참고:
- 이 자습서에서는 Oracle Cloud에 액세스해야 합니다. 무료 계정에 등록하려면 Oracle Cloud Infrastructure Free Tier 시작하기를 참조하십시오.
- Oracle Cloud Infrastructure 인증서, 테넌시 및 구획에 대한 예제 값을 사용합니다. 실습을 완료하려면 이 값을 클라우드 환경에 해당하는 값으로 대체하십시오.
Apache Spark Streaming과 함께 OCI Data Flow를 사용하여 확장 가능하고 실시간에 가까운 애플리케이션에서 Kafka 토픽을 처리합니다.
소개
OCI(Oracle Cloud Infrastructure) Data Flow는 Apache Spark라는 오픈 소스 프로젝트를 위한 관리형 서비스입니다. 기본적으로 Spark를 사용하면 대용량 파일 처리, 스트리밍 및 데이터베이스 작업에 사용할 수 있습니다. 확장성이 뛰어난 처리 기능으로 애플리케이션을 구축할 수 있습니다. Spark는 클러스터화된 시스템을 확장 및 사용하여 최소한의 구성으로 작업을 병렬화할 수 있습니다.
Spark를 관리 서비스(Data Flow)로 사용하면 확장 가능한 여러 서비스를 추가하여 클라우드 처리의 성능을 곱할 수 있습니다. 데이터 플로우는 Spark Streaming을 처리할 수 있습니다.
스트리밍 애플리케이션은 24시간 이상 연장되는 장기간 지속적 실행이 필요하며, 단 몇 주 또는 몇 달이 걸릴 수 있습니다. 예기치 않은 오류가 발생할 경우 스트리밍 애플리케이션은 잘못된 계산 결과를 생성하지 않고 실패 지점에서 다시 시작해야 합니다. 데이터 플로우는 Spark 구조화된 스트리밍 체크포인트를 사용하여 오브젝트 스토리지 버킷에 저장할 수 있는 처리된 오프셋을 기록합니다.
참고: 데이터를 일괄 처리 전략으로 처리해야 하는 경우 다음 문서를 참조할 수 있습니다. Autonomous Database 및 Kafka에서 Oracle Cloud Infrastructure Data Flow로 대용량 파일 처리
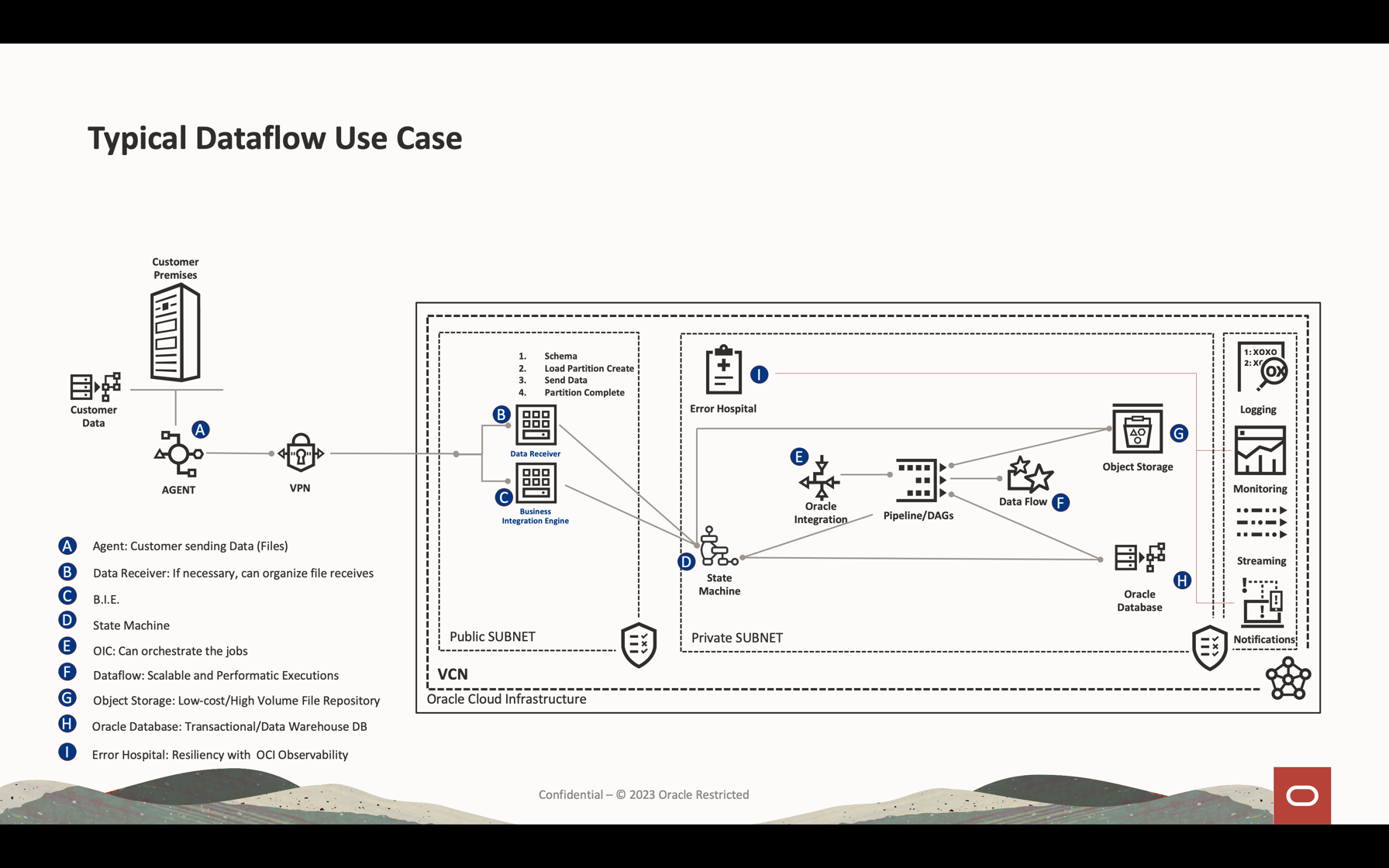
이 사용지침서에서는 데이터 볼륨 스트리밍을 처리하고 데이터베이스를 쿼리하고 데이터를 병합/결합하여 메모리의 다른 테이블을 형성하거나 거의 실시간으로 모든 대상으로 데이터를 전송하는 데 사용되는 가장 일반적인 활동을 볼 수 있습니다. 이 대용량 데이터는 매우 저렴하고 효과적인 성능을 갖춘 Kafka 대기열 및 데이터베이스에 작성할 수 있습니다.
목표
- 데이터 플로우를 사용하여 확장 가능하고 실시간에 가까운 애플리케이션에서 대량의 데이터를 처리하는 방법을 알아봅니다.
필요 조건
-
운영 Oracle Cloud 테넌트: 한 달 동안 US$ 300.00의 무료 Oracle Cloud 계정을 생성하여 이 자습서를 사용해 볼 수 있습니다. 무료 Oracle Cloud 계정 생성을 참조하십시오.
-
로컬 시스템에 설치된 OCI CLI(Oracle Cloud 명령줄 인터페이스): OCI CLI 설치 링크입니다.
-
로컬 시스템에 설치된 Apache Spark 애플리케이션입니다. 로컬에서 Oracle Cloud Infrastructure Data Flow 애플리케이션 개발, 클라우드에 배포를 검토하여 로컬 및 데이터 플로우에서 개발하는 방법을 알아보십시오.
참고: Apache Spark를 설치할 수 있는 공식 페이지입니다. 각 운영 체제 유형(Linux/Mac OS/Windows)에 대해 Apache Spark를 설치하는 다른 절차가 있습니다.
-
Spark Submit CLI가 설치되었습니다. Spark Submit CLI 설치 링크입니다.
-
로컬 시스템에 Maven이 설치됩니다.
-
OCI 개념에 대한 지식:
- 구획
- IAM 정책
- 테넌트
- 리소스의 OCID
작업 1: 오브젝트 스토리지 구조 생성
오브젝트 스토리지가 기본 파일 리포지토리로 사용됩니다. 다른 유형의 파일 저장소를 사용할 수 있지만 Object Storage는 성능으로 파일을 조작하는 간단하고 저렴한 방법입니다. 이 사용지침서에서는 두 애플리케이션이 오브젝트 스토리지에서 대용량 CSV 파일을 로드하여 Apache Spark가 대용량 데이터를 처리하는 빠르고 스마트한 방법을 보여줍니다.
-
구획 생성: 구획은 클라우드 리소스를 구성하고 격리하는 데 중요합니다. IAM 정책별로 리소스를 격리할 수 있습니다.
-
이 링크를 사용하여 구획에 대한 정책을 이해하고 설정할 수 있습니다. 구획 관리
-
이 자습서에서 두 애플리케이션의 모든 리소스를 호스트할 하나의 구획을 생성합니다. analytics라는 구획을 생성합니다.
-
Oracle Cloud 기본 메뉴로 이동하여 ID 및 보안, 구획을 검색합니다. 구획 섹션에서 구획 생성을 누르고 이름을 입력합니다.
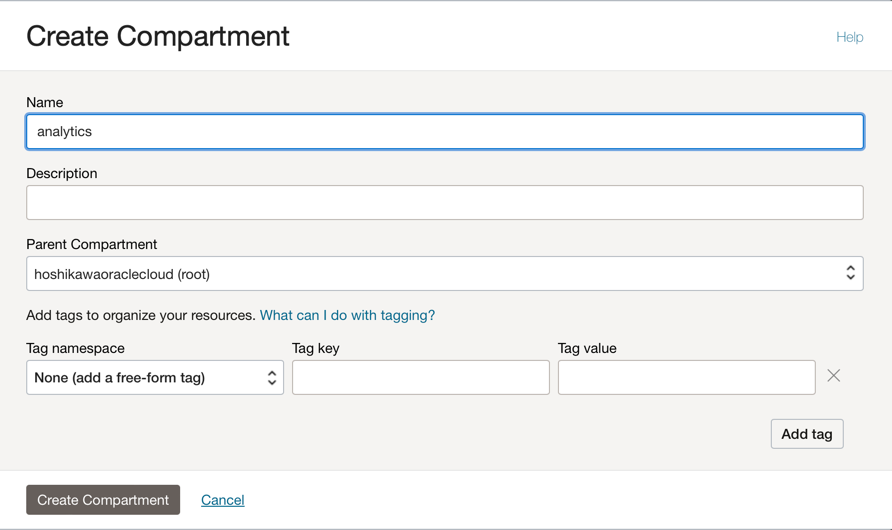
참고: 사용자 그룹에 대한 액세스 권한을 부여하고 사용자를 포함해야 합니다.
-
구획 생성을 눌러 구획을 포함합니다.
-
-
오브젝트 스토리지에 버킷 생성: 버킷은 객체를 저장하기 위한 논리적 컨테이너이므로 이 데모에 사용된 모든 파일이 이 버킷에 저장됩니다.
-
Oracle Cloud 기본 메뉴로 이동하여 스토리지 및 버킷을 검색합니다. Buckets 섹션에서 이전에 생성한 구획(분석)을 선택합니다.
-
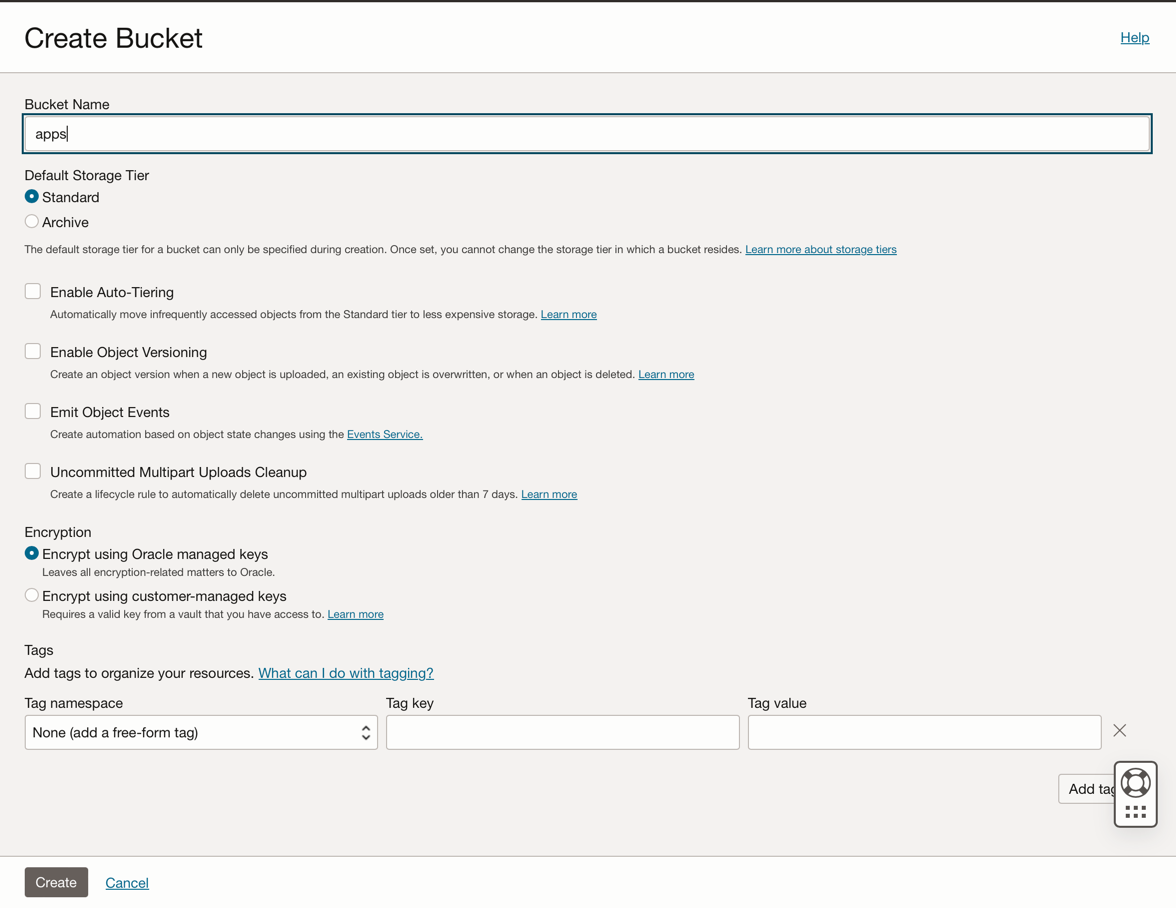
버킷 생성을 누릅니다. 네 개의 버킷 생성: 앱, 데이터, 데이터 흐름 로그, 지갑
-
4개의 버킷과 함께 버킷 이름 정보를 입력하고 기본 선택사항으로 다른 매개변수를 유지 관리합니다.
