2 Understanding Oracle Data Integrator Concepts
This chapter provides an introduction to the main concepts of Oracle Data Integrator.
This chapter includes the following topics:
Introduction to Declarative Design
To design an integration process with conventional ETL systems, a developer needs to design each step of the process: Consider, for example, a common case in which sales figures must be summed over time for different customer age groups. The sales data comes from a sales management database, and age groups are described in an age distribution file. In order to combine these sources then insert and update appropriate records in the customer statistics systems, you must design each step, which includes:
-
Load the customer sales data in the engine
-
Load the age distribution file in the engine
-
Perform a lookup between the customer sales data and the age distribution data
-
Aggregate the customer sales grouped by age distribution
-
Load the target sales statistics data into the engine
-
Determine what needs to be inserted or updated by comparing aggregated information with the data from the statistics system
-
Insert new records into the target
-
Update existing records into the target
This method requires specialized skills, depending on the steps that need to be designed. It also requires significant efforts in development, because even repetitive succession of tasks, such as managing inserts/updates in a target, need to be developed into each task. Finally, with this method, maintenance requires significant effort. Changing the integration process requires a clear understanding of what the process does as well as the knowledge of how it is done. With the conventional ETL method of design, the logical and technical aspects of the integration are intertwined. Declarative Design is a design method that focuses on "What" to do (the Declarative Rules) rather than "How" to do it (the Process). In our example, "What" the process does is:
-
Relate the customer age from the sales application to the age groups from the statistical file
-
Aggregate customer sales by age groups to load sales statistics
"How" this is done, that is the underlying technical aspects or technical strategies for performing this integration task – such as creating temporary data structures or calling loaders – is clearly separated from the declarative rules.
Declarative Design in Oracle Data Integrator uses the well known relational paradigm to declare in the form of a mapping the declarative rules for a data integration task, which includes designation of sources, targets, and transformations.
Declarative rules often apply to metadata to transform data and are usually described in natural language by business users. In a typical data integration project (such as a Data Warehouse project), these rules are defined during the specification phase in documents written by business analysts in conjunction with project managers. They can very often be implemented using SQL expressions, provided that the metadata they refer to is known and qualified in a metadata repository.
Declarative rules are implemented using Mappings, which connect sources to targets through a flow of components such as Join, Filter, Aggregate, Set, Split, and so on.
Table 2-1 gives examples of declarative rules.
Table 2-1 Examples of declarative rules
| Declarative Rule | Type | SQL Expression |
|---|---|---|
|
Sum of all amounts or items sold during October 2005 multiplied by the item price |
Aggregate |
SUM( CASE WHEN SALES.YEARMONTH=200510 THEN SALES.AMOUNT*PRODUCT.ITEM_PRICE ELSE 0 END ) |
|
Products that start with 'CPU' and that belong to the hardware category |
Filter |
Upper(PRODUCT.PRODUCT_NAME)like 'CPU%' And PRODUCT.CATEGORY = 'HARDWARE' |
|
Customers with their orders and order lines |
Join |
CUSTOMER.CUSTOMER_ID = ORDER.CUSTOMER_ID And ORDER.ORDER_ID = ORDER_LINE.ORDER_ID |
|
Reject duplicate customer names |
Unique Key Constraint |
Unique key (CUSTOMER_NAME) |
|
Reject orders with a link to an non-existent customer |
Reference Constraint |
Foreign key on ORDERS(CUSTOMER_ID) references CUSTOMER(CUSTOMER_ID) |
Introduction to Knowledge Modules
Knowledge Modules (KM) implement "how" the integration processes occur. Each Knowledge Module type refers to a specific integration task:
-
Reverse-engineering metadata from the heterogeneous systems for Oracle Data Integrator (RKM). See "Creating and Using Data Models and Datastores" in Developing Integration Projects with Oracle Data Integrator for more information on how to use the RKM.
-
Handling Changed Data Capture (CDC) on a given system (JKM). See "Using Journalizing" in Developing Integration Projects with Oracle Data Integrator for more information on how to use the Journalizing Knowledge Modules.
-
Loading data from one system to another, using system-optimized methods (LKM). These KMs are used in mappings. See "Creating and Using Mappings" in Developing Integration Projects with Oracle Data Integrator for more information on how to use the Loading Knowledge Modules.
-
Integrating data in a target system, using specific strategies (insert/update, slowly changing dimensions) (IKM). These KMs are used in mappings. See "Creating and Using Mappings" in Developing Integration Projects with Oracle Data Integrator for more information on how to use the Integration Knowledge Modules.
