Observação:
- Este tutorial requer acesso ao Oracle Cloud. Para se inscrever em uma conta gratuita, consulte Conceitos básicos do Oracle Cloud Infrastructure Free Tier.
- Ele usa valores de exemplo para credenciais, tenancy e compartimentos do Oracle Cloud Infrastructure. Ao concluir seu laboratório, substitua esses valores por valores específicos do seu ambiente de nuvem.
Execute o Modelo Mistral LLM na Instância A10 do OCI Compute com o Oracle Resource Manager usando a Implantação com um Clique
Introdução
O Oracle Cloud Infrastructure (OCI) Compute permite criar diferentes tipos de formas para testar modelos gráficos de Unidade de Processamento (GPU) para Inteligência Artificial (AI) implantados localmente. Neste tutorial, usaremos a forma A10 com recursos de VCN e sub-rede pré-existentes que você pode selecionar no Oracle Resource Manager.
O código do Terraform também inclui configurar a instância para executar um modelo Mistral (vLLM) Virtual Large Language Model (VML) local para tarefas de processamento de linguagem natural.
Objetivos
- Crie uma forma A10 no OCI Compute, faça download do modelo Mistral AI LLM e consulte o modelo vLLM local.
Pré-requisitos
-
Certifique-se de ter uma VCN (Rede Virtual na Nuvem) do OCI e uma sub-rede na qual a máquina virtual (VM) será implantada.
-
Compreensão dos componentes de rede e seus relacionamentos. Para obter mais informações, consulte Visão Geral do Serviço Networking.
-
Compreensão da rede na nuvem. Para obter mais informações, assista ao seguinte vídeo: Vídeo for Networking in the Cloud EP.01: Virtual Cloud Networks.
-
Requisitos:
- Tipo de Instância: Forma A10 com uma GPU Nvidia.
- Sistema Operacional: Oracle Linux.
- Seleção de Imagem: O script de implantação seleciona a imagem mais recente do Oracle Linux com suporte a GPU.
- Tags: Adiciona uma tag de formato livre GPU_TAG = "A10-1".
- Tamanho do Volume de Inicialização: 250GB.
- Inicialização: Usa cloud-init para fazer download e configurar o(s) modelo(s) Mistral vLLM.
Tarefa 1: Fazer Download do Código do Terraform para Implantação com um Clique
Faça download do código do Terraform do ORM aqui: orm_stack_a10_gpu-main.zip, para implementar o(s) modelo(s) Mistral vLLM localmente, o que permitirá que você selecione uma VCN existente e uma sub-rede para testar a implantação local do(s) modelo(s) Mistral vLLM em uma forma de instância A10.
Depois de fazer download do código do Terraform do ORM localmente, siga as etapas a partir daqui: Criando uma Pilha com Base em uma Pasta para fazer upload da pilha e executar a aplicação do código do Terraform.
Observação: certifique-se de ter criado uma VCN (Rede Virtual na Nuvem) do OCI e uma sub-rede na qual a VM será implantada.
Tarefa 2: Criar uma VCN no OCI (Opcional se ainda não tiver sido criada)
Para criar uma VCN no Oracle Cloud Infrastructure, consulte: Vídeo para Explorar como criar uma Rede Virtual na Nuvem no OCI.
ou
Para criar uma VCN, siga as etapas:
-
Faça log-in na Console do OCI, digite Nome do Tenant do Cloud, Nome do Usuário e Senha.
-
Clique no menu de hambúrguer (≡) no canto superior esquerdo.
-
Vá para Rede, Redes Virtuais na Nuvem e selecione o compartimento apropriado na seção Escopo da Lista.
-
Selecione VCN com Conectividade de Internet, e clique em Iniciar Assistente de VCN.