-
각 버킷에 대해 생성을 누릅니다. 생성된 버킷을 볼 수 있습니다.
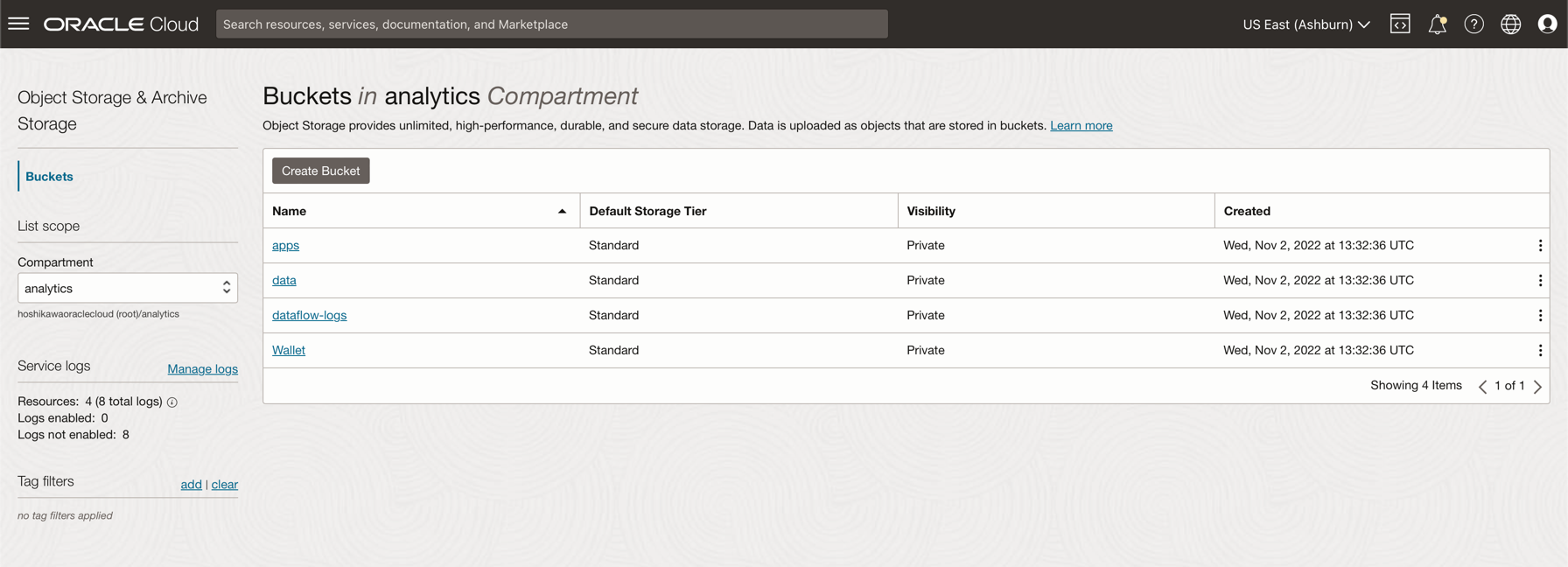
-
참고: 버킷에 대한 IAM 정책을 검토하십시오. 데모 애플리케이션에서 해당 버킷을 사용하려면 정책을 설정해야 합니다. Object Storage 개요 및 IAM 정책에서 개념과 설정을 검토할 수 있습니다.
작업 2: Autonomous Database 생성
Oracle Cloud Autonomous Database는 Oracle Database를 위한 관리형 서비스입니다. 이 자습서에서는 보안상의 이유로 응용 프로그램이 전자 지갑을 통해 데이터베이스에 연결됩니다.
-
Provision Autonomous Database에 설명된 대로 Autonomous Database를 인스턴스화합니다.
-
Oracle Cloud 기본 메뉴에서 데이터 웨어하우스 옵션을 선택하고 Oracle Database 및 Autonomous Data Warehouse를 선택한 다음 구획 분석을 선택하고 자습서에 따라 데이터베이스 인스턴스를 생성합니다.
-
인스턴스 이름을 처리된 로그로 지정하고 데이터베이스 이름으로 로그를 선택하면 애플리케이션의 코드를 변경할 필요가 없습니다.
-
ADMIN 비밀번호를 입력하고 Wallet zip 파일을 다운로드합니다.
-
데이터베이스를 생성한 후 ADMIN 사용자 비밀번호를 설정하고 전자 지갑 zip 파일을 다운로드할 수 있습니다.
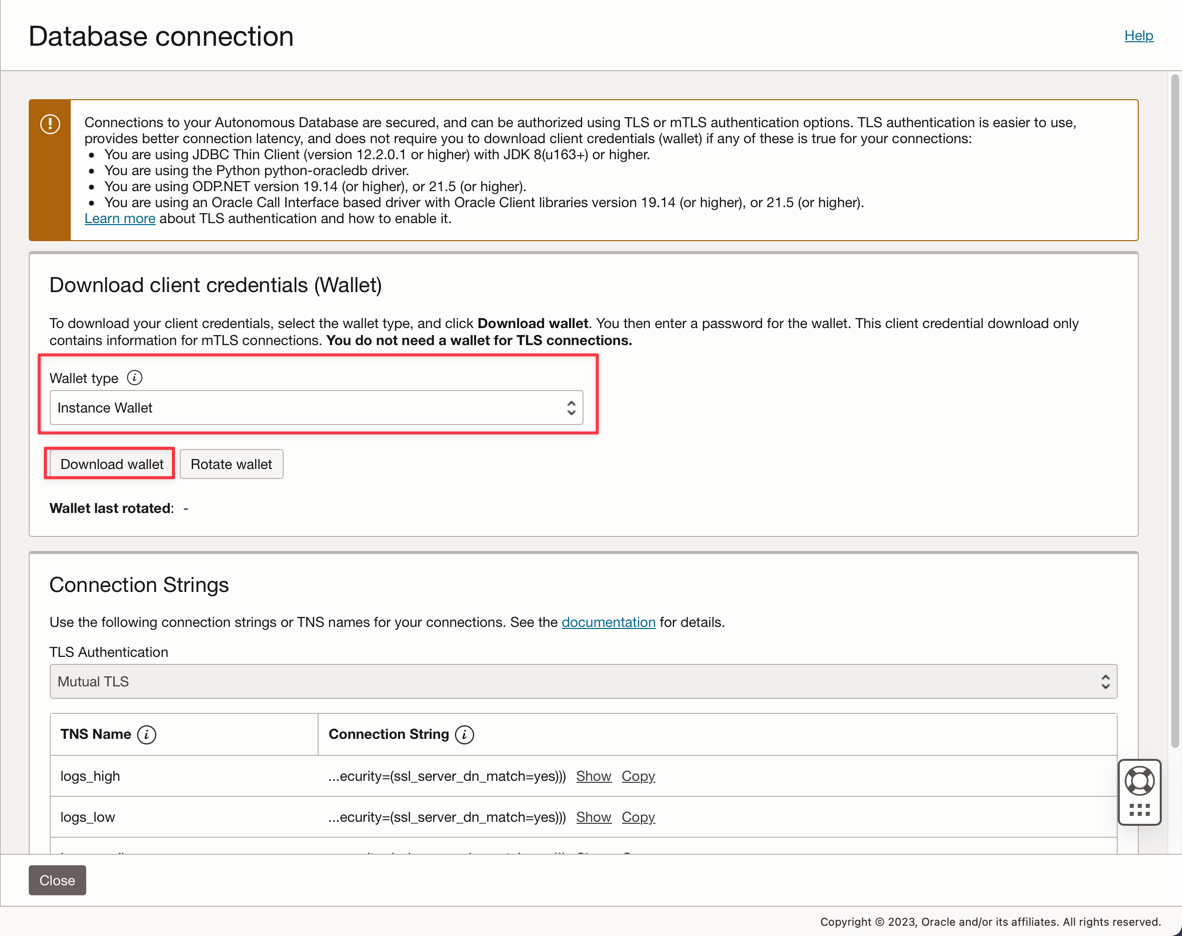
-
전자 지갑 zip 파일(
Wallet_logs.zip)을 저장하고 ADMIN 비밀번호에 주석을 추가합니다. 애플리케이션 코드를 설정해야 합니다. -
Storage, Buckets로 이동합니다. analytics 구획으로 변경하면 Wallet 버킷이 표시됩니다. 클릭하세요.
-
전자 지갑 zip 파일을 업로드하려면 업로드를 누르고 Wallet_logs.zip 파일을 첨부하십시오.
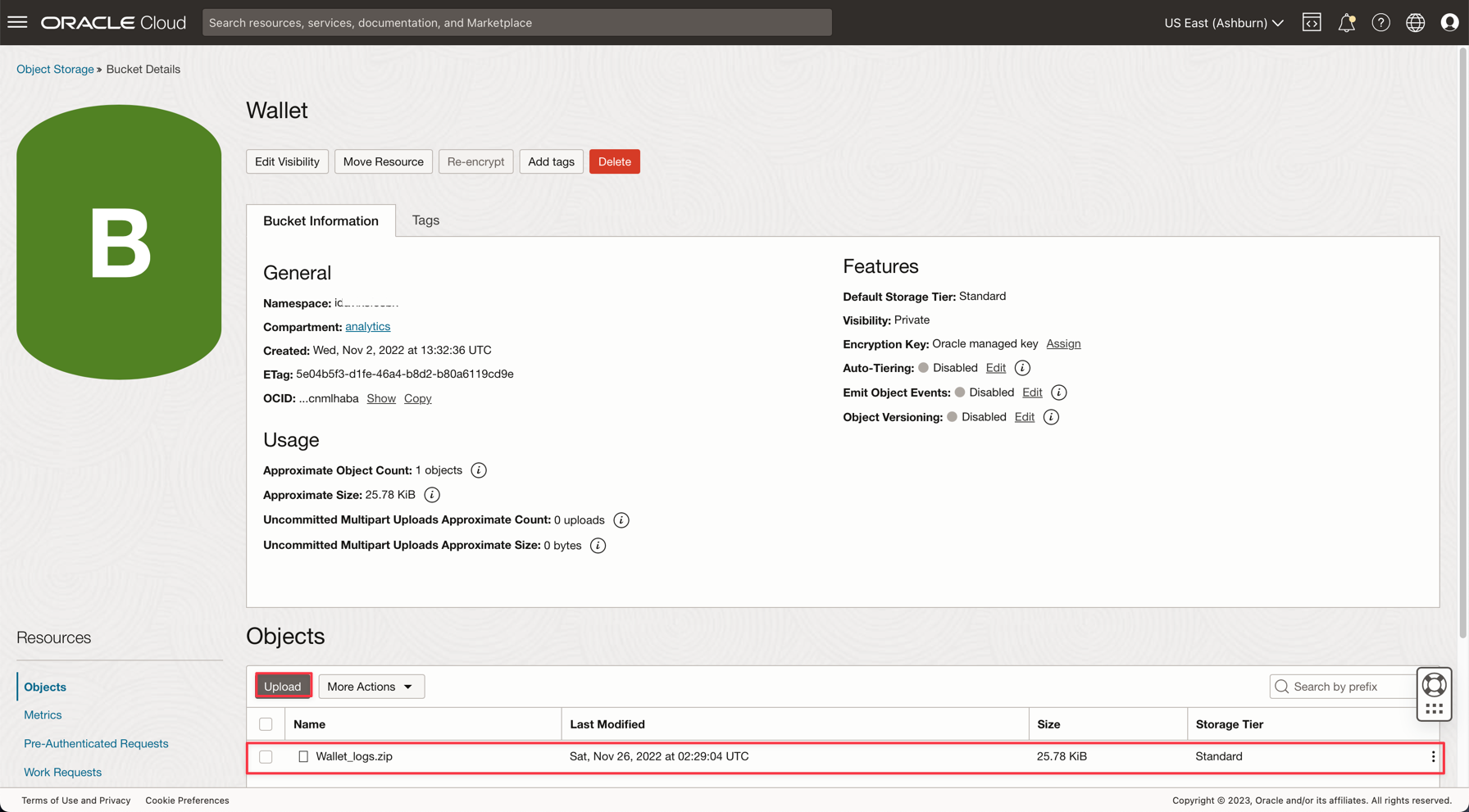
참고: 여기에서 Autonomous Database에 액세스하기 위한 IAM 정책 검토: Autonomous Database에 대한 IAM 정책
작업 3: CSV 샘플 파일 업로드
Apache Spark의 성능을 입증하기 위해 애플리케이션은 1,000,000개의 라인이 있는 CSV 파일을 읽습니다. 이 데이터는 하나의 명령행만으로 Autonomous Data Warehouse 데이터베이스에 삽입되고 Kafka 스트리밍(Oracle Cloud Streaming)에 게시됩니다. 이러한 모든 리소스는 확장 가능하며 대용량 데이터에 적합합니다.
