3 Setting Up a Topology
This chapter describes how to set up the topology in Oracle Data Integrator.
This chapter includes the following sections:
See Also:
"Overview of Oracle Data Integrator Topology" in Developing Integration Projects with Oracle Data Integrator.3.1 Setting Up the Topology
The following steps are a guideline to create the topology. You can always modify the topology after an initial setting:
-
Create the contexts corresponding to your different environments. See "Creating a Context".
-
Create the data servers corresponding to the servers used by Oracle Data Integrator. See "Creating a Data Server".
-
For each data server, create the physical schemas corresponding to the schemas containing data to be integrated with Oracle Data Integrator. See "Creating a Physical Schema".
-
Create logical schemas and associate them with physical schemas in the contexts. See "Creating a Logical Schema".
-
Create the physical agents corresponding to the Standalone, Standalone Colocated, or Java EE agents that are installed in your information systems. See "Creating a Physical Agent".
-
Create logical agents and associate them with physical agents in the contexts. See "Creating a Logical Agent".
Note:
You can use the New Model and Topology Objects dialog to create a model and associate it with topology objects, if connected to a work repository. For more information, see "Creating a Model and Topology Objects" in Developing Integration Projects with Oracle Data Integrator.3.1.1 Creating a Context
To create a context:
-
In Topology Navigator expand the Contexts navigation tree.
-
Click New context in the navigation tree header.
-
Fill in the following fields:
-
Name: Name of the context, as it appears in the Oracle Data Integrator graphical interface.
-
Code: Code of the context, allowing a context to be referenced and identified among the different repositories.
-
Password: Password requested when the user requests switches to this context in a graphical interface. It is recommended to use a password for critical contexts (for example, contexts pointing to Production data).
-
Check Default if you want this context to be displayed by default in the different lists in Designer Navigator or Operator Navigator.
-
-
From the File menu, click Save.
3.1.2 Creating a Data Server
A Data Server corresponds for example to a Database, JMS server instance, a scripting engine or a file system accessed with Oracle Data Integrator in the integration flows. Under a data server, subdivisions are created in the form of Physical Schemas.
Note:
Frequently used technologies have their data server creation methods detailed in Connectivity and Knowledge Modules Guide for Oracle Data Integrator.3.1.2.1 Pre-requisites and Guidelines
It is recommended to follow the guidelines below when creating a data server.
Review the Technology Specific Requirements
Some technologies require the installation and the configuration of elements such as:
-
Installation of a JDBC Driver. See Installing and Configuring Oracle Data Integrator for more information.
-
Installation of a Client Connector
-
Data source configuration
Refer to the documentation of the technology you are connecting to through the data server and to Connectivity and Knowledge Modules Guide for Oracle Data Integrator. The connection information may also change depending on the technology. Refer to the server documentation provided, and contact the server administrator to define the connection methods.
Create an Oracle Data Integrator User
For each database engine used by Oracle Data Integrator, it is recommended to create a user dedicated for ODI on this data server (typically named ODI_TEMP).
Grant the user privileges to:
-
Create/drop objects and perform data manipulation in his own schema.
-
Manipulate data into objects of the other schemas of this data server according to the operations required for the integration processes.
This user should be used as follows:
-
Use this user name/password in the data server user/password definition.
-
Use this user's schema as your Work Schema for all data schemas on this server.
3.1.2.2 Creating a Data Server
To create a Data Server:
-
In Topology Navigator expand the Technologies node in the Physical Architecture navigation tree.
Tip:
The list of technologies that are displayed in the Physical Architecture navigation tree may be very long. To narrow the list of displayed technologies, you can hide unused technologies by selecting Hide Unused Technologies from the Topology Navigator toolbar menu. -
Select the technology you want to create a data server for.
-
Right-click and select New Data Server.
-
Fill in the following fields in the Definition tab:
-
Name: Name of the Data Server that will appear in Oracle Data Integrator.
For naming data servers, it is recommended to use the following naming standard: <
TECHNOLOGY_NAME>_<SERVER_NAME>. -
... (Data Server): This is the physical name of the data server used by other data servers to identify it. Enter this name if your data servers can be inter-connected in a native way. This parameter is not mandatory for all technologies.
For example, for Oracle, this name corresponds to the name of the instance, used for accessing this data server from another Oracle data server through DBLinks.
-
User/Password: User name and password for connecting to the data server. This parameter is not mandatory for all technologies, as for example for the File technology.
Depending on the technology, this could be a "Login", a "User", or an "account". For some connections using the JNDI protocol, the user name and its associated password can be optional (if they have been given in the LDAP directory).
-
-
Define the connection parameters for the data server:
A technology can be accessed directly through JDBC or the JDBC connection to this data server can be served from a JNDI directory.
