Observação:
- Este tutorial requer acesso ao Oracle Cloud. Para se inscrever em uma conta gratuita, consulte Conceitos básicos do Oracle Cloud Infrastructure Free Tier.
- Ele usa valores de exemplo para credenciais, tenancy e compartimentos do Oracle Cloud Infrastructure. Ao concluir seu laboratório, substitua esses valores por valores específicos do seu ambiente de nuvem.
Analise documentos PDF em linguagem natural com a OCI Generative AI
Introdução
A Oracle Cloud Infrastructure Generative AI (OCI Generative AI) é uma solução avançada de inteligência artificial generativa que permite que empresas e desenvolvedores criem aplicações inteligentes usando modelos de linguagem de ponta. Com base em tecnologias poderosas, como os Grandes Modelos de Linguagem (LLMs), esta solução permite a automação de tarefas complexas, tornando os processos mais rápidos, mais eficientes e acessíveis por meio de interações de linguagem natural.
Uma das aplicações mais impactantes da OCI Generative AI é a análise de documentos em PDF. As empresas frequentemente lidam com grandes volumes de documentos, como contratos, relatórios financeiros, manuais técnicos e documentos de pesquisa. A busca manual de informações nesses arquivos pode ser demorada e propensa a erros.
Com o uso da inteligência artificial generativa, é possível extrair informações de forma instantânea e precisa, permitindo que os usuários consultem documentos complexos simplesmente formulando perguntas em linguagem natural. Isso significa que, em vez de ler páginas inteiras para encontrar uma cláusula específica em um contrato ou um ponto de dados relevante em um relatório, os usuários podem apenas perguntar ao modelo, que retorna rapidamente a resposta com base no conteúdo analisado.
Além da recuperação de informações, a OCI Generative AI também pode ser usada para resumir documentos longos, comparar conteúdo, classificar informações e até mesmo gerar insights estratégicos. Esses recursos tornam a tecnologia essencial para vários campos, como jurídico, financeiro, saúde e engenharia, otimizando a tomada de decisões e aumentando a produtividade.
Ao integrar essa tecnologia com ferramentas como serviços Oracle AI, OCI Data Science e APIs para processamento de documentos, as empresas podem criar soluções inteligentes que transformam completamente a maneira como interagem com seus dados, tornando a recuperação de informações mais rápida e eficaz.
Pré-requisitos
- Instale o Python
version 3.10ou superior e a CLI do OCI (Oracle Cloud Infrastructure Command Line Interface).
Tarefa 1: Instalar Pacotes Python
O código Python requer certas bibliotecas para usar a OCI Generative AI. Execute o seguinte comando para instalar os pacotes Python necessários.
pip install -r requirements.txt
Tarefa 2: Compreender o Código Python
Esta é uma demonstração da OCI Generative AI para consultar funcionalidades do Oracle SOA Suite e do Oracle Integration. Ambas as ferramentas são usadas atualmente para estratégias de integração híbrida, o que significa que operam em ambientes de nuvem e on-premises.
Como essas ferramentas compartilham funcionalidades e processos, esse código ajuda a entender como implementar a mesma abordagem de integração em cada ferramenta. Além disso, permite que os usuários explorem características e diferenças comuns.
Faça o download do código Python aqui:
Você pode encontrar os documentos PDF aqui:
Crie uma pasta chamada Manuals e mova esses PDFs para lá.
-
Importar Bibliotecas:
Importa as bibliotecas necessárias para processar PDFs, OCI Generative AI, vetorização de texto e armazenamento em bancos de dados vetoriais (Facebook AI Similarity Search (FAISS) e ChromaDB).
-
O
UnstructuredPDFLoaderé usado para extrair texto de PDFs. -
O
ChatOCIGenAIpermite o uso de modelos da OCI Generative AI para responder a perguntas. -
OCIGenAIEmbeddingscria incorporações (representações de vetor) de texto para pesquisa semântica.
-
-
Carregar e Processar PDFs:
Lista os arquivos PDF a serem processados.
-
O
UnstructuredPDFLoaderlê cada documento e o divide em páginas para facilitar a indexação e a pesquisa. -
Os IDs de documento são armazenados para referência futura.

-
-
Configurar o OCI Generative AI Model:
Configura o modelo
Llama-3.1-405bhospedado no OCI para gerar respostas com base nos documentos carregados.Define parâmetros como
temperature(controle de aleatoriedade),top_p(controle de diversidade) emax_tokens(limite de token).