-
다음 2개의 링크를 다운로드하고 데이터 버킷에 업로드합니다.
-
주:
- organizations.csv에는 로컬 시스템에서 응용 프로그램을 테스트하기 위한 행이 100개뿐입니다.
- organizations1M.csv에는 1,000,000개의 행이 포함되어 있으며 데이터 플로우 인스턴스에서 실행되는 데 사용됩니다.
-
Oracle Cloud 기본 메뉴에서 스토리지 및 버킷으로 이동합니다. 데이터 버킷을 누르고 이전 단계에서 2개의 파일을 업로드합니다.
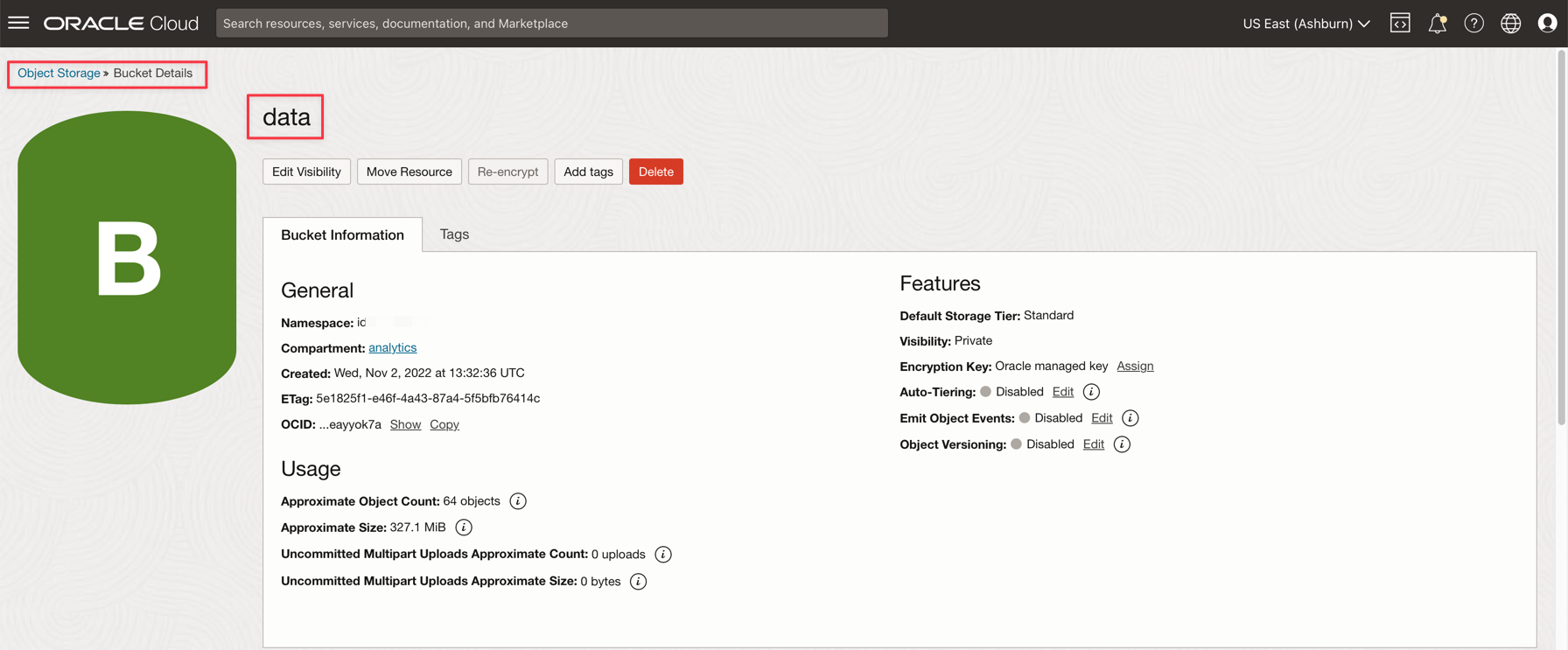

-
보조 테이블을 ADW 데이터베이스에 업로드
-
ADW 데이터베이스에 업로드하려면 이 파일을 다운로드하십시오. GDP PER CAPTA COUNTRY.csv
-
Oracle Cloud 기본 메뉴에서 Oracle Database 및 Autonomous Data Warehouse를 선택합니다.
-
처리된 로그 인스턴스를 눌러 세부정보를 봅니다.
-
데이터베이스 작업을 눌러 데이터베이스 유틸리티로 이동합니다.
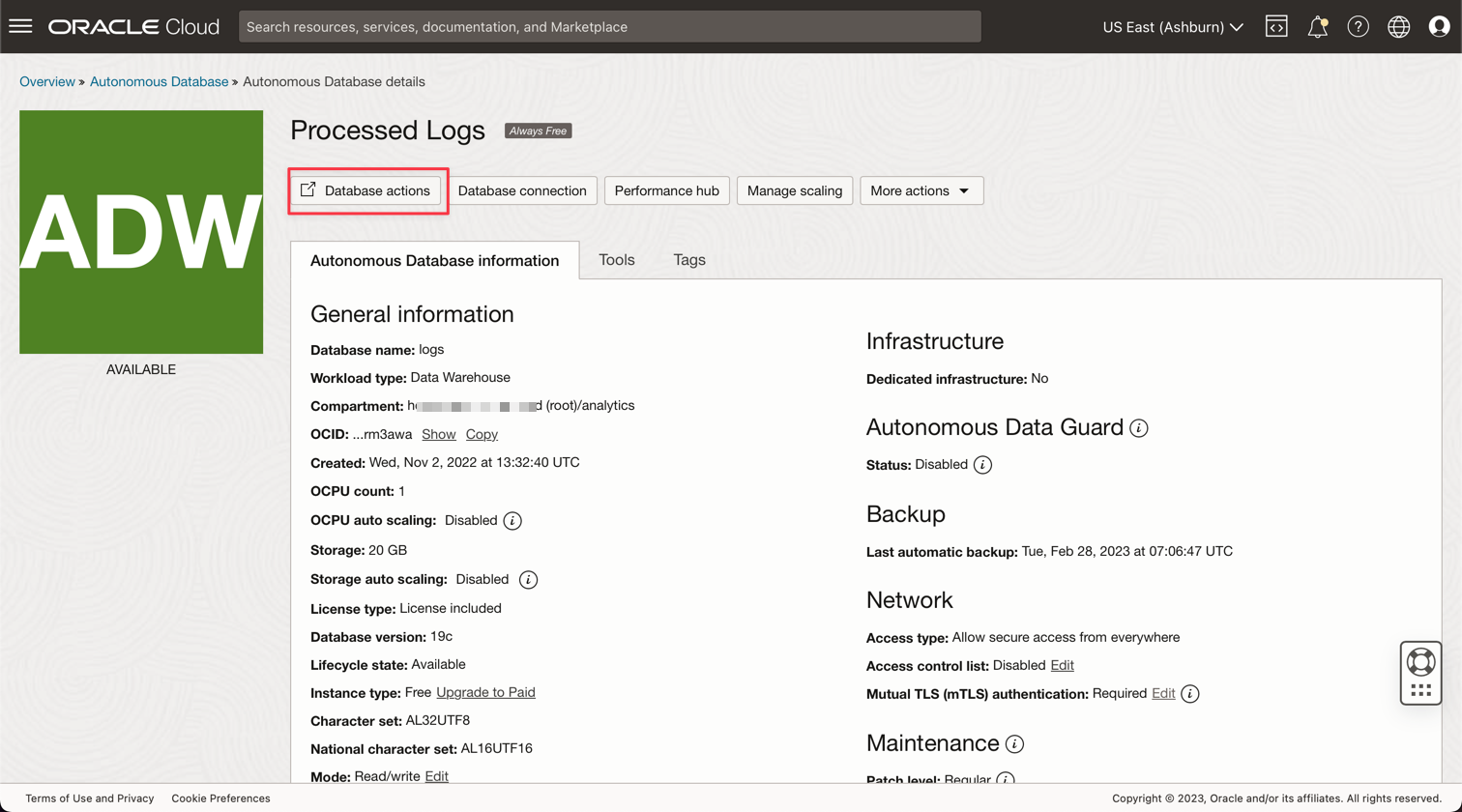
-
ADMIN 사용자에 대한 인증서를 입력합니다.
-
SQL 옵션을 눌러 질의 유틸리티로 이동합니다.
-
데이터 로드를 누릅니다.
-
GDP PER CAPTA COUNTRY.csv 파일을 콘솔 패널에 놓고 계속해서 데이터를 테이블로 가져옵니다.
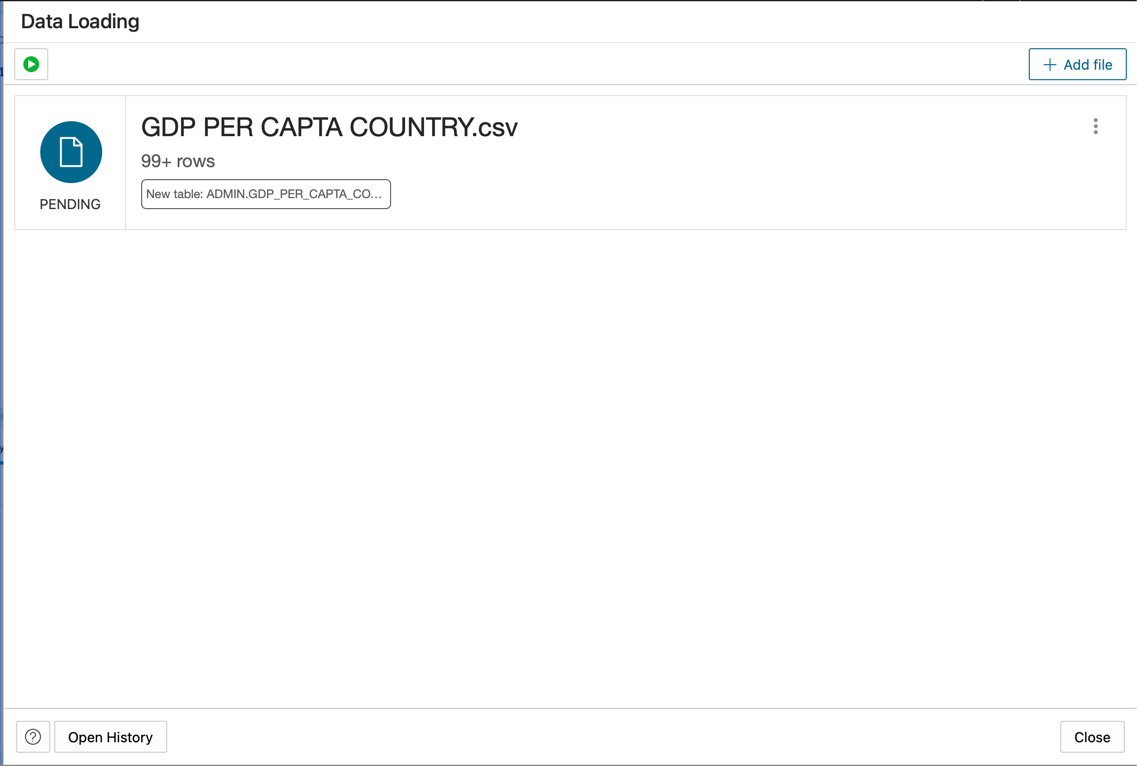
-
GDPPERCAPTA라는 새 테이블이 성공적으로 임포트된 것을 확인할 수 있습니다.
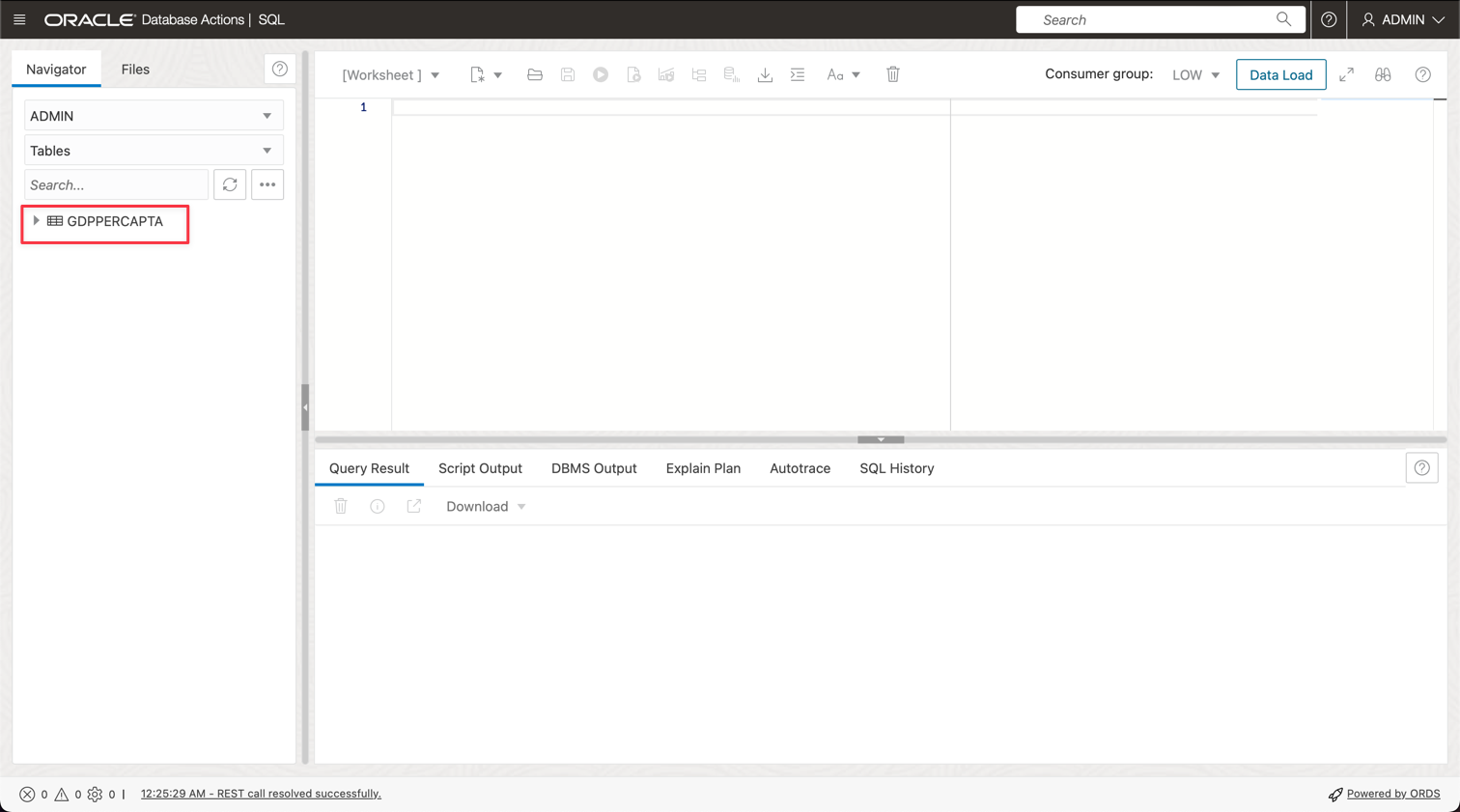
작업 4: ADW ADMIN 비밀번호에 대한 암호 저장소 생성
보안상의 이유로 ADW ADMIN 비밀번호는 저장소에 저장됩니다. Oracle Cloud Vault는 보안을 통해 이 비밀번호를 호스트할 수 있으며 OCI 인증을 통해 애플리케이션에서 액세스할 수 있습니다.
