Observação:
- Este tutorial requer acesso ao Oracle Cloud. Para se inscrever e obter uma conta grátis, consulte Conceitos Básicos do Oracle Cloud Infrastructure Free Tier.
- Ele usa valores de exemplo para credenciais, tenancy e compartimentos do Oracle Cloud Infrastructure. Ao concluir seu laboratório, substitua esses valores por valores específicos do seu ambiente de nuvem.
Análise de fluxo usando o Oracle Cloud Infrastructure Streaming e o Oracle Database
Introdução
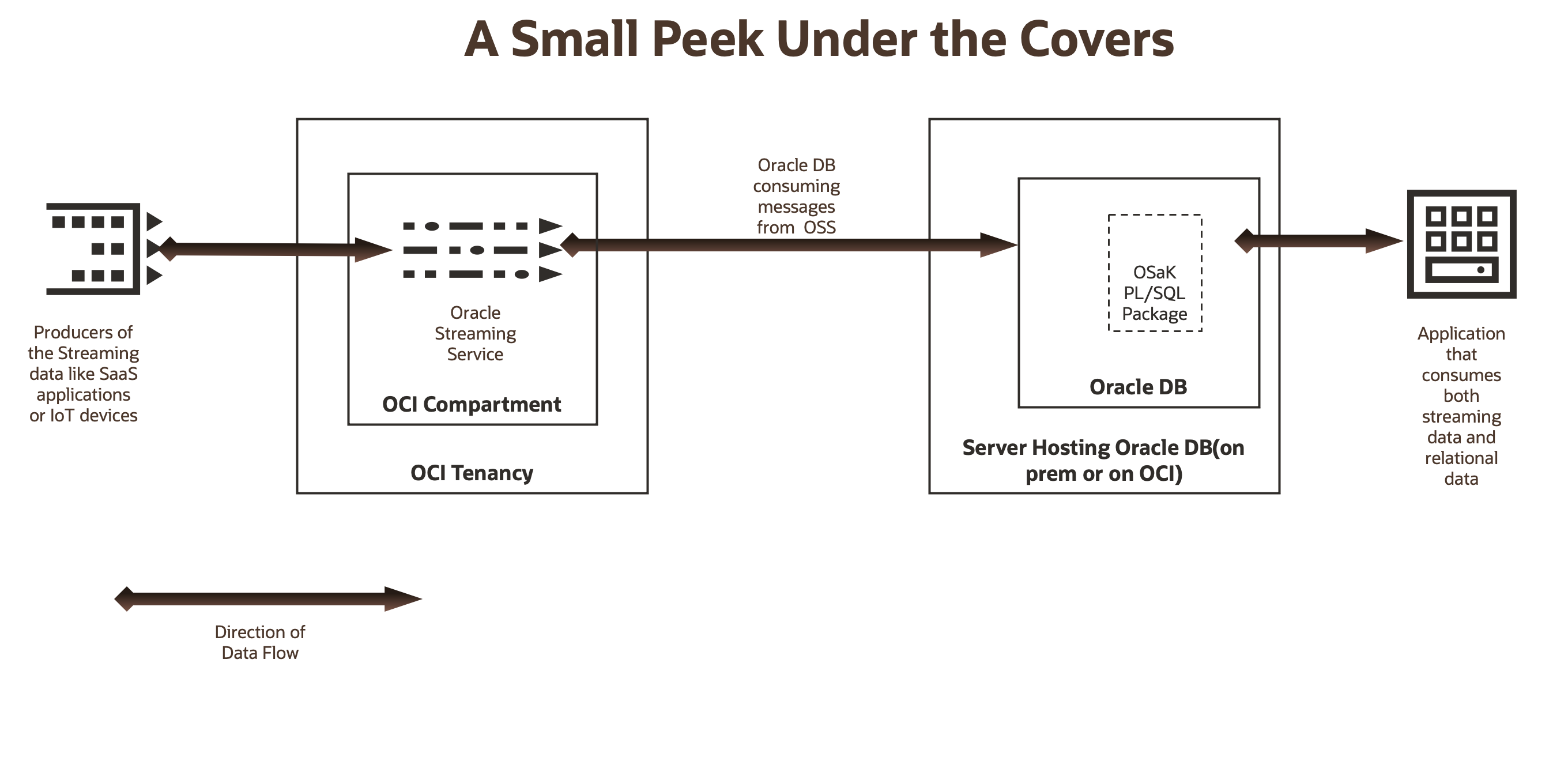
O Oracle Cloud Infrastructure Streaming é um serviço de streaming altamente escalável e disponível no Oracle Cloud Infrastructure (OCI). O serviço Stream é totalmente sem servidor e compatível com a API do Apache Kafka.
O Oracle SQL access to Kafka é um pacote Oracle PL/SQL e um pré-processador de tabela externa. Ele permite que o Oracle Database leia e processe eventos e mensagens de Tópicos do Kafka como Views ou Tabelas no Oracle Database. Depois que os dados do Kafka estiverem em uma tabela do Oracle Database ou visíveis em uma view do Oracle Database, eles poderão ser consultados com todo o poder do Oracle PL/SQL, assim como com quaisquer outros dados do Oracle Database.
Quando você recupera dados com o acesso do Oracle SQL às views ativadas do Kafka, os dados não são persistidos no Oracle Database. Mas quando você usa o acesso do Oracle SQL para tabelas com a tecnologia Kafka, ele é persistido no Oracle Database. Portanto, o acesso do Oracle SQL ao Kafka oferece aos desenvolvedores flexibilidade total sobre a persistência do streaming de dados no Oracle Database. Para obter uma boa visão geral e um caso de uso do acesso do Oracle SQL ao Kafka, consulte esta publicação no blog, Integrando o Data-in-Motion com o Data-at-Rest usando o Oracle SQL Access às Views do Kafka.
Em resumo, o acesso do Oracle SQL ao Kafka permite que os dados em movimento sejam processados com dados em repouso (dentro das tabelas do Oracle Database) usando o Oracle PL/SQL. Portanto, os aplicativos, por exemplo, aplicativos JDBC (Java Database Connectivity) podem processar eventos em tempo real do Kafka e dados críticos do Oracle Database, em transações do Oracle Database que dão garantias de ACID. Isso não é possível facilmente quando um aplicativo extrai eventos e dados do Kafka do Oracle Database separadamente.
Benefícios
- Os clientes podem usar o acesso do Oracle SQL ao Kafka para executar jobs de análise de fluxo em tempo real usando o Oracle PL/SQL lendo diretamente os dados do serviço Stream, sem nunca movê-los para um armazenamento de dados externo.
- Os clientes também podem usar o acesso do Oracle SQL ao Kafka puramente para movimentação de dados do serviço de Stream para o Oracle Database sem qualquer processamento.
- A operação de processamento de fluxo pode ser executada no contexto de uma transação Oracle ACID controlada pelo aplicativo.
- O acesso do Oracle SQL ao Kafka só atua como consumidor do Kafka e nunca como produtor do Kafka. Todo o gerenciamento de deslocamento é tratado por OSaK. Ele armazena essas informações em tabelas de metadados no Oracle Database. Portanto, o acesso do Oracle SQL ao Kafka permite semânticas de processamento exatamente uma vez, pois ele pode confirmar o deslocamento de partição para o Kafka e o serviço de Stream e os dados do aplicativo, em uma única transação do Oracle Database compatível com ACID para o Oracle Database. Isso elimina a perda ou a releitura de registros de streaming.
Casos de Uso
Imagine qualquer caso de uso em que você queira relacionar ou juntar seus dados de streaming com seus dados relacionais, por exemplo:
- Você deseja combinar os dados de streaming dos seus dispositivos de chatty IoT (provavelmente presentes nas instalações do seu cliente) com as informações relevantes do cliente, armazenadas no seu Oracle Database relacional de origem.
- Você deseja calcular médias de movimentação exponenciais precisas para preços de estoque que estão sendo transferidos para o serviço Stream. Você precisa fazer isso com uma semântica exatamente uma vez. Você deseja combinar esses dados com informações estáticas sobre esse estoque, como nome, ID da empresa, limite de mercado etc., armazenados no Oracle Database.
Observe que, como o acesso do Oracle SQL ao Kafka é um pacote PL/SQL que precisa ser instalado manualmente no Host do Servidor Oracle, ele só pode funcionar com instalações do Oracle Database autogerenciadas (no local ou na nuvem). Ele não pode funcionar com ofertas do Oracle Database sem servidor, como o Oracle Autonomous Database no Oracle Cloud Infrastructure (OCI).
Como o serviço Stream é compatível com a API do Kafka, ele funciona sem problemas com o acesso do Oracle SQL ao Kafka. No acesso do Oracle SQL ao ponto de vista do Kafka, um pool de fluxos de serviços do Stream é um cluster do Kafka e um fluxo de serviços do Stream é um tópico no cluster do Kafka.
Neste tutorial, mostraremos a facilidade com que podemos integrar o acesso do Oracle SQL ao Kafka com o serviço Stream.
Observação: se você já estiver familiarizado com o acesso do Oracle SQL ao Kafka, ao serviço de Stream e ao Kafka e quiser usar o acesso do Oracle SQL ao Kafka com o serviço de Stream, poderá ir diretamente para Configurar Clusters do Oracle Cloud Infrastructure Streaming para acesso do Oracle SQL à etapa 2.1 do Kafka. Utilize o restante do tutorial conforme necessário.
Pré-requisitos
- Conta ou tenancy do OCI com autorização para criar e usar o serviço Stream.
- Cluster Apache Kafka 0.10.2 ou posterior. O serviço Stream atende a esse requisito.
- Oracle Database 12.2 ou posterior, onde o acesso do Oracle SQL ao Kafka será instalado (a versão 19c é usada neste tutorial). Estamos usando o Oracle Linux como o sistema operacional de plataforma para o Oracle Database. As instruções gerais permanecem as mesmas para outras plataformas.
- Java 8 ou mais recente instalado no host do Oracle Database.
