1 Overview of Oracle Data Integrator
This chapter introduces Oracle Data Integrator.
This chapter includes the following sections:
-
Introduction to Data Integration with Oracle Data Integrator
-
Understanding the Oracle Data Integrator Component Architecture
Introduction to Data Integration with Oracle Data Integrator
Data Integration ensures that information is timely, accurate, and consistent across complex systems. This section provides an introduction to data integration and describes how Oracle Data Integrator provides support for Data Integration.
What is Data Integration?
Integrating data and applications throughout the enterprise, and presenting them in a unified view is a complex proposition. Not only are there broad disparities in technologies, data structures, and application functionality, but there are also fundamental differences in integration architectures. Some integration needs are Data Oriented, especially those involving large data volumes. Other integration projects lend themselves to an Event Driven Architecture (EDA) or a Service Oriented Architecture (SOA), for asynchronous or synchronous integration.
Data Integration ensures that information is timely, accurate, and consistent across complex systems. Although it is still frequently referred as Extract-Transform-Load (ETL), data integration was initially considered as the architecture used for loading Enterprise Data Warehouse systems. Data integration now includes data movement, data synchronization, data quality, data management, and data services.
About Oracle Data Integrator
Oracle Data Integrator provides a fully unified solution for building, deploying, and managing complex data warehouses or as part of data-centric architectures in a SOA or business intelligence environment. In addition, it combines all the elements of data integration—data movement, data synchronization, data quality, data management, and data services—to ensure that information is timely, accurate, and consistent across complex systems.
Oracle Data Integrator (ODI) features an active integration platform that includes all styles of data integration: data-based, event-based and service-based. ODI unifies silos of integration by transforming large volumes of data efficiently, processing events in real time through its advanced Changed Data Capture (CDC) framework, and providing data services to the Oracle SOA Suite. It also provides robust data integrity control features, assuring the consistency and correctness of data. With powerful core differentiators - heterogeneous E-LT, Declarative Design and Knowledge Modules - Oracle Data Integrator meets the performance, flexibility, productivity, modularity and hot-pluggability requirements of an integration platform.
What is E-LT?
Traditional ETL tools operate by first Extracting the data from various sources, Transforming the data in a proprietary, middle-tier ETL engine that is used as the staging area, and then Loading the transformed data into the target data warehouse, integration server, or Hadoop cluster. Hence the term ETL represents both the names and the order of the operations performed, as shown in Figure 1-1.
Figure 1-1 Traditional ETL versus ODI E-LT

Description of ''Figure 1-1 Traditional ETL versus ODI E-LT ''
The data transformation step of the ETL process is by far the most compute-intensive, and is performed entirely by the proprietary ETL engine on a dedicated server. The ETL engine performs data transformations (and sometimes data quality checks) on a row-by-row basis, and hence, can easily become the bottleneck in the overall process. In addition, the data must be moved over the network twice – once between the sources and the ETL server, and again between the ETL server and the target data warehouse or Hadoop cluster. Moreover, if one wants to ensure referential integrity by comparing data flow references against values from the target data warehouse, the referenced data must be downloaded from the target to the engine, thus further increasing network traffic, download time, and leading to additional performance issues.
In response to the issues raised by ETL architectures, a new architecture has emerged, which in many ways incorporates the best aspects of manual coding and automated code-generation approaches. Known as E-LT, this new approach changes where and how data transformation takes place, and leverages existing developer skills, RDBMS and Big Data engines, and server hardware to the greatest extent possible. In essence, E-LT moves the data transformation step to the target RDBMS, changing the order of operations to: Extract the data from the source tables, Load the tables into the destination server, and then Transform the data on the target RDBMS using native SQL operators. Note, with E-LT there is no need for a middle-tier engine or server as shown in Figure 1-1.
Oracle Data Integrator supports both ETL- and E-LT-Style data integration. See "Designing E-LT and ETL-Style Mappings" in Developing Integration Projects with Oracle Data Integrator for more information.
Understanding the Oracle Data Integrator Component Architecture
The Oracle Data Integrator platform integrates in the broader Fusion Middleware platform and becomes a key component of this stack. Oracle Data Integrator provides its run-time components as Java EE applications, enhanced to fully leverage the capabilities of the Oracle WebLogic Application Server. Oracle Data Integrator components include exclusive features for Enterprise-Scale Deployments, high availability, scalability, and hardened security. Figure 1-2 shows the ODI component architecture.
