Observação:
- Este tutorial requer acesso ao Oracle Cloud. Para se inscrever e obter uma conta gratuita, consulte Conceitos Básicos do Oracle Cloud Infrastructure Free Tier.
- Ele usa valores de exemplo para credenciais, tenancy e compartimentos do Oracle Cloud Infrastructure. Ao concluir seu laboratório, substitua esses valores por valores específicos do seu ambiente de nuvem.
Use o OCI Data Flow com o Apache Spark Streaming para processar um tópico Kafka em um aplicativo escalável e quase em tempo real
Introdução
O Oracle Cloud Infrastructure (OCI) Data Flow é um serviço gerenciado para o projeto de código-fonte aberto chamado Apache Spark. Basicamente, com o Spark, você pode usá-lo para processamento em massa de arquivos, streaming e operações de banco de dados. Você pode criar aplicativos com processamento escalável muito alto. O Spark pode escalar e usar máquinas clusterizadas para paralelizar jobs com configuração mínima.
Usando o Spark como serviço gerenciado (Data Flow), você pode adicionar muitos serviços escaláveis para multiplicar o poder do processamento em nuvem. O serviço Data Flow tem a capacidade de processar o Spark Streaming.
Os aplicativos de streaming exigem execução contínua por um longo período de tempo, que muitas vezes se estende além de 24 horas, e podem demorar semanas ou até meses. Em caso de falhas inesperadas, os aplicativos de streaming devem ser reiniciados do ponto de falha sem produzir resultados computacionais incorretos. O serviço Data Flow conta com o check-point de streaming estruturado do Spark para registrar o deslocamento processado que pode ser armazenado em seu bucket do Object Storage.
Observação: Se você precisar processar dados como uma estratégia de batch, poderá ler este artigo: Processar arquivos grandes no Autonomous Database e no Kafka com o Oracle Cloud Infrastructure Data Flow
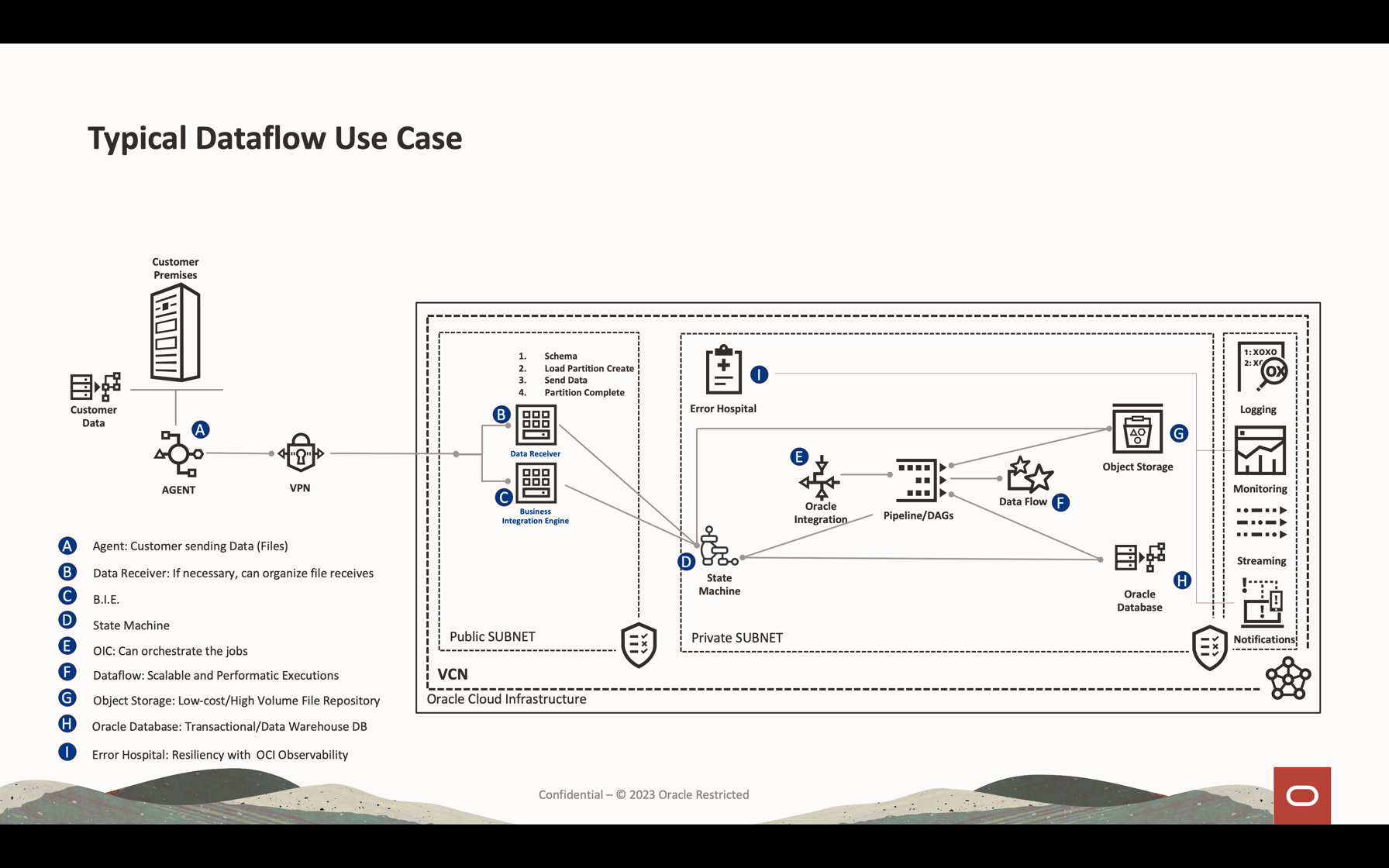
Neste tutorial, você pode ver as atividades mais comuns usadas para processar o streaming de volume de dados, consultar banco de dados e mesclar/participar dos dados para formar outra tabela na memória ou enviar dados para qualquer destino quase em tempo real. Você pode gravar esses dados em massa no seu banco de dados e em uma fila do Kafka com desempenho muito baixo custo e altamente eficaz.
Objetivos
- Saiba como o serviço Data Flow pode ser usado para processar uma grande quantidade de dados em um aplicativo escalável e quase em tempo real.
Pré-requisitos
-
Um tenant operacional do Oracle Cloud: Você pode criar uma conta gratuita do Oracle Cloud com US$ 300,00 por um mês para experimentar este tutorial. Consulte Criar uma Conta Grátis do Oracle Cloud
-
CLI do OCI (Interface de Linha de Comando do Oracle Cloud) instalado em sua máquina local: Este é o link para instalar a CLI do OCI.
-
Um aplicativo Apache Spark instalado em sua máquina local. Verifique Desenvolver Aplicativos Oracle Cloud Infrastructure Data Flow Localmente, Implantar na Nuvem para entender como desenvolver localmente e no serviço Data Flow.
Observação: Esta é a página oficial a ser instalada: Apache Spark. Existem procedimentos alternativos para instalar o Apache Spark para cada tipo de Sistema Operacional (Linux/Mac OS/Windows).
-
CLI de Submissão do Spark instalada. Este é o link para instalar a CLI de Submissão do Spark.
-
Maven instalado em sua máquina local.
-
Conhecimento dos Conceitos do OCI:
- Compartimentos
- Políticas de IAM
- Locação
- OCID dos seus recursos
Tarefa 1: Criar a estrutura do Object Storage
O Object Storage será usado como repositório de arquivos padrão. Você pode usar outro tipo de repositórios de arquivos, mas o Object Storage é uma maneira simples e de baixo custo de manipular arquivos com desempenho. Neste tutorial, ambos os aplicativos carregarão um arquivo CSV grande do armazenamento de objetos, mostrando como o Apache Spark é rápido e inteligente para processar um alto volume de dados.
-
Crie um compartimento: Os compartimentos são importantes para organizar e isolar seus recursos de nuvem. Você pode isolar seus recursos por Políticas do Serviço IAM.
-
Você pode usar este link para entender e configurar as políticas de compartimentos: Gerenciando Compartimentos
-
Crie um compartimento para hospedar todos os recursos dos 2 aplicativos neste tutorial. Crie um compartimento chamado analytics.
-
Vá para o menu principal do Oracle Cloud e procure: Identidade e Segurança, Compartimentos. Na seção Compartimentos, clique em Criar Compartimento e informe o nome.
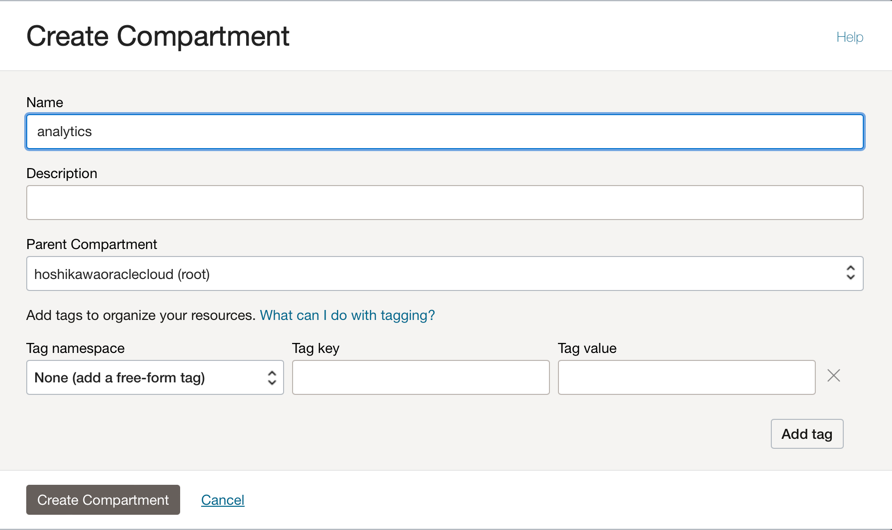
Observação: você precisa conceder acesso a um grupo de usuários e incluir seu usuário.
-
Clique em Criar Compartimento para incluir seu compartimento.
-
-
Crie seu bucket no Object Storage: Buckets são contêineres lógicos para armazenar objetos; portanto, todos os arquivos usados para essa demonstração serão armazenados nesse bucket.
-
Vá até o menu principal do Oracle Cloud e procure Armazenamento e Buckets. Na seção Buckets, selecione seu compartimento (análise), criado anteriormente.
-
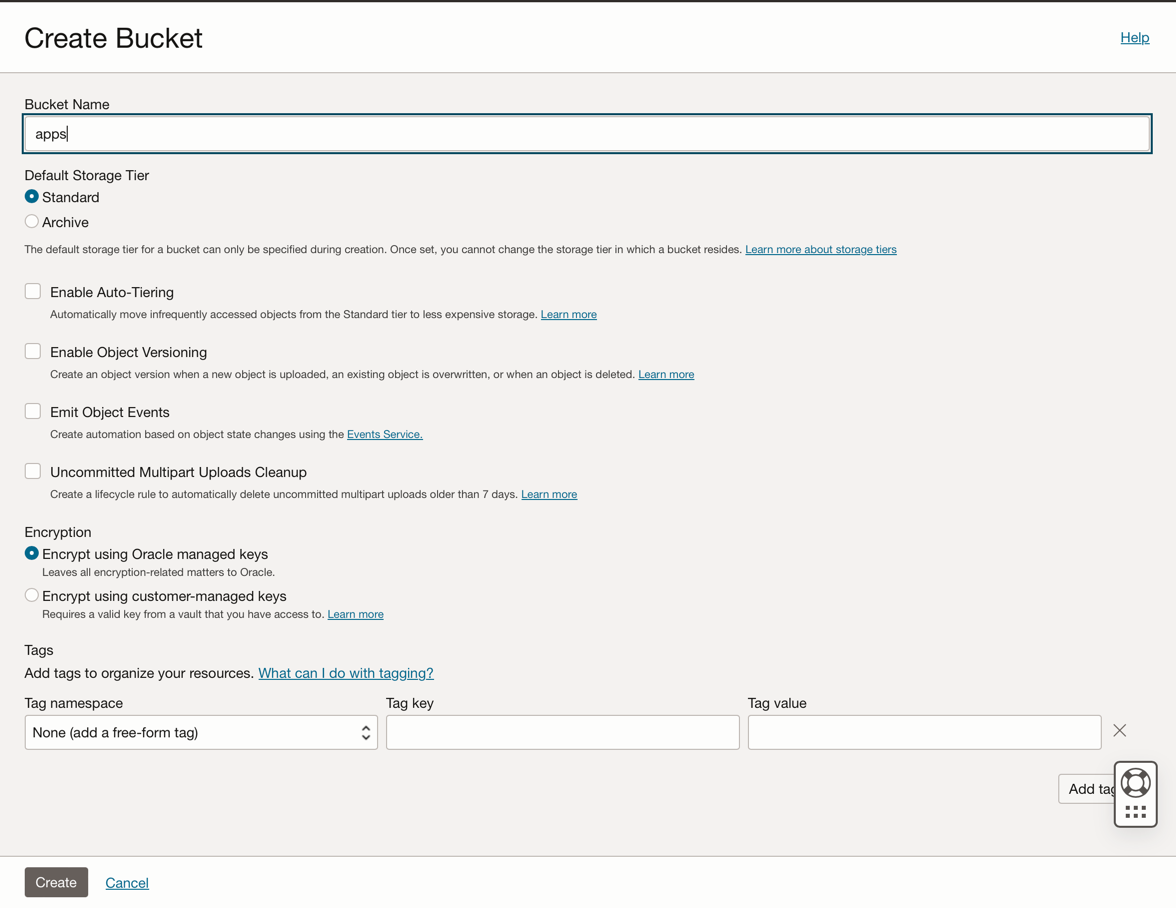
Clique em Criar Bucket. Crie 4 buckets: aplicativos, dados, dataflow-logs, Wallet
-
Informe as informações do Nome do Bucket com esses 4 buckets e mantenha os outros parâmetros com a seleção padrão.
