주:
- 이 사용지침서에서는 Oracle Cloud에 액세스해야 합니다. 무료 계정에 등록하려면 Oracle Cloud Infrastructure Free Tier 시작하기를 참조하십시오.
- Oracle Cloud Infrastructure 인증서, 테넌시 및 구획에 예제 값을 사용합니다. 실습을 완료할 때 이러한 값을 클라우드 환경과 관련된 값으로 대체하십시오.
OCI Generative AI로 자연어로 PDF 문서 분석하기
소개
Oracle Cloud Infrastructure Generative AI(OCI Generative AI)는 기업 및 개발자가 최첨단 언어 모델을 사용하여 지능형 애플리케이션을 생성할 수 있는 첨단 생성형 인공 지능 솔루션입니다. 이 솔루션은 LLM(대형 언어 모델)과 같은 강력한 기술을 기반으로 복잡한 작업을 자동화하여 자연어 상호 작용을 통해 프로세스를 더 빠르고 효율적이며 액세스할 수 있도록 합니다.
OCI Generative AI의 가장 영향력 있는 애플리케이션 중 하나는 PDF 문서 분석입니다. 기업은 종종 계약, 재무 보고서, 기술 설명서, 연구 문서 등 대량의 문서를 처리합니다. 이러한 파일에서 정보를 수동으로 검색하려면 시간이 많이 걸리고 오류가 발생하기 쉽습니다.
생성형 인공 지능을 사용하면 정보를 즉각적이고 정확하게 추출할 수 있으므로 사용자가 자연어로 질문을 작성하여 복잡한 문서를 간단히 쿼리할 수 있습니다. 즉, 계약의 특정 조항이나 보고서의 관련 데이터 포인트를 찾기 위해 전체 페이지를 읽는 대신 사용자가 모델에 물어볼 수 있으며 분석된 콘텐츠를 기반으로 답변을 빠르게 반환합니다.
또한 정보 검색 외에도 긴 문서를 요약하고, 콘텐츠를 비교하고, 정보를 분류하고, 전략적 인사이트를 생성하는 데 OCI Generative AI를 사용할 수 있습니다. 이러한 기능은 법률, 재무, 의료 및 엔지니어링과 같은 다양한 분야에 필수적인 기술을 만들어 의사 결정을 최적화하고 생산성을 높입니다.
이 기술을 Oracle AI 서비스, OCI Data Science, 문서 처리를 위한 API 등의 도구와 통합함으로써 기업은 데이터와의 상호 작용 방식을 완전히 혁신하는 지능형 솔루션을 구축하여 정보 검색을 더욱 빠르고 효과적으로 수행할 수 있습니다.
필수 조건
- Python
version 3.10이상을 설치하고 OCI CLI(Oracle Cloud Infrastructure Command Line Interface)를 설치합니다.
작업 1: Python 패키지 설치
Python 코드에는 OCI Generative AI를 사용하기 위한 특정 라이브러리가 필요합니다. 필요한 Python 패키지를 설치하려면 다음 명령을 실행하십시오.
pip install -r requirements.txt
작업 2: Python 코드 이해
Oracle SOA Suite 및 Oracle Integration의 기능 쿼리를 위한 OCI Generative AI 데모입니다. 두 도구 모두 현재 하이브리드 통합 전략에 사용되고 있으며 이는 클라우드 및 온프레미스 환경에서 모두 운영된다는 것을 의미합니다.
이러한 도구는 기능과 프로세스를 공유하므로 이 코드는 각 도구에서 동일한 통합 접근 방식을 구현하는 방법을 이해하는 데 도움이 됩니다. 또한 사용자가 일반적인 특성과 차이점을 탐색할 수 있습니다.
여기에서 Python 코드를 다운로드하십시오.
PDF 문서는 여기에서 찾을 수 있습니다:
Manuals이라는 폴더를 생성하고 이 PDF를 이동합니다.
-
라이브러리 임포트:
벡터 데이터베이스(Facebook AI Similarity Search, FAISS) 및 ChromaDB)에서 PDF, OCI Generative AI, 텍스트 벡터화 및 스토리지를 처리하는 데 필요한 라이브러리를 임포트합니다.
