Usando o Oracle NoSQL Database Migrator
Saiba mais sobre o Oracle NoSQL Database Migrator e como usá-lo para migração de dados.
O Oracle NoSQL Database Migrator é uma ferramenta que permite migrar tabelas do Oracle NoSQL de uma origem de dados para outra. Essa ferramenta pode operar em tabelas no Oracle NoSQL Database Cloud Service, Oracle NoSQL Database on-premises e AWS S3. A ferramenta Migrator suporta vários formatos de dados e tipos de mídia física diferentes. Os formatos de dados suportados são JSON, Parquet, JSON formatado pelo MongoDB, JSON formatado pelo DynamoDB e arquivos CSV. Os tipos de mídia física suportados são arquivos, OCI Object Storage, Oracle NoSQL Database on-premises, Oracle NoSQL Database Cloud Service e AWS S3.
Este artigo tem os seguintes tópicos:
Visão geral
O Oracle NoSQL Database Migrator permite mover tabelas do Oracle NoSQL de uma origem de dados para outra, como o Oracle NoSQL Database on-premises ou na nuvem ou até mesmo um arquivo JSON simples.
Pode haver muitas situações que exigem a migração de tabelas do NoSQL de ou para um Oracle NoSQL Database. Por exemplo, uma equipe de desenvolvedores que aprimoram um aplicativo NoSQL Database pode querer testar seu código atualizado na instância local do Oracle NoSQL Database Cloud Service (NDCS) usando cloudsim. Para verificar todos os casos de teste possíveis, eles devem configurar os dados de teste semelhantes aos dados reais. Para fazer isso, eles devem copiar as tabelas NoSQL do ambiente de produção para sua instância local do NDCS, o ambiente cloudsim. Em outra situação, os desenvolvedores do NoSQL podem precisar mover seus dados de aplicativos do local para a nuvem e vice-versa, seja para desenvolvimento ou teste.
Em todos esses casos e muito mais, você pode usar o Oracle NoSQL Database Migrator para mover suas tabelas do NoSQL de uma origem de dados para outra, como o Oracle NoSQL Database on-premises ou na nuvem ou até mesmo um arquivo JSON simples. Você também pode copiar tabelas NoSQL de um arquivo de entrada JSON formatado pelo MongoDB, um arquivo de entrada JSON formatado pelo DynamoDB (armazenado na origem do AWS S3 ou em arquivos) ou um arquivo CSV no seu Banco de Dados NoSQL on-premises ou na nuvem.
Conforme descrito na figura a seguir, o utilitário NoSQL Database Migrator atua como um conector ou um pipe entre a origem de dados e o destino (referido como dissipador). Em essência, esse utilitário exporta dados da origem selecionada e importa esses dados para o dissipador. Esta ferramenta é orientada por tabela, ou seja, você pode mover os dados apenas no nível da tabela. Uma única tarefa de migração opera em uma única tabela e suporta a migração de dados da tabela da origem para o sumidouro em vários formatos de dados.
O Oracle NoSQL Database Migrator foi projetado para oferecer suporte a origens e sumidouros adicionais no futuro. Para obter uma lista de origens e sumidouros suportados pelo Oracle NoSQL Database Migrator a partir da release atual, consulte Origens e Sinks Suportados. 
Descrição da ilustração migrator_overview.png
Terminologia usada com o Oracle NoSQL Database Migrator
Saiba mais sobre os diferentes termos usados no diagrama acima, em detalhes.
-
Origem: Uma entidade de onde as tabelas NoSQL são exportadas para migração. Alguns exemplos de origens são o Oracle NoSQL Database on-premise ou na nuvem, arquivo JSON, arquivo JSON formatado em MongoDB, arquivo JSON formatado em DynamoDB e arquivos CSV.
-
Dissipador: Uma entidade que importa as tabelas NoSQL do NoSQL Database Migrator. Alguns exemplos de sumidouros são o Oracle NoSQL Database on-premise ou o arquivo JSON e na nuvem.
A ferramenta NoSQL Database Migrator suporta diferentes tipos de fontes e sumidouros (ou seja, mídia física ou repositórios de dados) e formatos de dados (ou seja, como os dados são representados na origem ou no sumidouro). Os formatos de dados suportados são JSON, Parquet, JSON formatado pelo MongoDB, JSON formatado pelo DynamoDB e arquivos CSV. Os tipos de origem e sumidouro suportados são arquivos, OCI Object Storage, Oracle NoSQL Database on-premises e Oracle NoSQL Database Cloud Service.
-
Tubulação de Migração: Os dados de uma origem serão transferidos para o coletor pelo NoSQL Database Migrator. Isso pode ser visualizado como um Pipe de Migração.
-
Transformações: Você pode adicionar regras para modificar os dados da tabela NoSQL no pipe de migração. Essas regras são chamadas de Transformações. O Oracle NoSQL Database Migrator permite transformações de dados somente nos campos ou colunas de nível superior. Ela não permite que você transforme os dados nos campos aninhados. Alguns exemplos de transformações permitidas são:
-
Eliminar ou ignorar uma ou mais colunas,
-
Renomear uma ou mais colunas ou
-
Agrega várias colunas em um único campo, geralmente um campo JSON.
-
-
Arquivo de Configuração: Um arquivo de configuração é onde você define todos os parâmetros necessários para a atividade de migração em um formato JSON. Posteriormente, você especificará esse arquivo de configuração como um único parâmetro para o comando
runMigratorna CLI. Um formato de arquivo de configuração típico se parece com o mostrado abaixo.{ "source": { "type" : <source type>, //source-configuration for type. }, "sink": { "type" : <sink type>, //sink-configuration for type. }, "transforms" : { //transforms configuration. }, "migratorVersion" : "<migrator version>", "abortOnError" : <true|false> }Agrupar Parâmetros Obrigatório (S/N) Objetivo Valores Suportados sourcetypeS Representa a origem da qual os dados serão migrados. A origem fornece dados e metadados (se houver) para migração. Para saber o valor typede cada origem, consulte Origens e Pias Suportados.sourceconfiguração de origem para tipo S Define a configuração da origem. Esses parâmetros de configuração são específicos para o tipo de origem selecionada acima. Consulte Modelos de Configuração de Origem para obter a lista completa de parâmetros de configuração para cada tipo de origem. sinktypeS Representa o coletor para o qual migrar os dados. O sumidouro é o destino ou destino da migração. Para saber o valor typede cada origem, consulte Origens e Pias Suportados.sinkconfiguração de sumariação para tipo S Define a configuração do sumidouro. Esses parâmetros de configuração são específicos para o tipo de sumidouro selecionado acima. Consulte Modelos de Configuração do Separador para obter a lista completa de parâmetros de configuração para cada tipo de sumidouro. transformstransforma a configuração N Define as transformações a serem aplicadas aos dados no pipe de migração. Consulte Modelos de Configuração de Transformação para obter a lista completa de transformações suportadas pelo NoSQL Data Migrator. - migratorVersionN Versão do NoSQL Data Migrator - - abortOnErrorN Especifica se a atividade de migração deve ser interrompida em caso de erro ou não.
O valor padrão é verdadeiro indicando que a migração é interrompida sempre que encontra um erro de migração.
Se você definir esse valor como falso, a migração continuará mesmo em caso de falha de registros ou outros erros de migração. Os registros com falha e os erros de migração serão registrados como WARNINGs no terminal da CLI.verdadeiro, falso
Observação: Como o arquivo JSON faz distinção entre maiúsculas e minúsculas, todos os parâmetros definidos no arquivo de configuração fazem distinção entre maiúsculas e minúsculas, a menos que especificado de outra forma.
Origens e Receptores Suportados
Este tópico fornece a lista de origens e sumidouros suportados pelo Oracle NoSQL Database Migrator.
Você pode usar qualquer combinação de uma origem e um sumário válidos desta tabela para a atividade de migração. No entanto, você deve garantir que pelo menos uma das extremidades, ou seja, origem ou sumidouro, seja um produto Oracle NoSQL. Não é possível usar o NoSQL Database Migrator para mover os dados da tabela NoSQL de um arquivo para outro.
| Tipo (valor) | Formatar (valor) | Origem Válida | Dissipador Válido |
|---|---|---|---|
Oracle NoSQL Database (nosqldb) |
NA | S | S |
Oracle NoSQL Database Cloud Service (nosqldb_cloud) |
NA | S | S |
Sistema de arquivos (file) |
JSON (json) |
S | S |
Sistema de arquivos (file) |
JSON do MongoDB (mongodb_json) |
S | N |
Sistema de arquivos (file) |
JSON do DynamoDB (dynamodb_json) |
S | N |
Sistema de arquivos (file) |
Parquet (parquet) |
N | S |
Sistema de arquivos (file) |
CSV (csv) |
S | N |
Armazenamento de Objetos do OCI (object_storage_oci) |
JSON (json) |
S | S |
Armazenamento de Objetos do OCI (object_storage_oci) |
JSON do MongoDB (mongodb_json) |
S | N |
Armazenamento de Objetos do OCI (object_storage_oci) |
Parquet (parquet) |
N | S |
Armazenamento de Objetos do OCI (object_storage_oci) |
CSV (csv) |
S | N |
| AWS S3 | JSON do DynamoDB (dynamodb_json) |
S | N |
Observação: Muitos parâmetros de configuração são comuns na configuração de origem e sumidouro. Para facilitar a referência, a descrição de tais parâmetros é repetida para cada fonte e sumidouro nas seções de documentação, que explicam formatos de arquivo de configuração para vários tipos de fontes e sumidouros. Em todos os casos, a sintaxe e a semântica dos parâmetros com o mesmo nome são idênticas.
Segurança de Origem e Destinação
Alguns dos tipos de origem e sumidouro têm informações de segurança opcionais ou obrigatórias para fins de autenticação.
Todas as origens e sumidouros que usam serviços na Oracle Cloud Infrastructure (OCI) podem usar determinados parâmetros para fornecer informações de segurança opcionais. Essas informações podem ser fornecidas usando um arquivo de configuração do OCI ou um Controlador de Instâncias.
As origens e sumidouros do Oracle NoSQL Database exigirão informações de segurança obrigatórias se a instalação for segura e usar uma autenticação baseada no Oracle Wallet. Essas informações podem ser fornecidas adicionando um arquivo jar ao diretório <MIGRATOR_HOME>/lib.
Autenticando com Controladores de Instância
Controladores de instâncias é um recurso do serviço IAM que permite que as instâncias sejam atores autorizados (ou controladores) que possam executar ações nos recursos. Cada instância de computação tem sua própria identidade e é autenticada usando os certificados adicionados a ela.
O Oracle NoSQL Database Migrator fornece uma opção para estabelecer conexão com uma nuvem NoSQL e origens e sumidouros do OCI Object Storage usando a autenticação do controlador de instâncias. Ele só é suportado quando a ferramenta NoSQL Database Migrator é usada em uma instância de computação da OCI, por exemplo, a ferramenta NoSQL Database Migrator em execução em uma VM hospedada na OCI. Para ativar esse recurso, use o atributo useInstancePrincipal do arquivo de configuração de origem e sumidouro do NoSQL cloud. Para obter mais informações sobre parâmetros de configuração para diferentes tipos de origens e sumidouros, consulte Modelos de Configuração de Origem e Modelos de Configuração de Separação.
Para obter mais informações sobre principais de instância, consulte Chamando Serviços de uma Instância.
Autorização em origens e sumidouros do Oracle NoSQL Database Cloud Service
O acesso a recursos no Oracle NoSQL Database Cloud Service, como tabelas, tablespaces e APIs, é gerenciado por meio de políticas do IAM (Identity and Access Management). Isso garante que somente usuários ou aplicativos com as permissões de tabela apropriadas para inspecionar, ler, usar ou gerenciar em um compartimento específico possam interagir com esses recursos. Para obter mais informações, consulte Gerenciando o Acesso a Tabelas do NDCS.
Ao usar o utilitário Migrator para importar ou exportar dados de tabelas do Oracle NoSQL Database Cloud Service, suas permissões efetivas do IAM determinam os recursos que você pode ler ou gravar. Se um usuário de um grupo definido tentar uma ação além de seus privilégios autorizados, o utilitário Migrator retornará o erro de autorização correspondente conforme fornecido pelo OCI IAM.
Por exemplo, o OCI IAM negará qualquer tentativa de importar dados para uma tabela do Oracle NoSQL Database Cloud Service se seu grupo de usuários tiver apenas a permissão "ler" na tabela. Uma mensagem De Erro semelhante a esta é exibida nos logs:
[INSUFFICIENT_PERMISSION] Authorization failed or requested resource not foundWorkflow para o Oracle NoSQL Database Migrator
Saiba mais sobre as várias etapas envolvidas no uso do utilitário Migrator do Oracle NoSQL Database para migrar seus dados NoSQL.
O fluxo de alto nível de tarefas envolvidas no uso do NoSQL Database Migrator é mostrado na figura abaixo.
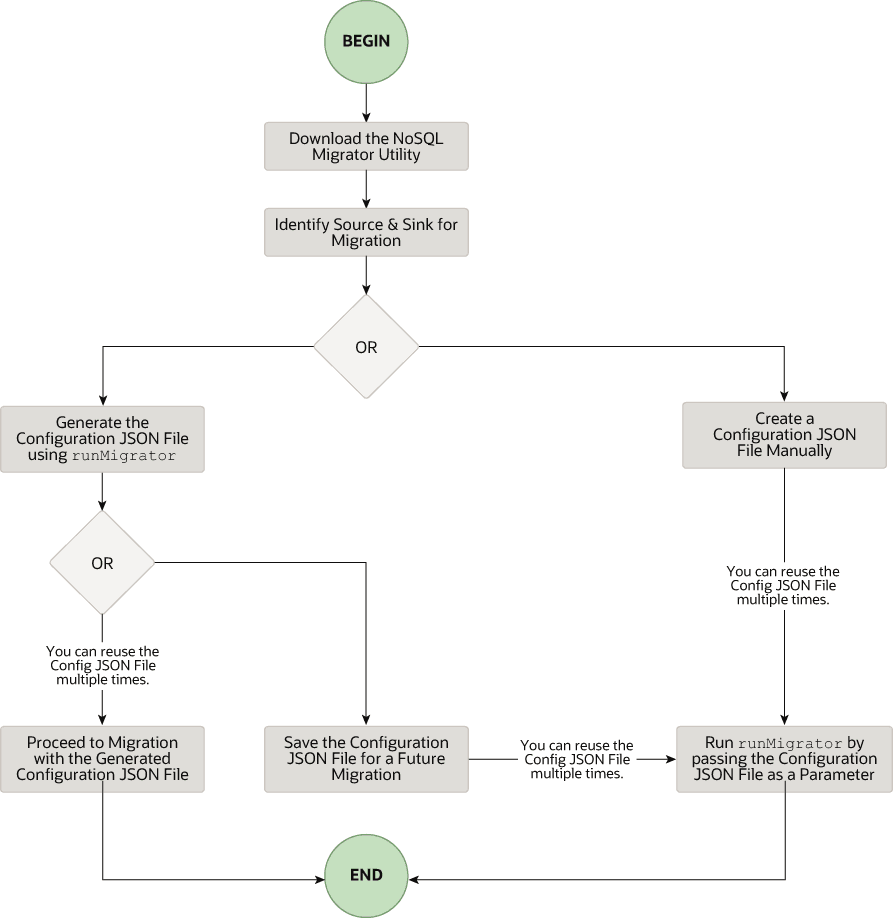
Descrição da ilustração migrator_flow.png
Fazer Download do Utilitário NoSQL Data Migrator
O utilitário Migrator do Oracle NoSQL Database está disponível para download na página Downloads do Oracle NoSQL. Depois de fazer download e descompactá-lo em sua máquina, você poderá acessar o comando runMigrator na interface de linha de comando.
Observação: O utilitário Migrator do Oracle NoSQL Database requer a execução de versões Java 11 ou superiores.
Identificar a Origem e o Pia
Antes de usar o migrador, você deve identificar a origem de dados e o coletor. Por exemplo, se você quiser migrar uma tabela NoSQL do Oracle NoSQL Database on-premises para um arquivo formatado em JSON, sua origem será o Oracle NoSQL Database e o dissipador será o arquivo JSON. Certifique-se de que a origem e o sumidouro identificados sejam suportados pelo Migrador do Oracle NoSQL Database referindo-se a Origens e Dissipadores Suportados. Essa também é uma fase apropriada para decidir o esquema da sua tabela NoSQL no destino ou no sumidouro e criá-los.
-
Identificar esquema da tabela do sumidouro: Se o sumidouro for o Oracle NoSQL Database on-premises ou na nuvem, você deverá identificar o esquema da tabela do sumidouro e garantir que os dados de origem correspondam ao esquema de destino. Se necessário, use transformações para mapear os dados de origem para a tabela do dissipador.
-
Esquema Padrão: O NoSQL Database Migrator fornece uma opção para criar uma tabela do coletor com o esquema padrão sem a necessidade de predefinir o esquema para a tabela.
JSON formatado em MongoDB:
Se a origem for um arquivo JSON formatado no MongoDB, o esquema padrão da tabela será o seguinte:
CREATE TABLE IF NOT EXISTS <tablename>(id STRING, document JSON,PRIMARY KEY(SHARD(id))Onde:
-
tablename = valor fornecido para o atributo de tabela na configuração.
-
id = valor _id de cada documento do arquivo de origem JSON exportado pelo MongoDB.
-
document = Para cada documento no arquivo exportado do MongoDB, o conteúdo excluindo o campo
_idé agregado na coluna do documento.
Observação:
- Se o valor _id não for fornecido como uma string no arquivo JSON formatado pelo MongoDB, o NoSQL Database Migrator o converterá em uma string antes de inseri-lo no esquema padrão.
- Se a tabela
<tablename>já existir no Oracle NoSQL Database on-premises ou na nuvem e você quiser migrar dados para a tabela usando a configuraçãodefaultSchema, certifique-se de que a tabela existente tenha a coluna ID em letras minúsculas (ID) e seja do tipo STRING.
JSON formatado por DynamoDB:
Se a origem for um arquivo JSON formatado pelo DynamoDB, o esquema padrão da tabela será o seguinte:
CREATE TABLE IF NOT EXISTS <tablename>(DDBPartitionKey_name DDBPartitionKey_type, [DDBSortKey_name DDBSortKey_type],DOCUMENT JSON, PRIMARY KEY(SHARD(DDBPartitionKey_name),[DDBSortKey_name]))Onde:
-
tablename = valor fornecido para a tabela do sumidouro na configuração
-
DDBPartitionKey_name = valor fornecido para a chave de partição na configuração
-
DDBPartitionKey_type = valor fornecido para o tipo de dados da chave de partição na configuração
-
DDBSortKey_name = valor fornecido para a chave de classificação na configuração, se houver
-
DDBSortKey_type = valor fornecido para o tipo de dados da chave de classificação na configuração, se houver
-
DOCUMENT = Todos os atributos, exceto a chave de partição e classificação de um item de tabela DynamoDB agregado em uma coluna JSON NoSQL
Se o formato de origem for um arquivo CSV, um esquema padrão não será suportado para a tabela de destino. Você pode criar um arquivo de esquema com uma definição de tabela contendo o mesmo número de colunas e tipos de dados que o arquivo CSV de origem. Para obter mais detalhes sobre a criação do arquivo de Esquema, consulte Fornecendo Esquema de Tabela.
Outras fontes válidas:
Para todas as outras origens, o esquema padrão será o seguinte:
CREATE TABLE IF NOT EXISTS <tablename> (id LONG GENERATED ALWAYS AS IDENTITY, document JSON, PRIMARY KEY(id))Onde:
-
tablename = valor fornecido para o atributo de tabela na configuração.
-
id = Um valor LONG gerado automaticamente.
-
document = O registro JSON fornecido pela origem é agregado na coluna do documento.
-
-
-
Fornecendo o Esquema da Tabela: O NoSQL Database Migrator permite que a origem forneça definições de esquema para os dados da tabela usando o atributo schemaInfo. O atributo schemaInfo está disponível em todas as origens de dados que não têm um esquema implícito já definido. Os armazenamentos de dados do dissipador podem escolher qualquer uma das seguintes opções.
-
Use o esquema padrão definido pelo NoSQL Database Migrator.
-
Use o esquema fornecido pela origem.
-
Substitua o esquema fornecido pela origem definindo seu próprio esquema. Por exemplo, se quiser transformar os dados do esquema de origem em outro esquema, você precisará substituir o esquema fornecido pela origem e usar o recurso de transformação da ferramenta NoSQL Database Migrator.
