AWS Glue 데이터 카탈로그로 외부 데이터 질의
자율운영 AI 데이터베이스는 Amazon AWS Glue Data Catalog 인스턴스와 동기화하기 위한 시스템을 지원합니다.
AWS Glue 데이터 카탈로그로 질의 정보
자율운영 AI 데이터베이스를 사용하면 AWS(Amazon Web Service) 접착제 데이터 카탈로그 메타데이터와 동기화할 수 있습니다. 데이터베이스 외부 테이블은 AWS Glue에서 수집한 모든 테이블에 대해 Amazon Simple Storage Service(S3)에 저장된 데이터에 대해 자율운영 AI 데이터베이스에 의해 자동으로 생성됩니다. 사용자는 외부 데이터 소스에 대한 스키마를 수동으로 파생시키고 외부 테이블을 생성할 필요 없이 자율운영 AI 데이터베이스에서 S3에 저장된 데이터를 쿼리할 수 있습니다.
Amazon AWS Glue Data Catalog는 데이터 전문가가 데이터를 검색하고 AWS 클라우드에서 데이터 거버넌스를 지원하는 중앙 집중식 메타데이터 관리 서비스입니다. 자율운영 AI 데이터베이스 인스턴스는 자동으로 데이터 카탈로그 메타데이터를 AWS Glue Data Catalog와 동기화할 수 있어 데이터베이스 사용자가 자율운영 AI 데이터베이스를 즉시 사용하여 AWS 클라우드에 저장된 데이터를 쿼리할 수 있습니다.
AWS Glue Data Catalog와 동기화하는 것은 OCI Data Catalog와 동기화하는 것과 동일한 속성을 가집니다. 동기화는 동적이므로 기본 데이터의 변경 사항에 대해 데이터베이스를 최신 상태로 유지하므로 수백~수천 개의 테이블을 자동으로 유지 관리하므로 관리 비용이 절감됩니다.
AWS Glue 데이터 카탈로그를 사용한 쿼리 관련 개념
다음 개념에 대한 이해는 AWS(Amazon Web Service) Glue 데이터 카탈로그로 질의하는 데 필요합니다.
AWS Glue 데이터 카탈로그: 데이터베이스
AWS Glue 데이터베이스는 논리적 그룹으로 구성된 관계형 테이블 정의 모음을 나타냅니다. 각 AWS Glue 데이터 카탈로그 인스턴스는 여러 데이터베이스를 관리합니다.
AWS Glue 데이터 카탈로그: 테이블
AWS Glue 테이블은 AWS 클라우드에 저장된 데이터에 대한 관계형 테이블을 나타냅니다. AWS Glue 테이블은 기본 데이터의 스키마를 정의하며 열 정보, 분할 영역 정보, 직렬화 정보, 저장 영역 정보, 통계, 사용자 정의 메타데이터 및 기타 메타데이터로 구성됩니다. AWS Glue 데이터 카탈로그의 테이블은 수동으로 생성하거나 AWS Glue 크롤러를 사용하여 자동으로 생성할 수 있습니다.
접착제 데이터 카탈로그: Crawler
Crawler를 사용하여 AWS Glue 데이터 카탈로그를 테이블로 채울 수 있습니다. 이는 대부분의 AWS Glue 사용자가 사용하는 기본 방법입니다. Crawler는 단일 실행에서 여러 데이터 저장소를 크롤할 수 있습니다. 완료되면 Crawler는 데이터 카탈로그에 하나 이상의 테이블을 생성하거나 갱신합니다. AWS Glue에서 정의하는 ETL(추출, 변환 및 로드) 작업은 이러한 데이터 카탈로그 테이블을 소스 및 대상으로 사용합니다. ETL 작업은 소스 및 대상 데이터 카탈로그 테이블에 지정된 데이터 저장소에서 읽고 데이터 저장소에 씁니다.
