Inferência de Batch para Jobs
Saiba como usar os vários tipos de usos de inferência de batch com jobs.
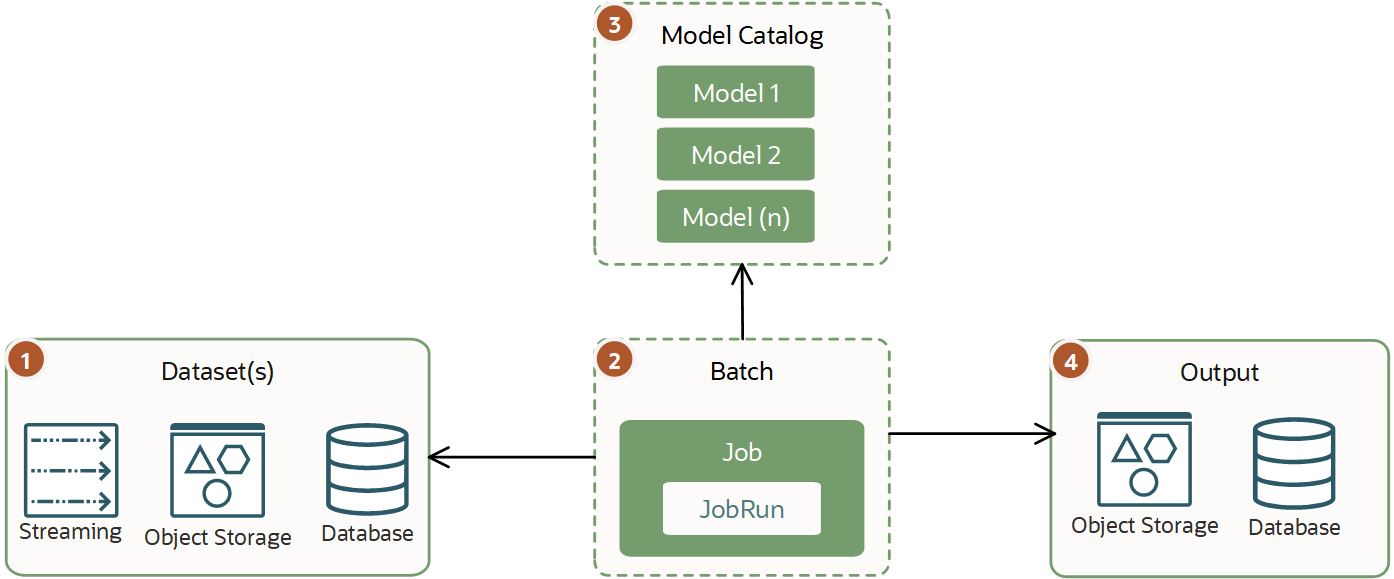
A inferência de batch tradicional é um processo assíncrono que está executando previsões com base em modelos e observações existentes e, em seguida, armazena a saída. Essa inferência de batch é um único job de máquina virtual que você pode executar com jobs do serviço Data Science.
Normalmente, uma carga de trabalho varia, mas é maior que uma inferência de min batch e pode exigir várias horas ou dias para ser finalizada. Esse tipo de carga de trabalho não exige produção de resultados em tempo real ou quase em tempo real. Ele pode ter requisitos extensivos na CPU ou na GPU e memória obrigatória para execução.
Para um melhor desempenho, use o modelo AI e ML diretamente em vez de chamá-lo em HTTP ou em outra rede. O uso direto do modelo é especialmente importante quando se exige processamento pesado com grandes conjuntos de dados. Por exemplo, processamento de imagens.