-
UnstructuredPDFLoader는 PDF에서 텍스트를 추출하는 데 사용됩니다. -
ChatOCIGenAIOCI Generative AI 모델을 사용하여 질문에 답할 수 있습니다. -
OCIGenAIEmbeddings는 의미 검색을 위해 텍스트의 임베딩(벡터 표현)을 생성합니다.
-
-
PDF 로드 및 처리:
처리할 PDF 파일을 나열합니다.
-
UnstructuredPDFLoader는 각 문서를 읽고 더 쉽게 인덱스화하고 검색할 수 있도록 페이지로 분할합니다. -
문서 ID는 나중에 참조할 수 있도록 저장됩니다.

-
-
OCI Generative AI 모델 구성:
로드된 문서를 기반으로 응답을 생성하도록 OCI에 호스트된
Llama-3.1-405b모델을 구성합니다.temperature(무작위 제어),top_p(다양성 제어) 및max_tokens(토큰 제한)과 같은 매개변수를 정의합니다.
주: 사용 가능한 LLaMA 버전은 시간에 따라 변경될 수 있습니다. 테넌시의 현재 버전을 확인하고 필요한 경우 코드를 업데이트하십시오.
-
임베딩 및 벡터 인덱싱 생성:
Oracle의 임베딩 모델을 사용하여 텍스트를 숫자 벡터로 변환함으로써 문서의 의미 검색을 용이하게 합니다.

-
FAISS는 빠른 쿼리를 위해 PDF 문서의 임베딩을 저장합니다.
-
retriever를 사용하면 사용자 질의의 의미 유사성에 따라 가장 관련성이 높은 발췌문을 검색할 수 있습니다.

-
-
첫 번째 처리 실행에서 벡터 데이터는 FAISS 데이터베이스에 저장됩니다.

-
프롬프트 정의:
생성형 모델에 대한 지능형 프롬프트를 생성하여 각 쿼리에 대해 관련 문서만 고려하도록 안내합니다.
이렇게 하면 응답의 정확성이 향상되고 불필요한 정보가 방지됩니다.

-
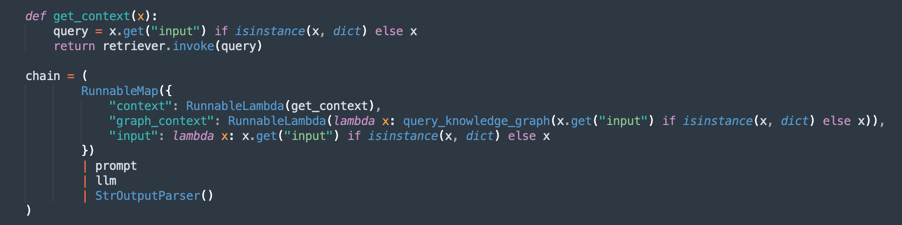
처리 체인(RAG - 검색 증강 생성) 생성:
RAG 흐름을 구현합니다. 설명:
retriever는 가장 관련성이 높은 문서 발췌문을 검색합니다.prompt는 더 나은 컨텍스트를 위해 질의를 구성합니다.llm는 검색된 문서를 기반으로 응답을 생성합니다.StrOutputParser는 최종 출력의 형식을 지정합니다.

-
질문 및 답변 루프:
사용자가 로드된 문서에 대해 질문할 수 있는 루프를 유지 관리합니다.
-
AI는 PDF에서 추출된 지식 기반을 사용하여 응답합니다.
-
quit를 입력하면 프로그램이 종료됩니다.

-
이제 3가지 옵션을 선택하여 문서를 처리할 수 있습니다. 당신은 생각할 수 있습니다 :
- 당신은 얼마나 많은 힘을 처리해야합니까?
- 몇 번이나 처리해야 합니까?
- 응답의 품질은 어떻습니까?
따라서 다음 옵션을 사용할 수 있습니다.
고정 크기 조각화: 문서 처리에 대한 보다 빠른 대안입니다. 그것은 당신이 원하는 것을 얻을 수 있습니다.
의미 조각화: 이 프로세스는 고정 크기 조각화보다 느리지만 품질 조각화가 더 많이 전달됩니다.