AWS Glue 테이블은 사용자가 수동으로 생성하거나 미리 정의된 크롤러나 사용자 정의 크롤러를 사용하여 자동으로 생성할 수 있습니다. 크롤러는 기본 데이터 저장소(예: Amazon S3)에 연결하고, 데이터 스키마를 파생시키기 위한 분류기를 호출하고, 추론된 메타데이터를 저장하기 위한 AWS Glue 테이블을 생성합니다. AWS Glue는 CSV, JSON, Parquet 및 AVRO와 같은 일반적인 파일 유형에 대한 분류기를 제공합니다.
자율운영 AI 데이터베이스 및 AWS Glue 간 매핑
동기화 프로세스 중에 외부 테이블은 AWS Glue Data Catalog 데이터베이스 및 Amazon S3의 테이블에서 파생된 자율운영 AI 데이터베이스에 생성됩니다.
AWS Glue는 데이터베이스 및 테이블에서 수집된 메타데이터를 구성합니다. AWS Glue 데이터베이스는 관계형 테이블 정의 모음입니다. 테이블과 연관된 파일의 공통 스키마 및 속성을 설명하는 AWS Glue 테이블입니다.
AWS Glue는 속성을 나타내는 관계형 모델을 따릅니다. 관계형 스키마에 계층적 스키마 매핑의 경우 AWS Glue는 반구조적 데이터의 스키마를 추론하고 ETL 프로세스를 사용하여 데이터를 관계형 스키마로 병합합니다.
다음 표는 OCI 데이터 카탈로그 개념과 AWS Glue 데이터 카탈로그 개념 간의 매핑을 나타냅니다.
| OCI 데이터 카탈로그 | AWS Glue 데이터 카탈로그 | Oracle Database |
|---|---|---|
| 데이터 자산 | Database | 스키마 |
| 폴더 | (버킷) | 스키마 |
| 논리적 개체 | 테이블 | 테이블 |
AWS Glue 데이터 카탈로그로 질의하기 위한 사용자 워크플로우
AWS Glue Data Catalog로 AWS S3 데이터를 쿼리하기 위한 기본 사용자 워크플로우에는 AWS Glue Data Catalog에 연결하고, 자율운영 AI 데이터베이스와 동기화하여 외부 테이블을 자동으로 생성한 다음, S3 데이터를 쿼리하는 작업이 포함됩니다.
데이터베이스 데이터 카탈로그 관리자는 자율운영 AI 데이터베이스 인스턴스와 AWS Glue 데이터 카탈로그 인스턴스 간에 접속을 생성한 다음, AWS Glue 데이터 카탈로그와 자율운영 AI 데이터베이스 간에 동기화를 구성하고 실행합니다. 자율운영 AI 데이터베이스는 S3에 저장된 데이터에 대해 AWS Glue에서 수집한 테이블에 대한 외부 테이블을 자동으로 생성합니다.
데이터베이스 데이터 카탈로그 질의 관리자 또는 데이터베이스 관리자는 생성된 외부 테이블에 대한 READ 액세스 권한을 부여하므로, 외부 데이터 소스에 대한 스키마를 수동으로 파생시키고 외부 테이블을 생성할 필요 없이 데이터 분석가 및 기타 데이터베이스 사용자가 자율운영 AI 데이터베이스를 찾아보고 질의할 수 있습니다.
사용자
아래 표에서는 사용자 워크플로 작업을 수행하는 다양한 사용자 유형에 대해 설명합니다.
| User | 설명 |
|---|---|
| 데이터베이스 데이터 카탈로그 관리자 | DCAT_SYNC 롤을 가진 데이터베이스 사용자입니다. |
| 데이터베이스 데이터 카탈로그 질의 관리자 | 데이터베이스 사용자는 자동으로 생성된 외부 테이블에 대한 액세스 권한을 다른 사용자에게 부여할 수 있습니다. |
| 데이터 분석가 | 자동 생성된 외부 테이블을 쿼리하거나 AWS Glue 데이터 카탈로그와 직접 상호 작용하여 AWS S3에서 데이터를 쿼리하는 자율운영 AI 데이터베이스의 데이터베이스 사용자입니다. |
| AWS Glue 데이터 카탈로그 사용자 | AWS Glue Data Catalog에 액세스할 수 있는 AWS 사용자입니다. |
| AWS S3 Object Storage 사용자 | AWS S3에 저장된 데이터에 액세스할 수 있는 AWS 사용자 |
사용자 워크플로우
주: DBMS_DCAT 패키지는 AWS Glue Data Catalog를 사용하여 AWS S3 객체 스토리지를 쿼리하는 데 필요한 작업을 수행하는 데 사용할 수 있습니다. DBMS_DCAT Package를 참조하십시오.