Oracle Cloud Infrastructure Streaming e Acesso do Oracle SQL à Integração com o Kafka
Crie um Pool e um Fluxo do Oracle Cloud Infrastructure
-
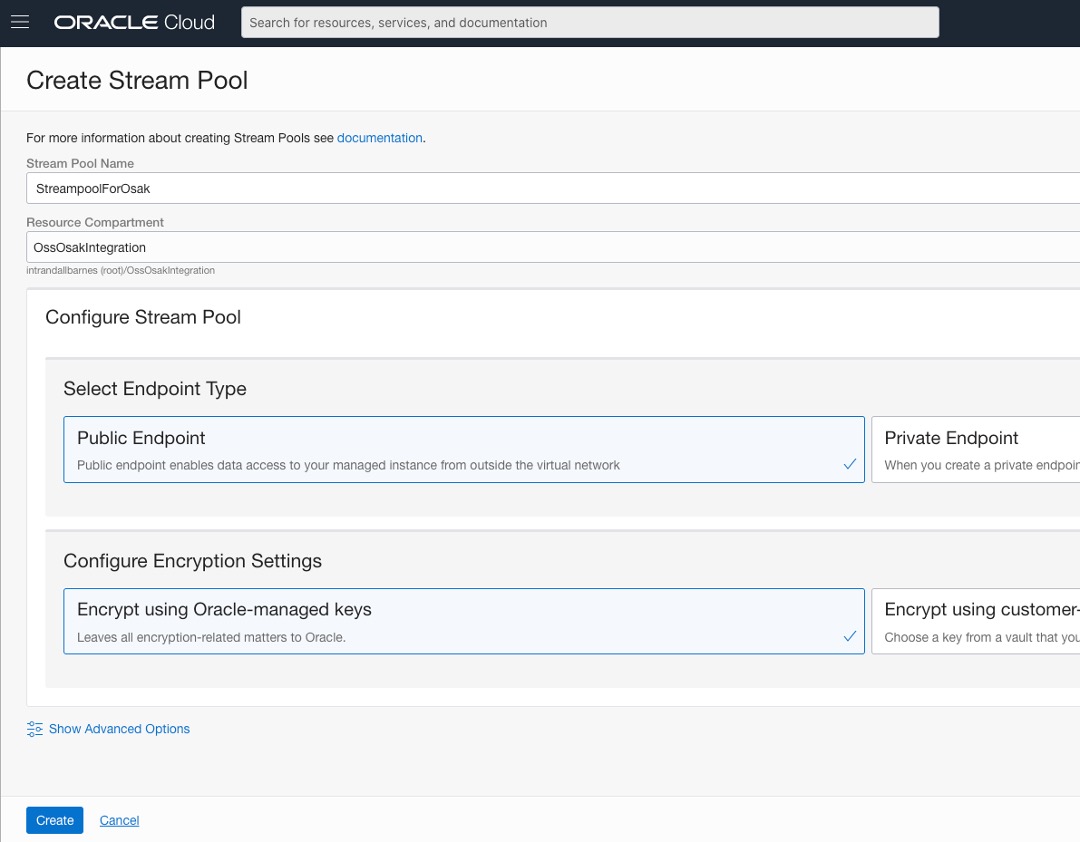
Faça log-in na sua conta/tenancy do OCI e configure um pool de streams de serviços do Stream chamado StreampoolForOsak e um stream chamado StreamForOsak da seguinte forma:
-
Agora criamos um fluxo denominado StreamForOsak no pool de fluxos StreampoolForOsak que acabamos de criar.
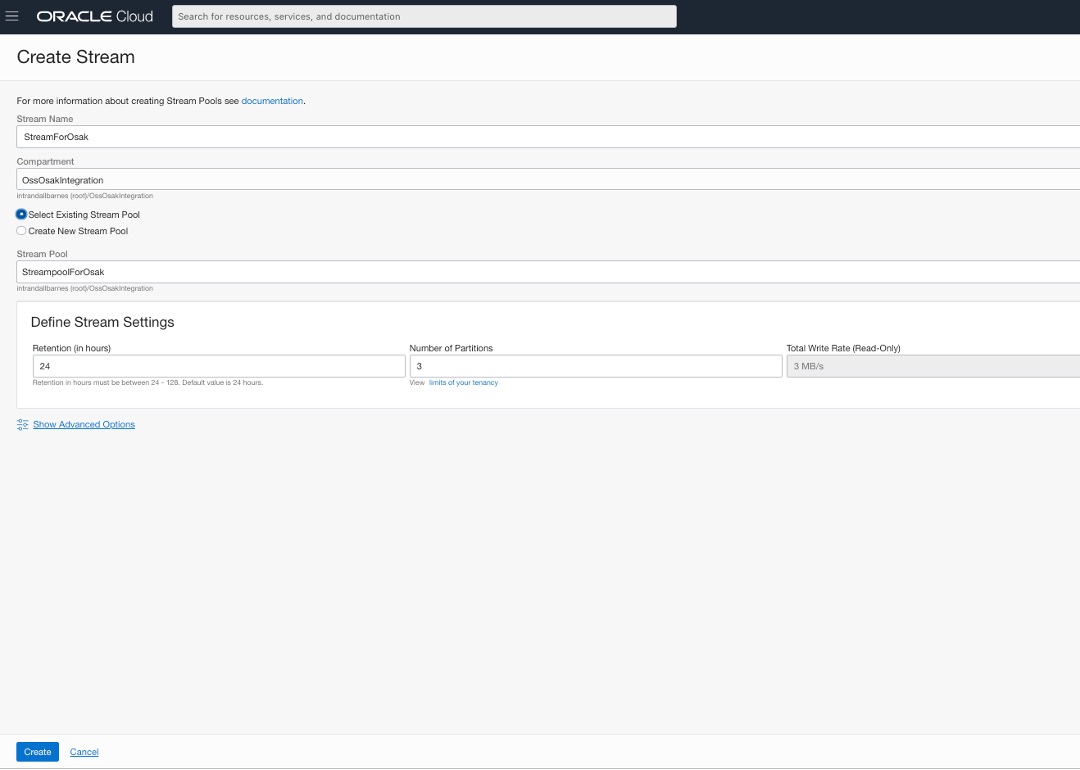
Para essas criações de recursos, você pode usar qualquer um dos seus compartimentos existentes. Para nossa conveniência, criamos um novo compartimento chamado OssOsakIntegration e todos os recursos estão no mesmo compartimento.
Na terminologia do serviço Stream, os tópicos do Kafka são chamados de Streams. Portanto, no acesso do Oracle SQL ao ponto de vista do Kafka, o fluxo StreamForOsak é um tópico do Kafka com três partições.
Agora terminamos com a criação do fluxo de serviço do Stream. Em seguida, os termos Stream Service e Kafka são intercambiáveis. Da mesma forma, os termos Tópico do Stream e do Kafka são intercambiáveis.
Crie um Usuário, Grupo e Políticas no Oracle Cloud Infrastructure
Se você já tiver um usuário existente com as autorizações certas para usar o serviço Stream, a etapa 2 poderá ser totalmente ignorada.
-
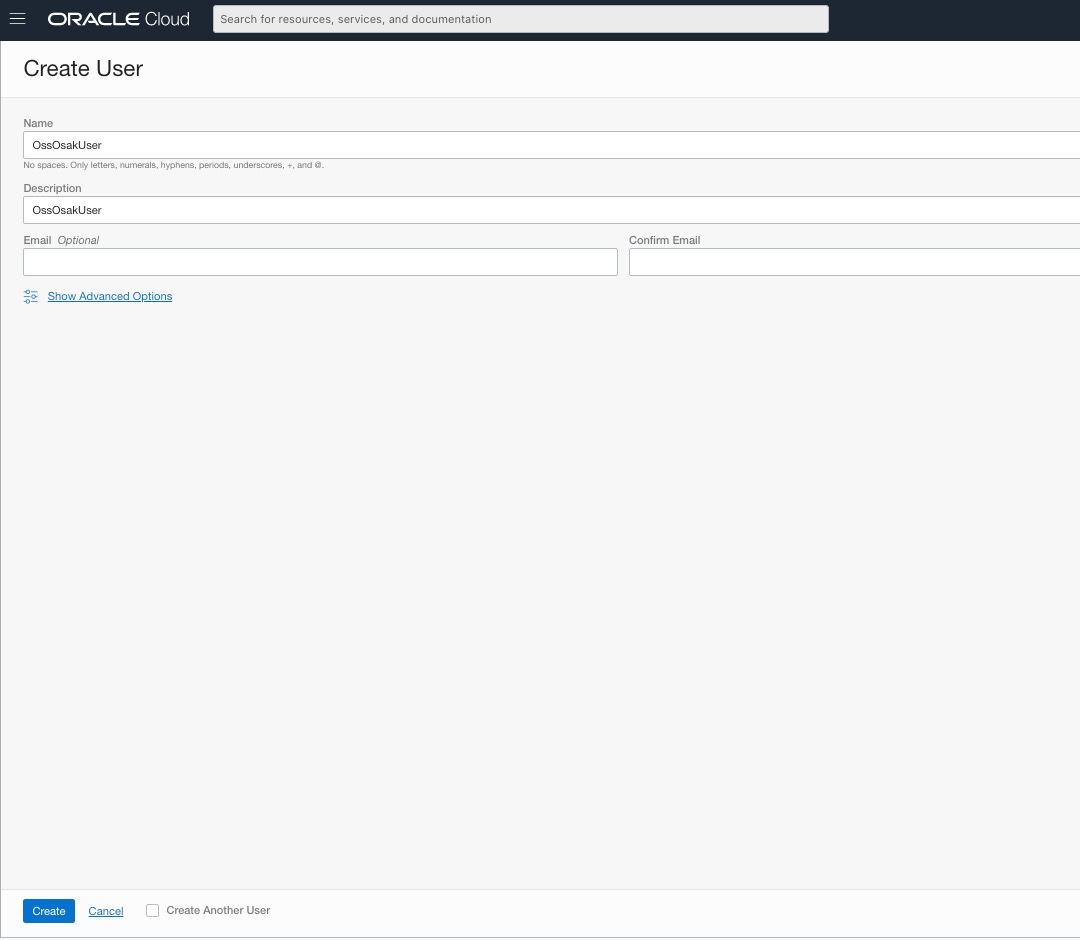
Para usar os fluxos de serviços do Stream com acesso do Oracle SQL ao Kafka, precisamos criar um novo usuário do OCI para ele. Criamos um novo usuário para essa finalidade com o nome de usuário OssOsakUser, na console web do OCI da seguinte forma:
-
Para que o usuário OssOsakUser se autentique no serviço de Stream (usando APIs do Kafka), precisamos criar um token de autenticação para esse novo usuário, da seguinte forma:
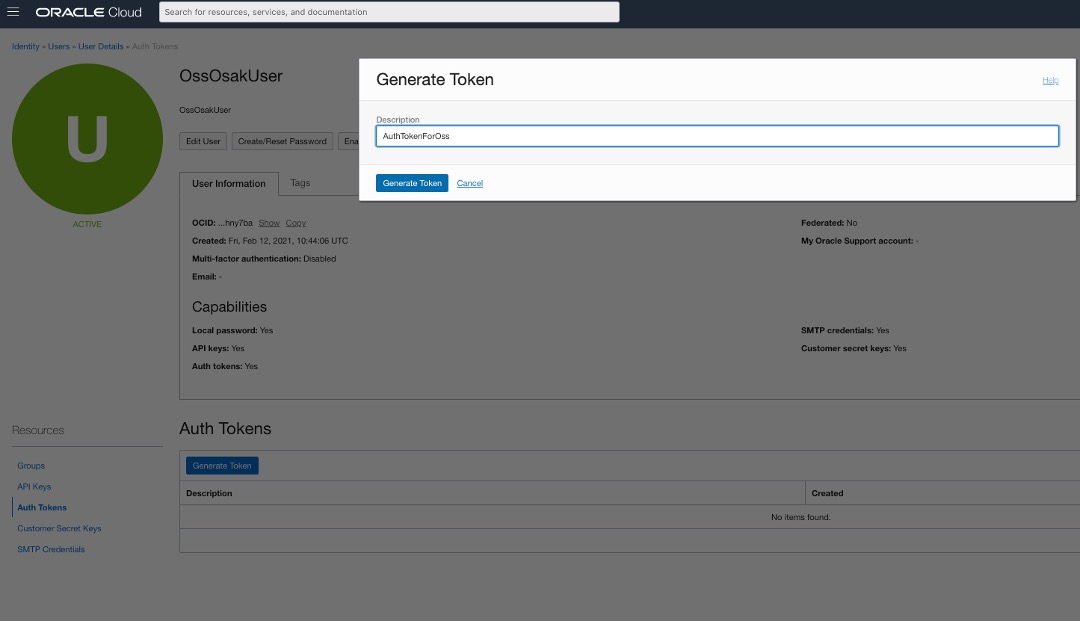
