Oracle Learning YouTubeチャネルでより無料のラーニング・コンテンツにアクセスしてください。また、education.oracle.com/learning-explorerにアクセスして、Oracle Learning Explorerになります。
製品ドキュメントについては、Oracle Help Centerを参照してください。
Use OCI Data Flow with Apache Spark Streaming to process a Kafka topic in a scalable and near real-time application
F79979-02
May 2023
Copyright © 2023, Oracle and/or its affiliates.