-
다음 설명서에 설명된 대로 저장소에 암호를 만듭니다. 저장소에 데이터베이스 관리자 암호 추가
-
응용 프로그램에 PASSWORD_SECRET_OCID이라는 변수를 생성하고 OCID를 입력합니다.

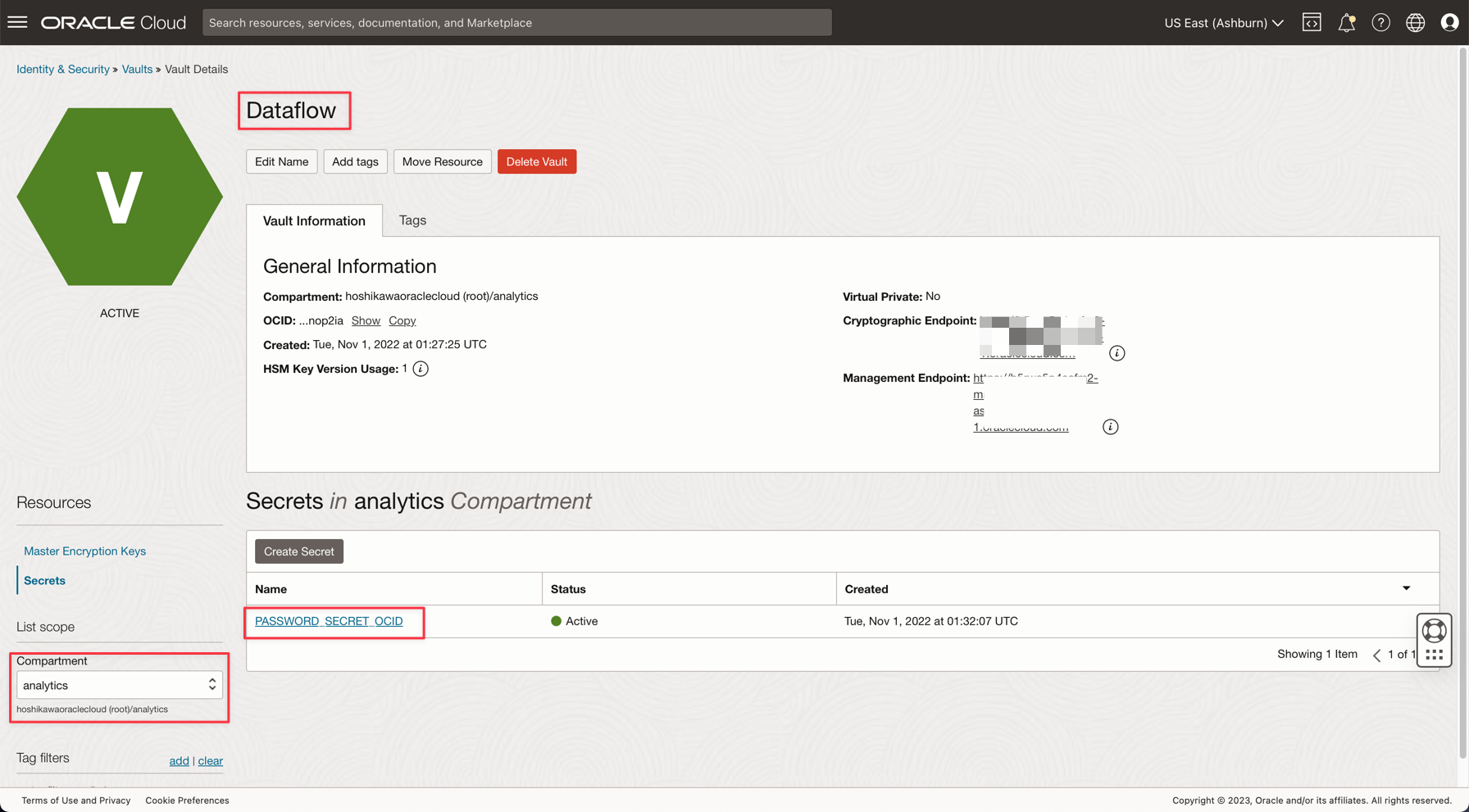
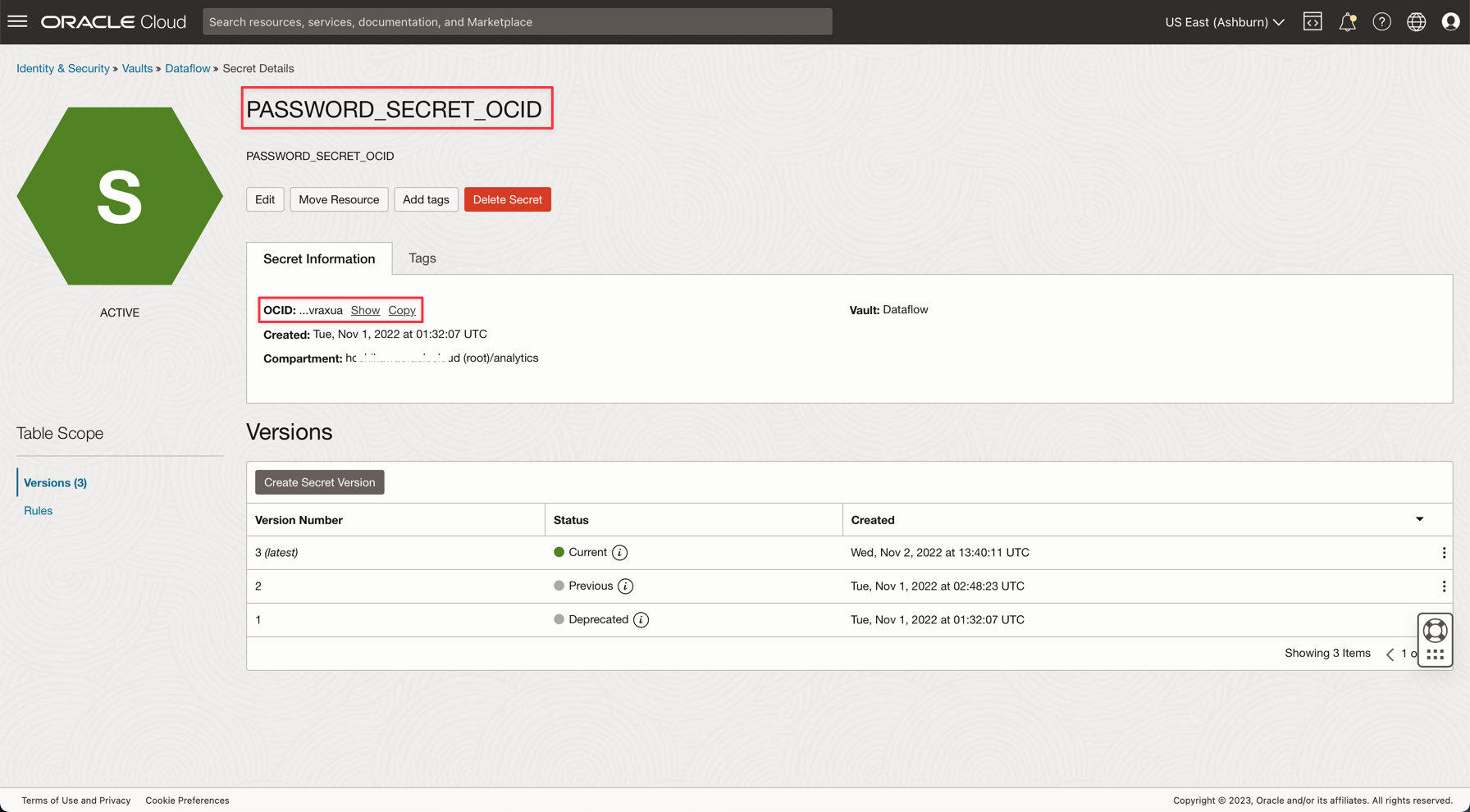
참고: OCI Vault IAM 정책에서 OCI Vault에 대한 IAM 정책을 검토하십시오.
작업 5: Kafka 스트리밍 생성(Oracle Cloud Streaming)
Oracle Cloud Streaming은 관리되는 스트리밍 서비스처럼 Kafka입니다. Kafka API 및 공통 SDK를 사용하여 애플리케이션을 개발할 수 있습니다. 이 사용지침서에서는 스트리밍 인스턴스를 생성하고 두 애플리케이션에서 실행되도록 구성하여 대량의 데이터를 게시하고 소비합니다.
-
Oracle Cloud 기본 메뉴에서 분석 및 AI, 스트림으로 이동합니다.
-
구획을 analytics로 변경합니다. 이 데모의 모든 리소스는 이 구획에 생성됩니다. 이는 더 안전하고 제어하기 쉬운 IAM입니다.
-
스트림 생성을 누릅니다.
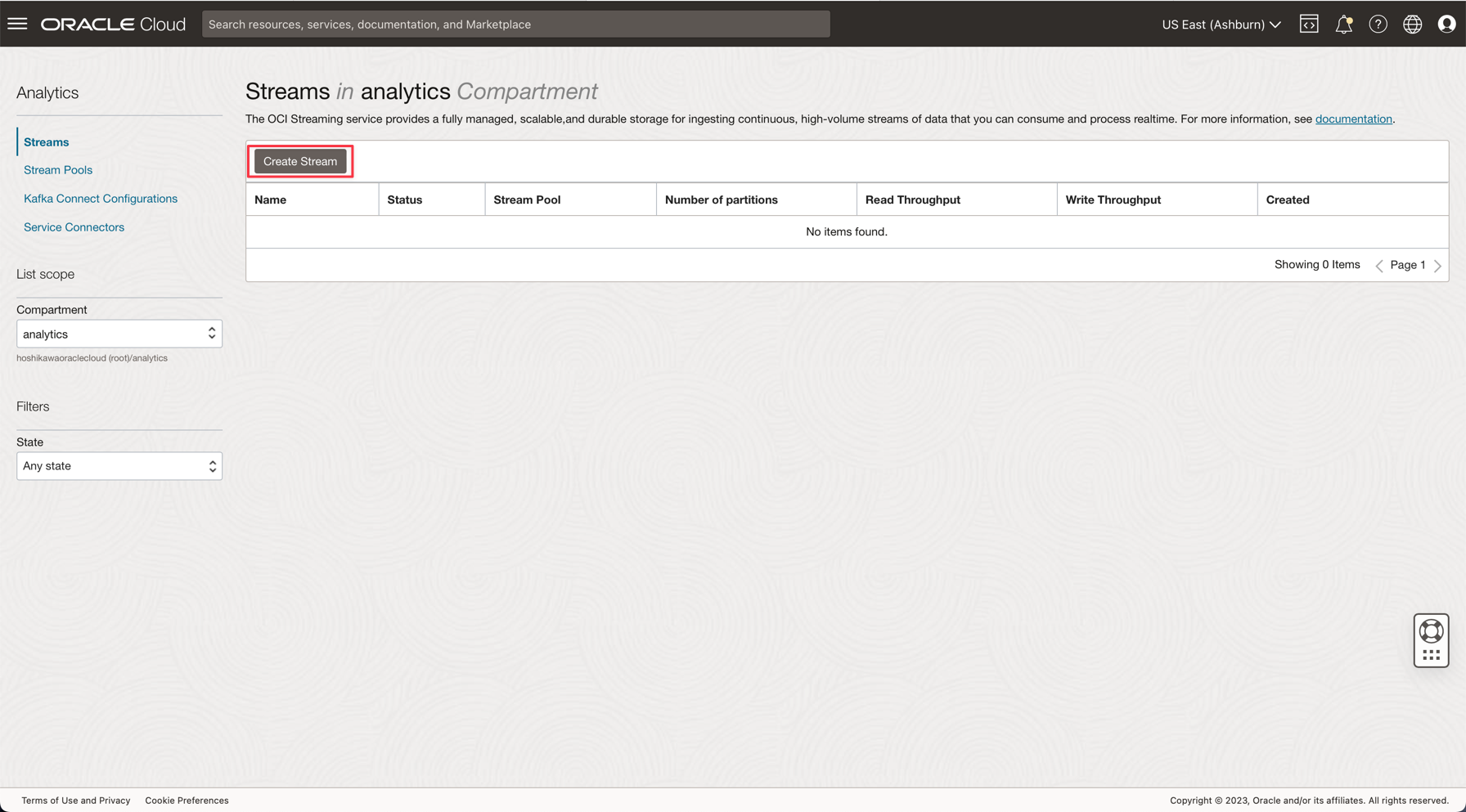
-
이름을 kafka_like(예)로 입력하고 다른 모든 매개변수를 기본값으로 유지 관리할 수 있습니다.