-
Controlling Data Integrity on the data flow (CKM). These KMs are used in data model's static check and mappings flow checks. See "Creating and Using Data Models and Datastores" and "Creating and Using Mappings" in Developing Integration Projects with Oracle Data Integrator for more information on how to use the Check Knowledge Modules.
-
Exposing data in the form of web services (SKM). See "Creating and Using Data Services" in Administering Oracle Data Integrator for more information on how to use the Service Knowledge Modules.
A Knowledge Module is a code template for a given integration task. This code is independent of the Declarative Rules that need to be processed. At design-time, a developer creates the Declarative Rules describing integration processes. These Declarative Rules are merged with the Knowledge Module to generate code ready for runtime. At runtime, Oracle Data Integrator sends this code for execution to the source and target systems it leverages in the E-LT architecture for running the process.
Knowledge Modules cover a wide range of technologies and techniques. Knowledge Modules provide additional flexibility by giving users access to the most-appropriate or finely tuned solution for a specific task in a given situation. For example, to transfer data from one DBMS to another, a developer can use any of several methods depending on the situation:
-
The DBMS loaders (Oracle's SQL*Loader, Microsoft SQL Server's BCP, Teradata TPump) can dump data from the source engine to a file then load this file to the target engine
-
The database link features (Oracle Database Links, Microsoft SQL Server's Linked Servers) can transfer data directly between servers
These technical strategies amongst others correspond to Knowledge Modules tuned to exploit native capabilities of given platforms.
Knowledge modules are also fully extensible. Their code is open and can be edited through a graphical user interface by technical experts willing to implement new integration methods or best practices (for example, for higher performance or to comply with regulations and corporate standards). Without having the skill of the technical experts, developers can use these custom Knowledge Modules in the integration processes.
For more information on Knowledge Modules, see the Connectivity and Modules Guide for Oracle Data Integrator and the Knowledge Module Developer's Guide for Oracle Data Integrator.
Introduction to Mappings
A mapping connects sources to targets through a flow of components such as Join, Filter, Aggregate, Set, Split, and so on.
A mapping also references the Knowledge Modules (code templates) that will be used to generate the integration process.
Datastores
A datastore is a data structure that can be used as a source or a target in a mapping. It can be:
-
a table stored in a relational database
-
a Hive table in a Hadoop cluster
-
an ASCII or EBCDIC file (delimited, or fixed length)
-
a node from a XML file
-
a JMS topic or queue from a Message Oriented Middleware
-
a node from a enterprise directory
-
an API that returns data in the form of an array of records
Regardless of the underlying technology, all data sources appear in Oracle Data Integrator in the form of datastores that can be manipulated and integrated in the same way. The datastores are grouped into data models. These models contain all the declarative rules –metadata - attached to datastores such as constraints.
Declarative Rules
The declarative rules that make up a mapping can be expressed in human language, as shown in the following example: Data is coming from two Microsoft SQL Server tables (ORDERS joined to LINES) and is combined with data from the CORRECTIONS file. The target SALES Oracle table must match some constraints such as the uniqueness of the ID column and valid reference to the SALES_REP table.
Data must be transformed and aggregated according to some mappings expressed in human language as shown in Figure 2-1.
Figure 2-1 Example of a business problem
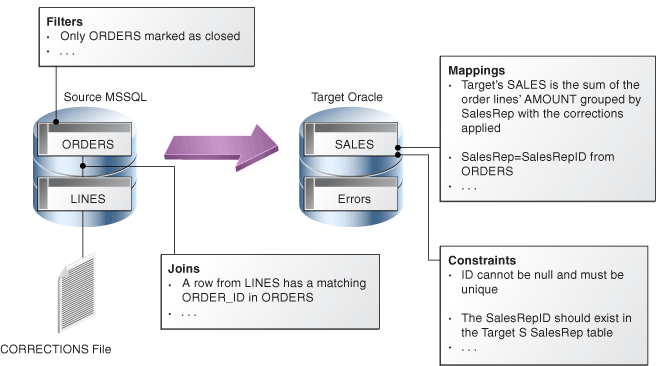
Description of ''Figure 2-1 Example of a business problem''
Translating these business rules from natural language to SQL expressions is usually straightforward. In our example, the rules that appear in Figure 2-1 could be translated as shown in Table 2-2.
