Integração do Serviço Data Flow com o Serviço Data Science
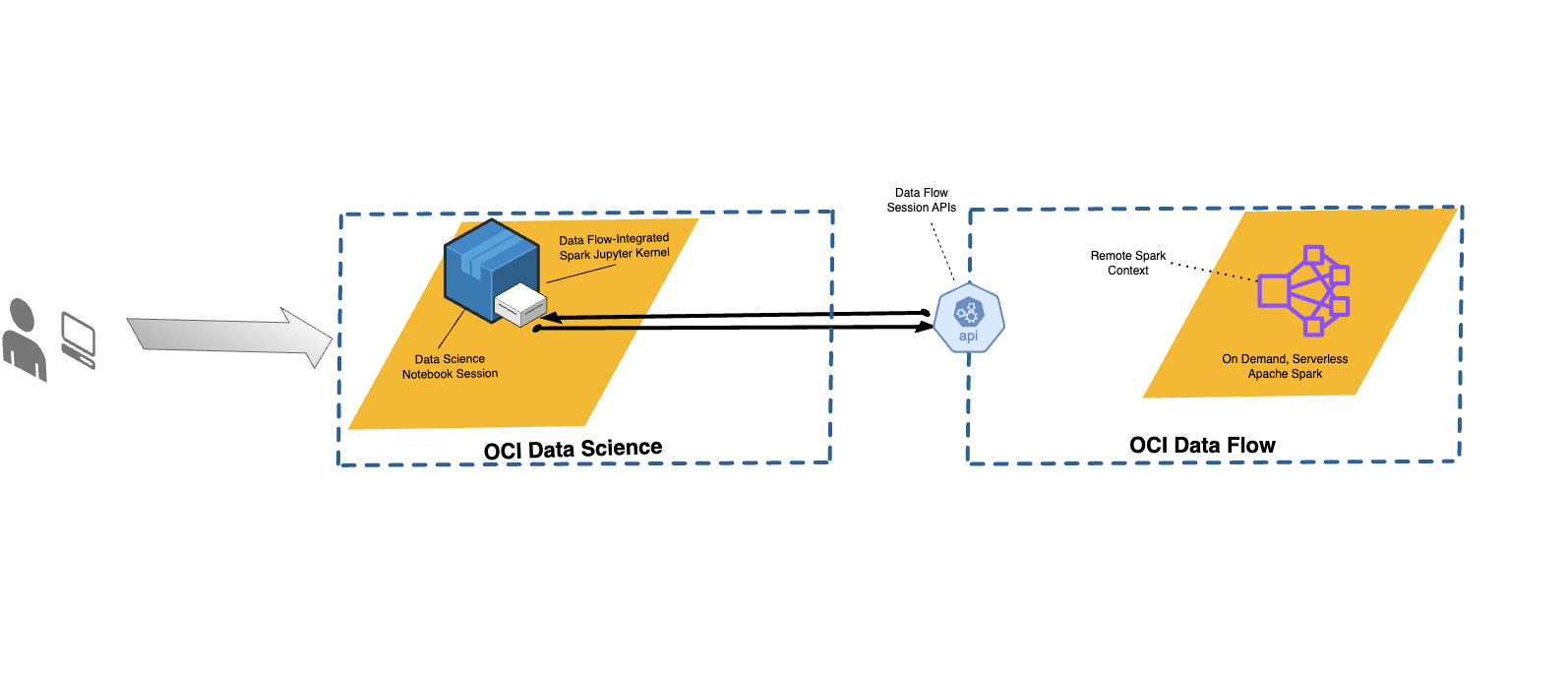
Com o serviço Data Flow, você pode configurar notebooks do Data Science para executar aplicativos interativos no serviço Data Flow.
O serviço Data Flow usa Jupyter Notebooks totalmente gerenciados para permitir que cientistas e engenheiros de dados criem, visualizem, colaborem e depurem aplicativos de engenharia e ciência de Dados. Você pode gravar esses aplicativos em Python, Scala e PySpark. Você também pode conectar uma sessão de notebook do serviço Data Science ao serviço Data Flow para executar aplicativos. Os kernels e aplicativos do Data Flow são executados no Oracle Cloud Infrastructure Data Flow .
O Apache Spark é um sistema de computação distribuído projetado para processar dados em escala. Ele suporta tarefas SQL em grande escala, tarefas de processamento em batch e de streams e tarefas de aprendizado de máquina. O Spark SQL fornece suporte semelhante a banco de dados. Para consultar dados estruturados, use o Spark SQL. Ele é uma implementação SQL padrão ANSI.
As Sessões do Serviço Data Flow suportam recursos do cluster do Data Flow com dimensionamento automático. Para obter mais informações, consulte Dimensionamento Automático na documentação do serviço Data Flow.
As Sessões do Serviço Data Flow suportam o uso de ambientes conda como ambientes de runtime Spark personalizáveis.
- Limitações
-
-
As Sessões do serviço Data Flow duram até 7 dias ou 10.080 minutos (maxDurationInMinutes).
- As sessões do serviço Data Flow têm um valor de timeout por inatividade padrão de 480 minutos (8 horas) (idleTimeoutInMinutes). Você pode configurar outro valor.