If the technology is accessed through a JNDI directory:
-
Check the JNDI Connection on the Definition tab.
-
Go to the JNDI tab, and fill in the following fields:
Field Description JNDI authentication - None: Anonymous access to the naming or directory service
-
Simple: Authenticated access, non-encrypted
-
CRAM-MD5: Authenticated access, encrypted MD5
-
<other value>: authenticated access, encrypted according to <other value>
JNDI User/Password User/password connecting to the JNDI directory JNDI Protocol Protocol used for the connection Note that only the most common protocols are listed here. This is not an exhaustive list.
-
LDAP: Access to an LDAP directory
-
SMQP: Access to a SwiftMQ MOM directory
-
<other value>: access following the sub-protocol <other value>
JNDI Driver The driver allowing the JNDI connection Example Sun LDAP directory:
com.sun.jndi.ldap.LdapCtxFactoryJNDI URL The URL allowing the JNDI connection For example:
ldap://suse70:389/o=linuxfocus.orgJNDI Resource The directory element containing the connection parameters For example:
cn=sampledbIf the technology is connected through JDBC:
-
Un-check the JNDI Connection box.
-
Go to the JDBC tab, and fill in the following fields:
Field Description JDBC Driver Name of the JDBC driver used for connecting to the data server JDBC URL URL allowing you to connect to the data server.
You can get a list of pre-defined JDBC drivers and URLs by clicking Display available drivers or Display URL sample.
-
-
Fill in the remaining fields in the Definition tab.
-
Array Fetch Size: When reading large volumes of data from a data server, Oracle Data Integrator fetches successive batches of records. This value is the number of rows (records read) requested by Oracle Data Integrator on each communication with the data server.
-
Batch Update Size: When writing large volumes of data into a data server, Oracle Data Integrator pushes successive batches of records. This value is the number of rows (records written) in a single Oracle Data Integrator INSERT command.
Caution:
The Fetch Array and Batch Update parameters are accessible only with JDBC. However, not all JDBC drivers accept the same values. At times, you are advised to leave them empty.Note:
The greater the number specified in the Fetch Array and Batch Update values, the fewer are the number of exchanges between the data server and Oracle Data Integrator. However, the load on the Oracle Data Integrator machine is greater, as a greater volume of data is recovered on each exchange. Batch Update management, like that of Fetch Array, falls within optimization. It is recommended that you start from a default value (30), then increase the value by 10 each time, until there is no further improvement in performance. -
Degree of Parallelism for Target: Indicates the number of threads allowed for a loading task. Default value is 1. Maximum number of threads allowed is 99.
Note:
The effect of increasing Degree of Parallelism is dependent on your target environment and whether the resources are sufficient to support a large number of target threads/connections. As per the Fetch Array and Batch Update sizes, you should perform some benchmarking to decide what is the best value for your environment. Details of the performance of the individual source and target threads can be viewed in the Execution Details section for the loading task in Operator. The Execute value is the time spent on performing the JDBC operation and the Wait value is the time the Source is waiting on the Targets to load the rows, or the time the Target is waiting on the Source to provide rows. Also, the Degree of Parallelism > 1 should not be used if you are relying on the order of loading rows, for example, if you are using sequences, timestamps, and so on. This is because the source rows are processed and loaded by one out of a number of target threads in an indeterminate manner.
-
-
From the File menu, click Save to validate the creation of the data server.
3.1.2.3 Creating a Data Server (Advanced Settings)
The following actions are optional:
These properties are passed when creating the connection, in order to provide optional configuration parameters. Each property is a (key, value) pair.
-
For JDBC: These properties depend on the driver used. Please see the driver documentation for a list of available properties. It is possible in JDBC to specify here the user and password for the connection, instead of specifying there in the Definition tab.
-
For JNDI: These properties depend on the resource used.
To add a connection property to a data server:
-
On the Properties tab click Add a Property.
-
Specify a Key identifying this property. This key is case-sensitive.
-
Specify a value for the property.
-
From the File menu, click Save.
On the Data Sources tab you can define JDBC data sources that will be used by Oracle Data Integrator Java EE agents deployed on application servers to connect to this data server. Note that data sources are not applicable for Standalone agents.
Defining data sources is not mandatory, but allows the Java EE agent to benefit from the data sources and connection pooling features available on the application server. Connection pooling allows reusing connections across several sessions. If a data source is not declared for a given data server in a Java EE agent, this Java EE agent always connects the data server using direct JDBC connection, that is without using any of the application server data sources.
Before defining the data sources in Oracle Data Integrator, please note the following:
-
Datasources for WebLogic Server should be created with the Statement Cache Size parameter set to 0 in the Connection Pool configuration. Statement caching has a minor impact on data integration performances, and may lead to unexpected results such as data truncation with some JDBC drivers. Note that this concerns only data connections to the source and target data servers, not the repository connections.