| 작업 | 사용자의 사용자 | 설명 |
|---|---|---|
| 정책 생성 | 데이터베이스 데이터 카탈로그 관리자 | 자율운영 AI 데이터베이스 사용자 인증서는 AWS Glue 데이터 카탈로그에 액세스하고 S3 객체 스토리지에서 읽을 수 있는 적절한 권한이 있어야 합니다. 자세한 내용은 필수 인증서 및 IAM 정책을 참조하십시오. |
| 인증서 생성 | 데이터베이스 데이터 카탈로그 관리자 | {::nomarkdown} <p>AWS Glue 데이터 카탈로그에 액세스하고 S3 객체 스토리지를 질의하기 위해 데이터베이스 인증서가 준비되어 있는지 확인합니다. 사용자가 DBMS_CLOUD.CREATE_CREDENTIAL를 호출하여 사용자 인증서를 생성합니다.</p><p>주: AWS(Amazon Web Services) 인증서만 지원됩니다. AWS ARN(Amazon Resource Names) 인증서는 지원되지 않습니다.</p><p>추가 정보: DBMS_CLOUD CREATE_CREDENTIAL Procedure,</p> |
| Connect | 데이터베이스 데이터 카탈로그 관리자 | 자율운영 AI 데이터베이스 인스턴스와 AWS Glue 데이터 카탈로그 인스턴스 간에 접속을 설정합니다. 연결은 AWS Glue Data Catalog User의 권한을 사용합니다. 자율운영 AI 데이터베이스 인스턴스에서 여러 AWS Glue 데이터 카탈로그 인스턴스로의 연결이 지원됩니다. 자율운영 AI 데이터베이스 인스턴스와 사용자가 AWS Glue 데이터 카탈로그 인스턴스 간에 접속을 시작하려면 다음과 같이 하십시오.
연결이 완료되면 자율운영 AI 데이터베이스는 AWS Glue 카탈로그 ID, 영역, 끝점 및 인증서 객체와 같은 연관된 메타데이터를 저장합니다. 자세한 내용은 SET_DATA_CATALOG_CONN 프로시저, UNSET_DATA_CATALOG_CONN 프로시저, DBMS_DCAT를 참조하십시오. SET_DATA_CATALOG_CREDENTIAL, DBMS_DCAT.SET_OBJECT_STORE_CREDENTIAL |
| 동기화 | 데이터베이스 데이터 카탈로그 관리자 | 사용자는 동기화는 다음을 수행합니다.
|
| 동기화 모니터링 | 데이터베이스 데이터 카탈로그 관리자 | 사용자는 USER_LOAD_OPERATIONS 뷰를 질의하여 동기화 상태를 볼 수 있습니다. 동기화 프로세스가 완료되면 사용자는 External Table에 대한 매핑 세부 정보를 포함하여 동기화 결과 로그를 볼 수 있습니다. |
| 권한 부여 | 데이터베이스 데이터 카탈로그 질의 관리자, 데이터베이스 관리자 | 데이터베이스 데이터 카탈로그 질의 관리자 또는 데이터베이스 관리자는 데이터 분석가 사용자에게 생성된 외부 테이블에 대한 READ 권한을 부여해야 합니다. 이렇게 하면 데이터 분석가가 생성된 External Table을 query할 수 있습니다. |
| 질의 | 데이터 분석가 | 데이터 분석가는 GLUE$* 스키마에서 동기화된 스키마와 테이블을 검토하고 Oracle SQL을 지원하는 도구나 응용 프로그램을 통해 External Table을 query할 수 있습니다. S3의 데이터는 AWS S3 객체 스토리지 사용자의 권한을 사용하여 액세스됩니다. 추가 정보: 예제: AWS Glue 데이터 카탈로그로 질의 |
| 연결 종료 | 데이터베이스 데이터 카탈로그 관리자 | 기존 데이터 카탈로그 연관을 제거하려면 사용자가 이 작업은 연결된 AWS Glue 데이터 카탈로그 및 카탈로그에서 파생된 외부 테이블을 더 이상 사용할 계획이 없는 경우에만 수행됩니다. 이 작업은 AWS Glue 데이터 카탈로그 메타데이터를 삭제하고 자율운영 AI 데이터베이스 인스턴스에서 동기화된 외부 테이블을 삭제합니다. 자세한 내용: UNSET_DATA_CATALOG_CONN 프로시저 |
예: AWS Glue 데이터 카탈로그로 질의
이 예에서는 AWS Glue Data Catalog를 사용하여 Amazon Simple Storage Service(Amazon S3)에 저장된 데이터세트를 통해 쿼리를 실행하는 프로세스를 단계별로 안내합니다.