-
Para cada bucket, clique em Criar. Você pode ver seus buckets criados.
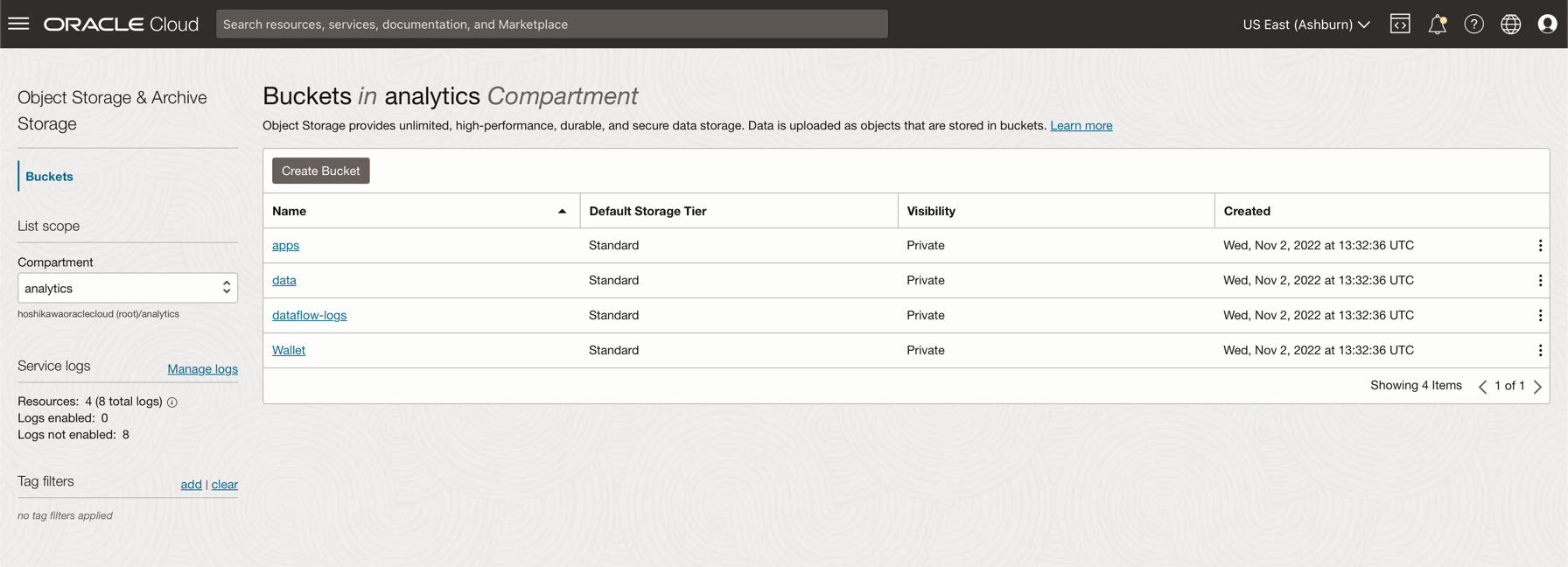
-
Observação: Verifique as Políticas do Serviço IAM para o bucket. Você deve configurar as políticas se quiser usar esses buckets em seus aplicativos de demonstração. Você pode revisar os conceitos e configurar aqui Visão Geral do Serviço Object Storage e Políticas do Serviço IAM.
Tarefa 2: Criar o Autonomous Database
O Oracle Cloud Autonomous Database é um serviço gerenciado para o Oracle Database. Para este tutorial, os aplicativos se conectarão ao banco de dados por meio de uma Wallet por motivos de segurança.
-
Instancie o Autonomous Database conforme descrito aqui: Provisionar o Autonomous Database.
-
No menu principal do Oracle Cloud, selecione a opção Data Warehouse, selecione Oracle Database e Autonomous Data Warehouse; selecione seu compartimento analytics e siga o tutorial para criar a instância do banco de dados.
-
Nomeie sua instância como Logs Processados, escolha logs como o nome do banco de dados e não é necessário alterar nenhum código nos aplicativos.
-
Informe a senha ADMIN e faça download do arquivo zip Wallet.
-
Depois de criar o banco de dados, você pode configurar a senha do usuário ADMIN e fazer download do arquivo zip Wallet.


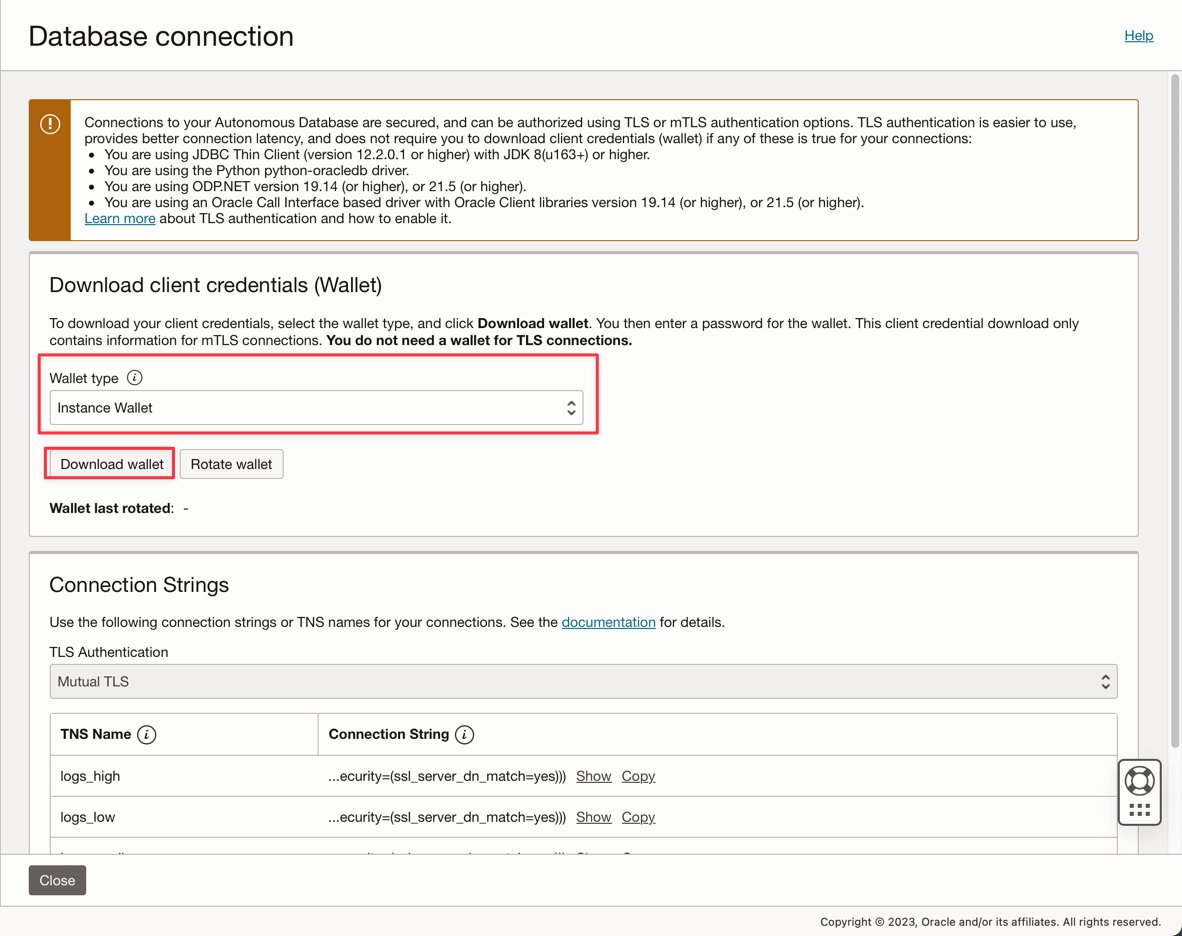
-
Salve seu arquivo zip Wallet (
Wallet_logs.zip) e anote sua senha ADMIN. Será necessário configurar o código do aplicativo. -
Vá para Armazenamento, Buckets. Altere para o compartimento do analytics e você verá o bucket do Wallet. Clique nele.
-
Para fazer upload do arquivo zip da Wallet, basta clicar em Fazer Upload e anexar o arquivo Wallet_logs.zip.
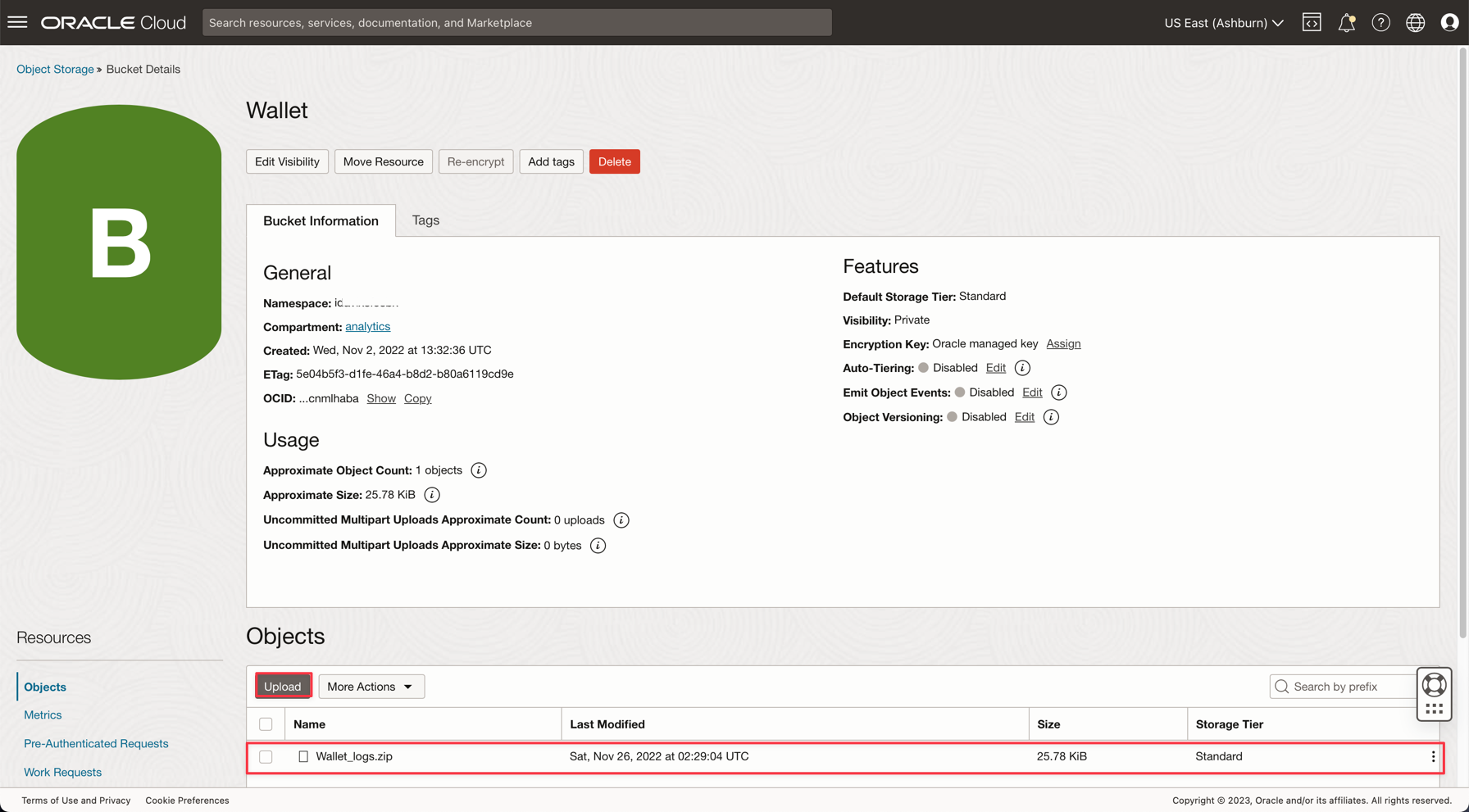
Observação: Verifique as Políticas do Serviço IAM para acessar o Autonomous Database aqui: Política do Serviço IAM para o Autonomous Database
Tarefa 3: Fazer Upload dos Arquivos de Amostra CSV
Para demonstrar o poder do Apache Spark, os aplicativos lerão um arquivo CSV com 1.000.000 linhas. Esses dados serão inseridos no banco de dados Autonomous Data Warehouse com apenas uma linha de comando e publicados em um streaming Kafka (Oracle Cloud Streaming). Todos esses recursos são escaláveis e perfeitos para alto volume de dados.