Depois de gerar o token, você obtém primeiro e a única chance de ver e copiar o token de autenticação. Portanto, copie o token de autenticação e mantenha-o em um lugar de onde você possa acessá-lo posteriormente. Você precisa dele em etapas posteriores, especificamente quando configuramos o cluster Kafka para acesso do Oracle SQL ao Kafka. O acesso do Oracle SQL ao Kafka usará esse nome de usuário: OssOsakUser e seu token de autenticação para acessar o serviço Stream, usando APIs de Consumidor do Kafka internamente.
-
O OssOsakUser também precisa ter o conjunto correto de privilégios no OCI IAM para acessar o cluster de serviço do Stream.
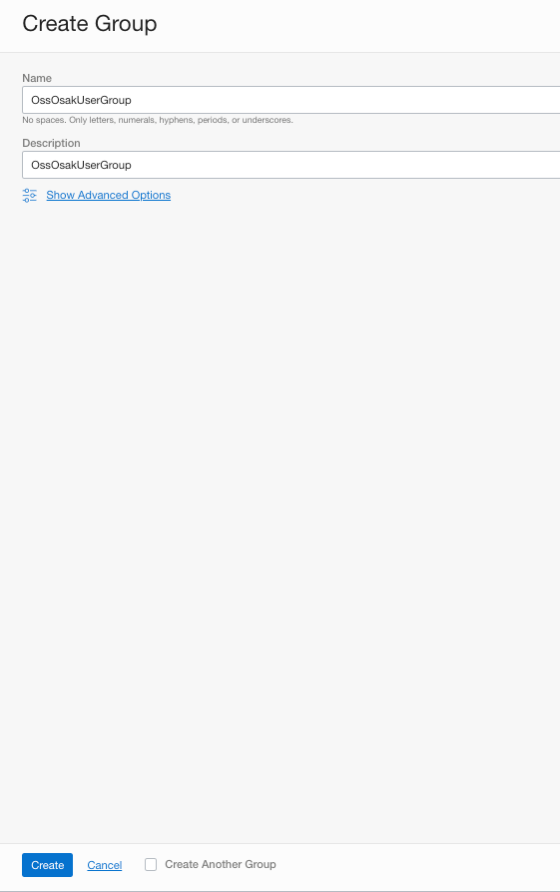
No OCI, os usuários adquirem privilégios com a ajuda de políticas designadas a grupos de usuários dos quais fazem parte. Portanto, precisamos criar um grupo para OssOsakUser, seguido de uma política para esse grupo.
Crie um grupo de usuários conforme mostrado abaixo:
-
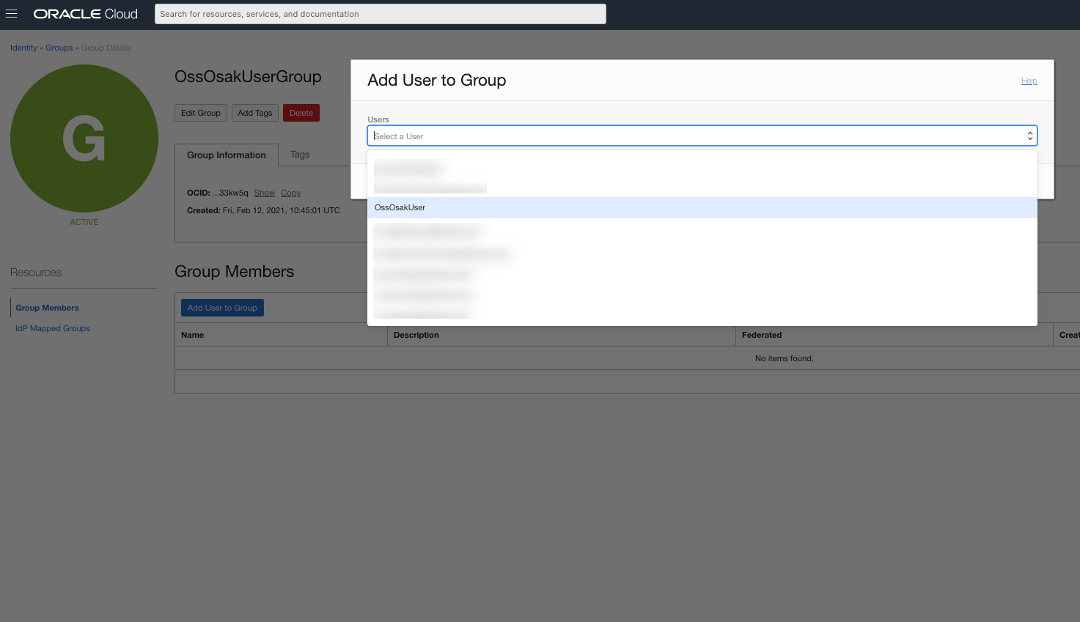
Adicione o usuário OssOsakUser ao grupo de usuários OssOsakUserGroup.
-
Para autorizar OssOsakUser a usar o fluxo de serviço do Stream, especificamente para publicar e ler mensagens dele, precisamos criar a política a seguir na tenancy. Esta política, uma vez criada, concede privilégios a todos os usuários do grupo OssOsakUserGroup. Como o usuário OssOsakUser está no mesmo grupo, ele adquire os mesmos privilégios.
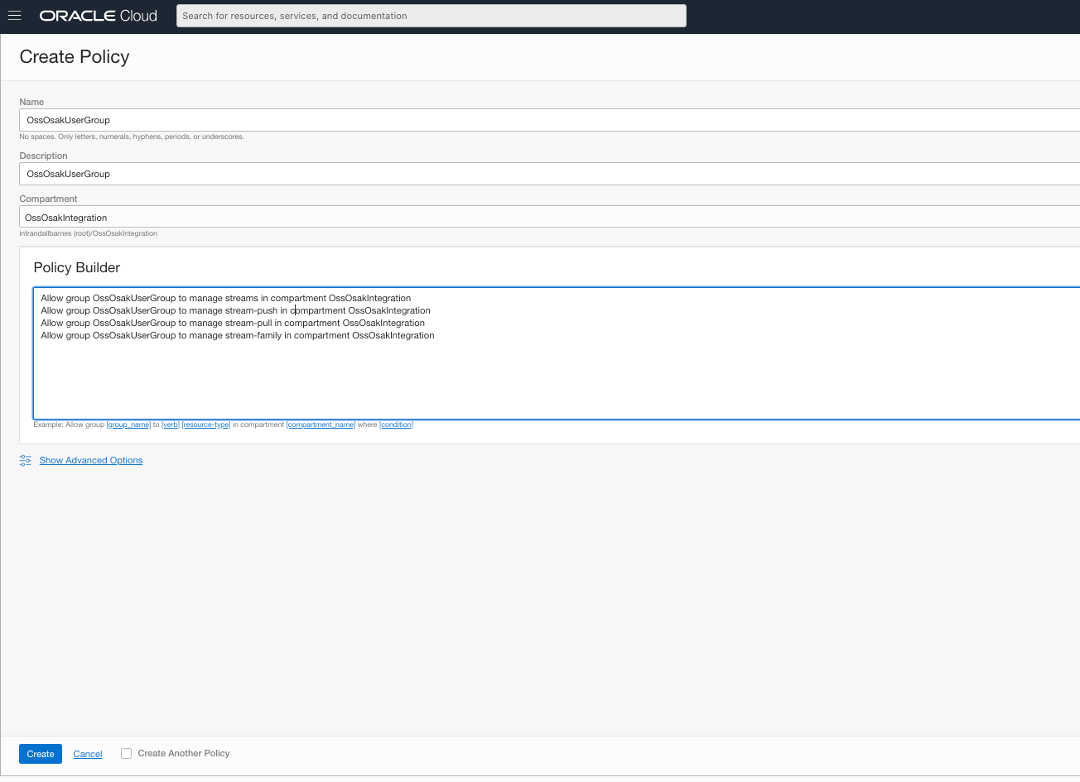
O trecho de texto da mesma política acima é o seguinte:
Allow group OssOsakUserGroup to manage streams in compartment OssOsakIntegration Allow group OssOsakUserGroup to manage stream-push in compartment OssOsakIntegration Allow group OssOsakUserGroup to manage stream-pull in compartment OssOsakIntegration Allow group OssOsakUserGroup to manage stream-family in compartment OssOsakIntegration
Instalar o Acesso do Oracle SQL ao Kafka em um Host do Oracle Database
-
O acesso do Oracle SQL ao kit Kafka está disponível como parte de um SQL Developer amplamente usado.