Observação: A versão disponível do LLaMA pode mudar com o tempo. Verifique a versão atual em sua tenancy e atualize seu código, se necessário.
-
Criar Incorporações e Indexação de Vetores:
Usa o modelo de incorporação da Oracle para transformar texto em vetores numéricos, facilitando pesquisas semânticas em documentos.

-
O FAISS armazena as incorporações dos documentos PDF para consultas rápidas.
-
O
retrieverpermite recuperar os trechos mais relevantes com base na semelhança semântica da consulta do usuário.

-
-
Na primeira execução do processamento, os dados vetoriais serão salvos em um banco de dados FAISS.

-
Defina o Prompt:
Cria um prompt inteligente para o modelo generativo, orientando-o a considerar apenas documentos relevantes para cada consulta.
Isso melhora a precisão das respostas e evita informações desnecessárias.

-
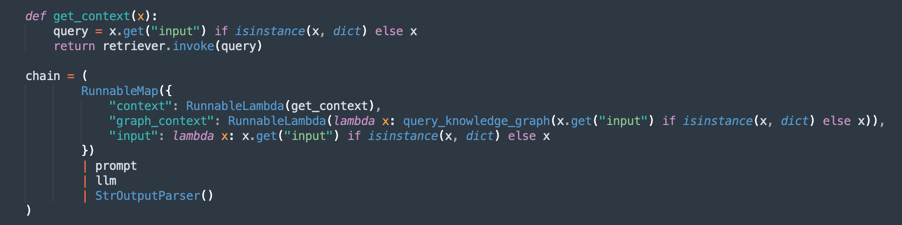
Crie a Cadeia de Processamento (RAG - Geração Aumentada de Recuperação):
Implementa um fluxo RAG, onde:
retrieverpesquisa os trechos de documento mais relevantes.- O
promptorganiza a consulta para um melhor contexto. llmgera uma resposta com base nos documentos recuperados.StrOutputParserformata a saída final.

-
Loop de Pergunta e Resposta:
Mantém um loop no qual os usuários podem fazer perguntas sobre os documentos carregados.
-
A IA responde usando a base de conhecimento extraída dos PDFs.
-
Se você informar
quit, ele sairá do programa.

-
Agora, você pode escolher 3 opções para processar os documentos. Você pode pensar:
- Quantos poderes você tem que processar?
- Quanto tempo você precisa processar?
- Como está a qualidade das suas respostas?
Portanto, você tem estas opções:
Fixed Size Chunking: Esta é uma alternativa mais rápida para processar seus documentos. Pode ser suficiente para obter o que você quer.
Divisão Semântica: Esse processo será mais lento do que a divisão em blocos de tamanho fixo, mas fornecerá mais divisão em blocos de qualidade.
Divisão Semântica com GraphRAG: Ele fornecerá um método mais preciso porque organizará os textos de divisão em blocos e os gráficos de conhecimento.
Divisão em blocos de tamanho fixo
Faça download do código aqui: oci_genai_llm_context_fast.py.
-
O que é o Fixed Size Chunking?
O Fixed Size Chunking é uma estratégia de divisão de texto simples e eficiente na qual os documentos são divididos em partes com base em limites de tamanho predefinidos, geralmente medidos em tokens, caracteres ou linhas.
Este método não analisa o significado ou a estrutura do texto. Ele simplesmente corta o conteúdo em intervalos fixos, independentemente de o corte acontecer no meio de uma frase, parágrafo ou ideia.
-
Como Funciona o Chunking de Tamanho Fixo:
-
Exemplo de Regra: Divida o documento a cada 1000 tokens (ou a cada 3000 caracteres).
-
Sobreposição Opcional: Para reduzir o risco de dividir o context relevante, algumas implementações adicionam uma sobreposição entre partes consecutivas (por exemplo, sobreposição de 200 toques) para garantir que o context importante não seja perdido no limite.
-
-
Benefícios do Chunking de Tamanho Fixo:
-
Processamento rápido: Não há necessidade de análise semântica, inferência de LLM ou compreensão de conteúdo. Apenas conte e corte.
-
Baixo consumo de recursos: Uso mínimo de CPU/GPU e memória, tornando-o escalável para grandes conjuntos de dados.
-
Fácil de implementar: Funciona com scripts simples ou bibliotecas de processamento de texto padrão.