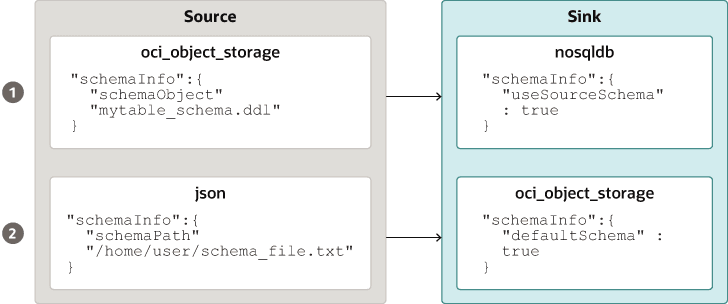
Descrição da ilustração source_sink_schema_example.png
O arquivo de esquema de tabela, por exemplo,
mytable_schema.ddlpode incluir instruções DDL de tabela. A ferramenta NoSQL Database Migrator executa este arquivo de esquema de tabela antes de iniciar a migração. A ferramenta migrator não suporta mais de uma instrução DDL por linha no arquivo de esquema. Por exemplo,CREATE TABLE IF NOT EXISTS(id INTEGER, name STRING, age INTEGER, PRIMARY KEY(SHARD(ID))) -
Observação: A migração falhará se a tabela estiver presente no sumidouro e a DDL no schemaPath for diferente da tabela.
- Criar Tabela do Sink: Depois de identificar o esquema da tabela do sumidouro, crie a tabela do sumidouro por meio da CLI do Administrador ou usando o atributo
schemaInfodo arquivo de configuração do sumidouro. Consulte Modelos de Configuração do Separador.
Observação: Se a origem for um arquivo CSV, crie um arquivo com os comandos DDL para o esquema da tabela de destino. Forneça o caminho do arquivo no parâmetro schemaInfo.schemaPath do arquivo de configuração do coletor.
Execute o comando runMigrator
O arquivo executável runMigrator está disponível nos arquivos do NoSQL Database Migrator extraídos. Você deve instalar o Java 11 ou uma versão mais recente e basear no sistema para executar com sucesso o comando runMigrator.
Você pode executar o comando runMigrator de duas maneiras:
-
Criando o arquivo de configuração usando as opções de runtime do comando
runMigrator, conforme mostrado abaixo.[~]$ ./runMigrator configuration file is not provided. Do you want to generate configuration? (y/n) [n]: y ... ...-
Quando você chama o utilitário
runMigrator, ele fornece uma série de opções de runtime e cria o arquivo de configuração com base em suas opções para cada opção. -
Depois que o utilitário criar o arquivo de configuração, você terá a opção de prosseguir com a atividade de migração na mesma execução ou salvar o arquivo de configuração para uma migração futura.
-
Independentemente da sua decisão de continuar ou adiar a atividade de migração com o arquivo de configuração gerado, o arquivo estará disponível para edições ou personalização para atender aos seus requisitos futuros. Você pode usar o arquivo de configuração personalizado para migração posteriormente.
-
-
Especificando um arquivo de configuração criado manualmente (no formato JSON) como parâmetro de runtime usando a opção
-cou--config. Você deve criar o arquivo de configuração manualmente antes de executar o comandorunMigratorcom a opção-cou--config. Para obter ajuda com os parâmetros de configuração de origem e sumidouro, consulte Referência do Migrador do Oracle NoSQL Database.[~]$ ./runMigrator -c </path/to/the/configuration/json/file>
Observação: O NoSQL Database Migrator consome unidades de leitura ao executar a exportação de dados da tabela do Oracle NoSQL Cloud Service para qualquer detector válido.
Andamento do Migrador de Log
A ferramenta NoSQL Database Migrator fornece opções que permitem que as mensagens de rastreamento, depuração e andamento sejam impressas em uma saída padrão ou em um arquivo. Essa opção pode ser útil no rastreamento do andamento da operação de migração, especialmente para tabelas ou conjuntos de dados muito grandes.
-
Níveis de Log
Para controlar o comportamento de log por meio da ferramenta NoSQL Database Migrator, informe o parâmetro de runtime -log-level ou -l para o comando
runMigrator. Você pode especificar a quantidade de informações de log a serem gravadas especificando o valor de nível de log apropriado.$./runMigrator --log-level <loglevel>Exemplo:
$./runMigrator --log-level debugTabela - Níveis de Log Suportados para o NoSQL Database Migrator
Nível de Log Descrição advertência Imprime erros e avisos. informações (padrão) Imprime o status de andamento da migração de dados, como validar a origem, validar o coletor, criar tabelas e contar o número de registros de dados migrados. depuração Imprime informações adicionais de depuração. all Imprime tudo. Este nível ativa todos os níveis de registro. -
Arquivo de Log:
É possível especificar o nome do arquivo de log usando o parâmetro –log-file ou -f. Se o arquivo –log-file for passado como parâmetro de tempo de execução para o comando
runMigrator, o NoSQL Database Migrator gravará todas as mensagens de log no arquivo para a saída padrão.$./runMigrator --log-file <log file name>Exemplo:
$./runMigrator --log-file nosql_migrator.log
Limitação
O Oracle NoSQL Database Migrator não bloqueia o banco de dados durante o backup e bloqueia outros usuários. Portanto, é altamente recomendável não executar as seguintes atividades quando uma tarefa de migração estiver em execução:
-
Quaisquer operações DML/DDL na tabela de origem.
-
Qualquer modificação relacionada à topologia no armazenamento de dados.
Migrando Metadados TTL para Linhas de Tabela
Saiba como migrar dados TTL da origem para o dissipador.
Time to Live (TTL) é um mecanismo que permite a expiração automática das linhas da tabela. O TTL é expresso como a quantidade de tempo, e os dados podem ser armazenados na loja. Os dados que atingiram seu valor de timeout de expiração não podem mais ser recuperados e não aparecerão em nenhuma estatística de armazenamento.
Você pode optar por incluir os metadados TTL para linhas de tabela juntamente com os dados reais ao executar a migração de tabelas do Oracle NoSQL Database. O NoSQL Database Migrator fornece parâmetros de configuração para suportar a exportação e a importação de metadados TTL da linha da tabela para os seguintes tipos de origem:
Tabela - Migrando metadados TTL
| Tipos de origens | Parâmetro de configuração de origem | Parâmetro de configuração do dissipador |
|---|---|---|
| Oracle NoSQL Database | includeTTL |
includeTTL |
| Oracle NoSQL Database Cloud Service | includeTTL |
includeTTL |
| Arquivo JSON Formatado no DynamoDB | ttlAttributeName |
includeTTL |
| Arquivo JSON Formatado pelo DynamoDB armazenado no AWS S3 | ttlAttributeName |
includeTTL |
Exportando metadados TTL no Oracle NoSQL Database e no Oracle NoSQL Database Cloud Service
O NoSQL Database Migrator fornece o parâmetro de configuração includeTTL para suportar a exportação de metadados TTL da linha da tabela.
Quando uma tabela é exportada, os dados de TTL são exportados para as linhas da tabela que têm um tempo de expiração válido. Se uma linha não expirar, o objeto JSON _metadata não será incluído explicitamente nos dados exportados porque seu valor de expiração é sempre
- O NoSQL Database Migrator exporta o tempo de expiração de cada linha como o número de milissegundos desde a época do UNIX (1º de janeiro de 1970). Por exemplo,
//Row 1
{
"id" : 1,
"name" : "xyz",
"age" : 45,
"_metadata" : {
"expiration" : 1629709200000 //Row Expiration time in milliseconds
}
}
//Row 2
{
"id" : 2,
"name" : "abc",
"age" : 52,
"_metadata" : {
"expiration" : 1629709400000 //Row Expiration time in milliseconds
}
}
//Row 3 No Metadata for below row as it will not expire
{
"id" : 3,
"name" : "def",
"age" : 15
}Importando metadados TTL
Opcionalmente, você pode importar metadados TTL usando o parâmetro de configuração includeTTL no modelo de configuração do sumidouro.
O horário de referência padrão da operação de importação é o horário atual em milissegundos, obtido de System.currentTimeMillis(), da máquina em que a ferramenta NoSQL Database Migrator está sendo executada. No entanto, você também pode definir uma hora de referência personalizada usando o parâmetro de configuração ttlRelativeDate se quiser estender a hora de expiração e importar linhas que, de outra forma, expirariam imediatamente. A extensão é calculada da seguinte forma e adicionada ao tempo de expiração.
Extended time = expiration time - reference timeA operação de importação trata os seguintes casos de uso ao migrar linhas de tabela contendo metadados TTL. Esses casos de uso só são aplicáveis quando o parâmetro de configuração includeTTL é definido como verdadeiro.
-
Caso de Uso 1: Nenhuma informação de metadados TTL está presente na linha da tabela de importação.
Se a linha que você deseja importar não contiver informações de TTL, o NoSQL Database Migrator definirá o TTL=0 para a linha.
-
Caso de Uso 2: O valor de TTL da linha da tabela de origem expirou em relação ao tempo de referência quando a linha da tabela é importada.
A linha da tabela expirada é ignorada e não gravada na loja.
-
Caso de Uso 3: O valor de TTL da linha da tabela de origem não expirou em relação ao tempo de referência quando a linha da tabela é importada.
A linha da tabela é importada com um valor TTL. No entanto, o valor TTL importado pode não corresponder ao valor TTL exportado original por causa das restrições de intervalo de horas e dias inteiros na classe TimeToLive. Por exemplo,
Considere uma linha de tabela exportada:
{ "id" : 8, "name" : "xyz", "_metadata" : { "expiration" : 1734566400000 //Thursday, December 19, 2024 12:00:00 AM in UTC } }O tempo de referência durante a importação é 1734480000000, que é quarta-feira, 18 de dezembro de 2024 12:00:00.
Linha da tabela importada
{ "id" : 8, "name" : "xyz", "_metadata" : { "ttl" : 1734739200000 //Saturday, December 21, 2024 12:00:00 AM } }
Importação de Metadados TTL no Arquivo JSON Formatado no DynamoDB e no Arquivo JSON Formatado no DynamoDB armazenado no AWS S3
O NoSQL Database Migrator fornece um parâmetro de configuração adicional, ttlAttributeName, para suportar a importação de metadados TTL dos itens de arquivo JSON formatados no DynamoDB.
Os arquivos JSON exportados do DynamoDB incluem um atributo específico em cada item para armazenar o timestamp de expiração do TTL. Para importar opcionalmente os valores de TTL dos arquivos JSON exportados do DynamoDB, você deve fornecer o nome do atributo específico como um valor para o parâmetro de configuração ttlAttributeName no Arquivo JSON Formatado pelo DynamoDB ou no Arquivo JSON Formatado pelo DynamoDB armazenado nos arquivos de configuração de origem do AWS S3. Além disso, você deve definir o parâmetro de configuração includeTTL no modelo de configuração do coletor. Os sumidouros válidos são Oracle NoSQL Database e Oracle NoSQL Database Cloud Service. O NoSQL Database Migrator armazena informações de TTL no objeto JSON _metadata para o item importado.
A operação de importação gerencia os seguintes casos de uso ao migrar itens de tabela dos arquivos JSON exportados do DynamoDB:
-
Caso de uso 1: O valor do parâmetro de configuração ttlAttributeName é definido como o nome do atributo TTL especificado no arquivo JSON exportado do DynamoDB.
O NoSQL Database Migrator importa o tempo de expiração deste item como o número de milissegundos desde a época do UNIX (1º de janeiro de 1970).
Por exemplo, considere um item no arquivo JSON exportado do DynamoDB:
{ "Item": { "DeptId": { "N": "1" }, "DeptName": { "S": "Engineering" }, "ttl": { "N": "1734616800" } } }Aqui, o atributo
ttlespecifica o valor de tempo de vida do item. Se você definir o parâmetro de configuração ttlAttributeName comottlno arquivo JSON formatado pelo DynamoDB ou no arquivo JSON formatado pelo DynamoDB armazenado no arquivo de configuração de origem do AWS S3, o NoSQL Database Migrator importará o tempo de expiração do item da seguinte forma:{ "DeptId": 1, "document": { "DeptName": "Engineering" } "_metadata": { "expiration": 1734616800000 } }
Observação: você pode fornecer o parâmetro de configuração ttlRelativeDate no modelo de configuração do coletor como o tempo de referência para calcular o tempo de expiração.
-
Caso de uso 2: O valor do parâmetro de configuração ttlAttributeName está definido; no entanto, o valor não existe como um atributo no item do arquivo JSON exportado do DynamoDB.
O NoSQL Database Migrator não importa as informações de metadados TTL para o item fornecido.
-
Caso de uso 3: O valor do parâmetro de configuração ttlAttributeName não corresponde ao nome do atributo no item do arquivo JSON exportado do DynamoDB. O NoSQL Database Migrator trata a importação de uma das seguintes maneiras com base na configuração do coletor:
-
Copia o atributo como um campo normal se configurado para importação usando o esquema padrão.
-
Ignora o atributo se configurado para importação usando um esquema definido pelo usuário.
-
Importando dados para um dissipador com uma coluna IDENTITY
Saiba como importar dados para um coletor que inclua uma coluna IDENTITY.
Você pode importar os dados de uma origem válida para uma tabela do sumidouro (On-premises/Cloud Services) com uma coluna IDENTITY. Você cria a coluna IDENTITY como GENERATED ALWAYS AS IDENTITY ou GENERATED BY DEFAULT AS IDENTITY. Para obter mais informações sobre a criação de tabelas com uma coluna IDENTITY, consulte Creating Tables With an IDENTITY Column no SQL Reference Guide.
Antes de importar os dados, certifique-se de que a tabela do Oracle NoSQL Database na pia esteja vazia se ela existir. Se houver dados pré-existentes na tabela do sumidouro, a migração poderá levar a problemas como substituir dados existentes na tabela do sumidouro ou ignorar dados de origem durante a importação.
Tabela de pia com coluna IDENTITY como GENERATED ALWAYS AS IDENTITY
Considere uma tabela dissipadora com a coluna IDENTITY criada como GENERATED ALWAYS AS IDENTITY. A importação de dados depende se a origem fornece ou não os valores para a coluna IDENTITY e ignora o parâmetro de transformação de Fields no arquivo de configuração.
Por exemplo, você deseja importar dados de uma origem de arquivo JSON para a tabela do Oracle NoSQL Database como sumidouro. O esquema da tabela sumidoura é:
CREATE TABLE IF NOT EXISTS migrateID(ID INTEGER GENERATED ALWAYS AS IDENTITY, name STRING, course STRING, PRIMARY KEY
(ID))O utilitário Migrator lida com a migração de dados conforme descrito nos seguintes casos:
| Condição de origem | Ação do usuário | Resultado da migração |
|---|---|---|
|
CASO 1: Os dados de origem não fornecem um valor para o campo IDENTITY da tabela de sumidouros. Exemplo: arquivo de origem JSON |
Criar/gerar o arquivo de configuração. |
A migração de dados foi bem-sucedida. Os valores da coluna IDENTITY são gerados automaticamente. Os dados migrados no Oracle NoSQL Database dissipam a tabela |
|
CASO 2: Os dados de origem fornecem valores para o campo IDENTITY da tabela de sumidouros. Exemplo: arquivo de origem JSON |
Criar/gerar o arquivo de configuração. Você fornece uma transformação ignoreFields para a coluna ID no modelo de configuração do coletor.
|
A migração de dados foi bem-sucedida. Os valores de ID fornecidos são ignorados e os valores da coluna IDENTITY são gerados automaticamente. Os dados migrados no Oracle NoSQL Database dissipam a tabela |
|
Você cria/gera o arquivo de configuração sem a transformação ignoreFields para a coluna IDENTITY. |
A migração de dados falha com a seguinte mensagem de erro:
|
Para obter mais detalhes sobre os parâmetros de configuração da transformação, consulte o tópico Modelos de Configuração da Transformação.
Dissipar tabela com a coluna IDENTITY como GENERATED BY DEFAULT AS IDENTITY
Considere uma tabela dissipadora com a coluna IDENTITY criada como GENERATED BY DEFAULT AS IDENTITY. A importação de dados depende de a origem fornecer ou não os valores para a coluna IDENTITY e ignorar o parâmetro de transformaçãoFields.
Por exemplo, você deseja importar dados de uma origem de arquivo JSON para a tabela do Oracle NoSQL Database como sumidouro. O esquema da tabela sumidoura é:
CREATE TABLE IF NOT EXISTS migrateID(ID INTEGER GENERATED BY DEFAULT AS IDENTITY, name STRING, course STRING, PRIMARY KEY
(ID))O utilitário Migrator lida com a migração de dados conforme descrito nos seguintes casos:
| Condição de origem | Ação do usuário | Resultado da migração |
|---|---|---|
|
CASO 1: Os dados de origem não fornecem um valor para o campo IDENTITY da tabela de sumidouros. Exemplo: arquivo de origem JSON |
Criar/gerar o arquivo de configuração. |
A migração de dados foi bem-sucedida. Os valores da coluna IDENTITY são gerados automaticamente. Os dados migrados no Oracle NoSQL Database dissipam a tabela |
|
CASO 2: Os dados de origem fornecem valores para o campo IDENTITY da tabela de sumidouros e é um campo Chave Primária. Exemplo: arquivo de origem JSON |
Criar/gerar o arquivo de configuração. Você fornece uma transformação ignoreFields para a coluna ID no modelo de configuração do coletor (Recomendado).
|
A migração de dados foi bem-sucedida. Os valores de ID fornecidos são ignorados e os valores da coluna IDENTITY são gerados automaticamente. Os dados migrados no Oracle NoSQL Database dissipam a tabela |
|
Você cria/gera o arquivo de configuração sem a transformação ignoreFields para a coluna IDENTITY. |
A migração de dados foi bem-sucedida. Os valores Quando você tenta inserir uma linha adicional na tabela sem fornecer um valor de ID, o gerador de sequência tenta gerar automaticamente o valor de ID. O valor inicial do gerador de sequência é 1. Como resultado, o valor de ID gerado pode duplicar um dos valores de ID existentes na tabela do coletor. Como isso é uma violação da restrição de chave primária, um erro é retornado e a linha não é inserida. Consulte Gerador de Sequência para obter informações adicionais. Para evitar a violação da restrição de chave primária, o gerador de sequência deve iniciar a sequência com um valor que não entre em conflito com os valores de ID existentes na tabela do dissipador. Para usar o atributo START WITH para fazer essa modificação, consulte o exemplo abaixo: Exemplo: Dados migrados na tabela do coletor do Oracle NoSQL Database Para localizar o valor apropriado para o gerador de sequência inserir na coluna ID, extraia o valor máximo do campo Saída: O valor máximo da coluna Isso iniciará a sequência no número 4. Agora, quando você insere linhas na tabela do coletor sem fornecer os valores de ID, o gerador de sequência gera automaticamente os valores de ID de 4 em diante, evitando a duplicação dos IDs. |
Para obter mais detalhes sobre os parâmetros de configuração da transformação, consulte o tópico Modelos de Configuração da Transformação.
Filtrar dados usando Predicados de consulta
Saiba como especificar predicados de consulta para exportar somente as linhas da tabela que correspondem aos critérios do filtro.
Predicado de Consulta
O NoSQL Database Migrator fornece uma opção para filtrar dados durante a exportação especificando um predicado de consulta. O predicado de consulta especifica condições que devem ser atendidas para que uma linha seja exportada. O utilitário Migrator converte o predicado de consulta em uma cláusula SQL WHERE e o aplica na tabela fornecida para fornecer uma condição de filtro a fim de exportar apenas as linhas correspondentes à condição especificada. Você pode usar funções incorporadas (modification_time(), expiration_time(), creation_time()) no predicado de consulta para criar opções de filtro avançadas.
Você só pode usar predicados de consulta em origens do Oracle NoSQL Database e do Oracle NoSQL Database Cloud Service para todos os sumidouros suportados. Para obter mais detalhes, consulte Oracle NoSQL Database e Oracle NoSQL Database Cloud Service.
Para obter uma demonstração do caso de uso, consulte Migrar do Oracle NoSQL Database Cloud Service para um arquivo JSON.
Filtro de despejo
O utilitário Migrator fornece uma opção para ecoar a consulta SQL executada no backend. Esse recurso ajuda a verificar a consulta gerada e, se necessário, refinar o filtro antes de executar a tarefa de migração.
