Proteger Bancos de Dados Críticos contra Falhas e Desastres Usando o Autonomous Data Guard
O recurso Autonomous Data Guard permite que você mantenha seus bancos de dados de produção críticos disponíveis para aplicativos de missão crítica, apesar de falhas, desastres, erros humanos ou corrompimento de dados. Esse tipo de recurso é frequentemente chamado recuperação de desastres.
No Autonomous AI Database on Dedicated Exadata Infrastructure, você configura e gerencia Autonomous Data Guard no nível do Autonomous Container Database.
Sobre o Autonomous Data Guard
O Autonomous Data Guard cria e mantém duas cópias completamente separadas do seu banco: um banco principal ao qual seus aplicativos se conectam e usam, e um banco de dados stand-by que é uma cópia síncrona do banco. Em seguida, caso o banco do dados principal se torne indisponível por qualquer motivo, o Autonomous Data Guard poderá converter o banco do dados stand-by para o banco do dados principal e, portanto, começará a fornecer serviços aos seus aplicativos.
Os bancos de dados principal e stand-by são frequentemente chamados bancos de dados de pares entre si. Você pode ter até dois bancos de dados stand-by por Autonomous Container Database.
Observação: os aplicativos devem ser configurados para usar o TAC (Transparent Application Continuity, Continuidade transparente de aplicativos) a fim de obter todos os benefícios dos recursos do Autonomous Data Guard.
O diagrama que se segue mostra como cada base de dados stand-by é mantida sincronizada com a base de dados principal.
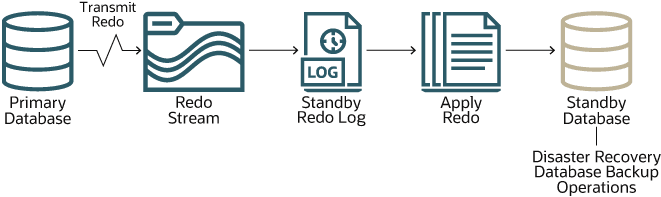
Descrição da ilustração autônomo-data-guard.png
As alterações feitas no banco de dados principal são registradas no redo log do banco de dados principal. O Autonomous Data Guard transmite esses registros de redo como um stream pela rede para o redo log do banco de dados stand-by. Em seguida, o banco de dados stand-by aplica esses registros ao banco de dados stand-by. Dessa forma, o banco de dados stand-by é mantido sincronizado com o banco de dados principal.
A sincronização é quase instantânea, mas, como o processo descrito implica, há duas operações que consomem tempo: transportar os registros de redo para o banco de dados stand-by e aplicar os registros de redo ao banco de dados stand-by. A primeira delas é chamada de lag de transporte e a outra é chamada de lag de aplicação. Você pode exibir valores de atraso atuais de um Autonomous AI Database na página Detalhes do banco de dados em Autonomous Data Guard. Você pode exibir valores de atraso atuais em todos os Autonomous AI Databases em um banco de dados contêiner na página Detalhes do banco de dados contêiner de maneira semelhante.
Observação: com vários bancos de dados stand-by, o Transporte de Redo em cascata não é suportado.
Configurando o Autonomous Data Guard
No Autonomous AI Database on Dedicated Exadata Infrastructure, você configura e gerencia o Autonomous Data Guard no nível do Autonomous Container Database (ACD). Você pode ativar o Autonomous Data Guard para ACDs já provisionados e adicionar até dois ACDs stand-by em sua página Detalhes usando a console do Oracle Cloud Infrastructure. Consulte Ativar o Autonomous Data Guard em um Autonomous Container Database e Adicionar um Segundo Autonomous Container Database Stand-by para obter instruções.
-
Agora você pode criar e gerenciar o Autonomous Data Guard entre um ACD no Oracle Cloud Infrastructure (OCI) e um ACD no Amazon Web Services (AWS).
-
Você pode adicionar um ACD stand-by da região da AWS ao ACD já provisionado na região do OCI. Como alternativa, você pode adicionar um ACD stand-by na região do OCI a um ACD já provisionado na região da AWS.