-
If using Connection Pooling with datasources, it is recommended to avoid ALTER SESSION statements in procedures and Knowledge Modules. If a connection requires ALTER SESSION statements, it is recommended to disable connection pooling in the related datasources.
To define JDBC data sources for a data server:
-
On the DataSources tab of the Data Server editor click Add a DataSource
-
Select a Physical Agent in the Agent field.
-
Enter the data source name in the JNDI Name field.
Note that this name must match the name of the data source in your application server.
-
Check JNDI Standard if you want to use the environment naming context (ENC).
When JNDI Standard is checked, Oracle Data Integrator automatically prefixes the data source name with the string
java:comp/env/to identify it in the application server's JNDI directory.Note that the JNDI Standard is not supported by Oracle WebLogic Server and for global data sources.
-
From the File menu, click Save.
After having defined a data source for a Java EE agent, you must create it in the application server into which the Java EE agent is deployed. There are several ways to create data sources in the application server, including:
-
Configure the data sources from the application server console. For more information, refer to your application server documentation.
-
"Deploying Datasources from Oracle Data Integrator in an application server for an Agent".
Setting Up On Connect/Disconnect Commands
On the On Connect/Disconnect tab you can define SQL commands that will be executed when a connection to a data server defined in the physical architecture is created or closed.
The On Connect command is executed every time an ODI component, including ODI client components, connects to this data server.
The On Disconnect command is executed every time an ODI component, including ODI client components, disconnects from this data server.
These SQL commands are stored in the master repository along with the data server definition.
Before setting up commands On Connect/Disconnect, please note the following:
-
The On Connect/Disconnect commands are only supported by data servers with a technology type Database (JDBC).
-
The On Connect and Disconnect commands are executed even when using data sources. In this case, the commands are executed when taking and releasing the connection from the connection pool.
-
Substitution APIs are supported. Note that the design time tags
<%are not supported. Only the execution time tags<?and<@are supported. -
Only global variables in substitution mode (
#GLOBAL.<VAR_NAME>or#<VAR_NAME>) are supported. See "Variable Scope" for more information. Note that the Expression Editor only displays variables that are valid for the current data server. -
The variables that are used in On Connect/Disconnect commands are only replaced at runtime, when the session starts. A command using variables will fail when testing the data server connection or performing a View Data operation on this data server. Make sure that these variables are declared in the scenarios.
-
Oracle Data Integrator Sequences are not supported in the On Connect and Disconnect commands.
The commands On Connect/Disconnect have the following usage:
-
When a session runs, it opens connections to data servers. every time a connection is opened on a data server that has a command On Connect defined, a task is created under a specific step called Command on Connect. This task is named after the data server to which the connection is established, the step and task that create the connection to this data server. It contains the code of the On Connect command.
-
When the session completes, it closes all connections to the data servers. Every time a connection is closed on a data server that has a command On Disunite defined, a task is created under a specific step called Command on Disconnect. This task is named after the data server that is disconnected, the step and task that dropped the connection to this data server. It contains the code of the On Disconnect command.
-
When an operation is made in ODI Studio or ODI Console that requires a connection to the data server (such as View Data or Test Connection), the commands On Connect/Disconnect are also executed if the Client Transaction is selected for this command.
Note:
You can specify whether or not to show On Connect and Disconnect steps in Operator Navigator. If the user parameter Hide On Connect and Disconnect Steps is set toYes, On Connect and Disconnect steps are not shown.To set up On Connect/Disconnect commands:
-
On the On Connect/Disconnect tab of the Data Server editor, click Launch the Expression Editor in the On Connect section or in the On Disconnect section.
-
In the Expression Editor, enter the SQL command.
Note:
The Expression Editor displays only the substitution methods and keywords that are available for the technology of the data server. Note that global variables are only displayed if the connection to the work repository is available. -
Click OK. The SQL command is displayed in the Command field.
-
Optionally, select Commit, if you want to commit the connection after executing the command. Note that if AutoCommit or Client Transaction is selected in the Execute On list, this value will be ignored.
-
Optionally, select Ignore Errors, if you want to ignore the exceptions encountered during the command execution. Note that if Ignore Errors is not selected, the calling operation will end in error status. A command with Ignore Error selected that fails during a session will appear as a task in a Warning state.
-
From the Log Level list, select the logging level (from 1 to 6) of the connect or disconnect command. At execution time, commands can be kept in the session log based on their log level. Default is
3. -
From the Execute On list, select the transaction(s) on which you want to execute the command.