Figure 1-2 Oracle Data Integrator Component Architecture
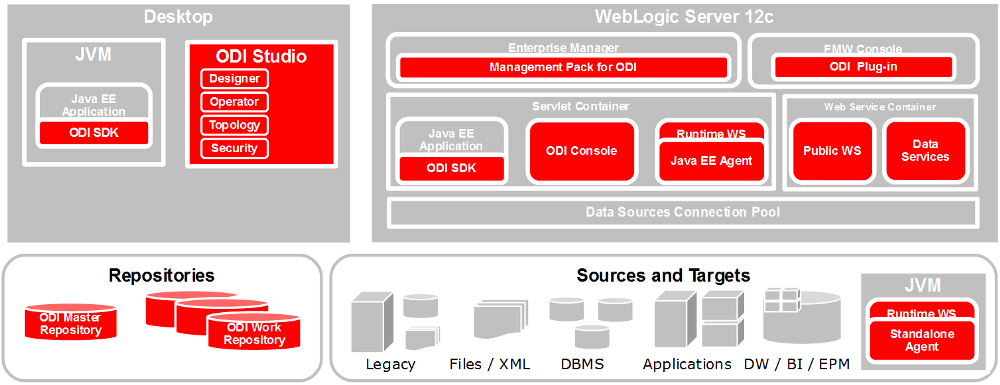
Description of ''Figure 1-2 Oracle Data Integrator Component Architecture''
Repositories
The central component of the architecture is the Oracle Data Integrator Repository. It stores configuration information about the IT infrastructure, metadata of all applications, projects, scenarios, and the execution logs. Many instances of the repository can coexist in the IT infrastructure. The architecture of the repository is designed to allow several separated environments that exchange metadata and scenarios (for example: Development, Test, Maintenance and Production environments). In the figure above, two repositories are represented: one for the development environment, and another one for the production environment. The repository also acts as a version control system where objects are archived and assigned a version number. The Oracle Data Integrator Repository can be installed on an OLTP relational database.
The Oracle Data Integrator Repository is composed of a master repository and several Work Repositories. Objects developed or configured through the users are stored in one of these repository types.
There is usually only one master repository that stores the following information:
-
Security information including users, profiles and rights for the ODI platform.
-
Topology information including technologies, server definitions, schemas, contexts, languages, etc.
-
Versioned and archived objects.
The Work Repository is the one that contains actual developed objects. Several work repositories may coexist in the same ODI installation (for example, to have separate environments or to match a particular versioning life cycle). A Work Repository stores information for:
-
Models, including schema definition, datastores structures and metadata, fields and attributes definitions, data quality constraints, cross references, data lineage etc.
-
Projects, including business rules, packages, procedures, folders, Knowledge Modules, variables etc.
-
Scenario execution, including scenarios, scheduling information and logs.
When the Work Repository contains only the execution information (typically for production purposes), it is then called an Execution Repository.
For more information on how to manage ODI repositories, see "Administering Repositories" in Administering Oracle Data Integrator.
Users
Administrators, Developers and Operators use the Oracle Data Integrator Studio to access the repositories. This Fusion Client Platform (FCP) based UI is used for administering the infrastructure (security and topology), reverse-engineering the metadata, developing projects, scheduling, operating and monitoring executions.
Business users (as well as developers, administrators and operators), can have read access to the repository, perform topology configuration and production operations through a web based UI called Oracle Data Integrator Console. This Web application can be deployed in a Java EE application server such as Oracle WebLogic.
ODI Studio provides four Navigators for managing the different aspects and steps of an ODI integration project:
Topology Navigator is used to manage the data describing the information system's physical and logical architecture. Through Topology Navigator you can manage the topology of your information system, the technologies and their datatypes, the data servers linked to these technologies and the schemas they contain, the contexts, the language and the agents, as well as the repositories. The site, machine, and data server descriptions will enable Oracle Data Integrator to execute the same mappings in different environments.
Designer Navigator is used to design data integrity checks and to build transformations such as for example:
-
Automatic reverse-engineering of existing applications or databases
-
Graphical development and maintenance of transformations and mappings
-
Visualization of data flows in the mappings
-
Automatic documentation generation
-
Customization of the generated code
The main objects you handle through Designer Navigator are Models and Projects.
Operator Navigator is the production management and monitoring tool. It is designed for IT production operators. Through Operator Navigator, you can manage your executions in the sessions, as well as the scenarios in production.