Observe o seguinte antes de configurar o Autonomous Data Guard:
-
Os Autonomous AI Databases implantados no Exadata Cloud@Customer devem ter a Porta 1522 aberta para permitir o tráfego TCP entre o banco de dados principal e o banco de dados stand-by em uma configuração do Autonomous Data Guard.
-
Não é possível ativar o Autonomous Data Guard em um ACD com uma execução de manutenção ativa programada nos próximos três dias. Você pode executar a manutenção ativa primeiro e, em seguida, ativar o Autonomous Data Guard ou alterar a programação de execução da manutenção para que ela não comece até que o segundo banco de dados stand-by seja adicionado.
-
A adição de um segundo banco de dados stand-by requer uma reinicialização incremental automática para o primeiro banco de dados stand-by. O banco de dados principal não é afetado por esta reinicialização incremental.
Configurar o Autonomous Data Guard com chaves gerenciadas pelo cliente
No Autonomous AI Database on Dedicated Exadata Infrastructure, você pode configurar e gerenciar o Autonomous Data Guard com chaves gerenciadas pelo cliente no nível do ACD (Autonomous Container Database). Você pode ativar o Autonomous Data Guard para ACDs já provisionados e adicionar até dois ACDs stand-by na respectiva página Detalhes usando a console do Oracle Cloud Infrastructure. Consulte Ativar o Autonomous Data Guard em um Autonomous Container Database e Adicionar um Segundo Autonomous Container Database Stand-by para obter instruções.
Observe o seguinte antes de configurar o Autonomous Data Guard com chaves gerenciadas pelo cliente:
-
Se você estiver usando o Oracle Cloud Infrastructure Key Management System (OCI KMS) e quiser ativar o Autonomous Data Guard entre Regiões:
-
Primeiro, você precisa replicar o vault do OCI para a região em que deseja adicionar o banco de dados stand-by. Consulte Replicando Vaults e Chaves para obter mais detalhes.
-
Você só pode ter os bancos de dados principal e stand-by em no máximo 2 regiões. Ou seja, se você quiser adicionar um segundo stand-by e já tiver usado a região cruzada para o primeiro stand-by, o segundo deverá estar na região principal ou na primeira região stand-by.
Observação: Os vaults virtuais criados antes da introdução do recurso de replicação de vault entre regiões não podem ser replicados entre regiões. Crie um novo vault e novas chaves se você tiver um vault que precise replicar em outra região e a replicação não for suportada para esse vault. No entanto, todos os vaults privados suportam replicação entre regiões. Consulte Replicação entre regiões do vault virtual para obter detalhes.
-
-
Se você estiver usando o Oracle Key Vault (OKV) e quiser ativar o Autonomous Data Guard entre Regiões, certifique-se de ter adicionado endereços IP de Conexão ao Cluster do OKV no Armazenamento de Chaves.
-
Se você estiver usando o AWS Key Management System (AWS KMS) e quiser ativar o Autonomous Data Guard entre Regiões:
- Você deve ter uma chave AWS Multi-region registrada na região principal. Você só poderá selecionar o tipo de chave da AWS como Multirregião quando criá-la e ela não poderá ser alterada posteriormente.
- Defina as políticas necessárias na região replicada, pois elas não são replicadas automaticamente.
- A chave Multi-região do AWS KMS deve ser replicada da região de origem para a região de destino no console da AWS. Consulte Replicar chaves do AWS KMS no console da AWS para obter detalhes.
- A chave Multi-região do AWS KMS deve ser replicada da região principal para a região de destino no console da OCI. Consulte Replicar chaves do AWS KMS no console da OCI para obter mais detalhes.
Transições e Operações de Atribuição
Após a criação de um ACD (Autonomous Container Database), você poderá alterar a atribuição dos bancos de dados pares usando uma operação de switchover ou failover. Se o failover automático estiver ativado, o Autonomous Data Guard executará automaticamente uma operação do failover sempre que o banco de dados principal ficar indisponível, por qualquer motivo.