Note:
Transactions from 0 to 9 and the Autocommit transaction correspond to connection created by sessions (by procedures or knowledge modules). The Client Transaction corresponds to the client components (ODI Console and Studio).You can select Select All or Unselect All to select or unselect all transactions.
-
From the File menu, click Save.
You can now test the connection, see "Testing a Data Server Connection" for more information.
3.1.2.4 Testing a Data Server Connection
It is recommended to test the data server connection before proceeding in the topology definition.
To test a connection to a data server:
-
In Topology Navigator expand the Technologies node in the Physical Architecture navigation tree and then expand the technology containing your data server.
-
Double-click the data server you want to test. The Data Server Editor opens.
-
Click Test Connection.
The Test Connection dialog is displayed.
-
Select the agent that will carry out the test. Local (No Agent) indicates that the local station will attempt to connect.
-
Click Detail to obtain the characteristics and capacities of the database and JDBC driver.
-
Click Test to launch the test.
A window showing "connection successful!" is displayed if the test has worked; if not, an error window appears. Use the detail button in this error window to obtain more information about the cause of the connection failure.
3.1.3 Creating a Physical Schema
An Oracle Data Integrator Physical Schema corresponds to a pair of Schemas:
-
A (Data) Schema, into which Oracle Data Integrator will look for the source and target data structures for the mappings.
-
A Work Schema, into which Oracle Data Integrator can create and manipulate temporary work data structures associated to the sources and targets contained in the Data Schema.
Frequently used technologies have their physical schema creation methods detailed in Connectivity and Knowledge Modules Guide for Oracle Data Integrator.
Before creating a Physical Schema, note the following:
-
Not all technologies support multiple schemas. In some technologies, you do not specify the work and data schemas since one data server has only one schema.
-
Some technologies do not support the creation of temporary structures. The work schema is useless for these technologies.
-
The user specified in the data server to which the Physical Schema is attached must have appropriate privileges on the schemas attached to this data server.
-
In a Physical Schema for the OWB technology, only OWB workspaces are displayed and can be selected.
To create a Physical Schema:
-
Select the data server, Right-click and select New Physical Schema. The Physical Schema Editor appears.
-
If the technology supports multiple schemas:
-
Select or type the Data Schema for this Data Integrator physical schema in ... (Schema). A list of the schemas appears if the technologies supports schema listing.
-
Select or type the Work Schema for this Data Integrator physical schema in ... (Work Schema). A list of the schemas appears if the technologies supports schema listing.
-
-
Check the Default box if you want this schema to be the default one for this data server (The first physical schema is always the default one).
-
Go to the Context tab.
-
Click Add.
-
Select a Context and an existing Logical Schema for this new Physical Schema.
If no Logical Schema for this technology exists yet, you can create it from this Editor.
To create a Logical Schema:
-
Select an existing Context in the left column.
-
Type the name of a Logical Schema in the right column.
This Logical Schema is automatically created and associated to this physical schema in this context when saving this Editor.
-
-
From the File menu, click Save.
3.1.4 Creating a Logical Schema
To create a logical schema:
-
In Topology Navigator expand the Technologies node in the Logical Architecture navigation tree.
-
Select the technology you want to attach your logical schema to.
-
Right-click and select New Logical Schema.
-
Fill in the schema name.
-
For each Context in the left column, select an existing Physical Schema in the right column. This Physical Schema is automatically associated to the logical schema in this context. Repeat this operation for all necessary contexts.
-
From the File menu, click Save.
3.1.5 Creating a Physical Agent
To create a Physical Agent:
-
In Topology Navigator right-click the Agents node in the Physical Architecture navigation tree.
-
Select New Agent.
-
Fill in the following fields:
-
Name: Name of the agent used in the Java graphical interface.
Note:
Avoid using Internal as agent name. Oracle Data Integrator uses the Internal agent when running sessions using the internal agent and reserves the Internal agent name. -
Host: Network name or IP address of the machine the agent will be launched on.
-
Port: Listening port used by the agent. By default, this port is the 20910.
-
Web Application Context: Name of the web application corresponding to the Java EE agent deployed on an application server. For Standalone and Standalone Colocated agents, this field should be set to oraclediagent.
-
Protocol: Protocol to use for the agent connection. Possible values are
httporhttps. Default ishttp. -
Maximum number of sessions supported by this agent.
-
Maximum number of threads: Controls the number of maximum threads an ODI agent can use at any given time. Tune this as per your system resources and CPU capacity.
-
Maximum threads per session: ODI supports executing sessions with multiple threads. This limits maximum parallelism for a single session execution.
-
Session Blueprint cache Management:
-
Maximum cache entries: For performance, session blueprints are cached. Tune this parameter to control the JVM memory consumption due to the Blueprint cache.