- A Sessão do serviço Data Flow só está disponível por meio de uma Sessão de Notebook do serviço Data Science.
- Somente o Spark versão 3.5.0 e 3.2.1 são suportados.
-
Assista ao vídeo tutorial sobre como usar o serviço Data Science com o Data Flow Studio. Consulte também a documentação do Oracle Accelerated Data Science SDK para obter mais informações sobre como integrar o serviço Data Science e o serviço Data Flow.
Instalando o Ambiente Conda
Siga estas etapas para usar o Data Flow com o Data Flow Magic.
Usando o Serviço Data Flow com o Serviço Data Science
Siga estas etapas para executar um aplicativo usando o serviço Data Flow com o serviço Data Science.
-
Certifique-se de ter as políticas configuradas para usar um notebook com o serviço Data Flow.
-
Certifique-se de ter as políticas do serviço Data Science configuradas corretamente.
- Para obter uma lista de todos os comandos suportados, use o comando
%help. - Os comandos nas etapas a seguir se aplicam ao Spark 3.5.0 e ao Spark 3.2.1. O Spark 3.5.0 é usado nos exemplos. Defina o valor de
sparkVersionde acordo com a versão do Spark usada.
Personalizando um Ambiente Spark do Serviço Data Flow com um Ambiente Conda
Você pode usar um ambiente conda publicado como um ambiente de runtime.
Executando a Biblioteca spark-nlp no Serviço Data Flow
Siga estas etapas para instalar a biblioteca Spark-nlp e executar no serviço Data Flow.
Você deve ter concluído as etapas 1 e 2 em Personalizando um Ambiente Spark do Serviço Data Flow com um Ambiente Conda. A biblioteca spark-nlp é pré-instalada no ambiente conda pyspark32_p38_cpu_v2.
Exemplos
Veja alguns exemplos de uso de Dados FlowMagic.
PySpark
sc representa o Spark e fica disponível quando o comando mágico %%spark é usado. A célula seguinte é um exemplo de brinquedo de como usar sc em uma célula de Dados FlowMagic. A célula chama o método .parallelize() , que cria um RDD, numbers, a partir de uma lista de números. As informações sobre o RDD são impressas. O método .toDebugString() retorna uma descrição da RDD.%%spark
print(sc.version)
numbers = sc.parallelize([4, 3, 2, 1])
print(f"First element of numbers is {numbers.first()}")
print(f"The RDD, numbers, has the following description\n{numbers.toDebugString()}")Spark SQL
O uso da opção -c sql permite executar comandos SQL do Spark em uma célula. Nesta seção, o conjunto de dados citi bike é usado. A célula a seguir lê o conjunto de dados em um dataframe do Spark e o salva como uma tabela. Este exemplo é usado para mostrar o Spark SQL.
%%spark
df_bike_trips = spark.read.csv("oci://dmcherka-dev@ociodscdev/201306-citibike-tripdata.csv", header=False, inferSchema=True)
df_bike_trips.show()
df_bike_trips.createOrReplaceTempView("bike_trips")O exemplo a seguir usa a opção -c sql para dizer aos Dados FlowMagic que o conteúdo da célula é SparkSQL. A opção -o <variable> obtém os resultados da operação Spark SQL e os armazena na variável definida. Neste caso, o
df_bike_trips é um dataframe Pandas que está disponível para uso no notebook.%%spark -c sql -o df_bike_trips
SELECT _c0 AS Duration, _c4 AS Start_Station, _c8 AS End_Station, _c11 AS Bike_ID FROM bike_trips;df_bike_trips.head()sqlContext para consultar a tabela:%%spark
df_bike_trips_2 = sqlContext.sql("SELECT * FROM bike_trips")
df_bike_trips_2.show()%%spark -c sql
SHOW TABLESWidget de Visualização Automática
Os dados FlowMagic vêm com autovizwidget que permite a visualização de dataframes Pandas. A função display_dataframe() utiliza um dataframe Pandas como parâmetro e gera uma GUI interativa no notebook. Ela tem guias que mostram a visualização dos dados em várias formas, como tabular, gráficos de pizza, gráficos de dispersão e gráficos de área e de barras.
display_dataframe() com o dataframe df_people criado na seção Spark SQL do notebook:from autovizwidget.widget.utils import display_dataframe
display_dataframe(df_bike_trips)Matplotlib
Uma tarefa comum que os cientistas de dados realizam é visualizar seus dados. Com grandes conjuntos de dados, geralmente não é possível e nem sempre é preferível extrair os dados do cluster do Spark do serviço Data Flow para a sessão de notebook. Este exemplo prova como usar recursos do lado do servidor para gerar um gráfico e incluí-lo no notebook.
%matplot plt para exibir o gráfico no notebook, mesmo que ele seja renderizado no lado do servidor:%%spark
import matplotlib.pyplot as plt
df_bike_trips.groupby("_c4").count().toPandas().plot.bar(x="_c4", y="count")
%matplot pltMais Exemplos
Mais exemplos estão disponíveis em GitHub com amostras do Serviço Data Flow e amostras do Serviço Data Science.