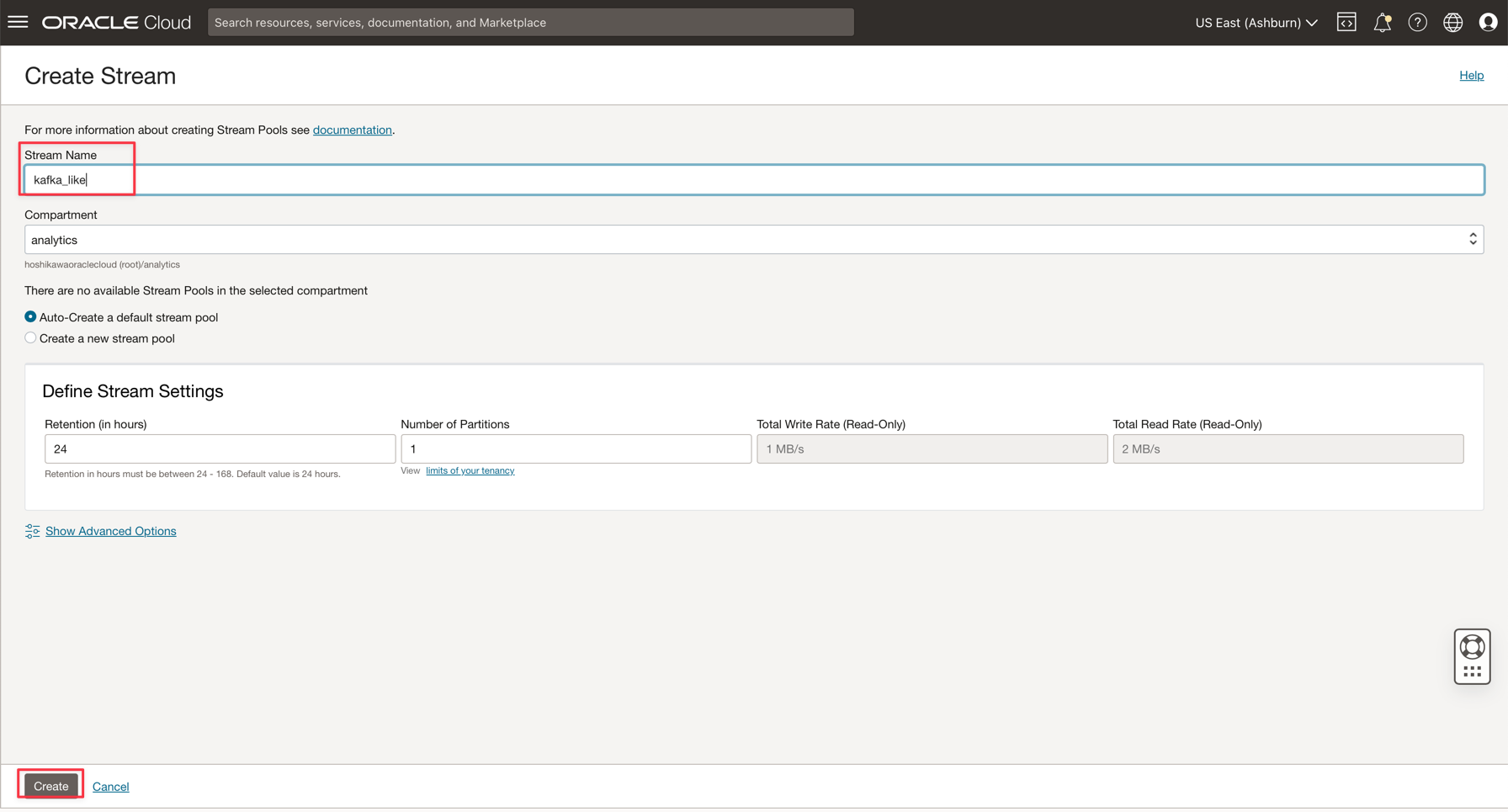
-
생성을 눌러 인스턴스를 초기화합니다.
-
Active 상태가 될 때까지 기다립니다. 이제 인스턴스를 사용할 수 있습니다.
참고: 스트리밍 생성 프로세스에서 기본 스트림 풀 자동 생성 옵션을 선택하여 기본 풀을 자동으로 생성할 수 있습니다.
-
DefaultPool 링크를 누릅니다.

-
연결 설정을 확인합니다.
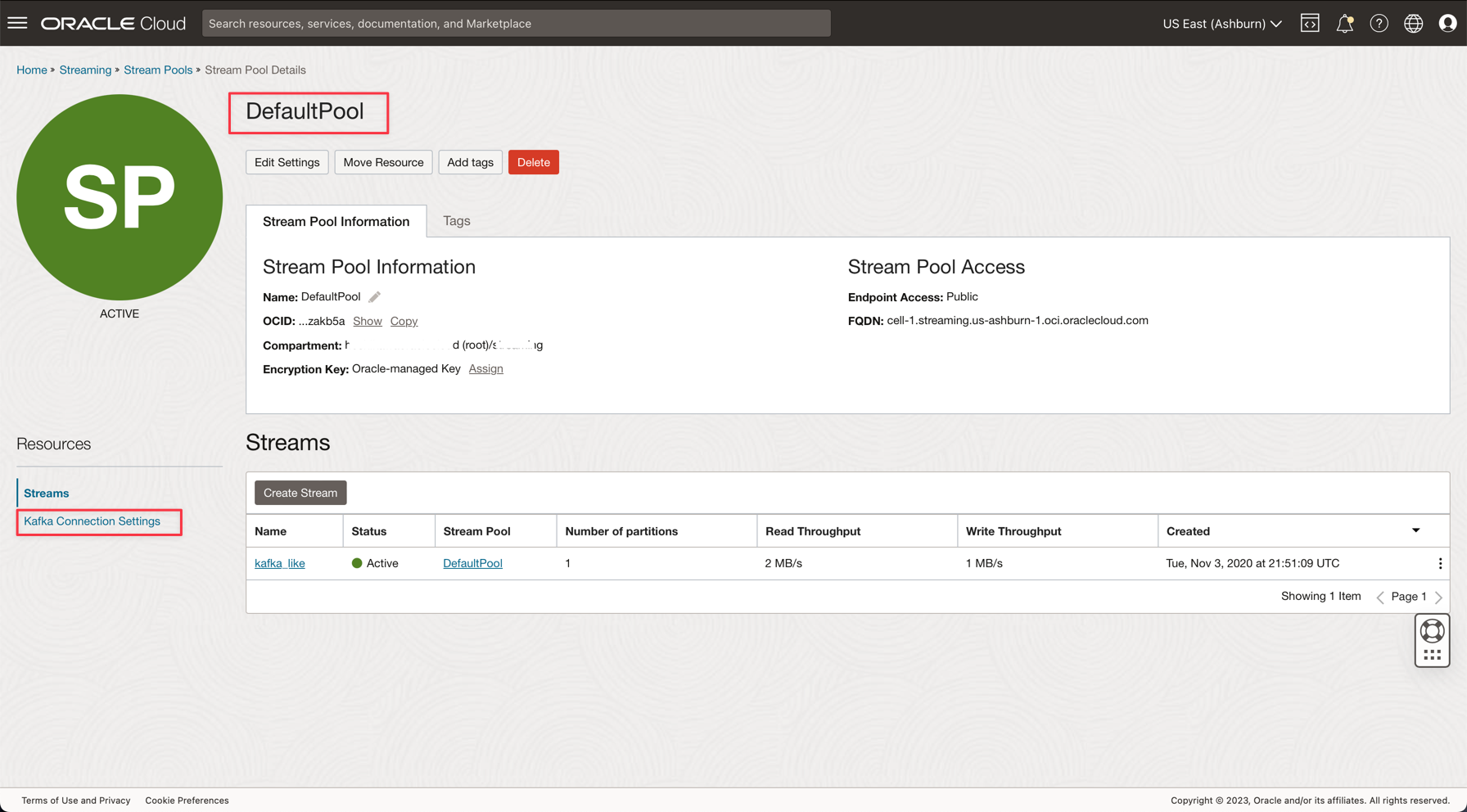
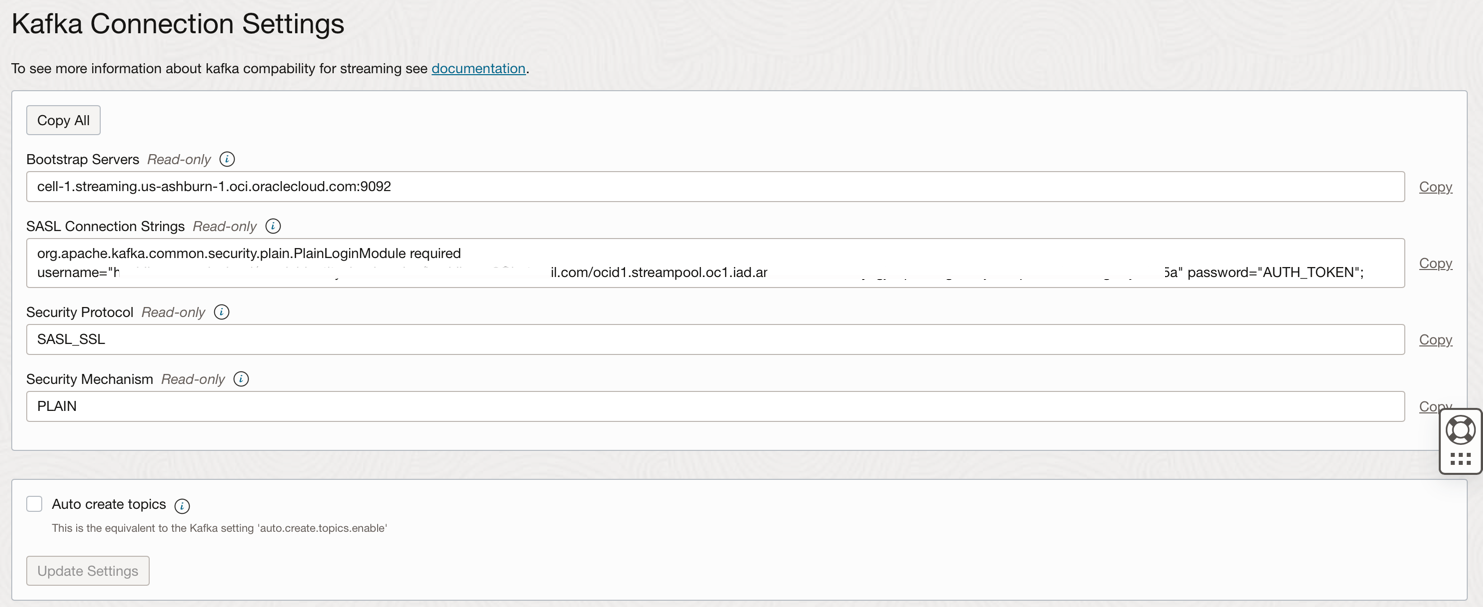
-
다음 단계에서 필요한 대로 이 정보에 주석을 추가합니다.
참고: OCI Streaming용 IAM 정책에서 OCI Streaming에 대한 IAM 정책을 검토하십시오.
작업 6: Kafka에 액세스하기 위한 AUTH TOKEN 생성
OCI IAM의 사용자와 연관된 인증 토큰을 사용하여 Oracle Cloud의 OCI 스트리밍(Kafka API) 및 기타 리소스에 액세스할 수 있습니다. Kafka Connection Settings에서 SASL Connection Strings는 이전 작업에 설명된 대로 password라는 매개변수와 AUTH_TOKEN 값을 가집니다. OCI 스트리밍에 대한 액세스를 사용으로 설정하려면 OCI 콘솔에서 사용자로 이동하여 AUTH TOKEN을 생성해야 합니다.
-
Oracle Cloud 기본 메뉴에서 ID 및 보안, 사용자로 이동합니다.
참고: AUTH TOKEN을 만들어야 하는 사용자는 지금까지 만든 리소스에 대해 구성된 OCI CLI 및 모든 IAM Policies 구성입니다. 리소스는 다음과 같습니다.
- Oracle Cloud Autonomous Data Warehouse
- Oracle Cloud 스트리밍
- Oracle 객체 저장영역
- Oracle 데이터 흐름
-
세부정보를 보려면 사용자 이름을 누르십시오.