Você pode executar o utilitário Migrator com a opção de filtro de dump da seguinte forma:
[~/nosqlMigrator]$./runMigrator --dump-filter|df [optional-config-file]-
Com o arquivo de configuração: O utilitário Migrator exibe o arquivo de configuração fornecido e a consulta gerada, conforme mostrado no seguinte exemplo:
[~/nosqlMigrator]./runMigrator --dump-filter migrator-config.json[INFO] Configuration for migration: { "source" : { "type" : "nosqldb", "storeName" : "kvstore", "helperHosts" : ["<hostname>:5000"], "table" : "users", "queryFilter" : "$row.address.city='Houston'", "includeTTL" : true, "requestTimeoutMs" : 5000 }, "sink" : { "type" : "file", "format" : "json", "useMultiFiles" : false, "schemaPath" : "<complete/path/to/the/JSON/file/with/DDL/commands/for/the/schema/definition>", "pretty" : true, "dataPath" : "<complete/path/to/directory>" }, "abortOnError" : true, "migratorVersion" : "1.8.0" } [INFO] Query for the migration: 'select $row, expiration_time($row) from users $row where $row.address.city='Houston'' -
Sem o arquivo de configuração: O utilitário Migrator coleta interativamente todas as entradas necessárias para gerar o arquivo de configuração, incluindo o predicado de consulta. Em seguida, ele exibe o arquivo de configuração e a consulta gerados.
Observação:
A opção de filtro de dump exibe apenas o arquivo de configuração e a consulta. Ele não inicia a migração de dados. Após a revisão, para executar a migração, execute o utilitário Migrator com seu arquivo de configuração usando a opção
--cou--configda seguinte forma:$./runMigrator --config <complete/path/to/the/JSON/config/file>
Demonstrações de Caso de Uso para o Oracle NoSQL Database Migrator
Saiba como executar a migração de dados usando o Oracle NoSQL Database Migrator para casos de uso específicos. Você pode encontrar instruções sistemáticas detalhadas com exemplos de código para executar a migração em cada um dos casos de uso.
Este artigo tem os seguintes tópicos:
Migrar do Oracle NoSQL Database Cloud Service para um arquivo JSON
Este exemplo mostra como usar o Oracle NoSQL Database Migrator para copiar dados e a definição de esquema de uma tabela NoSQL do Oracle NoSQL Database Cloud Service (NDCS) para um arquivo JSON.
Caso de Uso
Uma organização decide treinar um modelo usando os dados do Oracle NoSQL Database Cloud Service (NDCS) para prever comportamentos futuros e fornecer recomendações personalizadas. Eles podem pegar uma cópia periódica dos dados das tabelas NDCS para um arquivo JSON e aplicá-la ao mecanismo analítico para analisar e treinar o modelo. Isso os ajuda a separar as consultas analíticas dos caminhos críticos de baixa latência.
Exemplo
Para a demonstração, vamos ver como migrar os dados e a definição de esquema de uma tabela NoSQL chamada myTable do NDCS para um arquivo JSON.
Pré-requisitos
-
Identifique a origem e o dissipador da migração.
-
Origem: Oracle NoSQL Database Cloud Service
-
Dissipador: arquivo JSON
-
-
Identifique suas credenciais da nuvem do OCI e as capture no arquivo de configuração do OCI. Salve o arquivo de configuração em
/home/.oci/config. Consulte Adquirindo Credenciais.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Identifique o ponto final da região e o nome do compartimento do Oracle NoSQL Database Cloud Service.
-
ponto final:
us-ashburn-1 -
compartimento:
ocid1.compartment.oc1..aa..rhsmq
-
Procedimento
Para migrar a definição de dados e esquema da sua tabela do Oracle NoSQL Database Cloud Service para um arquivo JSON, você pode usar uma das seguintes opções:
-
Abra o prompt de comando e navegue até o diretório em que você extraiu o utilitário NoSQL Database Migrator.
-
Para gerar o arquivo de configuração usando o NoSQL Database Migrator, execute o comando
runMigratorsem nenhum parâmetro de runtime.[~/nosqlMigrator]$./runMigrator -
Como você não forneceu o arquivo de configuração como um parâmetro de tempo de execução, o utilitário solicitará se deseja gerar a configuração agora. Digite
**y**.Configuration file is not provided. Do you want to generate configuration? (y/n) [n]: y Generating a configuration file interactively. -
Com base nos prompts do utilitário, escolha suas opções para a configuração Origem.
Enter a location for your config [./migrator-config.json]: /home/<user>/nosqlMigrator/NDCS2JSON Select the source: 1) nosqldb 2) nosqldb_cloud 3) file 4) object_storage_oci 5) aws_s3 #? 2 Configuration for source type=nosqldb_cloud Enter endpoint URL or region ID of the Oracle NoSQL Database Cloud: us-phoenix-1 Select the authentication type: 1) credentials_file 2) instance_principal 3) delegation_token 4) session_token 5) oke_workload_identity #? 1 Enter path to the file containing OCI credentials [/home/<user>/.oci/config]: Enter the profile name in OCI credentials file [DEFAULT]: Enter the compartment name or id of the table []: developers Enter table name: myTable Include TTL data? If you select 'yes' TTL of rows will also be included in the exported data.(y/n) [n]: Enter percentage of table read units to be used for migration operation. (1-100) [90]: Enter store operation timeout in milliseconds. (1-30000) [5000]: -
Com base nos prompts do utilitário, escolha suas opções para a configuração do dissipador.
Select the sink: 1) nosqldb 2) nosqldb_cloud 3) file #? 3 Configuration for sink type=file Enter path to a directory to store JSON data: /home/<user>/nosqlMigrator would you like to export data to multiple files for each source?(y/n) [y]: n Would you like to store JSON in pretty format? (y/n) [n]: y Would you like to migrate the table schema also? (y/n) [y]: y Enter path to a file to store table schema: /home/<user>/nosqlMigrator/myTableSchema -
Com base nos prompts do utilitário, escolha suas opções para as transformações de dados de origem. O valor-padrão é
n.Would you like to add transformations to source data? (y/n) [n]: -
Informe sua opção para determinar se deseja continuar com a migração caso haja falha na migração de qualquer registro.
Would you like to continue migration in case of any record/row is failed to migrate?: (y/n) [n]: -
O utilitário exibe a configuração gerada na tela.
generated configuration is: { "source": { "type": "nosqldb_cloud", "endpoint": "us-ashburn-1", "table": "myTable", "compartment": "ocid1.compartment.oc1..aa..rhsmq", "credentials": "/home/<user>/.oci/config", "credentialsProfile": "DEFAULT", "readUnitsPercent": 90, "requestTimeoutMs": 5000 }, "sink": { "type": "file", "format": "json", "useMultiFiles" : false, "schemaPath": "/home/<user>/nosqlMigrator/myTableSchema", "pretty": true, "dataPath": "/home/<user>/nosqlMigrator" }, "abortOnError": true, "migratorVersion": "1.8.0" } -
O utilitário solicita que sua escolha decida se deseja continuar com a migração com o arquivo de configuração gerado ou não. O padrão é
y.Observação: Se você selecionar
n, poderá usar o arquivo de configuração gerado para executar a migração usando a opção./runMigrator -cou./runMigrator --config.Would you like to run the migration with above configuration? If you select no, you can use the generated configuration file to run the migration using: ./runMigrator --config /home/<user>/nosqlMigrator/NDCS2JSON (y/n) [y]: -
O NoSQL Database Migrator migra seus dados e esquema do NDCS para o arquivo JSON.
Records provided by source=10,Records written to sink=10,Records failed=0,Records skipped=0. Elapsed time: 0min 1sec 277ms Migration completed.Validação
Para validar a migração, você pode navegar até o diretório do coletor especificado e exibir o esquema e os dados.
-- Exported myTable Data. JSON files are created in the supplied data path
[~/nosqlMigrator]$cat myTable_1_5.json
{
"id" : 10,
"document" : {
"course" : "Computer Science",
"name" : "Neena",
"studentid" : 105
}
}
{
"id" : 3,
"document" : {
"course" : "Computer Science",
"name" : "John",
"studentid" : 107
}
}
{
"id" : 4,
"document" : {
"course" : "Computer Science",
"name" : "Ruby",
"studentid" : 100
}
}
{
"id" : 6,
"document" : {
"course" : "Bio-Technology",
"name" : "Rekha",
"studentid" : 104
}
}
{
"id" : 7,
"document" : {
"course" : "Computer Science",
"name" : "Ruby",
"studentid" : 100
}
}
{
"id" : 5,
"document" : {
"course" : "Journalism",
"name" : "Rani",
"studentid" : 106
}
}
{
"id" : 8,
"document" : {
"course" : "Computer Science",
"name" : "Tom",
"studentid" : 103
}
}
{
"id" : 9,
"document" : {
"course" : "Computer Science",
"name" : "Peter",
"studentid" : 109
}
}
{
"id" : 1,
"document" : {
"course" : "Journalism",
"name" : "Tracy",
"studentid" : 110
}
}
{
"id" : 2,
"document" : {
"course" : "Bio-Technology",
"name" : "Raja",
"studentid" : 108
}
}-- Exported myTable Schema
[~/nosqlMigrator]$cat myTableSchema
CREATE TABLE IF NOT EXISTS myTable (id INTEGER, document JSON, PRIMARY KEY(SHARD(id)))-
Prepare o arquivo de configuração (no formato JSON) com a origem do Oracle NoSQL Database Cloud Service (NDCS) e os detalhes do sumidouro JSON. Consulte Modelos de Configuração de Origem e Modelos de Configuração do Separador.
Uma tabela
usersé usada com os seguintes dados neste exemplo:{"id":10,"firstName":"John","lastName":"Smith","age":22,"income":45000,"address":{"city":"Santa Cruz","number":101,"phones":[{"area":408,"kind":"work","number":4538955},{"area":831,"kind":"home","number":7533341},{"area":831,"kind":"mobile","number":7533382}],"state":"CA","street":"Pacific Ave","zip":95008}} {"id":20,"firstName":"Jane","lastName":"Smith","age":22,"income":55000,"address":{"city":"San Jose","number":201,"phones":[{"area":608,"kind":"work","number":6538955},{"area":931,"kind":"home","number":9533341},{"area":931,"kind":"mobile","number":9533382}],"state":"CA","street":"Atlantic Ave","zip":95005}} {"id":30,"firstName":"Adam","lastName":"Smith","age":45,"income":75000,"address":{"city":"Houston","number":301,"phones":[{"area":618,"kind":"work","number":6618955},{"area":951,"kind":"home","number":9613341},{"area":981,"kind":"mobile","number":9613382}],"state":"TX","street":"Indian Ave","zip":95075}} {"id":40,"firstName":"Joanna","lastName":"Smith","age":null,"income":75000,"address":{"city":"Houston","number":401,"phones":[{"area":null,"kind":"work","number":1618955},{"area":451,"kind":"home","number":4613341},{"area":481,"kind":"mobile","number":4613382}],"state":"TX","street":"Tex Ave","zip":95085}}Certifique-se de incluir o parâmetro
queryFiltercom o predicado de consulta apropriado no modelo de configuração de origem para exportar somente as linhas necessárias da sua tabela. Para obter detalhes sobre como criar predicados de consulta, consulte a tabela Predicados de Consulta de Amostra no tópico Origem do NoSQL Database Cloud Service.Neste exemplo, o predicado de consulta exporta linhas com o campo
cityna coluna JSONaddress= 'Houston' da tabelausers.{ "source" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "users", "queryFilter" : "$row.address.city='Houston'", "compartment" : "ocid1.compartment.oc1..aa..rhsmq", "credentials" : "/home/<user>/.oci/config", "credentialsProfile" : "DEFAULT", "readUnitsPercent" : 90, "includeTTL" : true, "requestTimeoutMs" : 5000 }, "sink" : { "type" : "file", "format" : "json", "useMultiFiles" : true, "chunkSize" : 32, "schemaPath" : "/scratch/<user>/nosqlMigrator/tableschema.ddl", "pretty" : false, "dataPath" : "/scratch/<user>/nosqlMigrator" }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Abra o prompt de comando e navegue até o diretório em que você extraiu o utilitário NoSQL Database Migrator.
-
Execute o comando
runMigratorinformando o arquivo de configuração. Use a opção--configou-c.[~/nosqlMigrator]$./runMigrator --config <complete/path/to/the/JSON/config/file>Observação:
Você também pode executar o comando com o
para exibir e verificar a consulta gerada antes de executar a tarefa de migração da seguinte forma. Para obter mais detalhes, consulte
.
[~/nosqlMigrator]$./runMigrator --dump-filter <complete/path/to/the/JSON/config/file>O utilitário prossegue com a migração de dados da seguinte forma:
[INFO] creating source from given configuration: [INFO] [cloud source] : query = 'SELECT $row,expiration_time_millis($row) AS expiration FROM users $row where $row.address.city='Houston'' [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [json file sink] : writing table schema to /scratch/raumesh/nosqlMigrator/tableschema.ddl [INFO] migration started [INFO] Migration success for source users. read=2,written=2,failed=0 [INFO] Migration is successful for all the sources. [INFO] migration completed. Records provided by source=2, Records written to sink=2, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 182ms Migration completed.
Verificação
Para verificar a migração, você pode navegar até o diretório do coletor especificado e exibir o esquema e os dados. Somente as linhas na coluna JSON address com o valor de campo city 'Houston' são exportadas.
-- Exported users data. Schema and JSON files are created in the supplied data paths.
[~/nosqlMigrator]: cat tableschema.ddl
CREATE TABLE IF NOT EXISTS users (id INTEGER, firstName STRING, lastName STRING, age INTEGER, income INTEGER, address JSON, PRIMARY KEY(SHARD(id)))[~/nosqlMigrator]: cat users_6_10.json
{"id":30,"firstName":"Adam","lastName":"Smith","age":45,"income":75000,"address":{"city":"Houston","number":301,"phones":[{"area":618,"kind":"work","number":6618955},{"area":951,"kind":"home","number":9613341},{"area":981,"kind":"mobile","number":9613382}],"state":"TX","street":"Indian Ave","zip":95075}}
{"id":40,"firstName":"Joanna","lastName":"Smith","age":null,"income":75000,"address":{"city":"Houston","number":401,"phones":[{"area":null,"kind":"work","number":1618955},{"area":451,"kind":"home","number":4613341},{"area":481,"kind":"mobile","number":4613382}],"state":"TX","street":"Tex Ave","zip":95085}}
bash-4.4$Migrar do Oracle NoSQL Database Local para o Oracle NoSQL Database Cloud Service
Este exemplo mostra como usar o Oracle NoSQL Database Migrator para copiar dados e a definição de esquema de uma tabela do NoSQL do Oracle NoSQL Database para o Oracle NoSQL Database Cloud Service (NDCS).
Caso de Uso
Como desenvolvedor, você está explorando opções para evitar a sobrecarga de gerenciamento de recursos, clusters e coleta de lixo para suas cargas de trabalho existentes do NoSQL Database KVStore. Como solução, você decide migrar suas cargas de trabalho do KVStore locais existentes para o Oracle NoSQL Database Cloud Service porque o NDCS as gerencia automaticamente.
Exemplo
Para a demonstração, vamos ver como migrar a definição de dados e esquema de uma tabela NoSQL chamada myTable do NoSQL Database KVStore para o NDCS. Também usaremos esse caso de uso para mostrar como executar o utilitário runMigrator informando um arquivo de configuração pré-criado.
Pré-requisitos
-
Identifique a origem e o dissipador da migração.
-
Origem: Oracle NoSQL Database
-
Pia: Oracle NoSQL Database Cloud Service
-
-
Identifique suas credenciais da nuvem do OCI e as capture no arquivo de configuração do OCI. Salve o arquivo de configuração em
/home/.oci/config. Consulte Adquirindo Credenciais em Usando o Oracle NoSQL Database Cloud Service.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Identifique o ponto final da região e o nome do compartimento do Oracle NoSQL Database Cloud Service.
-
ponto final:
us-phoenix-1 -
compartimento:
developers
-
-
Identifique os seguintes detalhes do KVStore on-premise:
-
storeName:
kvstore -
helperHosts:
<hostname>:5000 -
tabela:
myTable
-
Procedimento
Para migrar a definição de dados e esquema do myTable do NoSQL Database KVStore para o NDCS:
-
Prepare o arquivo de configuração (no formato JSON) com os detalhes de Origem e Dissipador identificados. Consulte Modelos de Configuração de Origem e Modelos de Configuração do Separador.
{ "source" : { "type" : "nosqldb", "storeName" : "kvstore", "helperHosts" : ["<hostname>:5000"], "table" : "myTable", "requestTimeoutMs" : 5000 }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-phoenix-1", "table" : "myTable", "compartment" : "developers", "schemaInfo" : { "schemaPath" : "<complete/path/to/the/JSON/file/with/DDL/commands/for/the/schema/definition>", "readUnits" : 100, "writeUnits" : 100, "storageSize" : 1 }, "credentials" : "<complete/path/to/oci/config/file>", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Abra o prompt de comando e navegue até o diretório em que você extraiu o utilitário NoSQL Database Migrator.
-
Execute o comando
runMigratorespecificando o arquivo de configuração usando a opção--configou-c.[~/nosqlMigrator/nosql-migrator-1.8.0]$./runMigrator --config <complete/path/to/the/JSON/config/file> -
O utilitário prossegue com a migração de dados, conforme mostrado abaixo.
Records provided by source=10, Records written to sink=10, Records failed=0. Elapsed time: 0min 10sec 426ms Migration completed.
Validação
Para validar a migração, você pode fazer log-in na console do NDCS e verificar se o myTable foi criado com os dados de origem.
Migrar da origem de arquivos JSON para o Oracle NoSQL Database Cloud Service
Este exemplo mostra o uso do Oracle NoSQL Database Migrator para copiar dados de uma origem de arquivo JSON para o Oracle NoSQL Database Cloud Service.
Depois de avaliar várias opções, uma organização finaliza o Oracle NoSQL Database Cloud Service como sua plataforma NoSQL Database. Como seu conteúdo de origem está no formato de arquivo JSON, eles estão procurando uma maneira de migrá-los para o Oracle NoSQL Database Cloud Service.
Neste exemplo, você aprenderá a migrar os dados de um arquivo JSON chamado SampleData.json. Você executa o utilitário runMigrator especificando um arquivo de configuração pré-criado. Se o arquivo de configuração não for fornecido como um parâmetro de tempo de execução, o utilitário runMigrator solicitará que você gere a configuração por meio de um procedimento interativo.
Pré-requisitos
-
Identifique a origem e o dissipador da migração.
-
Origem: arquivo de origem JSON.
SampleData.jsoné o arquivo de origem. Ele contém vários documentos JSON com um documento por linha, delimitado por um novo caractere de linha.{"id":6,"val_json":{"array":["q","r","s"],"date":"2023-02-04T02:38:57.520Z","nestarray":[[1,2,3],[10,20,30]],"nested":{"arrayofobjects":[{"datefield":"2023-03-04T02:38:57.520Z","numfield":30,"strfield":"foo54"},{"datefield":"2023-02-04T02:38:57.520Z","numfield":56,"strfield":"bar23"}],"nestNum":10,"nestString":"bar"},"num":1,"string":"foo"}} {"id":3,"val_json":{"array":["g","h","i"],"date":"2023-02-02T02:38:57.520Z","nestarray":[[1,2,3],[10,20,30]],"nested":{"arrayofobjects":[{"datefield":"2023-02-02T02:38:57.520Z","numfield":28,"strfield":"foo3"},{"datefield":"2023-02-02T02:38:57.520Z","numfield":38,"strfield":"bar"}],"nestNum":10,"nestString":"bar"},"num":1,"string":"foo"}} {"id":7,"val_json":{"array":["a","b","c"],"date":"2023-02-20T02:38:57.520Z","nestarray":[[1,2,3],[10,20,30]],"nested":{"arrayofobjects":[{"datefield":"2023-01-20T02:38:57.520Z","numfield":28,"strfield":"foo"},{"datefield":"2023-01-22T02:38:57.520Z","numfield":38,"strfield":"bar"}],"nestNum":10,"nestString":"bar"},"num":1,"string":"foo"}} {"id":4,"val_json":{"array":["j","k","l"],"date":"2023-02-03T02:38:57.520Z","nestarray":[[1,2,3],[10,20,30]],"nested":{"arrayofobjects":[{"datefield":"2023-02-03T02:38:57.520Z","numfield":28,"strfield":"foo"},{"datefield":"2023-02-03T02:38:57.520Z","numfield":38,"strfield":"bar"}],"nestNum":10,"nestString":"bar"},"num":1,"string":"foo"}} -
Sink: Oracle NoSQL Database Cloud Service.