-
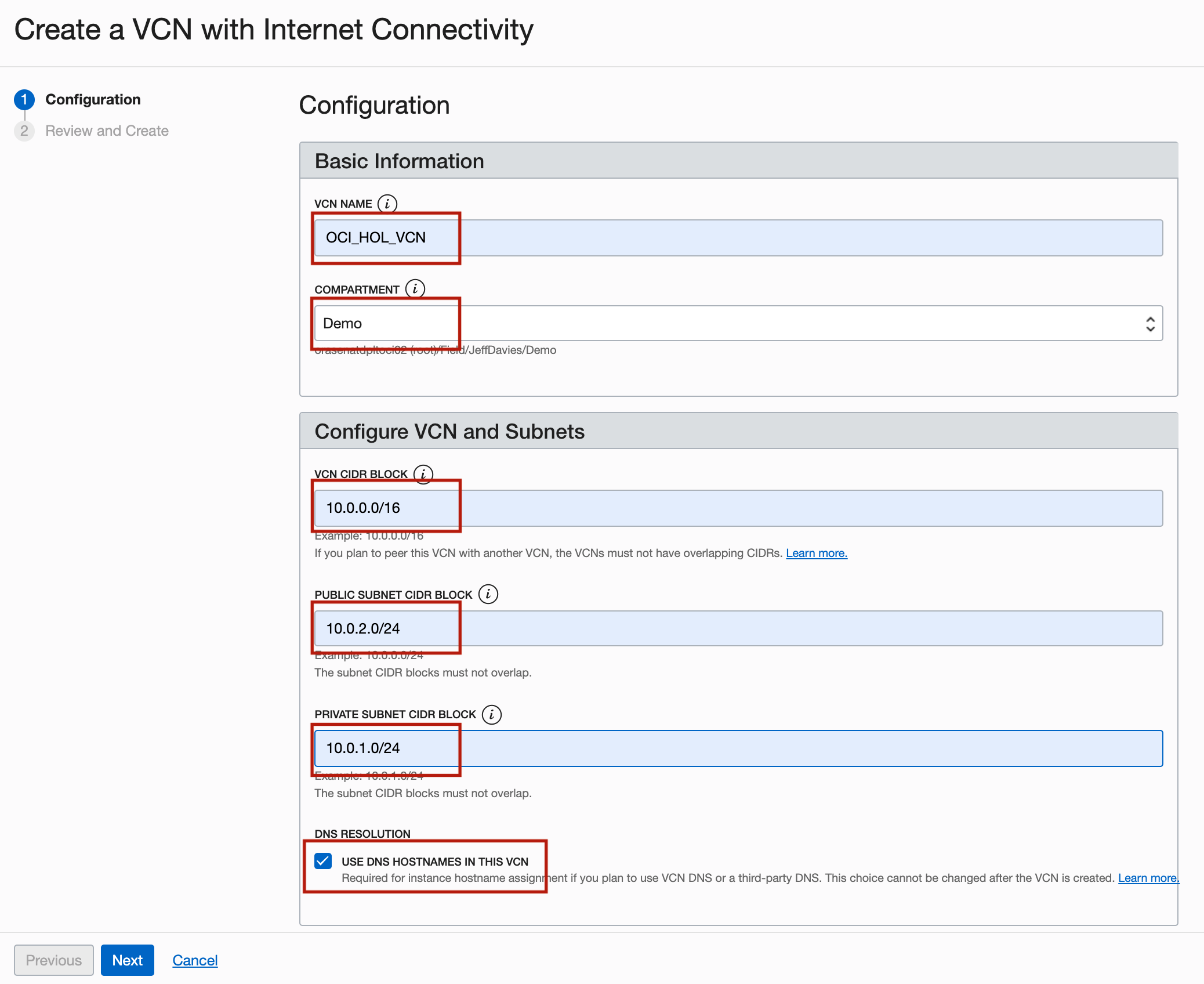
Na página Criar uma VCN com Conectividade de Internet, digite as informações a seguir e clique em Próximo.
- VCN NAME: Digite
OCI_HOL_VCN. - COMPARTAMENTO: Selecione o compartimento apropriado.
