ノート:
- このチュートリアルでは、Oracle Cloudへのアクセス権が必要です。無料アカウントにサインアップするには、Oracle Cloud Infrastructure Free Tierの開始を参照してください。
- Oracle Cloud Infrastructureの資格証明、テナンシおよびコンパートメントの値の例を使用します。演習を完了したら、これらの値をクラウド環境に固有の値に置き換えてください。
OCI Generative AIによる自然言語でのPDF文書の分析
はじめに
Oracle Cloud Infrastructure Generative AI(OCI Generative AI)は、企業や開発者が最先端の言語モデルを使用してインテリジェントなアプリケーションを作成できるようにする、高度な生成人工知能ソリューションです。このソリューションは、大規模言語モデル(LLM)などの強力なテクノロジに基づいて、複雑なタスクの自動化を可能にし、自然言語でのやりとりを通じてプロセスをより迅速かつ効率的に、アクセスできるようにします。
OCI Generative AIの最も影響力のあるアプリケーションの1つは、PDFドキュメント分析です。企業は、契約、財務レポート、技術マニュアル、研究論文など、大量の文書を頻繁に処理します。これらのファイルの情報を手動で検索すると、時間がかかり、エラーが発生しやすくなります。
生成人工知能を使用することで、情報を瞬時に正確に抽出できるため、ユーザーは自然言語で質問を策定するだけで複雑なドキュメントに問い合わせることができます。つまり、ページ全体を読み取って、契約内の特定の条項またはレポート内の関連データ・ポイントを検索するかわりに、分析されたコンテンツに基づいて回答をすばやく返すモデルを尋ねることもできます。
OCI Generative AIは、情報の取得だけでなく、長いドキュメントの要約、コンテンツの比較、情報の分類、戦略的インサイトの生成にも使用できます。これらの機能により、法律、財務、ヘルスケア、エンジニアリングなどのさまざまな分野でテクノロジーが不可欠になり、意思決定を最適化し、生産性を高めることができます。
このテクノロジーをOracle AIサービス、OCI Data Science、ドキュメント処理のためのAPIなどのツールと統合することで、企業はデータのやり取り方法を完全に変革するインテリジェントなソリューションを構築し、情報の取得を迅速かつ効果的に行うことができます。
前提条件
- Python
version 3.10以上およびOracle Cloud Infrastructureコマンドライン・インタフェース(OCI CLI)をインストールします。
タスク1: Pythonパッケージのインストール
Pythonコードには、OCI生成AIを使用するための特定のライブラリが必要です。次のコマンドを実行して、必要なPythonパッケージをインストールします。
pip install -r requirements.txt
タスク2: Pythonコードの理解
これは、Oracle SOA SuiteおよびOracle Integrationの機能を問い合せるためのOCI生成AIのデモです。どちらのツールも現在、ハイブリッド統合戦略として使用されており、クラウド環境とオンプレミス環境の両方で運用されています。
これらのツールは機能とプロセスを共有しているため、このコードは、各ツールで同じ統合アプローチを実装する方法を理解するのに役立ちます。さらに、ユーザーは共通の特性と違いを調べることができます。
ここからPythonコードをダウンロードします:
PDFドキュメントは次の場所にあります。
Manualsという名前のフォルダを作成し、これらのPDFをそこに移動します。
-
ライブラリのインポート:
ベクトル・データベース(Facebook AI類似検索(FAISS)およびChromaDB)のPDF、OCI生成AI、テキストベクトル化およびストレージの処理に必要なライブラリをインポートします。
-
UnstructuredPDFLoaderは、PDFからテキストを抽出するために使用されます。 -
ChatOCIGenAIを使用すると、OCI生成AIモデルを使用して質問に回答できます。 -
OCIGenAIEmbeddingsは、セマンティック検索用のテキストの埋込み(ベクトル表現)を作成します。
-
-
PDFのロードおよび処理:
処理するPDFファイルをリストします。
-
UnstructuredPDFLoaderは、各ドキュメントを読み取ってページに分割し、索引付けおよび検索を容易にします。 -
ドキュメントIDは、将来の参照のために保存されます。

-
-
OCI生成AIモデルの構成:
OCIでホストされている
Llama-3.1-405bモデルを構成し、ロードされたドキュメントに基づいてレスポンスを生成します。temperature(ランダム性制御)、top_p(多様性制御)およびmax_tokens(トークン制限)などのパラメータを定義します。