-
-
Identifique suas credenciais da nuvem do OCI e as capture no arquivo de configuração do OCI. Salve o arquivo de configuração no diretório
/home/<user>/.oci/config. Para obter mais detalhes, consulte Adquirindo Credenciais no Usando o Oracle NoSQL Database Cloud Service.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... region=us-ashburn-1 key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Identifique o ponto final da região e o nome do compartimento do Oracle NoSQL Database Cloud Service.
-
ponto final:
us-ashburn-1 -
compartimento:
Training-NoSQL
-
-
Identifique os seguintes detalhes para o arquivo de origem JSON:
-
schemaPath:
<absolute path to the schema definition file containing DDL statements for the NoSQL table at the sink>.Neste exemplo, o arquivo DDL é
schema_json.ddl.create table Migrate_JSON (id INTEGER, val_json JSON, PRIMARY KEY(id));O Oracle NoSQL Database Migrator fornece uma opção para criar uma tabela com o esquema padrão se o
schemaPathnão for fornecido. Para obter mais detalhes, consulte o tópico Identificar a Origem e o Dissipador no Workflow do Oracle NoSQL Database Migrator. -
Datapath:
<absolute path to a file or directory containing the JSON data for migration>.
-
Procedimento
Para migrar o arquivo de origem JSON do SampleData.json para o Oracle NoSQL Database Cloud Service, execute o seguinte:
-
Prepare o arquivo de configuração (no formato JSON) com os detalhes de origem e sumidouro identificados. Consulte Modelos de Configuração de Origem e Modelos de Configuração do Separador.
{ "source" : { "type" : "file", "format" : "json", "schemaInfo" : { "schemaPath" : "[~/nosql-migrator-1.8.0]/schema_json.ddl" }, "dataPath" : "[~/nosql-migrator-1.8.0]/SampleData.json" }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "Migrate_JSON", "compartment" : "Training-NoSQL", "includeTTL" : false, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "useSourceSchema" : true }, "credentials" : "/home/<user>/.oci/config", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Abra o prompt de comando e navegue até o diretório em que você extraiu o utilitário Migrator do Oracle NoSQL Database.
-
Execute o comando
runMigratorespecificando o arquivo de configuração usando a opção--configou-c.[~/nosql-migrator-1.8.0]$./runMigrator --config <complete/path/to/the/config/file> -
O utilitário prossegue com a migração de dados, conforme mostrado abaixo. A tabela
Migrate_JSONé criada no coletor com o esquema fornecido noschemaPath.creating source from given configuration: source creation completed creating sink from given configuration: sink creation completed creating migrator pipeline migration started [cloud sink] : start loading DDLs [cloud sink] : executing DDL: create table Migrate_JSON (id INTEGER, val_json JSON, PRIMARY KEY(id)),limits: [100, 60, 1] [cloud sink] : completed loading DDLs [cloud sink] : start loading records [json file source] : start parsing JSON records from file: SampleData.json [INFO] migration completed. Records provided by source=4, Records written to sink=4, Records failed=0, Records skipped=0. Elapsed time: 0min 5sec 778ms Migration completed.
Validação
Para validar a migração, você pode fazer log-in na console do Oracle NoSQL Database Cloud Service e verificar se a tabela Migrate_JSON foi criada com os dados de origem. Para obter o procedimento para acessar a console, consulte o artigo Acessando o Serviço na Console de Infraestrutura no documento do Oracle NoSQL Database Cloud Service.
Figura - Tabelas da Console do Oracle NoSQL Database Cloud Service
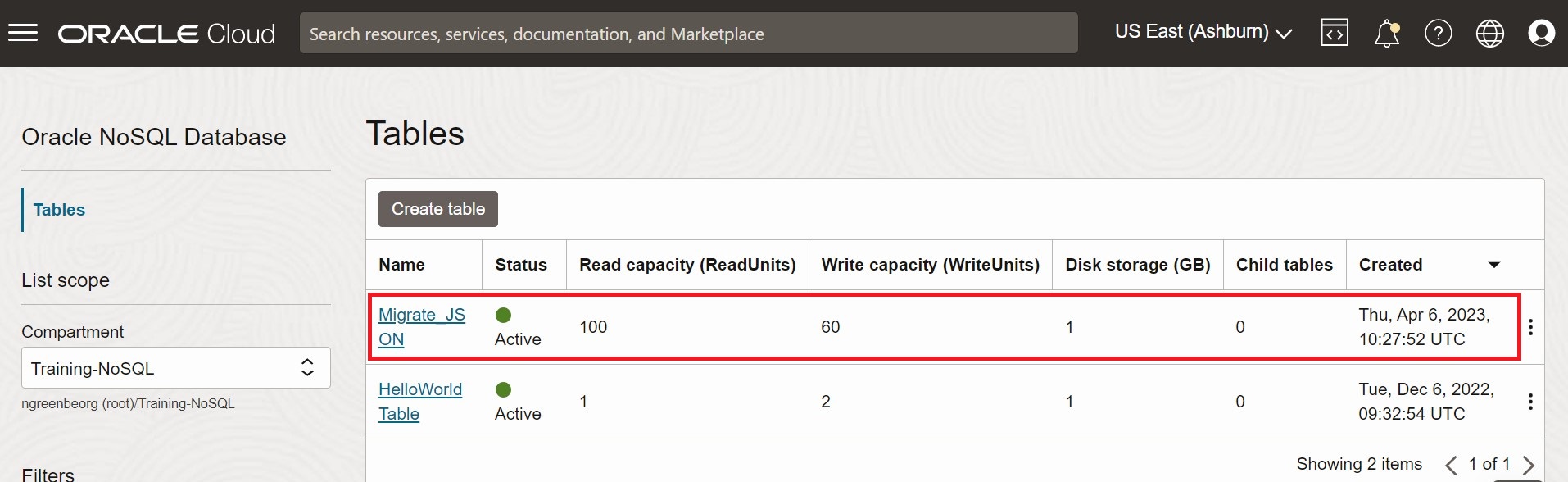
Descrição da ilustração migration_json1.png
Figura - Dados da Tabela da Console do Oracle NoSQL Database Cloud Service
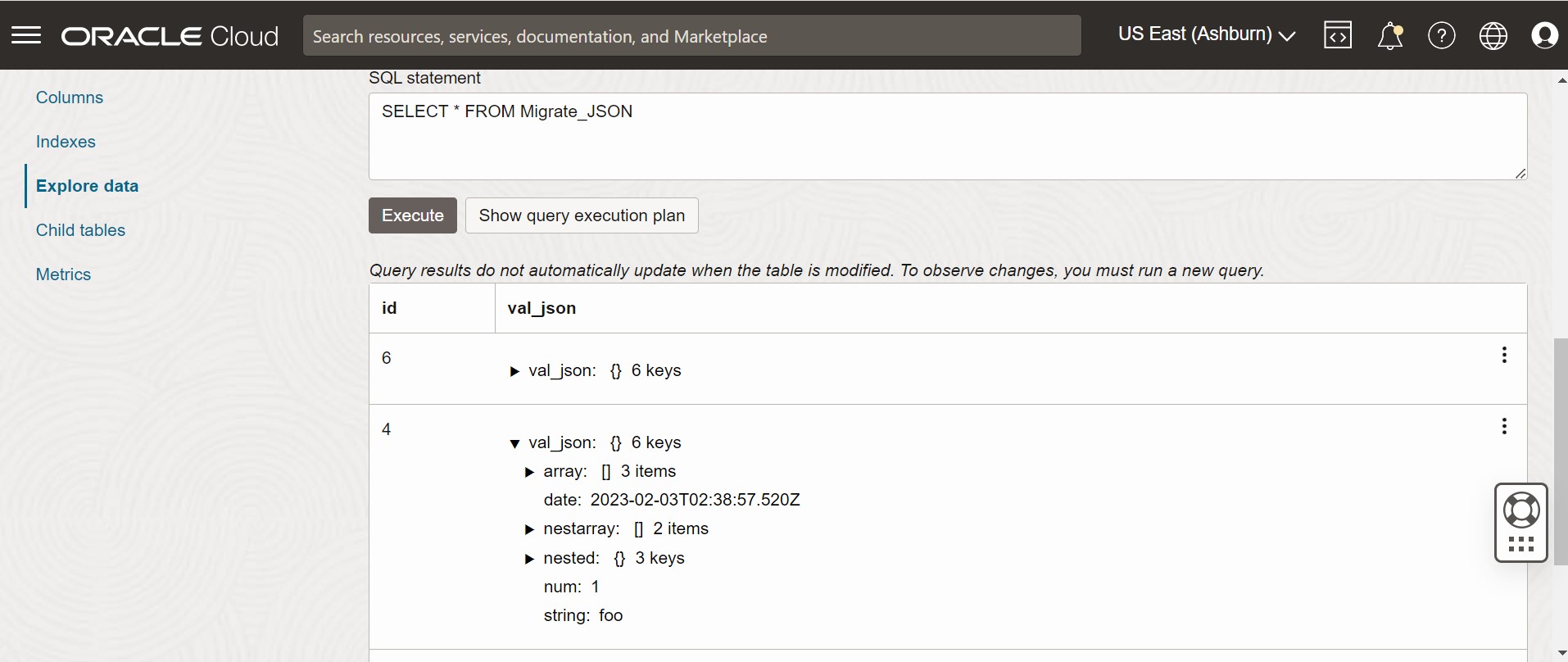
Descrição da ilustração migration_json2.png
Migrar do arquivo JSON do MongoDB para o Oracle NoSQL Database Cloud Service
Este exemplo mostra como usar o Migrador do Oracle NoSQL Database para copiar dados formatados pelo MongoDB para o Oracle NoSQL Database Cloud Service (NDCS).
Caso de Uso
Depois de avaliar várias opções, uma organização finaliza o Oracle NoSQL Database Cloud Service como sua plataforma NoSQL Database. As tabelas e os dados estão no MongoDB e a organização deseja migrar ambos para o Oracle NDCS.
Você pode copiar um arquivo ou diretório que contém os dados JSON exportados do MongoDB para migração especificando o arquivo ou diretório no modelo de configuração de origem.
Vamos considerar os dois arquivos JSON de amostra a seguir exportados do MongoDB para demonstrar nosso caso de uso.
Um exemplo de arquivo JSON formatado em MongoDB é o seguinte:
{"_id":0,"name":"Aimee Zank","scores":[{"score":1.463179736705023,"type":"exam"},{"score":11.78273309957772,"type":"quiz"},{"score":35.8740349954354,"type":"homework"}]}
{"_id":1,"name":"Aurelia Menendez","scores":[{"score":60.06045071030959,"type":"exam"},{"score":52.79790691903873,"type":"quiz"},{"score":71.76133439165544,"type":"homework"}]}
{"_id":2,"name":"Corliss Zuk","scores":[{"score":67.03077096065002,"type":"exam"},{"score":6.301851677835235,"type":"quiz"},{"score":66.28344683278382,"type":"homework"}]}
{"_id":3,"name":"Bao Ziglar","scores":[{"score":71.64343899778332,"type":"exam"},{"score":24.80221293650313,"type":"quiz"},{"score":42.26147058804812,"type":"homework"}]}
{"_id":4,"name":"Zachary Langlais","scores":[{"score":78.68385091304332,"type":"exam"},{"score":90.2963101368042,"type":"quiz"},{"score":34.41620148042529,"type":"homework"}]}Um exemplo de arquivo JSON formatado em MongoDB exportado de um aplicativo Spring é o seguinte:
{"_id":{"$oid":"63d3a87cf564fc21dac3838d"},"firstName":"John","lastName":"Smith","address":{"Country":"France"},"_class":"com.example.demo.Customer"}
{"_id":{"$oid":"63d3a87cf564fc21dac3838e"},"firstName":"Sam","lastName":"David","address":{"Country":"USA"},"_class":"com.example.demo.Customer"}
{"_id":"3","firstName":"Dona","lastName":"William","address":{"Country":"England"},"_class":"com.example.demo.Customer"}O MongoDB suporta dois tipos de extensões para os arquivos JSON formatados, Modo canônico e Modo relaxado. Você pode fornecer o arquivo JSON formatado em MongoDB que é gerado usando a ferramenta mongoexport no modo Canônico ou Relaxado. O NoSQL Database Migrator suporta os dois modos.
Para obter mais informações sobre o arquivo JSON estendido do MongoDB (v2), consulte mongoexport_formats.
Para obter mais informações sobre a geração de arquivo JSON formatado em MongoDB, consulte mongoexport.
Exemplo
Para a demonstração, vamos ver como migrar um arquivo JSON formatado no MongoDB para o NDCS. Usaremos um arquivo de configuração criado manualmente para este exemplo.
Pré-requisitos
-
Identifique a origem e o dissipador da migração.
-
Origem: Arquivo JSON formatado pelo MongoDB
-
Dissipador: Oracle NoSQL Database Cloud Service
-
- Extraia os dados do MongoDB usando o utilitário mongoexport. Consulte mongoexport.
-
Identifique suas credenciais da nuvem do OCI e as capture no arquivo de configuração do OCI. Salve o arquivo de configuração no diretório
/home/<user>/.oci/config. Para obter detalhes, consulte Adquirindo Credenciais.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Identifique o ponto final da região e o nome do compartimento do Oracle NoSQL Database Cloud Service.
-
ponto final:
us-ashburn-1 -
compartimento:
ocid1.compartment.oc1..aaaaaaaaadeskhnnfkenws4k2vdyklcc32hfpzzz4z3zum3ubhmpz6zxnoza
-
Procedimento
Para migrar os dados JSON formatados pelo MongoDB para o Oracle NoSQL Database Cloud Service, você pode escolher uma das seguintes opções:
-
Prepare o arquivo de configuração (no formato JSON) com os detalhes de Origem e Dissipador identificados. Consulte Modelos de Configuração de Origem e Modelos de Configuração do Separador.
Aqui, você define o parâmetro de configuração
defaultSchemacomo verdadeiro. Portanto, o NoSQL Database Migrator cria uma tabela com o esquema padrão no dissipador.{ "source" : { "type" : "file", "format" : "mongodb_json", "dataPath" : "<complete/path/to/the/MongoDB/Formatted/JSON/file>" }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "mongoImport", "compartment" : "ocid1.compartment.oc1..aaaaaaaaadeskhnnfkenws4k2vdyklcc32hfpzzz4z3zum3ubhmpz6zxnoza", "includeTTL" : false, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "defaultSchema" : true }, "credentials" : "<complete/path/to/the/oci/config/file>", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" }O esquema padrão para a origem de arquivo JSON formatada pelo MongoDB é o seguinte:
CREATE TABLE IF NOT EXISTS <tablename>(id STRING, document JSON,PRIMARY KEY(SHARD(id));Onde:
-
tablename= valor fornecido para o atributotablena configuração. -
id= O valor_idde cada documento do arquivo de origem JSON exportado pelo MongoDB. -
document= Para cada documento no arquivo exportado do MongoDB, o conteúdo excluindo o campo_idé agregado na colunadocument.
Observação: Se a tabela
<tablename>já existir no Oracle NoSQL Database Cloud Service e você quiser migrar dados para a tabela usando a configuraçãodefaultSchema, certifique-se de que a tabela existente tenha a coluna ID em letras minúsculas (id) e seja do tipo STRING. -
-
Abra o prompt de comando e navegue até o diretório em que você extraiu o utilitário NoSQL Database Migrator.
-
Execute o comando
runMigratorinformando o arquivo de configuração. Use a opção--configou-c.$./runMigrator --config <complete/path/to/the/JSON/config/file> -
O utilitário prossegue com a migração de dados, conforme mostrado abaixo.
[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [cloud sink] : start loading DDLs [INFO] [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS mongoImport (id STRING, document JSON, PRIMARY KEY(SHARD(id))),limits: [100, 60, 1] [INFO] [cloud sink] : completed loading DDLs [INFO] migration started [INFO] [mongo file source] : start parsing MongoDB JSON records from file: mongoDBSample.json [INFO] Migration success for source mongoDBSample. read=5,written=5,failed=0 [INFO] Migration is successful for all the sources. [INFO] migration completed. Records provided by source=5, Records written to sink=5, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 448ms Migration completed.
Verificação
Para verificar a migração, você pode fazer log-in na console do Oracle NoSQL Database Cloud Service e verificar se a tabela mongoImport foi criada com os dados de origem. Para ver o procedimento para acessar a console, consulte o artigo Acessando o Serviço na Console de Infraestrutura.
-
Prepare o arquivo de configuração (no formato JSON) com os detalhes de Origem e Dissipador identificados. Consulte Modelos de Configuração de Origem e Modelos de Configuração do Separador.
Aqui, você especifica o arquivo que contém a instrução DDL da tabela do sumidouro no parâmetro
schemaPathdo modelo de configuração de origem. De forma correspondente, defina o parâmetro de configuraçãouseSourceSchemacomo verdadeiro no modelo de configuração do sumidouro.Você pode gerar um esquema personalizado da seguinte forma:
-
Observe os nomes e os tipos de dados de cada coluna dos dados JSON formatados pelo MongoDB. Use essas informações para criar um arquivo DDL de esquema para a tabela do Oracle NoSQL Database Cloud Service.
-
No arquivo de esquema, nomeie a primeira coluna (chave primária) como
iddo tipo STRING. Inclua o mesmo nome e tipo para as colunas restantes conforme registrado no arquivo JSON formatado pelo MongoDB. -
Salve o arquivo de esquema e anote o caminho completo.
O esquema definido pelo usuário a seguir é usado neste exemplo:
CREATE TABLE IF NOT EXISTS sampleMongoDBImp (id STRING, name STRING, scores JSON, PRIMARY KEY(SHARD(id)));Você deve incluir uma transformação
renameFieldsinstruindo o NoSQL Database Migrator a converter a coluna_idemidao criar a tabela. Para obter detalhes do parâmetro, consulte Modelos de Configuração de Transformação. O NoSQL Database Migrator cria uma tabela com o esquema personalizado no dissipador.{ "source" : { "type" : "file", "format" : "mongodb_json", "schemaInfo" : { "schemaPath" : "<complete/path/to/the/schema/file>" }, "dataPath" : "<complete/path/to/the/MongoDB/Formatted/JSON/file>" }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "sampleMongoDBImp", "compartment" : "ocid1.compartment.oc1..aaaaaaaaadeskhnnfkenws4k2vdyklcc32hfpzzz4z3zum3ubhmpz6zxnoza", "includeTTL" : true, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "useSourceSchema" : true }, "credentials" : "<complete/path/to/the/oci/config/file>", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : false, "requestTimeoutMs" : 5000 }, "transforms": { "renameFields" : { "_id":"id" } }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
-
Abra o prompt de comando e navegue até o diretório em que você extraiu o utilitário NoSQL Database Migrator.
-
Execute o comando
runMigratorinformando o arquivo de configuração. Use a opção--configou-c.$./runMigrator --config <complete/path/to/the/JSON/config/file> -
O utilitário prossegue com a migração de dados, conforme mostrado abaixo.
[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [cloud sink] : start loading DDLs [INFO] [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS sampleMongoDBImp (id INTEGER, name STRING, scores JSON, PRIMARY KEY(SHARD(id))),limits: [100, 60, 1] [INFO] [cloud sink] : completed loading DDLs [INFO] migration started [INFO] [mongo file source] : start parsing MongoDB JSON records from file: mongoDBSample.json [INFO] Migration success for source mongoDBSample. read=5,written=5,failed=0 [INFO] Migration is successful for all the sources. [INFO] migration completed. Records provided by source=5, Records written to sink=5, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 438ms Migration completed.
Verificação
Para verificar a migração, você pode fazer log-in na console do Oracle NoSQL Database Cloud Service e verificar se a tabela sampleMongoDBImp foi criada com os dados de origem. Para ver o procedimento para acessar a console, consulte o artigo Acessando o Serviço na Console de Infraestrutura.
-
Para este caso de uso, usaremos o arquivo JSON formatado em MongoDB de amostra exportado de um aplicativo Spring como origem. Para obter mais detalhes sobre esse formato, consulte Dados do Spring.
-
Prepare o arquivo de configuração (no formato JSON) com os detalhes de Origem e Dissipador identificados. Consulte Modelos de Configuração de Origem e Modelos de Configuração do Separador.
Aqui, você especifica o arquivo que contém a instrução DDL da tabela do sumidouro no parâmetro
schemaPathdo modelo de configuração de origem. De forma correspondente, defina o parâmetro de configuraçãouseSourceSchemacomo verdadeiro no modelo de configuração do sumidouro.Você pode gerar um esquema personalizado da seguinte forma:
-
Observe os nomes e os tipos de dados de cada coluna dos dados JSON formatados pelo MongoDB.