GraphRAG를 사용한 의미 조각화: 조각화 텍스트 및 지식 그래프를 구성하기 때문에 보다 정확한 방법을 제공합니다.
고정 크기 조각화
oci_genai_llm_context_fast.py에서 코드를 다운로드합니다.
-
고정 크기 조각화란 무엇입니까?
고정 크기 조각화(Fixed Size Chunking)는 문서가 미리 정의된 크기 제한을 기준으로 청크로 나뉘는 간단하고 효율적인 텍스트 분할 전략으로, 일반적으로 토큰, 문자 또는 선으로 측정됩니다.
이 메소드는 텍스트의 의미나 구조를 분석하지 않습니다. 문장, 단락 또는 아이디어의 중간에 컷이 발생하는지 여부에 관계없이 고정된 간격으로 콘텐츠를 분할합니다.
-
고정 크기 조각화 작동 방식:
-
예제 규칙: 1000개의 토큰(또는 3000자마다)마다 문서를 분할합니다.
-
선택적 중복: 관련 context를 분할하는 위험을 줄이기 위해 일부 구현에서는 연속 청크(예: 200-토큰 겹침) 사이에 겹침을 추가하여 중요한 context가 경계에서 손실되지 않도록 합니다.
-
-
고정 크기 조각화의 이점:
-
빠른 처리: 의미 분석, LLM 추론 또는 콘텐츠 이해가 필요하지 않습니다. 그냥 계산하고 잘라.
-
낮은 리소스 사용량: CPU/GPU 및 메모리 사용량을 최소화하여 대용량 데이터 세트에 맞게 확장할 수 있습니다.
-
구현 용이성: 간단한 스크립트 또는 표준 텍스트 처리 라이브러리와 함께 작동합니다.
-
-
고정 크기 조각화의 제한 사항:
-
불량한 의미 인식: 청크는 문장, 단락 또는 논리적 섹션을 차단하여 불완전하거나 단편화된 아이디어로 이어질 수 있습니다.
-
검색 정밀도 감소: 의미 검색 또는 RAG(검색 증강 생성)와 같은 애플리케이션에서 청크 경계가 낮으면 검색된 답변의 관련성 및 품질에 영향을 줄 수 있습니다.
-
-
고정 크기 조각화를 사용하는 경우:
-
처리 속도와 확장성이 최우선 과제입니다.
-
의미 정밀도가 중요하지 않은 대규모 문서 수집 파이프라인의 경우
-
이후 세분화 또는 의미 분석이 다운스트림으로 발생하는 시나리오의 첫 번째 단계입니다.
-
이것은 텍스트를 분할하는 매우 간단한 방법입니다.

-
이것은 고정 조각화의 주요 과정입니다.

주: 고정 조각화를 더 빠르게 처리하려면 이 코드를 다운로드하십시오.
oci_genai_llm_context_fast.py -
의미 조각화
oci_genai_llm_context.py에서 코드를 다운로드합니다.
-
의미 조각화란 무엇입니까?
의미 조각화는 큰 문서(예: PDF, 프리젠테이션 또는 문서)가 청크라는 작은 부분으로 분할되는 텍스트 선행 처리 기법으로, 각 조각은 의미적으로 일관된 텍스트 블록을 나타냅니다.
기존의 고정 크기 조각화(예: 1000개 토큰 또는 X개 문자마다 분할)와 달리 의미 조각화는 인공 지능(일반적으로 큰 언어 모델 - LLM)을 사용하여 주제, 섹션 및 context와 관련된 자연 콘텐츠 경계를 감지합니다.
Semantic Chunking은 텍스트를 임의로 자르는 대신 각 섹션의 전체 의미를 보존하여 독립형 컨텍스트 인식 조각을 만듭니다.
-
의미 조각화로 인해 처리 속도가 느려지는 이유는 무엇입니까?
고정된 크기를 기반으로 하는 전통적인 조각화 프로세스는 빠릅니다. 시스템은 토큰 또는 문자만 계산하고 그에 따라 잘라냅니다. 의미 조각화를 사용할 경우 의미 분석의 몇 가지 추가 단계가 필요합니다.