Um switchover é uma reversão de atribuição entre o principal e seu banco de dados stand-by. Um switchover garante que não haja perda de dados. Durante um switchover, o banco de dados principal faz a transição para a atribuição de stand-by, e o banco de dados stand-by faz a transição para a atribuição principal. Para executar uma operação de switchover, consulte Alternar Atribuições em uma Configuração do Autonomous Data Guard.
Um failover ocorre quando o banco do dados principal está indisponível. O failover resulta em uma transição do banco de dados stand-by para a atribuição principal. Se o failover automático não estiver ativado, você poderá executar um failover manual conforme descrito em Fazer Failover para o Stand-by em uma Configuração do Autonomous Data Guard.
A disponibilidade e o status do banco de dados após uma operação de failover são caracterizados por dois objetivos de recuperação:
-
RTO (Recovery Time Objective). O RTO é o tempo máximo necessário para que o banco de dados fique disponível para os aplicativos após um failover e está relacionado, até certo ponto, ao atraso para aplicação no momento da falha. Para o Autonomous Data Guard, o RTO é de segundos até dois minutos.
-
RPO (Recovery Point Objective). O RPO é a duração máxima da perda de dados potencial do banco de dados principal com falha e está relacionado, até certo ponto, ao atraso no transporte no momento da falha. Para o Autonomous Data Guard, o RPO é quase zero.
Após um failover, o principal com falha se torna um Stand-by Desativado e permanece indisponível para qualquer conexão de banco de dados. Você pode reativá-lo e transformá-lo em um stand-by íntegro executando uma operação de reintegração. Depois que um principal com falha tiver sido reintegrado como stand-by, você poderá executar um switchover para retorná-lo à sua atribuição principal original. Para executar uma operação de reintegração, consulte Reintegrar o Stand-by Desativado em uma Configuração do Autonomous Data Guard.
Failover Automático ou Failover de Inicialização Rápida
Com o failover automático, sempre que o ACD principal se tornar indisponível por causa de uma falha de região, de uma falha de domínio da disponibilidade, de uma falha da Infraestrutura Exadata ou do AVMC (Cluster de VMs do Autonomous Exadata) ou da falha do próprio ACD, ele fará o failover automaticamente para o ACD stand-by. Isso também é conhecido como Failover de Inicialização Rápida.
Não é possível ativar o failover automático ao configurar o Autonomous Data Guard em um ACD. O failover automático só pode ser ativado ou desativado durante a atualização das definições do Autonomous Data Guard na página Detalhes do ACD.
Observação: O failover automático não pode ser ativado para Autonomous AI Databases implantados no Exadata Cloud@Customer com configuração do Autonomous Data Guard entre regiões.
Não é possível adicionar um segundo ACD standby com failover automático ativado para o primeiro ACD standby. Portanto, desative o failover automático usando Atualizar Definições do Autonomous Data Guard antes de criar o segundo ACD stand-by e reative-o posteriormente, se necessário.
Os modos de desempenho máximo e de proteção de disponibilidade máxima suportam failover automático:
-
No modo Disponibilidade máxima, o failover automático garante zero perda de dados.
-
No modo Desempenho máximo, o failover automático garante que o banco de dados stand-by não fique atrás do banco de dados principal além do valor especificado para o limite de atraso de failover do Fast Start. Por padrão, o limite de lag de failover para Início Rápido é definido como 30 segundos e só se aplica ao modo de desempenho Máximo. Nesse caso, o failover automático só é possível quando o lag de aplicação (potencial perda de dados) do stand-by não excede o limite de lag configurado. Você pode modificar o limite de atraso de failover do Fast Start para qualquer valor entre 5 e 3600.
Consulte Atualizar Definições do Autonomous Data Guard para obter mais detalhes.