-
No arquivo de esquema, nomeie a primeira coluna (chave primária) como
iddo tipo STRING. Agregue os campos restantes a um campo chamadokv_json_do tipo JSON, aderindo ao formato de dados do Spring. Para obter mais detalhes, consulte o Modelo de Persistência da estrutura de dados do spring. -
Salve o arquivo de esquema e anote o caminho completo.
O esquema definido pelo usuário a seguir é usado neste exemplo:
CREATE TABLE IF NOT EXISTS sampleMongoDBSpringImp(id STRING, kv_json_ JSON, PRIMARY KEY(SHARD(id)))Para a amostra de dados do Spring fornecida acima, você deve incluir as seguintes transformações:
-
Transformação
renameFieldspara converter a coluna_idemid -
Transformação
ignoreFieldspara ignorar a coluna_classe não incluí-la na tabela do dissipador -
Transformação
aggregateFieldspara agregar os campos restantes (excetoid) a um campo do tipo JSON
Para obter detalhes do parâmetro, consulte Modelos de Configuração de Transformação. O NoSQL Database Migrator cria uma tabela com o esquema personalizado no dissipador.
{ "source": { "type": "file", "format": "mongodb_json", "schemaInfo": { "schemaPath": "<complete/path/to/the/schema/file>" }, "dataPath": "<complete/path/to/the/MongoDB/Formatted/JSON/file>" }, "sink": { "type": "nosqldb_cloud", "endpoint": "us-ashburn-1", "table": "sampleMongoDBSpringImp", "compartment": "ocid1.compartment.oc1..aaaaaaaaadeskhnnfkenws4k2vdyklcc32hfpzzz4z3zum3ubhmpz6zxnoza", "includeTTL": true, "schemaInfo": { "readUnits": 100, "writeUnits": 60, "storageSize": 1, "useSourceSchema": true }, "credentials": "<complete/path/to/the/oci/config/file>", "credentialsProfile": "DEFAULT", "writeUnitsPercent": 90, "overwrite": false, "requestTimeoutMs": 5000 }, "transforms": { "renameFields": { "_id": "id" }, "ignoreFields": ["_class"], "aggregateFields": { "fieldName": "kv_json_", "skipFields": ["id"] } }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
-
Abra o prompt de comando e navegue até o diretório em que você extraiu o utilitário NoSQL Database Migrator.
-
Execute o comando
runMigratorinformando o arquivo de configuração. Use a opção--configou-c.$./runMigrator --config <complete/path/to/the/JSON/config/file> -
O utilitário prossegue com a migração de dados, conforme mostrado abaixo.
creating source from given configuration: source creation completed creating sink from given configuration: sink creation completed creating migrator pipeline [cloud sink] : start loading DDLs [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS sampleMongoDBSpringImp (id STRING, kv_json_ JSON, PRIMARY KEY(SHARD(id))),limits: [100, 60, 1] [cloud sink] : completed loading DDLs migration started [mongo file source] : start parsing MongoDB JSON records from file: mongodbspring.json Migration success for source mongodbspring. read=3,written=3,failed=0 Migration is successful for all the sources. migration completed. Records provided by source=3, Records written to sink=3, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 393ms Migration completed.
Verificação
Para verificar a migração, você pode fazer log-in na console do Oracle NoSQL Database Cloud Service e verificar se a tabela sampleMongoDBImp foi criada com os dados de origem. Para ver o procedimento para acessar a console, consulte o artigo Acessando o Serviço na Console de Infraestrutura.
Migrar do arquivo JSON do DynamoDB para o Oracle NoSQL Database Cloud Service
Este exemplo mostra como usar o Oracle NoSQL Database Migrator para copiar o arquivo JSON do DynamoDB para o NoSQL Database Cloud Service.
Caso de Uso
Depois de avaliar várias opções, uma organização finaliza o Oracle NoSQL Database Cloud Service pelo banco de dados DynamoDB. A organização deseja migrar suas tabelas e dados do DynamoDB para o Oracle NoSQL Database Cloud Service.
Consulte Mapeamento da tabela DynamoDB para a tabela do Oracle NoSQL para obter mais detalhes.
Você pode migrar um arquivo ou diretório contendo os dados JSON exportados do DynamoDB de um sistema de arquivos especificando o caminho no modelo de configuração de origem.
Um exemplo de Arquivo JSON formatado por DynamoDB é o seguinte:
{"Item":{"Id":{"N":"101"},"Phones":{"L":[{"L":[{"S":"555-222"},{"S":"123-567"}]}]},"PremierCustomer":{"BOOL":false},"Address":{"M":{"Zip":{"N":"570004"},"Street":{"S":"21 main"},"DoorNum":{"N":"201"},"City":{"S":"London"}}},"FirstName":{"S":"Fred"},"FavNumbers":{"NS":["10"]},"LastName":{"S":"Smith"},"FavColors":{"SS":["Red","Green"]},"Age":{"N":"22"},"ttl": {"N": "1734616800"}}}
{"Item":{"Id":{"N":"102"},"Phones":{"L":[{"L":[{"S":"222-222"}]}]},"PremierCustomer":{"BOOL":false},"Address":{"M":{"Zip":{"N":"560014"},"Street":{"S":"32 main"},"DoorNum":{"N":"1024"},"City":{"S":"Wales"}}},"FirstName":{"S":"John"},"FavNumbers":{"NS":["10"]},"LastName":{"S":"White"},"FavColors":{"SS":["Blue"]},"Age":{"N":"48"},"ttl": {"N": "1734616800"}}}Você exporta a tabela DynamoDB para o armazenamento do AWS S3 conforme especificado em Exportando dados da tabela DynamoDB para o Amazon S3.
Exemplo
Para esta demonstração, você aprenderá a migrar um arquivo JSON do DynamoDB para o Oracle NoSQL Database Cloud Service. Você usará um arquivo de configuração criado manualmente para este exemplo.
Pré-requisitos
-
Identifique a origem e o dissipador da migração.
-
Origem: Arquivo JSON do DynamoDB
-
Pia: Oracle NoSQL Database Cloud Service
-
-
Para importar dados de tabela do DynamoDB para o Oracle NoSQL Database, você deve primeiro exportar a tabela do DynamoDB para o S3. Consulte as etapas fornecidas em Exportando dados da tabela DynamoDB para o Amazon S3 para exportar sua tabela. Durante a exportação, você seleciona o formato como DynamoDB JSON. Os dados exportados contêm dados da tabela DynamoDB em vários arquivos
gzip, conforme mostrado abaixo./ 01639372501551-bb4dd8c3 |-- 01639372501551-bb4dd8c3 ==> exported data prefix |----data |------sxz3hjr3re2dzn2ymgd2gi4iku.json.gz ==>table data |----manifest-files.json |----manifest-files.md5 |----manifest-summary.json |----manifest-summary.md5 |----_started -
Você deve fazer download dos arquivos do AWS S3. A estrutura dos arquivos após o download será como mostrado abaixo.
download-dir/01639372501551-bb4dd8c3 |----data |------sxz3hjr3re2dzn2ymgd2gi4iku.json.gz ==>table data |----manifest-files.json |----manifest-files.md5 |----manifest-summary.json |----manifest-summary.md5 |----_started -
Identifique suas credenciais da nuvem do OCI e as capture no arquivo de configuração do OCI. Salve o arquivo de configuração no diretório
/home/<user>/.oci/config. Para obter mais detalhes, consulte Adquirindo Credenciais no Usando o Oracle NoSQL Database Cloud Service.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... region=us-ashburn-1 key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Identifique o ponto final da região e o nome do compartimento do Oracle NoSQL Database Cloud Service.
-
ponto final:
us-ashburn-1 -
compartimento:
Training-NoSQL
-
Procedimento
Para migrar os dados JSON do DynamoDB para o Oracle NoSQL Database:
-
Prepare o arquivo de configuração (no formato JSON) com os detalhes de origem e sumidouro identificados. Para obter detalhes, consulte Modelos de Configuração de Origem e Modelos de Configuração do Separador.
Observação: Se os itens da tabela JSON exportados do DynamoDB contiverem o atributo TTL, para opcionalmente importar os valores de TTL, especifique o atributo no parâmetro de configuração
ttlAttributeNamedo modelo de configuração de origem e defina o parâmetro de configuraçãoincludeTTLcomo verdadeiro no modelo de configuração do sumidouro. Para obter mais detalhes, consulte Migrando Metadados TTL para Linhas de Tabela.Aqui, você define o parâmetro de configuração
defaultSchemacomo verdadeiro. Portanto, o NoSQL Database Migrator cria o esquema padrão no coletor. Especifique oDDBPartitionKeye o tipo de coluna NoSQL correspondente. Caso contrário, um erro será exibido.Para obter detalhes sobre o esquema padrão de uma origem JSON exportada do DynamoDB, consulte o tópico Identificar Origem e Dissipar no Workflow para o Oracle NoSQL Data Migrator.
{ "source" : { "type" : "file", "format" : "dynamodb_json", "ttlAttributeName" : "ttl", "dataPath" : "complete/path/to/the/DynamoDB/Formatted/JSON/file" }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-sanjose-1", "table" : "sampledynDBImp", "compartment" : "ocid 1.compartment.oc1..aaaaaaaa......smq", "includeTTL" : true, "schemaInfo" : { "readUnits" : 10, "writeUnits" : 10, "storageSize" : 1, "schemaPath" : "complete/path/to/the/DDl/file" }, "credentials" : "/home/<username>/.oci/config", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" }O seguinte esquema padrão é usado neste exemplo:
CREATE TABLE IF NOT EXISTS sampledynDBImp (Id INTEGER, document JSON, PRIMARY KEY(SHARD(Id))) -
Abra o prompt de comando e navegue até o diretório em que você extraiu o utilitário NoSQL Database Migrator.
-
Execute o comando
runMigratorespecificando arquivos de configuração separados. Use a opção--configou-c../runMigrator --config <complete/path/to/the/JSON/config/file> -
O utilitário prossegue com a migração de dados, conforme ilustrado na seguinte amostra:
[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [cloud sink] : start loading DDLs [INFO] [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS sampledynDBImp (Id INTEGER, document JSON, PRIMARY KEY(SHARD(Id))) [INFO] [cloud sink] : completed loading DDLs [INFO] migration started [INFO] Start writing data to OnDB Sink [INFO] executing for source:DynamoSample [INFO] [DDB file source] : start parsing JSON records from file: DynamoSample.json.gz [INFO] Writing data to OnDB Sink completed. [INFO] migration completed. Records provided by source=2, Records written to sink=2, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 45ms Migration completed.
Verificação
Para validar a migração, você pode fazer log-in na console do Oracle NoSQL Database Cloud Service e verificar se a tabela sampledynDBImp foi criada com os dados de origem.
-
Prepare o arquivo de configuração (no formato JSON) com os detalhes de origem e sumidouro identificados. Para obter detalhes, consulte Modelos de Configuração de Origem e Modelos de Configuração do Separador.
Observação: Se os itens da tabela JSON exportados do DynamoDB contiverem o atributo TTL, para opcionalmente importar os valores de TTL, especifique o atributo no parâmetro de configuração
ttlAttributeNamedo modelo de configuração de origem e defina o parâmetro de configuraçãoincludeTTLcomo verdadeiro no modelo de configuração do sumidouro.Aqui, você define o parâmetro de configuração
defaultSchemacomo falso. Portanto, você especifica o arquivo que contém a instrução DDL da tabela do sumidouro no parâmetroschemaPath. Consulte Mapeamento de tipos DynamoDB para tipos Oracle NoSQL para obter mais detalhes.O esquema definido pelo usuário a seguir é usado neste exemplo:
CREATE TABLE IF NOT EXISTS sampledynDBImp (Id INTEGER, document JSON, PRIMARY KEY(SHARD(Id)))O NoSQL Database Migrator usa o arquivo de esquema para criar a tabela na pia como parte da migração. Desde que os dados da chave primária sejam fornecidos, o registro JSON de entrada será inserido. Caso contrário, um erro será exibido.
Observação:
-
Se a tabela de BD Dynamo tiver um tipo de dados não suportado no Banco de Dados NoSQL, a migração falhará.
-
Se os dados de entrada não contiverem um valor para uma coluna específica (exceto a chave primária), o valor padrão da coluna será usado. O valor padrão deve fazer parte da definição de coluna ao criar a tabela. Por exemplo,
id INTEGER not null default 0. Se a coluna não tiver uma definição padrão, SQL NULL será inserido se os valores não forem fornecidos para a coluna. -
Se você estiver modelando a tabela DynamoDB como um documento JSON, certifique-se de usar a transformação
AggregateFieldspara agregar dados de chave não principais em uma coluna JSON. Para obter detalhes, consulte aggregateFields
Generated configuration is { "source" : { "type" : "file", "format" : "dynamodb_json", "ttlAttributeName" : "ttl", "dataPath" : "complete/path/to/the/DynamoDB/Formatted/JSON/file" }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-sanjose-1", "table" : "sampledynDBImp", "compartment" : "ocid 1.compartment.oc1..aaaaaaaa......smq", "includeTTL" : true, "schemaInfo" : { "readUnits" : 10, "writeUnits" : 10, "storageSize" : 1, "schemaPath" : "complete/path/to/the/DDl/file" }, "credentials" : "/home/<username>/.oci/config", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
-
Abra o prompt de comando e navegue até o diretório em que você extraiu o utilitário NoSQL Database Migrator.
-
Execute o comando
runMigratorespecificando arquivos de configuração separados. Use a opção--configou-c../runMigrator --config <complete/path/to/the/JSON/config/file> -
O utilitário prossegue com a migração de dados, conforme ilustrado na seguinte amostra:
[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [cloud sink] : start loading DDLs [INFO] [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS sampledynDBImp (Id INTEGER, document JSON, PRIMARY KEY(SHARD(Id))) [INFO] [cloud sink] : completed loading DDLs [INFO] migration started [INFO] Start writing data to OnDB Sink [INFO] executing for source:DynamoSample [INFO] [DDB file source] : start parsing JSON records from file: DynamoSample.json.gz [INFO] Writing data to OnDB Sink completed. [INFO] migration completed. Records provided by source=2, Records written to sink=2, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 45ms Migration completed.
Verificação
Para validar a migração, você pode fazer log-in na console do Oracle NoSQL Database Cloud Service e verificar se a tabela sampledynDBImp foi criada com os dados de origem.
Migrar do arquivo JSON do DynamoDB no AWS S3 para o Oracle NoSQL Database Cloud Service
Este exemplo mostra como usar o Oracle NoSQL Database Migrator para copiar o arquivo JSON do DynamoDB armazenado em um armazenamento do AWS S3 para o Oracle NoSQL Database Cloud Service (NDCS).
Caso de Uso:
Depois de avaliar várias opções, uma organização finaliza o Oracle NoSQL Database Cloud Service pelo banco de dados DynamoDB. A organização deseja migrar suas tabelas e dados do DynamoDB para o Oracle NoSQL Database Cloud Service.
Consulte Mapeamento da tabela DynamoDB para a tabela do Oracle NoSQL para obter mais detalhes.
Você pode migrar um arquivo que contenha os dados JSON exportados do DynamoDB do armazenamento do AWS S3 especificando o caminho no modelo de configuração de origem.
Um exemplo de Arquivo JSON formatado por DynamoDB é o seguinte:
{"Item":{"Id":{"N":"101"},"Phones":{"L":[{"L":[{"S":"555-222"},{"S":"123-567"}]}]},"PremierCustomer":{"BOOL":false},"Address":{"M":{"Zip":{"N":"570004"},"Street":{"S":"21 main"},"DoorNum":{"N":"201"},"City":{"S":"London"}}},"FirstName":{"S":"Fred"},"FavNumbers":{"NS":["10"]},"LastName":{"S":"Smith"},"FavColors":{"SS":["Red","Green"]},"Age":{"N":"22"}}}
{"Item":{"Id":{"N":"102"},"Phones":{"L":[{"L":[{"S":"222-222"}]}]},"PremierCustomer":{"BOOL":false},"Address":{"M":{"Zip":{"N":"560014"},"Street":{"S":"32 main"},"DoorNum":{"N":"1024"},"City":{"S":"Wales"}}},"FirstName":{"S":"John"},"FavNumbers":{"NS":["10"]},"LastName":{"S":"White"},"FavColors":{"SS":["Blue"]},"Age":{"N":"48"}}}Você exporta a tabela DynamoDB para o armazenamento do AWS S3 conforme especificado em Exportando dados da tabela DynamoDB para o Amazon S3.
Exemplo:
Para esta demonstração, você aprenderá a migrar um arquivo JSON do DynamoDB em uma origem do AWS S3 para o NDCS. Você usará um arquivo de configuração criado manualmente para este exemplo.
Pré-requisitos
-
Identifique a origem e o dissipador da migração.
-
Fonte:DynamoDB JSON File no AWS S3
-
Dissipador: Oracle NoSQL Database Cloud Service
-
-
Identifique a tabela no AWS DynamoDB que precisa ser migrada para o NDCS. Faça login no console da AWS usando suas credenciais. Vá para DynamoDB. Em Tabelas, escolha a tabela a ser migrada.
-
Crie um bucket de objetos e exporte a tabela para o S3. No console da AWS, acesse o S3. Em buckets, crie um novo bucket de objeto. Volte para o DynamoDB e clique em Exportações para S3. Forneça a tabela de origem e o bucket do S3 de destino e clique em Exportar.
Para exportar sua tabela, consulte as etapas fornecidas em Exportando dados da tabela DynamoDB para o Amazon S3. Durante a exportação, você seleciona o formato como JSON do DynamoDB. Os dados exportados contêm dados da tabela DynamoDB em vários arquivos
gzip, conforme mostrado abaixo./ 01639372501551-bb4dd8c3 |-- 01639372501551-bb4dd8c3 ==> exported data prefix |----data |------sxz3hjr3re2dzn2ymgd2gi4iku.json.gz ==>table data |----manifest-files.json |----manifest-files.md5 |----manifest-summary.json |----manifest-summary.md5 |----_started -
Você precisa de credenciais do AWS (incluindo ID de chave de acesso e chave de acesso secreto) e arquivos de configuração (credenciais e, opcionalmente, configuração) para acessar o AWS S3 no NoSQL Database Migrator. Consulte Definir e exibir definições de configuração para obter mais detalhes sobre os arquivos de configuração. Consulte Criando um par de chaves para obter mais detalhes sobre a criação de chaves de acesso.
-
Identifique suas credenciais da nuvem do OCI e as capture no arquivo de configuração do OCI. Salve o arquivo de configuração em um diretório
.ocino diretório home (~/.oci/config). Consulte Adquirindo Credenciais para obter mais detalhes.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Identifique o ponto final da região e o nome do compartimento do Oracle NoSQL Database Cloud Service. Por exemplo,
-
ponto final:us-phoenix-1
-
compartimento: desenvolvedores
-
Procedimento
Para migrar os dados JSON do DynamoDB para o Oracle NoSQL Database Cloud Service, use uma das seguintes opções:
-
Prepare o arquivo de configuração (no formato JSON) com os detalhes de origem e sumidouro identificados. Para obter detalhes, consulte Modelos de Configuração de Origem e Modelos de Configuração do Separador.