- 분할 전에 전체 텍스트(또는 큰 블록) 읽기 및 해석: LLM은 콘텐츠를 이해하여 최적의 청크 경계를 식별해야 합니다.
- LLM 프롬프트 또는 주제 분류 모델 실행하기: 시스템은 종종 이게 아이디어의 끝인가요? 또는 이 단락이 새 섹션을 시작합니까?와 같은 질문을 LLM에 쿼리합니다.
- 더 높은 메모리 및 CPU/GPU 사용량: 모델은 조각화 결정을 내리기 전에 더 큰 텍스트 블록을 처리하므로 리소스 소비가 훨씬 높습니다.
- 순차적 및 증분적 의사 결정: 의미 조각화는 종종 단계(예: 10,000-token 블록을 분석한 다음 해당 블록 내부의 조각 경계를 세분화)에서 작동하므로 총 처리 시간이 늘어납니다.
참고:
- 시스템 처리 능력에 따라 Semantic Chunking을 사용하여 첫 번째 실행을 완료하는 데 오랜 시간이 걸립니다.
- 이 알고리즘을 사용하여 OCI 생성형 AI를 사용하여 사용자정의된 조각화를 생성할 수 있습니다.
-
의미 조각화 작동 방식:
-
smart_split_text(): 전체 텍스트를 10kb의 작은 부분으로 구분합니다(다른 전략을 채택하도록 구성할 수 있음). 메커니즘은 마지막 단락을 인식합니다. 단락의 일부가 다음 텍스트 조각에 있는 경우 이 부분은 처리에서 무시되고 다음 처리 텍스트 그룹에 추가됩니다. -
semantic_chunk(): 이 방법은 OCI LLM 메커니즘을 사용하여 단락을 구분합니다. 여기에는 제목, 표의 구성 요소, 스마트 청크를 실행하는 단락을 식별하는 인텔리전스가 포함됩니다. 여기서 전략은 Semantic Chunk 기법을 사용하는 것입니다. 일반적인 처리와 비교하면 임무를 완료하는 데 더 많은 시간이 걸릴 것입니다. 따라서 첫 번째 처리는 시간이 오래 걸리지만 다음에 FAISS가 미리 저장한 모든 데이터를 로드합니다. -
split_llm_output_into_chapters(): 이 메소드는 장을 구분하여 청크를 완성합니다.
주: 의미 조각화를 처리하려면 이 코드를 다운로드하십시오.
oci_genai_llm_context.py -
GraphRAG를 사용한 의미 조각화
oci_genai_llm_graphrag.py에서 코드를 다운로드합니다.
GraphRAG(그래프 증강 검색 증강 생성)은 기존의 벡터 기반 검색과 구조화된 지식 그래프를 결합한 고급 AI 아키텍처입니다. 표준 RAG 파이프라인에서 언어 모델은 벡터 데이터베이스(예: FAISS)의 의미적 유사성을 사용하여 관련 문서 청크를 검색합니다. 그러나 벡터 기반 검색은 임베딩 및 거리 측정 지표에만 의존하여 구조화되지 않은 방식으로 작동하므로 더 깊은 상황별 또는 관계형 의미를 놓칠 수 있습니다.
GraphRAG는 엔티티, 개념, 구성요소 및 해당 관계가 노드 및 모서리로 명시적으로 표시되는 지식 그래프 계층을 도입하여 이 프로세스를 향상시킵니다. 이 그래프 기반 context를 사용하면 언어 모델이 벡터 유사성만으로는 캡처할 수 없는 관계, 계층 및 종속성에 대해 추론할 수 있습니다.
-
왜 의미 조각화를 GraphRAG와 결합합니까?
의미 조각화는 장, 제목, 섹션 또는 논리적 분할과 같은 콘텐츠의 구조를 기반으로 큰 문서를 의미 있는 단위 또는 "조각"으로 지능적으로 분할하는 프로세스입니다. Rather than breaking documents purely by character limits or naive paragraph splitting, semantic chunking produces higher-quality, context-aware chunks that align better with human understanding.
-
GraphRAG 장점을 사용한 의미 조각화:
-
향상된 지식 표현:
- 의미 청크는 콘텐츠의 논리적 경계를 유지합니다.