ノート:使用可能なLLaMAバージョンは、時間の経過とともに変化することがあります。テナンシ内の現在のバージョンを確認し、必要に応じてコードを更新してください。
-
埋込みおよびベクトル索引付けの作成:
Oracleの埋込みモデルを使用してテキストを数値ベクトルに変換し、ドキュメントでのセマンティック検索を容易にします。

-
FAISSは、迅速な問合せのためにPDF文書の埋込みを格納します。
-
retrieverでは、ユーザーの問合せのセマンティック類似性に基づいて、最も関連性の高い抜粋を取得できます。

-
-
最初の処理実行では、ベクトル・データはFAISSデータベースに保存されます。

-
プロンプトの定義:
生成モデルのインテリジェント・プロンプトを作成し、各問合せに関連するドキュメントのみを考慮するように指示します。
これにより、応答の精度が向上し、不要な情報が回避されます。

-
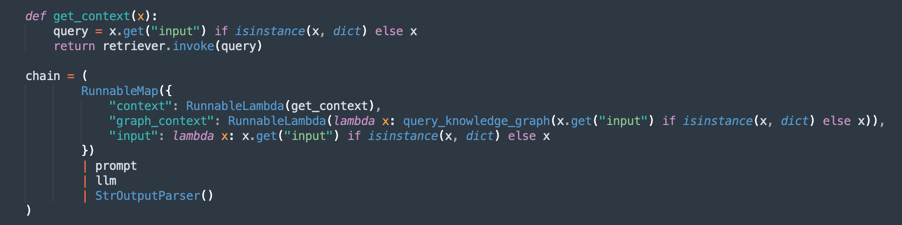
処理チェーンを作成します(RAG - Retrieval-Augmented Generation)。
RAGフローを実装します。ここでは:
retrieverは、最も関連性の高いドキュメントの抜粋を検索します。promptは、より適切なコンテキストのために問合せを編成します。llmは、取得したドキュメントに基づいてレスポンスを生成します。StrOutputParserは、最終出力をフォーマットします。

-
質問および回答のループ:
ロードされたドキュメントについてユーザーが質問できるループを維持します。
-
AIは、PDFから抽出されたナレッジ・ベースを使用して応答します。
-
quitと入力すると、プログラムは終了します。

-
これで、3つのオプションを選択してドキュメントを処理できるようになりました。次のことを考えられます。
- 処理する必要がある電力はいくつですか。
- 処理する時間はどれくらいですか。
- 回答の質はどうですか?
そのため、次のオプションがあります:
固定サイズのチャンク化:ドキュメントを処理するより高速な代替方法です。欲しいものを手に入れるには十分です。
セマンティック・チャンク化:このプロセスは、固定サイズのチャンク化よりも遅くなりますが、より質の高いチャンク化を実現します。
GraphRAGを使用したセマンティック・チャンク:チャンク・テキストおよびナレッジ・グラフが編成されるため、より正確なメソッドが提供されます。
固定サイズのチャンク化
oci_genai_llm_context_fast.pyからコードをダウンロードします。
-
固定サイズのチャンクとは何ですか?
固定サイズのチャンク化は、ドキュメントが事前定義されたサイズ制限(通常はトークン、文字または行で測定)に基づいてチャンクに分割される、シンプルで効率的なテキスト分割戦略です。
このメソッドは、テキストの意味や構造を分析しません。文、段落またはアイデアの途中でカットが発生するかどうかに関係なく、コンテンツを一定の間隔でスライスするだけです。
-
固定サイズのチャンクの仕組み:
-
ルールの例:ドキュメントを1000トークンごと(または3000文字ごとに)分割します。
-
オプションの重複:関連するcontextを分割するリスクを低減するために、一部の実装では、重要なcontextが境界で失われないように、連続したチャンク間の重複(たとえば、200トークンの重複)を追加します。
-
-
固定サイズのチャンクの利点:
-
高速処理:セマンティック分析、LLM推論、コンテンツ理解は必要ありません。カウントしてカット。
-
低リソース消費: CPU/GPUおよびメモリー使用量が最小限であるため、大規模なデータセットに対してスケーラブルになります。
-
実装が容易:単純なスクリプトまたは標準テキスト処理ライブラリと連携します。
-
-
固定サイズのチャンクの制限:
-
セマンティック認識の欠如:チャンクは、文、段落、または論理セクションを切り離し、不完全または断片化されたアイデアにつながる可能性があります。
-
取得精度の低下:セマンティック検索やRetrieval-Augmented Generation (RAG)などのアプリケーションでは、チャンクの境界が不十分な場合、取得した回答の関連性と品質に影響する可能性があります。
-
-
固定サイズのチャンクを使用する場合:
-
処理速度とスケーラビリティが最優先事項である場合。
-
セマンティック精度が重要でない大規模なドキュメント取り込みパイプラインの場合。
-
後の絞込みまたはセマンティック分析がダウンストリームで実行されるシナリオの最初のステップとして。
-
これは、テキストを分割する非常に簡単な方法です。

-
これが固定チャンクの主なプロセスです。

ノート:このコードをダウンロードして、固定チャンクをより高速に処理します:
oci_genai_llm_context_fast.py -
セマンティック・チャンキング
oci_genai_llm_context.pyからコードをダウンロードします。
-
Semantic Chunkingとは?