-
Unused Blueprint Lifetime (sec): Idle time interval for flushing a blueprint from the cache.
-
-
-
If you want to setup load balancing, go to the Load balancing tab and select a set of linked physical agent to which the current agent can delegate executions. See "Setting Up Load Balancing" for more information.
-
If the agent is launched, click Test. The successful connection dialog is displayed.
-
Click Yes.
3.1.6 Creating a Logical Agent
To create a logical agent:
-
In Topology Navigator right-click the Agents node in the Logical Architecture navigation tree.
-
Select New Logical Agent.
-
Fill in the Agent Name.
-
For each Context in the left column, select an existing Physical Agent in the right column. This Physical Agent is automatically associated to the logical agent in this context. Repeat this operation for all necessary contexts.
-
From the File menu, click Save.
3.2 Working with Big Data
Oracle Data Integrator lets you integrate Big Data, deploy and execute Oozie workflows, and generate code in languages such as Pig Latin and Spark.
The following steps are a guideline to set up a topology to work with Big Data:
Table 3-1 Working with Big Data
| Task | Documentation |
|---|---|
|
Set up the environment to integrate Hadoop data |
See "Setting Up the Environment for Integrating Hadoop Data" in Integrating Big Data with Oracle Data Integrator. |
|
Set up the data servers for Big Data technologies, such as Hive, HDFS, and HBase |
See the following sections in Integrating Big Data with Oracle Data Integrator: "Setting Up File Data Sources" |
|
Set up an Oozie Engine if you want to execute Oozie workflows from within Oracle Data Integrator |
See "Setting Up and Initializing the Oozie Runtime Engine" in Integrating Big Data with Oracle Data Integrator. |
|
Set up Hive, Pig, and Spark topology objects if you want to generate Pig Latin and Spark code |
See the following sections in Integrating Big Data with Oracle Data Integrator: "Creating a Hive Physical Schema" "Creating a Pig Physical Schema" |
3.3 Managing Agents
This section describes how to work with a Standalone agent, a Standalone Colocated agent, a Java EE agent and how to handle load balancing. For information on Oracle Data Integrator agents, see "Run-Time Agent" in Understanding Oracle Data Integrator and "Understanding Oracle Data Integrator Agents" in Installing and Configuring Oracle Data Integrator.
3.3.1 Standalone Agent
Managing the Standalone agent involves the actions discussed in these sections:
Note:
The agent command line scripts, which are required for performing the tasks described in this section, are only available if you have installed the Oracle Data Integrator Standalone agent. See Installing and Configuring Oracle Data Integrator for information about how to install the Standalone agent.3.3.1.1 Configuring a Standalone Agent
Configuring a Standalone agent is described in Installing and Configuring Oracle Data Integrator. See:
3.3.1.2 Launching a Standalone Agent
The Standalone agent is able to execute scenarios on predefined schedules or on demand. The instructions for launching the Standalone agent are provided in "Starting a Standalone Agent Using Node Manager" in Installing and Configuring Oracle Data Integrator.
3.3.1.3 Stopping an Agent
The procedure for stopping a Standalone agent is described in "Stopping Your Oracle Data Integrator Agents" in Installing and Configuring Oracle Data Integrator.
3.3.2 Standalone Colocated Agent
Managing a Standalone Colocated agent involves the actions discussed in these sections:
Note:
A Standalone Colocated agent is a Standalone agent that is configured in a WebLogic domain and is managed by an Administration Server. The WebLogic domain makes Oracle Fusion Middleware Infrastructure services available for managing the agent. See "Understanding the Standard Installation Topology for the Standalone Colocated Agent" in Installing and Configuring Oracle Data Integrator for more information.3.3.2.1 Configuring a Standalone Colocated Agent
Configuring a Standalone Colocated agent is described in Installing and Configuring Oracle Data Integrator. See:
3.3.2.2 Launching a Standalone Colocated Agent
The instructions for launching the Standalone Colocated agent are provided in "Starting a Standalone Colocated Agent" in Installing and Configuring Oracle Data Integrator.
3.3.2.3 Stopping an Agent
The procedure for stopping a Standalone Colocated agent is described in "Stopping Your Oracle Data Integrator Agents," in Installing and Configuring Oracle Data Integrator.
3.3.3 Java EE Agent
Managing a Java EE agent involves the actions discussed in the sections:
3.3.3.1 Deploying an Agent in a Java EE Application Server
Configuring a Java EE agent is described in Installing and Configuring Oracle Data Integrator. See:
3.3.3.2 Creating a Server Template for a Java EE Agent
Oracle Data Integrator provides a Server Template Generation wizard to help you create a server template for a run-time agent.