-
-
Limitações de Chunking de Tamanho Fixo:
-
Pobre consciência semântica: os chunks podem cortar frases, parágrafos ou seções lógicas, levando a ideias incompletas ou fragmentadas.
-
Precisão de recuperação reduzida: em aplicativos como pesquisa semântica ou Geração Aumentada de Recuperação (RAG), limites de partes ruins podem afetar a relevância e a qualidade das respostas recuperadas.
-
-
Quando usar divisão em blocos de tamanho fixo:
-
Ao processar velocidade e escalabilidade são as principais prioridades.
-
Para pipelines de ingestão de documentos em larga escala em que a precisão semântica não é crítica.
-
Como um primeiro passo em cenários onde o refinamento ou a análise semântica posteriores acontecerão a jusante.
-
Esse é um método muito simples de dividir o texto.

-
Este é o principal processo de chunking fixo.

Observação: Faça download deste código para processar o chunking fixo mais mais rápido:
oci_genai_llm_context_fast.py -
Divisão em blocos semânticos
Faça download do código aqui: oci_genai_llm_context.py.
-
O que é o Chunking Semântico?
O Chunking Semântico é uma técnica de pré-processamento de texto em que documentos grandes (como PDFs, apresentações ou artigos) são divididos em partes menores chamadas chunks, com cada bloco representando um bloco de texto semanticamente coerente.
Ao contrário do chunking tradicional de tamanho fixo (por exemplo, dividindo a cada 1000 tokens ou a cada X caracteres), o Chunking Semântico usa Inteligência Artificial (normalmente Modelos de Linguagem Grandes - LLMs) para detectar limites de conteúdo natural, respeitando tópicos, seções e context.
Em vez de cortar texto arbitrariamente, o Semantic Chunking tenta preservar o significado completo de cada seção, criando peças independentes e sensíveis ao contexto.
-
Por que a divisão semântica pode tornar o processamento mais lento?
Um processo de chunking tradicional, baseado em tamanho fixo, é rápido. O sistema conta apenas tokens ou caracteres e corta de acordo. Com o Semantic Chunking, várias etapas extras da análise semântica são necessárias:
- Ler e interpretar o texto completo (ou grandes blocos) antes de dividir: O LLM precisa entender o conteúdo para identificar os melhores limites de bloco.
- Executando prompts do LLM ou modelos de classificação de tópicos: O sistema geralmente consulta o LLM com perguntas como Este é o fim de uma ideia? ou Este parágrafo inicia uma nova seção?.
- Memória superior e uso de CPU/GPU: Como o modelo processa blocos de texto maiores antes de tomar decisões de divisão em blocos, o consumo de recursos é significativamente maior.
- Tomada de decisão sequencial e incremental: O chunking semântico geralmente funciona em etapas (por exemplo, analisar blocos de 10.000 tokens e, em seguida, refinar os limites do chunk dentro desse bloco), o que aumenta o tempo total de processamento.
Observação:
- Dependendo do poder de processamento da máquina, você aguardará um longo e longo tempo para finalizar a primeira execução usando Divisão Semântica.
- Você pode usar esse algoritmo para produzir chunking personalizado usando o OCI Generative AI.
-
Como Funciona o Chunking Semântico:
-
smart_split_text(): Separa o texto completo em pequenos pedaços de 10kb (você pode configurar para adotar outras estratégias). O mecanismo percebe o último parágrafo. Se parte do parágrafo estiver na próxima parte do texto, essa parte será ignorada no processamento e será anexada ao próximo grupo de texto de processamento. -
semantic_chunk(): Esse método usará o mecanismo do LLM do OCI para separar os parágrafos. Inclui a inteligência para identificar os títulos, componentes de uma tabela, os parágrafos para executar um bloco inteligente. A estratégia aqui é usar a técnica Chunk Semântico. Levará mais tempo para completar a missão se comparado com o processamento comum. Assim, o primeiro processamento levará muito tempo, mas o próximo carregará todos os dados pré-salvos do FAISS. -
split_llm_output_into_chapters(): Este método finalizará o bloco, separando os capítulos.
Observação: Faça download deste código para processar o chunking semântico:
oci_genai_llm_context.py -
Divisão em Blocos Semânticos com GraphRAG
Faça download do código aqui: oci_genai_llm_graphrag.py.