Use o link oficial do SQL Developer para fazer download da versão mais recente do SQL Developer. A partir da elaboração deste tutorial, a versão mais recente do SQL Developer é 20.4.
Certifique-se de fazer download do Oracle SQL Developer para a mesma plataforma do host do Oracle Database. Em nossa caixa de desenvolvimento, baixamos o Oracle SQL Developer para Oracle Linux RPM (já que nosso Oracle Database está sendo executado no Oracle Linux Platform).
Após a conclusão do download, extraia o conteúdo do arquivo RPM/zip do Oracle SQL Developer para qualquer diretório/pasta usando o comando
unzipoutar.tar xvf sqldeveloper-20.4.0.379.2205-20.4.0-379.2205.noarch.rpm -
Vá para o diretório em que o conteúdo do Oracle SQL Developer foi extraído e localize o acesso do Oracle SQL ao arquivo ZIP do Kafka chamado
orakafka.zipda seguinte forma:$ find . -name 'orakafta*' ./sqldeveloper/orakafta ./sqldeveloper/orakafta/orakafta.zipO acesso do Oracle SQL ao kit Kafka está no arquivo
orakafka.zip. Não estamos interessados no restante do conteúdo do desenvolvedor SQL para esta demonstração. No que diz respeito à instalação e ao uso do acesso do Oracle SQL ao Kafka,orakafka.zipé tudo o que precisamos. -
Copie o arquivo
orakafka.zippara o host do Oracle Database usando o comandoscpou clientes FTP baseados em GUI, como FileZilla.SSH para o nó do Oracle Database e mova
orakafka.zippara/home/oracle(diretório home do usuário oracle) com omv_ command. -
Para o restante das instruções de instalação do acesso do Oracle SQL ao Kafka, precisamos alternar para o usuário oracle no host do Oracle Database.
Certifique-se de que o diretório de trabalho atual seja
/home/oracle. Já temosorakafka.zipno mesmo diretório.[opc@dbass ~]$ sudo su - oracle Last login: Sat Feb 20 09:31:12 UTC 2021 [oracle@dbass ~]$ pwd /home/oracle [oracle@dbass ~]$ ls -al total 3968 drwx------ 6 oracle oinstall 4096 Feb 19 17:39 . drwxr-xr-x 5 root root 4096 Feb 18 15:15 .. -rw------- 1 oracle oinstall 4397 Feb 20 09:31 .bash_history -rw-r--r-- 1 oracle oinstall 18 Nov 22 2019 .bash_logout -rw-r--r-- 1 oracle oinstall 203 Feb 18 15:15 .bash_profile -rw-r--r-- 1 oracle oinstall 545 Feb 18 15:20 .bashrc -rw-r--r-- 1 oracle oinstall 172 Apr 1 2020 .kshrc drwxr----- 3 oracle oinstall 4096 Feb 19 17:37 .pki drwxr-xr-x 2 oracle oinstall 4096 Feb 18 15:20 .ssh -rw-r--r-- 1 oracle oinstall 4002875 Feb 19 17:38 orakafka.zip -
Extraia ou descompacte
orakafka.zip. Isso criará um novo diretório chamadoorakafka-<version>com o conteúdo extraído. Em nosso caso, éorakafka-1.2.0da seguinte forma:[oracle@dbass ~]$ unzip orakafka.zip Archive: orakafka.zip creating: orakafka-1.2.0/
extraindo: orakafka-1.2.0/kit_version.txt
inflando: orakafka-1.2.0/orakafka_distro_install.sh
extraindo: orakafka-1.2.0/orakafka.zip
inflando: orakafka-1.2.0/README
6. Now we follow the instructions found in the _**orakafka-1.2.0/README**_ for the setup of Oracle SQL access to Kafka. We follow _simple install_ for single-instance Oracle Database.
This README doc has instructions for Oracle SQL access to Kafka installation on Oracle Real Application Clusters (Oracle RAC) as well. By and large, in the case of Oracle RAC, we need to replicate the following steps on all nodes of Oracle RAC. Please follow the README for details.
[oracle@dbass ~]$ cd orakafka-1.2.0/
[oracle@dbass orakafka-1.2.0]$ ls -al
total 3944
drwxrwxr-x 2 oracle oinstall 4096 Feb 20 09:12 .
drwx—— 6 oracle oinstall 4096 Feb 19 17:39 ..
-rw-r–r– 1 oracle oinstall 6771 Oct 16 03:11 README
-rw-r–r– 1 oracle oinstall 5 Oct 16 03:11 kit_version.txt
-rw-rw-r– 1 oracle oinstall 3996158 Oct 16 03:11 orakafka.zip
-rwxr-xr-x 1 oracle oinstall 17599 Oct 16 03:11 orakafka_distro_install.sh
tar xvf sqldeveloper-20.4.0.379.2205-20.4.0-379.2205.noarch.rpm
7. As per _./orakafka-1.2.0/README_, we install Oracle SQL access to Kafka on the Oracle Database host with the help of _./orakafka-1.2.0/orakafka\_distro\_install.sh_ script. Argument -p lets us specify the location or base directory for the Oracle SQL access to Kafka installation on this host.
We choose the newly created empty directory named ora\_kafka\_home as the OSaK base directory on this host. So the full path of the OSaK base directory will be _/home/oracle/ora\_kafka\_home_.
[oracle@dbass ~]$ ./orakafka-1.2.0/orakafka_distro_install.sh -p ./ora_kafka_home/
Step Create Product Home::
————————————————————–
…../home/oracle/ora_kafka_home already exists..
Step Create Product Home: completed.
PRODUCT_HOME=/home/oracle/ora_kafka_home
Step Create app_data home::
————————————————————–
….. creating /home/oracle/ora_kafka_home/app_data and subdirectories
……Generated CONF_KIT_HOME_SCRIPT=/home/oracle/ora_kafka_home/app_data/scripts/configure_kit_home.sh
……Generated CONF_APP_DATA_HOME_SCRIPT=/home/oracle/ora_kafka_home/configure_app_data_home.sh
Step Create app_data home: completed.
APP_DATA_HOME=/home/oracle/ora_kafka_home/app_data
Step unzip_kit::
————————————————————–
…..checking for existing binaries in /home/oracle/ora_kafka_home/orakafka
…..unzip kit into /home/oracle/ora_kafka_home/orakafka
Archive: /home/oracle/orakafka-1.2.0/orakafka.zip
creating: /home/oracle/ora_kafka_home/orakafka/
extracting: /home/oracle/ora_kafka_home/orakafka/kit_version.txt
inflating: /home/oracle/ora_kafka_home/orakafka/README
creating: /home/oracle/ora_kafka_home/orakafka/doc/
inflating: /home/oracle/ora_kafka_home/orakafka/doc/README_INSTALL
creating: /home/oracle/ora_kafka_home/orakafka/jlib/
inflating: /home/oracle/ora_kafka_home/orakafka/jlib/osakafka.jar
inflating: /home/oracle/ora_kafka_home/orakafka/jlib/kafka-clients-2.5.0.jar
inflating: /home/oracle/ora_kafka_home/orakafka/jlib/slf4j-simple-1.7.28.jar
inflating: /home/oracle/ora_kafka_home/orakafka/jlib/lz4-java-no-jni-1.7.1.jar
inflating: /home/oracle/ora_kafka_home/orakafka/jlib/snappy-java-no-jni-1.1.7.3.jar
inflating: /home/oracle/ora_kafka_home/orakafka/jlib/zstd-no-jni-1.4.4-7.jar
inflating: /home/oracle/ora_kafka_home/orakafka/jlib/slf4j-api-1.7.30.jar
creating: /home/oracle/ora_kafka_home/orakafka/bin/
inflating: /home/oracle/ora_kafka_home/orakafka/bin/orakafka_stream.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/orakafka.sh
creating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/removeuser_cluster.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/setup_all.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/remove_cluster.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/verify_install.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/add_cluster.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/config_util.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/test_views.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/install.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/set_java_home.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/list_clusters.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/adduser_cluster.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/uninstall.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/test_cluster.sh
creating: /home/oracle/ora_kafka_home/orakafka/conf/
inflating: /home/oracle/ora_kafka_home/orakafka/conf/orakafka.properties.template
creating: /home/oracle/ora_kafka_home/orakafka/sql/
inflating: /home/oracle/ora_kafka_home/orakafka/sql/orakafkatab.plb
inflating: /home/oracle/ora_kafka_home/orakafka/sql/catnoorakafka.sql
inflating: /home/oracle/ora_kafka_home/orakafka/sql/catorakafka.sql
inflating: /home/oracle/ora_kafka_home/orakafka/sql/pvtorakafkaus.plb
inflating: /home/oracle/ora_kafka_home/orakafka/sql/orakafka_pkg_uninstall.sql
inflating: /home/oracle/ora_kafka_home/orakafka/sql/orakafkab.plb
inflating: /home/oracle/ora_kafka_home/orakafka/sql/pvtorakafkaub.plb
inflating: /home/oracle/ora_kafka_home/orakafka/sql/orakafka_pkg_install.sql
inflating: /home/oracle/ora_kafka_home/orakafka/sql/orakafkas.sql
creating: /home/oracle/ora_kafka_home/orakafka/lib/
inflating: /home/oracle/ora_kafka_home/orakafka/lib/libsnappyjava.so
inflating: /home/oracle/ora_kafka_home/orakafka/lib/libzstd-jni.so
inflating: /home/oracle/ora_kafka_home/orakafka/lib/liblz4-java.so
Step unzip_kit: completed.