- 이러한 청크에서 추출된 지식 그래프는 엔티티, 시스템, API, 프로세스 또는 서비스 간의 정확한 관계를 유지합니다.
-
다중 모달 상황별 검색(언어 모델이 둘 다 검색함):
- 벡터 데이터베이스에서 비구조적 context(의미적 유사성)입니다.
- 지식 그래프에서 구조화된 context(엔티티 관계 트리플)입니다.
- 이 하이브리드 접근 방식은 보다 완전하고 정확한 답변을 제공합니다.
-
향상된 추론 기능:
- 그래프 기반 검색을 통해 관계형 추론을 수행할 수 있습니다.
- LLM은 다음과 같은 질문에 답할 수 있습니다.
- Order API는 어떤 서비스에 종속됩니까?
- SOA Suite의 일부인 구성요소는 무엇입니까?
- 이러한 관계형 질의는 임베딩 전용 접근 방식으로는 불가능한 경우가 많습니다.
-
설명 가능성 및 추적 가능성 향상:
- 그래프 관계는 사람이 읽을 수 있고 투명합니다.
- 사용자는 텍스트 및 구조적 지식에서 답변이 파생되는 방법을 검사할 수 있습니다.
-
감소된 환각(Reduced Hallucination): 이 그래프는 소스 문서에서 추출된 검증된 관계 및 사실적 연결에 대한 응답을 앵커링하는 LLM의 제약 조건 역할을 수행합니다.
-
복잡한 도메인 전반의 확장성:
- 기술 도메인(예: API, 마이크로서비스, 법적 계약, 의료 표준)에서 구성 요소 간의 관계는 구성 요소 자체만큼 중요합니다.
- GraphRAG는 이러한 컨텍스트에서 의미 조각화와 효과적으로 결합되어 텍스트 깊이와 관계형 구조를 모두 유지합니다.
참고:
- 코드를 다운로드하여
oci_genai_llm_graphrag.py에서 graphRAG와 함께 의미 조각화를 처리합니다. - 다음이 필요합니다.