- BLOCO CIDR de VCN: Digite
10.0.0.0/16. - BLOCO CIDR DA SUB-REDE PÚBLICA: Digite
10.0.2.0/24. - BLOCO CIDR da SUB-rede Privada: Digite
10.0.1.0/24. - Resolução de DNS: Selecione USE DNS HOSTNAMES IN THIS VCN.
- VCN NAME: Digite
-
Na página Verificar, revise suas definições e clique em Criar.
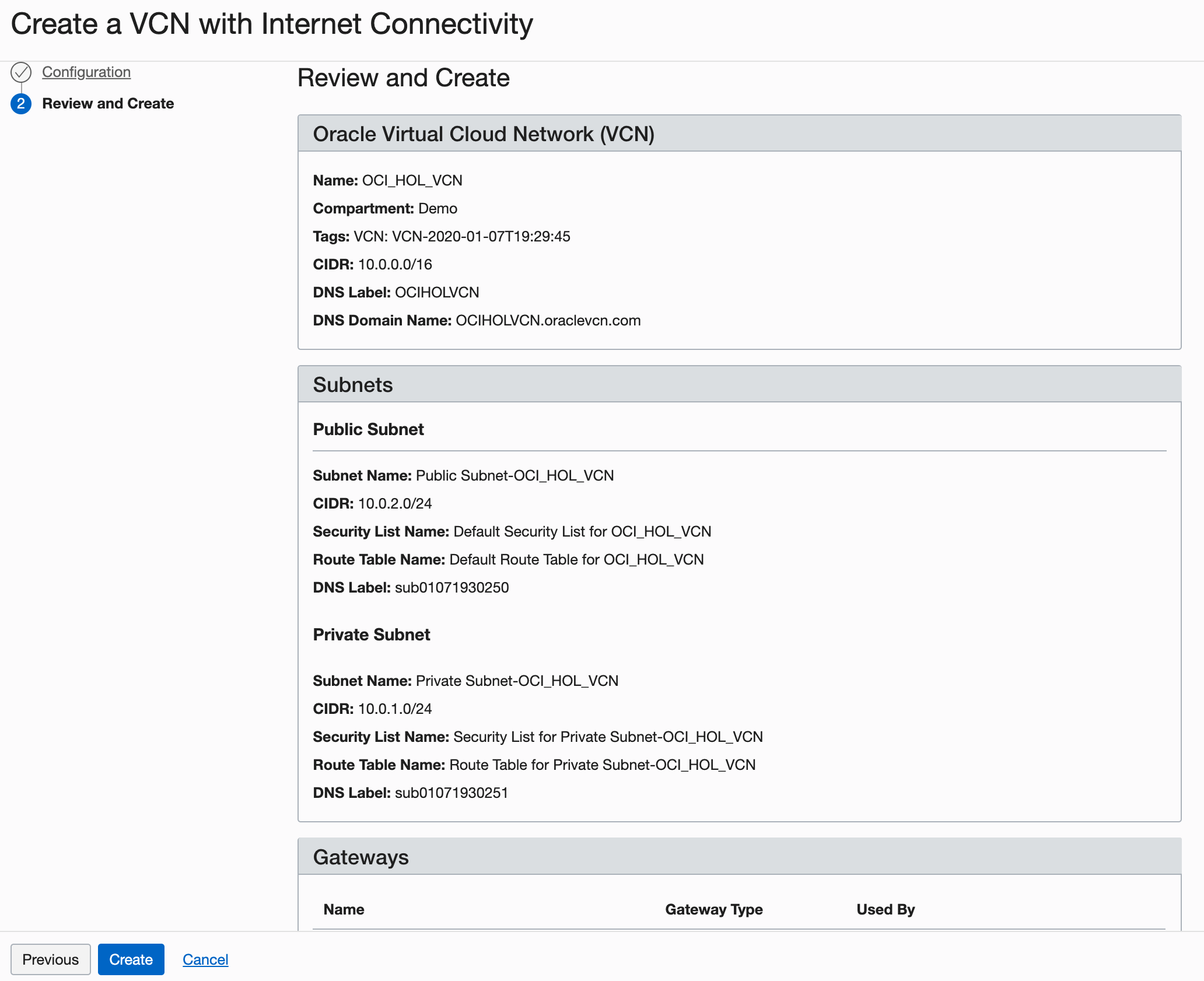
Descrição da ilustração setupVCN4.png
Levará um momento para criar a VCN e uma tela de andamento manterá você informado sobre o workflow.