Além de falhas de hardware, interrupções do domínio de disponibilidade e interrupções regionais, há mais algumas condições de integridade do banco de dados que podem acionar um Failover de Inicialização Rápida, conforme listado abaixo:
| Condição de Integridade do Banco de Dados | Descrição |
|---|---|
| Arquivo de Controle Corrompido | O arquivo de controle está permanentemente danificado devido a uma falha no disco. |
| Dicionário Corrompido | Corrompimento do dicionário de um banco de dados crítico. No momento, esse estado só pode ser detectado quando o banco de dados está aberto. |
| Erros de Gravação do Arquivo de Dados | Erros de gravação são encontrados em qualquer arquivo de dados, incluindo arquivos temporários, arquivos de dados do sistema e arquivos de undo. |
Como resultado do failover automático, a atribuição do banco de dados principal com falha torna-se Stand-by Desativado e, após um breve período, o banco de dados stand-by assume a atribuição do banco de dados principal. Após a conclusão do failover automático, uma mensagem é exibida na página de detalhes do banco de dados stand-by desativado, informando que ocorreu o failover.
Depois que o serviço resolver os antigos problemas do Autonomous Container Database principal, você poderá executar um switchover manual para retornar os dois bancos de dados às atribuições iniciais. Depois de provisionar o banco de dados stand-by, você poderá executar várias tarefas de gerenciamento relacionadas ao banco de dados stand-by, incluindo:
-
Fazer switchover manualmente de um banco de dados principal para um banco de dados stand-by.
-
Fazer failover manualmente de um banco de dados principal para um banco de dados stand-by.
-
Restabelecer um banco de dados principal para a atribuição stand-by após o failover.
-
Encerrando um banco de dados stand-by.
Em uma configuração do Autonomous Data Guard com vários bancos de dados stand-by e failover automático:
-
Failovers manuais exigem que você restabeleça manualmente o banco de dados principal original, que se torna o novo banco de dados stand-by.
-
Sempre que ocorre um failover automático, o Autonomous AI Database na Infraestrutura Dedicada do Exadata tenta restabelecer o principal antigo como stand-by. No entanto, se essa tentativa falhar, ela deverá ser reintegrada manualmente.
Banco de Dados Stand-by de Snapshot
Um banco de dados stand-by snapshot é um banco de dados stand-by totalmente atualizável criado por meio da conversão de um ACD (Autonomous Container Database) stand-by para um ACD stand-by snapshot. Consulte Converter Stand-by Físico em Stand-by Snapshot para obter instruções passo a passo.
Um banco de dados stand-by snapshot recebe e arquiva, mas não se aplica, dados de redo do banco de dados principal. No entanto, ele aumenta seu RTO (Recovery Time Objective) porque as alterações em tempo real do banco de dados principal não são aplicadas.
O recurso stand-by snapshot suporta vários casos de uso, mas aqui estão os principais casos de uso:
-
Conecte as instâncias de aplicativos principal e stand-by aos bancos de dados principal e stand-by no modo de leitura/gravação para executar configurações iniciais.
-
Aplique patch no banco de dados stand-by snapshot primeiro e teste com sua instância de aplicativo stand-by para confirmar a estabilidade do patch. Isso requer a conversão do stand-by físico em um stand-by snapshot primeiro, para que o patch possa ser aplicado no stand-by snapshot.
Observação: Você não pode converter um Autonomous Container Database stand-by físico em um stand-by snapshot com failover automático ativado.
Ao converter em um stand-by snapshot, você pode ativar novos serviços de banco de dados que estão ativos somente no modo snapshot ou usar o mesmo conjunto de serviços usados com o banco de dados principal. No entanto, a ativação de serviços de banco de dados principal no banco de dados stand-by snapshot pode resultar em solicitações de conexão stand-by snapshot encaminhadas para o banco de dados principal ou vice-versa, se você usar strings de conexão de banco de dados incorretas. Portanto, você deve ter cuidado ao usar a string de conexão apropriada ao estabelecer conexão com seu banco de dados principal e stand-by snapshot.
Observação: Quando você cria novos serviços com stand-by snapshot, as wallets de todos os Autonomous AI Databases no ACD stand-by snapshot são atualizadas. Para acessar o banco de dados, recarregue as wallets dos Autonomous AI Databases stand-by e use strings de conexão stand-by snapshot.