Inferência de Minibatch
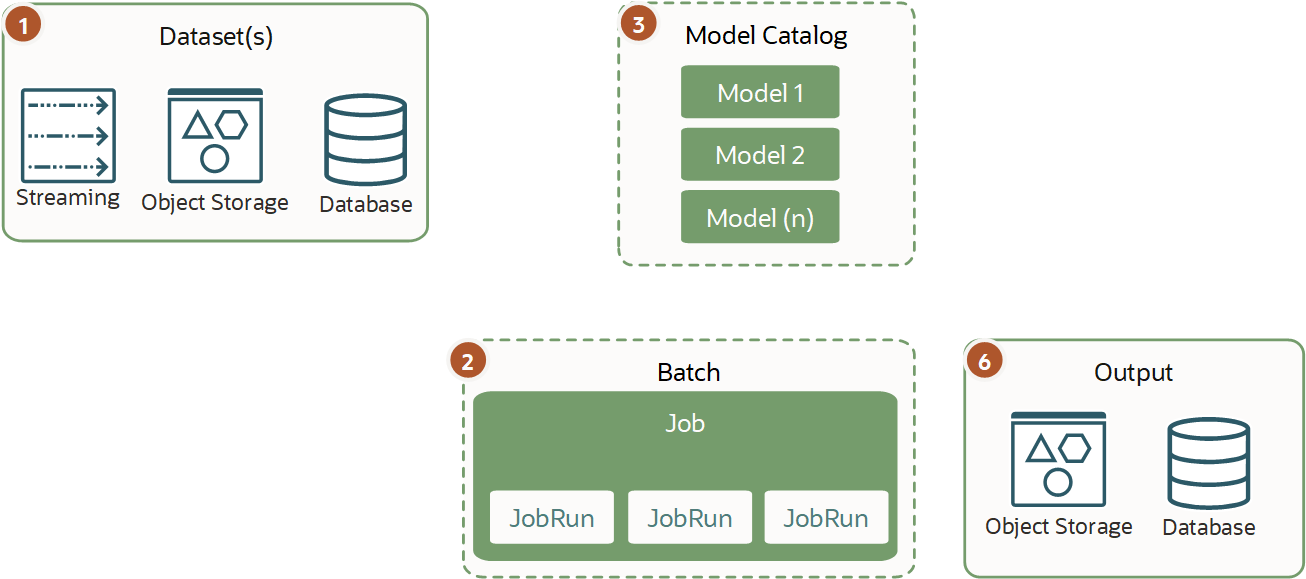
A inferência de minibatch é semelhante à inferência de batch com a diferença de que você pode dividir tarefas em batches pequenos usando vários jobs ou um único job que executa várias tarefas pequenas simultaneamente.
Como as tarefas são pequenas e os minibatches são executados regularmente, eles geralmente só são executados por vários minutos. Esse tipo de carga de trabalho é executado regularmente usando programadores ou acionadores para trabalhar em pequenos grupos de dados. O minibatch ajuda você a carregar e processar incrementalmente pequenas partes de dados ou inferência.
Você pode executar mini batches em um modelo do catálogo de modelos quando o melhor desempenho é necessário ou no modelo implantado porque geralmente as cargas de trabalho e a entrada de dados não são pesadas.
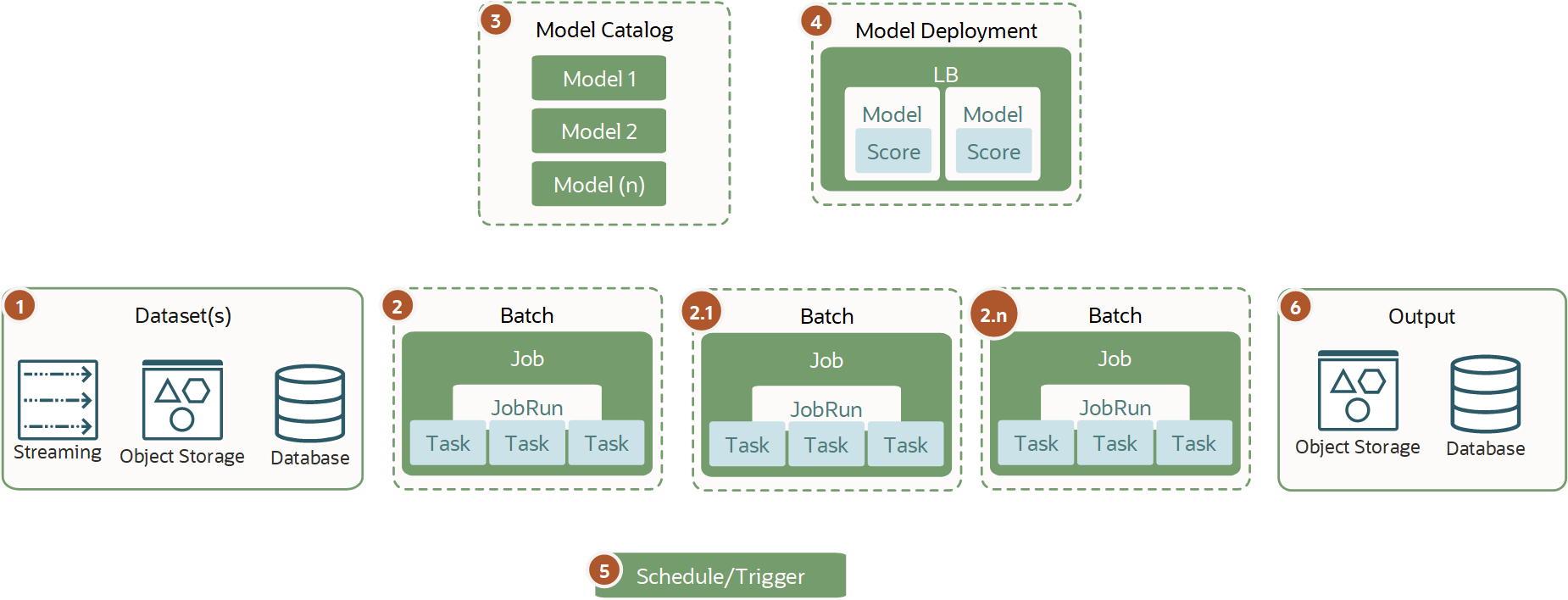
Inferência de Batch Distribuído
Você usa inferência de batch distribuído para jobs pesados.
Não confundir inferência de batch distribuído com treinamento de modelo distribuído porque são diferentes. Além disso, não é um tipo de implantação de modelo de inferência porque normalmente você deseja provisionar e usar a infraestrutura apenas durante o tempo de inferência de batch e destruí-la automaticamente ao concluir.