GraphRAG (Geração Aumentada de Recuperação de Gráficos) é uma arquitetura de IA avançada que combina a recuperação tradicional baseada em vetores com gráficos de conhecimento estruturados. Em um pipeline RAG padrão, um modelo de linguagem recupera partes de documentos relevantes usando similaridade semântica de um banco de dados vetorial (como FAISS). No entanto, a recuperação baseada em vetores opera de maneira não estruturada, contando puramente com incorporações e métricas de distância, que às vezes perdem significados contextuais ou relacionais mais profundos.
GraphRAG aprimora esse processo introduzindo uma camada de gráfico de conhecimento, na qual entidades, conceitos, componentes e seus relacionamentos são representados explicitamente como nós e bordas. Esse context baseado em gráfico permite que o modelo de linguagem raciocine sobre relacionamentos, hierarquias e dependências que a similaridade vetorial sozinha não pode capturar.
-
Por que Combinar Divisão em Blocos Semânticos com GraphRAG?
O chunking semântico é o processo de dividir inteligentemente grandes documentos em unidades significativas ou "chunks", com base na estrutura do conteúdo – como capítulos, cabeçalhos, seções ou divisões lógicas. Em vez de quebrar documentos puramente por limites de caracteres ou divisão ingênua de parágrafos, o chunking semântico produz pedaços de maior qualidade e com consciência de context que se alinham melhor com a compreensão humana.
-
Divisão em blocos semânticos com vantagens de GraphRAG:
-
Representação de Conhecimento Aprimorada:
- Os chunks semânticos preservam limites lógicos no conteúdo.
- Os gráficos de conhecimento extraídos desses blocos mantêm relacionamentos precisos entre entidades, sistemas, APIs, processos ou serviços.
-
Recuperação Contextual Multimodal (o modelo de idioma recupera ambos):
- context não estruturado do banco de dados vetorial (similaridade semântica).
- context estruturado a partir do gráfico de conhecimento (triplos entidade-relação).
- Essa abordagem híbrida leva a respostas mais completas e precisas.
-
Recursos de raciocínio aprimorados:
- A recuperação baseada em gráfico permite o raciocínio relacional.
- O LLM pode responder a perguntas como:
- De quais serviços a API de Pedidos depende?
- Quais componentes fazem parte do SOA Suite?
- Essas consultas relacionais geralmente são impossíveis com abordagens somente incorporação.
-
Maior Explicabilidade e Rastreabilidade:
- Os relacionamentos gráficos são legíveis e transparentes.
- Os usuários podem inspecionar como as respostas são derivadas do conhecimento textual e estrutural.
-
Alucinação Reduzida: O gráfico atua como uma restrição no LLM, ancorando respostas a relacionamentos verificados e conexões factuais extraídas dos documentos de origem.
-
Escalabilidade em domínios complexos:
- Em domínios técnicos (por exemplo, APIs, microsserviços, contratos legais, padrões de assistência médica), as relações entre os componentes são tão importantes quanto os próprios componentes.
- O GraphRAG combinado com o chunking semântico é dimensionado de forma eficaz nesses contextos, preservando a profundidade textual e a estrutura relacional.
Observação:
- Faça download do código para processar o chunking semântico com graphRAG aqui:
oci_genai_llm_graphrag.py. - Você precisará de:
- Um docker instalado e ativo para usar o banco de dados do sistema operacional de gráfico de código-fonte aberto Neo4J para testar.
- Instale a Biblioteca Python neo4j.