-
Depois que a VCN for criada, clique em View Virtual Cloud Network.
Em situações do mundo real, você criará várias VCNs com base em sua necessidade de acesso (quais portas abrir) e quem pode acessá-las.
Tarefa 3: Consulte os Detalhes da Configuração cloud-init
O script cloud-init instala todas as dependências necessárias, inicia o Docker, faz download e inicia o(s) modelo(s) vLLM Mistral. Você pode encontrar o código a seguir no arquivo cloudinit.sh baixado na Tarefa 1.
dnf install -y dnf-utils zip unzip
dnf config-manager --add-repo=https://download.docker.com/linux/centos/docker-ce.repo
dnf remove -y runc
dnf install -y docker-ce --nobest
systemctl enable docker.service
dnf install -y nvidia-container-toolkit
systemctl start docker.service
...
O Cloud-init fará download de todos os arquivos necessários para executar o modelo Mistral com base em seu token de API predefinido no Hugging Face.
A criação do token da API selecionará o modelo Mistral com base em sua entrada na GUI do ORM, permitindo a autenticação necessária para fazer download dos arquivos do modelo localmente. Para obter mais informações, consulte Tokens de acesso do usuário.
Tarefa 4: Monitorar o Sistema
Rastreie a conclusão do script cloud-init e o uso de recursos de GPU com os seguintes comandos (se necessário).
-
Monitore a conclusão do cloud-init:
tail -f /var/log/cloud-init-output.log. -
Monitore a utilização de GPUs:
nvidia-smi dmon -s mu -c 100. -
Implante e interaja com o modelo Mistral vLLM usando Python: (Altere os parâmetros somente se necessário (o comando já está incluído no script
cloud-init)):python -O -u -m vllm.entrypoints.openai.api_server \ --host 0.0.0.0 \ --model "/home/opc/models/${MODEL}" \ --tokenizer hf-internal-testing/llama-tokenizer \ --max-model-len 16384 \ --enforce-eager \ --gpu-memory-utilization 0.8 \ --max-num-seqs 2 \ >> "${MODEL}.log" 2>&1 &
Tarefa 5: Testar a Integração do Modelo
Interaja com o modelo das seguintes maneiras usando os comandos ou os detalhes do Jupyter Notebook.
-
Teste o modelo na CLI (Interface de Linha de Comando) depois que o script
cloud-initfor concluído.curl -X 'POST' 'http://0.0.0.0:8000/v1/chat/completions' \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -d '{ "model": "/home/opc/models/'"$MODEL"'", "messages": [{"role":"user", "content":"Write a small poem."}], "max_tokens": 64 }' -
Teste o modelo no Jupyter Notebook (certifique-se de abrir a porta
8888).import requests import json import os # Retrieve the MODEL environment variable model = os.environ.get('MODEL') url = 'http://0.0.0.0:8000/v1/chat/completions' headers = { 'accept': 'application/json', 'Content-Type': 'application/json', } data = { "model": f"/home/opc/models/{model}", "messages": [{"role": "user", "content": "Write a short conclusion."}], "max_tokens": 64 } response = requests.post(url, headers=headers, json=data) if response.status_code == 200: result = response.json() # Pretty print the response for better readability formatted_response = json.dumps(result, indent=4) print("Response:", formatted_response) else: print("Request failed with status code:", response.status_code) print("Response:", response.text) -
Integre o Gradio ao Chatbot para consultar o modelo.