Observação: Se os itens do Arquivo JSON do DynamoDB no AWS S3 contiverem o atributo TTL, para importar opcionalmente os valores de TTL, especifique o atributo no parâmetro de configuração
ttlAttributeNamedo modelo de configuração de origem e defina o parâmetro de configuraçãoincludeTTLcomo verdadeiro no modelo de configuração do sumidouro. Para obter mais detalhes, consulte Migrando Metadados TTL para Linhas de Tabela.Defina
defaultSchemacomoTRUEe, portanto, o utilitário Migrator cria o esquema padrão no coletor. Especifique oDDBPartitionKeye o tipo de coluna NoSQL correspondente. Caso contrário, um erro será gerado.{ "source" : { "type" : "aws_s3", "format" : "dynamodb_json", "s3URL" : "<https://<bucket-name>.<s3_endpoint>/export_path>", "credentials" : "</path/to/aws/credentials/file>", "credentialsProfile" : <"profile name in aws credentials file"> }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "<region_name>", "table" : "<table_name>", "compartment" : "<compartment_name>", "schemaInfo" : { "defaultSchema" : true, "readUnits" : 100, "writeUnits" : 60, "DDBPartitionKey" : "<PrimaryKey:Datatype>", "storageSize" : 1 }, "credentials" : "<complete/path/to/the/oci/config/file>", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" }Para uma origem JSON do DynamoDB, o esquema padrão da tabela será o mostrado abaixo:
CREATE TABLE IF NOT EXISTS <TABLE_NAME>(DDBPartitionKey_name DDBPartitionKey_type, [DDBSortKey_name DDBSortKey_type], DOCUMENT JSON, PRIMARY KEY(SHARD(DDBPartitionKey_name),[DDBSortKey_name]))Onde:
TABLE_NAME = valor fornecido para a 'tabela' do sumidouro na configuração
DDBPartitionKey_name = valor fornecido para a chave de partição na configuração
DDBPartitionKey_type = valor fornecido para o tipo de dados da chave de partição na configuração
DDBSortKey_name = valor fornecido para a chave de classificação na configuração, se houver
DDBSortKey_type = valor fornecido para o tipo de dados da chave de classificação na configuração, se houver
DOCUMENT = Todos os atributos, exceto a chave de partição e classificação de um item de tabela do BD Dynamo agregado em uma coluna JSON NoSQL
-
Abra o prompt de comando e navegue até o diretório em que você extraiu o utilitário NoSQL Database Migrator.
-
Execute o comando
runMigratorinformando o arquivo de configuração. Use a opção--configou-c.[~/nosqlMigrator]$./runMigrator --config <complete/path/to/the/JSON/config/file> -
O utilitário prossegue com a migração de dados, conforme mostrado abaixo.
Records provided by source=7.., Records written to sink=7, Records failed=0, Records skipped=0. Elapsed time: 0 min 2sec 50ms Migration completed.
Verificação
Você pode fazer log-in na console do Oracle NoSQL Database Cloud Service e verificar se a nova tabela foi criada com os dados de origem.
-
Prepare o arquivo de configuração (no formato JSON) com os detalhes de origem e sumidouro identificados. Para obter detalhes, consulte Modelos de Configuração de Origem e Modelos de Configuração do Separador.
Observação: Se os itens do Arquivo JSON do DynamoDB no AWS S3 contiverem o atributo TTL, para importar opcionalmente os valores de TTL, especifique o atributo no parâmetro de configuração ttlAttributeName do modelo de configuração de origem e defina o parâmetro de configuração includeTTL como verdadeiro no modelo de configuração do sumidouro. Para obter mais detalhes, consulte Migrando Metadados TTL para Linhas de Tabela.
Para especificar um arquivo de esquema definido pelo usuário no modelo de configuração do coletor, defina defaultSchema como
FALSEe especifique o schemaPath como um arquivo que contenha sua instrução DDL. Para obter detalhes, consulte Mapeamento de tipos DynamoDB para tipos Oracle NoSQL.Observação: Se a tabela do banco de dados Dynamo tiver um tipo de dados não suportado no NoSQL, a migração falhará.
Um exemplo de arquivo de esquema é mostrado abaixo.
CREATE TABLE IF NOT EXISTS sampledynDBImp (AccountId INTEGER,document JSON, PRIMARY KEY(SHARD(AccountId)));O arquivo de esquema é usado para criar a tabela na pia como parte da migração. Desde que os dados da chave primária sejam fornecidos, o registro JSON de entrada será inserido, caso contrário, ele gerará um erro.
Observação:
- Se os dados de entrada não contiverem um valor para uma determinada coluna (exceto a chave primária), o valor padrão da coluna será usado. O valor padrão deve fazer parte da definição de coluna ao criar a tabela. Por exemplo,
id INTEGER not null default 0. Se a coluna não tiver uma definição padrão, o SQL NULL será inserido se nenhum valor for fornecido para a coluna. - Se você estiver modelando a tabela DynamoDB como um documento JSON, certifique-se de usar a transformação
AggregateFieldspara agregar dados de chave não principais em uma coluna JSON. Para obter detalhes, consulte aggregateFields.
{ "source" : { "type" : "aws_s3", "format" : "dynamodb_json", "s3URL" : "<https://<bucket-name>.<s3_endpoint>/export_path>", "credentials" : "</path/to/aws/credentials/file>", "credentialsProfile" : <"profile name in aws credentials file"> }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "<region_name>", "table" : "<table_name>", "compartment" : "<compartment_name>", "schemaInfo" : { "defaultSchema" : false, "readUnits" : 100, "writeUnits" : 60, "schemaPath" : "<full path of the schema file with the DDL statement>", "storageSize" : 1 }, "credentials" : "<complete/path/to/the/oci/config/file>", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "requestTimeoutMs" : 5000 }, "transforms": { "aggregateFields" : { "fieldName" : "document", "skipFields" : ["AccountId"] } }, "abortOnError" : true, "migratorVersion" : "1.8.0" } - Se os dados de entrada não contiverem um valor para uma determinada coluna (exceto a chave primária), o valor padrão da coluna será usado. O valor padrão deve fazer parte da definição de coluna ao criar a tabela. Por exemplo,
-
Abra o prompt de comando e navegue até o diretório em que você extraiu o utilitário NoSQL Database Migrator.
-
Execute o comando
runMigratorinformando o arquivo de configuração. Use a opção--configou-c.[~/nosqlMigrator]$./runMigrator --config <complete/path/to/the/JSON/config/file> -
O utilitário prossegue com a migração de dados, conforme mostrado abaixo.
Records provided by source=7.., Records written to sink=7, Records failed=0, Records skipped=0. Elapsed time: 0 min 2sec 50ms Migration completed.
Verificação
Você pode fazer log-in na console do Oracle NoSQL Database Cloud Service e verificar se a nova tabela foi criada com os dados de origem.
Migrar entre regiões do Oracle NoSQL Database Cloud Service
Este exemplo mostra o uso do Oracle NoSQL Database Migrator para executar a migração entre regiões.
Uso do caso
Uma organização usa o Oracle NoSQL Database Cloud Service para armazenar e gerenciar seus dados. Ele decide replicar dados de uma região existente para uma região mais recente para fins de teste antes que a nova região possa ser iniciada para o ambiente de produção.
Nesse caso de uso, você aprenderá a usar o NoSQL Database Migrator para copiar dados da tabela user_data na região Ashburn para a região Phoenix.
Você executa o utilitário runMigrator especificando um arquivo de configuração pré-criado. Se você não fornecer o arquivo de configuração como um parâmetro de runtime, o utilitário runMigrator solicitará que você gere a configuração por meio de um procedimento interativo.
Pré-requisitos
-
Faça download do Oracle NoSQL Database Migrator na página Downloads do Oracle NoSQL e extraia o conteúdo para sua máquina. Para obter detalhes, consulte Workflow do Oracle NoSQL Database Migrator.
-
Identifique a origem e o dissipador da migração.
-
Origem: A tabela
user_datana região Ashburn.A tabela
user_datainclui os seguintes dados:{"id":40,"firstName":"Joanna","lastName":"Smith","otherNames":[{"first":"Joanna","last":"Smart"}],"age":null,"income":75000,"address":{"city":"Houston","number":401,"phones":[{"area":null,"kind":"work","number":1618955},{"area":451,"kind":"home","number":4613341},{"area":481,"kind":"mobile","number":4613382}],"state":"TX","street":"Tex Ave","zip":95085},"connections":[70,30,40],"email":"joanna.smith123@reachmail.com","communityService":"**"} {"id":10,"firstName":"John","lastName":"Smith","otherNames":[{"first":"Johny","last":"Good"},{"first":"Johny2","last":"Brave"},{"first":"Johny3","last":"Kind"},{"first":"Johny4","last":"Humble"}],"age":22,"income":45000,"address":{"city":"Santa Cruz","number":101,"phones":[{"area":408,"kind":"work","number":4538955},{"area":831,"kind":"home","number":7533341},{"area":831,"kind":"mobile","number":7533382}],"state":"CA","street":"Pacific Ave","zip":95008},"connections":[30,55,43],"email":"john.smith@reachmail.com","communityService":"****"} {"id":20,"firstName":"Jane","lastName":"Smith","otherNames":[{"first":"Jane","last":"BeGood"}],"age":22,"income":55000,"address":{"city":"San Jose","number":201,"phones":[{"area":608,"kind":"work","number":6538955},{"area":931,"kind":"home","number":9533341},{"area":931,"kind":"mobile","number":9533382}],"state":"CA","street":"Atlantic Ave","zip":95005},"connections":[40,75,63],"email":"jane.smith201@reachmail.com","communityService":"*****"} {"id":30,"firstName":"Adam","lastName":"Smith","otherNames":[{"first":"Adam","last":"BeGood"}],"age":45,"income":75000,"address":{"city":"Houston","number":301,"phones":[{"area":618,"kind":"work","number":6618955},{"area":951,"kind":"home","number":9613341},{"area":981,"kind":"mobile","number":9613382}],"state":"TX","street":"Indian Ave","zip":95075},"connections":[60,45,73],"email":"adam.smith201reachmail.com","communityService":"***"}Identifique o ponto final da região ou o ponto final de serviço e o nome do compartimento para sua origem.
-
ponto final:
us-ashburn-1 -
compartimento:
ocid1.compartment.oc1..aaaaaaaahcrgrgptoaq4cgpoymd32ti2ql4sdpu5puroausdf4og55z4tnya
-
-
Dissipador: A tabela
user_datana região Phoenix.Identifique o ponto final da região ou o ponto final do serviço e o nome do compartimento do seu dissipador.
-
ponto final:
us-phoenix-1 -
compartimento:
ocid1.compartment.oc1..aaaaaaaaleiwplazhwmicoogv3tf4lum4m4nzbcv5wfjmoxuz3doreagvdma
Identifique o esquema da tabela sumidoura.
Você pode usar o mesmo nome de tabela e esquema que a tabela de origem. Para obter informações sobre outras opções de esquema, consulte o tópico Identificar a Origem e o Dissipador no Workflow para o Oracle NoSQL Database Migrator
-
-
-
Identifique suas credenciais de nuvem do OCI para ambas as regiões e as capture no arquivo de configuração. Salve o arquivo de configuração em sua máquina no local
/home/<user>/.oci/config. Para obter mais detalhes, consulte Adquirindo Credenciais.Observação:
-
Se as regiões estiverem em tenancies diferentes, você deverá fornecer perfis diferentes no arquivo
/home//.oci/configcom as credenciais de nuvem apropriadas do OCI para cada uma delas. -
Se as regiões estiverem na mesma tenancy, você poderá ter um único perfil no arquivo
/home//.oci/config.
-
Neste exemplo, as regiões estão em diferentes tenancies. O perfil DEFAULT inclui credenciais do OCI para a região Ashburn e DEFAULT2 inclui credenciais do OCI para a região Phoenix.
No parâmetro endpoint do arquivo de configuração do migrador (modelos de configuração de origem e de sumidouro), você pode fornecer o URL do ponto final do serviço ou o ID da região das regiões. Para obter a lista de regiões de dados suportadas para o Oracle NoSQL Database Cloud Service e seus URLs de ponto final de serviço, consulte Regiões de Dados e URLs de Serviço Associados no documento do Oracle NoSQL Database Cloud Service.
[DEFAULT]
user=ocid1.user.oc1....
fingerprint=fd:96:....
tenancy=ocid1.tenancy.oc1....
region=us-ashburn-1
key_file=</fully/qualified/path/to/the/private/key/>
pass_phrase=abcd
[DEFAULT2]
user=ocid1.user.oc1....
fingerprint=1b:68:....
tenancy=ocid1.tenancy.oc1....
region=us-phoenix-1
key_file=</fully/qualified/path/to/the/private/key/>
pass_phrase=23456Procedimento
Para migrar a tabela user_data da região Ashburn para a região Phoenix, execute o seguinte:
-
Prepare o arquivo de configuração (no formato JSON) com os detalhes de origem e sumidouro identificados. Consulte Modelos de Configuração de Origem e Modelos de Configuração do Separador.
{ "source" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "user_data", "compartment" : "ocid1.compartment.oc1..aaaaaaaahcrgrgptoaq4cgpoymd32ti2ql4sdpu5puroausdf4og55z4tnya", "credentials" : "/home/<user>/.oci/config", "credentialsProfile" : "DEFAULT", "readUnitsPercent" : 100, "includeTTL" : false, "requestTimeoutMs" : 5000 }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-phoenix-1", "table" : "user_data", "compartment" : "ocid1.compartment.oc1..aaaaaaaaleiwplazhwmicoogv3tf4lum4m4nzbcv5wfjmoxuz3doreagvdma", "includeTTL" : false, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "useSourceSchema" : true }, "credentials" : "/home/<user>/.oci/config", "credentialsProfile" : "DEFAULT2", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Na sua máquina, navegue até o diretório em que você extraiu o utilitário NoSQL Database Migrator. Você pode acessar o comando
runMigratorna interface de linha de comando. -
Execute o comando
runMigratorespecificando o arquivo de configuração usando a opção –config ou -c.[~/nosql-migrator]$./runMigrator --config <complete/path/to/the/config/file> -
O utilitário prossegue com a migração de dados, conforme mostrado abaixo. A tabela
user_dataé criada no dissipador com o mesmo esquema da tabela de origem que você configurou o parâmetro useSourceSchema como verdadeiro no modelo de configuração do dissipador.creating source from given configuration: source creation completed creating sink from given configuration: sink creation completed creating migrator pipeline migration started [cloud sink] : start loading DDLs [cloud sink] : executing DDL: CREATE TABLE IF NOT EXISTS user_data (id INTEGER, firstName STRING, lastName STRING, otherNames ARRAY(RECORD(first STRING, last STRING)), age INTEGER, income INTEGER, address JSON, connections ARRAY(INTEGER), email STRING, communityService STRING, PRIMARY KEY(SHARD(id))),limits: [100, 60, 1] [cloud sink] : completed loading DDLs [cloud sink] : start loading records migration completed. Records provided by source=5, Records written to sink=5, Records failed=0, Records skipped=0. Elapsed time: 0min 5sec 603ms Migration completed.Observação:
-
Se a tabela já existir no sumidouro com o mesmo esquema que a tabela de origem, as linhas com as mesmas chaves primárias serão substituídas, pois você forneceu o parâmetro de substituição como verdadeiro no modelo de configuração.
-
Se a tabela já existir no dissipador com um esquema diferente da tabela de origem, a migração falhará.
-
Validação
Para validar a migração, você pode fazer log-in na console do Oracle NoSQL Database Cloud Service na região Phoenix. Verifique se os dados de origem da tabela user_data na região Ashburn foram copiados para a tabela user_data nesta região. Para ver o procedimento para acessar a console, consulte o artigo Acessando o Serviço na Console de Infraestrutura.
Migrar do Oracle NoSQL Database Cloud Service para o OCI Object Storage
Este exemplo mostra o uso do Oracle NoSQL Database Migrator de um Cloud Shell.
Uso do caso
Uma start-up venture planeja usar o Oracle NoSQL Database Cloud Service como sua solução de armazenamento de dados. A empresa deseja usar o Oracle NoSQL Database Migrator para copiar dados de uma tabela no Oracle NoSQL Database Cloud Service para o OCI Object Storage para fazer backups periódicos de seus dados. Como medida econômica, a empresa deseja executar o utilitário NoSQL Database Migrator no Cloud Shell, que pode ser acessado por todos os usuários do OCI.
Nesse caso de uso, você aprenderá a copiar o utilitário NoSQL Database Migrator para um Cloud Shell na região inscrita e executar uma migração de dados. Você migra os dados de origem da tabela do Oracle NoSQL Database Cloud Service para um arquivo JSON no OCI Object Storage.
Você executa o utilitário runMigrator especificando um arquivo de configuração pré-criado. Se você não fornecer o arquivo de configuração como um parâmetro de runtime, o utilitário runMigrator solicitará que você gere a configuração por meio de um procedimento interativo.
Pré-requisitos
-
Faça download do Oracle NoSQL Database Migrator na página Downloads do Oracle NoSQL para sua máquina local.
-
Inicie o Cloud Shell no menu Ferramentas do desenvolvedor na console da nuvem. O Web browser abre o diretório home. Clique no menu do Cloud Shell no canto superior direito da janela do Cloud Shell e selecione a opção upload na lista drop-down. Na janela pop-up, arraste e solte o pacote do Oracle NoSQL Database Migrator da sua máquina local ou clique na opção Selecionar do seu computador, selecione o pacote da sua máquina local e clique no botão Fazer Upload. Você também pode arrastar e soltar o pacote do Oracle NoSQL Database Migrator diretamente da sua máquina local para o diretório home no Cloud Shell. Extraia o conteúdo do pacote.
-
Identifique a origem e o sumidouro do backup.
-
Origem: tabela
NDCSuploadna região Ashburn do Oracle NoSQL Database Cloud Service.Para demonstração, considere os seguintes dados na tabela
NDCSupload:{"id":1,"name":"Jane Smith","email":"iamjane@somemail.co.us","age":30,"income":30000.0} {"id":2,"name":"Adam Smith","email":"adam.smith@mymail.com","age":25,"income":25000.0} {"id":3,"name":"Jennifer Smith","email":"jenny1_smith@mymail.com","age":35,"income":35000.0} {"id":4,"name":"Noelle Smith","email":"noel21@somemail.co.us","age":40,"income":40000.0}Identifique o ID do ponto final e do compartimento para sua origem. Para o ponto final, você pode fornecer o identificador da região ou o ponto final do serviço. Para obter a lista de regiões de dados suportadas no Oracle NoSQL Database Cloud Service, consulte Regiões de Dados e URLs de Serviço Associados.
-
ponto final:
us-ashburn-1 -
ID do compartimento:
ocid1.compartment.oc1..aaaaaaaahcrgrgptoaq4cgpoymd32ti2ql4sdpu5puroausdf4og55z4tnya
-
-
Dissipador: arquivo JSON no Bucket do OCI Object Storage.
Identifique o ponto final, o namespace, o bucket e o prefixo da região para o OCI Object Storage. Para obter mais detalhes, consulte Acessando o Oracle Cloud Object Storage. Para obter a lista de pontos finais do serviço OCI Object Storage, consulte Pontos Finais do Serviço Object Storage.
-
ponto final:
us-ashburn-1 -
bucket:
Migrate_oci -
prefixo:
Delegation -
namespace: <> Se você não fornecer um namespace, o utilitário usará o namespace padrão da tenancy.
Observação: Se o Bucket do Object Storage estiver em outro compartimento, certifique-se de ter os privilégios para gravar objetos no bucket. Para obter mais detalhes sobre como definir as políticas, consulte Gravar objetos no serviço Object Storage.
-
-
Procedimento
Para migrar do Oracle NoSQL Database Cloud Service para o OCI Object Storage, execute o seguinte na janela do Cloud Shell:
-
Prepare um arquivo de configuração do Migrator,
migrator-config.json, com a origem do Oracle NoSQL Database Cloud Service e o dissipador do OCI Object Storage. Para modelos, consulte Modelos de Configuração de Origem e Modelos de Configuração do Separador. Certifique-se de definir o parâmetrouseDelegationTokencomotruenos modelos de configuração de origem e sumidouro.O seguinte modelo de configuração é usado neste caso de uso:
{ "source" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "NDCSupload", "compartment" : "ocid1.compartment.oc1..aaaaaaaahcrgrgptoaq4cgpoymd32ti2ql4sdpu5puroausdf4og55z4tnya", "useDelegationToken" : true, "readUnitsPercent" : 90, "includeTTL" : true, "requestTimeoutMs" : 5000 }, "sink" : { "type" : "object_storage_oci", "format" : "json", "endpoint" : "us-ashburn-1", "namespace" : "", "bucket" : "Migrate_oci", "prefix" : "Delegation", "chunkSize" : 32, "compression" : "", "useDelegationToken" : true }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
No Cloud Shell, navegue até o diretório em que você extraiu o utilitário NoSQL Database Migrator.
-
Execute o comando
runMigratorespecificando o arquivo de configuração usando a opção--configou-c.[~/nosql-migrator]$./runMigrator --config <complete/path/to/the/config/file> -
O utilitário NoSQL Database Migrator prossegue com a migração de dados. Como você definiu o parâmetro useDelegationToken como verdadeiro, o Cloud Shell se autentica automaticamente usando o token de delegação ao executar o utilitário NoSQL Database Migrator. O NoSQL Database Migrator copia seus dados da tabela
NDCSuploadpara um arquivo JSON no bucket do Object StorageMigrate_oci. Verifique os logs para obter um backup de dados bem-sucedido.[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] migration started [INFO] [OCI OS sink] : writing table schema to Delegation/Schema/schema.ddl [INFO] [OCI OS sink] : start writing records with prefix Delegation [INFO] migration completed. Records provided by source=4,Records written to sink=4,Records failed=0. Elapsed time: 0min 0sec 486ms Migration completed.Observação:
Os dados são copiados para o arquivo:
Migrate_oci/NDCSupload/Delegation/Data/000000.jsonDependendo do parâmetro chunkSize no modelo de configuração do coletor, os dados de origem podem ser divididos em vários arquivos JSON no mesmo diretório.