Você pode converter o ACD stand-by snapshot de volta para um ACD stand-by físico do OCI (Oracle Cloud Infrastructure) manualmente. Consulte Converter Snapshot Stand-by em Stand-by Físico para obter instruções detalhadas. Se um stand-by snapshot não for convertido manualmente em um stand-by físico, ele será convertido automaticamente de volta em um stand-by físico após 7 dias da sua criação. Em qualquer caso, a conversão do stand-by snapshot de volta para um stand-by físico descartará todas as atualizações locais para seus bancos de dados stand-by snapshot e aplicará os dados de redo recebidos dos bancos de dados principais.
Quando um ACD stand-by está no modo stand-by snapshot, você não pode executar as seguintes operações no ACD principal:
-
Criar ou encerrar Autonomous AI Databases
-
Amplie ou reduza os Autonomous AI Databases
-
Restaurar Autonomous AI Databases
Se a situação exigir, você poderá failover manualmente para um stand-by snapshot do banco de dados principal. Nesse caso, o failover converte seu banco de dados stand-by snapshot em um banco de dados stand-by físico descartando todas as atualizações locais feitas no seu stand-by snapshot e aplicando dados do banco de dados principal. Consulte Fazer Failover para o Stand-by em uma Configuração do Autonomous Data Guard para obter instruções passo a passo.
Não é permitido um switchover entre o banco de dados principal e seu banco de dados stand-by snapshot. Você deve converter manualmente seu stand-by snapshot em um stand-by físico antes de tentar um switchover.
Acessando Bancos de Dados Stand-by de Aplicativos Cliente
Em uma configuração do Autonomous Data Guard, os aplicativos clientes normalmente se conectam e executam operações no banco de dados principal.
Estabelecendo Conexão com o Banco de dados Stand-by Físico
Além dessa conectividade normal, o Autonomous Data Guard fornece a opção para conectar aplicativos cliente que executam operações somente leitura no banco do dados stand-by. Para aproveitar essa opção, os aplicativos cliente se conectam ao banco de dados usando nomes do serviço de banco de dados que incluem "_RO" (para "somente leitura"), conforme descrito em Nomes de Serviço de Banco de dados Predefinidos para o Autonomous AI Database.
Estabelecendo Conexão com o Banco de dados Snapshot Stand-by
O Autonomous Data Guard também permite que você conecte aplicativos clientes que executam operações de leitura/gravação ao banco de dados stand-by snapshot. Essas operações são locais para o banco de dados stand-by snapshot e não modificam seu banco de dados principal. Para estabelecer conexão com um banco de dados stand-by snapshot, os aplicativos clientes podem usar nomes de serviço de banco de dados que incluem "_SS" (para "stand-by de snapshot"), conforme descrito em Nomes de Serviço de Banco de Dados Predefinidos para Autonomous AI Databases.
Observação: Quando o banco de dados stand-by está no modo stand-by snapshot, todos os serviços de banco de dados que incluem serviços "_RO" em seu nome estão inativos e não podem ser usados para conexões.
Monitorando Tempos de Espera
À medida que os bancos que usam Autonomous Data Guard estiverem em execução, você poderá monitorar o atraso de transporte e aplicar tempos de atraso na página Detalhes do banco (ou do banco) de dados contêiner escolhendo Grupos do Autonomous Data Guard. Você também pode usar o console da OCI ou APIs de observabilidade para monitorar o atraso de transporte e configurar alarmes e notificações. Consulte Observabilidade do Banco de Dados com Métricas do Autonomous AI Database para obter mais informações.
Você deve esperar pequenas flutuações ao longo do tempo à medida que a carga de trabalho em seu banco de dados diminui e flui. No entanto, se você notar uma tendência crescente no tempo de espera, poderá executar estas ações para resolver a situação:
-
Tendência de Aumento no Atraso da Aplicação. Uma tendência crescente no atraso para aplicação indica que o banco de dados stand-by não tem capacidade suficiente para acompanhar os registros de redo provenientes do banco de dados principal. Para resolver essa situação, expanda as OCPUs do banco de dados, conforme descrito em Adicionar Recursos de CPU ou Armazenamento a um Autonomous AI Database Dedicado.