Successfully installed orakafka kit in /home/oracle/ora_kafka_home
8. Configure JAVA\_HOME for Oracle SQL access to Kafka. We find the Java path on the node as follows:
[oracle@dbass ~]$ java -XshowSettings:properties -version 2>&1 > /dev/null | grep 'java.home'
java.home = /usr/java/jre1.8.0_271-amd64
[oracle@dbass ~]$ exportação JAVA_HOME=/usr/java/jre1.8.0_271-amd64
To set Java home for OSaK, we use the script _/home/oracle/ora\_kafka\_home/orakafka/bin/orakafka.sh_ script, with _set\_java\_home_ option.
[oracle@dbass bin]$ pwd
/home/oracle/ora_kafka_home/orakafka/bin
[oracle@dbass bin]$ ./orakafka.sh set_java_home -p $JAVA_HOME
Step1: Check for valid JAVA_HOME
————————————————————–
Found /usr/java/jre1.8.0_271-amd64/bin/java, JAVA_HOME path is valid.
Step1 succeeded.
Step2: JAVA version check
————————————————————–
java version “1.8.0_271”
Java(TM) SE Runtime Environment (build 1.8.0_271-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.271-b09, mixed mode)
Java version >= 1.8
Step2 succeeded.
Step3: Creating configure_java.sh script
————————————————————–
Wrote to /home/oracle/ora_kafka_home/app_data/scripts/configure_java.sh
Step3 succeeded.
Successfully configured JAVA_HOME in /home/oracle/ora_kafka_home/app_data/scripts/configure_java.sh
The above information is written to /home/oracle/ora_kafka_home/app_data/logs/set_java_home.log.2021.02.20-04.38.23
[oracle@dbass bin]$
9. Verify installation of OSaK with _verify\_install_ option of script _orakafka.sh_ as follows:
[oracle@dbass ~]$ cd ora_kafka_home/
[oracle@dbass ora_kafka_home]$ cd orakafka/bin/
[oracle@dbass bin]$ ./orakafka.sh verify_install
Verifique toda a propriedade dos arquivos/dirs - transmitida
Verifique os privilégios do diretório - transmitidos
Verifique os arquivos executáveis esperados - transmitidos
As informações acima são gravadas em /home/oracle/ora_kafka_home/app_data/logs/verify_install.log.2021.02.19-18.10.15
### Set Up Oracle Cloud Infrastructure Stream Clusters for Oracle SQL Access to Kafka
1. Under _ora\_kafka\_home_, that is _/home/oracle/ora\_kafka\_home_, we have two more READMEs as follows:
[oracle@dbass ~]$ localize ora_kafka_home/ -name "README*"
ora_kafka_home/orakafka/README
ora_kafka_home/orakafka/doc/README_INSTALL
_~/ora\_kafka\_home/orakafka/README_ is the readme for this release of OSaK that we have installed. Please read through this readme.
And _ora\_kafka\_home/orakafka/doc/README\_INSTALL_ is the README for the actual setup of a Kafka cluster for Oracle SQL access to Kafka. The rest of the steps 2 onwards below follow this README by and large. As per the same, we will leverage _~/ora\_kafka\_home/orakafka/bin/orakafka.s_h script, for adding a Kafka cluster, adding an Oracle Database user for using the Kafka cluster in the next steps.
2. Add our Stream service stream pool to Oracle SQL access to Kafka.
As mentioned earlier, from the Oracle SQL access to Kafka point of view, the Stream service stream pool is a Kafka cluster.
We use the _add\_cluster_ option of the _orakafka.sh_ script to add the cluster to OSaK. We use the _\-c_ argument to name the cluster as _kc1_.
[oracle@dbass bin]$ pwd
/home/oracle/ora_kafka_home/orakafka/bin
[oracle@dbass bin]$ ./orakafka.sh add_cluster -c kc1
Step1: Criação do diretório de configuração do cluster do sistema de arquivos
---------------------
Criação do diretório de cluster do sistema de arquivos concluída.
Configure as propriedades de segurança em /home/oracle/ora_kafka_home/app_data/clusters/KC1/conf/orakafka.properties.
Step1 bem-sucedido.
Step2: Gere DDL para a criação do diretório DB de configuração do cluster
---------------------
Execute o script SQL a seguir enquanto estiver conectado como sysdba
para criar o diretório do banco de dados de configuração do cluster:
@/home/oracle/ora_kafka_home/app_data/scratch/orakafka_create_KC1_CONF_DIR.sql
Step2 script gerado com sucesso.
****SUMÁRIO*****
Tarefas a pagar:
- Configure as propriedades de segurança em /home/oracle/ora_kafka_home/app_data/clusters/KC1/conf/orakafka.properties
- Execute o SQL a seguir enquanto estiver conectado como sysdba:
@/home/oracle/ora_kafka_home/app_data/scratch/orakafka_create_KC1_CONF_DIR.sql
As informações acima são gravadas em /home/oracle/ora_kafka_home/app_data/logs/add_cluster.log.2021.02.20-05.23.30
[componente oracle@dbass]$
We get two TODO tasks as per output from the above execution of the _add\_cluster_ command.
1. For the first task, we add security properties for our Stream service stream to `/home/oracle/ora_kafka_home/app_data/clusters/KC1/conf/orakafka.properties`.
Where to get Kafka-compatible security configs for the Stream service cluster also known as (AKA) streampool? We get these security configs from the OCI web console as shown below.
Please take note of the bootstrap server endpoint(_cell-1.streaming.ap-mumbai-1.oci.oraclecloud.com:9092_ from the screenshot below) as well. It is not related to the security configs of the cluster, but we need it in later steps for connecting to our Stream service and Kafka cluster.

We write the above config values to OSaK in the following format, to `/home/oracle/ora_kafka_home/app_data/clusters/KC1/conf/orakafka.properties` file using any text editor like say vi.

For clarity, we have the same configs in text format as follows:
```
security.protocol=SASL_SSL
sasl.mechanism=PLAIN
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<YOUR_TENANCY_NAME>/<YOUR_OCI_USERID_HERE>/<YOUR_OCI_STREAMPOOL_OCID>" password=" YOUR_AUTH_TOKEN";
sasl.plain.username="<YOUR_TENANCY_NAME>/<YOUR_OCI_USERID_HERE>/<YOUR_OCI_STREAMPOOL_OCID>"
sasl.plain.password ="YOUR_AUTH_TOKEN";
```
**Note:** default Kafka Consumer Configs are already pre-populated in _orakafka.properties_ for this cluster. If there is a need, one can modify these configs.
2. For the second TODO task, do SQL script execution as follows:
```
[oracle@dbass ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Sat Feb 20 05:37:28 2021
Version 19.9.0.0.0
Copyright (c) 1982, 2020, Oracle. All rights reserved.
Connected to:
Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production
Version 19.9.0.0.0
SQL> alter session set container=p0;
Session altered.
SQL> @/home/oracle/ora_kafka_home/app_data/scratch/orakafka_create_KC1_CONF_DIR.sql
Creating database directory "KC1_CONF_DIR"..
Directory created.
The above information is written to /home/oracle/ora_kafka_home/app_data/logs/orakafka_create_KC1_CONF_DIR.log
Disconnected from Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production
Version 19.9.0.0.0
```
Take note of directory object _KC1\_CONF\_DIR_ created by the above SQL script.
**Note:** As dictated in add\_cluster output, we run the SQL script as a _SYSDBA_ user, inside the PDB of our interest (_p0_ PDB here).
3. To make sure that the cluster configuration is working, we can leverage the _test\_cluster_ option of script _orakafka.sh_.
We pass cluster name with -c argument and bootstrap server with -b argument. We have from bootstrap server info from step 4.2.1.
```
[oracle@dbass bin]$ pwd
/home/oracle/ora_kafka_home/orakafka/bin
[oracle@dbass bin]$ ./orakafka.sh test_cluster -c kc1 -b cell-1.streaming.ap-mumbai-1.oci.oraclecloud.com:9092
Kafka cluster configuration test succeeded.
Kafka cluster configuration test - "KC1"
------------------------------------------------------
KAFKA_BOOTSTRAP_SERVERS=cell-1.streaming.ap-mumbai-1.oci.oraclecloud.com:9092
LOCATION_FILE="/home/oracle/ora_kafka_home/app_data/clusters/KC1/logs/orakafka_stream_KC1.loc"
ora_kafka_operation=metadata
kafka_bootstrap_servers=cell-1.streaming.ap-mumbai-1.oci.oraclecloud.com:9092
List topics output:
StreamForOsak,3
...
For full log, please look at /home/oracle/ora_kafka_home/app_data/clusters/KC1/logs/test_KC1.log.2021.02.20-09.01.12
Test of Kafka cluster configuration for "KC1" completed.
The above information is written to /home/oracle/ora_kafka_home/app_data/logs/test_cluster.log.2021.02.20-09.01.12
[oracle@dbass bin]$
```
As you can see our Kafka cluster configuration test succeeded! We get the list of topics, AKA the Stream service streams in the output here. Topic names are followed by the number of partitions for that stream. Here we have the number of partitions as three, as the Stream service stream StreamForOsak has exactly three partitions.