- Neo4J 오픈 소스 그래프 OS 데이터베이스를 사용하여 테스트하기 위해 설치되고 활성 상태인 docker입니다.
- neo4j Python 라이브러리를 설치합니다.
이 코드에는 다음 두 가지 방법이 있습니다.
-
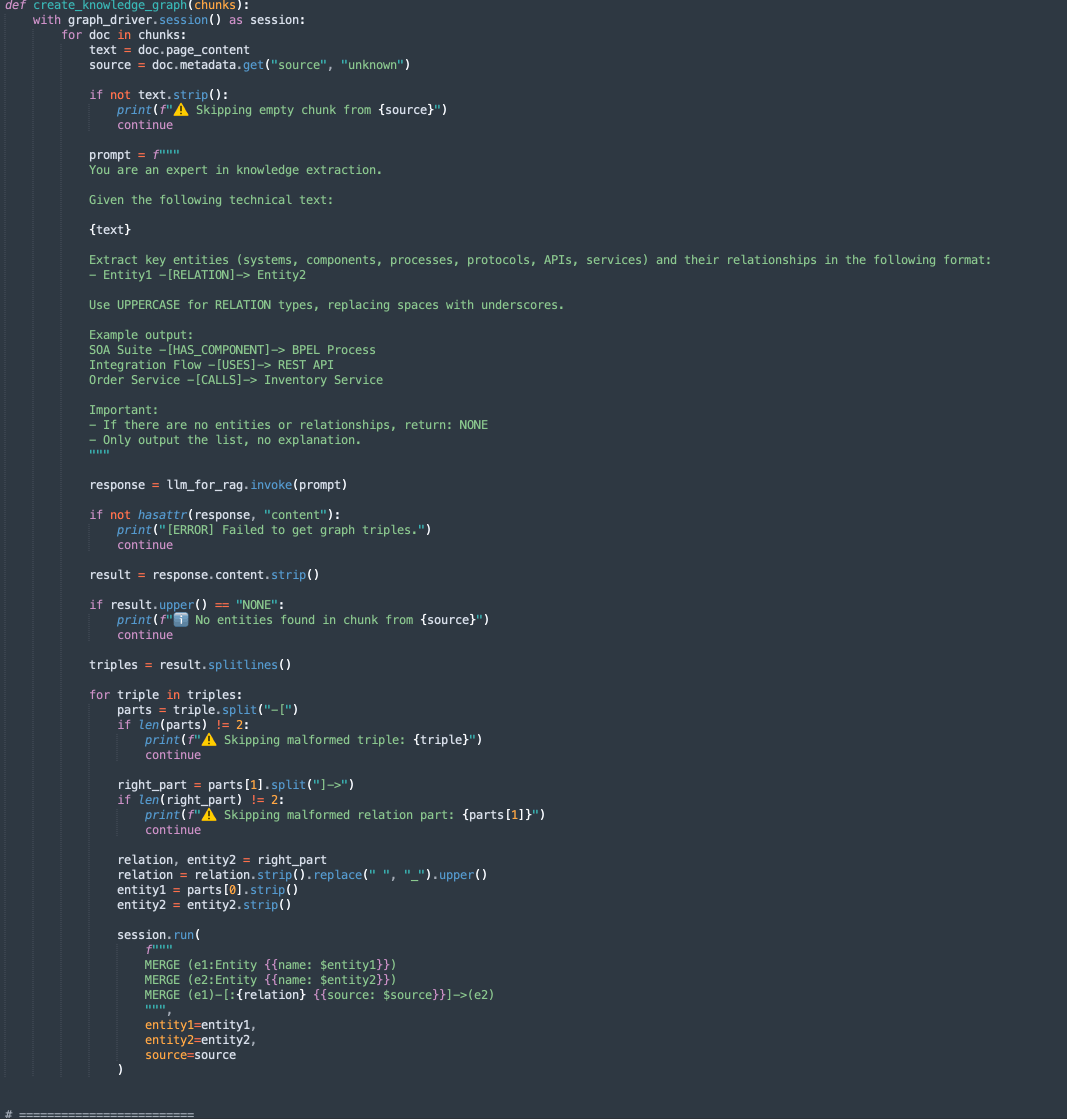
create_knowledge_graph:-
이 방법은 텍스트 청크에서 엔티티 및 관계를 자동으로 추출하여 Neo4j 지식 그래프에 저장합니다.
-
각 문서 조각에 대해 엔티티(예: 시스템, 구성요소, 서비스, API) 및 해당 관계를 추출하라는 프롬프트가 표시되면서 LLM(대형 언어 모델)으로 콘텐츠를 전송합니다.
-
각 행을 구문 분석하고 Entity1, RELATION 및 Entity2를 추출합니다.
-
Cypher 질의를 사용하여 이 정보를 Neo4j 그래프 데이터베이스에 노드 및 모서리로 저장합니다.
MERGE (e1:Entity {name: $entity1}) MERGE (e2:Entity {name: $entity2}) MERGE (e1)-[:RELATION {source: $source}]->(e2)
-
-
-
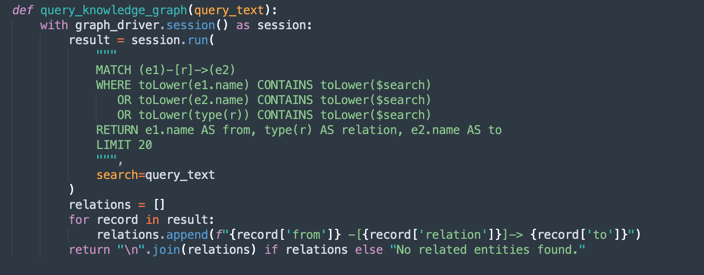
query_knowledge_graph:-
이 메소드는 Neo4j 지식 그래프를 질의하여 특정 키워드 또는 개념과 관련된 관계를 검색합니다.
-
다음을 검색하는 Cypher query를 실행합니다.
Any relationship (e1)-[r]->(e2) Where e1.name, e2.name, or the relationship type contains the query_text (case-insensitive). -
최대 20개의 일치하는 3배를 다음과 같이 형식 지정합니다.