-
Tendência de Aumento no Atraso do Transporte. Uma tendência crescente de atraso no transporte indica um problema de desempenho da rede. A equipe de operações do Oracle Cloud monitora constantemente o desempenho da rede, para que você consiga ver a situação se resolver sem adotar nenhuma medida. No entanto, se quiser, você poderá levar a situação ao conhecimento da equipe de operações gerando uma solicitação de serviço, conforme descrito em Criar uma Solicitação de Serviço no My Oracle Support.
Opções de Configuração do Autonomous Data Guard
Ao configurar o Autonomous Data Guard, especifique em quais recursos do Exadata Infrastructure e do Cluster da VM do Autonomous Exadata você deseja criar o banco de dados stand-by e especifique o modo da proteção dos dados que deseja usar.
Você tem as seguintes opções ao especificar quais recursos do Exadata Infrastructure e do Cluster da VM do Autonomous Exadata usar para o stand-by:
-
Em outra região do Exadata Infrastructure e do Cluster de VMs Autônomas do Exadata do Banco de Dados Principal:
Essa opção oferece o mais alto nível de proteção contra desastres, incluindo uma perda catastrófica da conectividade de rede externa ou de energia para toda uma região.
Para fazer o melhor uso dessa proteção entre regiões, sua camada de aplicativos também precisa ser configurada para oferecer suporte à proteção entre regiões. Portanto, a Oracle recomenda que você escolha essa opção se sua camada de aplicativos já estiver configurada dessa forma ou se estiver disposto a reconfigurá-la para oferecer suporte à proteção entre regiões.
Se você optar por localizar o banco de dados stand-by em outra região, a Oracle recomenda que você use o modo de proteção Desempenho Máximo.
-
Em outro domínio de disponibilidade (AD) do Exadata Infrastructure e do Cluster da VM do Autonomous Exadata do bancode dados principal:
Essa escolha fornece um alto nível de proteção contra desastres, incluindo uma perda catastrófica de conectividade ou energia de rede externa para um nome de domínio de disponibilidade dentro de uma região.
Essa opção oferece um bom equilíbrio entre a proteção de dados e a simplicidade da configuração em sua camada de aplicativos.
Se você optar por localizar o banco de dados stand-by em outro domínio de disponibilidade, a Oracle recomenda que você use o Modo de proteção Disponibilidade Máxima.
-
No mesmo domínio de disponibilidade (AD) do Exadata Infrastructure e do Cluster de VMs Autônomas do Exadata do banco da dados principal:
Esta opção fornece um nível mínimo de proteção contra desastres, e a Oracle recomenda que você não a escolha.
Se os recursos Exadata Infrastructure e Autonomous Exadata VM Cluster do bancode dados principal estiverem em uma região que tenha apenas um domínio da disponibilidade, a Oracle recomenda que você use a opção "em outra região".
Se você optar por localizar o banco de dados stand-by no mesmo domínio da disponibilidade, a Oracle recomenda que você use o Modo de proteção Disponibilidade Máxima
-
Em outra tenancy do Exadata Infrastructure e do Cluster da VM Autônoma do Exadata do Banco de Dados Principal:
APLICA-SE A:
 Oracle Public Cloud somente
Oracle Public Cloud somenteEssa opção permite adicionar um banco de dados stand-by em uma tenancy diferente do banco de dados principal, permitindo que seu banco de dados faça failover ou switchover para esse banco de dados stand-by entre tenancies. Você também pode criar um stand-by snapshot na tenancy remota. Ter um banco de dados stand-by entre tenancies pode ser útil com a migração do banco de dados entre tenancies.
Bancos de dados stand-by entre tenancies:
-
Pode ser ativado com o modelo de computação ECPU ou OCPU. O banco de dados stand-by deve usar o mesmo modelo de computação do banco de dados principal.
-
Suporta failover automático. No entanto, o failover Automático não pode ser ativado para Autonomous AI Databases implantados no Exadata Cloud@Customer com configuração do Autonomous Data Guard entre regiões.