To open the Server Template Generation wizard:
-
From the Physical Agent Editor toolbar menu, select Generate Server Template. This starts the Template Generation wizard, shown in Figure 3-1.
Figure 3-1 Server Template Generation Wizard - Agent Information Tab
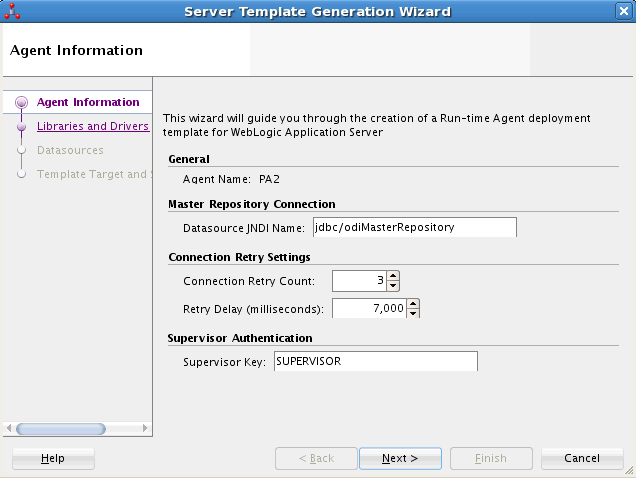
Description of "Figure 3-1 Server Template Generation Wizard - Agent Information Tab"
-
In the Agent Information tab, review the agent information and modify the default configuration if needed.
The Agent Information includes the following parameters:
-
General
Agent Name: Displays the name of the agent that you want to deploy.
-
Master Repository Connection
Datasource JNDI Name: The name of the datasource used by the Java EE agent to connect to the master repository. The template can contain a definition of this datasource. Default is
jdbc/odiMasterRepository. -
Connection Retry Settings
Connection Retry Count: Number of retry attempts done if the agent loses the connection to the repository. Note that setting this parameter to a non-zero value, enables a high availability connection retry feature if the ODI repository resides on an Oracle RAC database. If this feature is enabled, the agent can continue to execute sessions without interruptions even if one or more Oracle RAC nodes become unavailable.
Retry Delay (milliseconds): Interval (in milliseconds) between each connection retry attempt.
-
Supervisor Authentication
Supervisor Key: Name of the key in the application server credential store that contains the login and the password of an ODI user with Supervisor privileges. This agent will use this user credentials to connect to the repository.
-
-
Click Next. The Libraries and Drivers tab is displayed, shown in Figure 3-2.
Figure 3-2 Server Template Generation Wizard - Libraries and Drivers Tab
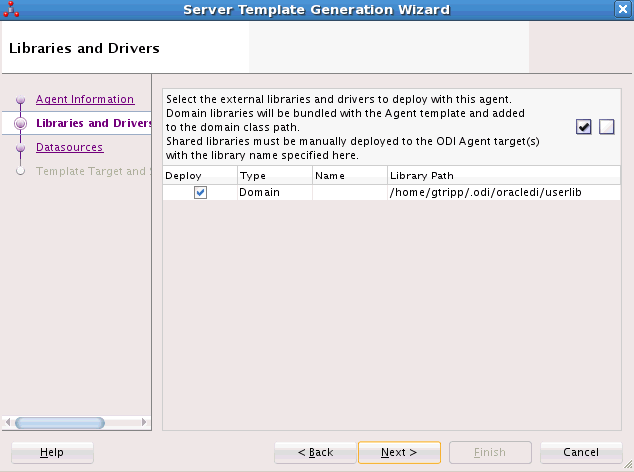
Description of "Figure 3-2 Server Template Generation Wizard - Libraries and Drivers Tab"
-
In the Libraries and Drivers tab, select from the list the external libraries and drivers to deploy with this agent. Only libraries added by the user appear here.
Note that the libraries can be any JAR or ZIP file that is required for this agent. Additional JDBC drivers or libraries for accessing the source and target data servers must be selected here.
You can also select a Domain library or a Shared library in the Type column. On selecting Domain, the respective JAR is added as part of the system class path and is visible to all the applications in that domain. On selecting Shared, you can select a JAR and make it a shared library, when it is deployed. If the JAR is selected as a shared library, the Name column is enabled and the JAR file's reference name, which is the name provided in the MANIFEST file against Extension-Name attribute, is displayed. If the JAR file does not have a reference name, you must add a unique name in the Name column as selected shared libraries are deployed into the WebLogic server with the name provided in ODI Studio.
Note:
OpenTool JAR should always be selected as Shared type. Also, JARs which are selected as shared, should be deployed as a shared library manually into the Weblogic server. Now these JARs will be added as part of the application class path.You can use the corresponding buttons in the toolbar to select or deselect all libraries and/or drivers in the list.