import requests import gradio as gr import os def interact_with_model(prompt): model = os.getenv("MODEL") # Retrieve the MODEL environment variable within the function url = 'http://0.0.0.0:8000/v1/chat/completions' headers = { 'accept': 'application/json', 'Content-Type': 'application/json', } data = { "model": f"/home/opc/models/{model}", "messages": [{"role": "user", "content": prompt}], "max_tokens": 64 } response = requests.post(url, headers=headers, json=data) if response.status_code == 200: result = response.json() completion_text = result["choices"][0]["message"]["content"].strip() # Extract the generated text return completion_text else: return {"error": f"Request failed with status code {response.status_code}"} # Example Gradio interface iface = gr.Interface( fn=interact_with_model, inputs=gr.Textbox(lines=2, placeholder="Write a prompt..."), outputs=gr.Textbox(type="text", placeholder="Response..."), title="Mistral 7B Chat Interface", description="Interact with the Mistral 7B model deployed locally via Gradio.", live=True ) # Launch the Gradio interface iface.launch(share=True)
Tarefa 6: Implantar o Modelo usando o Docker (se necessário)
Como alternativa, implante o modelo usando o Docker e a origem externa.
docker run --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
--env "HUGGING_FACE_HUB_TOKEN=$ACCESS_TOKEN" \
-p 8000:8000 \
--ipc=host \
--restart always \
vllm/vllm-openai:latest \
--model mistralai/$MODEL \
--max-model-len 16384
Você pode consultar o modelo das seguintes maneiras:
-
Consulte o modelo iniciado com o Docker e a origem externa usando a CLI.
curl -X 'POST' 'http://0.0.0.0:8000/v1/chat/completions' \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -d '{ "model": "mistralai/'"$MODEL"'", "messages": [{"role": "user", "content": "Write a small poem."}], "max_tokens": 64 }' -
Consulte o modelo com o Docker de origem externa usando o Jupyter Notebook.
import requests import json import os # Retrieve the MODEL environment variable model = os.environ.get('MODEL') url = 'http://0.0.0.0:8000/v1/chat/completions' headers = { 'accept': 'application/json', 'Content-Type': 'application/json', } data = { "model": f"mistralai/{model}", "messages": [{"role": "user", "content": "Write a short conclusion."}], "max_tokens": 64 } response = requests.post(url, headers=headers, json=data) if response.status_code == 200: result = response.json() # Pretty print the response for better readability formatted_response = json.dumps(result, indent=4) print("Response:", formatted_response) else: print("Request failed with status code:", response.status_code) print("Response:", response.text) -
Consulte o modelo com o Docker de origem externa usando o Jupyter Notebook e o Gradio Chatbot.
import requests import gradio as gr import os # Function to interact with the model via API def interact_with_model(prompt): url = 'http://0.0.0.0:8000/v1/chat/completions' headers = { "accept": "application/json", "Content-Type": "application/json", } # Retrieve the MODEL environment variable model = os.environ.get('MODEL') data = { "model": f"mistralai/{model}", "messages": [{"role": "user", "content": prompt}], "max_tokens": 64 } response = requests.post(url, headers=headers, json=data) if response.status_code == 200: result = response.json() completion_text = result["choices"][0]["message"]["content"].strip() # Extract the generated text return completion_text else: return {"error": f"Request failed with status code {response.status_code}"} # Example Gradio interface iface = gr.Interface( fn=interact_with_model, inputs=gr.Textbox(lines=2, placeholder="Write a prompt..."), outputs=gr.Textbox(type="text", placeholder="Response..."), title="Model Interface", # Set a title for your Gradio interface description="Interact with the model deployed via Gradio.", # Set a description live=True ) # Launch the Gradio interface iface.launch(share=True) -
Modelo em execução com o docker usando os arquivos locais já baixados (começa mais rápido).