-
Faça download destes 2 links e faça Upload para o bucket de dados:
-
Observação:
- organizations.csv tem apenas 100 linhas para testar os aplicativos em sua máquina local.
- organizations1M.csv contém 1.000.000 linhas e será usado para execução na instância do serviço Data Flow.
-
No menu principal do Oracle Cloud, vá para Armazenamento e Buckets. Clique no bucket de dados e faça upload dos 2 arquivos da etapa anterior.
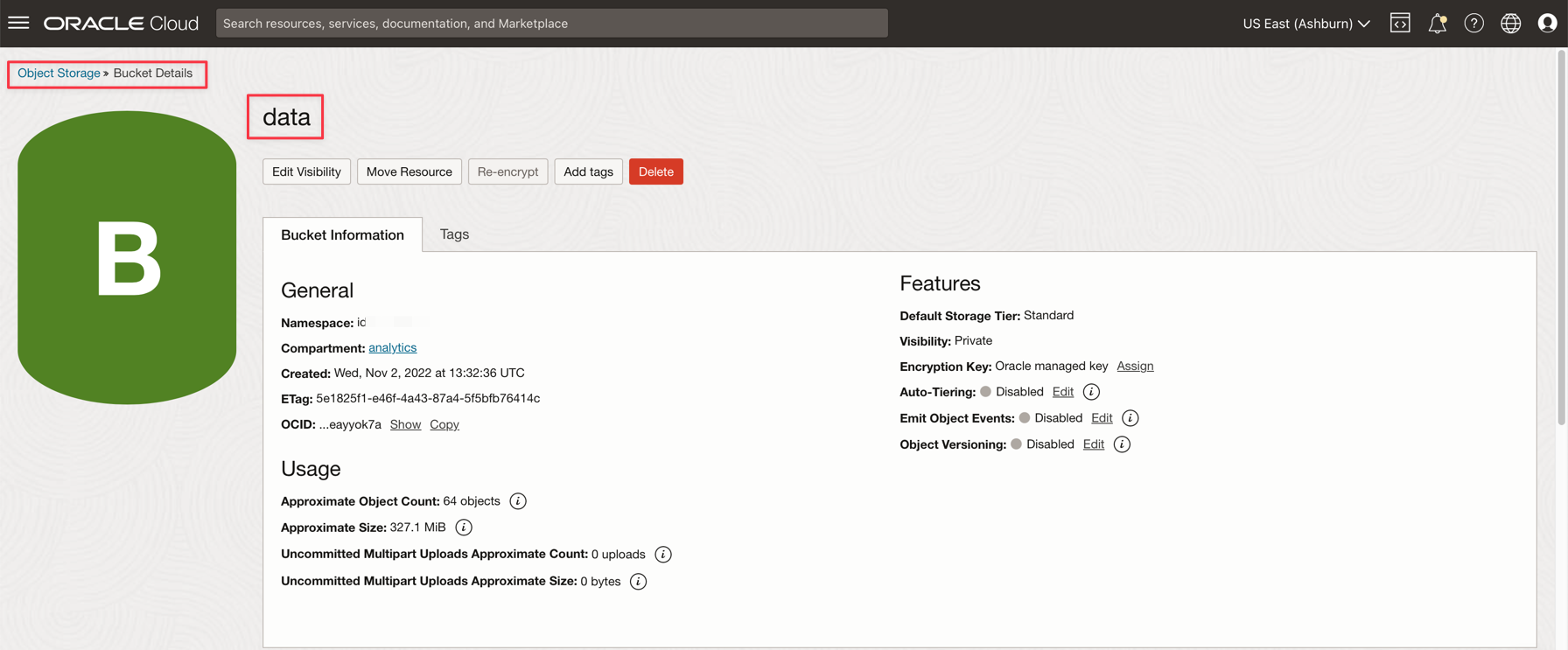

-
Fazer upload de uma tabela auxiliar para o Banco de Dados ADW
-
Faça download deste arquivo para fazer upload para o Banco de Dados ADW: GDP PER CAPTA COUNTRY.csv
-
No menu principal do Oracle Cloud, selecione Oracle Database e Autonomous Data Warehouse.
-
Clique na Instância Logs Processados para exibir os detalhes.
-
Clique em Ações do banco de dados para ir para os utilitários do banco de dados.
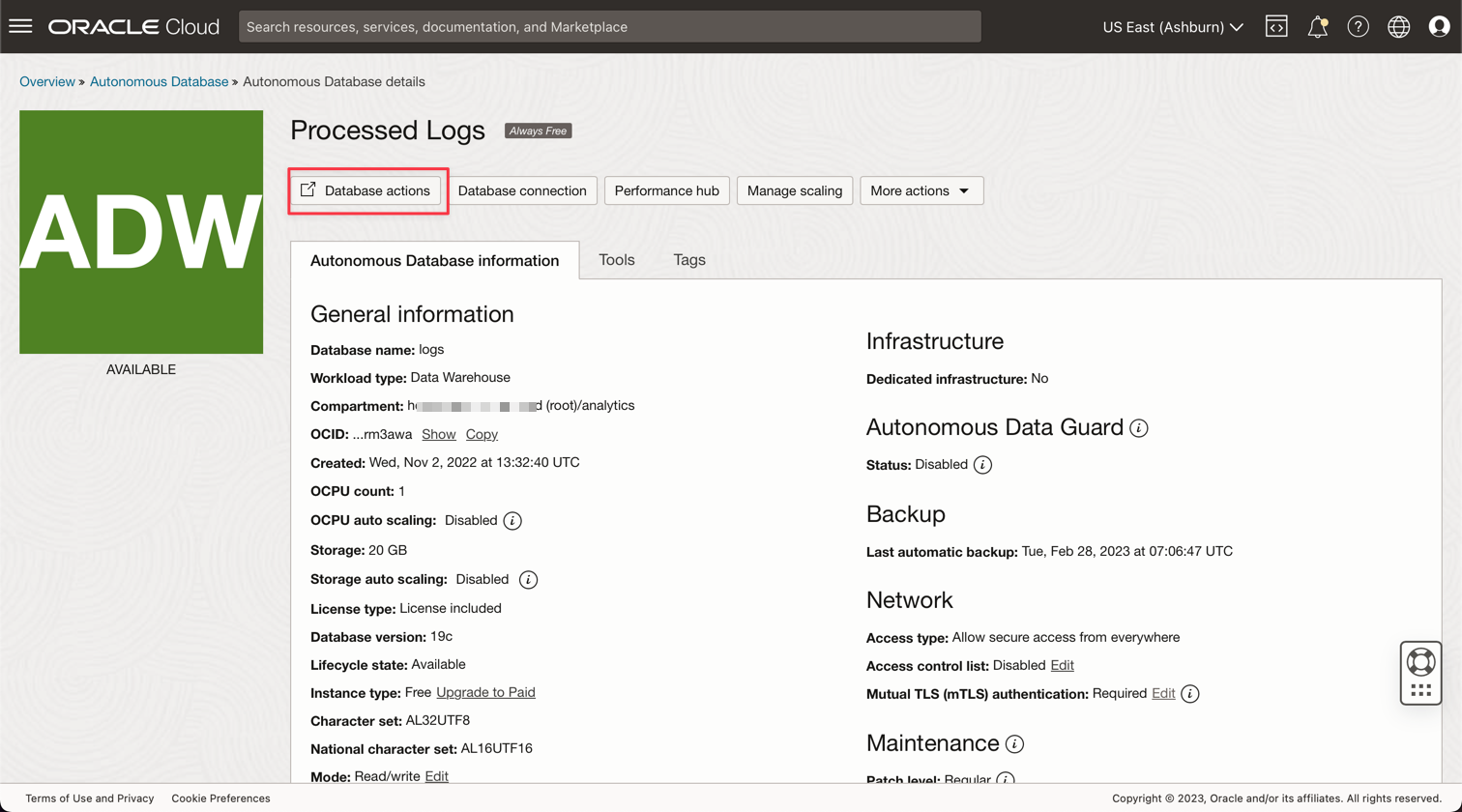
-
Informe suas credenciais para o usuário ADMIN.
-
Clique na opção SQL para ir para Utilitários de Consulta.
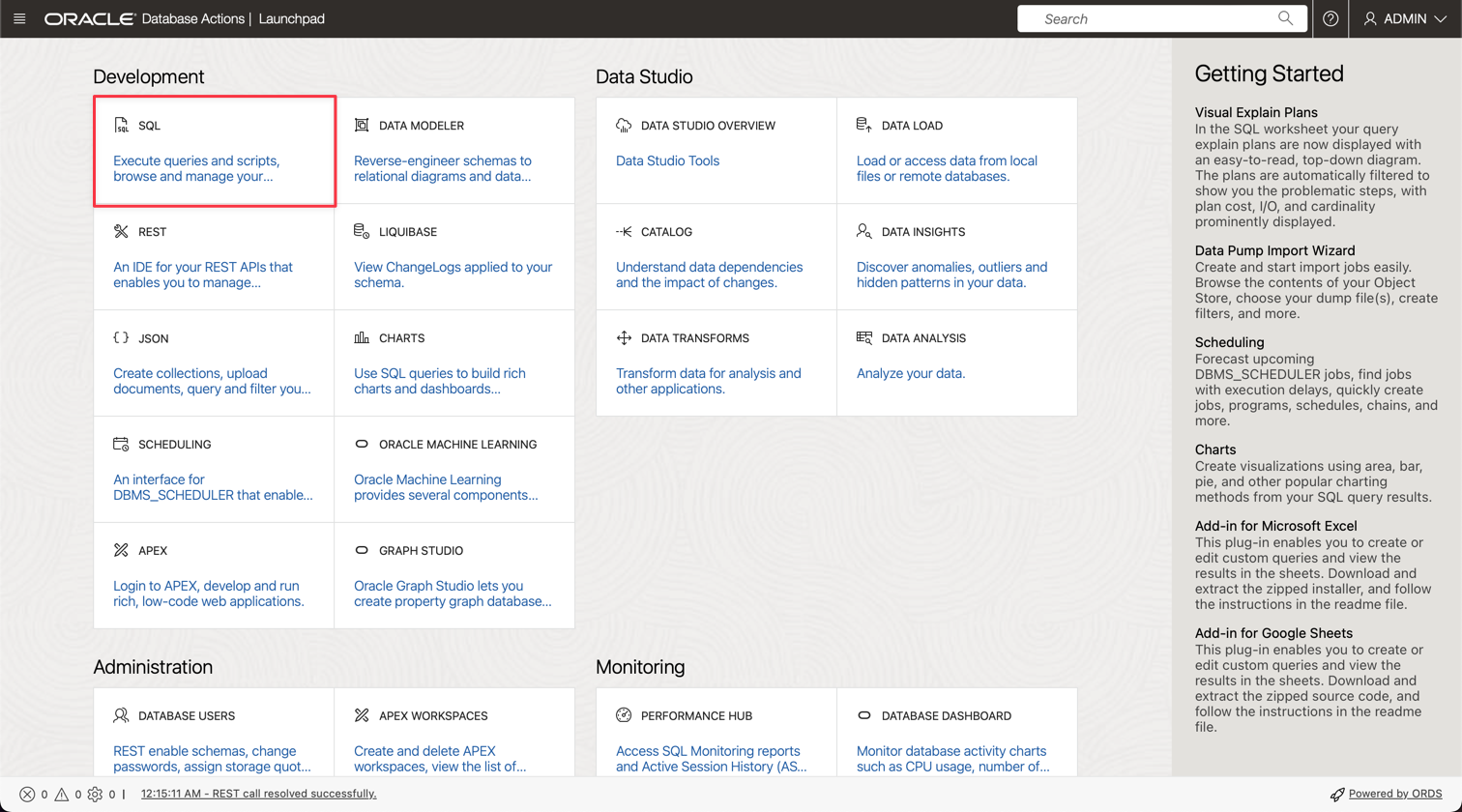
-
Clique em Carga de Dados.