이 예에서 AWS Glue Data Catalog의 메타데이터는 이전에 크롤하여 데이터 카탈로그에 존재했던 Amazon S3 객체를 확인하기 위해 검사됩니다. 그런 다음 자율운영 AI 데이터베이스는 AWS Glue Data Catalog 및 Amazon S3와 연결됩니다. 데이터 카탈로그는 자율운영 AI 데이터베이스와 동기화되어 Amazon S3에 저장된 데이터 집합에 외부 테이블을 생성합니다. External Table은 Amazon S3의 데이터 집합을 query하는 데 사용됩니다.
-
AWS Glue Data Catalog에서 메타데이터를 검사합니다.
-
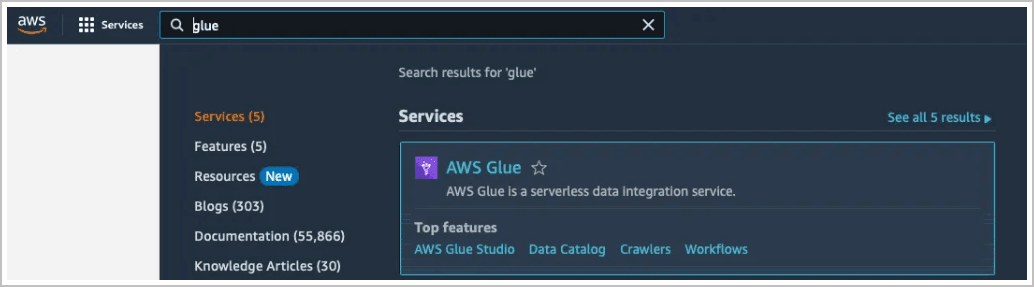
AWS Glue 콘솔을 시작합니다.
-
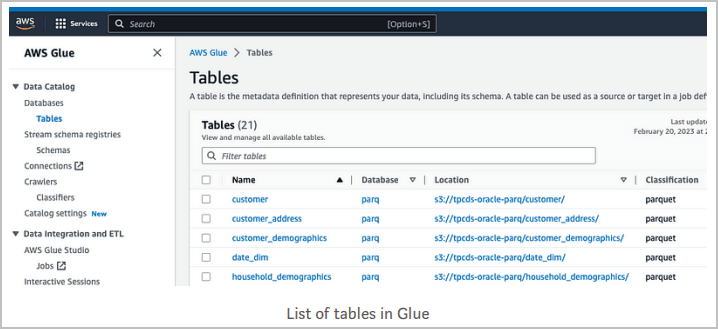
데이터 카탈로그, 데이터베이스 및 테이블로 이동하여 기존 객체를 찾습니다.
이 예제에서 일부 객체는 AWS Glue가 이전에 다음과 같이 테이블을 크롤하고 생성한 Amazon S3에 존재합니다.
-
-
AWS Glue를 자율운영 AI 데이터베이스와 연관시킵니다.
-
자율운영 AI 데이터베이스에서 인증서를 생성합니다.
다음 절차 호출에는 자율운영 AI 데이터베이스에 Amazon S3의 기본 데이터에 대한 액세스 권한을 제공하기 위한 액세스 ID 및 보안 키가 포함됩니다.
exec dbms_cloud.create_credential('CRED_AWS','<access id>', '<access key>'); -
인증서를 AWS Glue Data Catalog 및 Amazon S3 객체 스토리지와 연관시킵니다.