3. Configure an Oracle Database user for the added Kafka cluster.
We already have created an Oracle Pluggable Databases (PDB) level Oracle Database user with username books\_admin, for the PDB named _p0_. We use the _adduser\_cluster_ option to grant required permissions for user books\_admin on Kafka cluster _kc1_.
[oracle@dbass bin]$ ./orakafka.sh adduser_cluster -c kc1 -u books_admin
Step1: Generate DDL to grant permissions on cluster configuration directory to "BOOKS_ADMIN"
--------------------------------------------------------------------------------------------
Execute the following script while connected as sysdba
to grant permissions on cluster conf directory :
@/home/oracle/ora_kafka_home/app_data/scratch/orakafka_adduser_cluster_KC1_user1.sql
Step1 successfully generated script.
***********SUMMARY************
TODO tasks:
1. Execute the following SQL while connected as sysdba:
@/home/oracle/ora_kafka_home/app_data/scratch/orakafka_adduser_cluster_KC1_user1.sql
The above information is written to /home/oracle/ora_kafka_home/app_data/logs/adduser_cluster.log.2021.02.20-10.45.57
[oracle@dbass bin]$
Assim como na etapa anterior, temos uma tarefa TODO a ser executada.
De acordo com a saída, temos um script SQL gerado automaticamente. Precisamos executar esse script (como sysdba), para conceder ao usuário do Oracle Database permissões books_admin no diretório de configuração de cluster para o cluster kc1.
Esse diretório em nosso caso é /home/oracle/ora_kafka_home/app_data/clusters/KC1.
[oracle@dbass ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Sat Feb 20 10:56:17 2021
Version 19.9.0.0.0
Copyright (c) 1982, 2020, Oracle. All rights reserved.
Connected to:
Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production
Version 19.9.0.0.0
SQL> alter session set container=p0;
Session altered.
SQL> @/home/oracle/ora_kafka_home/app_data/scratch/orakafka_adduser_cluster_KC1_user1.sql
PL/SQL procedure successfully completed.
Granting permissions on "KC1_CONF_DIR" to "BOOKS_ADMIN"
Grant succeeded.`
`The above information is written to /home/oracle/ora_kafka_home/app_data/logs/orakafka_adduser_cluster_KC1_user1.log
Disconnected from Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production
Version 19.9.0.0.0
[oracle@dbass ~]$
-
Agora, aproveitamos a opção install de orakafka.sh. Passamos o diretório pai (com argumento -p) dos dados deste usuário relacionados às suas atividades OSaK nos Clusters do Kafka aos quais ele foi adicionado.
Esse comando gera automaticamente dois scripts DDL (Data Definition Language) para nós da seguinte forma:
[oracle@dbass bin]$ ./orakafka.sh install -u books_admin -r /home/oracle/ora_kafka_home/books_admin_user_data_dir Step1: Creation of filesystem location and default directories -------------------------------------------------------------- Created filesystem location directory at /home/oracle/ora_kafka_home/books_admin_user_data_dir/orakafka_location_dir Created filesystem default directory at /home/oracle/ora_kafka_home/books_admin_user_data_dir/orakafka_default_dir Step1 succeeded. Step2: Generate DDL for creation of DB location and default directories -------------------------------------------------------------- Execute the following SQL script while connected as sysdba to setup database directories: @/home/oracle/ora_kafka_home/app_data/scratch/setup_db_dirs_user1.sql On failure, to cleanup location and default directory setup, please run "./orakafka.sh uninstall -u 'BOOKS_ADMIN'" Step2 successfully generated script. Step3: Install ORA_KAFKA package in "BOOKS_ADMIN" user schema -------------------------------------------------------------- Execute the following script in user schema "BOOKS_ADMIN" to install ORA_KAFKA package in the user schema @/home/oracle/ora_kafka_home/app_data/scratch/install_orakafka_user1.sql On failure, to cleanup ORA_KAFKA package from user schema, please run "./orakafka.sh uninstall -u 'BOOKS_ADMIN'" Step3 successfully generated script. ***********SUMMARY************ TODO tasks: 1. Execute the following SQL while connected as sysdba: @/home/oracle/ora_kafka_home/app_data/scratch/setup_db_dirs_user1.sql 2. Execute the following SQL in user schema: @/home/oracle/ora_kafka_home/app_data/scratch/install_orakafka_user1.sql The above information is written to /home/oracle/ora_kafka_home/app_data/logs/install.log.2021.02.20-11.33.09 [oracle@dbass bin] -
A primeira tarefa é executar um script SQL para registrar os dois diretórios, ou seja, /home/oracle/ora_kafka_home/books_admin_user_data_dir/orakafka_location_dir e /home/oracle/ora_kafka_home/books_admin_user_data_dir/orakafka_default_dir
no Oracle DB, como objetos de diretórios.Conforme prescrito na saída, precisamos executá-lo com privilégios SYSDBA, da seguinte forma:
[oracle@dbass ~]$ sqlplus / as sysdba SQL*Plus: Release 19.0.0.0.0 - Production on Sat Feb 20 11:46:04 2021 Version 19.9.0.0.0 Copyright (c) 1982, 2020, Oracle. All rights reserved. Connected to: Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production Version 19.9.0.0.0 SQL> alter session set container=p0; Session altered. SQL> @/home/oracle/ora_kafka_home/app_data/scratch/setup_db_dirs_user1.sql Checking if user exists.. PL/SQL procedure successfully completed. Creating location and default directories.. PL/SQL procedure successfully completed. Directory created. Directory created. Grant succeeded. Grant succeeded. Creation of location dir "BOOKS_ADMIN_KAFKA_LOC_DIR" and default dir "BOOKS_ADMIN_KAFKA_DEF_DIR" completed. Grant of required permissions on "BOOKS_ADMIN_KAFKA_LOC_DIR","BOOKS_ADMIN_KAFKA_DEF_DIR" to "BOOKS_ADMIN" completed. The above information is written to /home/oracle/ora_kafka_home/app_data/logs/setup_db_dirs_user1.log Disconnected from Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production Version 19.9.0.0.0 [oracle@dbass ~]$Anote os objetos de diretório criados pelos scripts SQL acima, ou seja, BOOKS_ADMIN_KAFKA_LOC_DIR e BOOKS_ADMIN_KAFKA_DEF_DIR.
Agora, vamos para a segunda tarefa TODO.
-
Aqui executamos outro script SQL como books_admin (e não sysdba) no PDB p0. Este script instalará o acesso do Oracle SQL ao pacote e aos objetos do Kafka no esquema pertencente a books_admin.
[oracle@dbass ~]$ sqlplus books_admin@p0pdb #p0pdb is tns entry for p0 pdb SQL*Plus: Release 19.0.0.0.0 - Production on Sat Feb 20 11:52:33 2021 Version 19.9.0.0.0 Copyright (c) 1982, 2020, Oracle. All rights reserved. Enter password: Last Successful login time: Fri Feb 19 2021 14:04:59 +00:00 Connected to: Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production Version 19.9.0.0.0 SQL> ALTER SESSION SET CONTAINER=p0; Session altered. SQL> @/home/oracle/ora_kafka_home/app_data/scratch/install_orakafka_user1.sql Verifying user schema.. PL/SQL procedure successfully completed. Verifying that location and default directories are accessible.. PL/SQL procedure successfully completed. Installing ORA_KAFKA package in user schema.. .. Creating ORA_KAFKA artifacts Table created. Table created. Table created. Table created. Package created. No errors. Package created. No errors. Package body created. No errors. Package body created. No errors. The above information is written to /home/oracle/ora_kafka_home/app_data/logs/install_orakafka_user1.log Disconnected from Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production Version 19.9.0.0.0 [oracle@dbass ~]$
Registrar o Cluster do Serviço Stream com o Oracle Database e Criar Views para o Stream
Nesta etapa, o cluster kc1 com o Oracle Database e criamos views para o fluxo StreamForOsak.
Todas as consultas SQL desta etapa devem ser executadas como usuário books_admin e no PDB p0.
- Registre o cluster com acesso do Oracle SQL ao procedimento Kafka ORA_KAFKA.REGISTER_CLUSTER.
BEGIN
ORA_KAFKA.REGISTER_CLUSTER
('kc1', -- cluster name
'cell-1.streaming.ap-mumbai-1.oci.oraclecloud.com:9092', -- fill up your bootstrap server here
'BOOKS_ADMIN_KAFKA_DEF_DIR', -- default directory for external table created in previous steps
'BOOKS_ADMIN_KAFKA_LOC_DIR', -- this directory object too is created in previous steps
'KC1_CONF_DIR', --config dir for cluster
'Registering kc1 for this session'); --description
END;
/
- Crie uma tabela do Oracle Database chamada BOOKS, que precisa ter o mesmo esquema que as mensagens em nosso Tópico do Kafka StreamForOsak.
CREATE TABLE BOOKS ( -- reference table. It is empty table. Schema of this table must correspond to Kafka Messages
id int,
title varchar2(50),
author_name varchar2(50),
author_email varchar2(50),
publisher varchar2(50)
);
/
- Crie uma view para nosso tópico StreamForOsak com o procedimento de ajuda armazenado no acesso do Oracle SQL ao pacote Kafka viz CREATE_VIEWS, como a seguir.
DECLARE
application_id VARCHAR2(128);
views_created INTEGER;
BEGIN
ORA_KAFKA.CREATE_VIEWS
('kc1', -- cluster name
'OsakApp0', -- consumer group name that OSS or Kafka cluster sees.
'StreamForOsak', -- Kafka topic aka OSS stream name
'CSV', -- format type
'BOOKS', -- database reference table
views_created, -- output
application_id); --output
dbms_output.put_line('views created = ' || views_created);
dbms_output.put_line('application id = ' || application_id);
END;
/
O acesso do Oracle SQL ao Kafka suporta dois formatos para mensagens do Kafka, CSV e JSON. Aqui estamos usando CSV. Portanto, um exemplo de mensagem Kafka em conformidade com o esquema de tabela BOOKS pode ser 101, Famous Book, John Smith, john@smith.com, First Software.
tar xvf sqldeveloper-20.4.0.379.2205-20.4.0-379.2205.noarch.rpm
- A etapa acima criará uma view para cada partição do tópico. Como o tópico StreamForOsak tem três partições, teremos três views. O nome de cada view estará no formato KV_<CLUSTER_NAME>_<GROUP_NAME>_TOPIC_<NUM_OF_PARTITION>.