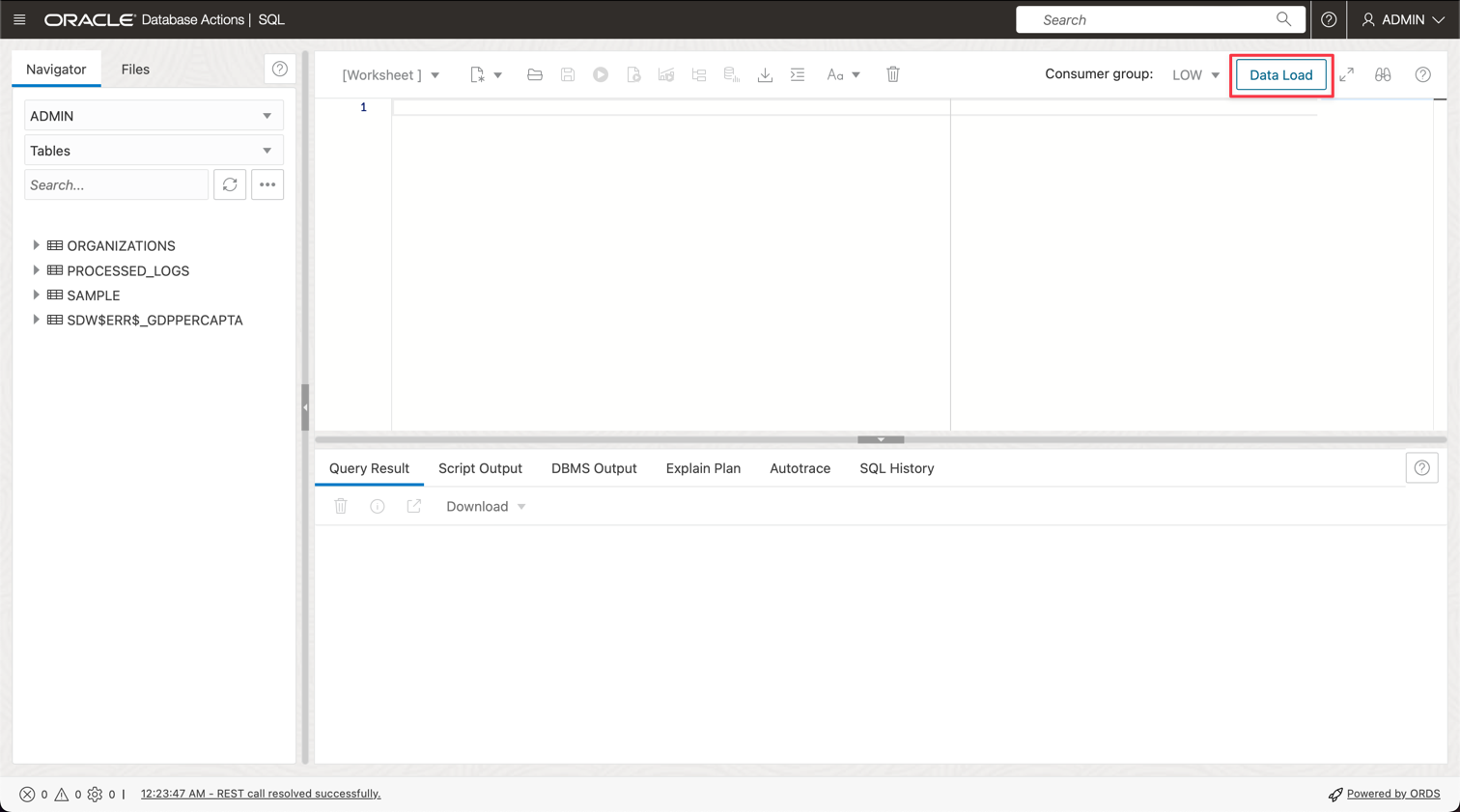
-
Solte o arquivo GDP PER CAPTA COUNTRY.csv no painel do console e continue a importar os dados para uma tabela.
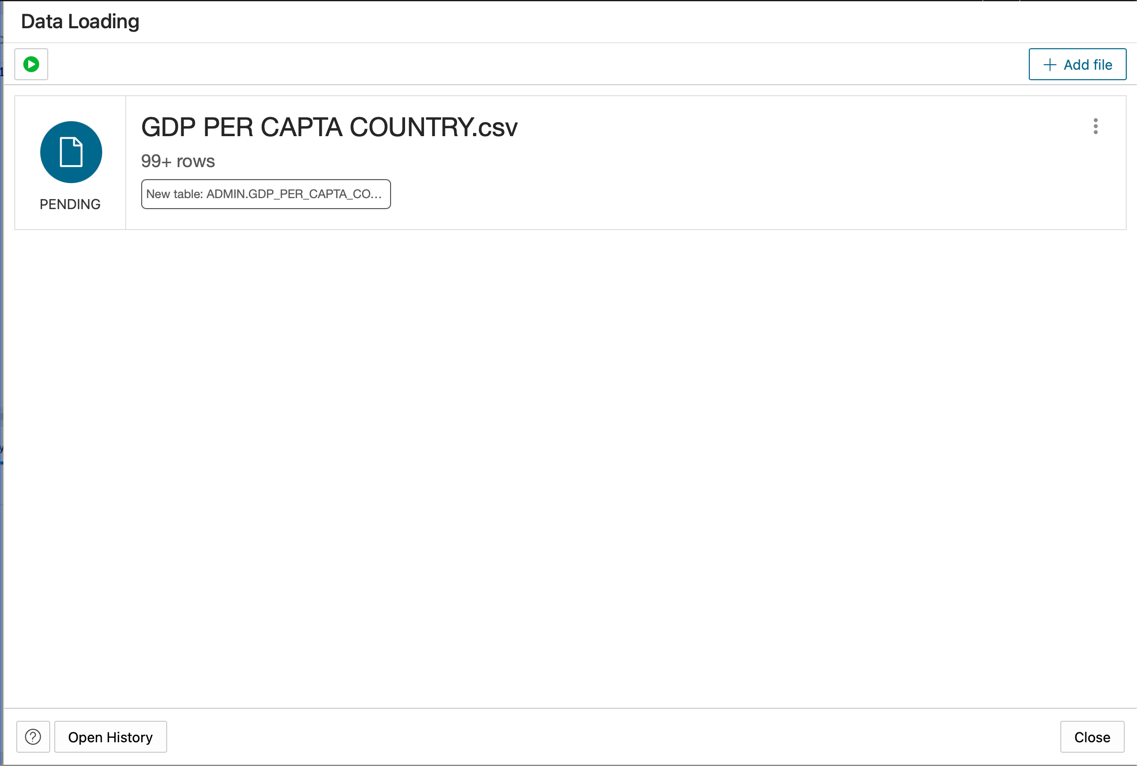
-
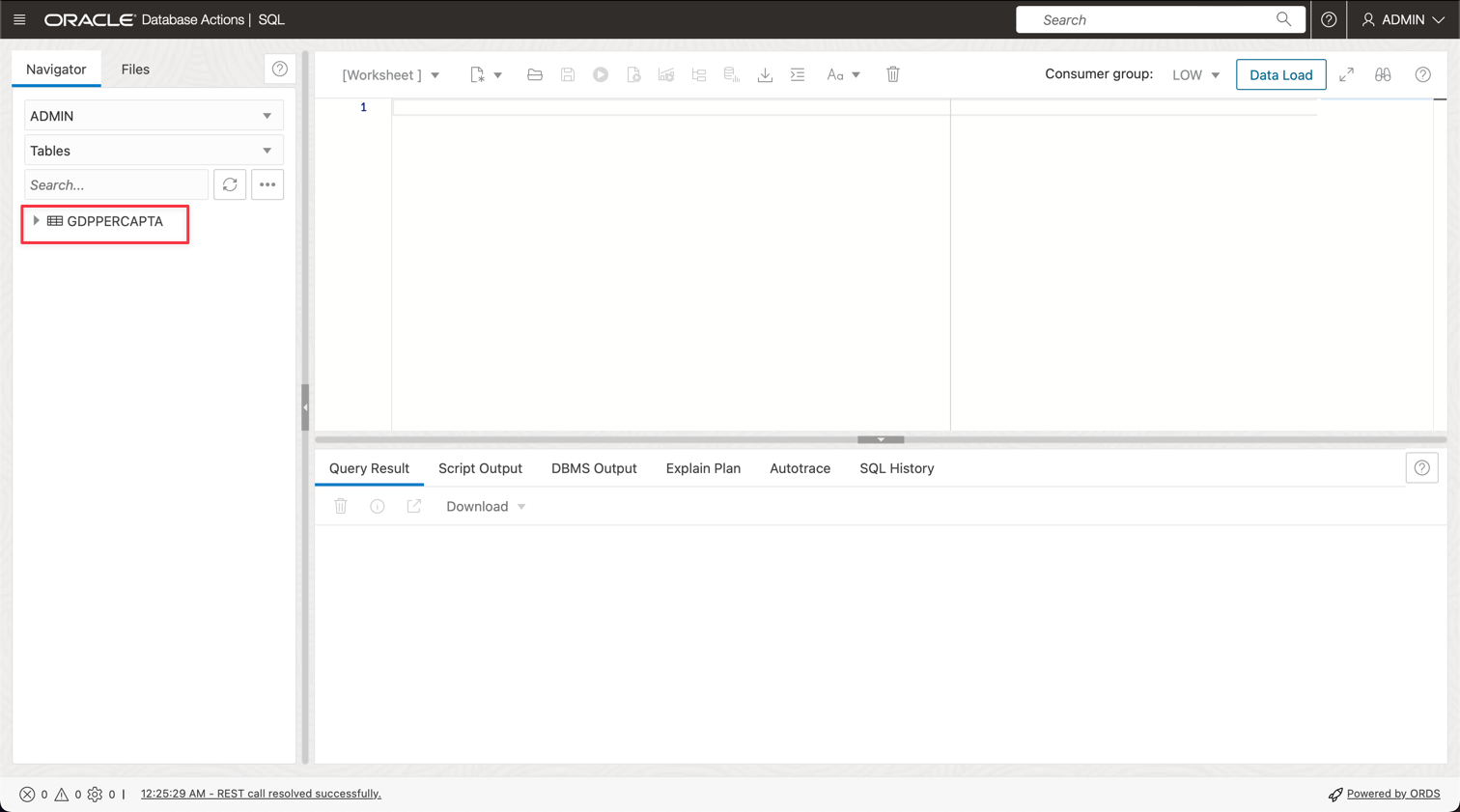
Você pode ver sua nova tabela chamada GDPPERCAPTA importada com sucesso.
Tarefa 4: Criar um Vault Secreto para sua senha ADMIN do ADW
Por motivos de segurança, a senha ADMIN do ADW será salva em um Vault. O Oracle Cloud Vault pode hospedar essa senha com segurança e pode ser acessado em seu aplicativo com Autenticação do OCI.
-
Crie seu segredo em um vault conforme descrito na seguinte documentação: Adicione a senha de administrador do banco de dados ao Vault
-
Crie uma variável denominada PASSWORD_SECRET_OCID em seus aplicativos e digite o OCID.