O esquema é copiado para o arquivo:
Migrate_oci/NDCStable1/Delegation/Schema/schema.ddl
Validação
Para validar seu backup de dados, faça log-in na console do Oracle NoSQL Database Cloud Service. Navegue pelos menus, Storage > Object Storage & Archive Storage > Buckets. Acesse os arquivos do diretório NDCSupload/Delegation no bucket Migrate_oci. Para ver o procedimento para acessar a console, consulte o artigo Acessando o Serviço na Console de Infraestrutura.
Migrar do OCI Object Storage para o Oracle NoSQL Database Cloud Service Usando Autenticação do OKE
Este exemplo mostra como usar o Oracle NoSQL Database Migrator com Autenticação de Identidade de Carga de Trabalho do OKE para copiar dados de um arquivo JSON na tabela do OCI Object Storage para o Oracle NoSQL Database Cloud Service.
Uso do caso
Como desenvolvedor, você está explorando uma opção para restaurar dados de um arquivo JSON no bucket do OCI Object Storage (OCI OS) para a tabela do Oracle NoSQL Database Cloud Service (NDCS) usando o NoSQL Database Migrator em um aplicativo em contêiner. Um aplicativo conteinerizado é um ambiente virtualizado que agrupa o aplicativo e todas as suas dependências (como bibliotecas, binários e arquivos de configuração) em um pacote. Isso permite que o aplicativo seja executado de forma consistente em diferentes ambientes, independentemente da infraestrutura subjacente.
Você deseja executar o NoSQL Database Migrator em um pod do Oracle Cloud Infrastructure Container Engine for Kubernetes (OKE). Para acessar com segurança OS serviços OS e NDCS do OCI no pod do OKE, você usará o método de Autenticação de Identidade de Carga de Trabalho (WIA).
Nesta demonstração, você criará uma imagem do docker para o NoSQL Database Migrator, copiará a imagem em um repositório no Container Registry, criará um cluster do OKE e implantará a imagem do Migrator no pod de cluster do OKE para executar o utilitário Migrator. Aqui, você fornecerá um arquivo de configuração do NoSQL Database Migrator criado manualmente para executar o utilitário Migrator como um aplicativo em contêiner.
Pré-requisitos
-
Identifique a origem e o dissipador da migração.
-
Origem: arquivos JSON e arquivo de esquema no bucket do SO do OCI.
Identifique o ponto final da região, o namespace, o bucket e o prefixo do OCI OS em que OS arquivos e o esquema JSON de origem estão disponíveis. Para obter mais detalhes, consulte Acessando o Oracle Cloud Object Storage. Para obter a lista de pontos finais do serviço OCI OS, consulte Pontos Finais do Serviço Object Storage.
-
ponto final:
us-ashburn-1 -
bucket:
Migrate_oci -
prefixo:
userSession -
namespace:
idhkv1iewjzj
O nome do namespace de um bucket é o mesmo do namespace da tenancy e é gerado automaticamente quando sua tenancy é criada. Você pode obter o nome do namespace da seguinte forma:
-
Na console do Oracle NoSQL Database Cloud Service, navegue até Armazenamento > Buckets.
-
Selecione seu compartimento em Escopo da Lista e selecione o bucket. A página Detalhes do Bucket exibe o nome no parâmetro Namespace.
Se você não fornecer um nome de namespace do OCI OS, o utilitário Migrator usará o namespace padrão da tenancy.
-
-
Dissipador: tabela
usersno Oracle NoSQL Database Cloud Service.Identifique o ponto final da região ou o ponto final do serviço e o nome do compartimento para seu dissipador:
-
ponto final:
us-ashburn-1 -
compartimento:
ocid1.compartment.oc1..aaaaaaaaleiwplazhwmicoogv3tf4lum4m4nzbcv5wfjmoxuz3doreagvdma
Identifique o esquema da tabela sumidoura.
Para usar o nome da tabela e o esquema armazenados no bucket do SO do OCI, defina o parâmetro
useSourceSchemacomo verdadeiro. Para obter informações sobre outras opções de esquema, consulte o tópico Identificar a Origem e o Dissipador no Workflow para o Oracle NoSQL Database Migrator.Observação: Certifique-se de ter os privilégios de gravação no compartimento no qual você está restaurando dados para a tabela NDCS. Para obter mais detalhes, consulte Gerenciando Compartimentos.
-
-
-
Prepare uma imagem do Docker para o NoSQL Database Migrator e mova-a para o Container Registry.
-
Obtenha o namespace da tenancy na console do OCI.
Faça log-in na console do Oracle NoSQL Database Cloud Service. Na barra de navegação, selecione o menu Perfil e, em seguida, selecione Tenancy: <Tenany name>.
Copie o nome do namespace do Object Storage, que é o espaço de nomes da tenancy, para a área de transferência.
-
Crie uma imagem do Docker para o utilitário Migrator.
Navegue até o diretório em que você extraiu o utilitário NoSQL Database Migrator. O pacote Migrator inclui um arquivo do docker denominado Dockerfile. Em uma interface de comando, use o seguinte comando para criar uma imagem do Docker do utilitário Migrator:
#Command: docker build -t nosqlmigrator:<tag> .#Example: docker build -t nosqlmigrator:1.0 .Você pode especificar um identificador de versão para a imagem do Docker na opção
tag. Verifique sua imagem do Docker usando o comando:#Command: Docker images#Example output ------------------------------------------------------------------------------------------ REPOSITORY TAG IMAGE ID CREATED SIZE localhost/nosqlmigrator 1.0 e1dcec27a5cc 10 seconds ago 487 MB quay.io/podman/hello latest 83fc7ce1224f 10 months ago 580 kB docker.io/library/openjdk 17-jdk-slim 8a3a2ffec52a 2 years ago 406 MB ------------------------------------------------------------------------------------------ -
Gere um token de Autenticação.
Você precisa de um token de Autenticação para fazer log-in no Container Registry a fim de armazenar a imagem do Migrator Docker. Se você ainda não tiver um token de Autenticação, deverá gerar um. Para obter detalhes, consulte Obtendo um Token de Autorização.
-
Armazene a imagem do Migrator Docker no Container Registry.
Para acessar a Imagem do Migrator Docker no pod do Kubernetes, você deve armazenar a imagem em qualquer registro público ou privado. Por exemplo, Docker, Artifact Hub, OCI Container Registry etc. são alguns registros. Nesta demonstração, usamos Container Registry. Para obter detalhes, consulte Visão Geral do Serviço Container Registry.
-
Na console do OCI, crie um repositório no Container Registry. Para obter detalhes, consulte Criando um Repositório.
Para esta demonstração, você cria o repositório
okemigrator.Figura - Repositório no Container Registry
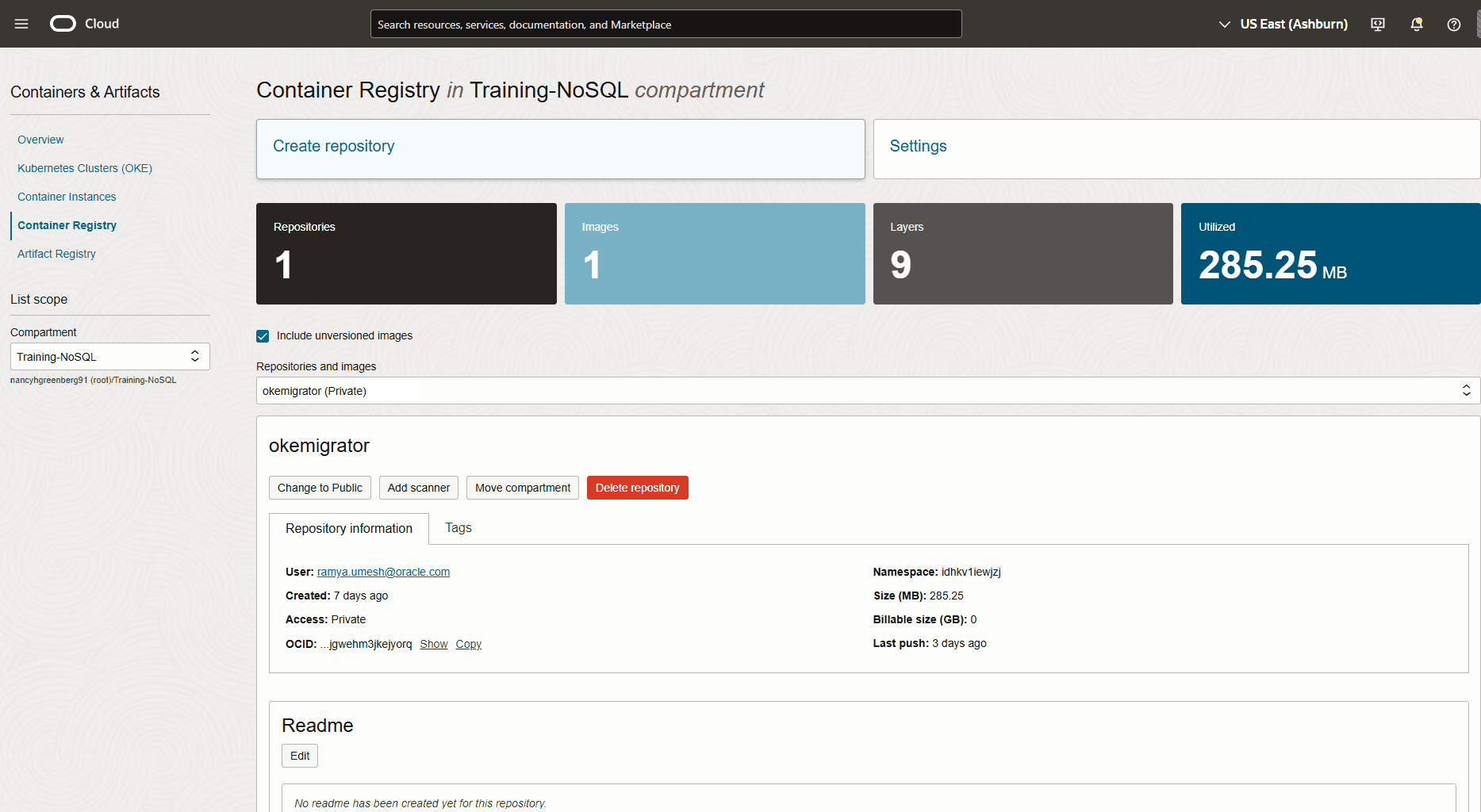
-
Faça login no Container Registry na interface de comando usando o seguinte comando:
#Command: docker login <region-key>.ocir.io -u <tenancy-namespace>/<user name>password: <Auth token>#Example: docker login iad.ocir.io -u idhx..xxwjzj/rx..xxxxh@oracle.com password: <Auth token>#Output: Login Succeeded!No comando acima,
region-key: Especifica a chave da região na qual você está usando o Container Registry. Para obter detalhes, consulte Disponibilidade por Região.tenancy-namespace: Especifica o namespace da tenancy que você copiou da console do OCI.user name: Especifica o nome do usuário da console do OCI.password: Especifica seu token de Autenticação. -
Marque e envie sua imagem do Migrator Docker para o Container Registry usando os seguintes comandos:
#Command: docker tag <Migrator Docker image> <region-key>.ocir.io/<tenancy-namespace>/<repo>:<tag> docker push <region-key>.ocir.io/<tenancy-namespace>/<repo>:<tag>#Example: docker tag localhost/nosqlmigrator:1.0 iad.ocir.io/idhx..xxwjzj/okemigrator:1.0 docker push iad.ocir.io/idhx..xxwjzj/okemigrator:1.0No comando acima,
repo: Especifica o nome do repositório que você criou no Container Registry.tag: Especifica o identificador de versão da imagem do Docker.#Output: Getting image source signatures Copying blob 0994dbbf9a1b done | Copying blob 37849399aca1 done | Copying blob 5f70bf18a086 done | Copying blob 2f263e87cb11 done | Copying blob f941f90e71a8 done | Copying blob c82e5bf37b8a done | Copying blob 2ad58b3543c5 done | Copying blob 409bec9cdb8b done | Copying config e1dcec27a5 done | Writing manifest to image destination
-
-
-
Configurar um cluster do OKE com WIA para NDCS e SO do OCI.
-
Criar um cluster do Kubernetes usando o OKE.
Na console do OCI, defina e crie um cluster do Kubernetes com base na disponibilidade de recursos de rede usando o OKE. Você precisa de um cluster do Kubernetes para executar o utilitário Migrator como um aplicativo em contêiner. Para obter detalhes sobre a criação de clusters, consulte Criando Clusters do Kubernetes Usando Workflows da Console.
Para esta demonstração, você pode criar um cluster gerenciado de nó único usando o workflow Criação Rápida detalhado no link acima.
Figura - Cluster do Kubernetes para Contêiner do Migrador
-
Configurar o WIA na console do OCI para acessar outros recursos do OCI do Cluster do Kubernetes.
Para conceder ao utilitário Migrator acesso ao bucket do NDCS e do OCI OS durante a execução dos pods de cluster do Kubernetes, configure o WIA. Siga estas etapas:
-
Configure o arquivo de configuração kubeconfig do cluster.
-
Na console do OCI, abra o cluster do Kubernetes que você criou e clique no botão Access Cluster.
-
Na caixa de diálogo Acessar Seu Cluster, clique em Acesso ao Cloud Shell.
-
Clique em Iniciar Cloud Shell para exibir a janela do Cloud Shell.
-
Execute o comando do Oracle Cloud Infrastructure CLI para configurar o arquivo kubeconfig. Você pode copiar o comando da caixa de diálogo Acessar Seu Cluster. Você pode esperar a seguinte saída:
#Example: oci ce cluster create-kubeconfig --cluster-id ocid1.cluster.oc1.iad.aaa...muqzq --file $HOME/.kube/config --region us-ashburn-1 --token-version 2.0.0 --kube-endpoint PUBLIC_ENDPOINT#Output: New config written to the Kubeconfig file /home/<user>/.kube/config
-
-
Copie o OCID do cluster da opção
cluster-idno comando acima e salve-o para usar em etapas adicionais.ocid1.cluster.oc1.iad.aaa...muqzq -
Crie um namespace para a conta de serviço do Kubernetes usando o seguinte comando na janela do Cloud Shell:
#Command: kubectl create namespace <namespace-name>#Example: kubectl create namespace migrator#Output: namespace/migrator created -
Crie uma conta de serviço do Kubernetes para o aplicativo Migrator em um namespace usando o seguinte comando na janela do Cloud Shell:
#Command: kubectl create serviceaccount <service-account-name> --namespace <namespace-name>#Example: kubectl create serviceaccount migratorsa --namespace migrator#Output: serviceaccount/migratorsa created -
Definir uma política do IAM na console do OCI para permitir que a carga de trabalho acesse os recursos do OCI no cluster do Kubernetes.
Na console do OCI, navegue pelos menus Identity & Security > Identity > Policies. Crie as políticas a seguir para permitir o acesso aos recursos
nosql-familyeobject-family. Use o OCID dos valores de cluster, namespace e conta de serviço das etapas anteriores.#Command: Allow <subject> to <verb> <resource-type> in <location> where <conditions>#Example: Allow any-user to manage nosql-family in compartment Training-NoSQL where all { request.principal.type = 'workload', request.principal.namespace = 'migrator', request.principal.service_account = 'migratorsa', request.principal.cluster_id = 'ocid1.cluster.oc1.iad.aaaaaaaa2o6h5noeut7i4xr2bp4aohcc2ncozgvn3nny3uqu7cvp2rwmuqzq'} Allow any-user to manage object-family in compartment Training-NoSQL where all { request.principal.type = 'workload', request.principal.namespace = 'migrator', request.principal.service_account = 'migratorsa', request.principal.cluster_id = 'ocid1.cluster.oc1.iad.aaaaaaaa2o6h5noeut7i4xr2bp4aohcc2ncozgvn3nny3uqu7cvp2rwmuqzq'}Para obter mais detalhes sobre como criar políticas, consulte Usando a Console para Criar Política.
-
-
Procedimento
Para migrar do arquivo JSON no bucket do SO do OCI para a tabela NDCS, execute o seguinte na janela do Cloud Shell:
-
Prepare um arquivo de configuração do Migrator,
migrator-config.json, com a origem do SO OCI e o dissipador NDCS. Para modelos, consulte Modelos de Configuração de Origem e Modelos de Configuração do Separador.Para usar o OKE WIA para acessar o bucket do SO do OCI e o NDCS, defina o parâmetro
useOKEWorkloadIdentitycomo verdadeiro nos modelos de configuração de origem e sumidouro. Aqui, você usará o esquema de origem do arquivo DDL do esquema no bucket do SO do OCI. Portanto, defina o parâmetrouseSourceSchemacomo verdadeiro no modelo de configuração do coletor.Observação: ao usar o OKE WIA, você não pode gerar o arquivo de configuração do Migrator interativamente. Você deve preparar o arquivo de configuração manualmente referindo-se aos modelos de configuração de origem e sumidouro.
{ "source" : { "type" : "object_storage_oci", "format" : "json", "endpoint" : "us-ashburn-1", "namespace" : "", "bucket" : "Migrate_oci", "prefix" : "userSession", "useOKEWorkloadIdentity" : true }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "users", "compartment" : "Training-NoSQL", "includeTTL" : true, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "useSourceSchema" : true }, "useOKEWorkloadIdentity" : true, "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Crie um recurso de mapa de configuração (configmap) para informar o arquivo de entrada de configuração
migrator-config.jsonao contêiner Migrator no runtime no pod do Kubernetes. O configmap monta o arquivo de configuração do Migrator no sistema de arquivos do contêiner como um volume de montagem.#Command: kubectl create configmap oci-migrator-config --from-file=<Migrator configuration file> -n <namespace-name>#Example: kubectl create configmap oci-migrator-config --from-file=migrator-config.json -n migrator#Output: configmap/oci-migrator-config created -
Crie um segredo de registro do Docker que inclua as credenciais do OCI a serem usadas ao extrair a imagem do Migrator Docker do Container Registry para o pod do Kubernetes.
#Command: kubectl create secret docker-registry ocirsecret --docker-server=<region-key>.ocir.io --docker-username='tenancy-namespace/username' --docker-password='auth token' --docker-email='<user Email>' -n <namespace-name>#Example: kubectl create secret docker-registry ocirsecret --docker-server=iad.ocir.io --docker-username='idhx..xxwjzj/rx..xxxxh@oracle.com' --docker-password='<Auth token>' --docker-email='rx..xxxxh@oracle.com' -n migrator#Output: secret/ocirsecret created -
Crie um arquivo de manifesto, que você usará para especificar a imagem do Migrator Docker. Certifique-se de fornecer os valores das etapas anteriores para namespace, nome da conta de serviço do Kubernetes, nome da imagem do Docker, segredo de registro do Docker e configmap. Você pode consultar o seguinte arquivo de manifesto de amostra:
#migrator-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nosql-migrator spec: replicas: 1 selector: matchLabels: app: nosql-migrator template: metadata: labels: app: nosql-migrator spec: serviceAccountName: migratorsa automountServiceAccountToken: true containers: - name: nosqlmigrator image: iad.ocir.io/idhx..xxwjzj/okemigrator:1.0 imagePullPolicy: Always args: ["--config", "/config/migrator-config.json", "--log-level", "DEBUG"] volumeMounts: - name: config-volume mountPath: /config # Mount the file here imagePullSecrets: - name: ocirsecret volumes: - name: config-volume configMap: name: oci-migrator-config -
Implante a imagem do Migrator Docker no pod do Kubernetes usando o comando a seguir. O OKE executa o utilitário Migrator em um contêiner em um dos nós do cluster do Kubernetes.
#Command: kubectl create -f <manifest file> -n <namespace-name>#Example: kubectl create -f migrator-deployment.yaml -n migrator#Output: deployment.apps/nosql-migrator created -
Você pode verificar os logs usando os seguintes comandos:
-
Extraia o nome do pod no qual o utilitário Migrator está sendo executado.