docker run --gpus all \ -v /home/opc/models/$MODEL/:/mnt/model/ \ --env "HUGGING_FACE_HUB_TOKEN=$TOKEN_ACCESS" \ -p 8000:8000 \ --env "TRANSFORMERS_OFFLINE=1" \ --env "HF_DATASET_OFFLINE=1" \ --ipc=host vllm/vllm-openai:latest \ --model="/mnt/model/" \ --max-model-len 16384 \ --tensor-parallel-size 2 -
Consulte o modelo com o Docker usando os arquivos locais e a CLI.
curl -X 'POST' 'http://0.0.0.0:8000/v1/chat/completions' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{ > "model": "/mnt/model/", > "messages": [{"role": "user", "content": "Write a humorous limerick about the wonders of GPU computing."}], > "max_tokens": 64, > "temperature": 0.7, > "top_p": 0.9 > }' -
Consulte o modelo com o Docker usando os arquivos locais e o Jupyter Notebook.
import requests import json import os url = "http://0.0.0.0:8000/v1/chat/completions" headers = { "accept": "application/json", "Content-Type": "application/json", } # Assuming `MODEL` is an environment variable set appropriately model = f"/mnt/model/" # Adjust this based on your specific model path or name data = { "model": model, "messages": [{"role": "user", "content": "Write a humorous limerick about the wonders of GPU computing."}], "max_tokens": 64, "temperature": 0.7, "top_p": 0.9 } response = requests.post(url, headers=headers, json=data) if response.status_code == 200: result = response.json() # Extract the generated text from the response completion_text = result["choices"][0]["message"]["content"].strip() print("Generated Text:", completion_text) else: print("Request failed with status code:", response.status_code) print("Response:", response.text) -
Consulte o modelo com o Docker de origem externa usando o Jupyter Notebook e o Gradio Chatbot.
import requests import gradio as gr import os # Function to interact with the model via API def interact_with_model(prompt): url = 'http://0.0.0.0:8000/v1/chat/completions' # Update the URL to match the correct endpoint headers = { "accept": "application/json", "Content-Type": "application/json", } # Assuming `MODEL` is an environment variable set appropriately model = "/mnt/model/" # Adjust this based on your specific model path or name data = { "model": model, "messages": [{"role": "user", "content": prompt}], "max_tokens": 64, "temperature": 0.7, "top_p": 0.9 } response = requests.post(url, headers=headers, json=data) if response.status_code == 200: result = response.json() completion_text = result["choices"][0]["message"]["content"].strip() return completion_text else: return {"error": f"Request failed with status code {response.status_code}"} # Example Gradio interface iface = gr.Interface( fn=interact_with_model, inputs=gr.Textbox(lines=2, placeholder="Write a humorous limerick about the wonders of GPU computing."), outputs=gr.Textbox(type="text", placeholder="Response..."), title="Model Interface", # Set your desired title here description="Interact with the model deployed locally via Gradio.", live=True ) # Launch the Gradio interface iface.launch(share=True)Observação: Comandos do firewall para abrir a porta
8888do Jupyter Notebook.sudo firewall-cmd --zone=public --permanent --add-port 8888/tcp sudo firewall-cmd --reload sudo firewall-cmd --list-all
Agradecimentos
-
Autor - Bogdan Bazarca (Engenheiro Sênior de Nuvem)
-
Colaboradores - Equipe do Oracle NACI-AI-CN-DEV
Mais Recursos de Aprendizagem
Explore outros laboratórios em docs.oracle.com/learn ou acesse mais conteúdo de aprendizado gratuito no canal Oracle Learning YouTube. Além disso, visite education.oracle.com/learning-explorer para se tornar um Oracle Learning Explorer.
Para obter a documentação do produto, visite o Oracle Help Center.
Run Mistral LLM Model on OCI Compute A10 Instance with Oracle Resource Manager using One Click Deployment
G11818-01
July 2024