-
Click Next. The Datasources tab is displayed, shown in Figure 3-3.
Figure 3-3 Server Template Generation Wizard - Datasources Tab
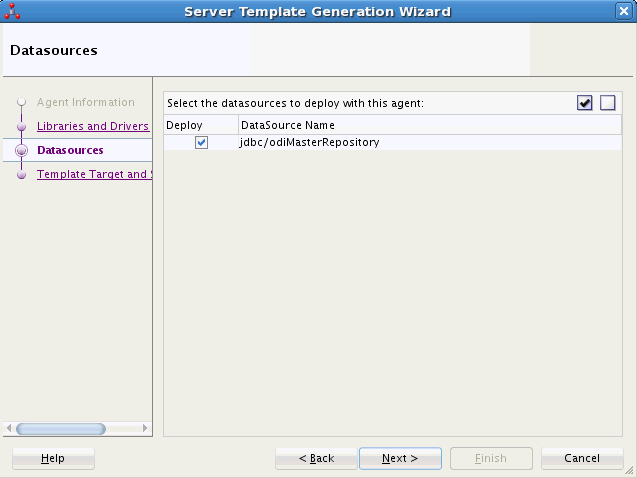
Description of "Figure 3-3 Server Template Generation Wizard - Datasources Tab"
-
In the Datasources tab, select the datasources definitions that you want to include in this agent template. You can only select datasources from the wizard. Naming and adding these datasources is done in the Data Sources tab of the Physical Agent editor.
-
Click Next. The Template Target and Summary tab is displayed, shown in Figure 3-4.
Figure 3-4 Server Template Generation Wizard - Template Target and Summary Tab
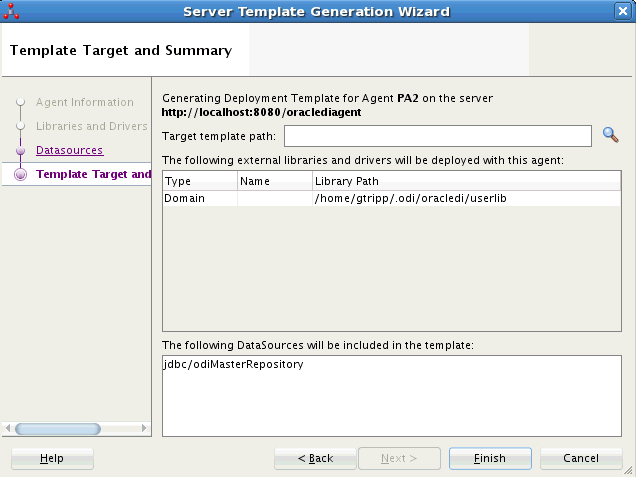
Description of "Figure 3-4 Server Template Generation Wizard - Template Target and Summary Tab"
-
In Template Target and Summary tab, enter the Target Template Path where the server template will be generated.
-
Click Finish to close the wizard and generate the server template.
The Template generation information dialog appears.
-
Click OK to close the dialog.
The generated template can be used to deploy the agent in WLS or WAS using the respective configuration wizard. Refer to Installing and Configuring Oracle Data Integrator for more information.
Declare the Supervisor in the Credential Store
After deploying the template, it is necessary to declare the Supervisor into the WLS or WAS Credential Store. Refer to Installing and Configuring Oracle Data Integrator for more information.
3.3.3.3 Deploying Datasources from Oracle Data Integrator in an application server for an Agent
You can deploy datasources from the Topology Navigator into an application server for which a Java EE agent is configured. Note that the datasources can only be deployed on the Oracle WebLogic Server.
To deploy datasources in an application server:
-
Open the Physical Agent Editor configured for the application server into which you want to deploy the datasources.
-
Go to the Datasources tab.
-
Drag and drop the source/target data servers from the Physical Architecture tree in the Topology Navigator into the DataSources tab.
-
Provide a JNDI Name for these datasources.
-
Right-click any of the datasource, then select Deploy Datasource on Server.
-
On the Datasources Deployment dialog, select the server on which you want to deploy the data sources. Possible values are WLS or WAS server.
-
In the Deployment Server Details section, fill in the following fields:
-
Host: Host name or IP address of the application server.
-
Port: Bootstrap port of the deployment manager
-
User: Server user name.
-
Password: This user's password
-
-
In the Datasource Deployment section, provide the name of the server on which the datasource should be deployed, for example
odi_server1. -
Click OK.
Note:
This operation only creates the Datasources definition in the Oracle WebLogic Server. It does not install drivers or library files needed for these datasources to work. Additional drivers added to the Studio classpath can be included into the Agent Template. See "Creating a Server Template for a Java EE Agent" for more information.WLS Datasource Configuration and Usage
When setting up datasources in WebLogic Server for Oracle Data Integrator, please note the following:
-
Datasources should be created with the Statement Cache Size parameter set to 0 in the Connection Pool configuration. Statement caching has a minor impact on data integration performances, and may lead to unexpected results such as data truncation with some JDBC drivers.