Aqui temos três views conforme mostrado abaixo, uma para cada partição.
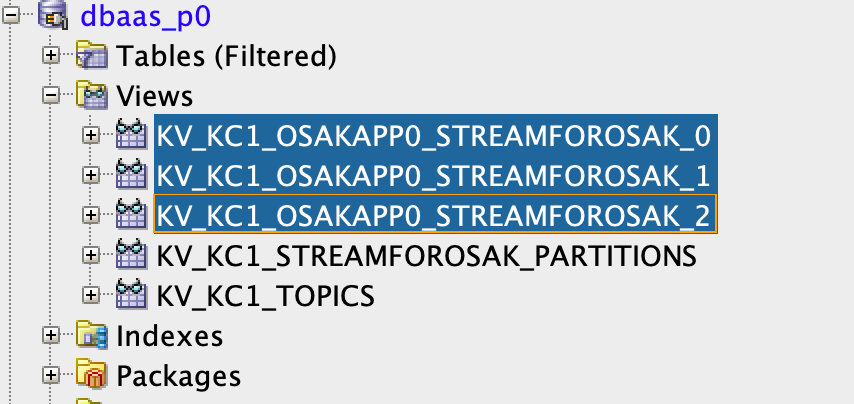
Portanto, a view KV_KC1_OSAKAPP0_STREAMFOROSAK_0 está mapeada para a partição 0, a view KV_KC1_OSAKAPP0_STREAMFOROSAK_2 está mapeada para a partição 1 e, por último, KV_KC1_OSAKAPP0_STREAMFOROSAK_0 está mapeada para a partição 2 do tópico StreamForOsak.
Produza Dados para o Fluxo
- Produza uma mensagem de teste para transmitir StreamForOsak, usando o botão Produzir Mensagem de Teste da console Web do OCI (Oracle Cloud Infrastructure), conforme mostrado abaixo.
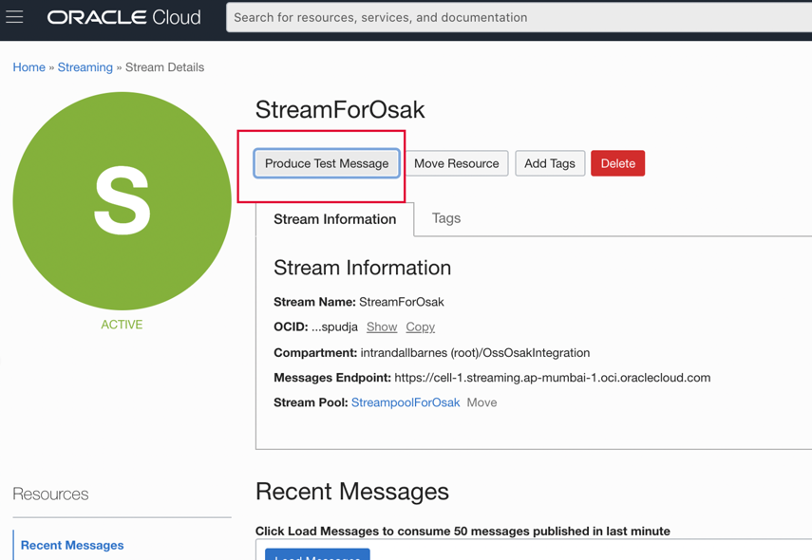
Quando clicamos em Produzir Mensagem de Teste, é exibida uma janela com um campo para informar nossa mensagem de teste, conforme mostrado abaixo.
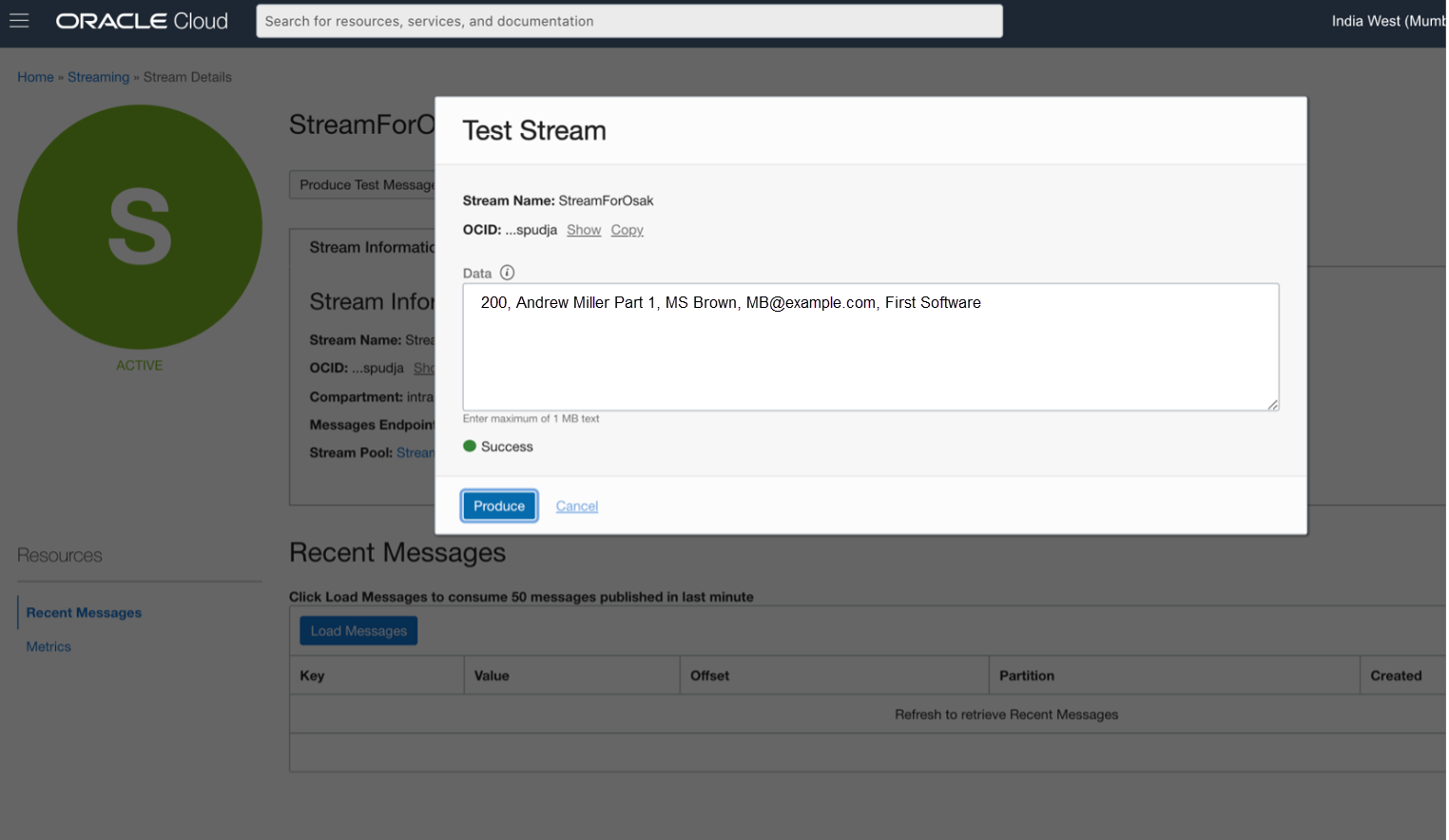
Inserimos a mensagem abaixo:
200, Andrew Miller Parte 1, MS Brown, mb@example.com, Primeiro Software
É desnecessário dizer que também poderíamos ter usado a API Kafka Producer padrão em Java/Python ou OCI SDK para o serviço de Stream, para produzir a mensagem para o fluxo de serviço de Stream.
- Depois de clicarmos em Produzir na janela acima, publicamos a mensagem para o fluxo StreamForOsak. Podemos usar o utilitário Carregar Mensagem para ver a partição em que nossa mensagem chegou.
