Sobre Pipelines de Dados no Autonomous AI Database
Os pipelines de dados do Autonomous AI Database são pipelines de carga ou de exportação.
Os pipelines de carga fornecem carregamento contínuo de dados incrementais de origens externas (à medida que os dados chegam ao armazenamento de objetos, eles são carregados em uma tabela de banco de dados). Os pipelines de exportação fornecem exportação contínua de dados incrementais para o armazenamento de objetos (como novos dados aparecem em uma tabela de banco de dados, eles são exportados para o armazenamento de objetos). Os pipelines usam o scheduler de banco de dados para carregar ou exportar continuamente dados incrementais.
Os pipelines de dados do Autonomous AI Database fornecem o seguinte:
-
Operações Unificadas: Os pipelines permitem que você carregue ou exporte dados com rapidez e facilidade e repita essas operações em intervalos regulares para novos dados. O pacote
DBMS_CLOUD_PIPELINEfornece um conjunto unificado de procedimentos PL/SQL para configuração de pipeline e para criar e iniciar um job programado para operações de carga ou exportação. -
Processamento de Dados Programado: Os pipelines monitoram sua origem de dados e carregam ou exportam periodicamente os dados à medida que novos dados chegam.
-
Alto Desempenho: Os pipelines dimensionam as operações de transferência de dados com os recursos disponíveis no seu Autonomous AI Database. Por padrão, os pipelines usam paralelismo para todas as operações de carga ou exportação, e dimensionam com base nos recursos de CPU disponíveis no Autonomous AI Database ou com base em um atributo de prioridade configurável.
-
Atomicidade e Recuperação: Os pipelines garantem a atomicidade de modo que os arquivos no armazenamento de objetos sejam carregados exatamente uma vez para um pipeline de carga.
-
Monitoramento e Diagnóstico e Solução de Problemas: Os pipelines fornecem tabelas detalhadas de log e status que permitem monitorar e depurar operações de pipeline.
-
Compatível com Várias Nuvens: Os pipelines no Autonomous AI Database suportam a fácil alternância entre provedores de nuvem sem alterações nas aplicações. Os pipelines suportam todos os formatos de URI de credenciais e armazenamento de objetos que o Autonomous AI Database suporta (Oracle Cloud Infrastructure Object Storage, Amazon S3, Azure Blob Storage ou Azure Data Lake Storage, Google Cloud Storage e armazenamentos de objetos compatíveis com Amazon S3).
Sobre o Ciclo de Vida do Pipeline de Dados no Autonomous AI Database
O pacote DBMS_CLOUD_PIPELINE fornece procedimentos para criar, configurar, testar e iniciar um pipeline. O ciclo de vida e os procedimentos do pipeline são os mesmos para pipelines de carga e exportação.
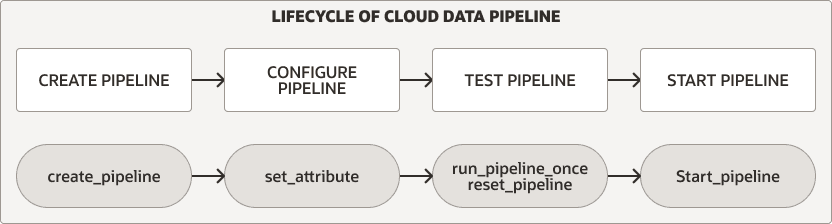
Descrição da ilustração pipeline_lifecycle.png
Para qualquer tipo de pipeline, você executa as seguintes etapas para criar e usar um pipeline:
-
Crie e configure o pipeline. Consulte Criar e Configurar Pipelines para obter mais informações.
-
Teste um novo pipeline. Consulte Testar Pipelines para obter mais informações.
-
Inicie um pipeline. Consulte Iniciar um Pipeline para obter mais informações.
Além disso, você pode monitorar, interromper ou eliminar pipelines:
-
Enquanto um pipeline está em execução, durante o teste ou durante o uso regular depois de iniciar o pipeline, você pode monitorar o pipeline. Consulte Monitorar e Solucionar Problemas de Pipelines para obter mais informações.
-
Você pode interromper um pipeline e iniciá-lo novamente mais tarde ou eliminar um pipeline quando terminar de usar o pipeline. Consulte Interromper um Pipeline e Eliminar um Pipeline para obter mais informações.
Sobre Pipelines de Carga no Autonomous AI Database
Use um pipeline de carga para carregamento contínuo de dados incrementais de arquivos externos no armazenamento de objetos em uma tabela de banco de dados. Um pipeline de carregamento identifica periodicamente novos arquivos no armazenamento de objetos e carrega os novos dados na tabela do banco de dados.
Um pipeline de carga opera da seguinte forma (alguns desses recursos são configuráveis usando atributos de pipeline):
-
Os arquivos do armazenamento de objetos são carregados em paralelo em uma tabela de banco de dados.
-
Um Pipeline de carregamento usa o nome do arquivo de armazenamento de objetos para identificar e carregar exclusivamente arquivos mais novos.
-
Depois que um arquivo no armazenamento de objetos for carregado na tabela do banco de dados, se o conteúdo do arquivo for alterado no armazenamento de objetos, ele não será carregado novamente.