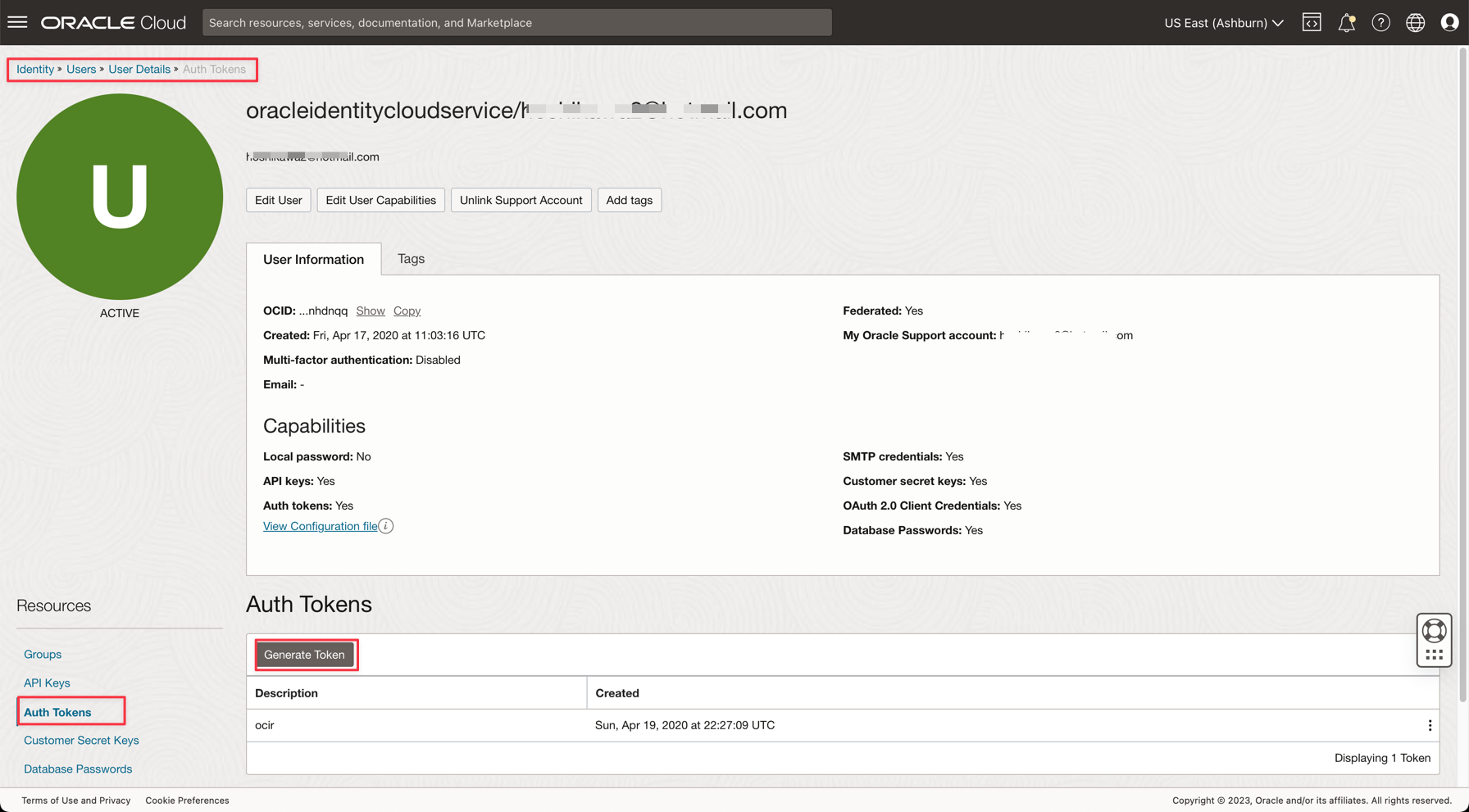
-
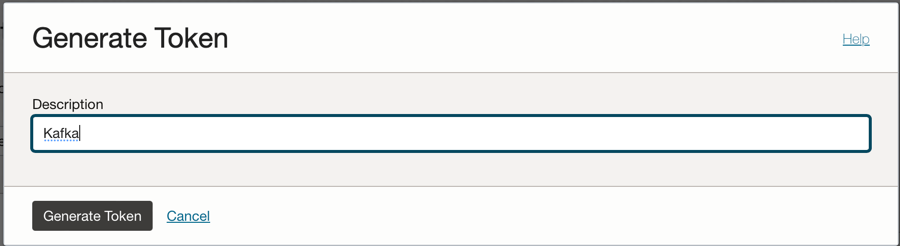
콘솔 왼쪽에 있는 Auth Tokens 옵션을 누르고 Generate Token을 누릅니다.
참고: 토큰은 이 단계에서만 생성되며 단계를 완료한 후에는 표시되지 않습니다. 따라서 값을 복사하여 저장합니다. 토큰 값이 손실되면 인증 토큰을 다시 생성해야 합니다.

작업 7: 데모 응용 프로그램 설정
이 자습서에는 필요한 정보를 설정할 데모 애플리케이션이 있습니다.
- DataflowSparkStreamDemo: 이 애플리케이션은 Kafka Streaming에 연결하고 모든 데이터를 소비하고 GDPPERCAPTA라는 ADW 테이블과 병합합니다. 스트림 데이터가 GDPPERCAPTA와 병합되고 CSV 파일로 저장되지만 다른 Kafka 토픽에 노출될 수 있습니다.
-
다음 링크를 사용하여 응용 프로그램을 다운로드합니다.
-
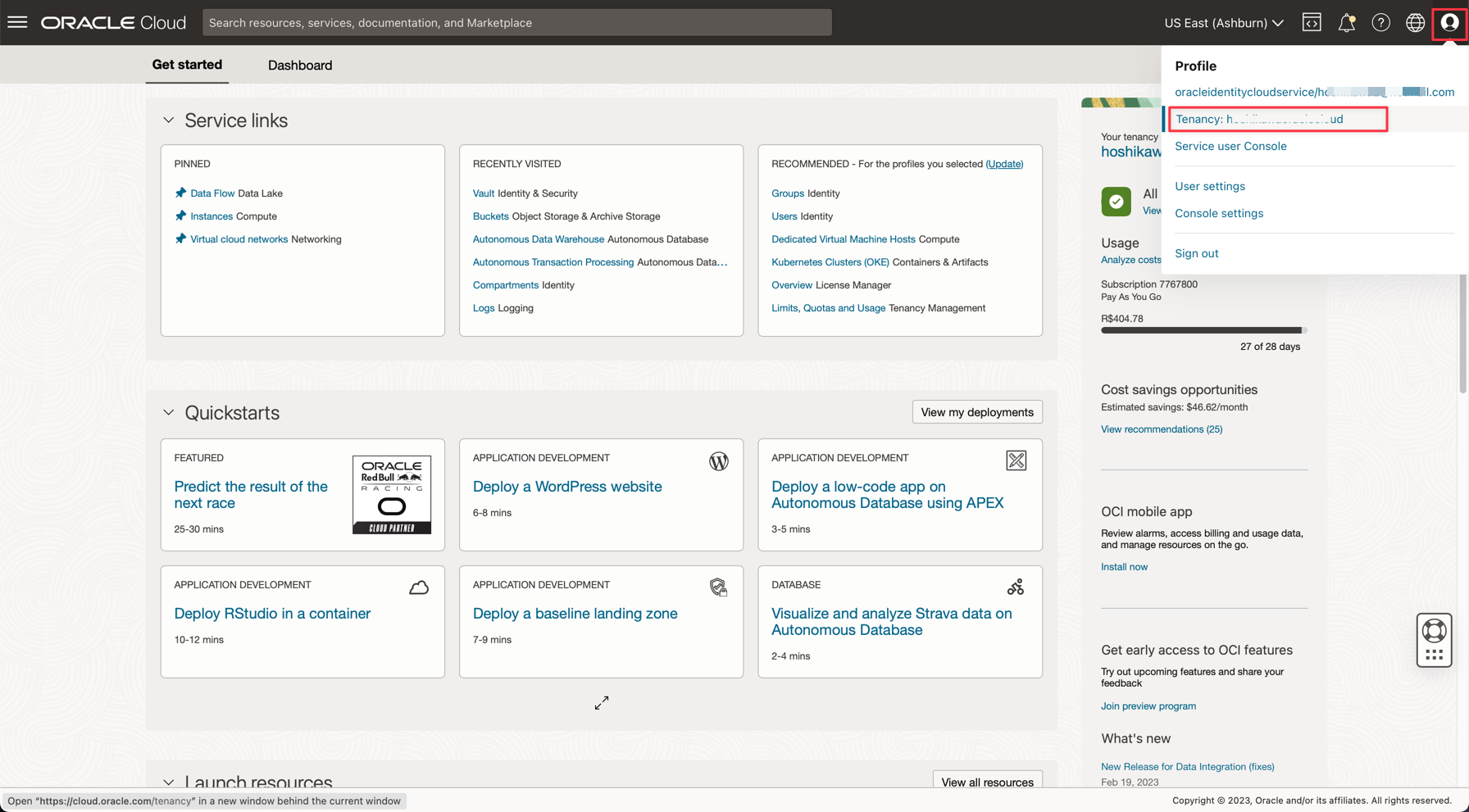
Oracle Cloud 콘솔에서 다음 세부정보를 찾습니다.
-
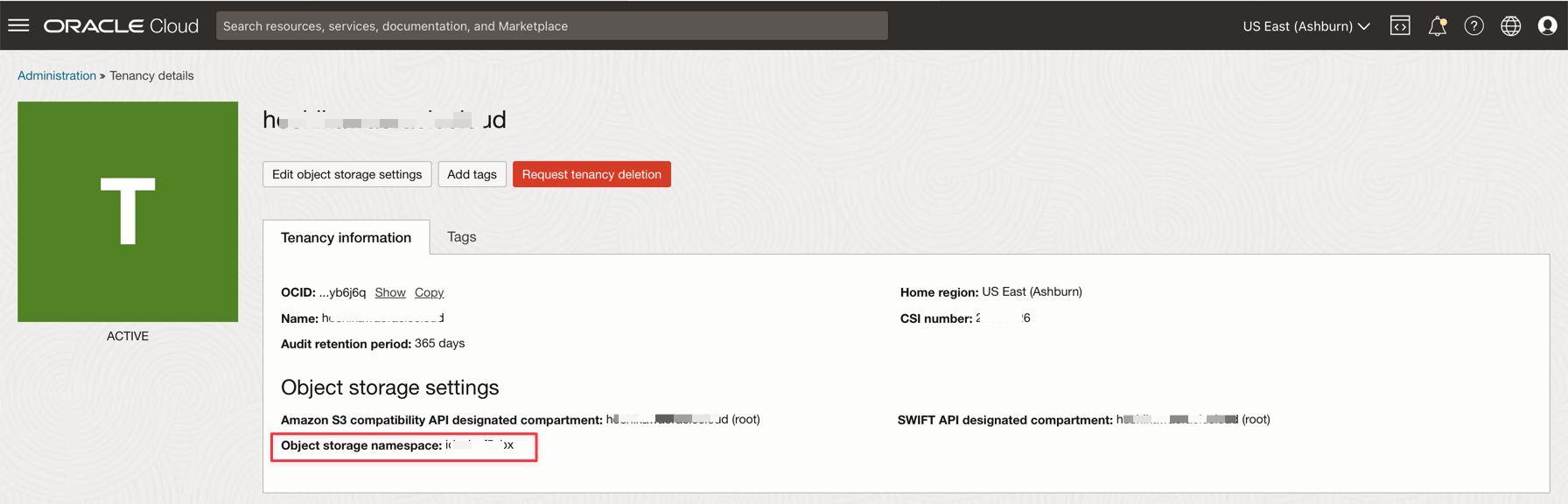
테넌시 네임스페이스
-
비밀번호 암호
-
스트리밍 접속 설정
-
인증 토큰
-
-
다운로드한 zip 파일(
Java-CSV-DB.zip및JavaConsumeKafka.zip)을 엽니다. /src/main/java/example 폴더로 이동하고 Example.java 코드를 찾습니다.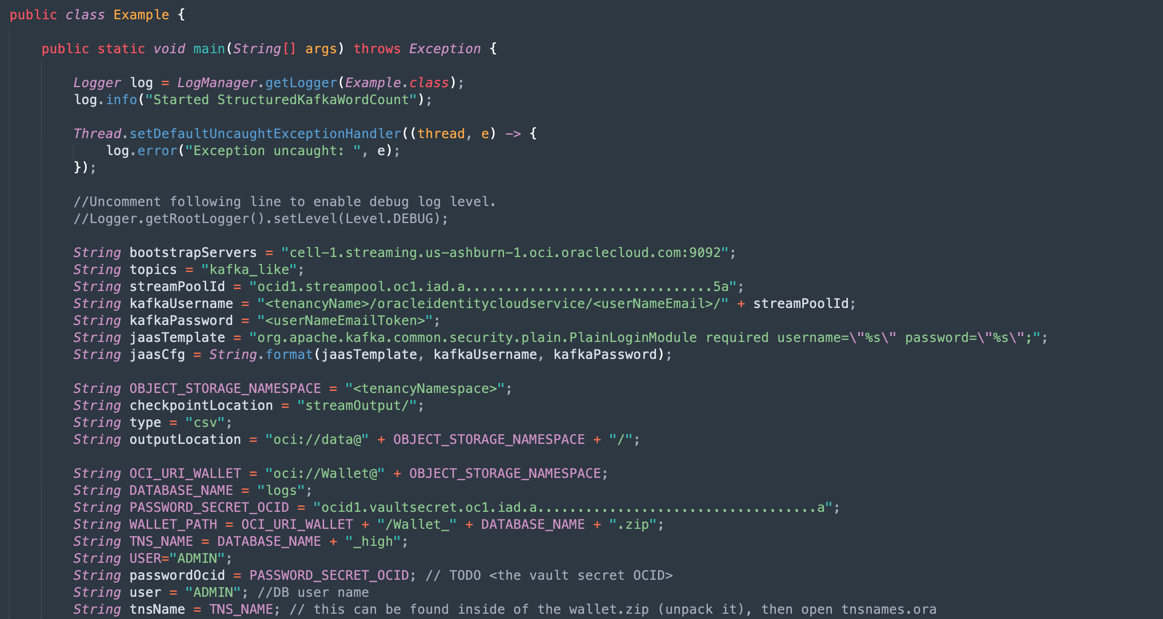
테넌시 리소스 값으로 변경해야 하는 변수입니다.