セマンティック・チャンキングは、大きなドキュメント(PDF、プレゼンテーション、記事など)がチャンクと呼ばれる小さな部分に分割され、各チャンクが意味的に一貫したテキスト・ブロックを表すテキスト前処理手法です。
従来の固定サイズのチャンク(たとえば、1000トークンごとまたはX文字ごとに分割する)とは異なり、セマンティック・チャンクは、人工知能(通常は大規模言語モデル- LLM)を使用して、トピック、セクションおよびcontextを尊重して自然コンテンツの境界を検出します。
セマンティック・チャンキングは、テキストを任意に切断するのではなく、各セクションの完全な意味を保持し、スタンドアロンのコンテキスト対応ピースを作成しようとします。
-
セマンティック・チャンク化により処理速度が低下する理由
固定サイズに基づく従来のチャンク化プロセスは高速です。システムはトークンまたは文字のみをカウントし、それに応じて切り取ります。セマンティック・チャンク化では、セマンティック分析のいくつかの追加ステップが必要です。
- 分割前の全文(または大きなブロック)の読取りおよび解釈: LLMは、最適なチャンク境界を識別するためにコンテンツを理解する必要があります。
- LLMプロンプトまたはトピック分類モデルの実行:多くの場合、LLMに対して「これはアイデアの終わりですか。」や「この段落で新しいセクションを開始しますか。」などの質問を尋ねます。
- メモリーおよびCPU/GPU使用率の向上:モデルはチャンク決定を行う前に大きいテキスト・ブロックを処理するため、リソース消費は大幅に高くなります。
- 順次および増分的な意思決定:セマンティック・チャンク化は、多くの場合、ステップ(たとえば、10,000トークン・ブロックを分析し、そのブロック内のチャンク境界を改良)で機能するため、合計処理時間が長くなります。
ノート:
- マシンの処理能力に応じて、セマンティック・チャンクを使用して、最初の実行をファイナライズするのに長い時間がかかります。
- このアルゴリズムを使用して、OCI生成AIを使用してカスタマイズされたチャンクを生成できます。
-
セマンティック・チャンキングの仕組み:
-
smart_split_text():全文を10KBの小さい部分で区切ります(他の戦略を採用するように構成できます)。最後の段落がわかります。段落の一部が次のテキスト部分にある場合、この部分は処理で無視され、次の処理テキスト・グループに追加されます。 -
semantic_chunk():このメソッドでは、OCI LLMメカニズムを使用して段落を区切ります。これには、タイトル、表のコンポーネント、スマート・チャンクを実行する段落を識別するためのインテリジェンスが含まれます。ここでは、セマンティック・チャンク手法を使用します。共通の処理と比較して、ミッションの完了にはより多くの時間がかかります。そのため、最初の処理には時間がかかりますが、次にFAISSの事前保存されたすべてのデータをロードします。 -
split_llm_output_into_chapters():このメソッドは、チャンクをファイナライズし、章を区切ります。
ノート:このコードをダウンロードして、セマンティック・チャンクを処理します:
oci_genai_llm_context.py -
GraphRAGを使用したセマンティック・チャンク化
oci_genai_llm_graphrag.pyからコードをダウンロードします。