A inferência de batch distribuído é necessária em um conjunto de dados grande e em uma inferência pesada que não podem ser processados em tempo hábil em uma única VM ou BM e que exigem escala horizontal. Você pode ter uma ou várias configurações de job em execução (1+n) em vários tipos de infraestrutura e dividir o conjunto de dados. Esse tipo de carga de trabalho fornece o melhor desempenho quando trabalham com o modelo AI e ML diretamente do catálogo de modelos usando a memória de infraestrutura, CPU ou GPU até o máximo de jobs em uso.
Comparar Cargas de Trabalho de Inferência de Batch
Uma comparação de alto nível entre os diferentes tipos de cargas de trabalho e os tipos de inferência de batch correspondentes:
|
Inferência de Batch |
Inferência de Minibatch |
Inferência de Batch Distribuído |
|
|---|---|---|---|
|
Infraestrutura |
Grande |
Leve a média |
Muito grande |
|
VM |
Única |
Único ou muitos (em pequena escala) |
Muitos |
|
Velocidade de Provisionamento - Obrigatória |
Média |
Rápida |
Média a lenta |
|
Programações - Obrigatórias |
Sim |
Sim |
Dependente do caso de uso |
|
Trigger - Obrigatório |
Sim |
Sim |
Não |
|
Cargas de Trabalho |
Grande |
Leve |
Grande ou pesada |
|
Tamanho dos Conjuntos de Dados |
Grande |
Pequeno |
Dimensionamento extremamente grande ou automático |
|
Tempo de Processamento de Batch (no entanto, a estimativa pode ser diferente, dependendo do caso de uso) |
Médio a muito longo (de dois dígitos de minutos de processo até dias ou horas) |
Curto até quase em tempo real |
Médio a muito longo (de algumas horas até dias) |
|
Implantação de Modelo |
Não é obrigatório |
Sim, mas não é obrigatório |
Não é obrigatório |
|
Pontos Finais |
Não |
Não |
Não |