변수 이름 리소스 이름 정보 제목 bootstrapServers 스트리밍 접속 설정 부트스트랩 서버 streamPoolId 스트리밍 접속 설정 ocid1.streampool.oc1.iad..... 값(SASL 접속 문자열) kafkaUsername 스트리밍 접속 설정 SASL 접속 문자열에서 " " 내의 usename 값 kafkaPassword 인증 토큰 값은 생성 단계에만 표시됩니다. OBJECT_STORAGE_NAMESPACE 테넌시 네임스페이스 테넌트 이름 공간 테넌시 네임스페이스 테넌트 PASSWORD_SECRET_OCID PASSWORD_SECRET_OCID OCID
참고: 이 데모에 대해 생성되는 모든 리소스는 US-ASHBURN-1 지역에 있습니다. 작업할 영역을 확인하십시오. 영역을 변경할 경우 두 코드 파일에서 두 점을 변경해야 합니다.
Example.java: "us-ashburn-1"을 새 영역으로 대체하여 bootstrapServers 변수를 변경합니다.
OboTokenClientConfigurator.java: 새 영역으로 CANONICAL_REGION_NAME 변수를 변경합니다.
작업 8: Java 코드 이해
이 자습서는 Java에서 생성되었으며 이 코드도 Python으로 이식할 수 있습니다. 효율성과 확장성을 입증하기 위해 애플리케이션은 통합 프로세스의 일반적인 사용 사례에서 몇 가지 가능성을 보여주기 위해 개발되었습니다. 따라서 응용 프로그램 코드는 다음 예를 보여줍니다.
- Kafka Stream에 연결하여 데이터 읽기
- ADW 테이블과 함께 JOINS를 처리하여 유용한 정보 작성
- 모든 유용한 정보가 포함된 CSV 파일을 Kafka에서 출력
이 데모는 로컬 시스템에서 실행하고 Data Flow 인스턴스에 배포하여 작업 실행으로 실행할 수 있습니다.
주: 데이터 플로우 작업 및 로컬 시스템의 경우 OCI CLI 구성을 사용하여 OCI 리소스에 액세스하십시오. 데이터 플로우측에서는 모든 항목이 미리 구성되어 있으므로 매개변수를 변경할 필요가 없습니다. 로컬 시스템측에서 OCI CLI를 설치하고 테넌트, 사용자 및 전용 키를 구성하여 OCI 리소스에 액세스해야 합니다.
다음 섹션에서 Example.java 코드를 보여드리겠습니다.
-
Apache Spark 초기화: 이 코드 부분은 Spark 초기화를 나타냅니다. 실행 프로세스를 수행하는 많은 매개변수가 자동으로 구성되므로 Spark 엔진으로 작업하기가 매우 쉽습니다. 데이터 플로우 내부 또는 로컬 시스템에서 실행 중인 경우 초기화가 달라집니다. 데이터 플로우에 있는 경우 ADW 전자 지갑 zip 파일을 로드할 필요가 없습니다. 로드, 압축 해제 및 전자 지갑 파일 읽기 작업은 데이터 플로우 환경 내에서 자동으로 수행되지만 로컬 시스템에서는 일부 명령을 사용하여 수행해야 합니다.
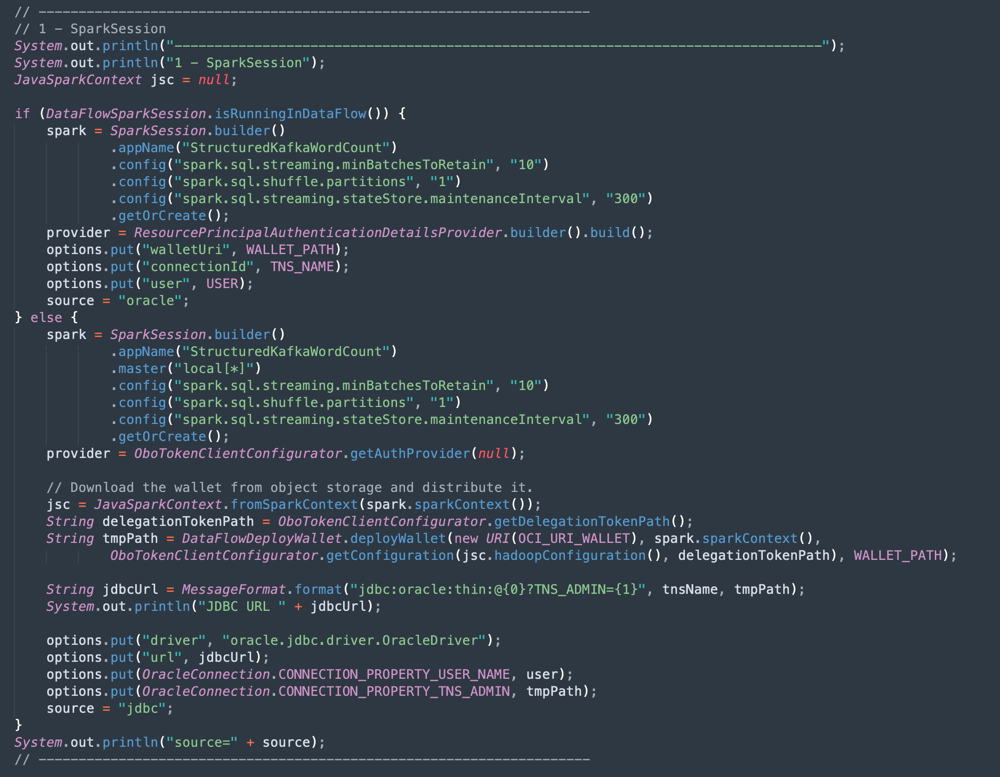
-
ADW Vault Secret 읽기: 코드의 이 부분은 Vault에 액세스하여 Autonomous Data Warehouse 인스턴스에 대한 암호를 가져옵니다.
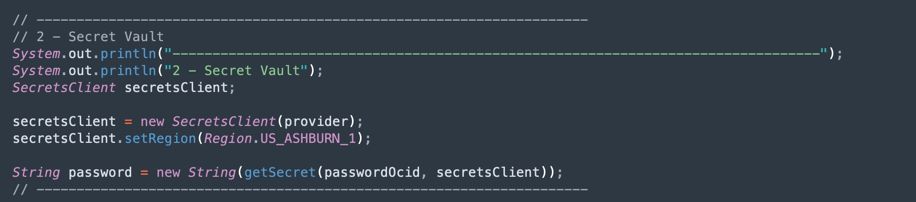
-
ADW 테이블 질의: 이 섹션에서는 테이블에 대한 질의를 실행하는 방법을 보여줍니다.

-
Kafka Operations: Kafka API를 사용하여 OCI 스트리밍에 접속하기 위한 준비입니다.
참고: Oracle Cloud Streaming은 대부분의 Kafka API와 호환됩니다.
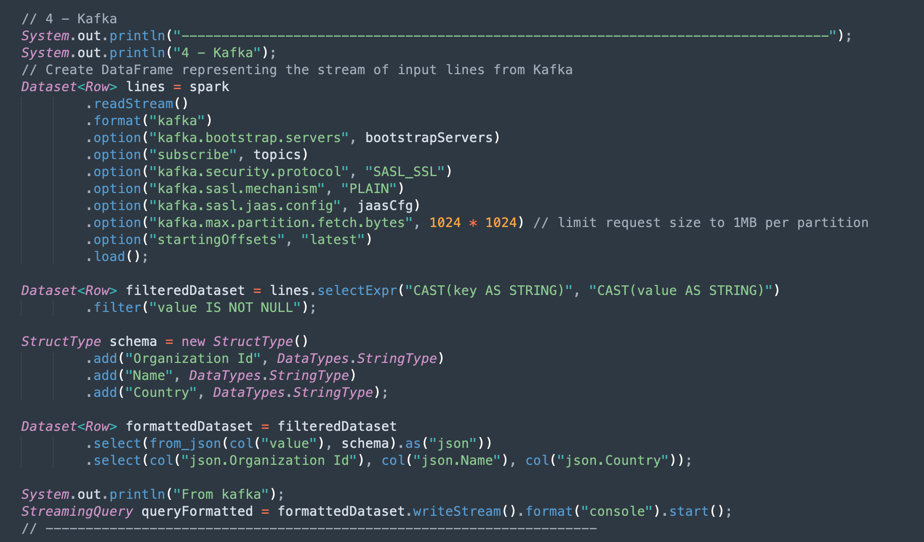
Kafka 토픽에서 올바른 구조(조직 ID, 이름, 국가)를 가진 데이터 세트로 가져오는 JSON 데이터를 구문 분석하는 프로세스가 있습니다.
-
Kafka 데이터 집합 및 Autonomous Data Warehouse 데이터 집합의 데이터 병합: 이 섹션에서는 두 개의 데이터 집합으로 질의를 실행하는 방법을 보여줍니다.

-
CSV 파일로 출력: 병합된 데이터가 CSV 파일로 출력을 생성하는 방법입니다.

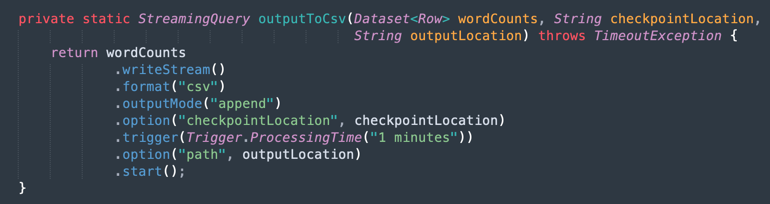
작업 9: Maven으로 애플리케이션 패키지화
Spark에서 작업을 실행하기 전에 Maven을 사용하여 애플리케이션을 패키지화해야 합니다.
-
/DataflowSparkStreamDemo 폴더로 이동하고 다음 명령을 실행합니다.
mvn package -
Maven에서 패키징을 시작할 수 있습니다.
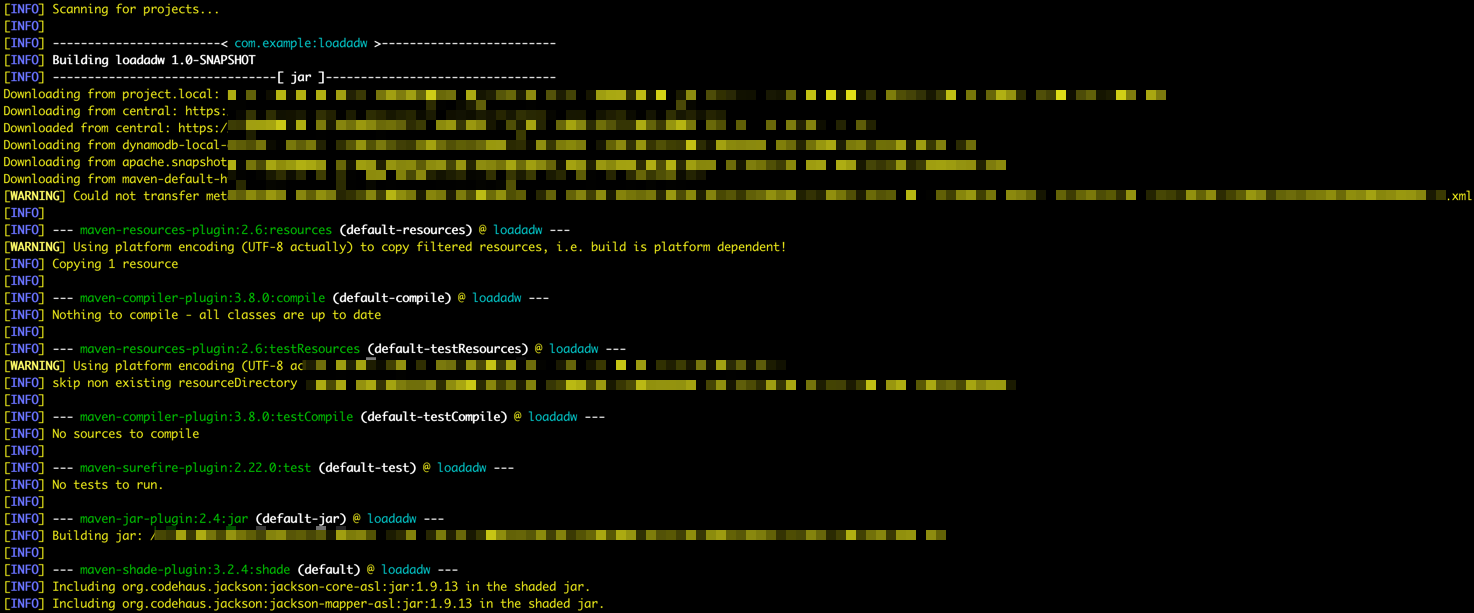
-
모든 항목이 올바르면 Success 메시지가 표시됩니다.