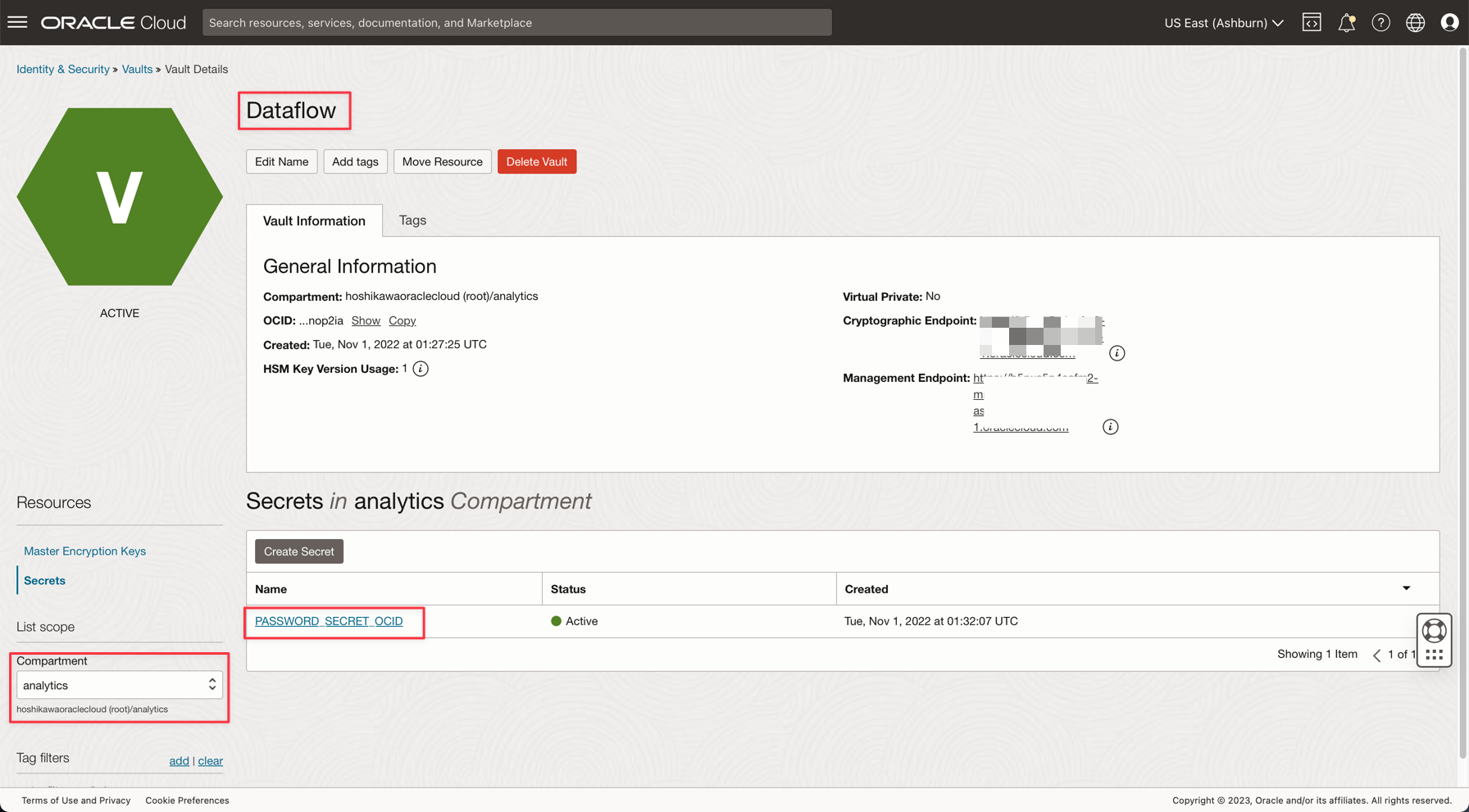
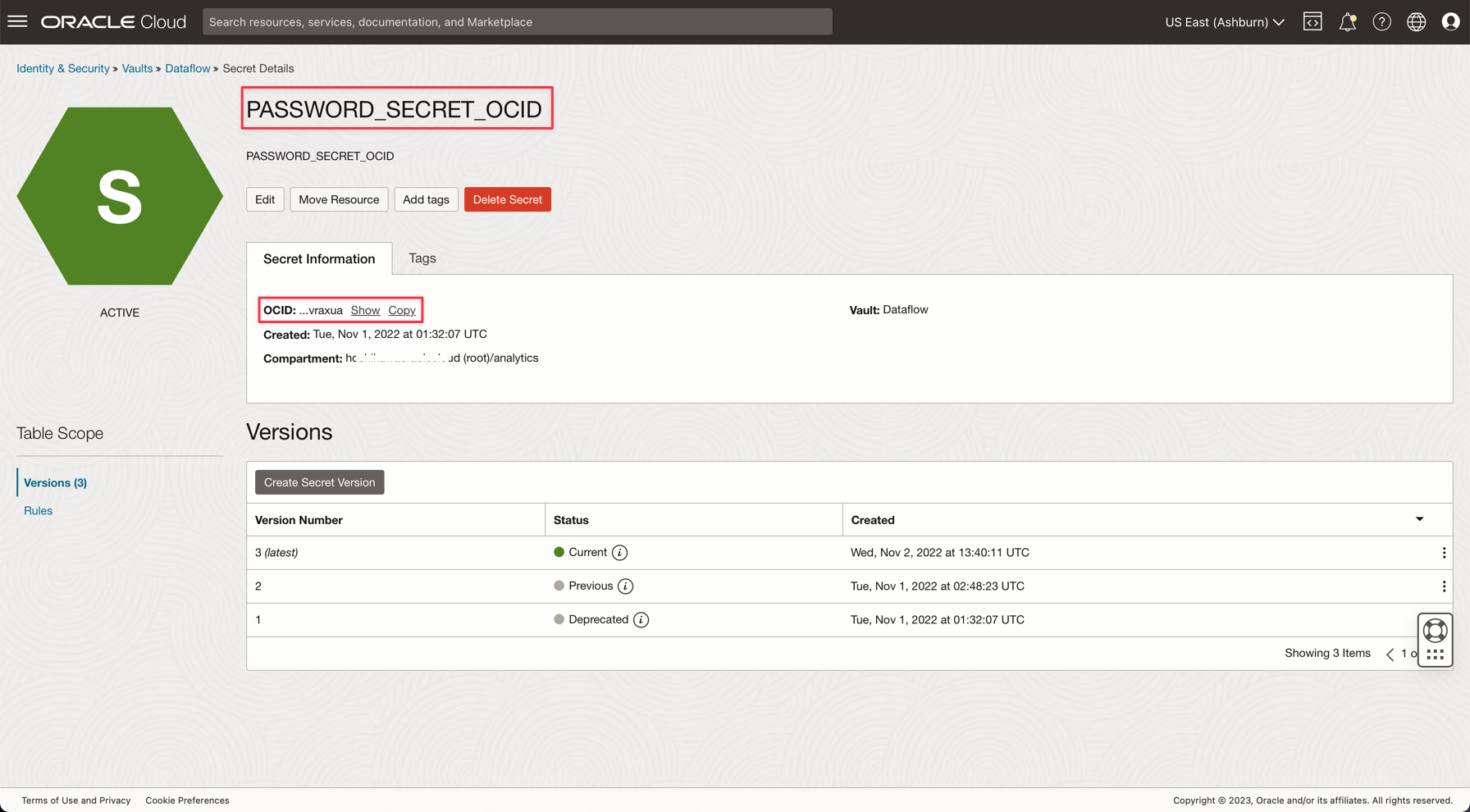
Observação: Verifique a Política do IAM para o OCI Vault aqui: Política do OCI Vault IAM.
Tarefa 5: Criar um Streaming Kafka (Oracle Cloud Streaming)
O Oracle Cloud Streaming é um serviço de streaming gerenciado como Kafka. Você pode desenvolver aplicativos usando as APIs Kafka e SDKs comuns. Neste tutorial, você criará uma instância do Streaming e a configurará para ser executada em ambos os aplicativos para publicar e consumir um alto volume de dados.
-
No menu principal do Oracle Cloud, vá para Análise e IA, Streams.
-
Altere o compartimento para o serviço analytics. Cada recurso nesta demonstração será criado neste compartimento. Isso é mais seguro e fácil de controlar o IAM.
-
Clique em Criar Stream.
-
Digite o nome como kafka_like (por exemplo) e você pode manter todos os outros parâmetros com os valores padrão.
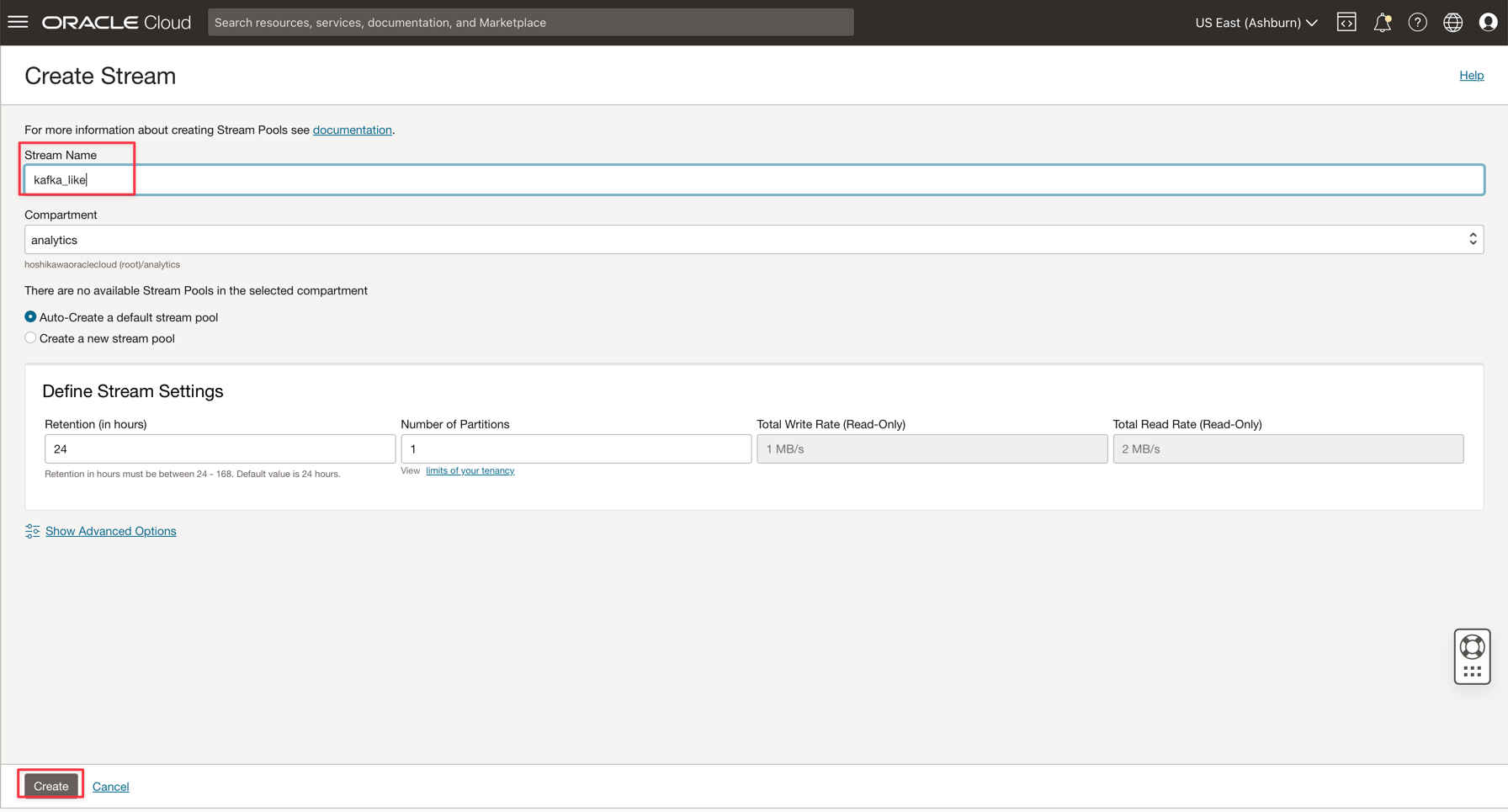
-
Clique em Criar para inicializar a instância.
-
Aguarde o status Ativo. Agora você pode usar a instância.
Observação: No processo de criação de streaming, você pode selecionar a opção Criar automaticamente um pool de fluxos padrão para criar automaticamente seu pool padrão.
-
Clique no link DefaultPool.

-
Exiba a definição de conexão.
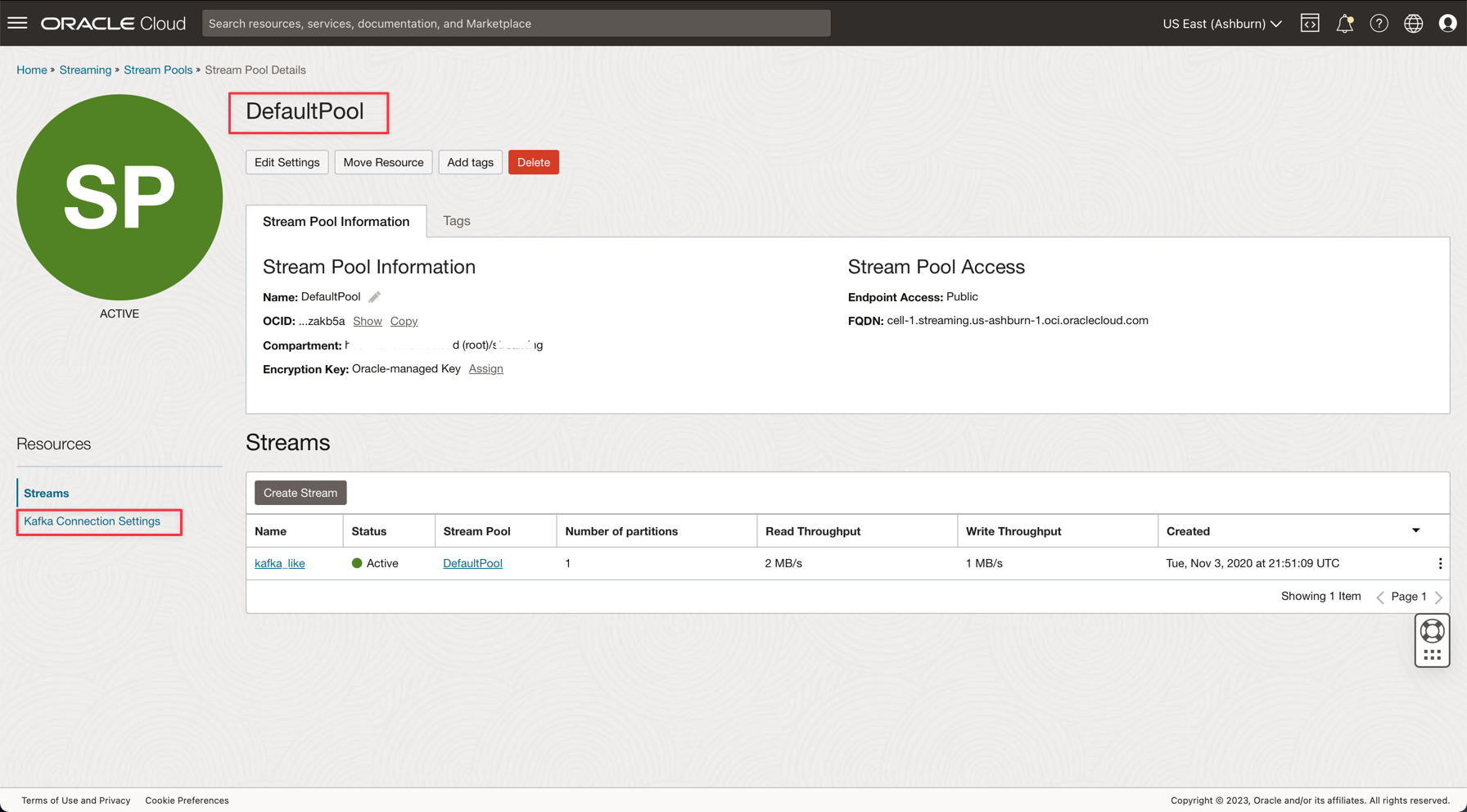
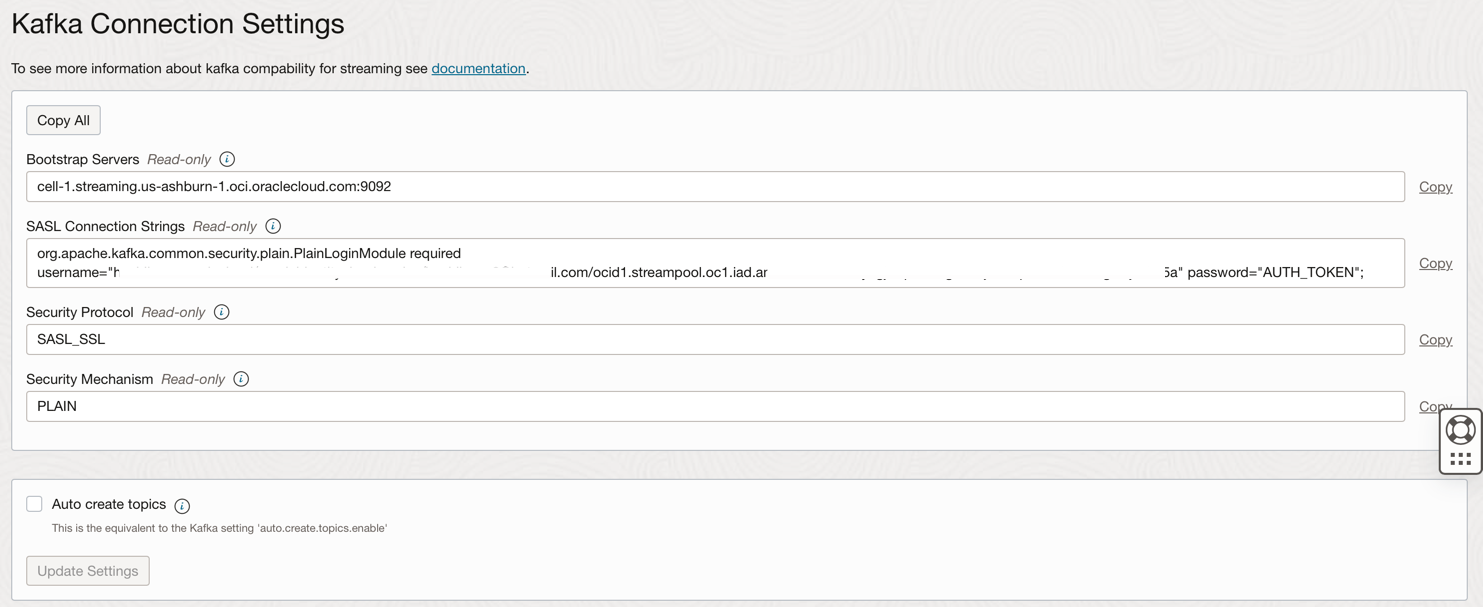
-
Anote essas informações conforme necessário na próxima etapa.