-
Não é possível adicionar usando a console do Oracle Cloud Infrastructure. Você só pode adicionar um banco de dados stand-by entre tenancies usando CLI ou API REST. Depois de adicionar o banco de dados stand-by, você poderá exibir o banco de dados stand-by entre tenancies, executar um failover ou switchover para o banco de dados stand-by entre tenancies na console do Oracle Cloud Infrastructure.
-
Sobre os Modos de Proteção
O Autonomous Data Guard fornece estes modos de proteção de dados:
-
Disponibilidade Máxima. Este modo de proteção fornece o mais alto nível de proteção de dados possível sem comprometer a disponibilidade do banco de dados principal.
O banco de Dados principal não confirma as transações até receber a confirmação de que os dados foram recebidos no stand-by (não que foram gravados em disco). Se o banco de dados principal não receber essa confirmação dentro de 30 segundos, ele funcionará como se estivesse no modo máximo de desempenho para preservar a disponibilidade de banco de dados principal até que receba novamente confirmações em tempo hábil.
Esse modo de proteção garante que não haja qualquer perda de dados, exceto no caso de determinadas falhas duplas, como falha de um banco de dados principal após falha do banco de dados stand-by.
-
Desempenho Máximo. Esse é o modo de proteção padrão. Ele fornece o mais alto nível de proteção de dados possível sem afetar o desempenho do banco de dados principal.
O banco de dados principal faz commit das transações assim que todos os dados de redo gerados por essas transações forem gravados em seu redo log on-line. Ele também envia dados de redo para o banco de dados stand-by, mas isso é feito de forma assíncrona com relação ao commit da transação; portanto, o desempenho do banco de dados principal não é afetado pelos atrasos na gravação dos dados de redo para o banco de dados stand-by.
Esse modo de proteção oferece um pouco menos proteção de dados do que o modo de disponibilidade máxima e tem impacto mínimo no desempenho do banco de dados principal.
Você pode alterar o modo de proteção em uma configuração do Autonomous Data Guard na console da Oracle Cloud Infrastructure (OCI). Consulte Atualizar Definições do Autonomous Data Guard para obter instruções passo a passo.
Para obter mais informações sobre modos de proteção no Oracle Data Guard (que são a base do recurso Autonomous Data Guard), consulte Modos de Proteção do Oracle Data Guard em Conceitos e Administração do Oracle Data Guard.
Melhores Práticas ao Configurar o Autonomous Data Guard
Embora o Autonomous AI Database permita criar até dois ACDs stand-by com o Autonomous Data Guard, você pode optar por usar um ou vários ACDs stand-by, dependendo do seu requisito. No entanto, para usar a opção de recuperação de desastres mais resiliente que um Autonomous AI Database oferece, você pode adicionar um ACD stand-by local e um ACD stand-by remoto ou entre regiões com disponibilidade máxima como modo de proteção de dados.
Vamos entender os benefícios deste projeto:
-
Stand-by Local:
-
O failover automático para um stand-by local na mesma região fornece isolamento de desastre local significativo e simplicidade de failover de aplicativo.
-
O valor comercial de um banco de dados stand-by local é visto em failover de perda de dados zero e tempo de inatividade do aplicativo reduzido para segundos.
-
Os aplicativos fazem failover de forma automática e transparente para o stand-by local, mantendo a mesma latência entre os servidores de aplicativos e o banco de dados. Isso é particularmente importante para aplicativos OLTP e de pacote porque uma maior latência pode afetar significativamente a taxa de transferência e o tempo geral de resposta do aplicativo.
-
-
Stand-by Remoto:
-
Se um desastre regional tornar os sistemas stand-by principal e local inacessíveis, o aplicativo e o banco de dados poderão fazer failover para o stand-by remoto.
-
Embora o tempo de inatividade do banco de dados ainda seja muito baixo quando ocorre um desastre regional, o tempo de inatividade do aplicativo pode ser maior devido à orquestração adicional necessária para operações de failover de DNS, aplicativo e banco de dados para a região secundária.
-
-
Disponibilidade Máxima:
-
Se o failover automático ou o failover de início rápido (FSFO) estiver ativado, sempre que o ACD principal ficar indisponível, o Autonomous Data Guard fará failover para o stand-by local sem perda de dados e sem alteração na latência do banco de dados no aplicativo.