Entity1 -[RELATION]-> Entity2
-
참고:
Neo4j 사용법:
이 구현에서는 데모 및 프로토타이핑을 위해 Neo4j를 내장된 지식 그래프 데이터베이스로 사용합니다. Neo4j는 개발, 테스트 및 중소, 중견 워크로드에 적합한 강력하고 유연한 그래프 데이터베이스이지만, 특히 고가용성, 확장성 및 고급 보안 준수가 필요한 환경에서 엔터프라이즈급, 미션 크리티컬 또는 고도의 보안 워크로드에 대한 요구사항을 충족하지 못할 수 있습니다.
운용 환경 및 엔터프라이즈 시나리오의 경우 다음을 제공하는 그래프 기능과 함께 Oracle Database를 활용하는 것이 좋습니다.
엔터프라이즈급 안정성 및 보안.
미션 크리티컬 워크로드를 위한 확장성.
관계형 데이터와 통합된 기본 그래프 모델(등록정보 그래프 및 RDF)입니다.
고급 분석, 보안, 고가용성 및 재해 복구 기능.
전체 Oracle Cloud Infrastructure(OCI) 통합.
조직은 그래프 워크로드에 Oracle Database를 사용하여 안전하고 확장 가능한 단일 엔터프라이즈 플랫폼 내에서 정형, 반구조적 및 그래프 데이터를 통합할 수 있습니다.
작업 3: Oracle Integration 및 Oracle SOA Suite 콘텐츠에 대한 질의 실행
다음 명령을 실행합니다.
FOR FIXED CHUNKING TECHNIQUE (MORE FASTER METHOD)
python oci_genai_llm_context_fast.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
FOR SEMANTIC CHUNKING TECHNIQUE
python oci_genai_llm_context.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
FOR SEMANTIC CHUNKING COMBINED WITH GRAPHRAG TECHNIQUE
python oci_genai_llm_graphrag.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
주:
--device및--gpu_name매개변수는 머신에 GPU가 있는 경우 GPU를 사용하여 Python의 처리를 가속화하는 데 사용할 수 있습니다. 이 코드는 로컬 모델에서도 사용할 수 있습니다.
제공된 컨텍스트는 Oracle SOA Suite와 Oracle Integration을 구분하며, 다음 사항을 고려하여 코드를 테스트할 수 있습니다.
- 질의는 Oracle SOA Suite에 대해서만 수행해야 합니다. 따라서 Oracle SOA Suite 문서만 고려해야 합니다.
- 질의는 Oracle Integration에 대해서만 수행해야 합니다. 따라서 Oracle Integration 문서만 고려해야 합니다.
- 질의를 수행하려면 Oracle SOA Suite와 Oracle Integration을 비교해야 합니다. 따라서 모든 문서를 고려해야 합니다.
문서를 올바르게 해석하는 데 큰 도움이 되는 다음 컨텍스트를 정의할 수 있습니다.
다음 이미지는 Oracle SOA Suite와 Oracle Integration 간의 비교 예제를 보여줍니다.

다음 단계
이 코드는 지능형 PDF 분석을 위한 OCI Generative AI의 적용을 보여줍니다. 사용자는 의미 검색 및 생성형 AI 모델을 사용하여 대량의 문서를 효율적으로 쿼리하여 정확한 자연어 응답을 생성할 수 있습니다.
이러한 접근 방식은 법률, 규정 준수, 기술 지원 및 학술 연구와 같은 다양한 분야에 적용될 수 있으므로 정보 검색이 훨씬 빠르고 스마트해집니다.
관련 링크
승인
- 작성자 - 크리스티아노 호시카와(Oracle LAD A-팀 솔루션 엔지니어)
추가 학습 자원
docs.oracle.com/learn에서 다른 랩을 탐색하거나 Oracle Learning YouTube 채널에서 더 많은 무료 학습 콘텐츠에 액세스하세요. 또한 education.oracle.com/learning-explorer를 방문하여 Oracle Learning Explorer가 되십시오.
제품 설명서는 Oracle Help Center를 참조하십시오.
Analyze PDF Documents in Natural Language with OCI Generative AI
G29542-05
Copyright ©2025, Oracle and/or its affiliates.