Observação: Verifique as Políticas do Serviço IAM para o OCI Streaming aqui: Política do Serviço IAM para OCI Streaming.
Tarefa 6: Gerar um AUTH TOKEN para acessar o Kafka
Você pode acessar o OCI Streaming (API Kafka) e outros recursos no Oracle Cloud com um Token de Autenticação associado ao seu usuário no OCI IAM. Em Definições de Conexão Kafka, as Strings de Conexão SASL têm um parâmetro chamado password e um valor AUTH_TOKEN, conforme descrito na tarefa anterior. Para permitir o acesso ao OCI Streaming, você precisa ir para seu usuário na Console do OCI e criar um AUTH TOKEN.
-
No menu principal do Oracle Cloud, vá para Identidade e Segurança, Usuários.
Observação: Lembre-se de que o usuário que você precisa criar AUTH TOKEN é o usuário configurado com a CLI do OCI e toda a configuração de Políticas do IAM para os recursos criados até agora. Os recursos são:
- Oracle Cloud Autonomous Data Warehouse
- Oracle Cloud Streaming
- Armazenamento de Objetos da Oracle
- Fluxo de Dados da Oracle
-
Clique no seu nome de usuário para ver os detalhes.
-
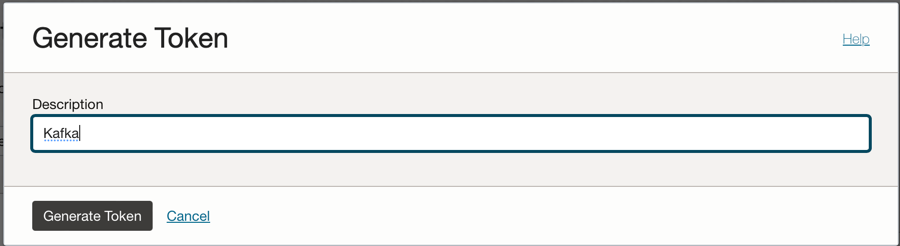
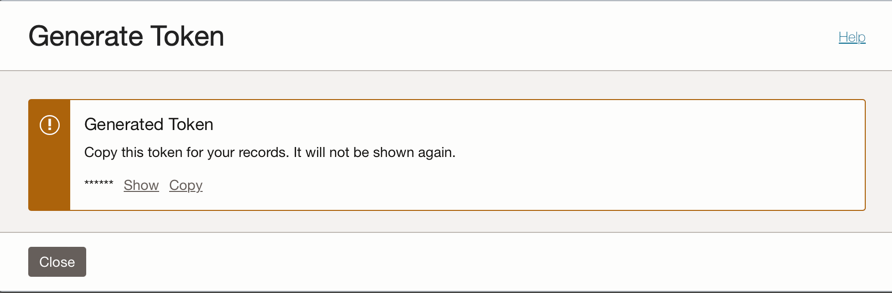
Clique na opção Tokens de Autenticação no lado esquerdo da console e clique em Gerar Token.
Observação: o token será gerado somente nesta etapa e não ficará visível depois que você concluir a etapa. Então, copie o valor e salve-o. Se você perder o valor do token, deverá gerar o token de autenticação novamente.
Tarefa 7: Configurar o aplicativo Demo
Este tutorial tem um aplicativo de demonstração para o qual vamos configurar as informações necessárias.
- DataflowSparkStreamDemo: Este aplicativo estabelecerá conexão com o Kafka Streaming e consumirá todos os dados e mesclará com uma tabela ADW chamada GDPPERCAPTA. Os dados do fluxo serão mesclados com GDPPERCAPTA e serão salvos como um arquivo CSV, mas podem ser expostos a outro tópico do Kafka.
-
Faça download do aplicativo usando o seguinte link:
-
Encontre os seguintes detalhes na Console do Oracle Cloud:
-
Namespace da Tenancy
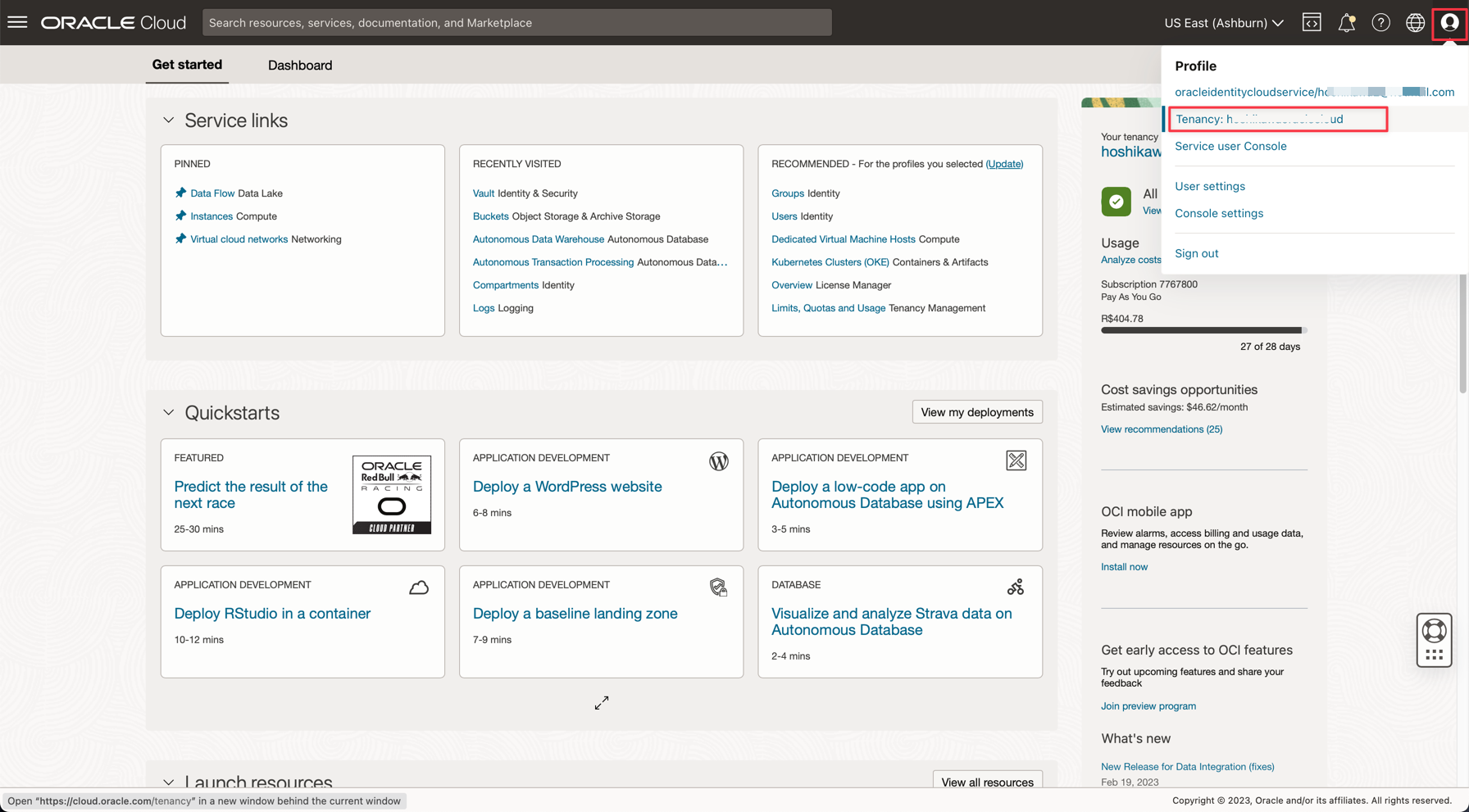
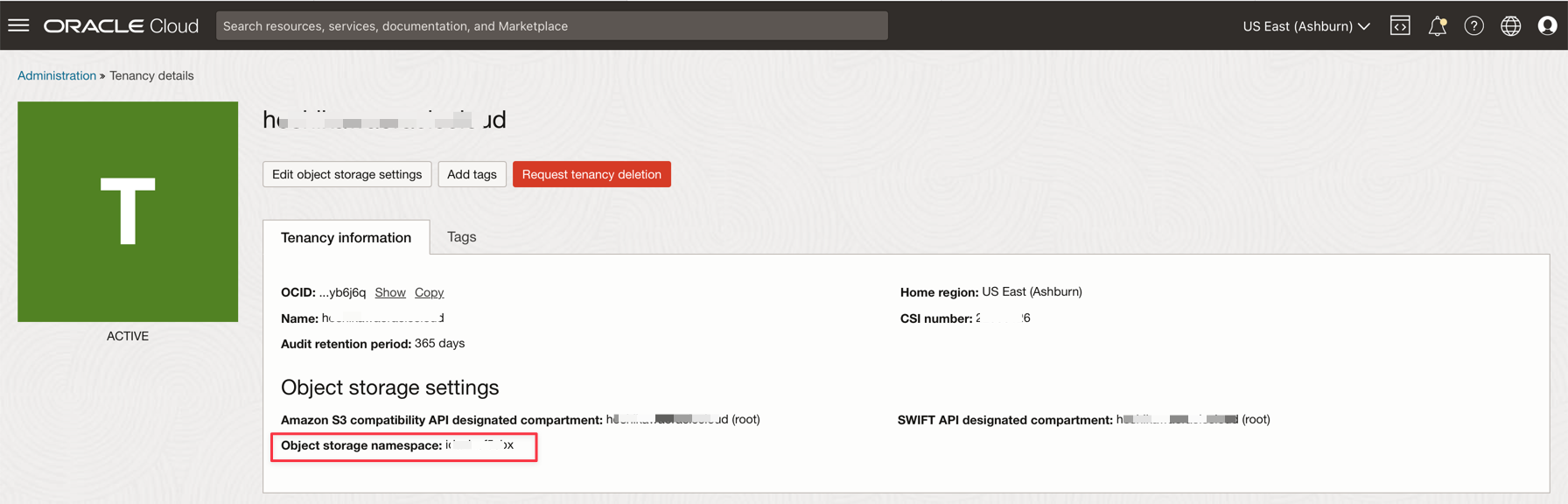
-
Segredo da Senha
-
Definições de Conexão do Streaming
-
Token de Autenticação
-
-
Abra o arquivo zip baixado (
Java-CSV-DB.zipeJavaConsumeKafka.zip). Vá para a pasta /src/main/java/example e localize o código Example.java.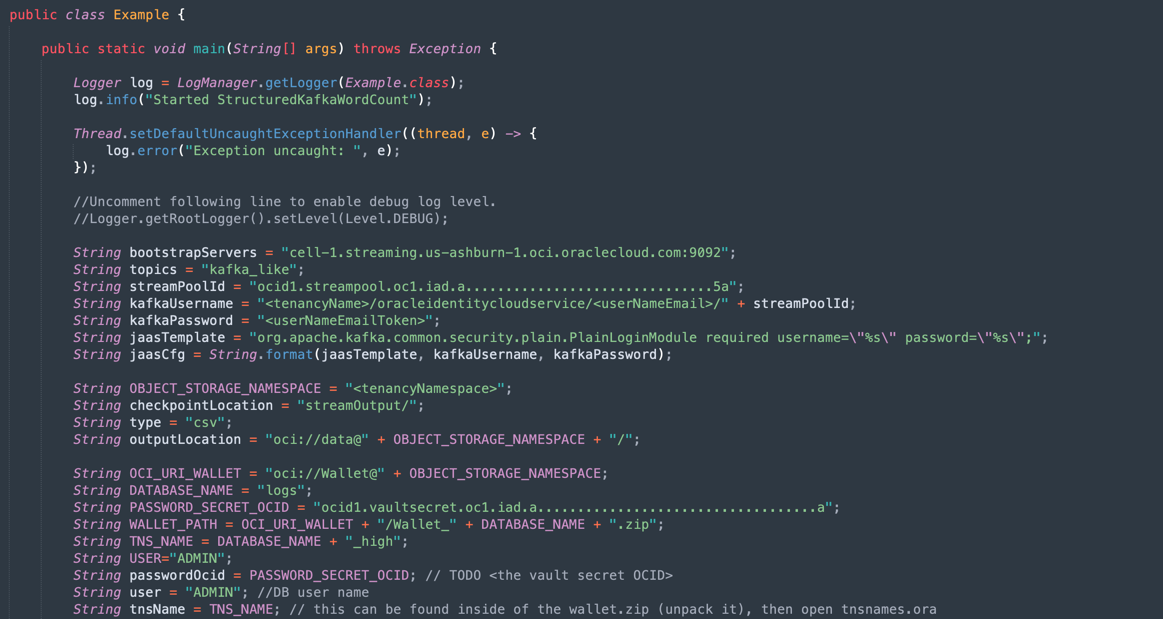
Essas são as variáveis que precisam ser alteradas com os valores de recursos da tenancy.