-
If using Connection Pooling with datasources, it is recommended to avoid ALTER SESSION statements in procedures and Knowledge Modules. If a connection requires ALTER SESSION statements, it is recommended to disable connection pooling in the related datasources, as an altered connection returns to the connection pool after usage.
3.3.4 Load Balancing Agents
Oracle Data Integrator allows you to load balance parallel session execution between physical agents.
Each physical agent is defined with:
-
A maximum number of sessions it can execute simultaneously from a work repository.
The maximum number of sessions is a value that must be set depending on the capabilities of the machine running the agent. It can be also set depending on the amount of processing power you want to give to the Oracle Data Integrator agent.
-
Optionally, a number of linked physical agents to which it can delegate sessions' executions.
An agent's load is determined at a given time by the ratio (Number of running sessions / Maximum number of sessions) for this agent.
3.3.4.1 Delegating Sessions
When a session is started on an agent with linked agents, Oracle Data Integrator determines which one of the linked agents is less loaded, and the session is delegated to this linked agent.
An agent can be linked to itself, in order to execute some of the incoming sessions, instead of delegating them all to other agents. Note that an agent not linked to itself is only able to delegate sessions to its linked agents, and will never execute a session.
Delegation cascades in the hierarchy of linked agents. If agent A has agent B1 and B2 linked to it, and agent B1 has agent C1 linked to it, then sessions started on agent A will be executed by agent B2 or agent C1. Note that it is not recommended to make loops in agents links.
If the user parameter "Use new Load Balancing" is set to Yes, sessions are also re-balanced each time a session finishes. This means that if an agent runs out of sessions, it will possibly be reallocated sessions already allocated to another agent.
3.3.4.2 Agent Unavailable
When for a given agent the number of running sessions reaches its maximum number of sessions, the agent will put incoming sessions in a "queued" status until the number of running sessions falls below the maximum of sessions.
If an agent is unavailable (because it crashed for example), all its sessions in queue will be re-assigned to another load balanced agent that is neither running any session nor having sessions in queue if the user parameter Use the new load balancing is set to Yes.
3.3.4.3 Setting Up Load Balancing
To setup load balancing:
-
Define a set of physical agents, and link them in a hierarchy of agents (see "Creating a Physical Agent" for more information).
-
Start all the physical agents corresponding to the agents defined in the topology.
-
Run the executions on the root agent of your hierarchy. Oracle Data Integrator will balance the load of the executions between its linked agents.
3.4 Roadmap for Setting Up a High Availability Topology
This section provides the high level steps you need to perform to set up a high availability topology.
Table 3-2 Roadmap for Setting Up a High Availability Topology
| Task | Documentation |
|---|---|
|
1. Install Real Application Clusters |
See Oracle Real Application Clusters Administration and Deployment Guide. |
|
2. Install middleware components |
See Installing and Configuring the Oracle Fusion Middleware Infrastructure. |
|
3. Configure Repository Connections to Oracle RAC |
See "Configuring Repository Connections to Oracle RAC" in High Availability Guide. |
|
4. Install Oracle HTTP Server |
|
|
5. Configure a load balancer |
See "Configuring the Load Balancer" and "Server Load Balancing in a High Availability Environment" in High Availability Guide. |
|
6. Scale out the topology (machine scale out) |
See "Scaling Out a Topology (Machine Scale Out)" in High Availability Guide. |
|
7. Create the high availability domain |
See "Configuring Active GridLink Data Sources with Oracle RAC" in High Availability Guide. |
|
8. Configure high availability for the Administration Server |
See "Administration Server High Availability" in High Availability Guide. |
|
9. Reconfigure agents |
See "Reconfigure Agents". |
3.4.1 Reconfigure Agents
Agent definitions should point to the load balancer address instead of the individual server addresses. Connect to Oracle Data Integrator Studio and edit the Load Balancer Host and Port properties, as shown below:
-
Start Oracle Data Integrator Studio at ODI_HOME
/oracledi/client/odi.sh. -
After Oracle Data Integrator Studio comes up, click on Connect to Repository on the left-hand pane.
-
When the Login window appears, click OK to log on.
-
When you are connected, open the Physical Architecture section on the left-hand pane.
-
Select Agents and then select OracleDIAgent.
-
Edit the following properties:
- Host: The load balancer virtual server address.
- Port: The load balancer virtual address listening port.
-
Click Test to test the agent connection.
-
Save and exit Oracle Data Integrator Studio.