Table 2-2 Business rules translated
| Type | Rule | SQL Expression/Constraint |
|---|---|---|
|
Filter |
Only ORDERS marked as closed |
ORDERS.STATUS = 'CLOSED' |
|
Join |
A row from LINES has a matching ORDER_ID in ORDERS |
ORDERS.ORDER_ID = LINES.ORDER_ID |
|
Aggregate |
Target's SALES is the sum of the order lines' AMOUNT grouped by sales rep, with the corrections applied |
SUM(LINES.AMOUNT + CORRECTIONS.VALUE) |
|
Mapping |
Sales Rep = Sales Rep ID from ORDERS |
ORDERS.SALES_REP_ID |
|
Constraint |
ID must not be null |
ID is set to |
|
Constraint |
ID must be unique |
A unique key is added to the data model with (ID) as set of columns |
|
Constraint |
The Sales Rep ID should exist in the Target SalesRep table |
A reference (foreign key) is added in the data model on |
Implementing this business problem using Oracle Data Integrator is a very easy and straightforward exercise. It is done by simply translating the business rules into a mapping.
Data Flow
Business rules defined in the mapping are automatically converted into a data flow that will carry out the joins, filters, mappings, and constraints from source data to target tables.
By default, Oracle Data Integrator will use the Target RDBMS as a staging area for loading source data into temporary tables and applying all the required mappings, staging filters, joins and constraints. The staging area is a separate area in the RDBMS (a user/database) where Oracle Data Integrator creates its temporary objects and executes some of the rules (mapping, joins, final filters, aggregations etc.). When performing the operations this way, Oracle Data Integrator uses an E-LT strategy as it first extracts and loads the temporary tables and then finishes the transformations in the target RDBMS.
In some particular cases, when source volumes are small (less than 500,000 records), this staging area can be located in memory in Oracle Data Integrator's in-memory relational database – In-Memory Engine. Oracle Data Integrator would then behave like a traditional ETL tool.
Figure 2-2 shows the data flow automatically generated by Oracle Data Integrator to load the final SALES table. The business rules will be transformed into code by the Knowledge Modules (KM). The code produced will generate several steps. Some of these steps will extract and load the data from the sources to the staging area (Loading Knowledge Modules - LKM). Others will transform and integrate the data from the staging area to the target table (Integration Knowledge Module - IKM). To ensure data quality, the Check Knowledge Module (CKM) will apply the user defined constraints to the staging data to isolate erroneous records in the Errors table.
Figure 2-2 Oracle Data Integrator Knowledge Modules in action
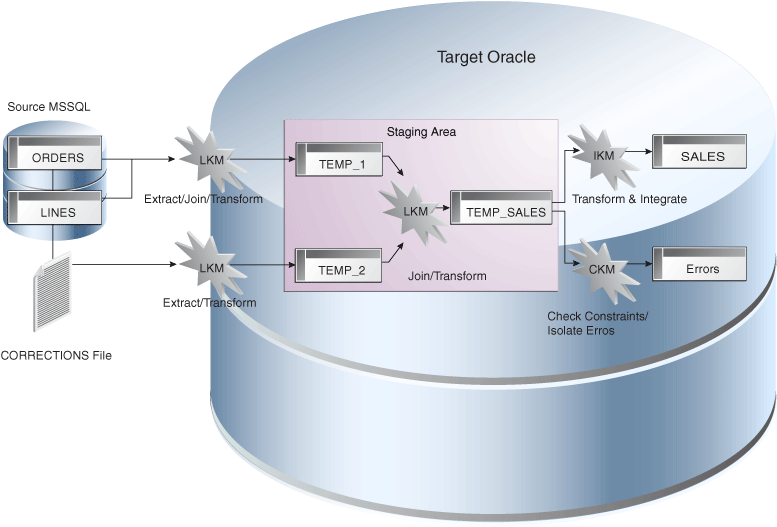
Description of ''Figure 2-2 Oracle Data Integrator Knowledge Modules in action''
Oracle Data Integrator Knowledge Modules contain the actual code that will be executed by the various servers of the infrastructure. Some of the code contained in the Knowledge Modules is generic. It makes calls to the Oracle Data Integrator Substitution API that will be bound at run-time to the business-rules and generates the final code that will be executed.
At design time, declarative rules are defined in the mappings and Knowledge Modules are only selected and configured.
At run-time, code is generated and every Oracle Data Integrator API call in the Knowledge Modules (enclosed by <% and %>) is replaced with its corresponding object name or expression, with respect to the metadata provided in the Repository. The generated code is orchestrated by Oracle Data Integrator run-time component - the Agent – on the source and target systems to make them perform the processing, as defined in the E-LT approach.
See "Creating and Using Mappings" in Developing Integration Projects with Oracle Data Integrator for more information on how to work with mappings.