NOME DA VARIÁVEL NOME DO RECURSO TÍTULO DAS INFORMAÇÕES bootstrapServers Definições de Conexão do Streaming Servidores de Inicialização streamPoolId Definições de Conexão do Streaming Valor ocid1.streampool.oc1.iad..... na String de Conexão SASL kafkaUsername Definições de Conexão do Streaming valor de usename dentro " " na String de Conexão SASL kafkaPassword Token de Autenticação O valor é exibido somente na etapa de criação OBJECT_STORAGE_NAMESPACE NAMESPACE DA TENANCY LOCAÇÃO ESPAÇO DE NOMES NAMESPACE DA TENANCY LOCAÇÃO PASSWORD_SECRET_OCID PASSWORD_SECRET_OCID OCID
Observação: todos os recursos criados para essa demonstração estão na região US-ASHBURN-1. Verifique em qual região você deseja trabalhar. Se você alterar a região, precisará alterar 2 pontos em 2 arquivos de código:
Example.java: Altere a variável bootstrapServers, substituindo o "us-ashburn-1" pela sua nova região
OboTokenClientConfigurator.java: Altere a variável CANONICAL_REGION_NAME com sua nova região
Tarefa 8: Compreender o código Java
Este tutorial foi criado em Java e este código também pode ser transferido para Python. Para comprovar a eficiência e a escalabilidade, o aplicativo foi desenvolvido para mostrar algumas possibilidades em um caso de uso comum de um processo de integração. Portanto, o código do aplicativo mostra os seguintes exemplos:
- Conecte-se ao Fluxo do Kafka e leia os dados
- Processar JOINS com uma tabela ADW para criar informações úteis
- Saída de um arquivo CSV com todas as informações úteis provenientes do Kafka
Esta demonstração pode ser executada em sua máquina local e implantada na instância do serviço Data Flow para ser executada como uma execução de job.
Observação: Para o job do serviço Data Flow e sua máquina local, use a configuração da CLI do OCI para acessar os recursos do OCI. No lado do Fluxo de Dados, tudo é pré-configurado; portanto, não é necessário alterar os parâmetros. No lado da sua máquina local, você deve ter instalado a CLI do OCI e configurado o tenant, o usuário e a chave privada para acessar seus recursos do OCI.
Vamos mostrar o código Example.java nas seções:
-
Inicialização do Apache Spark: Esta parte do código representa a inicialização do Spark. Muitos parâmetros para executar processos de execução são configurados automaticamente, portanto é muito fácil trabalhar com o mecanismo Spark. A inicialização será diferente se você estiver executando dentro do serviço Data Flow ou em sua máquina local. Se você estiver no serviço Data Flow, não precisará carregar o arquivo zip da Wallet ADW, a tarefa de carregar, descompactar e ler os arquivos da Wallet será automática dentro do ambiente do serviço Data Flow, mas na máquina local, ela precisará ser feita com alguns comandos.
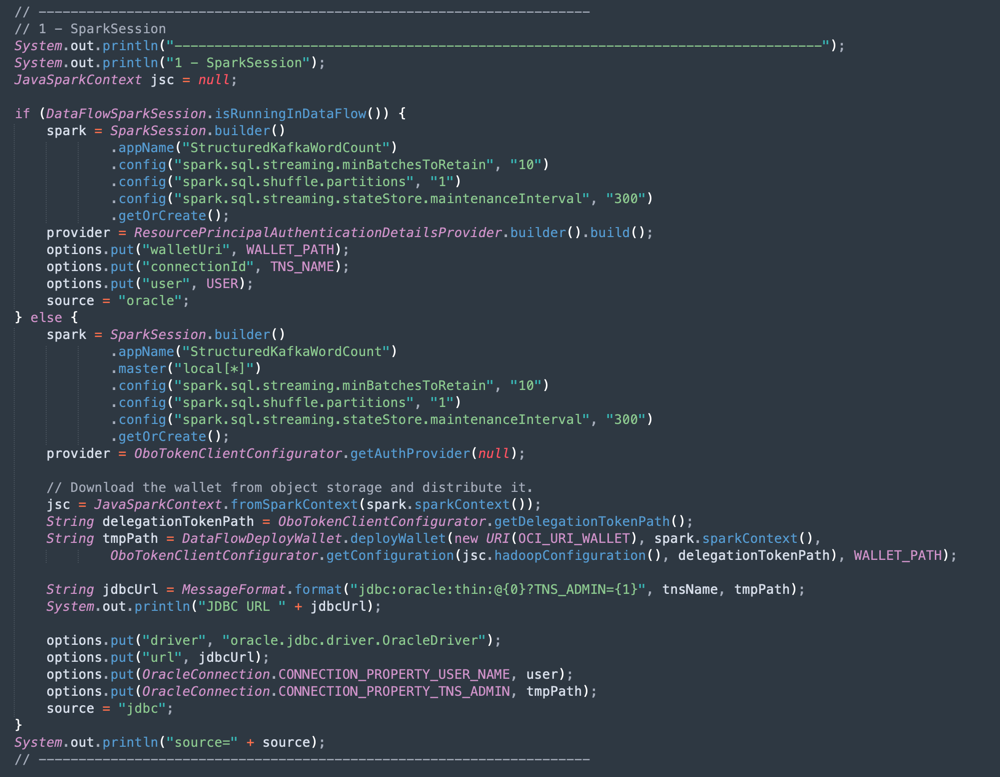
-
Leia o Segredo do Vault do ADW: Esta parte do código acessa seu vault para obter o segredo da sua instância do Autonomous Data Warehouse.
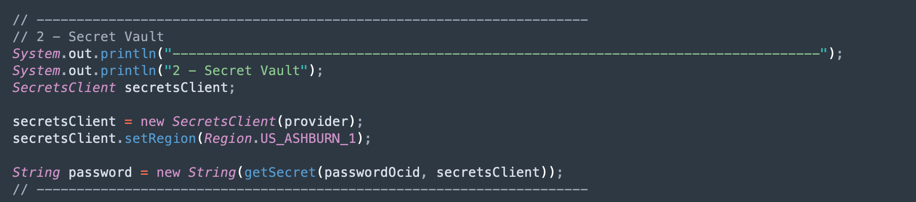
-
Consultar uma Tabela ADW: Esta seção mostra como executar uma consulta em uma tabela.

-
Operações Kafka: Esta é a preparação para estabelecer conexão com o OCI Streaming usando a API Kafka.
Observação: O Oracle Cloud Streaming é compatível com a maioria das APIs Kafka.
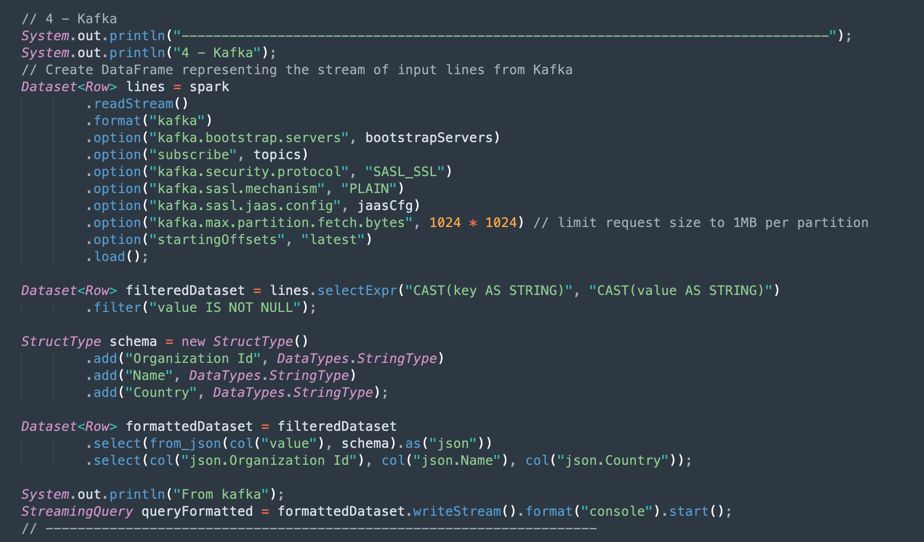
Há um processo para fazer parsing dos dados JSON provenientes do tópico Kafka em um conjunto de dados com a estrutura correta (Id da Organização, Nome, País).
-
Mesclar os dados de um Conjunto de Dados Kafka e de um Conjunto de Dados Autonomous Data Warehouse: Esta seção mostra como executar uma consulta com 2 conjuntos de dados.

-
Saída em um arquivo CSV: Veja como os dados mesclados geram a saída em um arquivo CSV.

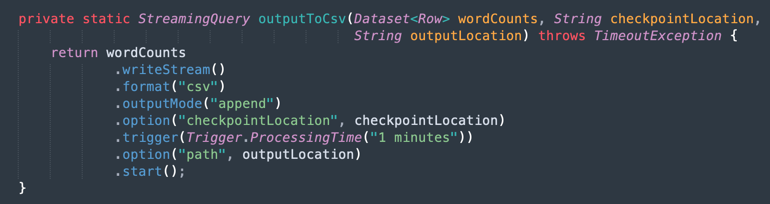
Tarefa 9: Empacotar seu aplicativo com Maven
Antes de executar o job no Spark, é necessário empacotar seu aplicativo com o Maven.
-
Vá para a pasta /DataflowSparkStreamDemo e execute este comando:
mvn package -
Você pode ver o Maven iniciando o pacote.
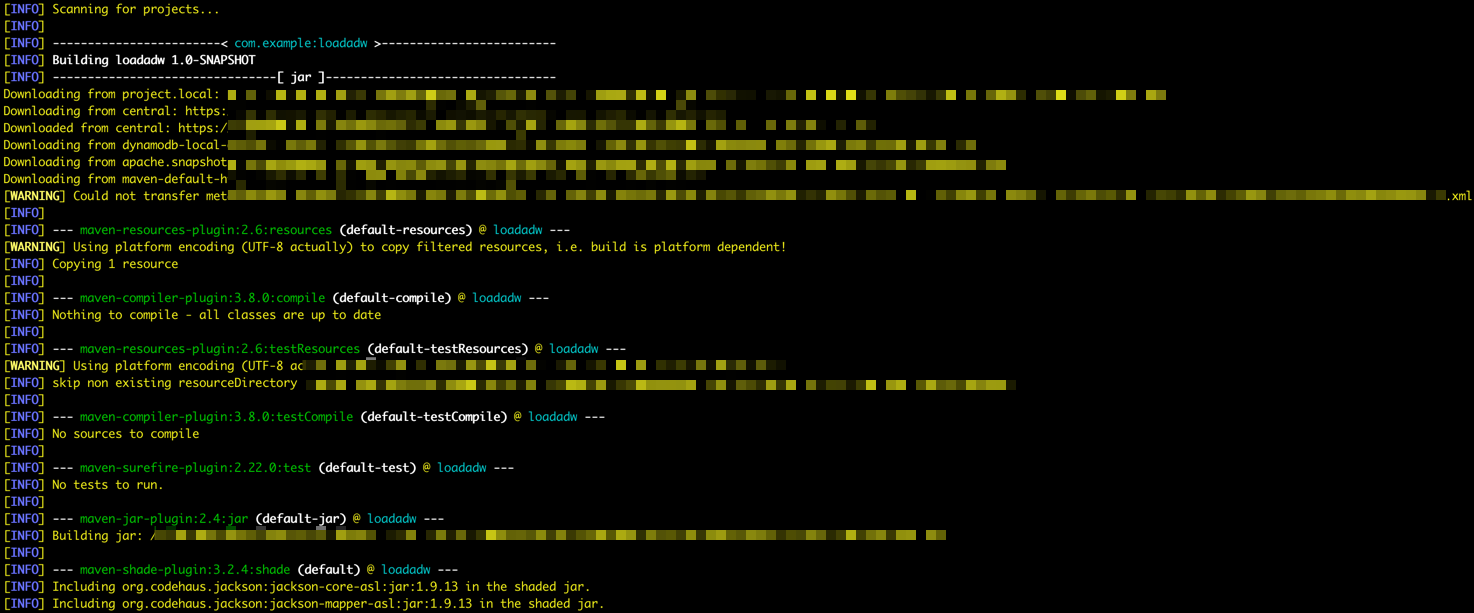
-
Se tudo estiver correto, você poderá ver a mensagem Sucesso.
