Modelos de IA de Documentos pré-treinados
O Vision fornece modelos de IA de documentos pré-treinados que permitem organizar e extrair texto e estrutura de documentos de negócios.
Os recursos AnalyzeDocument e DocumentJob do Vision estão migrando para um novo serviço, o Document Understanding. Os seguintes recursos são afetados:
- Detecção de tabelas
- Classificação de documentos
- Extração de chave-valor de recebimento
- Documentar o OCR
Casos de Uso
Os modelos de IA de documentos pré-treinados permitem automatizar operações de back-office e processar recebimentos com mais precisão.
- Pesquisa inteligente
- Enriqueça arquivos baseados em imagem com metadados, incluindo tipo de documento e campos-chave, para facilitar a recuperação.
- Relatório de despesa
- Extraia as informações necessárias de recebimentos para automatizar fluxos de trabalho de negócios. Por exemplo, relatórios de despesas de funcionários, conformidade de gastos e reembolso.
- Processamento de Linguagem Natural Downstream (NLP)
- Extraia texto de arquivos PDF e organize-o como entrada para NLP, seja em tabelas ou em palavras e linhas.
- Captura de pontos de fidelidade
- Automatize os cálculos de pontos de fidelidade dos recebimentos, com base no número de itens ou no valor total pago.
Formatos Suportados
O Vision suporta vários formatos de documento.
- JPEG
- PNG
- TIFF
Modelos Pré-treinados
A visão tem cinco tipos de modelo pré-treinado.
OCR (Optical Character Recognition)
O Vision pode detectar e reconhecer texto em um documento. A classificação de idioma identifica o idioma de um documento, então o OCR desenha caixas delimitadoras em torno do texto impresso ou escrito à mão que encontra em uma imagem e digitaliza o texto.
Se você tiver um PDF com texto, o Vision localizará o texto nesse documento e extrairá o texto. Em seguida, ele fornece caixas delimitadoras para o texto identificado. A Detecção de Texto pode ser usada com modelos de IA de Documento ou Análise de Imagem.
A Vision fornece uma pontuação de confiança para cada agrupamento de texto. A pontuação de confiança é um número decimal. Pontuações mais próximas de 1 indicam maior confiança no texto extraído, enquanto pontuações mais baixas indicam menor pontuação de confiança. O intervalo da pontuação de confiança para cada rótulo é de 0 a 1.
O suporte ao OCR é limitado ao inglês. Se você souber que o texto nas imagens está em inglês, defina o idioma como
Eng.- Extração de palavra
- Extração de linha de texto
- Pontuação de confiança
- Polígonos delimitadores
- Solicitação única
- Solicitação em batch
- Embora a classificação de idioma identifique vários idiomas, o OCR é limitado ao inglês.
Um exemplo de uso do OCR no Vision.
- Documento de entrada
-
Entrada OCR

.{ "analyzeDocumentDetails": { "compartmentId": "", "document": { "namespaceName": "", "bucketName": "", "objectName": "", "source": "OBJECT_STORAGE" }, "features": [ { "featureType": "TEXT_DETECTION" }, { "featureType": "LANGUAGE_CLASSIFICATION", "maxResults": 5 } ] } } - Saída:
- Saída OCR
 Resposta da API:
Resposta da API: { "documentMetadata": { "pageCount": 1, "mimeType": "image/jpeg" }, "pages": [ { "pageNumber": 1, "dimensions": { "width": 361, "height": 600, "unit": "PIXEL" }, "detectedLanguages": [ { "languageCode": "ENG", "confidence": 0.9999994 }, { "languageCode": "ARA", "confidence": 4.7619238e-7 }, { "languageCode": "NLD", "confidence": 7.2325456e-8 }, { "languageCode": "CHI_SIM", "confidence": 3.0645523e-8 }, { "languageCode": "ITA", "confidence": 8.6900076e-10 } ], "words": [ { "text": "Example", "confidence": 0.99908227, "boundingPolygon": { "normalizedVertices": [ { "x": 0.0664819944598338, "y": 0.011666666666666667 }, { "x": 0.22160664819944598, "y": 0.011666666666666667 }, { "x": 0.22160664819944598, "y": 0.035 }, { "x": 0.0664819944598338, "y": 0.035 } ] } ... "detectedLanguages": [ { "languageCode": "ENG", "confidence": 0.9999994 } ], ...
Classificação do Documento
A Classificação do Documento pode ser usada para classificar um documento.
- NFF
- Recebimento
- Currículo ou CV
- Formulário de imposto
- carteira de habilitação
- Passaporte
- Demonstrativo bancário
- Marcar
- Demonstrativo de Pagamento
- Outros
- Classificar documento
- Pontuação de confiança
- Solicitação única
- Solicitação em batch
Um exemplo de uso de classificação de documento no Vision.
- Documento de entrada
- Entrada da Classificação do Documento
- Saída:
- Resposta da API:
{ "documentMetadata": { "pageCount": 1, "mimeType": "image/jpeg" }, "pages": [ { "pageNumber": 1, "dimensions": { "width": 361, "height": 600, "unit": "PIXEL" }, "detectedDocumentTypes": [ { "documentType": "RECEIPT", "confidence": 1 }, { "documentType": "TAX_FORM", "confidence": 6.465067e-9 }, { "documentType": "CHECK", "confidence": 6.031838e-9 }, { "documentType": "BANK_STATEMENT", "confidence": 5.413888e-9 }, { "documentType": "PASSPORT", "confidence": 1.5554872e-9 } ], ... detectedDocumentTypes": [ { "documentType": "RECEIPT", "confidence": 1 } ], ...