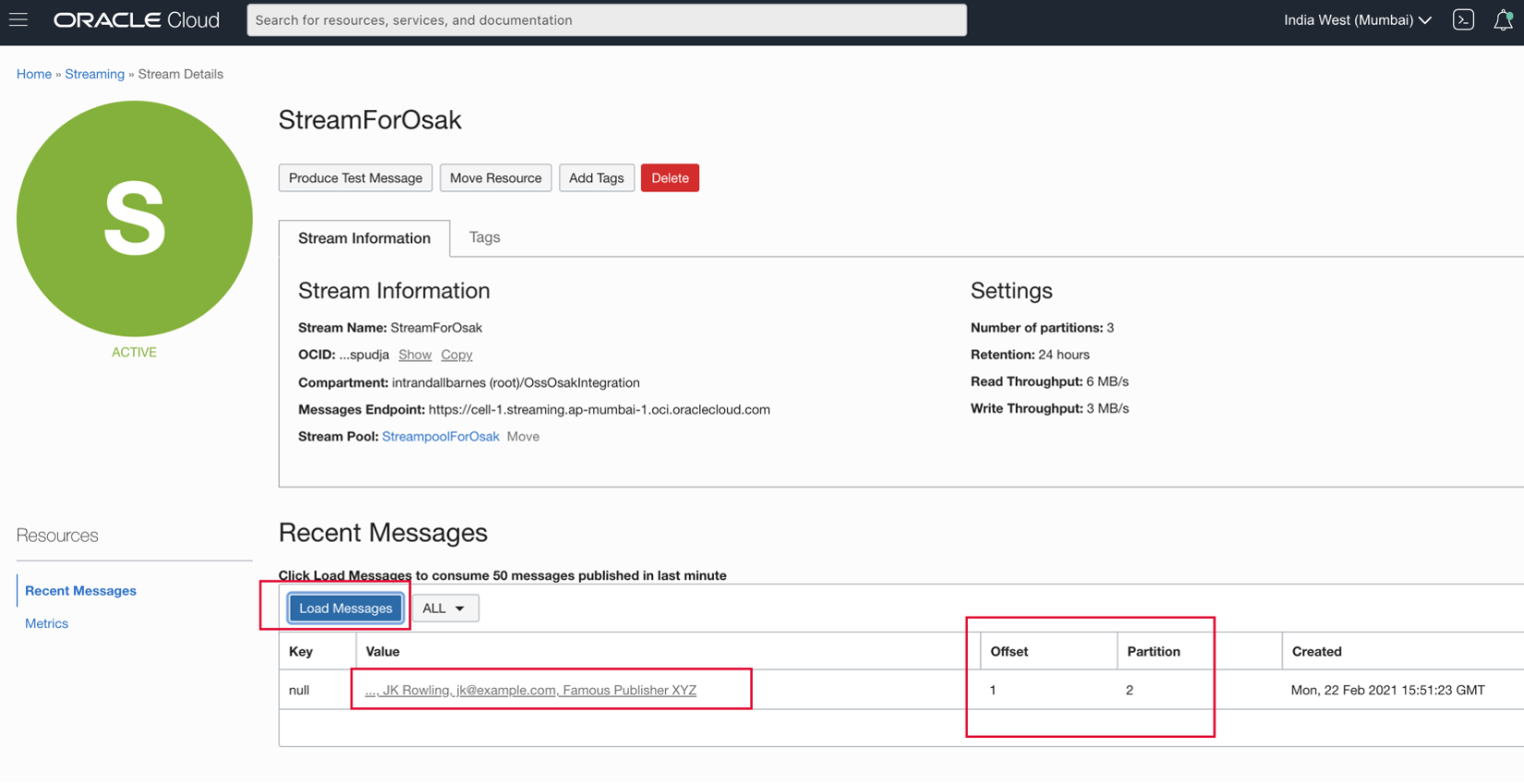
Conforme mostrado acima, nossa mensagem foi exibida na partição 2 do tópico StreamForOsak.
Recuperar as Mensagens do Serviço Stream Usando as Views de Banco de Dados Configuradas pelo Acesso Oracle SQL aos Procedimentos Armazenados do Kafka
Podemos executar uma consulta SQL simples:
SELECT * FROM KV_KC1_OSAKAPP0_STREAMFOROSAK_2_
Ou, como mostrado abaixo, podemos simplesmente abrir a view do desenvolvedor SQL para ver os dados na view KV_KC1_OSAKAPP0_STREAMFOROSAK_2:
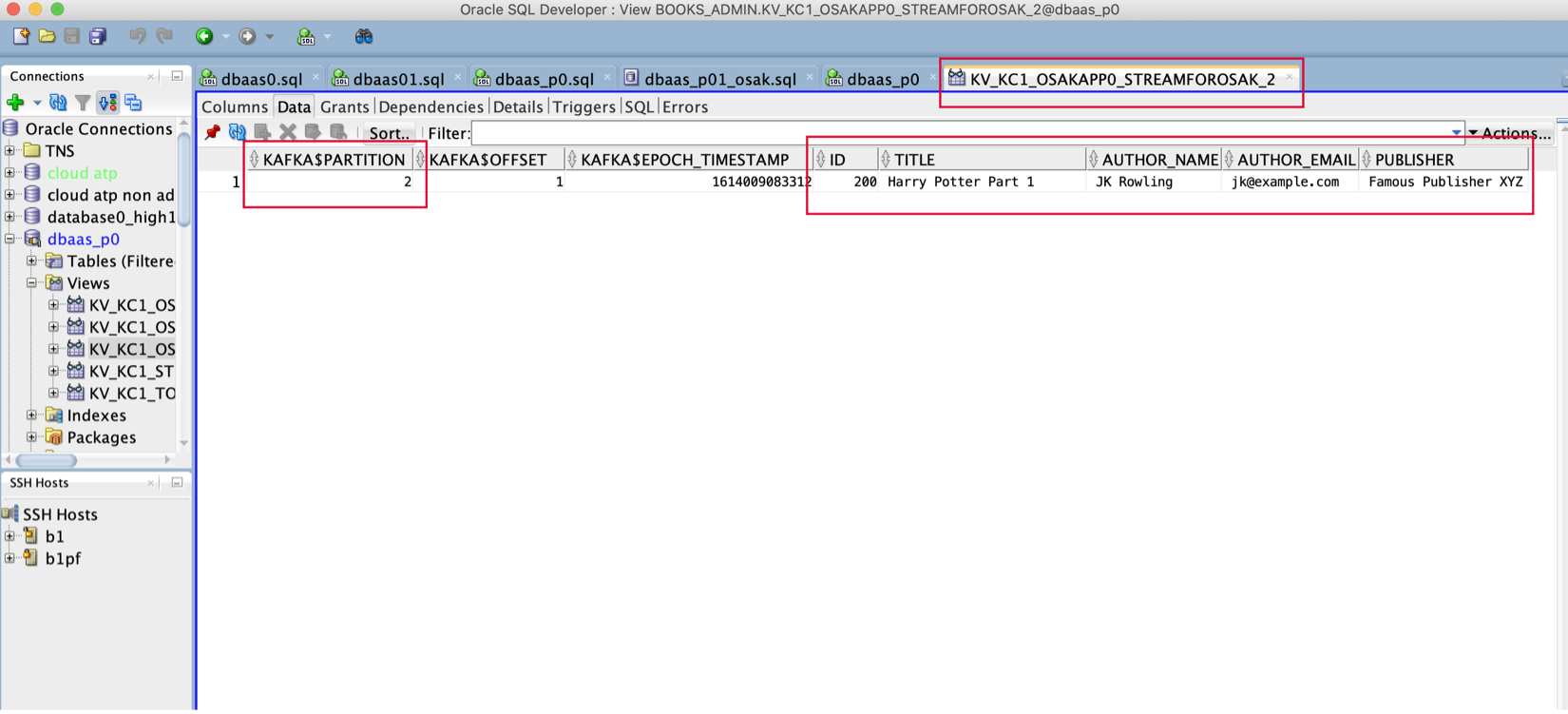
Escolhemos a exibição KV_KC1_OSAKAPP0_STREAMFOROSAK_2, pois corresponde à partição 2 do fluxo StreamForOsak. Assim, toda vez que executarmos a consulta SELECT SQL para essa view, ela vai para a partição correspondente de seu tópico associado e extrai novas mensagens não confirmadas (para o grupo de consumidores OsakApp0), como linhas na view. Cada mensagem obtém sua própria linha na view. Observe que os dados dessas exibições não são persistidos.
Olhos curiosos também podem observar que o acesso do Oracle SQL ao Kafka extrai e armazena informações de metadados como o deslocamento da mensagem, sua partição e timestamp em colunas adicionais.
Muito provavelmente, você deseja consultar essa view repetidamente e, para cada execução da consulta, deseja que a view se mova sequencialmente no fluxo. Você pode conseguir isso facilmente com o seguinte trecho de código canônico:
LOOP
ORA_KAFKA.NEXT_OFFSET(‘_KV_KC1_OSAKAPP0_STREAMFOROSAK_2_’);
SELECT * FROM KV_KC1_OSAKAPP0_STREAMFOROSAK_2_;
ORA_KAFKA.UPDATE_OFFSET(‘_KV_KC1_OSAKAPP0_STREAMFOROSAK_2_’);
COMMIT;
END LOOP;
Como dito anteriormente, quando usamos o acesso do Oracle SQL ao Kafka, as deslocações de fluxo são gerenciadas pelo Oracle Database, e não pelo serviço de Fluxo. Eles vivem em tabelas do sistema que rastreiam o posicionamento de deslocamentos para todas as partições acessadas pela exibição KV_KC1_OSAKAPP0_STREAMFOROSAK_2.
A chamada NEXT_OFFSET simplesmente vincula a view KV_KC1_OSAKAPP0_STREAMFOROSAK_2 a um novo conjunto de deslocamentos que representam novos dados que residem na partição do Oracle Cloud Infrastructure Streaming acessada pela view. O UPDATE_OFFSET comunica quantas linhas foram lidas para cada partição e avança as compensações para novas posições.
A COMMIT garante que essa unidade de trabalho seja compatível com ACID.
Conclusão
Neste tutorial, nós nos concentramos em como podemos instalar o acesso do Oracle SQL ao Kafka e usá-lo com o serviço de Stream. Como o serviço Stream é compatível com o Kafka, é exatamente como um cluster Kafka para acesso ao Oracle SQL ao Kafka.
Observe que, aqui, quase não arranhamos a superfície em relação à funcionalidade oferecida pelo acesso do Oracle SQL ao Kafka. O acesso do Oracle SQL ao Kafka é altamente configurável. Podemos até armazenar os dados de streaming nas tabelas do Oracle Database, que persistem no disco, ao contrário das views. Consulte os arquivos README fornecidos no acesso do Oracle SQL à instalação do Kafka e as referências abaixo para obter mais detalhes.
Links Relacionados
- Documentação do desenvolvedor Oracle PL/SQL para acesso ao Oracle SQL ao Kafka
- Acesso do Oracle SQL ao Kafka no blog do Oracle
- Acesso do Oracle SQL ao Kafka no Oracle Big Data SQL
- Oracle Cloud Infrastructure Streaming
- Compatibilidade da API do Kafka do serviço de streaming
Agradecimentos
- Autor - Mayur Raleraskar, Arquiteto de Soluções
"
Mais Recursos de Aprendizagem
Explore outros laboratórios em docs.oracle.com/learn ou acesse mais conteúdo de aprendizado gratuito no canal YouTube do Oracle Learning. Além disso, visite education.oracle.com/learning-explorer para se tornar um Oracle Learning Explorer.
Para obter a documentação do produto, visite o Oracle Help Center.
Stream analytics using Oracle Cloud Infrastructure Streaming and Oracle Database
F50456-01
November 2021
Copyright © 2021, Oracle and/or its affiliates.