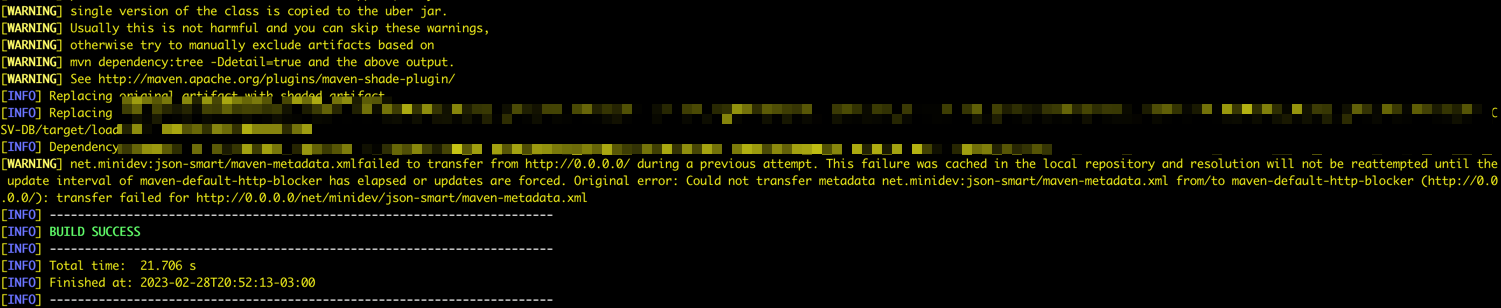
작업 10: 실행 확인
-
다음 명령을 실행하여 로컬 Spark 시스템에서 애플리케이션을 테스트합니다.
spark-submit --class example.Example target/consumekafka-1.0-SNAPSHOT.jar -
Oracle Cloud Streaming Kafka 인스턴스로 이동하고 테스트 메시지 생성을 눌러 일부 데이터를 생성하여 실시간 애플리케이션을 테스트합니다.
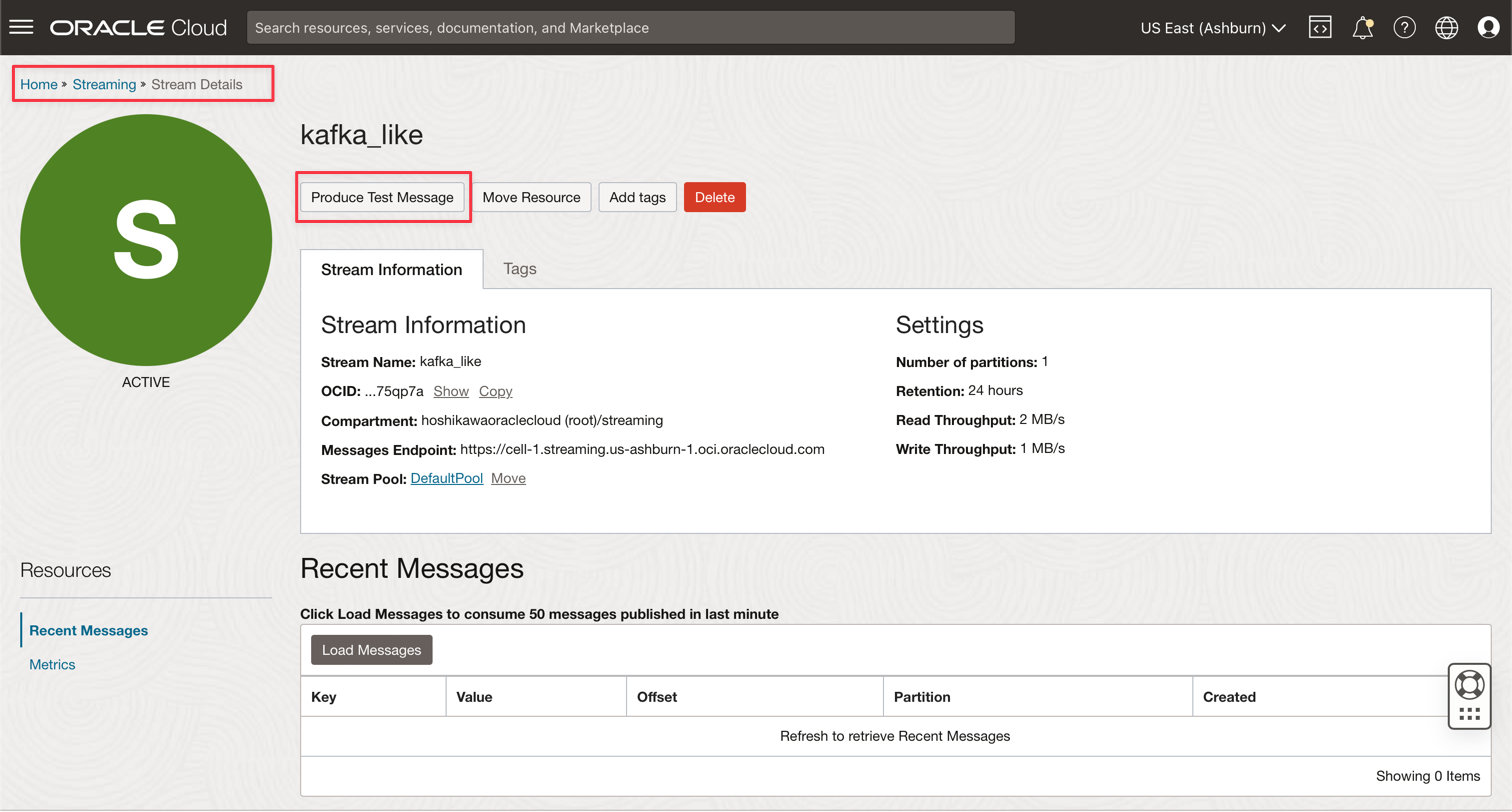
-
이 JSON 메시지를 Kafka 토픽에 넣을 수 있습니다.
{"Organization Id": "1235", "Name": "Teste", "Country": "Luxembourg"}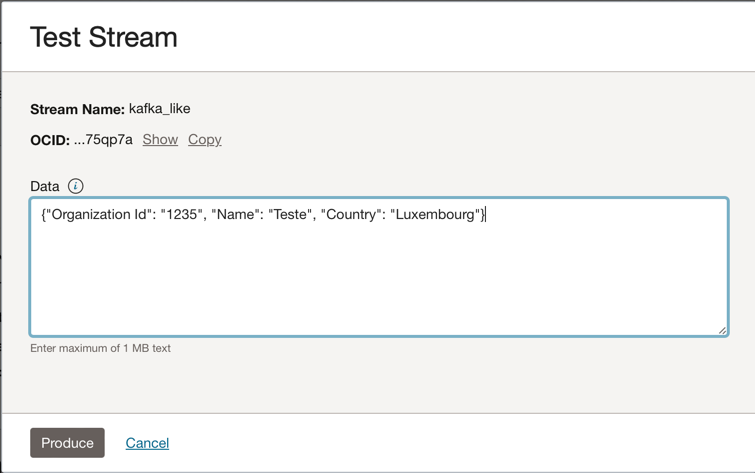
-
생성을 누를 때마다 애플리케이션에 하나의 메시지를 보냅니다. 다음과 같이 응용 프로그램의 출력 로그를 볼 수 있습니다.
-
kafka 토픽에서 읽은 데이터입니다.

-
ADW 테이블에서 병합된 데이터입니다.

-
작업 11: 데이터 플로우 작업 생성 및 실행
이제 로컬 Spark 머신에서 두 애플리케이션을 성공적으로 실행하면 테넌시의 Oracle Cloud Data Flow에 배포할 수 있습니다.
참고: Oracle Object Storage 및 Oracle Streaming(Kafka)과 같은 리소스에 대한 액세스를 구성하려면 Spark Streaming 설명서를 참조하십시오. 데이터 플로우에 대한 액세스 사용
-
오브젝트 스토리지로 패키지를 업로드합니다.
- 데이터 플로우 애플리케이션을 생성하기 전에 Java 아티팩트 애플리케이션(사용자의 ***-SNAPSHOT.jar 파일)을 앱이라는 오브젝트 스토리지 버킷에 업로드해야 합니다.
-
데이터 플로우 애플리케이션을 생성합니다.
-
Oracle Cloud 기본 메뉴를 선택하고 분석 및 AI 및 데이터 플로우로 이동합니다. 데이터 플로우 애플리케이션을 생성하기 전에 analytics 구획을 선택해야 합니다.
-
애플리케이션 생성을 누릅니다.
-
이와 같은 매개변수를 채웁니다.
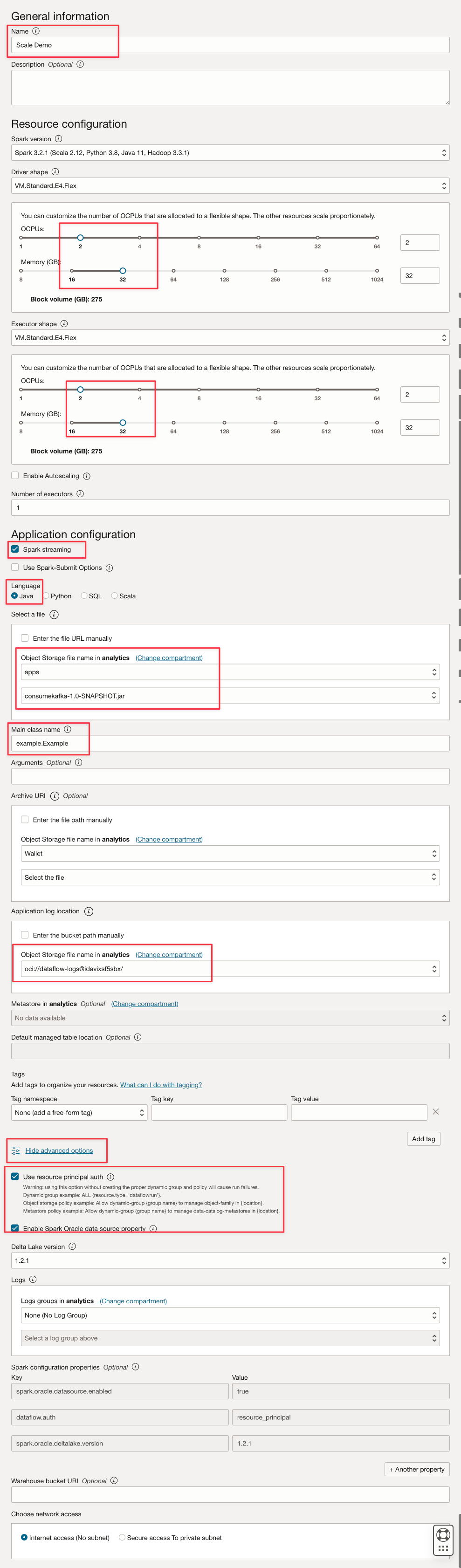
-
생성을 누릅니다.
-
생성한 후 데모 스케일 링크를 눌러 세부정보를 확인합니다. 작업을 실행하려면 실행을 누르십시오.
참고: 고급 옵션 표시를 눌러 Spark Stream 실행 유형에 대한 OCI 보안을 사용으로 설정합니다.

-
-
다음 옵션을 활성화합니다.

-
Run을 눌러 작업을 실행합니다.
-
매개변수를 확인하고 Run을 다시 누릅니다.
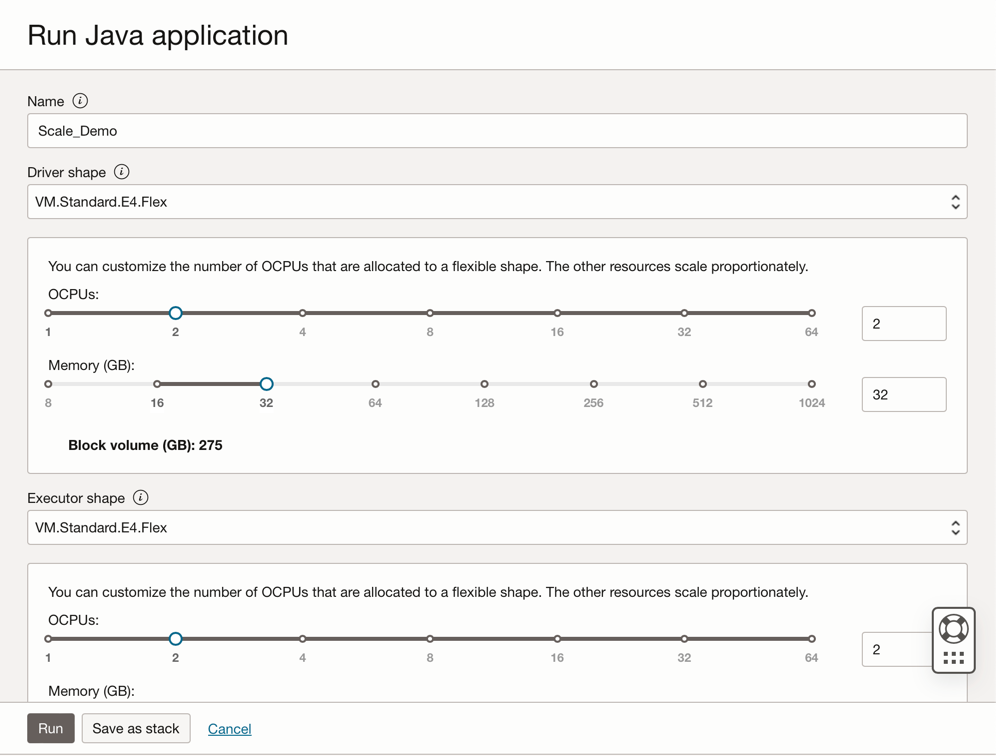
-
작업의 상태를 볼 수 있습니다.

-
상태가 Succeeded로 이동할 때까지 기다린 후 결과를 볼 수 있습니다.

-
관련 링크
승인
- 작성자 - Cristiano Hoshikawa(Oracle LAD A-Team 솔루션 엔지니어)
추가 학습 자원
docs.oracle.com/learn에서 다른 실습을 탐색하거나 Oracle Learning YouTube 채널에서 더 많은 무료 학습 콘텐츠에 액세스할 수 있습니다. 또한 education.oracle.com/learning-explorer을 방문하여 Oracle Learning Explorer가 됩니다.
제품 설명서는 Oracle Help Center를 참조하십시오.
Use OCI Data Flow with Apache Spark Streaming to process a Kafka topic in a scalable and near real-time application
F79979-02
May 2023
Copyright © 2023, Oracle and/or its affiliates.