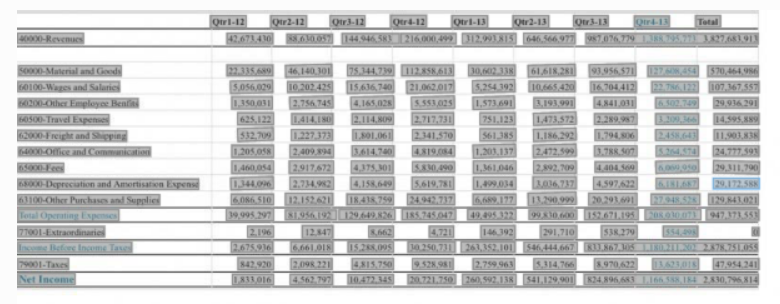
Extração de Tabela
A extração de tabelas pode ser usada para identificar tabelas em um documento e extrair seu conteúdo. Por exemplo, se um recebimento em PDF contiver uma tabela que inclua os impostos e o valor total, o Vision identificará a tabela e extrairá a estrutura da tabela.
A Vision fornece o número de linhas e colunas da tabela e o conteúdo de cada célula da tabela. Cada célula tem uma pontuação de confiança. A pontuação de confiança é um número decimal. Pontuações mais próximas de 1 indicam maior confiança no texto extraído, enquanto pontuações mais baixas indicam menor pontuação de confiança. O intervalo da pontuação de confiança para cada rótulo é de 0 a 1.
- Extração de tabelas para tabelas com e sem bordas
- Polígonos delimitadores
- Pontuação de confiança
- Solicitação única
- Solicitação em batch
- Somente idioma inglês
Um exemplo de uso de extração de tabela no Vision.
- Documento de entrada
- Entrada de Extração de Tabela

- Saída:
- Saída de Extração da Tabela
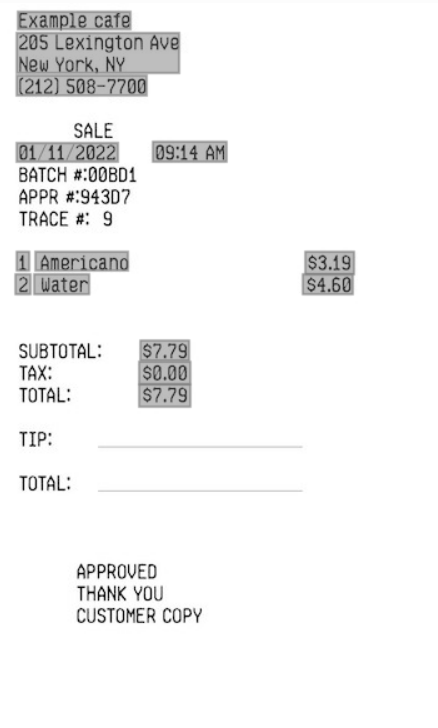
Extração de Chave-Valor (Recibos)
A extração de valor de chave pode ser usada para identificar valores para chaves predefinidas em um recebimento. Por exemplo, se um recibo incluir um nome de comerciante, endereço de comerciante ou número de telefone de comerciante, a Vision poderá identificar esses valores e retorná-los como um par de valores-chave.
- Extrair valores para pares de valores-chave predefinidos
- Polígonos delimitadores
- Solicitação única
- Solicitação em batch
- Suporta recibos apenas em inglês.
- MerchantName
- O nome do comerciante que emitiu o recibo.
- MerchantPhoneNumber
- O número de telefone do comerciante.
- MerchantAddress
- O endereço do comerciante.
- TransactionDate
- A data em que o recebimento foi emitido.
- TransactionTime
- A hora em que o recibo foi emitido.
- Total
- O valor total do recebimento, após a aplicação de todos os encargos e impostos.
- Subtotal
- O subtotal antes dos impostos.
- Tax
- Quaisquer impostos sobre vendas.
- Dica
- A quantidade de gorjeta dada pelo comprador.
- ItemName
- Nome do item.
- ItemPrice
- Preço unitário do item.
- ItemQuantity
- O número de cada item comprado.
- ItemTotalPrice
- O preço total do item de linha.
Um exemplo de uso de extração de valor-chave no Vision.
- Documento de entrada
- Entrada de Extração de Chave-Valor (Recibos)
- Saída:
- Saída de Extração de Chave-Valor (Recibos)
PDF do OCR (Ótico de Reconhecimento de Caracteres)
O OCR PDF gera um arquivo PDF pesquisável no Object Storage. Por exemplo, o Vision pode pegar um arquivo PDF com texto e imagens e retornar um arquivo PDF onde você pode procurar o texto no PDF.
- Gerar PDF pesquisável
- Solicitação única
- Solicitação em batch
Um exemplo de uso do OCR PDF no Vision.
- Entrada
-
OCR ODF Input
 Solicitação de API:
Solicitação de API:{ "analyzeDocumentDetails": { "compartmentId": "", "document": { "source": "INLINE", "data": "......" }, "features": [ { "featureType": "TEXT_DETECTION", "generateSearchablePdf": true } ] } } - Saída:
- PDF Pesquisável.
Usando os Modelos Pré-treinados de IA de Documentos
A Vision fornece modelos pré-treinados para que os clientes extraiam insights sobre seus documentos sem precisar de Cientistas de Dados.
Você precisa do seguinte antes de usar um modelo pré-treinado:
-
Uma conta de tenancy paga no Oracle Cloud Infrastructure.
-
Familiaridade com o Oracle Cloud Infrastructure Object Storage.
Você pode chamar os modelos de IA de Documento pré-treinados como uma solicitação em lote usando APIs Rest, SDK ou CLI. Você pode chamar os modelos de IA de Documento pré-treinados como uma única solicitação usando a Console, APIs Rest, SDK ou CLI.
Consulte a seção Limites para obter informações sobre o que é permitido em solicitações de batch.