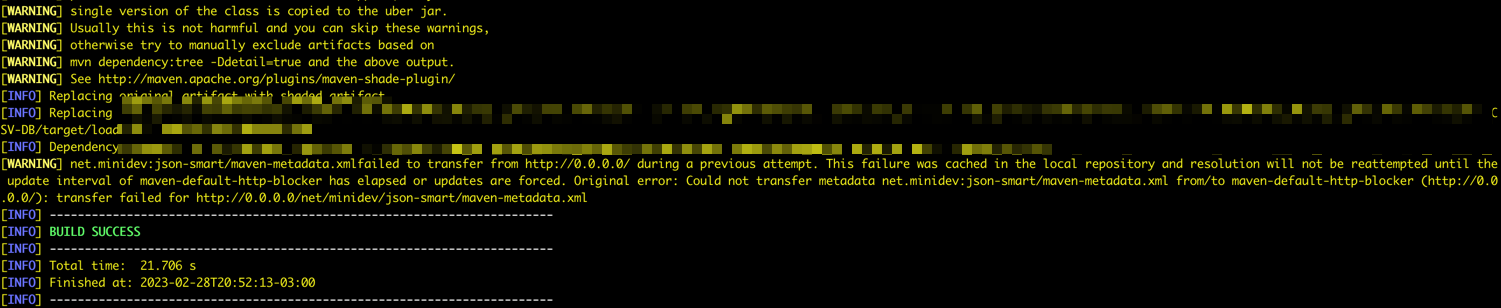
Tarefa 10: Verificar a execução
-
Teste seu aplicativo na sua máquina Spark local executando este comando:
spark-submit --class example.Example target/consumekafka-1.0-SNAPSHOT.jar -
Vá para sua instância do Kafka do Oracle Cloud Streaming e clique em Produzir Mensagem de Teste para gerar alguns dados e testar seu aplicativo em tempo real.
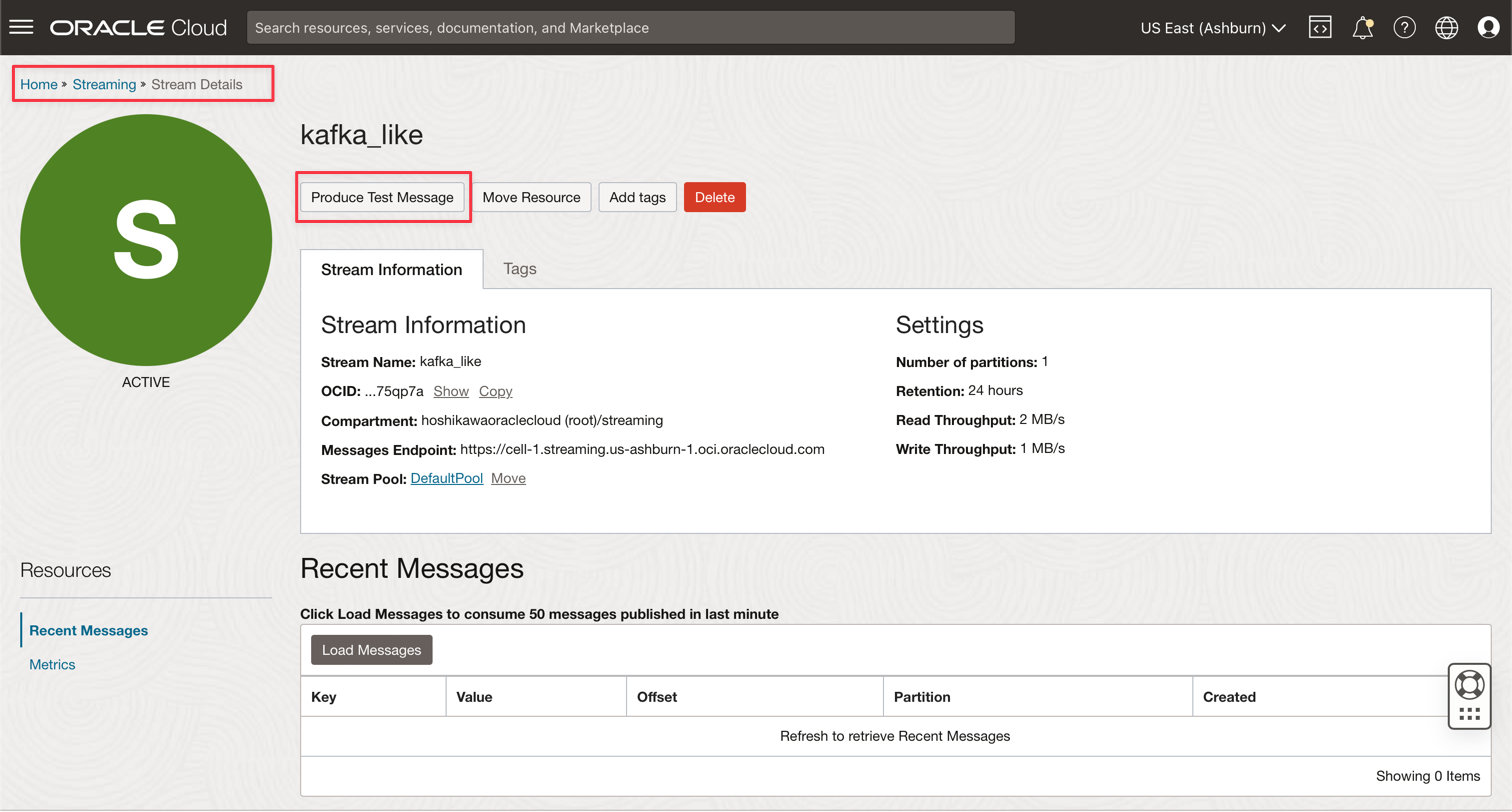
-
Você pode colocar essa mensagem JSON no tópico do Kafka.
{"Organization Id": "1235", "Name": "Teste", "Country": "Luxembourg"}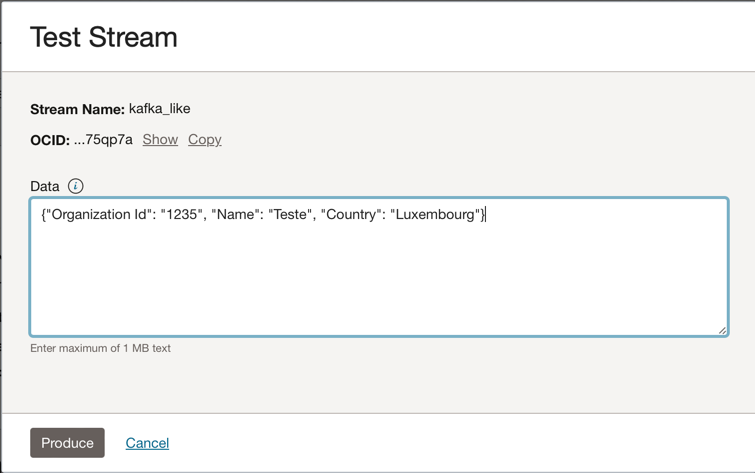
-
Toda vez que você clicar em Produzir, enviará uma mensagem ao aplicativo. Você pode ver o log de saída do aplicativo algo como este:
-
Estes são os dados lidos no tópico do kafka.

-
Estes são os dados mesclados da tabela ADW.

-
Tarefa 11: Criar e executar um job do serviço Data Flow
Agora, com os dois aplicativos em execução com sucesso em sua máquina Spark local, você pode implantá-los no Oracle Cloud Data Flow em sua tenancy.
Observação: Consulte a documentação do Spark Streaming para configurar o acesso a recursos como Oracle Object Storage e Oracle Streaming (Kafka): Ativar Acesso ao Serviço Data Flow
-
Fazer upload dos pacotes no Object Storage.
- Antes de criar um aplicativo do serviço Data Flow, você precisa fazer upload do seu aplicativo de artefato Java (seu arquivo ***-SNAPSHOT.jar) para o bucket do serviço Object Storage chamado apps.
-
Crie um aplicativo do serviço Data Flow.
-
Selecione o menu principal do Oracle Cloud e vá para Análise e IA e Data Flow. Certifique-se de selecionar seu compartimento do serviço analytics antes de criar um Aplicativo do serviço Data Flow.
-
Clique em Criar aplicativo.
-
Preencha os parâmetros como este.
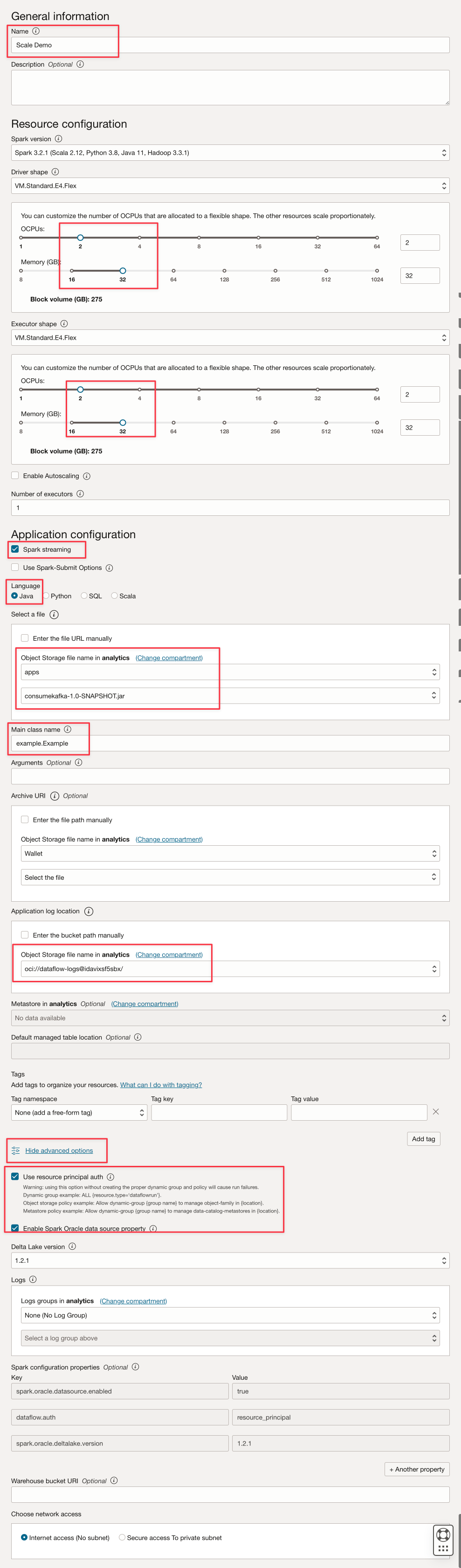
-
Clique em Criar.
-
Após a criação, clique no link Dimensionar Demonstração para exibir detalhes. Para executar um job, clique em RUN.
Observação: Clique em Mostrar opções avançadas para ativar a segurança do OCI para o tipo de execução Spark Stream.

-
-
Ative as seguintes opções.

-
Clique em Executar para executar o job.
-
Confirme os parâmetros e clique em Executar novamente.
-
É possível exibir o Status do job.

-
Aguarde até que o Status vá para Bem-sucedido e você poderá ver os resultados.

-
Links Relacionados
Aquisições
- Autor - Cristiano Hoshikawa (Engenheiro de Soluções de Equipe A do Oracle LAD)
Mais Recursos de Aprendizagem
Explore outros laboratórios no site docs.oracle.com/learn ou acesse mais conteúdo de aprendizado gratuito no canal YouTube do Oracle Learning. Além disso, visite education.oracle.com/learning-explorer para se tornar um Oracle Learning Explorer.
Para obter a documentação do produto, visite o Oracle Help Center.
Use OCI Data Flow with Apache Spark Streaming to process a Kafka topic in a scalable and near real-time application
F79979-02
May 2023
Copyright © 2023, Oracle and/or its affiliates.