GraphRAG (Graph-Augmented Retrieval-Augmented Generation)は、従来のベクトルベースの取得と構造化されたナレッジ・グラフを組み合せた高度なAIアーキテクチャです。標準RAGパイプラインでは、言語モデルがベクトル・データベース(FAISSなど)からセマンティック類似度を使用して関連するドキュメント・チャンクを取得します。ただし、ベクトルベースの取得は構造化されていない方法で動作し、埋め込みや距離メトリックのみに依存します。これは、より深いコンテキスト的または関係的な意味を欠くことがあります。
GraphRAGは、エンティティ、概念、コンポーネントおよびその関係がノードおよびエッジとして明示的に表されるナレッジ・グラフ・レイヤーを導入することで、このプロセスを強化します。このグラフベースのcontextにより、言語モデルは、ベクトル類似性のみでは取得できない関係、階層および依存関係を推論できます。
-
セマンティック・チャンクとGraphRAGを組み合せる理由
セマンティック・チャンク化とは、章、見出し、セクション、論理的な区分など、コンテンツの構造に基づいて、大規模なドキュメントを意味のある単位またはチャンクにインテリジェントに分割するプロセスです。純粋に文字制限やナイーブな段落分割によって文書を分割するのではなく、セマンティック・チャンクは、人間の理解とよりよく合致する、高品質でcontext対応のチャンクを生成します。
-
GraphRAGの利点のセマンティック・チャンク:
-
拡張されたナレッジ表現:
- セマンティック・チャンクは、コンテンツの論理的な境界を保持します。
- これらのチャンクから抽出されたナレッジ・グラフは、エンティティ、システム、API、プロセスまたはサービス間の正確な関係を維持します。
-
マルチモーダル・コンテキスト取得(言語モデルは両方を取得します):
- ベクトル・データベースからの非構造化context (セマンティック類似性)。
- ナレッジ・グラフからの構造化context (エンティティ相関トリプル)。
- このハイブリッド・アプローチは、より完全で正確な回答につながります。
-
改善された推論機能:
- グラフベースの取得により、リレーショナル推論が可能になります。
- LLMは、次のような質問に答えることができます。
- Order APIはどのサービスに依存しますか。
- SOA Suiteの一部であるコンポーネントはどれですか。
- これらのリレーショナル問合せは、埋込みのみのアプローチでは不可能です。
-
説明可能性とトレーサビリティの向上:
- グラフの関係は、人間が判読可能で透明です。
- ユーザーは、テキスト・ナレッジと構造ナレッジの両方からアンサーがどのように導出されるかを調べることができます。
-
ハルシネーションの削減:このグラフはLLMの制約として機能し、ソース・ドキュメントから抽出された検証済関係およびファクト接続へのレスポンスをアンカーします。
-
複雑なドメイン間のスケーラビリティ:
- 技術ドメイン(API、マイクロサービス、法的契約、ヘルスケア標準など)では、コンポーネント間の関係はコンポーネント自体と同じくらい重要です。
- GraphRAGとセマンティック・チャンク・スケールを組み合せると、これらのコンテキストで効果的にスケーリングされ、テキストの深さとリレーショナル構造の両方が維持されます。
ノート:
- graphRAGを使用してセマンティック・チャンクを処理するコードをここからダウンロードします:
oci_genai_llm_graphrag.py。 - 次のものが必要になります。