-
Se o failover automático ou o failover de inicialização rápida (FSFO) estiver ativado, sempre que toda a região principal se tornar inacessível, o sistema passará por failover para o stand-by remoto com uma potencial perda de dados.
-
Como o Autonomous Data Guard Afeta as Operações de Gerenciamento Padrão
Em alguns casos, as operações de gerenciamento padrão executadas nos Autonomous Container Databases funcionam de forma diferente nos bancos de dados contêineres principal e stand-by em uma configuração do Autonomous Data Guard em comparação com os bancos de dados contêiner padrão. A lista a seguir descreve essas diferenças.
-
Alterar a programação de manutenção
A programação de manutenção de um banco de dados contêiner principal e seu stand-by estão vinculados: a manutenção no banco de dados stand-by é realizada alguns dias antes da manutenção no banco de dados principal. O padrão é 7 dias; você pode escolher de 1 a 7 dias ao criar o banco de dados contêiner principal ou posteriormente editando seus Detalhes de Manutenção.
-
Alterar o tipo de manutenção
O tipo de manutenção de um banco de dados contêiner principal e seu stand-by deve ser o mesmo. Você escolhe o tipo de manutenção para os bancos de dados principal e stand-by ao criar o banco de dados contêiner principal ou, posteriormente, editando seus Detalhes de Manutenção.
-
Desativar backups automáticos
Você não pode desativar backups automáticos ao provisionar um ACD (Autonomous Container Database) com o Autonomous Data Guard.
-
Gerenciar manutenção programada
Você pode gerenciar a manutenção programada de um banco de dados contêiner principal e seu stand-by separadamente. No entanto, como a manutenção dos dois está vinculada, você deve executar a manutenção programada no stand-by antes de executá-la no principal se optar por substituir o horário de manutenção programado.
-
Mover para outro compartimento
Você pode mover bancos de dados contêineres principal e stand-by para diferentes compartimentos de forma separada e independente, como se eles fossem bancos de dados contêiner padrão. No entanto, como acontece com os bancos de dados contêineres padrão, você deve ter muito cuidado ao mover um banco de dados contêiner para garantir que o banco de dados contêiner permaneça acessível aos grupos apropriados de usuários de nuvem.
-
Reiniciar
Você pode reiniciar bancos de dados contêineres principal e stand-by separadamente e de forma independente, como se eles fossem bancos de dados contêineres padrão.
-
Rotacionar a chave de criptografia
Você pode rotacionar as chaves de criptografia do ACD principal ou do banco de dados principal.
-
Encerrar
Você pode encerrar bancos de dados contêiner principais e stand-by separadamente. No entanto, as consequências de encerrar um banco de dados contêiner principal e encerrar um banco de dados contêiner stand-by diferem:
-
O encerramento de um banco de dados contêiner primário encerra o banco de dados contêiner primário e stand-by. Não é possível encerrar um banco dados contêiner principal que contenha Autonomous AI Databases.
-
O encerramento de um banco de dados container stand-by encerra o banco e o remove da configuração Autonomous Data Guard. Se ele tiver apenas um principal restante, a configuração do Autonomous Data Guard será removida, transformando o principal em um banco de dados contêiner stand-alone.
-
Guias Passo a Passo
Para obter orientação passo a passo sobre como gerenciar a configuração do Autonomous Data Guard em um Autonomous Container Database, consulte:
-
Ativar o Autonomous Data Guard em um Autonomous Container Database
-
Exibir o Status de uma Configuração do Autonomous Data Guard
-
Alternar Atribuições em uma Configuração do Autonomous Data Guard
-
Fazer Failover para o Stand-by em uma Configuração do Autonomous Data Guard
-
Reintegrar o Stand-by Desativado em uma Configuração do Autonomous Data Guard
Você também pode usar a API para exibir e gerenciar a configuração da Autonomous Data Guard. Para obter mais detalhes, consulte API para Gerenciar a Configuração do Autonomous Data Guard.