Existem 2 métodos neste código:
-
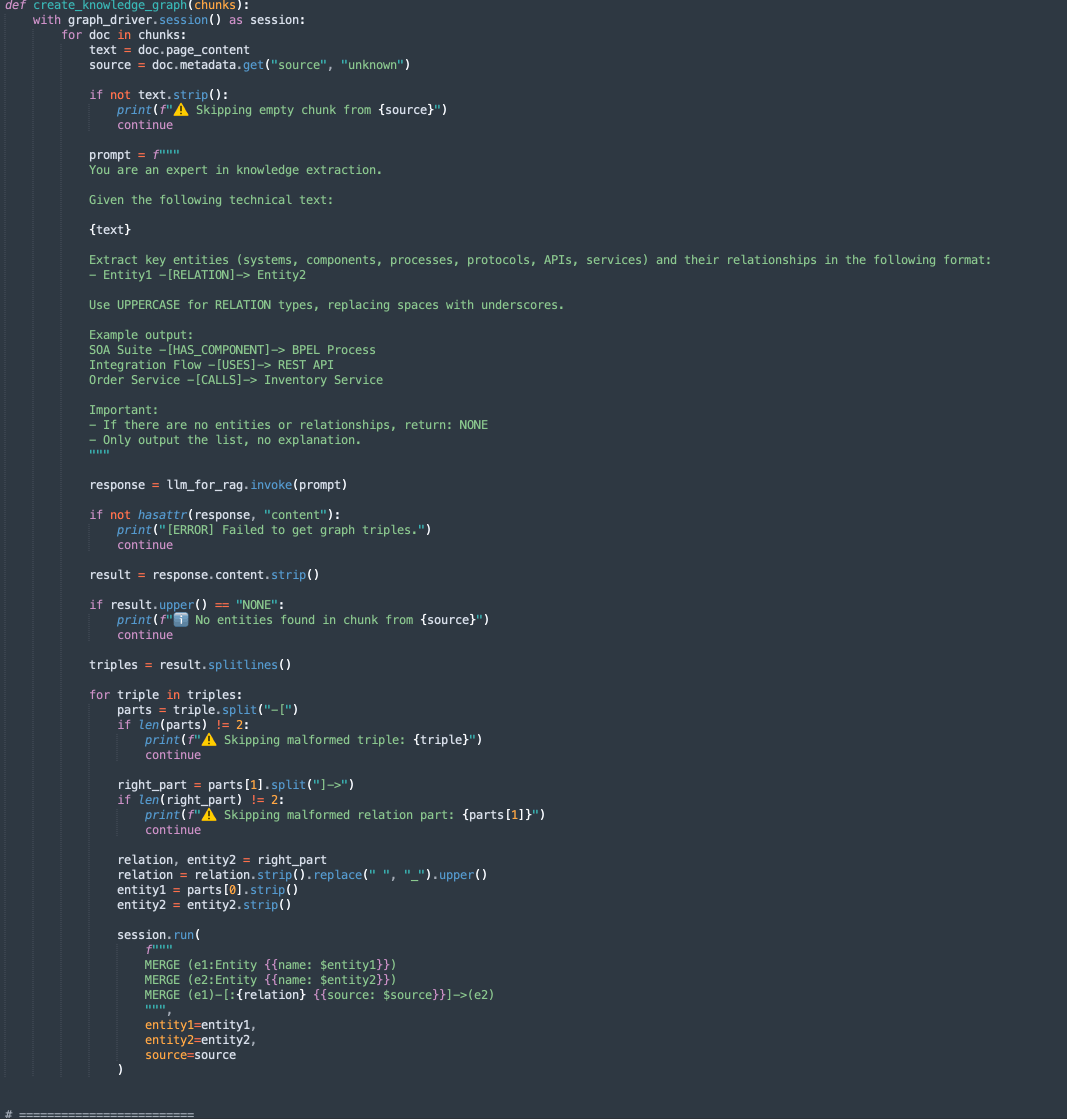
create_knowledge_graph:-
Esse método extrai automaticamente entidades e relacionamentos de blocos de texto e os armazena em um gráfico de conhecimento Neo4j.
-
Para cada trecho de documento, ele envia o conteúdo para um LLM (Large Language Model) com um prompt solicitando a extração de entidades (como sistemas, componentes, serviços, APIs) e seus relacionamentos.
-
Ele analisa cada linha, extrai Entity1, RELATION e Entity2.
-
Armazena essas informações como nós e bordas no banco de dados gráfico Neo4j usando consultas Cypher:
MERGE (e1:Entity {name: $entity1}) MERGE (e2:Entity {name: $entity2}) MERGE (e1)-[:RELATION {source: $source}]->(e2)
-
-
-
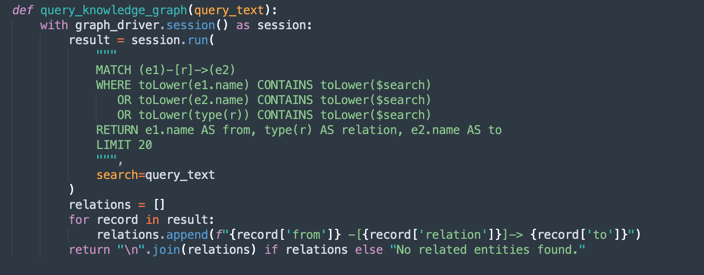
query_knowledge_graph:-
Esse método consulta o gráfico de conhecimento Neo4j para recuperar relacionamentos relacionados a uma palavra-chave ou conceito específico.