- Neo4JオープンソースのグラフOSデータベースを使用してテストするためにインストールされ、アクティブになっているdocker。
- neo4j Pythonライブラリをインストールします。
このコードには2つのメソッドがあります。
-
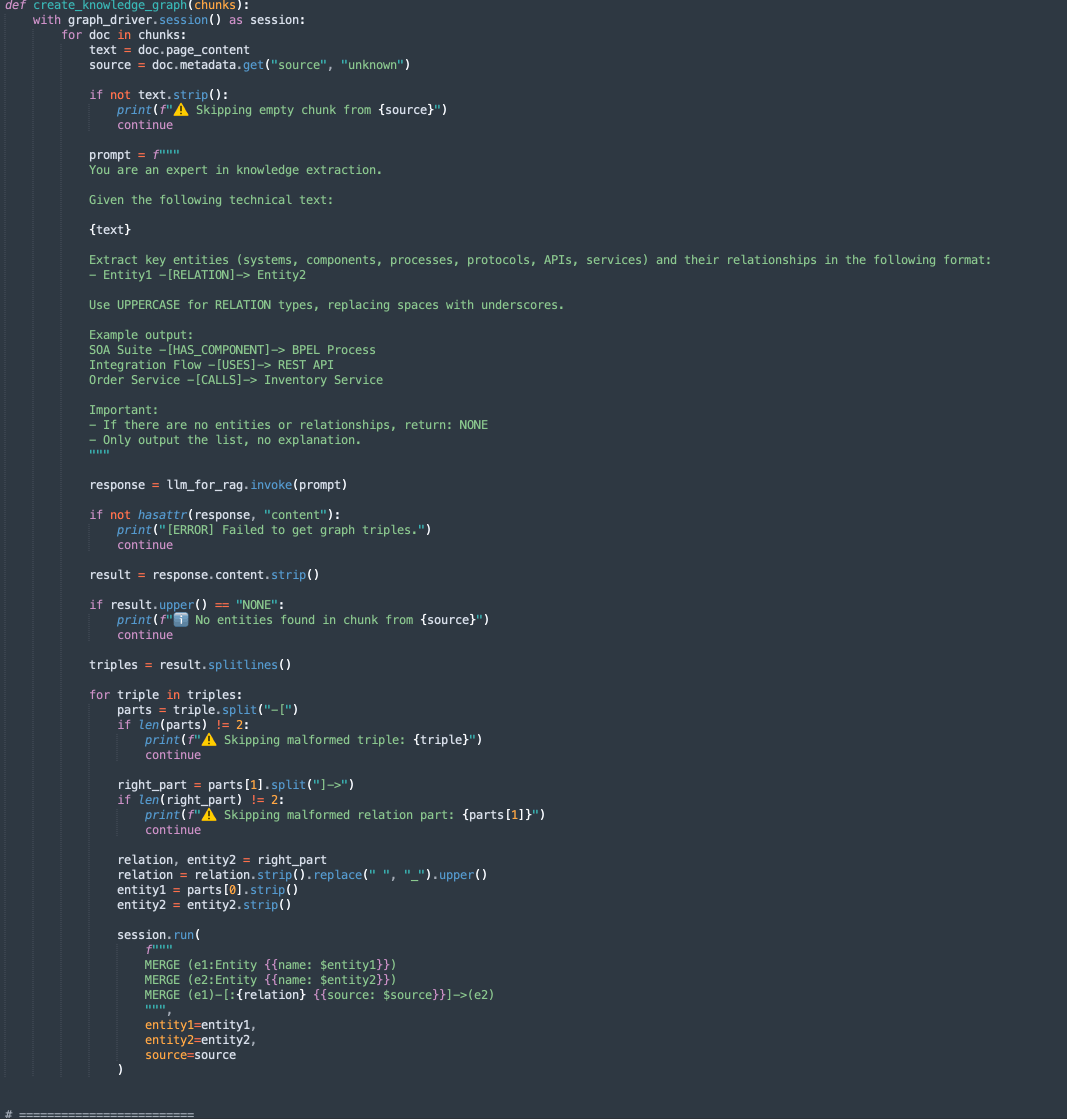
create_knowledge_graph:-
このメソッドは、テキスト・チャンクからエンティティおよび関係を自動的に抽出し、Neo4jナレッジ・グラフに格納します。
-
ドキュメント・チャンクごとに、LLM (Large Language Model)にコンテンツを送信し、エンティティ(システム、コンポーネント、サービス、APIなど)とその関係の抽出を求めるプロンプトを表示します。
-
各行が解析され、Entity1、RELATIONおよびEntity2が抽出されます。
-
Cypher問合せを使用して、次の情報をノードおよびエッジとしてNeo4jグラフ・データベースに格納します。
MERGE (e1:Entity {name: $entity1}) MERGE (e2:Entity {name: $entity2}) MERGE (e1)-[:RELATION {source: $source}]->(e2)
-
-
-
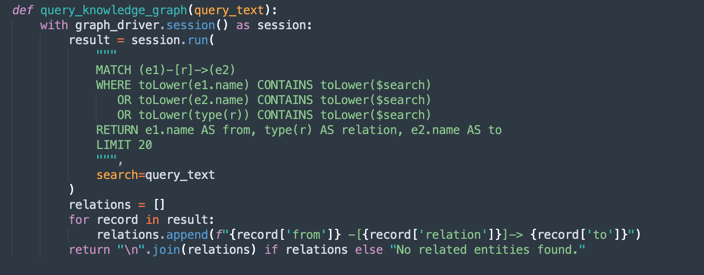
query_knowledge_graph:-
このメソッドは、Neo4jナレッジ・グラフを問い合せて、特定のキーワードまたは概念に関連する関係を取得します。
-
次を検索するCypher問合せを実行します。
Any relationship (e1)-[r]->(e2) Where e1.name, e2.name, or the relationship type contains the query_text (case-insensitive). -
次のようにフォーマットされた最大20個の一致するトリプルを返します。
Entity1 -[RELATION]-> Entity2
-
ノート:
Neo4j使用方法:
この実装では、デモンストレーションおよびプロトタイピングの目的で、Neo4jを組込みナレッジ・グラフ・データベースとして使用します。Neo4jは、開発、テストおよび中小から中規模のワークロードに適した強力で柔軟なグラフ・データベースですが、特に高可用性、スケーラビリティおよび高度なセキュリティ・コンプライアンスを必要とする環境では、エンタープライズ・グレード、ミッションクリティカル、または非常にセキュアなワークロードの要件を満たしていない可能性があります。
本番環境およびエンタープライズ・シナリオでは、次の機能を提供するOracle Databaseとグラフ機能を利用することをお薦めします。
エンタープライズグレードの信頼性とセキュリティ。
ミッションクリティカルなワークロードのスケーラビリティ。
リレーショナル・データと統合されたネイティブ・グラフ・モデル(プロパティ・グラフおよびRDF)。
高度なアナリティクス、セキュリティ、高可用性、ディザスタ・リカバリ機能。
Oracle Cloud Infrastructure(OCI)の完全な統合。
Oracle Databaseをグラフ・ワークロードに使用することで、組織は構造化データ、半構造化データ、グラフ・データを単一のセキュアでスケーラブルなエンタープライズ・プラットフォームに統合できます。
タスク3: Oracle IntegrationおよびOracle SOA Suiteコンテンツの問合せの実行