Security Navigator is the tool for managing the security information in Oracle Data Integrator. Through Security Navigator you can create users and profiles and assign user rights for methods (edit, delete, etc) on generic objects (data server, datatypes, etc), and fine-tune these rights on the object instances (Server 1, Server 2, etc).
Run-Time Agent
At design time, developers generate scenarios from the business rules that they have designed. The code of these scenarios is then retrieved from the repository by the Run-Time Agent. This agent then connects to the data servers and orchestrates the code execution on these servers. It retrieves the return codes and messages for the execution, as well as additional logging information – such as the number of processed records, execution time etc. - in the Repository.
The Agent comes in three different flavors:
-
Standalone Agent
The standalone agent runs in a separate Java Virtual Machine (JVM) process. It connects to the work repository and to the source and target data servers via JDBC. Standalone agents can be installed on any server with a Java Virtual Machine installed. This type of agent is more appropriate when you need to use a resource that is local to one of your data servers (for example, the file system or a loader utility installed with the database instance), and you do not want to install a Java EE application server on this machine.
-
Standalone Colocated Agent
A standalone colocated agent runs in a separate Java Virtual Machine (JVM) process but is part of a WebLogic Server domain and controlled by a WebLogic Administration Server. Standalone colocated agents can be installed on any server with a Java Virtual Machine installed, but require a connection to the WebLogic Administration Server. This type of agent is more appropriate when you need to use a resource that is local to one of your data servers but you want to centralize management of all applications in an enterprise application server.
-
Java EE Agent
A Java EE agent is deployed as a web application in a Java EE application server, for example, Oracle WebLogic Server. The Java EE agent can benefit from all the features of the application server (for example, JDBC data sources or clustering for Oracle WebLogic Server). This type of agent is more appropriate when there is a need for centralizing the deployment and management of all applications in an enterprise application server, or when you have requirements for high availability.
These agents are multi-threaded java programs that support load balancing and can be distributed across the information system. This agent holds its own execution schedule which can be defined in Oracle Data Integrator, and can also be called from an external scheduler. It can also be invoked from a Java API or a web service. See "Setting Up a Topology" in Administering Oracle Data Integrator more information on how to create and manage agents.
Oracle Data Integrator Console
Business users (as well as developers, administrators and operators), can have read access to the repository, perform topology configuration and production operations through a web based UI called Oracle Data Integrator Console. This web application can be deployed in a Java EE application server such as Oracle WebLogic.
To manage and monitor the Java EE and Standalone Agents as well as the ODI Console, Oracle Data Integrator provides a plug-in that integrates with Oracle Enterprise Manager Cloud Control as well as Oracle Fusion Middleware Control Console.
ODI Domains
An ODI domain contains the Oracle Data Integrator components that can be managed using Oracle Enterprise Manager Cloud Control (EMCC). An ODI domain contains:
-
Several Oracle Data Integrator Console applications. An Oracle Data Integrator Console application is used to browse master and work repositories.
-
Several Run-Time Agents attached to the Master Repositories. These agents must be declared in the Master Repositories to appear in the domain. These agents may be Standalone Agents or Java EE Agents. See "Setting Up a Topology" in Administering Oracle Data Integrator for information about how to declare Agents in the Master Repositories.
In EMCC, the Master Repositories and Agent pages display both application metrics and information about the Master and Work Repositories. You can also navigate to Oracle Data Integrator Console from these pages, for example to view the details of a session. In order to browse Oracle Data Integrator Console in EMCC, the connections to the Work and Master repositories must be declared in Oracle Data Integrator Console. See Installing and Configuring Oracle Data Integrator for more information.
Materialized Client Libraries for SDK APIs
The materialized client libraries enable usage of SDK APIs from a non Oracle Home Environment.
The following three materialized client libraries are located in <OH>/odi/modules/clients directory:
-
oracle.odi.common.clientLib.jar -
oracle.odi.tp.clientLib.jar -
oracle.odi.sdk.clientLib.jar
Note:
These libraries are available only in Enterprise installation.To use SDK APIs from a non Oracle Home Environment, include the following in the classpath:
-
All three materialized client libraries mentioned above.
-
JDBC driver for the database on which the ODI Repository is installed.
After the libraries and JDBC driver are included in the classpath, you can create an OdiInstance and invoke the SDK APIs.
See also, see Java API Reference for Oracle Data Integrator.