이러한 프로시저 호출은 각각 데이터 카탈로그와 객체 저장 영역을 인증서와 연관시킵니다.
exec dbms_dcat.set_data_catalog_credential('CRED_AWS'); exec dbms_dcat.set_object_store_credential('CRED_AWS'); -
Glue가 실행 중인 AWS 지역을 설정합니다.
exec dbms_dcat.set_data_catalog_conn(region => 'us-west-2', catalog_type=>'AWS_GLUE');
-
-
메타데이터를 동기화하여 AWS Glue 데이터베이스 및 테이블에서 파생된 자율운영 AI 데이터베이스에 외부 테이블을 생성합니다.
-
이제 연관이 완료되었으므로
all_glue_databases뷰를 사용하여 AWS Glue 데이터 카탈로그 내에 있는 데이터베이스를 찾습니다.select * from all_glue_databases order by name; -
all_glue_tables뷰를 사용하여 동기화에 사용할 수 있는 테이블 목록을 가져옵니다.select * from all_glue_tables order by database_name, name;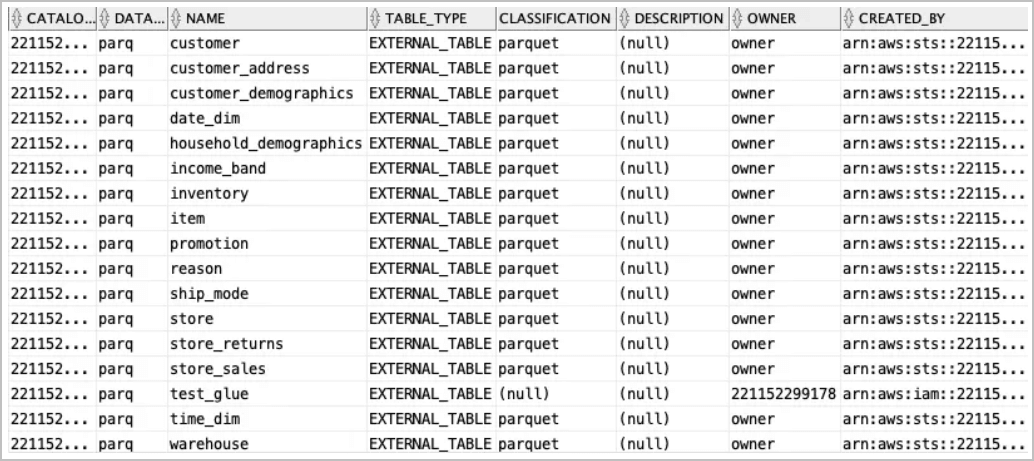
-
자율운영 AI 데이터베이스를
parq데이터베이스에 있는 두 개의 테이블store및item와 동기화합니다.begin dbms_dcat.run_sync( synced_objects => ' { "database_list": [ { "database": "parq", "table_list": ["store","item"] } ] }', error_semantics => 'STOP_ON_ERROR'); end; /
-
-
자율운영 AI 데이터베이스에서 새 객체를 검사하고 S3에서 쿼리를 실행합니다.
-
SQL Developer를 사용하여 이전 동기화 작업에서 생성한 새 객체를 확인합니다.
GLUE$PARQ_TPCDS_ORACLE_PARQ스키마는dbms_dcat.run_sync프로시저 호출에 의해 자동으로 생성되고 이름이 지정되었습니다.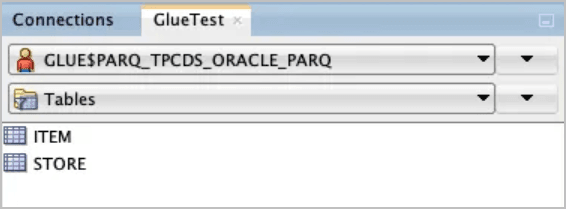
-
Amazon S3의 데이터세트 저장소에 대해 SQL 쿼리를 실행합니다.
SELECT * FROM glue$parq_tpcds_oracle_parq.store;
-