-
Executa uma consulta de Cifra que procura:
Any relationship (e1)-[r]->(e2) Where e1.name, e2.name, or the relationship type contains the query_text (case-insensitive). -
Retorna até 20 triplos correspondentes formatados como:
Entity1 -[RELATION]-> Entity2
-
Observação:
Neo4j Uso:
Essa implementação usa o Neo4j como um banco de dados de gráfico de conhecimento incorporado para fins de demonstração e prototipagem. Embora o Neo4j seja um banco de dados gráfico avançado e flexível adequado para desenvolvimento, teste e cargas de trabalho de pequeno a médio porte, ele pode não atender aos requisitos para cargas de trabalho de nível empresarial, de missão crítica ou altamente seguras, especialmente em ambientes que exigem alta disponibilidade, escalabilidade e conformidade de segurança avançada.
Para ambientes de produção e cenários corporativos, recomendamos aproveitar o Oracle Database com recursos do Graph, que oferece:
Confiabilidade e segurança de nível empresarial.
Escalabilidade para cargas de trabalho de missão crítica.
Modelos gráficos nativos (Property Graph e RDF) integrados com dados relacionais.
Recursos avançados de análise, segurança, alta disponibilidade e recuperação de desastres.
Integração completa da Oracle Cloud Infrastructure (OCI).
Ao usar o Oracle Database para cargas de trabalho gráficas, as organizações podem unificar dados estruturados, semiestruturados e gráficos em uma única plataforma empresarial segura e escalável.
Tarefa 3: Executar Consulta para o Conteúdo do Oracle Integration e do Oracle SOA Suite
Execute o seguinte comando.
FOR FIXED CHUNKING TECHNIQUE (MORE FASTER METHOD)
python oci_genai_llm_context_fast.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
FOR SEMANTIC CHUNKING TECHNIQUE
python oci_genai_llm_context.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
FOR SEMANTIC CHUNKING COMBINED WITH GRAPHRAG TECHNIQUE
python oci_genai_llm_graphrag.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
Observação: Os parâmetros
--devicee--gpu_namepodem ser usados para acelerar o processamento em Python, usando GPU se sua máquina tiver um. Considere que esse código também pode ser usado com modelos locais.
O contexto fornecido faz a distinção entre Oracle SOA Suite e Oracle Integration. Você pode testar o código considerando estes pontos:
- A consulta deve ser feita somente para o Oracle SOA Suite. Portanto, somente os documentos do Oracle SOA Suite devem ser considerados.
- A consulta deve ser feita somente para o Oracle Integration. Portanto, somente os documentos do Oracle Integration devem ser considerados.
- A consulta requer uma comparação entre o Oracle SOA Suite e o Oracle Integration. Portanto, todos os documentos devem ser considerados.
Podemos definir o contexto a seguir, o que ajuda muito na interpretação correta dos documentos.
A imagem a seguir mostra o exemplo de comparação entre o Oracle SOA Suite e o Oracle Integration.

Próximas Etapas
Este código demonstra uma aplicação da OCI Generative AI para análise inteligente de PDF. Ele permite que os usuários consultem com eficiência grandes volumes de documentos usando pesquisas semânticas e um modelo de IA generativa para gerar respostas precisas em linguagem natural.
Essa abordagem pode ser aplicada em diversos campos, como jurídico, compliance, suporte técnico e pesquisa acadêmica, tornando a recuperação de informações muito mais rápida e inteligente.
Links Relacionados
-
Integração entre a nuvem e a IA de conversação: LangChain e a plataforma OCI Data Science
-
Introdução a Agentes Python Personalizados e Incorporados LangChain
-
Oracle Database Insider - Graph RAG: Traga o Poder dos Gráficos para a IA Generativa
Confirmações
- Autor - Cristiano Hoshikawa (Engenheiro de Soluções da Equipe A do Oracle LAD)
Mais Recursos de Aprendizado
Explore outros laboratórios em docs.oracle.com/learn ou acesse mais conteúdo de aprendizado gratuito no canal do Oracle Learning YouTube. Além disso, acesse education.oracle.com/learning-explorer para se tornar um Oracle Learning Explorer.
Para obter a documentação do produto, visite o Oracle Help Center.
Analyze PDF Documents in Natural Language with OCI Generative AI
G29543-05
Copyright ©2025, Oracle and/or its affiliates.