#Command: kubectl get pods -n <namespace-name>#Example: kubectl get pods -n migrator#Output: NAME READY STATUS RESTARTS AGE nosql-migrator-ccdbf549-6sjjg 1/1 Running 0 56s -
Use o nome do pod para extrair os logs do Migrator.
#Command: kubectl logs -f <kubernetes cluster pod name> -n <namespace-name>#Example: kubectl logs -f nosql-migrator-ccdbf549-6sjjg -n migrator#Output: SLF4J(I): Connected with provider of type [org.apache.logging.slf4j.SLF4JServiceProvider] [INFO] Configuration for migration: { "source" : { "type" : "object_storage_oci", "format" : "json", "endpoint" : "us-ashburn-1", "namespace" : "idhkv1iewjzj", "bucket" : "Migrate_oci", "prefix" : "userSession", "useOKEWorkloadIdentity" : true }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "users", "compartment" : "Training-NoSQL", "includeTTL" : true, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "useSourceSchema" : true }, "useOKEWorkloadIdentity" : true, "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } [INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] migration started [INFO] [cloud sink] : start loading DDLs [INFO] [cloud sink] : completed loading DDLs [INFO] [cloud sink] : start loading records [INFO] [OCI OS source] : start parsing JSON records from object: users/userSession/Data/users_1_5_0.json [INFO] [OCI OS source] : start parsing JSON records from object: users/userSession/Data/users_6_10_0.json [INFO] migration completed. Records provided by source=5, Records written to sink=5, Records failed=0, Records skipped=0. Elapsed time: 0min 1sec 15ms Migration completed.
Observação:
Você pode executar iterativamente a migração de dados da seguinte forma:
-
Exclua o contêiner
nosql-migratorusando o seguinte comando:#Command: kubectl delete -f <manifest file> -n <namespace-name>#Example: kubectl delete -f migrator-deployment.yaml -n migrator#Output: deployment.apps "nosql-migrator" deleted -
Atualize o arquivo de entrada de configuração
migrator-config.json. -
Exclua e recrie o configmap usando os comandos da Etapa 2.
Não é necessário criar o segredo de registro do Docker e o arquivo de manifesto novamente.
-
Implante a imagem do Migrator Docker no pod do Kubernetes usando o arquivo de manifesto (Etapa 5).
-
Verificação
Para verificar sua restauração de dados, faça log-in na console do Oracle NoSQL Database Cloud Service. Na barra de navegação, vá para Bancos de Dados > NoSQL Database. Selecione seu compartimento na lista drop-down para exibir a tabela users. Para obter o procedimento para acessar a console, consulte Acessando o Serviço na Console de Infraestrutura.
Migrar do Oracle NoSQL Database para o OCI Object Storage Usando Autenticação de Token de Sessão
Este exemplo mostra como usar o Oracle NoSQL Database Migrator com autenticação de token de sessão para copiar dados da tabela do Oracle NoSQL Database para um arquivo JSON em um bucket do OCI Object Storage.
Uso do caso
Como desenvolvedor, você está explorando uma opção para fazer backup dos dados da tabela do Oracle NoSQL Database no OCI Object Storage (SO OCI). Você deseja usar a autenticação baseada em token de sessão.
Nesta demonstração, você usará os comandos da CLI (Interface de Linha de Comando) do OCI para criar um token de sessão. Você criará manualmente um arquivo de configuração do Migrator e executará a migração de dados.
Pré-requisitos
-
Identifique a origem e o dissipador da migração.
-
Origem: tabela
usersno Oracle NoSQL Database. -
Dissipador: arquivo JSON no bucket do SO do OCI
Identifique o ponto final da região, o namespace, o bucket e o prefixo do SO do OCI. Para obter mais detalhes, consulte Acessando o Oracle Cloud Object Storage. Para obter a lista de pontos finais do serviço OCI OS, consulte Pontos Finais do Serviço Object Storage.
-
ponto final:
us-ashburn-1 -
bucket:
Migrate_oci -
prefixo:
userSession -
namespace:
idhkv1iewjzjO nome do namespace de um bucket é o mesmo do namespace da tenancy e é gerado automaticamente quando sua tenancy é criada. Você pode obter o nome do namespace da seguinte forma:
-
Na console do Oracle NoSQL Database Cloud Service, navegue até Storage> Buckets.
-
Selecione o Compartimento no Escopo da Lista e selecione o bloco. A página Detalhes do Bucket exibe o nome no parâmetro Namespace.
Se você não fornecer um nome de namespace do OCI OS, o utilitário Migrator usará o namespace padrão da tenancy.
-
-
Observação: Certifique-se de ter OS privilégios para gravar objetos no bucket do SO do OCI. Para obter mais detalhes sobre como definir as políticas, consulte Gravar no Serviço Object Storage.
-
Gere um token de sessão seguindo estas etapas:
-
Instalar e configurar o OCI CLI. Consulte Início Rápido.
-
Use um dos comandos da CLI do OCI a seguir para gerar um token de sessão. Para obter mais detalhes sobre as opções disponíveis, consulte Autenticação baseada em Token para a CLI.
# Create a session token using OCI CLI from a web browser: oci session authenticate --region <region_name> --profile-name <profile_name> # Example: oci session authenticate --region us-ashburn-1 --profile-name SESSIONPROFILEou
# Create a session token using OCI CLI without a web browser: oci session authenticate --no-browser --region <region_name> --profile-name <profile_name> # Example: oci session authenticate --no-browser --region us-ashburn-1 --profile-name SESSIONPROFILENo comando acima:
region_name: Especifica o ponto final da região do seu SO do OCI. Para obter uma lista de regiões de dados suportadas no Oracle NoSQL Database Cloud Service, consulte Regiões de Dados e URLs de Serviço Associados.profile_name: Especifica o perfil, que o comando da CLI do OCI usa para gerar um token de sessão.O comando da CLI do OCI cria uma entrada no arquivo de configuração do OCI no caminho
$HOME/.oci/config, conforme mostrado na seguinte amostra:[SESSIONPROFILE] fingerprint=f1:e9:b7:e6:25:ff:fe:05:71:be:e8:aa:cc:3d:0d:23 key_file=$HOME/.oci/sessions/SESSIONPROFILE/oci_api_key.pem tenancy=ocid1.tenancy.oc1..aaaaa ... d6zjq region=us-ashburn-1 security_token_file=$HOME/.oci/sessions/SESSIONPROFILE/tokenO
security_token_fileaponta para o caminho do token de sessão que você gerou usando o comando da CLI do OCI acima.Observação:
-
Se o perfil já existir no arquivo de configuração do OCI, o comando da CLI do OCI substituirá o perfil pela configuração relacionada ao token de sessão ao gerar o token de sessão.
-
Especifique o seguinte no modelo de configuração do sumidouro:
-
O caminho para o arquivo de configuração do OCI no parâmetro de credenciais.
-
O perfil usado ao gerar o token de sessão no parâmetro credentialProfile.
"credentials" : "$HOME/.oci/config" "credentialsProfile" : "SESSIONPROFILE"O utilitário Migrator extrai automaticamente os detalhes do token de sessão gerado usando os parâmetros acima. Se você não especificar o parâmetro de credenciais, o utilitário Migrator procurará o arquivo de credenciais no caminho
$HOME/.oci. Se você não especificar o parâmetro credenciaisProfile, o utilitário Migrator usará o nome de perfil padrão (DEFAULT) do arquivo de configuração do OCI.- O token de sessão é válido por 60 minutos. Para estender a duração da sessão, você pode atualizar a sessão. Para obter detalhes, consulte Atualizando um Token.
-
-
Procedimento
Para migrar da tabela do Oracle NoSQL Database para um arquivo JSON no bucket do SO do OCI:
-
Prepare o arquivo de configuração (no formato JSON) com a origem e o arquivo JSON do Oracle NoSQL Database no coletor de buckets do SO OCI. Para modelos, consulte Modelos de Configuração de Origem e Modelos de Configuração de Separação.
Para usar a autenticação de token de sessão para acessar o bucket do SO do OCI, defina o parâmetro useSessionToken como verdadeiro no modelo de configuração do dissipador. De forma correspondente, especifique o caminho de configuração no parâmetro de credenciais e o nome do perfil no parâmetro credentialProfile.
{ "source" : { "type" : "nosqldb", "storeName" : "kvstore", "helperHosts" : ["<hostname>:<port>"], "table" : "users", "includeTTL" : true, "requestTimeoutMs" : 5000 }, "sink" : { "type" : "object_storage_oci", "format" : "json", "endpoint" : "us-ashburn-1", "namespace" : "idhkv1iewjzj", "bucket" : "Migrate_oci", "prefix" : "userSession", "chunkSize" : 32, "compression" : "", "useSessionToken" : true, "credentials" : "$/home/.oci/config", "credentialsProfile" : "SESSIONPROFILE" }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Abra o prompt de comando e navegue até o diretório em que você extraiu o utilitário NoSQL Database Migrator.
-
Execute o comando runMigrator especificando a opção de arquivo de configuração. Use a opção
--configou-cpara passar o arquivo de configuração da seguinte forma:./runMigrator --config ./migrator-config.json -
O utilitário Migrator prossegue com a migração de dados. Uma saída de amostra é mostrada abaixo.
Com o parâmetro useSessionToken verdadeiro, o utilitário Migrator se autentica automaticamente usando o token de sessão. O utilitário Migrator copia seus dados da tabela
userspara um arquivo JSON no bucket do SO do OCI chamadoMigrate_oci. Verifique os logs para obter um backup de dados bem-sucedido.[INFO] creating source from given configuration: [INFO] source creation completed [INFO] creating sink from given configuration: [INFO] sink creation completed [INFO] creating migrator pipeline [INFO] [OCI OS sink] : writing table schema to userSession/Schema/schema.ddl [INFO] migration started [INFO] Migration success for source users_6_10. read=2,written=2,failed=0 [INFO] Migration success for source users_1_5. read=3,written=3,failed=0 [INFO] Migration is successful for all the sources. [INFO] migration completed. Records provided by source=5, Records written to sink=5, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 982ms Migration completed.Observação:
Dependendo do parâmetro chunkSize no modelo de configuração do coletor, o utilitário Migrator divide os dados de origem em vários arquivos JSON no mesmo diretório. Neste exemplo, o utilitário Migrator copia dados para os arquivos
users_1_5_0.jsoneusers_6_10_0.jsonno diretórioMigrate_oci/userSession/Data.O esquema da tabela de origem é copiado para o arquivo
schema.ddlno diretórioMigrate_oci/userSession/Schema.
Verificação
Para verificar seu backup de dados, faça log-in na console do Oracle NoSQL Database Cloud Service. Navegue pelos menus, Storage > Object Storage & Archive Storage > Buckets. Acesse os arquivos do diretório userSession no bucket Migrate_oci. Para obter o procedimento para acessar a console, consulte Acessando o Serviço na Console de Infraestrutura
Migrar de arquivo CSV para o Oracle NoSQL Database Cloud Service
Este exemplo mostra o uso do Oracle NoSQL Database Migrator para copiar dados de um arquivo CSV para o Oracle NoSQL Database Cloud Service.
Exemplo
Depois de avaliar várias opções, uma organização finaliza o Oracle NoSQL Database Cloud Service como sua plataforma NoSQL Database. Como seu conteúdo de origem está no formato de arquivo CSV, eles estão procurando uma maneira de migrá-los para o Oracle NoSQL Database Cloud Service.
Neste exemplo, você aprenderá a migrar os dados de um arquivo CSV chamado course.csv, que contém informações sobre vários cursos oferecidos por uma universidade. Você gera o arquivo de configuração interativamente no utilitário runMigrator.
Você também pode preparar o arquivo de configuração com os detalhes de origem e sumidouro identificados. Consulte Referência do Migrador do Oracle NoSQL Database.
Pré-requisitos
-
Identifique a origem da migração.
-
Origem: arquivo CSV
Neste exemplo, o arquivo de origem é
course.csv1,"Computer Science", "San Francisco", "2500" 2,"Bio-Technology", "Los Angeles", "1200" 3,"Journalism", "Las Vegas", "1500" 4,"Telecommunication", "San Francisco", "2500" -
O arquivo CSV deve estar em conformidade com o formato
RFC4180. -
Crie um arquivo que contenha os comandos DDL para o esquema da tabela de destino,
course. A definição de tabela deve corresponder ao arquivo de dados CSV referente ao número de colunas e seus tipos.Neste exemplo, o arquivo DDL é
mytable_schema.ddlcreate table course (id INTEGER, name STRING, location STRING, fees INTEGER, PRIMARY KEY(id));
-
-
Identifique a pia para a migração.
-
Dissipador: Oracle NoSQL Database Cloud Service
-
Identifique suas credenciais da nuvem do OCI e as capture no arquivo de configuração. Salve o arquivo de configuração em
/home/<user>/.oci/config. Para obter mais detalhes, consulte Adquirindo Credenciais.[DEFAULT] tenancy=ocid1.tenancy.oc1.... user=ocid1.user.oc1.... fingerprint= 43:d1:.... region=us-ashburn-1 key_file=</fully/qualified/path/to/the/private/key/> pass_phrase=<passphrase> -
Identifique o ponto final da região e o nome do compartimento do Oracle NoSQL Database Cloud Service.
-
ponto final:
us-ashburn-1 -
compartimento:
ocid1.compartment.oc1..aaaaaaaavjikiwmylfnpofefbdaleg6rqyf7cdnr5o6vozg4lyajeunrhsmq
-
-
Procedimento
Para migrar dados do arquivo course.csv para o Oracle NoSQL Database Cloud Service, execute as seguintes etapas:
-
Abra o prompt de comando e navegue até o diretório em que você extraiu o utilitário Migrator do Oracle NoSQL Database.
-
Para gerar o arquivo de configuração usando o Oracle NoSQL Database Migrator, execute o comando
runMigratorsem nenhum parâmetro de runtime.[~/nosql-migrator-1.8.0]$./runMigrator -
Como você não forneceu o arquivo de configuração como um parâmetro de tempo de execução, o utilitário solicitará se deseja gerar a configuração agora. Digite
y.Você pode escolher um local para o arquivo de configuração ou manter o local padrão pressionando o
Enter key.Configuration file is not provided. Do you want to generate configuration? (y/n) [n]: y Generating a configuration file interactively. Enter a location for your config [./migrator-config.json]: ./migrator-config.json already exist. Do you want to overwrite?(y/n) [n]: y -
Com base nos prompts do utilitário, escolha suas opções para a configuração Origem.
Select the source: 1) nosqldb 2) nosqldb_cloud 3) file 4) object_storage_oci 5) aws_s3 #? 3 Configuration for source type=file Select the source file format: 1) json 2) mongodb_json 3) dynamodb_json 4) csv #? 4 -
Forneça o caminho para o arquivo CSV de origem. Além disso, com base nos prompts do utilitário, você pode optar por reordenar os nomes das colunas, selecionar o método de codificação e reduzir os espaços de rejeito da tabela de destino.
Enter path to a file or directory containing csv data: [~/nosql-migrator]/course.csv Does the CSV file contain a headerLine? (y/n) [n]: n Do you want to reorder the column names of NoSQL table with respect to CSV file columns? (y/n) [n]: n Provide the CSV file encoding. The supported encodings are: UTF-8,UTF-16,US-ASCII,ISO-8859-1. [UTF-8]: Do you want to trim the tailing spaces? (y/n) [n]: n -
Com base nos prompts do utilitário, escolha a opção
nosqldb_cloudpara a configuração do dissipador.Select the sink: 1) nosqldb 2) nosqldb_cloud #? 2 -
Forneça o URL do ponto final ou o ID da região da sua tenancy e selecione o tipo de autenticação para que o utilitário Migrator acesse o Oracle NoSQL Database Cloud Service.
Configuration for sink type=nosqldb_cloud Enter endpoint URL or region ID of the Oracle NoSQL Database Cloud: us-ashburn-1 Select the authentication type: 1) credentials_file 2) instance_principal 3) delegation_token 4) session_token 5) oke_workload_identity #? 1 -
Com base nos prompts do utilitário, forneça o nome do arquivo de credenciais a ser usado para autenticação, o perfil de credenciais, o ID do compartimento e o nome da tabela na qual você deseja copiar dados no coletor.
Enter path to the file containing OCI credentials [/home/<user>/.oci/config]: Enter the profile name in OCI credentials file [DEFAULT]: Enter the compartment name or id of the table []: ua_nosql Enter table name: course -
Informe sua opção para definir o valor TTL. O valor-padrão é
n.Include TTL data? If you select 'yes' TTL value provided by the source will be set on imported rows. (y/n) [n]: y Would you like to provide TTL reference time?(y/n) [n]: n -
Com base nos prompts do utilitário, especifique se a tabela de destino deve ou não ser criada por meio da ferramenta Migrator do Oracle NoSQL Database. Se a tabela já tiver sido criada, será sugerido fornecer
n. Se a tabela não for criada, o utilitário solicitará o caminho do arquivo que contém os comandos DDL do esquema da tabela de destino.Would you like to create table as part of migration process? Use this option if you want to create table through the migration tool. If you select yes, you will be asked to provide a file that contains table DDL or to use schema provided by the source or default schema. (y/n) [n]: y Enter path to a file containing table DDL: [~/nosql-migrator]/mytable_schema.ddl -
Informe os valores de throughput e a alocação de armazenamento para a tabela de sumidouros.
Would you like to use on demand read and write units? (y/n) [n]: n Enter read throughput in KB of new table: 100 Enter write throughput in KB of new table: 60 Enter storage size in GB of new table: 1 Enter percentage of table write units to be used for migration operation. (1-100) [90]: 90 -
Insira suas opções para determinar se os registros devem ou não ser substituídos se a tabela já estiver disponível na pia. Você também pode adicionar transformações aos dados de origem.
would you like to overwrite records which are already present? If you select 'no' records with same primary key will be skipped [y/n] [y]: y Enter store operation timeout in milliseconds. [5000]: Would you like to add transformations to source data? (y/n) [n]: n Would you like to continue migration if any data fails to be migrated? (y/n) [n]: n -
O utilitário exibe a configuração gerada na tela.
{ "source" : { "type" : "file", "format" : "csv", "dataPath" : "[~/nosql-migrator]/course.csv", "hasHeader" : false, "csvOptions" : { "encoding" : "UTF-8", "trim" : false } }, "sink" : { "type" : "nosqldb_cloud", "endpoint" : "us-ashburn-1", "table" : "course", "compartment" : "ua_nosql", "includeTTL" : true, "schemaInfo" : { "readUnits" : 100, "writeUnits" : 60, "storageSize" : 1, "schemaPath" : "[~/nosql-migrator]/mytable_schema.ddl" }, "credentials" : "/home/<user>/.oci/config", "credentialsProfile" : "DEFAULT", "writeUnitsPercent" : 90, "overwrite" : true, "requestTimeoutMs" : 5000 }, "abortOnError" : true, "migratorVersion" : "1.8.0" } -
Finalmente, o utilitário solicita que você especifique se deseja ou não prosseguir com a migração usando o arquivo de configuração gerado. A opção padrão é
y.Observação:
Se você selecionar
n, a migração de dados não será iniciada. O arquivo de configuração gerado é salvo no diretório Migrator. Use um dos comandos a seguir para executar o utilitário de Migração com a opção de arquivo de configuração../runMigrator -c ./migrator-config.json./runMigrator --config ./migrator-config.jsonWould you like to run the migration with above configuration? If you select no, you can use the generated configuration file to run the migration using: ./runMigrator --config ./migrator-config.json (y/n) [y]: y -
O NoSQL Database Migrator copia seus dados do arquivo CSV para o Oracle NoSQL Database Cloud Service.
creating source from given configuration: source creation completed creating sink from given configuration: sink creation completed creating migrator pipeline [cloud sink] : start loading DDLs [cloud sink] : executing DDL: create table if not exists course (id INTEGER, name STRING, location STRING, fees INTEGER, PRIMARY KEY(id)),limits: [100, 60, 1] [cloud sink] : completed loading DDLs migration started [csv file source] : start parsing CSV records from file: course.csv Migration success for source course. read=4,written=4,failed=0 Migration is successful for all the sources. migration completed. Records provided by source=4, Records written to sink=4, Records failed=0,Records skipped=0. Elapsed time: 0min 0sec 395ms Migration completed.
Verificação
Para verificar a migração, você pode fazer log-in na console do Oracle NoSQL Database Cloud Service e acessar a tabela course. A tabela contém os dados de origem. Para obter o procedimento para acessar a console, consulte o artigo Acessando o Serviço na Console de Infraestrutura no documento do Oracle NoSQL Database Cloud Service.