-
Se o arquivo de armazenamento de objetos for excluído, ele não afetará os dados na tabela de banco de dados.
-
-
Se forem encontradas falhas, um pipeline de carga repetirá automaticamente a operação. Tentativas de novas tentativas em cada execução subsequente do job programado do pipeline.
-
Nos casos em que os dados em um arquivo não estão em conformidade com a tabela do banco de dados, ele é marcado como
FAILEDe pode ser revisado para depurar e solucionar o problema.- Se qualquer arquivo falhar ao carregar, o pipeline não será interrompido e continuará a carregar os outros arquivos.
-
Os pipelines de carga suportam vários formatos de arquivo de entrada, incluindo: JSON, CSV, XML, Avro, ORC e Parquet.
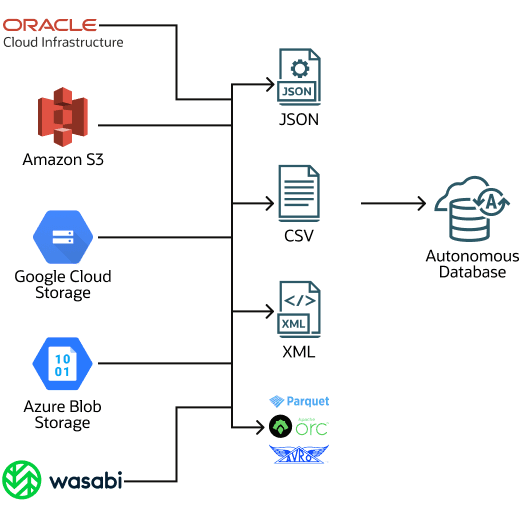
A migração de bancos de dados não Oracle é um caso de uso possível para um pipeline de carga. Quando você precisar migrar seus dados de um banco de dados não Oracle para o Oracle Autonomous AI Database, poderá extrair os dados e carregá-los no Autonomous AI Database (o formato Oracle Data Pump não pode ser usado para migrações de bancos de dados não Oracle). Usando um formato de arquivo genérico, como CSV, para exportar dados de um banco de dados não Oracle, você pode salvar seus dados em arquivos e fazer upload dos arquivos para o armazenamento de objetos. Em seguida, crie um pipeline para carregar os dados no Autonomous AI Database. O uso de um pipeline de carga para carregar um grande conjunto de arquivos CSV fornece benefícios importantes, como tolerância a falhas e operações de retomada e repetição. Para uma migração com um grande conjunto de dados, você pode criar vários pipelines, um por tabela, para os arquivos de banco de dados não Oracle, para carregar dados no Autonomous AI Database.
Sobre Pipelines de Exportação no Autonomous AI Database
Use um pipeline de exportação para exportação incremental contínua de dados do banco de dados para o armazenamento de objetos. Um pipeline de exportação identifica periodicamente os dados candidatos e faz upload dos dados para o armazenamento de objetos.
Há três opções de pipeline de exportação (as opções de exportação são configuráveis usando atributos de pipeline):
-
Exporte resultados incrementais de uma consulta para o armazenamento de objetos usando uma coluna de data ou timestamp como chave para rastrear dados mais recentes.
-
Exporte dados incrementais de uma tabela para armazenamento de objetos usando uma coluna de data ou timestamp como chave para rastrear dados mais recentes.
-
Exporte dados de uma tabela para armazenamento de objetos usando uma consulta para selecionar dados sem uma referência a uma coluna de data ou timestamp (para que o pipeline exporte todos os dados que a consulta seleciona para cada execução do scheduler).
Os pipelines de exportação têm os seguintes recursos (alguns deles são configuráveis usando atributos de pipeline):
-
Os resultados são exportados em paralelo para o armazenamento de objetos.
-
Em caso de falhas, um job de pipeline subsequente repete a operação de exportação.
-
Os pipelines de exportação suportam vários formatos de arquivo de exportação, incluindo: CSV, JSON, Parquet ou XML.
Sobre Pipelines Mantidos pela Oracle
O Autonomous AI Database fornece pipelines incorporados para exportar logs para o armazenamento de objetos. Esses pipelines são pré-configurados e podem ser iniciados pelo usuário ADMIN.
Os pipelines Mantidos pela Oracle são:
-
ORA$AUDIT_EXPORT: Este pipeline exporta os logs de auditoria do banco de dados para o armazenamento de objetos no formato JSON e é executado a cada 15 minutos após o início do pipeline (com base no valor do atributointerval). -
ORA$APEX_ACTIVITY_EXPORT: Este pipeline exporta o log de atividades do espaço de trabalho do Oracle APEX para o armazenamento de objetos no formato JSON. Esse pipeline é pré-configurado com a consulta SQL para recuperar registros de atividade do APEX e é executado a cada 15 minutos após o início do pipeline (com base no valor do atributointerval).
Os pipelines Mantidos pela Oracle pertencem ao usuário ADMIN e os atributos dos Pipelines Mantidos pela Oracle podem ser modificados pelo usuário ADMIN.
Por padrão, os Pipelines Mantidos pela Oracle usam OCI$RESOURCE_PRINCIPAL como o credential_name.
Consulte Usar Pipelines Mantidos pela Oracle para obter mais informações.