次のコマンドを実行します
FOR FIXED CHUNKING TECHNIQUE (MORE FASTER METHOD)
python oci_genai_llm_context_fast.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
FOR SEMANTIC CHUNKING TECHNIQUE
python oci_genai_llm_context.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
FOR SEMANTIC CHUNKING COMBINED WITH GRAPHRAG TECHNIQUE
python oci_genai_llm_graphrag.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
ノート:
--deviceおよび--gpu_nameパラメータを使用すると、マシンにGPUがある場合はGPUを使用して、Pythonでの処理を高速化できます。このコードはローカル・モデルでも使用できます。
提供されるコンテキストでは、Oracle SOA SuiteとOracle Integrationが区別され、次の点を考慮してコードをテストできます。
- 問合せはOracle SOA Suiteに対してのみ行う必要があります。したがって、Oracle SOA Suiteドキュメントのみを考慮する必要があります。
- 問合せはOracle Integrationに対してのみ行う必要があります。したがって、Oracle Integrationドキュメントのみを考慮する必要があります。
- 問合せでは、Oracle SOA SuiteとOracle Integrationの比較が必要です。そのため、すべてのドキュメントを考慮する必要があります。
次のコンテキストを定義することで、ドキュメントを正しく解釈するのに役立ちます。
次の図は、Oracle SOA SuiteとOracle Integrationの比較の例を示しています。

次のステップ
このコードは、インテリジェントなPDF分析のためのOCI生成AIの適用を示しています。これにより、ユーザーはセマンティック検索と生成AIモデルを使用して大量のドキュメントを効率的に問い合せて、正確な自然言語レスポンスを生成できます。
このアプローチは、法律、コンプライアンス、テクニカル・サポート、学術研究など、さまざまな分野に適用できるため、情報の取得がはるかに迅速でスマートになります。
関連リンク
確認
- 著者 - 星川クリスティアーノ(Oracle LAD Aチーム・ソリューション・エンジニア)
その他の学習リソース
docs.oracle.com/learnで他のラボを確認するか、Oracle Learning YouTubeチャネルで無料のラーニング・コンテンツにアクセスしてください。また、education.oracle.com/learning-explorerにアクセスして、Oracle Learning Explorerになります。
製品ドキュメントについては、Oracle Help Centerを参照してください。
Analyze PDF Documents in Natural Language with OCI Generative AI
G29541-05
Copyright ©2025, Oracle and/or its affiliates.